目录
[1.1 数据集下载](#1.1 数据集下载)
[1.2 数据集简介](#1.2 数据集简介)
[2.1 用到的模块](#2.1 用到的模块)
[2.2 设置随机种子](#2.2 设置随机种子)
[2.3 图像的预处理](#2.3 图像的预处理)
[2.4 CNN模型层结构](#2.4 CNN模型层结构)
[2.5 初始化](#2.5 初始化)
[2.6 训练和验证](#2.6 训练和验证)
[3.1 定义相同预处理](#3.1 定义相同预处理)
[3.2 定义相同的层结构](#3.2 定义相同的层结构)
[3.3 初始化](#3.3 初始化)
[3.4 预测](#3.4 预测)
[4.1 训练集结果 编辑](#4.1 训练集结果 编辑)
[4.2 测试集结果](#4.2 测试集结果)
[4.3 总结与改进](#4.3 总结与改进)
[5.1 训练部分代码](#5.1 训练部分代码)
[5.2 测试部分代码](#5.2 测试部分代码)
一,数据集介绍
1.1 数据集下载
本数据集下载自:
Cat and Dog![]() https://www.kaggle.com/datasets/tongpython/cat-and-dog
https://www.kaggle.com/datasets/tongpython/cat-and-dog
1.2 数据集简介
该数据集分为训练集和测试集,其中训练集包含4000张"cat"照片和4000张"dog"照片
测试集包括1000+"cat"照片和1000+"dog"照片


二,模型训练
2.1 用到的模块
python
import os # 用于文件路径操作
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.optim import lr_scheduler # 学习率调度器
from torch.utils.data import DataLoader, random_split # 数据加载和分割工具
from torchvision import datasets, transforms # 计算机视觉数据集和数据增强工具
import matplotlib.pyplot as plt # 绘图工具
import numpy as np # 数值计算库和之前的实验不同的是加入了学习率调度器这个东西,用于动态调整优化器的学习率,以平衡训练初期的快速收敛和后期的精细调优。合理的学习率调整策略可以显著提升模型性能,避免陷入局部最优或过拟合。学习率调度器可以看作是深度学习训练中的 "自动调优助手",它的核心目标是通过算法自动调整学习率。
2.2 设置随机种子
python
torch.manual_seed(42) # 设置PyTorch随机种子
np.random.seed(42) # 设置NumPy随机种子确保实验结果可复现
2.3 图像的预处理
python
# 定义训练集数据预处理流程(包含数据增强)
train_transform = transforms.Compose([
transforms.Resize((256, 256)), # 将图像缩放到256x256尺寸
transforms.RandomCrop(224), # 随机裁剪到224x224尺寸(增强模型泛化能力)
transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)
transforms.ToTensor(), # 将图像转换为PyTorch张量
# 图像归一化(使用ImageNet数据集的均值和标准差)
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 定义验证集数据预处理流程(无数据增强,仅标准化)
val_transform = transforms.Compose([
transforms.Resize((256, 256)), # 缩放到256x256尺寸
transforms.CenterCrop(224), # 中心裁剪到224x224尺寸(保持一致性)
transforms.ToTensor(), # 转换为张量
# 相同的归一化操作,确保和训练集数据分布一致
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 设置数据集路径(需替换为实际路径)
data_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\training_set\training_set'
# 创建原始数据集(训练集和验证集使用不同的预处理流程)
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform) # 训练集带增强
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform) # 验证集无增强
# 划分数据集为训练集和验证集(80%训练,20%验证)
train_size = int(0.8 * len(train_dataset)) # 计算训练集样本数量
val_size = len(train_dataset) - train_size # 计算验证集样本数量
# 创建随机数生成器(确保分割结果可复现)
generator = torch.Generator().manual_seed(42)
# 按索引随机分割数据集(使用相同的随机种子保证划分一致)
train_indices, val_indices = random_split(
range(len(train_dataset)), # 使用数据集索引进行分割
[train_size, val_size], # 分割比例
generator=generator # 指定随机数生成器
)
# 根据索引创建子集(分别对应训练集和验证集)
train_dataset = torch.utils.data.Subset(train_dataset, train_indices) # 训练集子集
val_dataset = torch.utils.data.Subset(val_dataset, val_indices) # 验证集子集验证集的使命是 "真实评估",而非 "数据增强"。保持其数据分布与测试集一致,是确保模型性能评估可靠的关键。验证集的核心作用就是在训练过程中实时、客观地评估模型性能
2.4 CNN模型层结构
python
class CatDogCNN(nn.Module):
def __init__(self):
super(CatDogCNN, self).__init__() # 继承父类初始化
# 第一层卷积:输入3通道,输出32通道,卷积核3x3,填充1保持尺寸
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 第二层卷积:输入32通道,输出64通道,卷积核3x3,填充1
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
# 第三层卷积:输入64通道,输出128通道,卷积核3x3,填充1
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
# 第四层卷积:输入128通道,输出256通道,卷积核3x3,填充1
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2) # 最大池化层:尺寸减半
# 全连接层1:输入维度由卷积层输出决定(256通道,14x14尺寸)
self.fc1 = nn.Linear(256 * 14 * 14, 512)
# 全连接层2:输出2类(猫和狗)
self.fc2 = nn.Linear(512, 2)
self.dropout = nn.Dropout(0.5) # 随机失活层(防止过拟合)
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 卷积 -> 激活 -> 池化 的标准流程
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
x = self.pool(self.relu(self.conv4(x)))
# 将多维张量展平为一维(用于全连接层输入)
x = x.view(-1, 256 * 14 * 14)
x = self.dropout(x) # 应用随机失活
x = self.relu(self.fc1(x)) # 全连接层+激活函数
x = self.dropout(x) # 再次应用随机失活
x = self.fc2(x) # 最终分类层(不添加Softmax,由损失函数处理)
return x
2.5 初始化
python
# 初始化设备(优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device) # 将模型移动到指定设备(CPU/GPU)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数(适用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,初始学习率0.001
# 创建学习率调度器(当验证损失不再下降时降低学习率)
scheduler = lr_scheduler.ReduceLROnPlateau(
optimizer, # 关联的优化器
mode='min', # 监控指标为最小值(验证损失)
patience=3, # 连续3个epoch无改善则调整学习率
factor=0.5 # 学习率调整因子(乘以0.5)
)2.6 训练和验证
python
# 定义训练和验证函数
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):
best_val_acc = 0.0 # 记录最佳验证准确率
history = { # 用于保存训练过程中的指标
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
for epoch in range(epochs): # 遍历指定的训练轮数
# --------------------------- 训练阶段 ---------------------------
model.train() # 设置模型为训练模式(激活Dropout等层)
train_loss = 0.0 # 初始化训练损失
train_correct = 0 # 初始化正确预测数
train_total = 0 # 初始化总样本数
# 遍历训练数据加载器
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
# 累加损失和准确率统计
train_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1) # 获取最大概率的类别索引
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
# 计算平均训练损失和准确率
train_loss = train_loss / len(train_dataset)
train_acc = 100.0 * train_correct / train_total
# --------------------------- 验证阶段 ---------------------------
model.eval() # 设置模型为评估模式(关闭Dropout等层)
val_loss = 0.0 # 初始化验证损失
val_correct = 0 # 初始化正确预测数
val_total = 0 # 初始化总样本数
with torch.no_grad(): # 不计算梯度(节省内存和计算资源)
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备
outputs = model(inputs) # 前向传播(无梯度)
loss = criterion(outputs, labels) # 计算损失
# 累加验证损失和准确率统计
val_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
val_total += labels.size(0)
val_correct += predicted.eq(labels).sum().item()
# 计算平均验证损失和准确率
val_loss = val_loss / len(val_dataset)
val_acc = 100.0 * val_correct / val_total
# --------------------------- 学习率调整 ---------------------------
scheduler.step(val_loss) # 根据验证损失调整学习率
# --------------------------- 模型保存 ---------------------------
if val_acc > best_val_acc: # 如果当前验证准确率更高
best_val_acc = val_acc # 更新最佳准确率
# 保存模型参数到文件
torch.save(model.state_dict(), 'best_cat_dog_model.pth')
# --------------------------- 结果记录 ---------------------------
history['train_loss'].append(train_loss) # 记录训练损失
history['train_acc'].append(train_acc) # 记录训练准确率
history['val_loss'].append(val_loss) # 记录验证损失
history['val_acc'].append(val_acc) # 记录验证准确率
# 打印当前epoch的训练结果
print(f'Epoch {epoch + 1}/{epochs}')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')
print('-' * 50) # 分隔线
return model, history # 返回训练好的模型和训练历史三,模型测试
3.1 定义相同预处理
python
# 定义预处理流程(与验证集一致)
test_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])3.2 定义相同的层结构
python
class CatDogCNN(nn.Module):
def __init__(self):
super(CatDogCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(256 * 14 * 14, 512)
self.fc2 = nn.Linear(512, 2)
self.dropout = nn.Dropout(0.5)
self.relu = nn.ReLU()
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
x = self.pool(self.relu(self.conv4(x)))
x = x.view(-1, 256 * 14 * 14)
x = self.dropout(x)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x3.3 初始化
python
# 初始化模型和设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device)
model.load_state_dict(torch.load('best_cat_dog_model.pth', map_location=device))
model.eval() # 设置为评估模式3.4 预测
python
def test_on_dataset(test_dir):
"""
对整个测试数据集进行预测并计算准确率
:param test_dir: 测试集路径(需包含'cat'和'dog'子文件夹)
:return: 测试集准确率
"""
try:
# 检查路径是否存在
if not os.path.exists(test_dir):
raise FileNotFoundError(f"错误:测试集路径不存在 - {test_dir}")
# 加载数据集
test_dataset = datasets.ImageFolder(
test_dir,
transform=test_transform
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=32,
shuffle=False,
num_workers=0 # 避免多线程冲突
)
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"测试集准确率:{accuracy:.2f}%")
return accuracy
except Exception as e:
print(f"批量预测失败:{e}")
return None四,测试结果
4.1 训练集结果 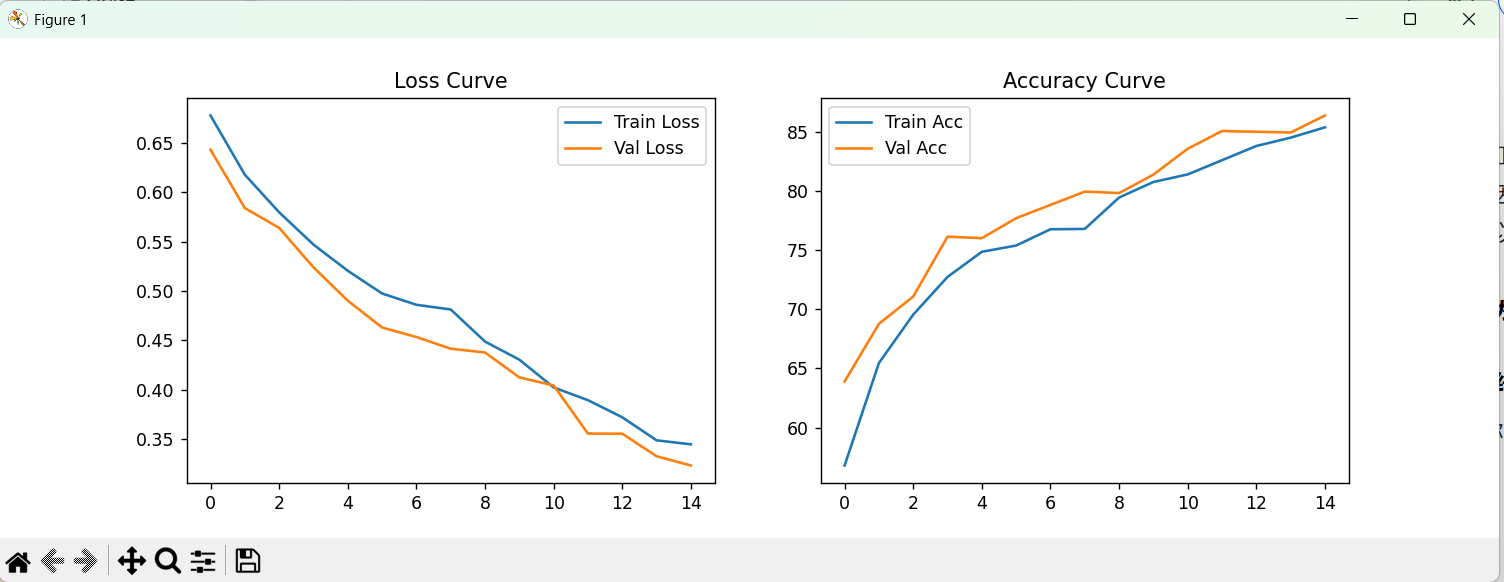
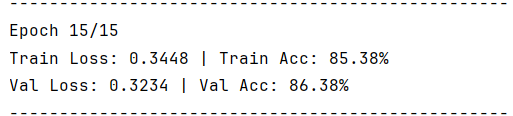
4.2 测试集结果

4.3 总结与改进
该模型使用到最基本的CNN模型,由于参数设置的问题以及模型本身的问题,导致识别的准确率不高,相比相对比较成熟的模型如:resnet,Inception,EfficientNet等还存在较大差距,下次实验将利用效果更好的模型进行训练。但是就优点来说,该模型并没有发生过拟合的情况,测试集与训练集以及验证集的识别率都高度一致。
五,完整代码
5.1 训练部分代码
python
# 导入必要的库
import os # 用于文件路径操作
import torch # PyTorch深度学习框架核心库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.optim import lr_scheduler # 学习率调度器
from torch.utils.data import DataLoader, random_split # 数据加载和分割工具
from torchvision import datasets, transforms # 计算机视觉数据集和数据增强工具
import matplotlib.pyplot as plt # 绘图工具
import numpy as np # 数值计算库
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE' # 添加在此处
# 设置随机种子,确保实验结果可复现
torch.manual_seed(42) # 设置PyTorch随机种子
np.random.seed(42) # 设置NumPy随机种子
# 定义训练集数据预处理流程(包含数据增强)
train_transform = transforms.Compose([
transforms.Resize((256, 256)), # 将图像缩放到256x256尺寸
transforms.RandomCrop(224), # 随机裁剪到224x224尺寸(增强模型泛化能力)
transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)
transforms.ToTensor(), # 将图像转换为PyTorch张量
# 图像归一化(使用ImageNet数据集的均值和标准差)
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 定义验证集数据预处理流程(无数据增强,仅标准化)
val_transform = transforms.Compose([
transforms.Resize((256, 256)), # 缩放到256x256尺寸
transforms.CenterCrop(224), # 中心裁剪到224x224尺寸(保持一致性)
transforms.ToTensor(), # 转换为张量
# 相同的归一化操作,确保和训练集数据分布一致
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 设置数据集路径(需替换为实际路径)
data_dir = r'C:\Users\10532\Desktop\Study\Test\Data\catordog\training_set\training_set'
# 创建原始数据集(训练集和验证集使用不同的预处理流程)
train_dataset = datasets.ImageFolder(data_dir, transform=train_transform) # 训练集带增强
val_dataset = datasets.ImageFolder(data_dir, transform=val_transform) # 验证集无增强
# 划分数据集为训练集和验证集(80%训练,20%验证)
train_size = int(0.8 * len(train_dataset)) # 计算训练集样本数量
val_size = len(train_dataset) - train_size # 计算验证集样本数量
# 创建随机数生成器(确保分割结果可复现)
generator = torch.Generator().manual_seed(42)
# 按索引随机分割数据集(使用相同的随机种子保证划分一致)
train_indices, val_indices = random_split(
range(len(train_dataset)), # 使用数据集索引进行分割
[train_size, val_size], # 分割比例
generator=generator # 指定随机数生成器
)
# 根据索引创建子集(分别对应训练集和验证集)
train_dataset = torch.utils.data.Subset(train_dataset, train_indices) # 训练集子集
val_dataset = torch.utils.data.Subset(val_dataset, val_indices) # 验证集子集
# 创建数据加载器(用于批量加载数据)
train_loader = DataLoader(
train_dataset, # 训练集数据集
batch_size=32, # 批量大小
shuffle=True # 训练时打乱数据顺序
)
val_loader = DataLoader(
val_dataset, # 验证集数据集
batch_size=32, # 批量大小
shuffle=False # 验证时不打乱数据
)
# 定义改进的CNN模型(猫狗分类任务)
class CatDogCNN(nn.Module):
def __init__(self):
super(CatDogCNN, self).__init__() # 继承父类初始化
# 第一层卷积:输入3通道,输出32通道,卷积核3x3,填充1保持尺寸
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 第二层卷积:输入32通道,输出64通道,卷积核3x3,填充1
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
# 第三层卷积:输入64通道,输出128通道,卷积核3x3,填充1
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
# 第四层卷积:输入128通道,输出256通道,卷积核3x3,填充1
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2) # 最大池化层:尺寸减半
# 全连接层1:输入维度由卷积层输出决定(256通道,14x14尺寸)
self.fc1 = nn.Linear(256 * 14 * 14, 512)
# 全连接层2:输出2类(猫和狗)
self.fc2 = nn.Linear(512, 2)
self.dropout = nn.Dropout(0.5) # 随机失活层(防止过拟合)
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 卷积 -> 激活 -> 池化 的标准流程
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = self.pool(self.relu(self.conv3(x)))
x = self.pool(self.relu(self.conv4(x)))
# 将多维张量展平为一维(用于全连接层输入)
x = x.view(-1, 256 * 14 * 14)
x = self.dropout(x) # 应用随机失活
x = self.relu(self.fc1(x)) # 全连接层+激活函数
x = self.dropout(x) # 再次应用随机失活
x = self.fc2(x) # 最终分类层(不添加Softmax,由损失函数处理)
return x
# 初始化设备(优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CatDogCNN().to(device) # 将模型移动到指定设备(CPU/GPU)
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数(适用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,初始学习率0.001
# 创建学习率调度器(当验证损失不再下降时降低学习率)
scheduler = lr_scheduler.ReduceLROnPlateau(
optimizer, # 关联的优化器
mode='min', # 监控指标为最小值(验证损失)
patience=3, # 连续3个epoch无改善则调整学习率
factor=0.5 # 学习率调整因子(乘以0.5)
)
# 定义训练和验证函数
def train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs):
best_val_acc = 0.0 # 记录最佳验证准确率
history = { # 用于保存训练过程中的指标
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
for epoch in range(epochs): # 遍历指定的训练轮数
# --------------------------- 训练阶段 ---------------------------
model.train() # 设置模型为训练模式(激活Dropout等层)
train_loss = 0.0 # 初始化训练损失
train_correct = 0 # 初始化正确预测数
train_total = 0 # 初始化总样本数
# 遍历训练数据加载器
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备
optimizer.zero_grad() # 清空梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
# 累加损失和准确率统计
train_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1) # 获取最大概率的类别索引
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
# 计算平均训练损失和准确率
train_loss = train_loss / len(train_dataset)
train_acc = 100.0 * train_correct / train_total
# --------------------------- 验证阶段 ---------------------------
model.eval() # 设置模型为评估模式(关闭Dropout等层)
val_loss = 0.0 # 初始化验证损失
val_correct = 0 # 初始化正确预测数
val_total = 0 # 初始化总样本数
with torch.no_grad(): # 不计算梯度(节省内存和计算资源)
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移动到设备
outputs = model(inputs) # 前向传播(无梯度)
loss = criterion(outputs, labels) # 计算损失
# 累加验证损失和准确率统计
val_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
val_total += labels.size(0)
val_correct += predicted.eq(labels).sum().item()
# 计算平均验证损失和准确率
val_loss = val_loss / len(val_dataset)
val_acc = 100.0 * val_correct / val_total
# --------------------------- 学习率调整 ---------------------------
scheduler.step(val_loss) # 根据验证损失调整学习率
# --------------------------- 模型保存 ---------------------------
if val_acc > best_val_acc: # 如果当前验证准确率更高
best_val_acc = val_acc # 更新最佳准确率
# 保存模型参数到文件
torch.save(model.state_dict(), 'best_cat_dog_model.pth')
# --------------------------- 结果记录 ---------------------------
history['train_loss'].append(train_loss) # 记录训练损失
history['train_acc'].append(train_acc) # 记录训练准确率
history['val_loss'].append(val_loss) # 记录验证损失
history['val_acc'].append(val_acc) # 记录验证准确率
# 打印当前epoch的训练结果
print(f'Epoch {epoch + 1}/{epochs}')
print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.2f}%')
print('-' * 50) # 分隔线
return model, history # 返回训练好的模型和训练历史
# 开始训练模型
print("开始训练模型...")
model, history = train_model(
model, train_loader, val_loader, criterion, optimizer, scheduler, epochs=15
)
# --------------------------- 结果可视化 ---------------------------
plt.figure(figsize=(12, 4)) # 创建绘图窗口
# 绘制损失曲线
plt.subplot(1, 2, 1) # 子图1(左)
plt.plot(history['train_loss'], label='Train Loss') # 训练损失
plt.plot(history['val_loss'], label='Val Loss') # 验证损失
plt.legend() # 显示图例
plt.title('Loss Curve') # 设置标题
# 绘制准确率曲线
plt.subplot(1, 2, 2) # 子图2(右)
plt.plot(history['train_acc'], label='Train Acc') # 训练准确率
plt.plot(history['val_acc'], label='Val Acc') # 验证准确率
plt.legend() # 显示图例
plt.title('Accuracy Curve') # 设置标题
plt.show() # 显示图像
# 打印最佳验证集准确率
print(f"最佳验证集准确率: {max(history['val_acc']):.2f}%")5.2 测试部分代码
python
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from PIL import Image
import os
# 定义模型类(与训练代码完全一致)
class CatDogCNN(nn.Module):
def __init__(self):
super(CatDogCNN, self).__init__()
# 四层卷积+池化结构,逐步提取图像特征
self.conv1 = nn.Conv2d(3, 32, 3, padding=1) # 输入3通道,输出32通道,3x3卷积核
self.conv2 = nn.Conv2d(32, 64, 3, padding=1) # 通道数翻倍
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.conv4 = nn.Conv2d(128, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2) # 2x2最大池化,每次尺寸减半
# 全连接分类器
self.fc1 = nn.Linear(256 * 14 * 14, 512) # 卷积输出展平后的维度 -> 512
self.fc2 = nn.Linear(512, 2) # 512 -> 2类(猫/狗)
self.dropout = nn.Dropout(0.5) # 防止过拟合
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 前向传播过程:卷积+ReLU+池化的四层结构
x = self.pool(self.relu(self.conv1(x))) # 输入:224x224 -> 输出:112x112
x = self.pool(self.relu(self.conv2(x))) # 112x112 -> 56x56
x = self.pool(self.relu(self.conv3(x))) # 56x56 -> 28x28
x = self.pool(self.relu(self.conv4(x))) # 28x28 -> 14x14
x = x.view(-1, 256 * 14 * 14) # 展平为一维向量
x = self.dropout(x) # 训练时随机丢弃神经元
x = self.relu(self.fc1(x)) # 全连接+激活
x = self.dropout(x)
x = self.fc2(x) # 输出最终分类得分
return x
# 初始化模型和设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断是否可用GPU
model = CatDogCNN().to(device) # 创建模型并移至GPU/CPU
model.load_state_dict(torch.load('best_cat_dog_model.pth', map_location=device)) # 加载预训练权重
model.eval() # 设置为评估模式(关闭Dropout等)
# 定义预处理流程(与验证集一致)
test_transform = transforms.Compose([
transforms.Resize((256, 256)), # 图像缩放到256x256
transforms.CenterCrop(224), # 中心裁剪到224x224(模型输入尺寸)
transforms.ToTensor(), # 转换为Tensor并归一化到[0,1]
# 使用ImageNet数据集的均值和标准差进行归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
### 测试集批量预测函数 ###
def test_on_dataset(test_dir):
"""
对整个测试数据集进行预测并计算准确率
:param test_dir: 测试集路径(需包含'cat'和'dog'子文件夹)
:return: 测试集准确率
"""
try:
# 检查路径是否存在
if not os.path.exists(test_dir):
raise FileNotFoundError(f"错误:测试集路径不存在 - {test_dir}")
# 加载数据集(假设目录结构:test_dir/cat/*.jpg 和 test_dir/dog/*.jpg)
test_dataset = datasets.ImageFolder(
test_dir,
transform=test_transform # 应用预处理
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=32, # 每批处理32张图像
shuffle=False, # 不打乱顺序
num_workers=0 # 单线程加载(避免多线程冲突)
)
# 批量预测并计算准确率
correct = 0 # 预测正确的样本数
total = 0 # 总样本数
with torch.no_grad(): # 禁用梯度计算,节省内存和加速
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device) # 数据移至设备
outputs = model(inputs) # 模型预测
_, predicted = torch.max(outputs.data, 1) # 获取预测类别(最大值索引)
total += labels.size(0) # 累加总样本数
correct += (predicted == labels).sum().item() # 累加正确预测数
accuracy = 100 * correct / total # 计算准确率百分比
print(f"测试集准确率:{accuracy:.2f}%")
return accuracy
except Exception as e:
print(f"批量预测失败:{e}")
return None
### 主函数(执行预测) ###
if __name__ == "__main__":
# ---------------------- 配置路径 ----------------------
# 测试集路径(替换为你的测试集根目录)
test_dataset_path = r"C:\Users\10532\Desktop\Study\Test\Data\catordog\test_set\test_set"
# ---------------------- 执行测试集批量预测 ----------------------
print("\n----------------------")
print(f"正在测试数据集:{test_dataset_path}")
test_on_dataset(test_dataset_path)