本文主要探索 开源网络剪枝(结构化剪枝与稀疏化置零)技术在地平线 征程 5 上的可行性和有效性,涉及到的压缩方案,均不考虑硬件加速特性。
01 实验结果先解读
表中涉及到结构化剪枝两种(ABCPruner_2020、HRankPlus_2020)、结构化稀疏两种(CHEX_2022、1XN_2022),从实验数据可以看出:
- 在分类任务中,在不使用数据增强、蒸馏、嫁接等主流且有效提升精度的方法下,结构化剪枝与稀疏化在精度损失较小的情况下,在 征程 5 上均可以提升性能(latency、FPS)。
- 结构化稀疏比结构化剪枝,精度上表现更好,但性能表现弱于后者。
- 网络稀疏化应用于轻量型网络结构,如 mobilenet,压缩百分比相对较小,精度损失相比 resnet 较大,侧面说明轻量型网络中冗余结构相对较少。
1.1 分类模型

HRankplus 和 ABCPruner 属于结构化剪枝,1XN 和 CHEX 属于结构化稀疏。复现的文件:https://pan.baidu.com/s/1zmUqTuxE1k5LIGPpqBq_Sw 32sv
1.2 检测模型
使用稀疏化方法 CHEX 对 SSD_resnet50_300x300 方法在 coco2017 检测数据集上进行实践。

已使用 hb_verifier 工具验证 quanti.onnx 和 bin 模型的输出一致性
模型压缩常用的方案包括量化、蒸馏、紧凑型网络设计以及网络剪枝(稀疏化),下面分别对前三种进行简单的介绍(不感兴趣可跳过 ),对网络剪枝和稀疏化进行详细的介绍(对应上面的实践结果)。
02 量化
2.1 概述
将网络参数从 32 位浮点数据映射到更低位数(int16/int8/int4 等)的数据,这个过程称之为量化。反之,称之为反量化。
量化本质上是对数值范围的重新调整,可以「粗略」理解为是一种线性映射。(之所以加「粗略」二字,是因为有些论文会用非线性量化(对数量化等),但目前在工业界落地的还都是线性量化(对称量化、非对称量化、二值化等),地平线采用的主要是线性量化中的对称量化。
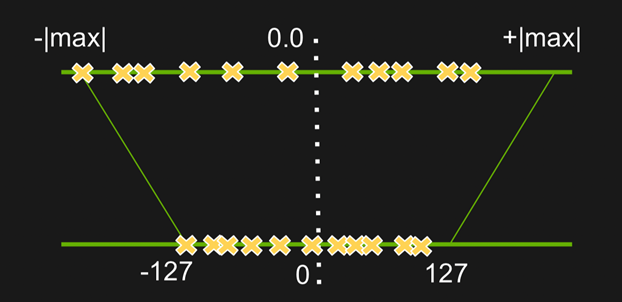
反量化一般没有信息损失,而量化一般会有精度损失。这是由于 float32 能保存的数值范围比 uint8 多,因此必定有大量数值无法用 uint8 表示,只能四舍五入成 uint8 类型的数值,继而引起量化误差。

量化的可行性依据:神经网络具有良好的鲁棒性,将高精度模型量化到低精度模型,这个过程可以认为是引入了噪声,而模型对噪声相对不敏感,因此量化后的模型也能保持较好的精度。
量化的目的:降低计算复杂度,提高模型推理速度,降低存储体积,减少计算能耗。在一些对能耗和时间要求更高的场景下,量化是一个必然的选择。
2.2 浮点/定点转换公式
用 r 表示浮点实数,q 表示量化后的定点整数。浮点和整型之间的换算公式为:
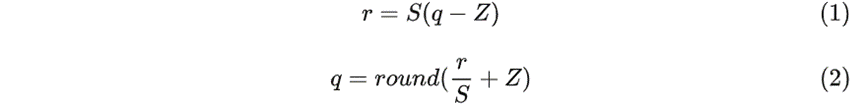
其中,S 是 scale,表示实数和整数之间的比例关系,Z 是 zero point,表示实数中的 0 经过量化后对应的整数,它们的计算方法为:
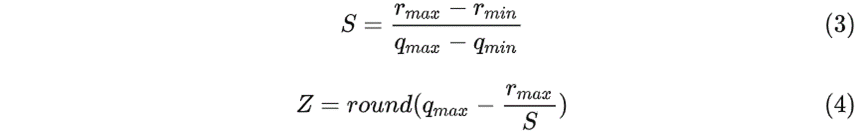
其中,分别是 浮点实数 r 的最小值和最大值,分别是 定点整数 q 的最小值和最大值。
重点解释:定点整数的 zero point 代表浮点实数的 0,二者之间的换算不存在精度损失,这一点可以从公式 (2) 中看出来,把 r=0 代入后就可以得到 q=Z。这么做的目的是为了在 padding 时保证浮点数值的 0 和定点整数的 zero point 完全等价,保证定点和浮点之间的表征能够一致。
对称/非对称量化:当实数中的 0 量化后对应整数 Z 也是 0 时,称之为对称量化,否则,为非对称量化。对称量化相比于非对称量化的精度可能要差一些,但速度会快一些,原因可见公式(7),将公式中的 Z 置零。
2.3 矩阵运算的量化
卷积网络中的卷积层和全连接层本质上都是一堆矩阵乘法,下面我们来看一看如何将矩阵中的浮点运算转换为定点运算。
假设 r_1、、r_2 是浮点实数上的两个 N×N 的矩阵,r3 是 r_1、、r_2 相乘后的矩阵,矩阵相乘可表示为:
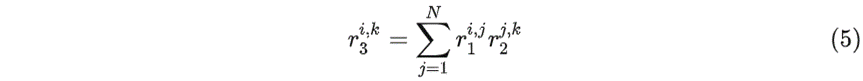
假设S 1、S 2 是r 1 矩阵对应的 scale 和 zero point,S 2 、Z 2 、S 3 、Z3 同理,那么由 (5) 式可以推出:
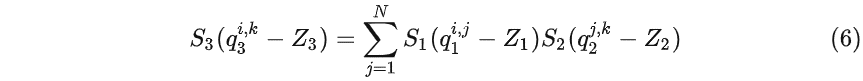
整理一下可以得到:
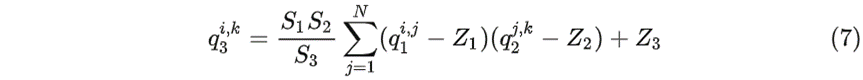
观察 (7) 式可以发现,除了 S 1S 2/S3 ,其它都是定点整数运算。
那如何把 S 1S 2/S3 也变成定点运算呢?
假设M =S 1S 2/S 3,由于 M 通常都是 (0, 1) 之间的实数 (这是通过大量实验统计出来的),因此可以表示成,其中 M0 是一个定点实数。注意,定点数并不一定是整数,所谓定点,指的是小数位数是固定的。
因此,如果存在,我们就可以通过 M0 的 bit 位移操作实现,这样整个矩阵计算过程就都在定点上计算了。
03 知识蒸馏
知识蒸馏是一种基于"教师---学生网络"的方法,属于迁移学习的一个分支,教师网络通常是精度更高的大网络,学生网络通常是结构相对简单的小网络。
主要思想:在网络训练期间,将教师网络的输出信息作为监督信号(知识、软标签),用于指导学生网络去模仿教师网络学习到的信息,继而达到提升学生网络精度的目的。
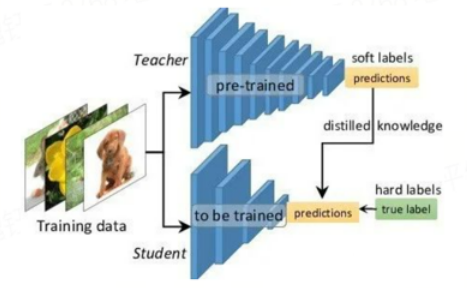
举个例子,一张 dog 的图片,它像 cat 的概率远高于像 car 的概率,而仅从 label 上是无法体现出这一点的,因此需要一些"暗知识"来体现这一点,这个"暗知识"就是教师网络的输出信息。

关于如何转移"暗知识",就有很多花样了,在这里不去阐述。
知识蒸馏在分类任务中有着非常优秀的表现,在目标检测等复杂任务场景中的应用还需要进一步的探索与实践。
04 紧凑型网络设计
紧凑型网络设计的原理是不使用传统的计算量较大的卷积方法进行特征提取,而是设计、选用一些计算量更小、特征提取能力较强的特殊卷积方法,例如我们耳熟能详的深度可分离卷积。下面对传统卷积和深度可分离卷积的实现进行分析。
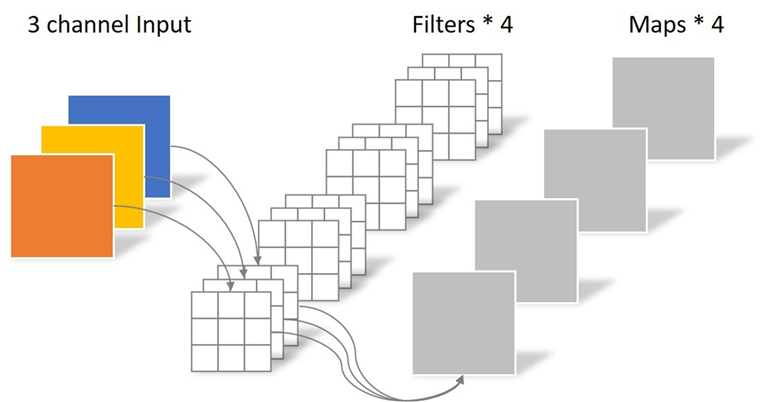
传统卷积通过一次卷积,实现 self_channel 上和 channel 之间的特征信息都关注,生成 4 张特征图;
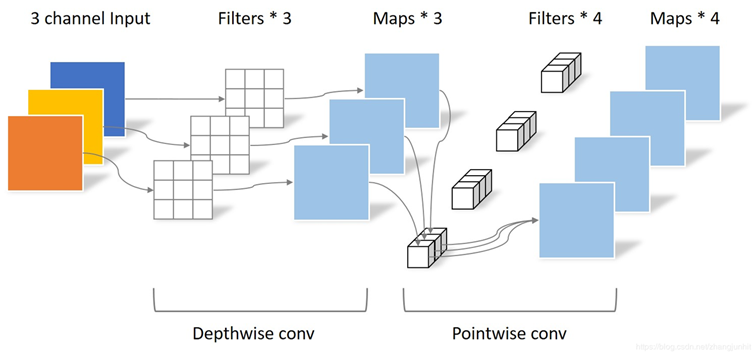
深度可分离卷积,先通过 depthwise conv 获取 self_channel 上的特征信息,再通过 pointwise conv 获取通道间的特征信息,生成 4 张特征图。
在特征提取能力大致相同的情况下,深度可分离卷积的实现方式,参数量大幅减少。紧凑型网络结构的设计需要大量实验驱动,以保证设计出的网络结构在不同应用场景下均有着良好的表现。
05 网络剪枝与稀疏化
5.1 总体介绍
网络剪枝的目的:在保证任务精度的同时,剪枝网络中更多的冗余结构,继而加快模型运行速度。
网络剪枝分为非结构化剪枝和结构化剪枝。非结构化剪枝通过剪枝网络每层的神经元来压缩网络,剪枝某个神经元就是将该神经元的值设置为 0,本质上是一种稀疏化的过程。由于其可以通过算法深入到神经元进行剪枝,因此可以获得更高的压缩率。
这种方法可以通过稀疏化存储方式减少内存占用,较大程度上压缩网络存储体积,但并没有减少计算量。同时,这种剪枝方式也会导致不规则的内存访问,影响网络的在线推理效率,需要特殊设计的软硬件进行加速。
与之相对应的是结构化网络剪枝。结构化剪枝是一种移除网络中 Vector 或 kernel 或 filter 的剪枝方法,剪枝后的网络可以使用基础线性代数程序库,是一种软硬件友好型剪枝方式。尽管相对于非结构化剪枝而言,结构化剪枝压缩率较低,但结构化剪枝不仅可以降低模型在设备上的内存占用,还可以真正意义上减少网络的计算量,加速模型推理。
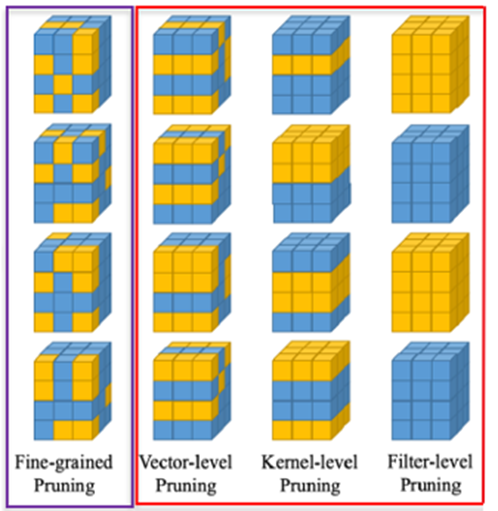
网络剪枝所面临的挑战主要包括以下三点:
(1) 缺乏权威的度量标准。"Smaller-Norm-Less-Important(SNLI)"流派,网络剪枝基于某度量标准来判断某个结构是否重要,继而进行剪枝,这个度量标准众说纷纭,例如基于 L1 范数、矩阵中 0 的个数、导数、信息熵等等,给研究者们带来无限可能。非 SNLI 流派认为,不是某个网络结构重要,而是网络每层过滤器的保留率重要。
(2) 需要依赖训练数据。针对不同的任务场景,模型剪枝需要依赖数据,现有的大多数剪枝方法采用迭代剪枝的方式,边训练边剪枝,无法在离开数据的情况下获取剪枝模型。
(3) 耗费大量时间与计算资源。网络剪枝通常采用多阶段优化的迭代裁剪(逐层迭代、端到端迭代),最后将迭代裁剪后的网络进行大量重训练来恢复网络精度,需要消耗大量计算资源。
5.2 filter/channel 剪枝发展历程
逐层迭代剪枝过程:

端到端迭代剪枝过程:

终极目的都是为了获取过滤器保留率(or 压缩率)。
常规卷积剪枝示意图如下:
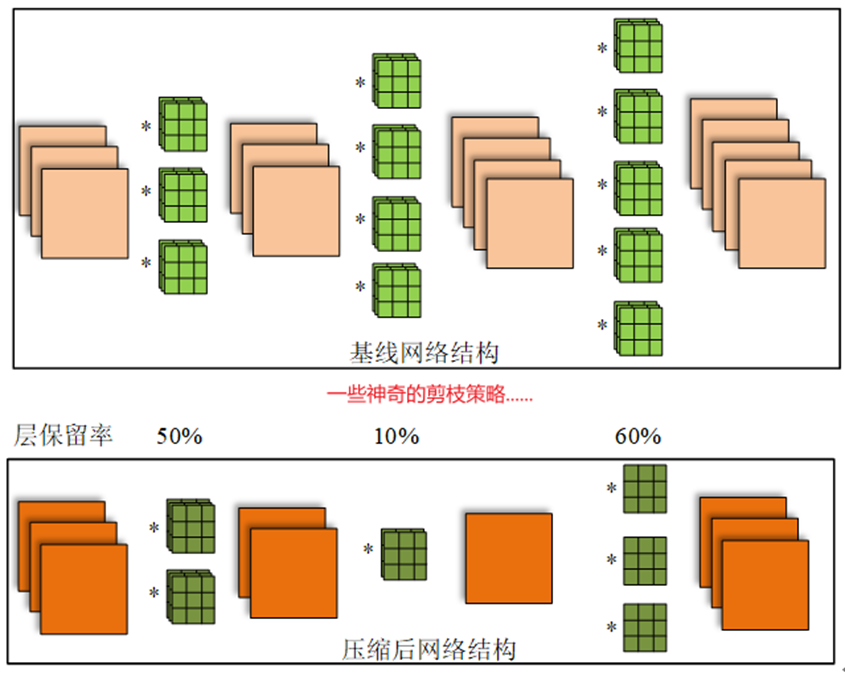
注意:某一层 filter 少了,下一层每个 filter 中的 kernel 也会跟着减少。
具有短连接的网络剪枝示意图如下:
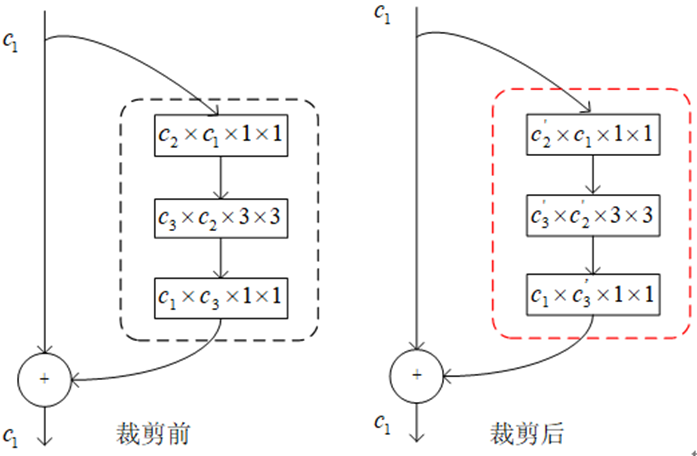
其中,C 2×C 1×1×1 表示卷积层有C 2 个过滤器(filter),每个过滤器有C 1 个卷积核(kernel),C′表示压缩后的过滤器(or 卷积核)个数。
保留率(or 压缩率)的获取方案可以分为:人工设置(HRankPlus)和方案搜索(ABCPruner),下面在典型论文中分别进行介绍。
5.3 HRankPlus
CVPR 2020, Oral
*5.3.1 理论知识*
灵感来自于一个发现:无论 CNN 接收的图像 batch 数是多少,由单个滤波器生成的多个特征图的平均秩总是相同的。作者提出一种针对低秩特征图所对应过滤器进行剪枝的算法。
剪枝原理:低秩特征图包含的信息较少。
为什么 秩 可以作为衡量特征图信息丰富度的指标?作者通过两个理论、一个实验来证明。
什么是矩阵的秩(Rank) :
一个矩阵可以看作多个列向量的组合,如果一个列向量可以被其它列向量的通过一定的线性运算表达出来,就说这些向量是线性相关的。倘若一组向量相互不能够被表达,那么这组向量就是线性无关。
一个矩阵的 rank 就是最大线性不相关的向量个数。一个矩阵的秩反应了矩阵所拥有的有效信息量,不相关的向量组合可以看作是有效的信息,而相关的向量可以用这些有效的信息来表达,它是冗余的。
理论 1:
对特征图进行奇异值分解,特征图可以分解为包含大部分信息但比原始特征图的秩小一点的矩阵(秩为 r ′ r^{'} r′的矩阵)和包含小部分额外信息的矩阵。这个过程表明矩阵的秩越高,信息量越大(因为大的可以一直分成小的,所以比小的信息量高)
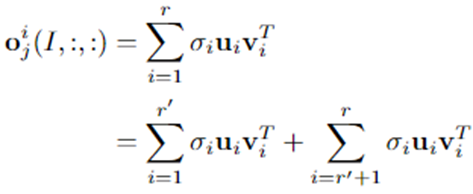
理论 2:
无论 CNN 看到多少数据,单个过滤器生成的 feature map 的平均秩总是相同的,这表明,只使用输入图像的一小部分就可以准确地估计 CNN 中特征图的秩,从而达到高效的目的。

- x 轴:某层多个特征图的 indices
- y 轴:第几个 batch 喂入的数据
实验 1:
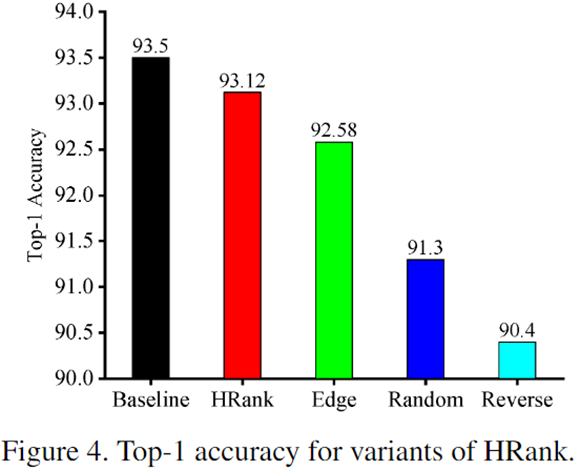
- HRank:剪 low_rank
- Edge:low_rank 和 high_rank 都剪
- Random:随机剪
- Reverse:剪 high_rank
5.3.2 剪枝过程
多个输入 feature map 经过一个 filter 之后的 feature map 的平均 rank 几乎是不变的,这表明输出 feature map 的秩主要是由 filter 决定的(由输入 feature map 和 filter 共同决定)。
这给了作者启发:通过少量输入(feature map)就可以估算一个 filter 生成的 feature map 的秩的大小,这极大程度上减少了网络剪枝的计算开销,因为不用去计算更多的输入数据了。
生成秩的过程中:batch 设置为 128,使用 5 个 batch 来评估 CNN 卷积层的秩。
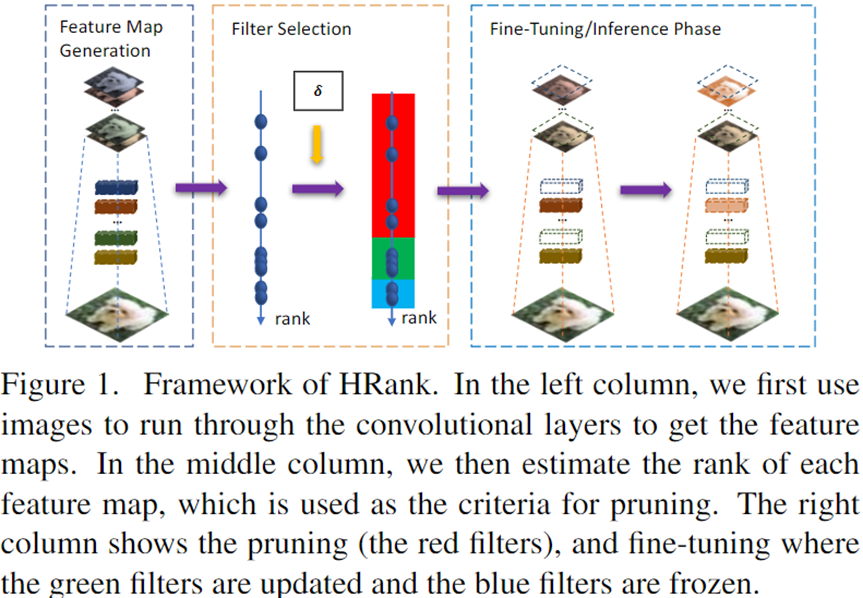
首先,将图像输入模型,生成特征图,获取每个特征图的平均秩并对这些秩进行降序排列。
然后,确定各卷积层过滤器的压缩率:经验设置(vgg 是 layer-by-layer,resnet 是 block-by-block)
最后,根据计算得到的秩,从 filter 中筛选出秩高的保留,从而得到剪枝后的模型,微调。
5.3.3 压缩率对网络结构影响的解读
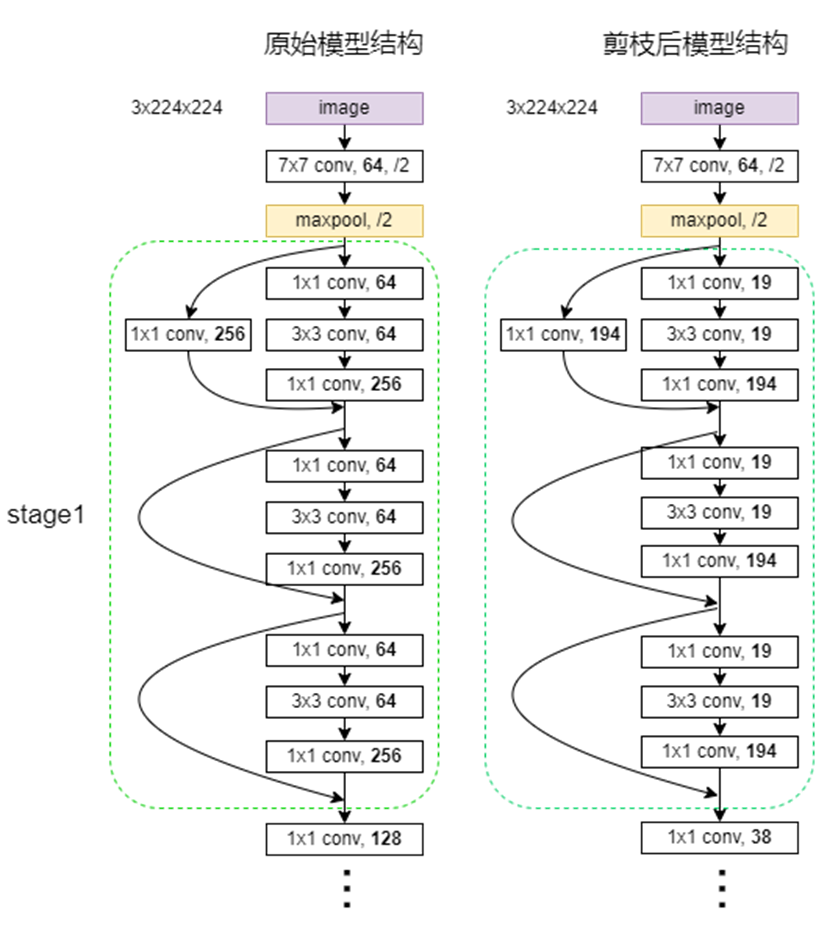
stage_repeat = [3, 4, 6, 3]
stage_out_channel = [64] + [256] * 3 + [512] * 4 + [1024] * 6 + [2048] * 3
compress_rate = [0.0]+[0.24]*3+[0.7]*7+[0.45]*90.0:第一个卷积层 filter 个数压缩率
0.24*3:前三个 stage 的输出 filter 个数压缩率,最后一个 stage 输出 filter 个数不压缩
0.7*7+0.45*9:4 个 stage 中3, 4, 6, 3个每个 block 中间层 filter 个数压缩率
stage_repeat = [3, 4, 6, 3]
stage_out_channel = [64] + [256] * 3 + [512] * 4 + [1024] * 6 + [2048] * 3
compress_rate = [0.0]+[0.24]*3+[0.7]*7+[0.45]*9
def adapt_channel(compress_rate):
...
return overall_channel, mid_channel
overall_channel, mid_channel = adapt_channel(compress_rate)
print(overall_channel)
print(len(overall_channel))
print(mid_channel)
print(len(mid_channel))64, 194, 194, 194, 389, 389, 389, 389, 778, 778, 778, 778, 778, 778, 2048, 2048, 2048
17=1+3+4+6+3=第一个卷积输出+各个残差块输出
19, 19, 19, 38, 38, 38, 38, 140, 140, 140, 140, 140, 140, 281, 281, 281
16= 3+4+6+3=各个残差块中间层输出
剪枝前后模型结构示意图如下:
5.4 ABCPruner
IJCAI 2020
5.4.1 理论知识
目前大多数方法是根据经验规则实现通道剪枝:一类是根据规则决定哪些 filter(权重)"重要"。另一类是根据经验决定各层剪枝率。
ABCPruner 是一种基于人工蜂群(artifical bee colony)算法的通道剪枝方法。目的是有效地找到最佳的剪枝结构,即每一层中的通道数,而不是选择"重要"的 channel(启发于 19 年 ICLR 上的 Rethinking),对最佳剪枝结构的搜索,公式化为一个优化问题,参考 ABC 算法以搜索策略解决这个问题(启发于 18 年 CVPR 上的 Amc),减少人为干扰。
5.4.2 剪枝过程
对于一个有 L 层卷积的网络,裁剪的可能性方案有 ∏ j = 1 L c j \prod _{j=1} ^{L} c_j j=1∏Lcj,这种可能性方案太多,需要进行限制。
将每层的裁剪方案限制成十个,具体做法:假设该层的 filter 数目为 c,取 10%c,20%c,...,100%c 十个数作为该层裁剪的选择空间。总结:将通道组合压缩到一个特定空间。
具体实现过程:
- 初始化一个 structure set,set 中的每个元素表示每层要保留的通道数目(实际上是初始化多个 structure set,每个 set 代表一种剪枝方案)
- 根据这个集合对每层进行随机裁剪
- 训练少量 epochs,测试精度 fitness(减少计算资源消耗)
- 然后使用 ABC 来更新 structure set
- 重复 2,3,4
- 挑选出最优结构,进行微调
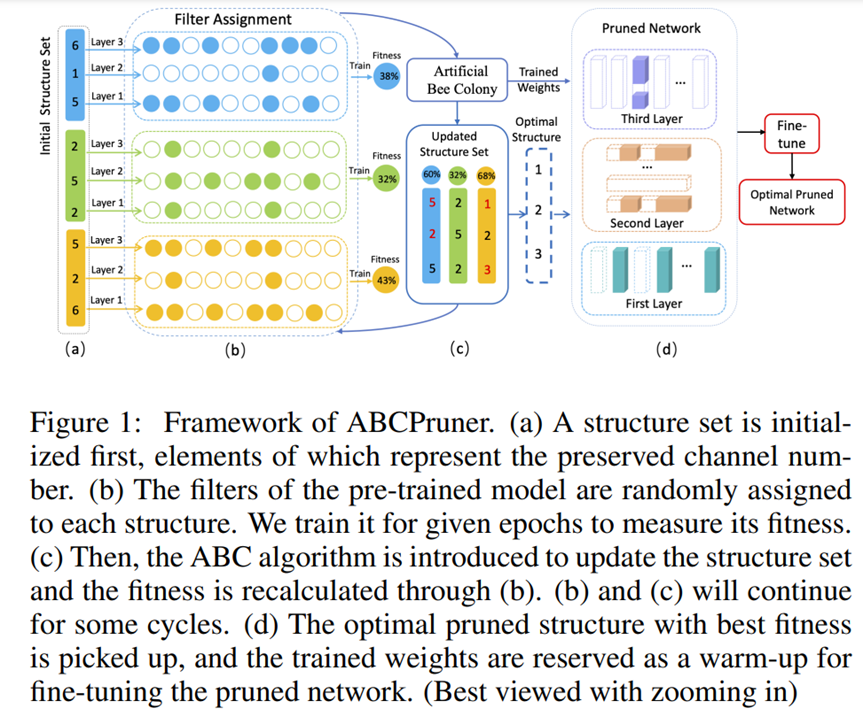
T:表示走多少圈 ABC 算法
α:保留率上限
n:被剪枝网络集合中的网络个数
ti:计数器
M:某个网络结构 M 次没变,重新初始化它
C′:被剪枝网络结构
fitC:网络结构 C 的 fitness

从 2022 年发的一些文章上看,大家倾向于往稀疏化置零上进行探索了。相比于上面介绍的结构化剪枝,稀疏化置零不需要考虑维度匹配的限制,通常精度更高,但需要硬件支持稀疏化。
5.5 1xN Pruning
TPAMI 2022
5.5.1 理论知识
kernel 级别剪枝:剪枝 filter 中的某个 kernel
filter 级别剪枝:剪枝 filter 中的所有 kernel(该方案也会剪枝掉下一层 filter 中的对应 kernel)
1XN Pruning:剪枝具有相同输入 channel index 的连续 N 个输出 kernel(如:连续 4 个 filter 中的第 1 个 kernel)
5.5.2 剪枝过程
1XN 剪枝方法依据 L1 范数,剪枝粒度介于 Kernel Pruning 和 Filter Pruning 之间,下图中 N 取 4 进行解释。
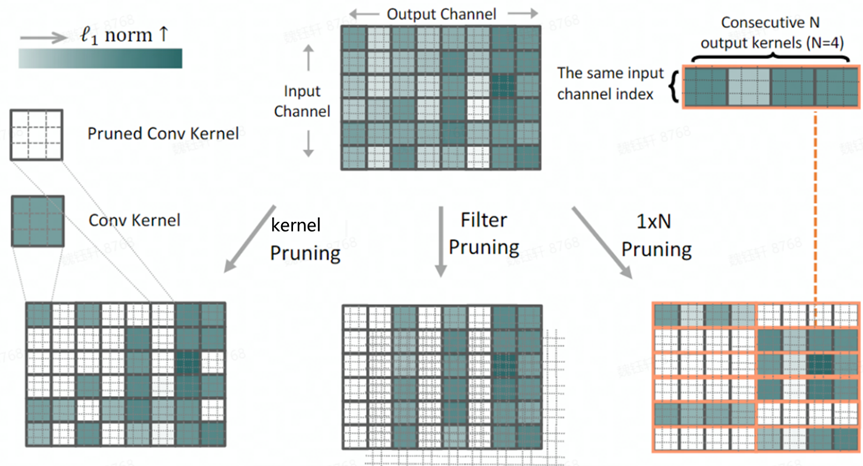
关于如何实现该方案,会涉及到过滤器重排,稀疏矩阵编解码等复杂操作,这里不再进行详述。
注意:
- 该剪枝方案是一种稀疏化的操作,是将某些 kernel 全部置零,理论上属于结构化剪枝(稀疏),考虑到维度匹配问题,在网络搭建时,无法控制到内部 kernel 级别,故无法获取剪枝后的网络,需要支持稀疏化的硬件才能加速。
5.6 CHEX
CVPR 2022
5.6.1 剪枝过程
在整个训练过程中,通过定期 prune channels 和 regrow channels,降低过早修剪"重要"通道的风险。
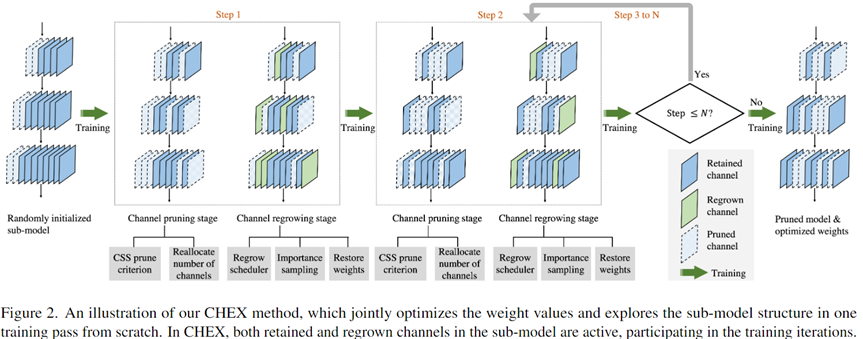
- 原始模型:Conv-6-8-10,随机初始化子模型结构
- Channel pruning stage:根据目标稀疏度,剪枝不重要的 channel,每一层的通道数会在这一步使用"sub-model structure exploration technique"进行重新生成,例如,图中 step1 中的 conv-3-4-5,step2 中的 Conv-2-3-7。
- Channel regrowing stage:每一次 pruning 后,会 regrow 之前剪枝掉的一部分 channel,这些恢复的 channel weight,会使用被剪枝前最近一次的 weight。
- 每进行一次 2。3 两步(成对出现),会训练一些 epoch,这个过程重复 N 次,得到剪枝后的网络。

5.6.2 轻量型网络剪枝结果
论文中提供的在轻量型网络上的剪枝效果。
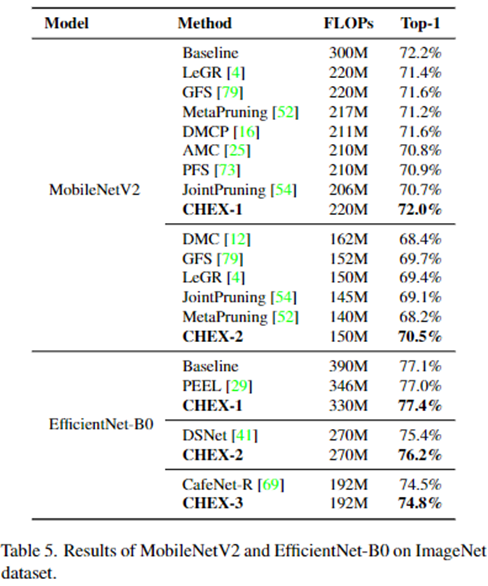
注意:
- 该剪枝方案是一种稀疏化的操作,虽然是将某 filter 权重全部置零,理论上属于结构化剪枝,但由于剪枝通道位置是不定的,每一层剪枝率也不定,特别是对于具有 shortcut 的网络,无法获取剪枝后的网络,因此只能是结构化稀疏置零,故需要支持稀疏化的硬件才能加速。
06 模型转换与测试性能
6.1 模型转换
大家可以参考这篇文章进行模型转换(毕竟要做精度评测,校准数据要准备好):
https://developer.horizon.cc/forumDetail/118363912788935513
6.2 性能评测
- latency 单核单线程
./hrt_model_exec perf --model_file chex_ssd_resnet50_baseline_rgb.bin --core_id 1 --frame_count 2000 --thread_num 1
- FPS 双核多线程
*./hrt_model_exec perf --model_file chex_ssd_resnet50_baseline_rgb.bin --core_id 0 --frame_count 2000 --thread_num 8*
07 总结和思考
- 结构化压缩方案(包括结构化剪枝和稀疏化置零)在地平线 征程 5 上均可以实现加速。
- 未来地平线会支持稀疏化训练吗?会有标准的参考文档进行介绍吗?期待中~
08 参考链接
https://zhuanlan.zhihu.com/p/149659607
https://zhangkaifang.blog.csdn.net/article/details/108753791
https://www.sohu.com/a/395528127_129720
https://blog.csdn.net/u011231598/article/details/116455709
https://github.com/lmbxmu/HRankPlus
https://blog.csdn.net/m0_37192554/article/details/106402269
-model_file chex_ssd_resnet50_baseline_rgb.bin --core_id 0 --frame_count 2000 --thread_num 8****
07 总结和思考
- 结构化压缩方案(包括结构化剪枝和稀疏化置零)在地平线 征程 5 上均可以实现加速。
- 未来地平线会支持稀疏化训练吗?会有标准的参考文档进行介绍吗?期待中~
08 参考链接
https://zhuanlan.zhihu.com/p/149659607
https://zhangkaifang.blog.csdn.net/article/details/108753791
https://www.sohu.com/a/395528127_129720
https://blog.csdn.net/u011231598/article/details/116455709
https://github.com/lmbxmu/HRankPlus
https://blog.csdn.net/m0_37192554/article/details/106402269
https://blog.csdn.net/lihuanyu520/article/details/107097820