生成对抗网络(GANs,Generative Adversarial Networks)是由两个神经网络组成的深度学习模型,分别是生成器(Generator)和判别器(Discriminator),它们在训练过程中互相对抗。生成器负责生成假数据,而判别器则负责判断数据是来自真实数据集还是生成器。随着训练的进行,生成器生成的数据越来越真实,判别器也越来越擅长区分真假数据。通过这种对抗训练,生成器能够生成高度逼真的数据样本。
1. 生成器(Generator)
生成器的目标是通过输入的随机噪声生成逼真的数据。它通常接收一个随机的向量作为输入,然后通过神经网络进行处理,输出伪造的数据样本。生成器的目的是迷惑判别器,使其判断错误,将生成的假数据误判为真实数据。
2. 判别器(Discriminator)
判别器的任务是判断输入的数据是真实的还是生成的假数据。它接收真实数据和生成数据作为输入,并输出一个表示真实性的概率值。判别器的目标是尽可能准确地分辨真假数据。判别器的输出通常是一个介于0和1之间的概率值,值接近1表示真实数据,值接近0表示生成数据。
3. 训练过程:
生成对抗网络的训练是一个动态的过程,其中生成器和判别器通过对抗学习逐步改进。训练过程的目标是通过优化两者的损失函数,使得生成器能够生成越来越真实的数据,而判别器则能够更加精确地区分真实与生成的数据。
- 生成器的目标是最大化判别器对生成数据判断为真实的概率。
- 判别器的目标是最大化对真实数据的判断概率和最小化对生成数据的判断概率。
训练的目标是找到一个平衡点,使得生成器能够生成非常逼真的数据,而判别器无法区分真假数据。

训练开始时,生成器会生成明显虚假的数据,而判别器会快速学会判断这些数据是虚假的

随着训练的进行,生成器越来越接近生成能够欺骗判别器的输出

最后,如果生成器训练顺利,鉴别器就越难区分真实和虚假。它会开始将虚假数据归类为真实数据,准确性也会降低。
图源:https://developers.google.com/machine-learning/gan/gan_structure?hl=zh-cn

- 从随机噪声向量(z)中采样,这个向量通常是从一个简单的分布(如正态分布)中采样得到的,生成器利用这个随机向量生成一个假样本(生成数据)。然后,判别器(Discriminator)将接收这个假样本,并被优化为将其分类为"假"的概率(即接近0)。
- 生成器通过优化其参数,使得判别器将生成的假样本分类为"真实"。在此阶段,生成器的目标是最大化判别器对其生成样本判断为真实的概率(使得判别器误判假样本为真实)。
- 判别器接收两种数据类型:一种是生成器生成的假样本(Fake Sample),另一种是来自真实数据集的真实样本(Real Sample)。
- 判别器的任务是判断输入的样本是"真实的"还是"伪造的",输出一个表示真假概率的值。
- 判别器(D):使用
反向传播最小化错误,即判别器的目标是减少其在分类任务中的错误,尽量避免将生成的假样本判定为真实。 - 生成器(G):通过
反向传播最小化错误,生成器的目标是让判别器尽量判断其生成的假样本为真实数据,从而"欺骗"判别器。
图源: https://developer.nvidia.com/blog/photo-editing-generative-adversarial-networks-1/
4. 损失函数:
GAN的损失函数通常是基于对数损失(log loss)来定义的。生成器的损失是其生成的数据被判别器判定为真实的概率,而判别器的损失则是它正确区分真实和假数据的能力。最常用的损失函数形式是对数损失的最小化。
- 生成器的损失函数:最大化判别器对生成数据判断为真实的概率。
- 判别器的损失函数:最大化对真实数据判断为真实,最小化对假数据判断为真实的概率。
5. 训练的对抗过程:
GAN的训练是一个"零和博弈"的过程。生成器和判别器在训练过程中互相对抗。随着训练的进行,生成器会逐渐学会如何生成更加真实的数据,而判别器则学会如何更加准确地区分真假数据。
这种对抗训练的方式使得GAN在生成逼真数据方面非常强大,尤其是在图像、视频生成、艺术创作等方面有着广泛的应用。
6. 常见的GAN变种:
由于GAN存在训练不稳定、梯度消失等问题,研究人员提出了许多改进版本的GAN,以提高其稳定性和生成效果。常见的变种包括:
- 条件生成对抗网络(Conditional GANs, cGANs):在GAN的基础上加入条件变量,使得生成器能够根据输入的条件(如标签)生成特定类别的样本。
- Wasserstein GAN(WGAN):通过引入Wasserstein距离作为损失函数,解决了传统GAN训练中存在的不稳定性问题。
- CycleGAN:用于无监督图像到图像的转换,例如图像风格转换、图像修复等。
- StyleGAN:用于高质量图像生成,尤其在面部图像生成领域表现突出。
条件生成对抗网络:
训练GAN时通常不需要标签,但如果数据集(如MNIST)中包含标签,可以利用这些标签来训练条件生成对抗网络(Conditional GAN)。条件GAN通过为生成和判别过程提供额外的条件信息来改进模型。在MNIST数据集上,可以基于希望生成的数字类别来对GAN进行条件化。
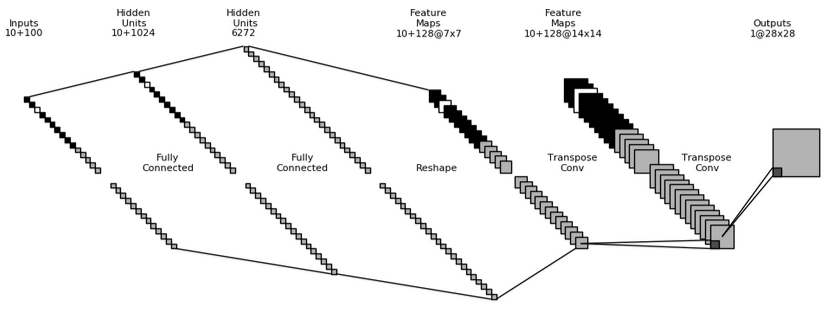
上半部分:生成器(Generator)
输入层:
输入包括两个部分:一个是长度为100的随机噪声向量(表示潜在空间的变量z),另一个是10维的独热编码(表示数字类别的标签,MNIST有10个类别)。
隐藏层:
全连接层 :输入经过全连接层,映射为1024个隐藏单元。这个过程帮助生成器从随机噪声中提取出特征。
全连接层 :接着,输出通过第二个全连接层(6272个单元)进一步处理,生成更高维度的特征。
特征图(Feature Maps):
接下来,生成器将数据转换成特征图(Feature Maps),大小为128x7x7,表示将图像的空间特征展开为多个通道(feature maps)。
重塑(Reshape):
特征图被重塑(Reshape),以便将其传递给卷积层。
转置卷积(Transpose Conv):
经过两个转置卷积(Transpose Convolution)层之后,生成器逐步扩大特征图的尺寸,最后输出为一个28x28的图像。转置卷积层用于上采样,帮助生成器生成具有空间结构的图像。
输出层:
最终的输出是一个28x28的图像,尺寸与MNIST数字的图像大小一致。
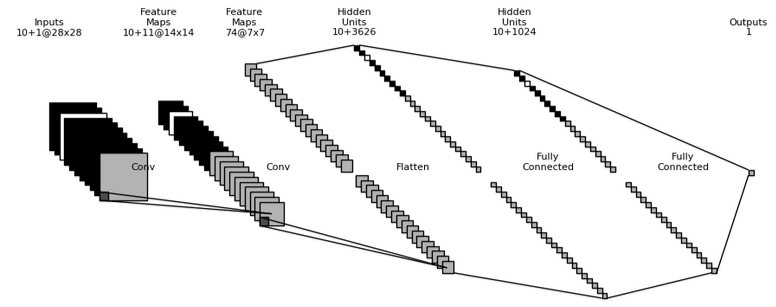
下半部分:判别器(Discriminator)
输入层:
判别器的输入是来自数据集的真实图像或生成器生成的假图像。输入尺寸为28x28,代表MNIST图像。
卷积层(Convolutional Layers):
图像通过两个卷积层(Conv),每个卷积层都有不同的过滤器数量,用于提取图像的空间特征。
Flatten层:
卷积层的输出被展平(Flatten),转换为一维向量,便于后续的全连接层处理。
全连接层:
数据经过两个全连接层,首先转换为1024个隐藏单元,再通过最后一个全连接层输出一个单一的值,表示图像是真实的(值接近1)还是假的(值接近0)。
输出层:
输出是一个二分类的结果,通常使用sigmoid激活函数来输出一个介于0和1之间的概率值,用于判断输入图像的真实性。
在实现中,我将类别的独热编码表示与每层的激活值拼接在一起。对于全连接层,独热编码是一个长度为10的向量(因为MNIST有10个数字类别),其中只有与类别ID对应的索引位置为1,其余位置为0。这一做法同样可以扩展到卷积层:在这种情况下,条件信息通过一组10个特征图来表示,只有与类别ID匹配的特征图位置为1,其余位置为0。在训练过程中,潜在变量z是从一个100维的正态分布中随机采样的,这个选择虽然是任意的,但能够产生良好的效果。
图源: https://developer.nvidia.com/blog/photo-editing-generative-adversarial-networks-1/