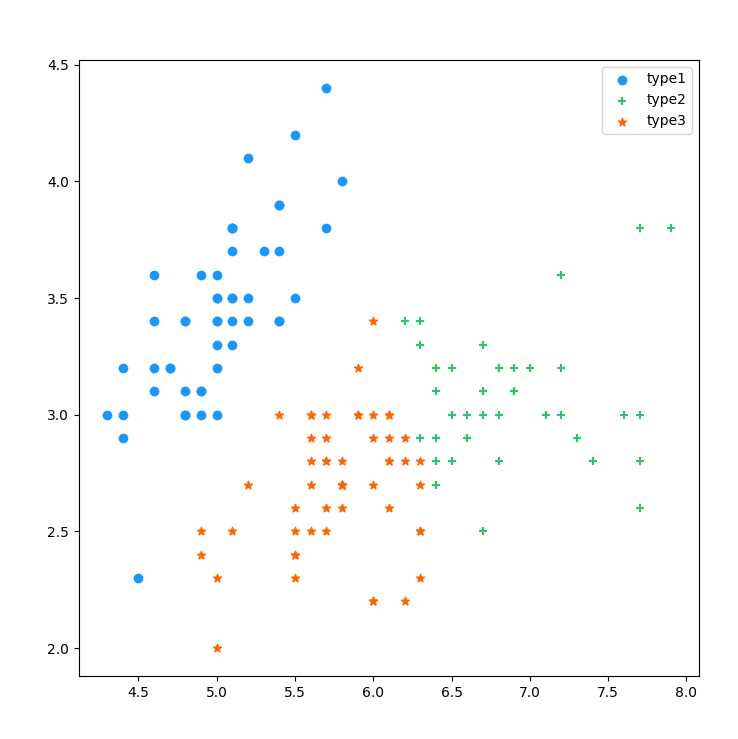
先来看看K-Means算法的核心流程吧

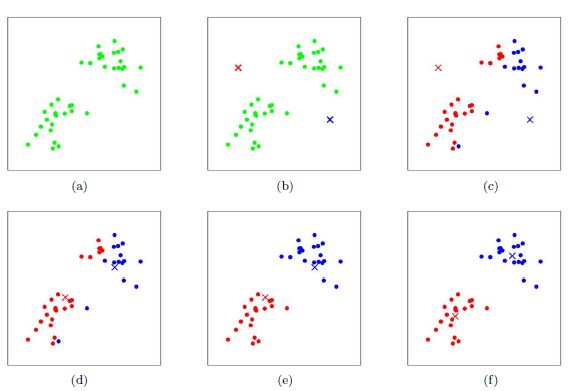
下面我们通过一个简单聚类来介绍K-Means算法迭代过程
如图(a)所示:表示初始化数据集。
如图(b)所示:假设K=2,随机选择两个点作为类别质心,分别为图中的红色和蓝色质心。
如图©所示:分别求样本点xi到这两个质心的距离,并标记每个样本点的类别为距离质心最近的类别。划分得到两个簇C1和C2,完成一次迭代。
如图(d)所示:对标记为红色的点和蓝色的点分别求新的质心。
如图(e)所示:重复图©(d)过程,标记每个样本点的类别为距离质心最近的类别,重新划分得到两个簇C1和C2。
如图(f)所示:直到质心不再改变后完成迭代,最终得到两个簇C1和C2。
问题来了,这个初始质心如何随机选择
随机法: 随机选择某k个样本点作为初始质心,此方法可能导致收敛速度过慢。
层次聚类法: 先使用层次聚类进行聚类,提取出k个簇,选择这k个簇的质心作为KMeans的初始质心。
k-means++法(咱们一会代码就是这个方法): 随机选择一个样本点作为初始质心,计算任一样本点到初始质心的距离,根据距离来确定下一个质心,让下一个质心离上一个质心足够远,直到选中k个质心。
直接上个K-Means代码
python
import numpy as np
import random
from matplotlib.pylab import plt # pip install matplotlib
from sklearn.datasets import load_iris # pip install scikit-learn
# i.chaoxing.com
# X = np.array([[1, 2], [1, 3], [3, 1], [2, 3], [4, 2]])
X = load_iris().data[:,:2] # 每条数据只取前两项特征值
class K_Means:
def __init__(self, K, times):
# 分类个数
self.k = K
# 优化质心坐标的循环次数
self.times = times
# 划分后的数据集合
self.quality_center = []
# 数据集
self.train_x = []
# 计算两个数据的距离
def calc_distance(self, p1, p2):
return np.sum((p1 - p2) ** 2)
# 计算数据集的质心点坐标
def Cmass(self, data):
size = len(data)
l = np.array([0.0] * len(data[0]))
for item in data:
l += item
return [round(item, 2) for item in l / size]
# 初始化质心点坐标集合
def initQualityCenter(self, X):
# quality_center的每一个元素 {坐标,索引,分类元素}
quality_center, size = [], 0
# visit: 访问记录 0代表没访问过 1代表访问过
visited = [0] * len(X)
# 当前quality_center中每个质心的下标
total_center_index = []
index = int(random.random() * len(X))
while size < self.k:
quality_center.append({'center': X[index], 'index': index, 'element': []})
total_center_index.append(index)
visited[index], last_center, max_distance = 1, X[index], -1
size += 1
for x_i, x_v in enumerate(X):
if visited[x_i] != 1:
distance = self.calc_distance(x_v, last_center)
if distance > max_distance:
max_distance = distance
index = x_i
for i, m in enumerate(X):
if i not in total_center_index:
min_distance, index = 9999999999.0, -1
for q_i, q_m in enumerate(quality_center):
d = self.calc_distance(m, q_m['center'])
if d < min_distance:
min_distance = d
index = q_i
quality_center[index]['element'].append(i)
return quality_center
# 优化质心坐标和分类
def resetQualityCenter(self, X, quality_center):
for _ in range(self.times):
for q_i, item in enumerate(quality_center):
mark_index = [X[i] for i in [*item['element'], item['index']]]
center = self.Cmass(mark_index)
quality_center[q_i]['center'] = center
quality_center[q_i]['element'] = []
for i, m in enumerate(X):
min_distance, index = 9999999999.0, -1
for q_i, q_m in enumerate(quality_center):
d = self.calc_distance(m, q_m['center'])
if d < min_distance:
min_distance = d
index = q_i
quality_center[index]['element'].append(i)
return quality_center
# 训练数据集
def fit(self, X):
self.train_x = X
# 初始化质心坐标和分类
quality_center = self.initQualityCenter(X)
# 优化质心坐标和分类
self.quality_center = self.resetQualityCenter(X, quality_center)
# 绘制可视化图
def preview(self):
icon,color = ['o','+','*','^'],['#1897ff','#2AC864','#ff6600','#000000']
plt.figure(figsize=(8, 8))
for i,item in enumerate(self.quality_center):
l = [self.train_x[mark] for mark in item['element']]
x, y = [item[0] for item in l], [item[1] for item in l]
plt.scatter(x,y,marker=icon[i],c=color[i],label='type'+str(i+1))
plt.legend()
plt.show()
m = K_Means(K=3, times=8)
m.fit(X)
m.preview()让我们看一下分类后的可视化图