- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
- ResNext是分组卷积的开始之作,这里本文将学习ResNext网络;
- 本文复现了ResNext50神经网络,并用其进行了猴痘病分类实验;
- 没有最好的网络。只有最适合的网络,网络不是越复杂,越优秀越好,必须根据实际数据情况,目标要求决定,很多时候,简单的网络反而效果更好;
- 欢迎收藏 + 关注,本人将会持续更新
文章目录
1、知识简介
1、分组卷积
分组卷积最早出现在AlexNet网络中,在这里将通道数分成两组,采用两个GPU并行提取特征,网络结构如下:
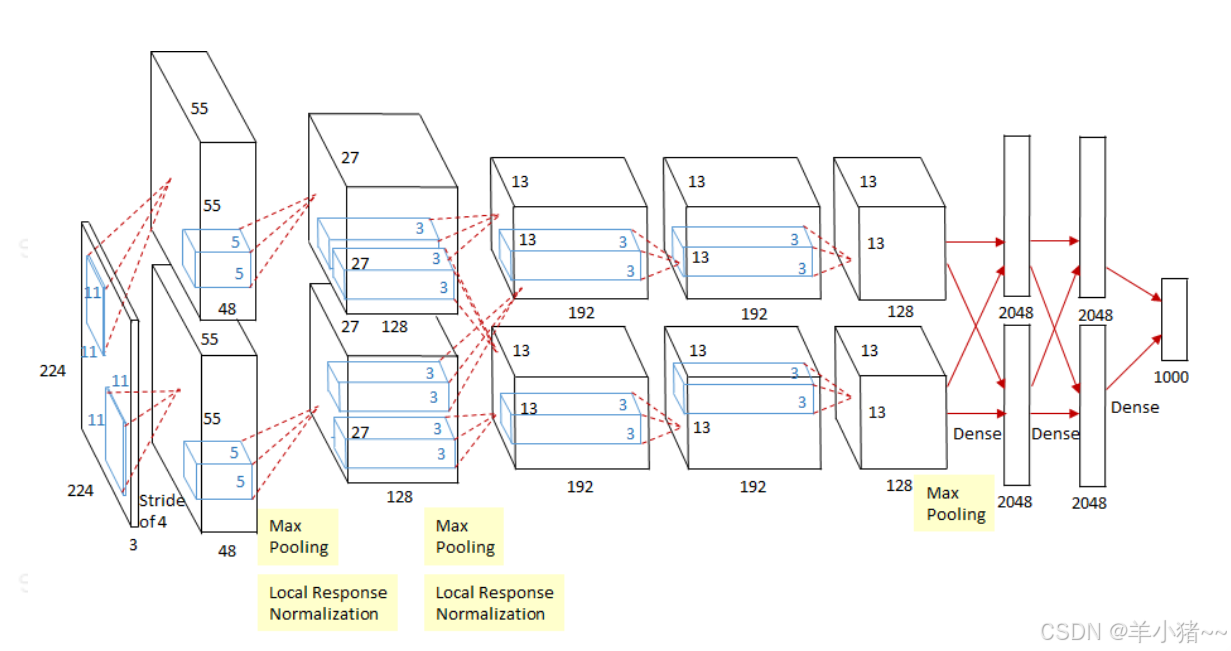
提取到的特征图如下:

作者发现第一组提取的主要是黑白特征,第二组提取的主要是彩色特征,这样分组特征可以更好的提取不同特征数据。
普通卷积 VS 分组卷积
先看常规卷积 ,在常规卷积中,输入feature map尺寸为 n 个,输出feature map与卷积和数量相同也是n个,卷积核大小为:c * k * k,n个卷积核总大小为:n * c * k * k,最后输出的维度是:n * h1 * w1,如下图左边所示:
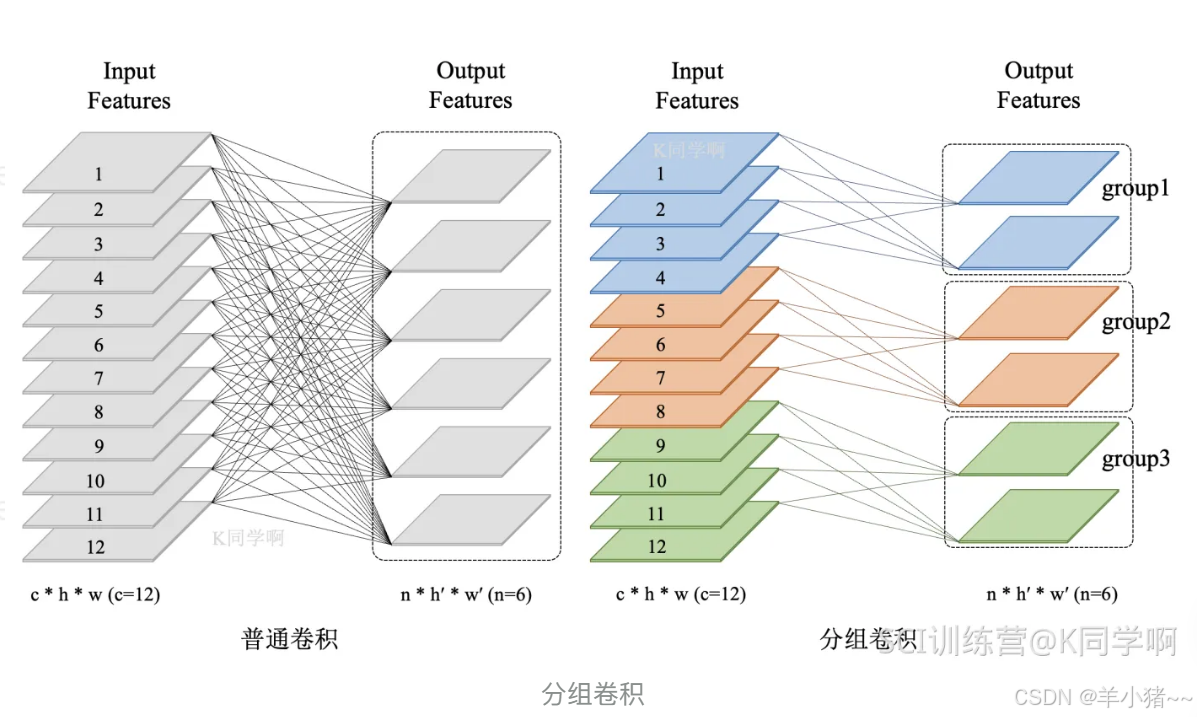
分组卷积 ,就是对输入的feature map进行分组,然后每组分别卷积。假设输入feature map的尺寸为 c * h * w,输出的feature map为 n,假设分为 g 组,则每组的输入的feature map数量为 c / g,每组输出的feature map为 n / g。但是注意 :只是每个卷积核的输入通道数量变成了 c / g,卷积核大小是不变的,每一组 卷积核运算后得到了 (n / g) * h1 * w1,最后将各组矩阵进行拼接就可以得出最后的结果,最后输出的维度依然是n * h1 * w1,与常规卷积一样。
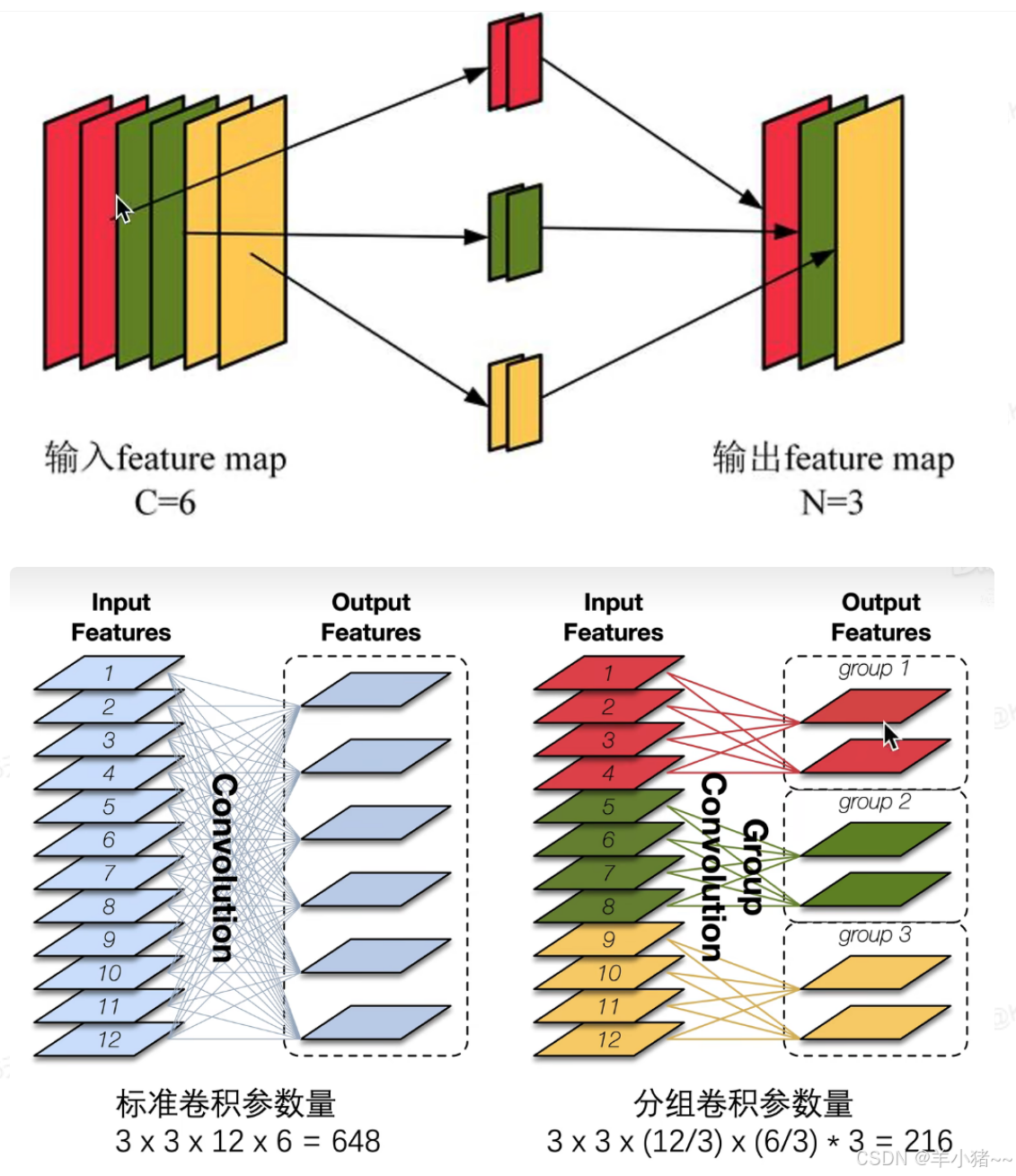
参数了对比:
- 常规卷积:c * k * k * n,c通道数,k * k:卷积核矩阵大小,n卷积核数量;
- 分组卷积:(c / g) * k * k * (n / g) * g = k * k * c * n * (1 / g),从参数了来看,分组卷积更小;
更详细的图如下:
2、split-transform-merge
"Split-Transform-Merge" 是一种常见的设计模式或处理流程,广泛应用于软件开发、数据处理和系统架构中。它的核心思想是将一个复杂的问题分解为更小的部分(Split),对每个部分进行独立的处理或转换(Transform),最后将处理后的结果重新组合(Merge)以完成整体任务。
1. Split(拆分)
在这一阶段,输入数据或任务被分解成更小、更易于管理的部分。拆分的方式取决于具体问题和上下文。例如:
- 数据拆分:将大数据集分割成多个小块。
- 任务拆分:将一个复杂的任务分解为多个子任务。
- 并行化:通过拆分实现并行处理,提高效率。
示例:
- 分组卷积中,输入通道分组拆分,分组进行卷积。
2. Transform(转换/处理)
在拆分后,每个部分被独立处理或转换。这是整个流程的核心阶段,通常涉及计算、分析或修改操作。转换的具体内容取决于任务需求:
- 数据清洗、格式转换。
- 算法计算或模型推理。
- 对子任务的独立执行。
示例:
- 分组卷积中 ,每一组分别进行卷积计算,互补干扰。
3. Merge(合并)
在所有子任务完成后,将处理后的结果重新组合起来,形成最终的输出。合并的方式需要确保结果的完整性和一致性:
- 数据合并:将多个处理后的数据块拼接成完整的数据集。
- 结果整合:将多个子任务的结果汇总为最终答案。
- 冲突解决:如果子任务之间存在冲突或重复,需要在合并阶段解决。
示例:
- 分组卷积中,最后将每一组卷积的结果进行组合。
3、ResNext-50简介
ResNext网络被誉为,分组卷积的开山之作 ,是何凯明团队在2017年CVPR会与提出的,是ResNet网络的升级版。
在论文中,作者提到了一个普遍存在的现象,提高模型准确率,往往采用的是加深或加宽网络的方法,这种方法虽然有一定效果,但是网络设计的难度和计算了也随着增加,因为不代表网络越深就越好,有时候提升了精度,但是代价也大,就如VGG16提出来的时候,计算了庞大。
在论文中,作者提出了在不额外增加计算代价的情况下,提升网络精度 ,提出了cardinality概念(cardinality指的是分组卷积中的"组数").
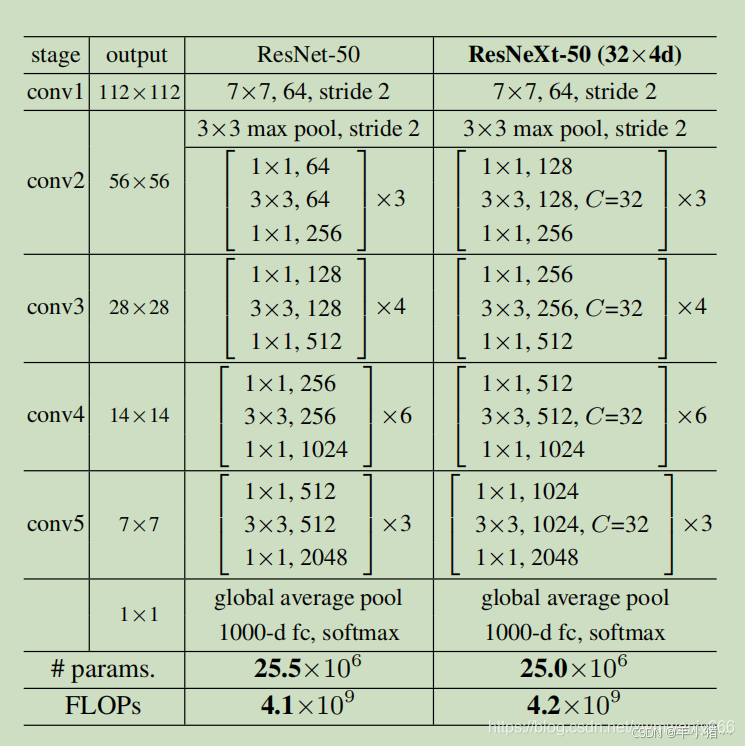
下图中,左边是(Resnet)右边数(Resnext)的模块差异,在ResNet 中,输入具有256个通道特征经过1 * 1卷积压缩到4倍到64个通道特征,然后通过3 * 3卷积核进行特征提取,最后经过 3 * 3卷积核进行还原通道数量输出,并于原来特征进行残差连接。在ResNext 中,将256个输入通道特征分成32个组,每个组首先进行64倍压缩到4个通道,然后用3 * 3卷积核大小进行特征提取,最后通过1 * 1卷积核进行通道还原,后会将每个分组的结构进行维度拼接并与原始特征进行残差连接。
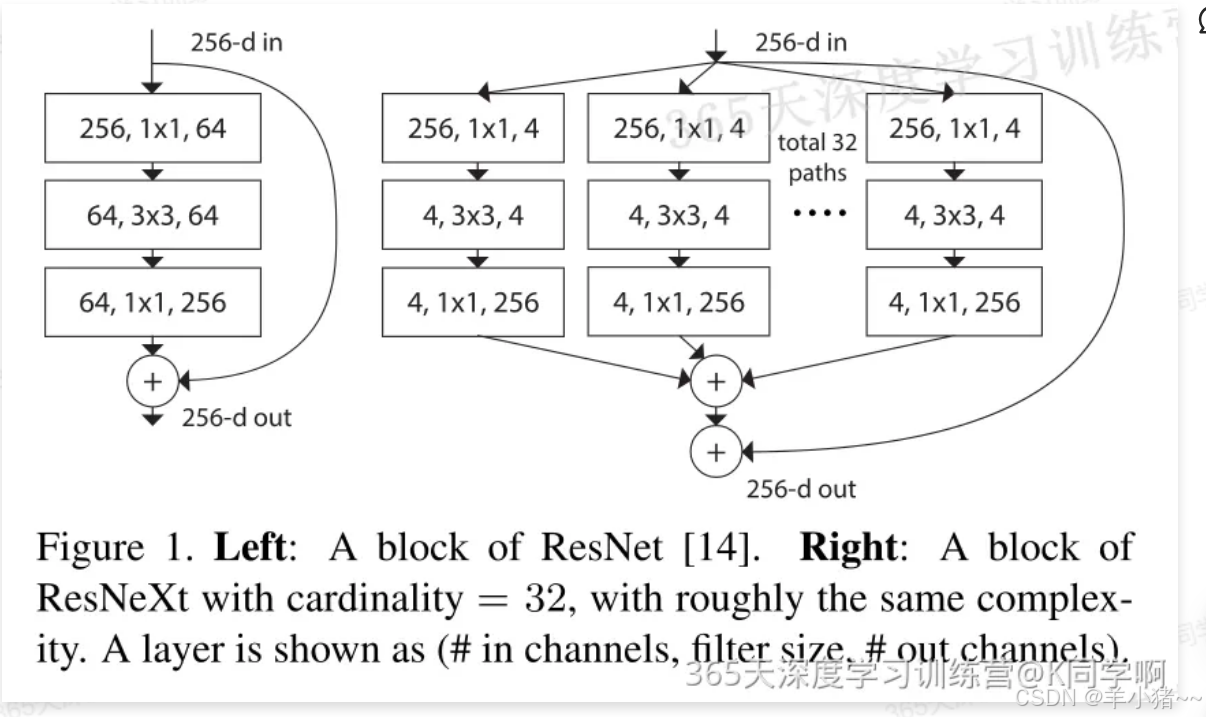
cardinatity指的是一个block中所具有的相同分支的数目,即"组数".
下面进行ResNext-50网络图的搭建(pytorch复现)
2、ResNext-50实验
1、导入数据
1、导入库
python
import torch
import torch.nn as nn
import torchvision
import numpy as np
import os, PIL, pathlib
# 设置设备
device = "cuda" if torch.cuda.is_available() else "cpu"
device 'cuda'2、查看数据信息和导入数据
数据目录有两个文件:一个数据文件,一个权重。
python
data_dir = "./data/"
data_dir = pathlib.Path(data_dir)
# 类别数量
classnames = [str(path).split('/')[0] for path in os.listdir(data_dir)]
classnames['Monkeypox', 'Others']3、展示数据
python
import matplotlib.pylab as plt
from PIL import Image
# 获取文件名称
data_path_name = "./data/Others"
data_path_list = [f for f in os.listdir(data_path_name) if f.endswith(('jpg', 'png'))]
# 创建画板
fig, axes = plt.subplots(2, 8, figsize=(16, 6))
for ax, img_file in zip(axes.flat, data_path_list):
path_name = os.path.join(data_path_name, img_file)
img = Image.open(path_name) # 打开
# 显示
ax.imshow(img)
ax.axis('off')
plt.show()
4、数据导入
python
from torchvision import transforms, datasets
# 数据统一格式
img_height = 224
img_width = 224
data_tranforms = transforms.Compose([
transforms.Resize([img_height, img_width]),
transforms.ToTensor(),
transforms.Normalize( # 归一化
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 加载所有数据
total_data = datasets.ImageFolder(root=data_dir, transform=data_tranforms)5、数据划分
python
# 大小 8 : 2
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_size
train_data, test_data = torch.utils.data.random_split(total_data, [train_size, test_size])6、动态加载数据
python
batch_size = 32
train_dl = torch.utils.data.DataLoader(
train_data,
batch_size=batch_size,
shuffle=True
)
test_dl = torch.utils.data.DataLoader(
test_data,
batch_size=batch_size,
shuffle=False
)
python
# 查看数据维度
for data, labels in train_dl:
print("data shape[N, C, H, W]: ", data.shape)
print("labels: ", labels)
breakdata shape[N, C, H, W]: torch.Size([32, 3, 224, 224])
labels: tensor([1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 0, 0, 1, 0, 0])2、构建ResNext-50网络
ResNet-50网络结构图 :
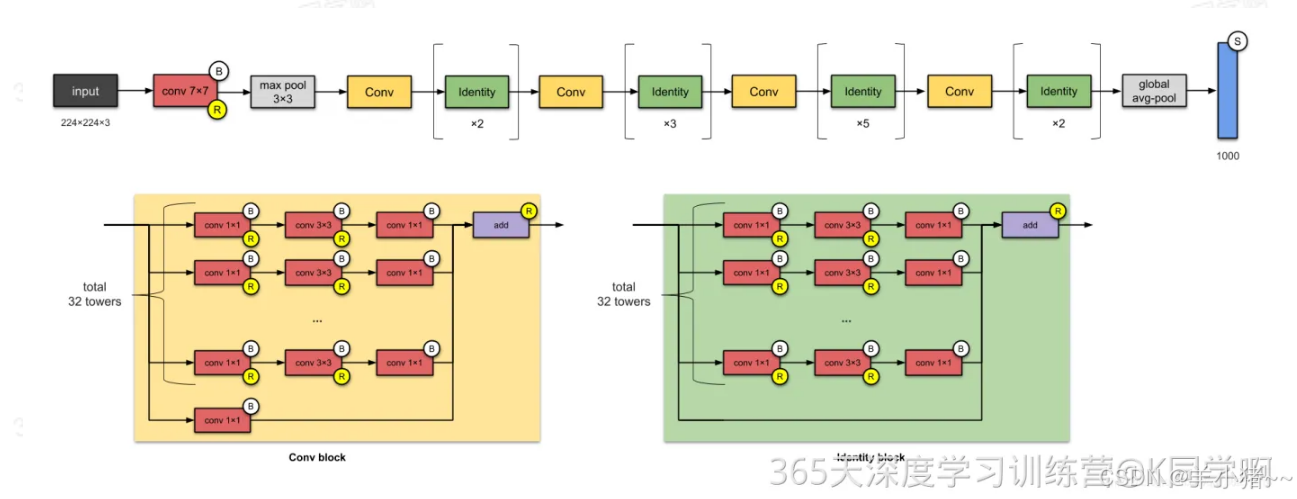
在复现ResNext50网络中,我查阅了不少资料,但是我好像都没怎么看懂那个代码,后面我发现这个就是在ResNet50上加了分组卷积,其他网络结构就是在每一层,第二层的数量是resnet的2倍,后面基于以前搭建的ResNet网络结果进行修改,代码如下所示。
在ResNext50中,有几个参数需要注意:
- 分组卷积:cardinality参数代表分组卷积数量,在Conv2d中groups参数就是分组卷积数量。
- 通道数计算:每组的输出通道数由 group_depth 决定,总输出通道数为 cardinality × group_depth。这里,下面本人搭建的ResNext50网络结构,每一层输入通道数,输出通道数,都是自己手动输入的,故这里group_depth隐藏在filters中(手动计算).
回忆 :
Bottleneck 的基本概念
Bottleneck 结构通常由三个卷积层组成,他是ResNet以及其变体的基本网络层单元。
- 第一个 1×1 卷积:降低输入特征图的通道数,减少后续计算量。
- 中间的 3×3 卷积:核心特征提取过程。在 ResNeXt 中,这一层使用分组卷积来增强表达能力。
- 最后一个 1×1 卷积:恢复通道数到原始或者更高的数量,以便与输入特征图进行残差连接。
注意:
- 在ResNext网络结构中,分组卷积只在Bottleneck只在第二层使用
python
import torch.nn.functional as F
# Bottleneck: 分为残差模块一、残差模块二
# 定义残差模块一,这个用于处理输入和输出通道一样的情况
'''
卷积核大小:1 3 1
核心特点:
尺寸不变:输入和输出的尺寸保持一致。
没有下采样:没有使用步长大于1的卷积操作,因此没有改变特征图的空间尺寸
'''
class Identity_block(nn.Module):
def __init__(self, in_channels, kernel_size, filters, cardinality):
super(Identity_block, self).__init__()
# 输出通道
filter1, filter2, filter3 = filters
# 卷积层一, 降维
self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=1)
self.bn1 = nn.BatchNorm2d(filter1)
# 卷积层2, 分组卷积, 核心:特征提取
self.conv2 = nn.Conv2d(filter1, filter2,
kernel_size=kernel_size,
padding=1,
groups=cardinality
) # 通过卷积输入输出公式发现,padding=1,可以保证输入和输出尺寸相同
self.bn2 = nn.BatchNorm2d(filter2)
# 卷积层3, 升维
self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1)
self.bn3 = nn.BatchNorm2d(filter3)
def forward(self, x):
# 记录原始值
xx = x
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
# 残差连接,输入、输出维度不变
x += xx
x = F.relu(x)
return x
# 定义卷积模块二:用于处理输入和输出不一样的情况
'''
* 卷积核还是:1 3 1
* stride=2
* 这里的分支是采用一个Conv2D,和一个归一化BN层,也是为了处理数据维度吧, 这种维度的变化,可以用ai举例子
核心特点:
尺寸变化,stride=2降维
'''
class ConvBlock(nn.Module):
def __init__(self, in_channels, kernel_size, filters, cardinality, stride=2):
super(ConvBlock, self).__init__()
filter1, filter2, filter3= filters
# 卷积层1, 降维
self.conv1 = nn.Conv2d(in_channels, filter1, kernel_size=1, stride=stride)
self.bn1 = nn.BatchNorm2d(filter1)
# 卷积2, 分组卷积,核心:特征提取
self.conv2 = nn.Conv2d(filter1, filter2,
kernel_size=kernel_size,
padding=1,
groups=cardinality) # 需要维持维度不变
self.bn2 = nn.BatchNorm2d(filter2)
# 卷积3, 降维
self.conv3 = nn.Conv2d(filter2, filter3, kernel_size=1, stride=1) # stride = 1,维持通道不变
self.bn3 = nn.BatchNorm2d(filter3)
# 用于匹配维度的shortcut卷积,这个就是上面Identity_block的x分支
self.shortcut = nn.Conv2d(in_channels, filter3, kernel_size=1, stride=stride)
self.shortcut_bn = nn.BatchNorm2d(filter3)
def forward(self, x):
xx = x
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.bn3(self.conv3(x))
temp = self.shortcut_bn(self.shortcut(xx))
x += temp
x = F.relu(x)
return x
# 定义ResNext50
class ResNext50(nn.Module):
def __init__(self, classes): # 类别数量
super().__init__()
# 头顶, resnet以及变体一般都是这个
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 第一部分
self.part1_1 = ConvBlock(64, 3, [128, 128, 256], cardinality=32, stride=1)
self.part1_2 = Identity_block(256, 3, [128, 128, 256], cardinality=32)
self.part1_3 = Identity_block(256, 3, [128, 128, 256], cardinality=32)
# 第二部分
self.part2_1 = ConvBlock(256, 3, [256, 256, 512], cardinality=32)
self.part2_2 = Identity_block(512, 3, [256, 256, 512], cardinality=32)
self.part2_3 = Identity_block(512, 3, [256, 256, 512], cardinality=32)
self.part2_4 = Identity_block(512, 3, [256, 256, 512], cardinality=32)
# 第三部分
self.part3_1 = ConvBlock(512, 3, [512, 512, 1024], cardinality=32)
self.part3_2 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)
self.part3_3 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)
self.part3_4 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)
self.part3_5 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)
self.part3_6 = Identity_block(1024, 3, [512, 512, 1024], cardinality=32)
# 第四部分
self.part4_1 = ConvBlock(1024, 3, [1024, 1024, 2048], cardinality=32)
self.part4_2 = Identity_block(2048, 3, [1024, 1024, 2048], cardinality=32)
self.part4_3 = Identity_block(2048, 3, [1024, 1024, 2048], cardinality=32)
# 平均池化
self.avg_pool = nn.AvgPool2d(kernel_size=7)
# 全连接
self.fn1 = nn.Linear(2048, classes)
def forward(self, x):
# 头部
x = F.relu(self.bn1(self.conv1(x)))
x = self.max_pool(x)
x = self.part1_1(x)
x = self.part1_2(x)
x = self.part1_3(x)
x = self.part2_1(x)
x = self.part2_2(x)
x = self.part2_3(x)
x = self.part2_4(x)
x = self.part3_1(x)
x = self.part3_2(x)
x = self.part3_3(x)
x = self.part3_4(x)
x = self.part3_5(x)
x = self.part3_6(x)
x = self.part4_1(x)
x = self.part4_2(x)
x = self.part4_3(x)
x = self.avg_pool(x)
x = x.view(x.size(0), -1) # 扁平化
x = self.fn1(x)
return x
model = ResNext50(classes=len(classnames)).to(device)
modelResNext50(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(part1_1): ConvBlock(
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(shortcut_bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part1_2): Identity_block(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part1_3): Identity_block(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part2_1): ConvBlock(
(conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(shortcut_bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part2_2): Identity_block(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part2_3): Identity_block(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part2_4): Identity_block(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_1): ConvBlock(
(conv1): Conv2d(512, 512, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2))
(shortcut_bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_2): Identity_block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_3): Identity_block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_4): Identity_block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_5): Identity_block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part3_6): Identity_block(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part4_1): ConvBlock(
(conv1): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(2, 2))
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(shortcut): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2))
(shortcut_bn): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part4_2): Identity_block(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(part4_3): Identity_block(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1))
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(avg_pool): AvgPool2d(kernel_size=7, stride=7, padding=0)
(fn1): Linear(in_features=2048, out_features=2, bias=True)
)3、模型训练
1、构建训练集
python
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
batch_size = len(dataloader)
train_acc, train_loss = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
# 训练
pred = model(X)
loss = loss_fn(pred, y)
# 梯度下降法
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_acc /= size
train_loss /= batch_size
return train_acc, train_loss2、构建测试集
python
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
batch_size = len(dataloader)
test_acc, test_loss = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
test_loss += loss.item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_acc /= size
test_loss /= batch_size
return test_acc, test_loss3、设置超参数
python
loss_fn = nn.CrossEntropyLoss() # 损失函数
learn_lr = 1e-4 # 超参数
optimizer = torch.optim.Adam(model.parameters(), lr=learn_lr) # 优化器4、模型训练
python
import copy
train_acc = []
train_loss = []
test_acc = []
test_loss = []
epoches = 50
best_acc = 0
for i in range(epoches):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
# 保存最佳模型到 best_model
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model) # 拷贝最好模型
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
# 输出
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}')
print(template.format(i + 1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print("Done")
PATH = './best_model.pth' # 保存的参数文件名
torch.save(best_model.state_dict(), PATH)Epoch: 1, Train_acc:62.3%, Train_loss:0.696, Test_acc:66.4%, Test_loss:0.604
Epoch: 2, Train_acc:67.9%, Train_loss:0.620, Test_acc:69.9%, Test_loss:0.580
Epoch: 3, Train_acc:69.5%, Train_loss:0.580, Test_acc:68.3%, Test_loss:0.603
Epoch: 4, Train_acc:71.6%, Train_loss:0.547, Test_acc:73.9%, Test_loss:0.530
Epoch: 5, Train_acc:74.7%, Train_loss:0.519, Test_acc:75.1%, Test_loss:0.520
Epoch: 6, Train_acc:78.2%, Train_loss:0.464, Test_acc:67.8%, Test_loss:0.683
Epoch: 7, Train_acc:78.1%, Train_loss:0.459, Test_acc:69.0%, Test_loss:0.652
Epoch: 8, Train_acc:80.8%, Train_loss:0.411, Test_acc:72.7%, Test_loss:0.643
Epoch: 9, Train_acc:84.8%, Train_loss:0.362, Test_acc:74.8%, Test_loss:0.575
Epoch:10, Train_acc:87.4%, Train_loss:0.314, Test_acc:77.9%, Test_loss:0.536
Epoch:11, Train_acc:89.3%, Train_loss:0.266, Test_acc:79.0%, Test_loss:0.505
Epoch:12, Train_acc:89.4%, Train_loss:0.260, Test_acc:78.3%, Test_loss:0.601
Epoch:13, Train_acc:90.7%, Train_loss:0.226, Test_acc:81.4%, Test_loss:0.493
Epoch:14, Train_acc:93.9%, Train_loss:0.159, Test_acc:80.4%, Test_loss:0.616
Epoch:15, Train_acc:93.8%, Train_loss:0.152, Test_acc:80.4%, Test_loss:0.620
Epoch:16, Train_acc:92.2%, Train_loss:0.190, Test_acc:82.3%, Test_loss:0.621
Epoch:17, Train_acc:94.0%, Train_loss:0.142, Test_acc:82.3%, Test_loss:0.582
Epoch:18, Train_acc:95.8%, Train_loss:0.106, Test_acc:79.3%, Test_loss:0.625
Epoch:19, Train_acc:95.5%, Train_loss:0.127, Test_acc:81.1%, Test_loss:0.625
Epoch:20, Train_acc:95.4%, Train_loss:0.113, Test_acc:83.0%, Test_loss:0.482
Epoch:21, Train_acc:96.7%, Train_loss:0.087, Test_acc:83.0%, Test_loss:0.667
Epoch:22, Train_acc:97.3%, Train_loss:0.083, Test_acc:80.4%, Test_loss:0.695
Epoch:23, Train_acc:97.1%, Train_loss:0.077, Test_acc:83.7%, Test_loss:0.634
Epoch:24, Train_acc:96.6%, Train_loss:0.086, Test_acc:82.5%, Test_loss:0.732
Epoch:25, Train_acc:96.6%, Train_loss:0.098, Test_acc:83.9%, Test_loss:0.711
Epoch:26, Train_acc:96.0%, Train_loss:0.107, Test_acc:75.3%, Test_loss:0.821
Epoch:27, Train_acc:95.6%, Train_loss:0.105, Test_acc:81.6%, Test_loss:0.596
Epoch:28, Train_acc:96.7%, Train_loss:0.088, Test_acc:84.4%, Test_loss:0.606
Epoch:29, Train_acc:97.5%, Train_loss:0.071, Test_acc:86.5%, Test_loss:0.615
Epoch:30, Train_acc:98.2%, Train_loss:0.051, Test_acc:80.4%, Test_loss:0.772
Epoch:31, Train_acc:98.5%, Train_loss:0.041, Test_acc:83.7%, Test_loss:0.694
Epoch:32, Train_acc:98.5%, Train_loss:0.048, Test_acc:82.8%, Test_loss:0.671
Epoch:33, Train_acc:97.7%, Train_loss:0.064, Test_acc:84.1%, Test_loss:0.745
Epoch:34, Train_acc:98.4%, Train_loss:0.054, Test_acc:83.7%, Test_loss:0.661
Epoch:35, Train_acc:98.2%, Train_loss:0.068, Test_acc:83.0%, Test_loss:0.605
Epoch:36, Train_acc:96.8%, Train_loss:0.086, Test_acc:83.2%, Test_loss:0.551
Epoch:37, Train_acc:97.8%, Train_loss:0.063, Test_acc:82.3%, Test_loss:0.739
Epoch:38, Train_acc:97.6%, Train_loss:0.065, Test_acc:83.0%, Test_loss:0.583
Epoch:39, Train_acc:98.2%, Train_loss:0.045, Test_acc:83.4%, Test_loss:0.697
Epoch:40, Train_acc:98.1%, Train_loss:0.048, Test_acc:82.5%, Test_loss:0.710
Epoch:41, Train_acc:98.2%, Train_loss:0.054, Test_acc:83.2%, Test_loss:0.564
Epoch:42, Train_acc:98.4%, Train_loss:0.051, Test_acc:85.5%, Test_loss:0.514
Epoch:43, Train_acc:99.0%, Train_loss:0.025, Test_acc:83.9%, Test_loss:0.663
Epoch:44, Train_acc:99.1%, Train_loss:0.029, Test_acc:85.5%, Test_loss:0.594
Epoch:45, Train_acc:98.3%, Train_loss:0.036, Test_acc:84.6%, Test_loss:0.719
Epoch:46, Train_acc:98.7%, Train_loss:0.036, Test_acc:84.4%, Test_loss:0.631
Epoch:47, Train_acc:97.7%, Train_loss:0.055, Test_acc:81.4%, Test_loss:0.643
Epoch:48, Train_acc:98.7%, Train_loss:0.040, Test_acc:85.1%, Test_loss:0.607
Epoch:49, Train_acc:98.8%, Train_loss:0.037, Test_acc:80.2%, Test_loss:0.897
Epoch:50, Train_acc:98.6%, Train_loss:0.042, Test_acc:84.4%, Test_loss:0.601
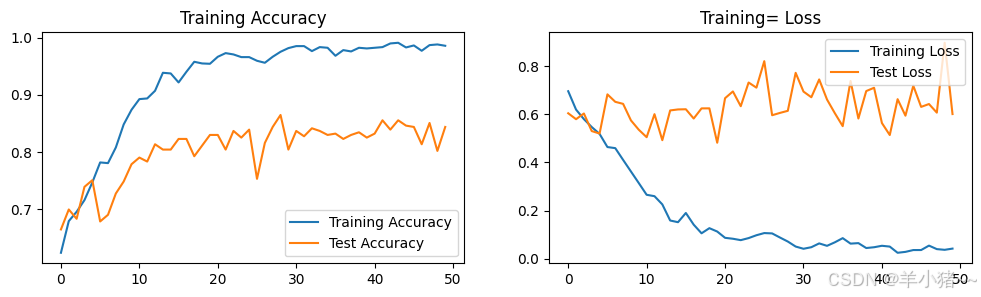
Done5、结果可视化
python
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
epochs_range = range(epoches)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training= Loss')
plt.show()
6、模型评估
python
# 加载最好模型
best_model.load_state_dict(torch.load(PATH, map_location=device))
# 模型测试
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(epoch_test_acc, epoch_test_loss)0.8648018648018648 0.6145411878824234