使用NVIDIA NIM微服务加速科学文献综述

引言
系统文献综述是研究者探索科学领域的重要起点。对于刚接触该领域的科学家而言,它提供了结构化的领域概览;对于专家来说,它能够完善他们的理解并激发新的想法。仅在2024年,Web of Science数据库就索引了218,650篇综述文章,这凸显了这些资源在研究中的重要性。
完成一篇系统综述能够显著提升研究者的知识基础和学术影响力。然而,传统的综述撰写需要收集、阅读和总结特定主题上大量的学术文章。由于这种手动工作的耗时性质,处理的文献范围通常被限制在几十到几百篇文章之内。跨学科内容------通常超出研究者专业领域------又增加了另一层复杂性。
这些挑战使得创建全面、可靠且有影响力的系统综述变得越来越困难。
大型语言模型(LLMs)的出现提供了一个突破性的解决方案,使从大量文献中快速提取和综合信息成为可能。参加澳大利亚生成式AI编程节(Generative AI Codefest Australia)提供了一个独特的机会,在NVIDIA AI专家的支持下探索这一想法,利用NVIDIA NIM微服务加速文献综述。这使我们能够快速测试和微调多个最先进的LLM,用于我们的文献分析过程。
测试LLM处理科学论文的潜力
作为南极环境未来保障特别研究计划(ARC Special Research Initiative Securing Antarctica's Environmental Future, SAEF)中专注于生理生态学的研究小组,我们着手撰写一篇关于非血管植物(如苔藓或地衣)对风的全球响应的文献综述。
然而,我们很快面临了一个挑战:许多关于风-植物相互作用的相关文章在标题或摘要中并未明确提及这些关键词,而这些通常是文献筛选过程中的主要过滤条件。对该主题的全面分析需要手动阅读每篇文章的全文------这是一个极其耗时的过程。
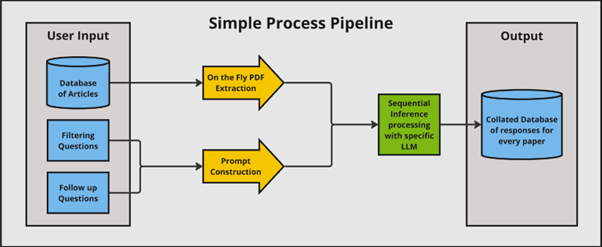
我们决定探索使用LLM从文章中提取特定与风-植物相互作用相关的内容的潜力。为实现这一目标,我们基于LlaMa 3.1 8B Instruct NIM微服务实现了一个简单的问答应用(图1)。这使我们能够快速获得初始原型。
这个首个原型按顺序处理论文,对于优化提取每篇文章关键信息的提示词非常有用。
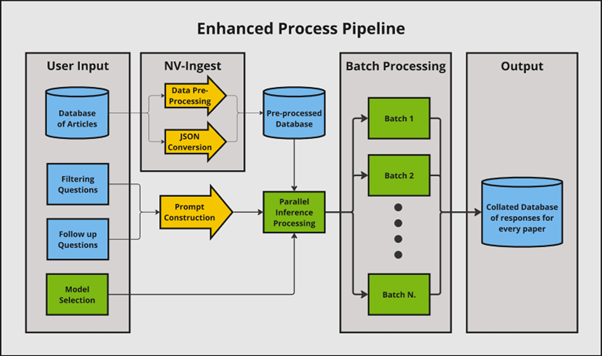
为验证提取信息的准确性,我们最初手动验证了结果。当在测试数据集中没有发现明显错误时,我们确定了使用LLM进一步提高关键信息提取效率的机会(图2)。这些包括将论文从PDF格式转换为结构化JSON;提取图像、表格和图表;以及使用并行处理加速论文处理。
增强LLM性能以提高信息提取效率
通过使用NVIDIA NIM微服务和nv-ingest,我们在本地环境中部署了LLM和数据摄取流程,配备了八个NVIDIA A100 80-GB GPU。我们还使用低秩适应(LoRA)微调模型,以提高从论文中提取信息的准确性。
我们从Web of Science和Scopus数据库收集了超过2K篇与目标研究领域相关的科学文章。在生成式AI编程节的一周时间里,我们专注于实验各种策略,以优化从这些文章中提取关键信息的效率和准确性。
最佳模型选择
为确定性能最佳的模型,我们在一组随机选择的文章上测试了NVIDIA API目录中的一系列指令型和通用LLM。每个模型都根据其在信息提取方面的准确性和全面性进行评估。
最终,我们确定Llama-3.1-8B-instruct最适合我们的需求。
处理速度
我们使用streamlit开发了一个问答模块,用于回答用户定义的特定研究问题。
为进一步提高处理速度,我们实现了发送到LLM引擎的提示的并行处理,并使用KV缓存,这在使用16个线程时显著将计算时间加速了6倍。
提取内容类型
我们使用nv-ingest从原始PDF中提取内容,包括文本、图像、表格和图表,转换为结构化JSON文件。这使得信息提取超越了文本内容,为回答问题提供了更全面的上下文。
在推理过程中使用JSON文件而非原始PDF文件也对降低处理时间产生了显著影响,额外提高了4.25倍的速度。
成果与性能提升
得益于这些改进,我们显著减少了从数据库中提取信息所需的时间,与初始实现相比,总体速度提升了25.25倍。
使用两台A100 80-GB GPU和16个线程,处理整个数据库现在只需不到30分钟。
与传统方法相比,即手动阅读和分析整篇文章(通常需要约一小时),这种优化的工作流程实现了超过99%的时间节省(图3)。
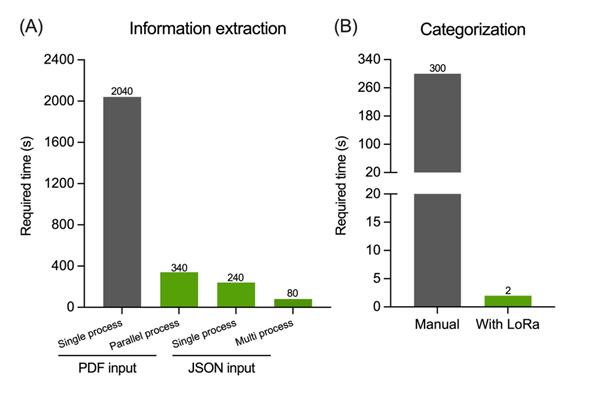
除了信息提取外,我们还研究了自动文章分类。通过在手动注释的论文样本上使用LoRA适配器微调Llama-3.1-8b-Instruct,我们成功实现了分类过程的自动化,展示了其在组织复杂科学论文数据集方面的有效性。
结果表明,每篇文章的分类仅需2秒,而经验丰富的读者进行手动分类平均需要300多秒(图3)。
未来发展方向
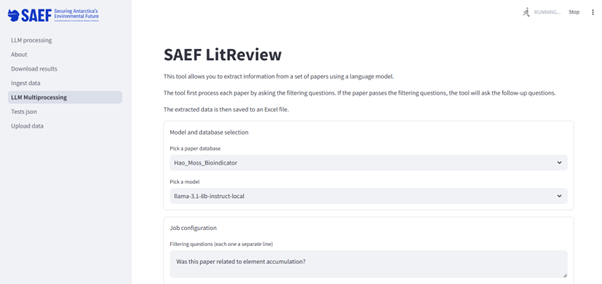
我们目前正在完善工作流程以进一步加速处理。我们还在改进用户界面,以提供更多本地部署的LLM访问,并增强其他研究人员的可访问性(图4)。
我们计划实施NVIDIA AI Blueprint用于多模态PDF数据提取,以识别与每个研究问题最相关的文章,并与这些论文进行交互。
除了技术改进外,我们的目标是为每个问题组织提取的关键信息,并生成可视化内容(如显示论文中提到的实验位置的地图),以进一步加速系统综述的撰写。
总结
我们在生成式AI编程节的工作展示了AI在加速系统文献综述方面的变革潜力。借助NVIDIA NIM,我们快速从想法转变为工作解决方案,显著改进了从科学论文中提取信息的过程。
这一经验突显了AI如何能够简化研究工作流程,实现更快速、更全面的洞察。LLM有潜力促进跨学科研究,使科学家能够更有效地探索复杂的多领域研究领域。
展望未来,我们的目标是完善这些方法和工具,确保它们对未来跨各种主题的研究具有可访问性和可扩展性。