SCALING IN-THE-WILD TRAINING FOR DIFFUSIONBASED ILLUMINATION HARMONIZATION AND EDITING BY IMPOSING CONSISTENT LIGHT TRANSPORT
通过实施一致的光传输,扩展基于漫射的照明协调和编辑的野外训练
Abstract:基于扩散的图像生成器正在成为照明协调和编辑的独特方法。目前扩大基于扩散的照明编辑模型训练的瓶颈主要在于难以保留底层图像细节并保持内在属性(如反照率)不变。如果没有适当的约束,直接使用复杂、多样或野生数据训练最新的大型图像模型可能会产生结构引导的随机图像生成器,而不是实现精确照明操作的预期目标。我们提出了**在训练期间施加一致光 (ICLight) 传输,其根源在于物理原理,即物体在不同照明条件下的外观与其在混合照明下的外观一致。这种一致性允许稳定且可扩展的照明学习、对各种数据源的统一处理,并有助于实现物理接地的模型行为,即仅修改图像的照明,同时保持其他固有属性不变。**基于这种方法,我们可以将基于扩散的照明编辑模型的训练扩展到大数据量(1000 万>),涵盖所有可用的数据类型(真实光舞台、渲染样本、野外合成增强等),并使用强大的主干(SDXL、Flux 等)。我们还证明,这种方法减少了不确定性并减轻了材料不匹配或反照率改变等伪影。
研究贡献:
(1) 我们提出了 IC-Light,这是一种通过施加一致的光传输来扩大基于漫射的照明编辑模型训练的方法,确保在保留固有图像细节的同时确保精确的照明修改;
(2) 我们提供预训练的照明编辑模型,以促进照明编辑应用程序在跨不同领域的内容创建和操作;
(3) 我们提出了广泛的实验来验证这种方法的可扩展性和性能,表明它在处理各种照明条件方面与其他方法的不同;
(4) 我们介绍了其他应用程序,例如法线贴图生成和艺术照明操作,进一步展示了我们的方法在现实世界、野外场景中的多功能性和稳健性。
效果展示:

数据收集
如图 2 所示,我们使用多种可用类型的数据源对照明效果的分布进行建模:任意图像、3D 数据和灯光舞台图像。这些分布允许捕获各种复杂的真实照明场景,例如背光、边缘光、发光等。为简单起见,我们将所有数据处理为通用格式。每个外观图像 IL ∈ Rh×w×3 都与一个 32px 环境贴图 L ∈ R32×3232×、一个前景蒙版 M ∈ Rh×w、一个可选的背景图像 B ∈ Rh×w×3 和一个可选的降级图像 ID ∈ Rh×w×3 配对。

野外图像增强
我们使用数据增强将任意图像转换为具有相同本征(例如反照率)但照明外观不同的图像的成对照明训练数据。每个样本都包括输入条件的一个外观、输出目标的另一个外观以及其他元数据,如环境映射。输出目标的图像是高质量的野外图像,而输入条件的图像包含随机增强和降级,以增强扩散模型的鲁棒性和泛化性。
具体来说,我们首先通过在两种方法之间随机选择来提取任意图像的环境映射:我们要么使用 Phongthawee 等人(2023 年)的方法,要么使用补充材料中详述的自定义 environment-fromnormal 方法。我们使用 Zheng et al. (2024) 检测前景掩码,并使用蒸馏加速 (Luo et al., 2023) 稳定扩散修复模型生成背景图像。我们使用 Xiao et al. (2023) 的方法检测提示,或者如果图像来自文本图像数据集,则使用现有的图像提示来检测提示。然后,我们生成一个"退化外观",它与原始图像具有相同的固有反照率,但照明完全改变了;
具体来说,我们通过在补充材料中随机应用 6 种反照率提取方法来提取图像反照率。然后,我们使用 3 种随机法线估计方法合成柔和阴影图像,并使用随机阴影材料合成硬阴影。最后,我们向随机区域添加随机级别的镜面反射。有关完整详细信息,另请参阅补充材料。着色图像是从多个在线图像库中购买的 20k 高质量阴影材质,以及使用在这 20k 购买样本上训练的 Flux LoRA 生成的 500k 材质。我们通过将 CLIP Vision 与关键词"美丽的照明"、"光线"和"照明"的相似性进行比较,过滤了 50M 图像以最终确定 6M 图像,以删除与照明无关的图像。
3D 渲染数据
我们使用类似于 G-buffer Objaverse 的方法渲染 Objaverse。区别在于,我们使用用 PyTorch 编写的基于图像的渲染管道,以获得更快的速度。我们使用从之前的 "野外图像增强" 中获得的随机环境图,并使用 Xiao et al. (2023) 的方法来检测提示。我们不生成退化图像,而是直接使用随机的未配对环境映射将改变的外观渲染为 Id。我们数据集的这一部分的比例最终确定为 4M 图像。
Light Stage
我们使用来自 Mnichelson (2006)、Liu et al. (2024a) 的多个轻量级数据集,以及一个具有 20k 级灯光舞台外观的内部数据集。我们将所有 One-Light-At-a-Time (OLAT) 数据预渲染为相同的上述格式。我们使用从之前的 "in-the-wildation 图像增强" 中获得的随机环境图,使用 Xiao et al. (2023) 的方法来检测提示,并使用随机的未配对环境图将改变的外观渲染为 Id。
实施一致光传输
我们的目标是学习一个健壮的通用模型来处理野外照明模式。然而,学习大规模、复杂和嘈杂的数据是具有挑战性的。如果没有合适的正则化和约束,模型很容易降级为与预期照明编辑不对应的随机行为。我们的解决方案是在训练期间实施一致光 (IC-Light) 传输,其根源在于物理原理,即对象在不同照明条件下的外观线性混合与其在混合照明条件下的外观一致。
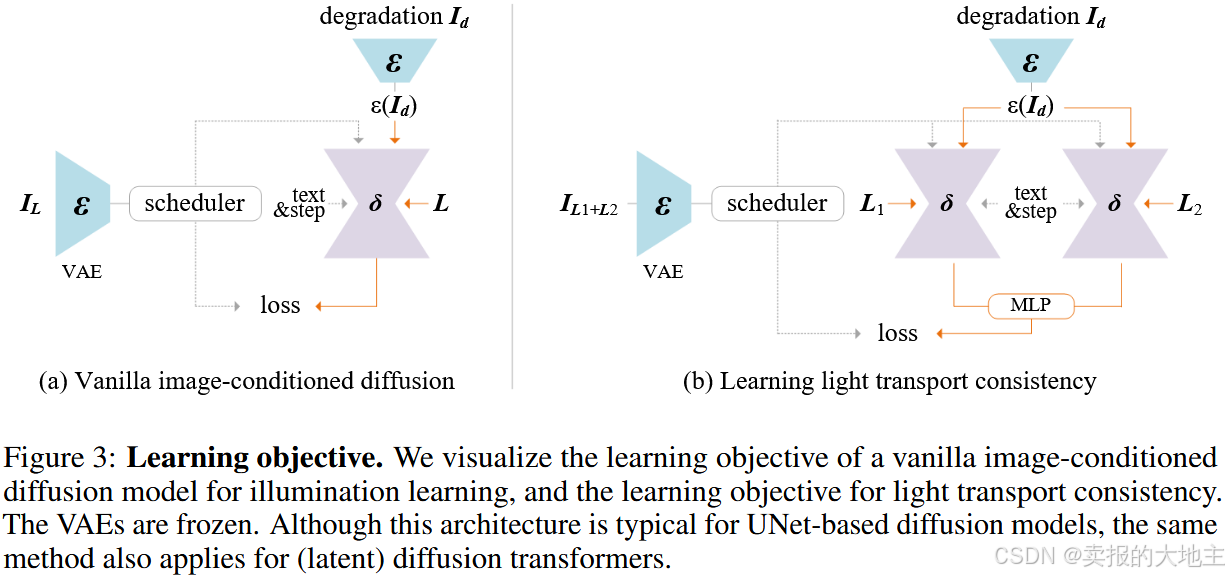
图 3:学习目标。我们可视化了用于照明学习的普通图像条件扩散模型的学习目标,以及光传输一致性的学习目标。VAE 被冻结。虽然这种架构对于基于 UNet 的扩散模型来说是典型的,但同样的方法也适用于(潜在)扩散转换器。
Vanilla 目标 我们从 vanilla 图像条件漫射模型开始,以学习没有特殊约束的照明。如图 3-(a) 所示,以典型的 Stable Diffusion UNet 为例,我们操纵 UNet 架构,在输入卷积层上添加 4 个通道,以接收 Id、目标对象的随机重新点亮外观或降级图像。我们将任何 32 × 32 × 3 HDRI 环境光源图像 L 重塑为 3072 个数字,并使用投影 3072 → 4096 → 4096 →→ 2304 从头开始训练 MLP(由 Leaky RELU 激活),并将 2304 输出数字重塑为 3 × 768 嵌入,可以通过 SD 1.5 直接接收为具有 3 个标记和 768 个通道的提示嵌入输入。给定目标重射图像 IL,潜在扩散算法首先将 IL 编码为潜ε (IL),然后逐渐向潜像中添加噪声以产生噪声潜ε (IL)t,其中 t 表示添加噪声的次数。给定包括时间步长 t、照明条件 L 以及输入降级 ID 在内的一组条件,图像扩散算法学习网络δ以预测噪声

其中 ε 是扩散目标(EPS/V 预测模型的噪声或 V 目标,或流匹配的流目标);Lvanilla 是成本函数。了解此目标后,可以使用扩散模型实现基本的图像重新照明功能。此外,为了训练背景条件模型,我们将 B 连接到 Id (如果数据集的某些部分没有背景,则用所有零填充额外的通道)。然而,由于照明数据具有挑战性且噪声大,因此这个单一的目标通常会导致随机模型行为,例如颜色不匹配、细节不正确等
光传输一致性 在计算摄影中,光传输理论表明,考虑到任意外观 I∗ L 和相关的环境照明 L,矩阵 T 始终存在,因此

其中 T 可以看作是 T ∈ R(h×w×3)×(32×32×3)。"∗"表示原始高动态范围中的图像。实际测量 (Debevec et al., 2000) 验证了 T 始终可以用单个矩阵表示,而没有任何非线性变换。由于这种线性,光传输解释了外观合并

其中 L1、L2 是两个任意环境照明贴图。这直观地表明,物体在不同照明下的外观混合(例如,L1、L2)等同于在合并照明下的外观(例如,I∗ L1+L2)。这种现象也通过实际测量得到了验证,例如,(Haeberli, 1992),我们在补充材料中附上了相关的验证示例。
在本文中,我们观察到 Eq.(3) 由于其线性性,可以被任意扩散目标代替。例如,考虑一个简单的 k 扩散 ε 目标在 σma 空间步长 σt,估计的噪声 εL(以 L 为条件)和噪声图像 Iσt,估计的干净外观可以写成 IˆL = (Iσt − εL)/σt。通过应用 Eq.(3) 由于 IˆL1+L2 = IˆL1 + IˆL2 我们也会得到 εL1+L2 = εL1 + εL2 。因此,Eq.(3) 可以替换为任何扩散目标,例如 eps-prediction、v-prediction、flow match 等,只要目标本身是线性的和一阶的。 轻传输一致性的核心思想是保证 Eq。(3) 在扩散训练过程中,以约束模型仅修改图像照明而不改变其他内在属性(即保持内部光传输 T 不变)。这可以通过最小化 ||I∗ L1+L2 − (I ∗ L1 + I∗ L2 )||22 (其中 || · ||22 是 L2 标准)。使用上述转换,我们可以将其写为 eps 预测模型 ∥εL1+L2 − (εL1 + εL2 )∥22 的损失函数。 对于实际实施,考虑到大多数扩散模型不是在 HDR 图像上训练的像素扩散模型,因此需要对潜在扩散或 LDR 像素扩散进行转换。我们使用一个简单的可学习多层感知器 (MLP) φ(·, ·) 通过替换方程中的和项来学习潜在数据域(LDR、HDR、Latent)之间的隐式适应。3. 以 epsprediction 为例,我们有光传输一致性的最终形式

其中φ(·, ·) 是隐藏状态为 128 的 5 层 MLP,输入/输出与不同模型的潜伏通道相同,⊙是与前景蒙版相乘的像素倍增(调整为与潜伏图像相同的大小)。在训练过程中,我们通过从均匀分布中随机生成 4 × 4 个掩码来合成 L1、L2,并将掩码大小调整为与 L 相同的形状,然后,我们将掩码区域视为 L1,将未掩码区域视为 L2,确保 L = L1 + L2。这个损失函数可以完全扩展为
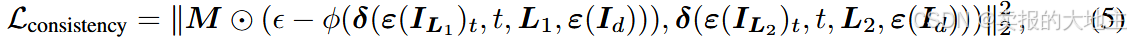
其中每个组件如图 3-(b) 所示。
联合学习目标 最终学习目标可以写成

其中 L 是合并目标,我们使用 λvanilla = 1.0,λconsistency = 0.1 作为默认权重。