-
**🍨 本文为🔗365天深度学习训练营(https://mp.weixin.qq.com/s/rnFa-IeY93EpjVu0yzzjkw) 中的学习记录博客**
-
**🍖 原作者:K同学啊(https://mtyjkh.blog.csdn.net/)**
一:前期准备工作
1.设置硬件设备
python
import torch.nn as nn
import torch.nn.functional as F
import torchvision,torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
python
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
plt.rcParams['savefig.dpi'] = 500
plt.rcParams['figure.dpi'] = 500
plt.rcParams['font.sans-serif'] = ['SimHei']
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("/content/drive/MyDrive/alzheimers_disease_data.csv")
df = df.iloc[:,1:-1]
df
二:构建数据集
1.标准化
python
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
sc = StandardScaler()
X = sc.fit_transform(X)2.划分数据集
python
X = torch.tensor(np.array(X),dtype = torch.float32)
y = torch.tensor(np.array(y),dtype = torch.int64)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
X_train.shape,y_train.shape
3.构建数据加载器
python
from torch.utils.data import TensorDataset,DataLoader
train_dl = DataLoader(TensorDataset(X_train,y_train),batch_size=64,shuffle=True)
test_dl = DataLoader(TensorDataset(X_test,y_test),batch_size=64,shuffle=True)三:模型训练
1.构建模型
python
class model_rnn(nn.Module):
def __init__(self):
super(model_rnn, self).__init__()
self.rnn0 = nn.RNN(input_size=32,hidden_size=200,num_layers=1,batch_first=True)
self.fc0 = nn.Linear(200,50)
self.fc1 = nn.Linear(50,2)
def forward(self,x):
out,hidden1 = self.rnn0(x)
out = self.fc0(out)
out = self.fc1(out)
return out
model = model_rnn()
model.to(device)
model
2.定义训练函数
python
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出pred和真实值y之间的差距,y为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss3.定义测试函数
python
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0 # 初始化测试损失和正确率
# 当不进行训练时,停止梯度更新,节省计算内存消耗
# with torch.no_grad():
for imgs, target in dataloader: # 获取图片及其标签
with torch.no_grad():
imgs, target = imgs.to(device), target.to(device)
# 计算误差
tartget_pred = model(imgs) # 网络输出
loss = loss_fn(tartget_pred, target) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 记录acc与loss
test_loss += loss.item()
test_acc += (tartget_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss4.正式训练模型
python
loss_fn = nn.CrossEntropyLoss()
opt = torch.optim.Adam(model.parameters(),lr=5e-5)
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = opt.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss,lr))
print("="*20,'Done',"="*20)
四:模型评估
1.Loss与Accuracy图
python
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 200 #分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()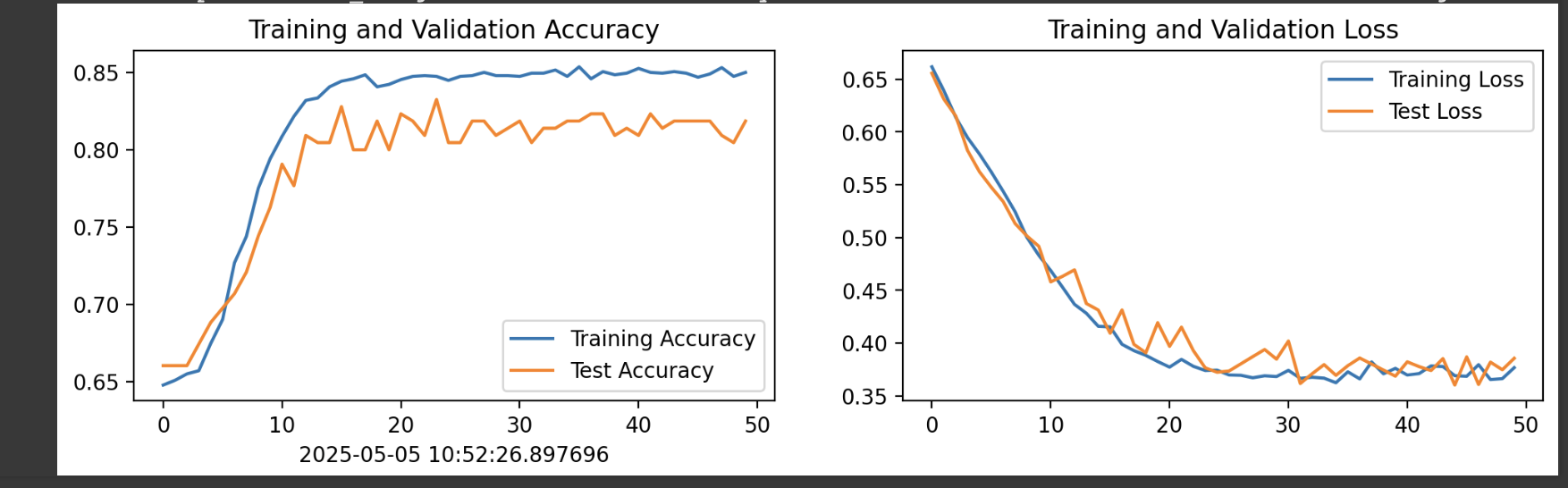
2.混淆矩阵
python
print("============输入数据shape为============")
print("X_test.shape: ",X_test.shape)
print("y_test.shape: ",y_test.shape)
pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print("============输出数据shape为============")
print("pred.shape: ",pred.shape)
python
#混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, pred)
plt.figure(figsize=(6,5))
plt.suptitle('')
sns.heatmap(cm, annot=True,fmt="d",cmap='Blues')
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix",fontsize=12)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.tight_layout()
plt.show()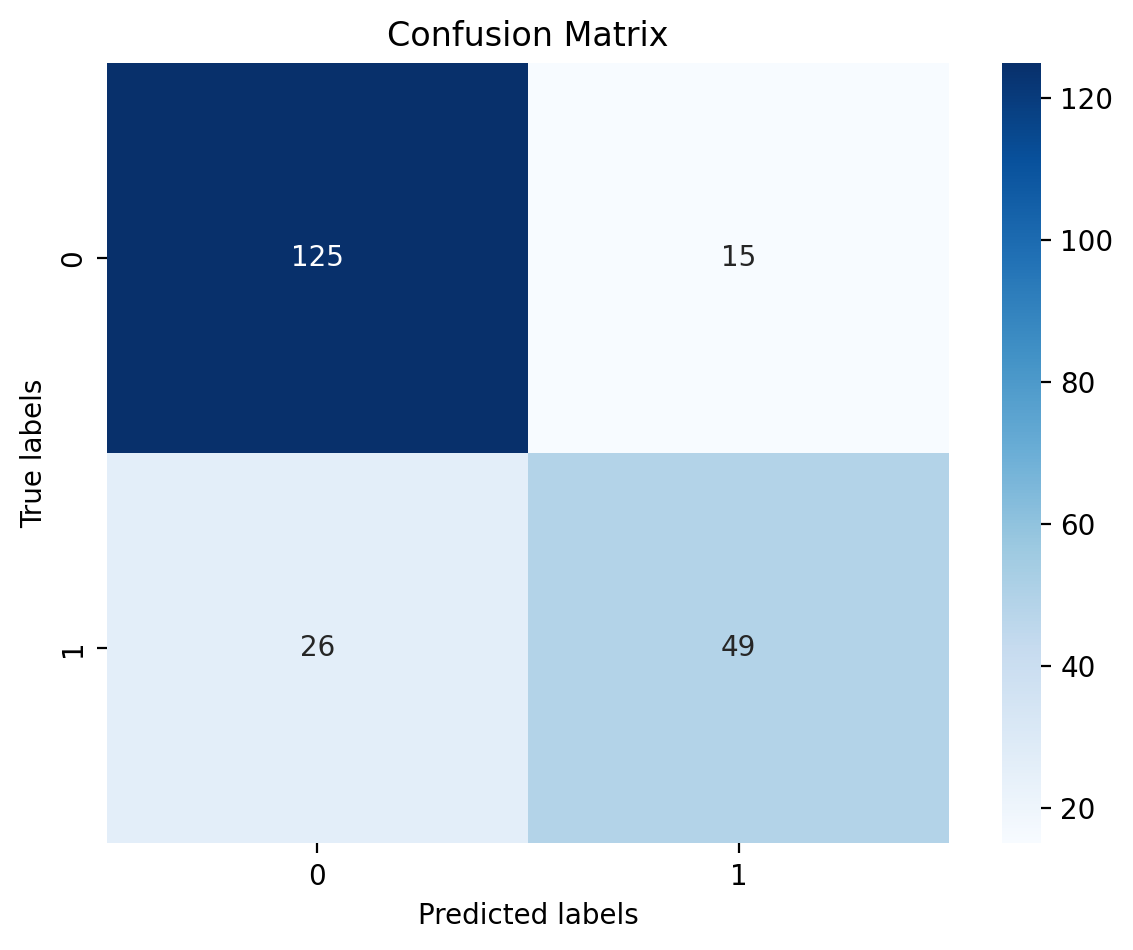
3.调用模型进行预测
python
test_X = X_test[0].reshape(1,-1)
pred = model(test_X.to(device)).argmax(1).item()
print("预测结果为:",pred)
print("=="*20)
print("0: 未患病")
print("1: 已患病")