一、引言
随着信息技术的快速发展,数据的获取与处理变得尤为重要。多模态文件信息抽取能力是指从包含多种类型数据(如文本、图像、音频、视频等)的文件中自动提取有用信息的技术。这种技术在多个领域都有广泛的应用,能够显著提高信息处理的效率和准确性。
通过传统人工方式来处理数据并提取信息,难免有失偏颇。因此通过先进的人工智能技术,识别和解析各种格式的文件,从而提取出有价值的信息,大幅提升数据处理效率成为大势所趋。
本文将带你使用AI技术进行多模态文件信息抽取的实战教程。无论是需要从大量文档和数据中提取关键信息从而提高数据处理效率和准确性、要对大量图片进行分类、标注、搜索优化还是对音视频信息进一步提取和处理,都可以通过该教程学有所获。
二、资源分享
正式开始之前,为了方便大家学习,我整理了一份多模态大模型的学习资料
包含教程、讲义、源码、论文和面试题等等(如图)
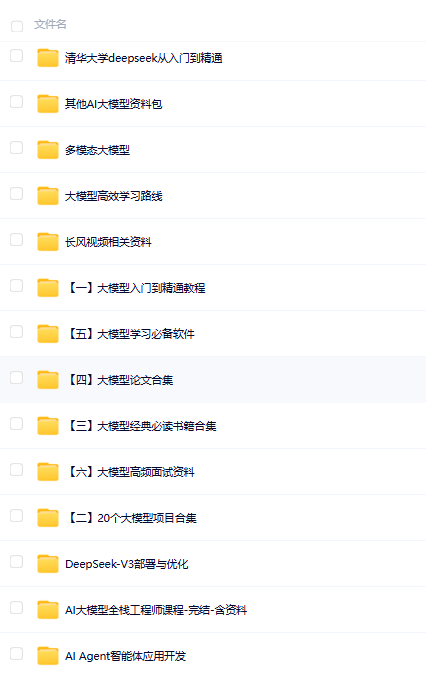
除此之外还有100G人工智能学习资料
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集。更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
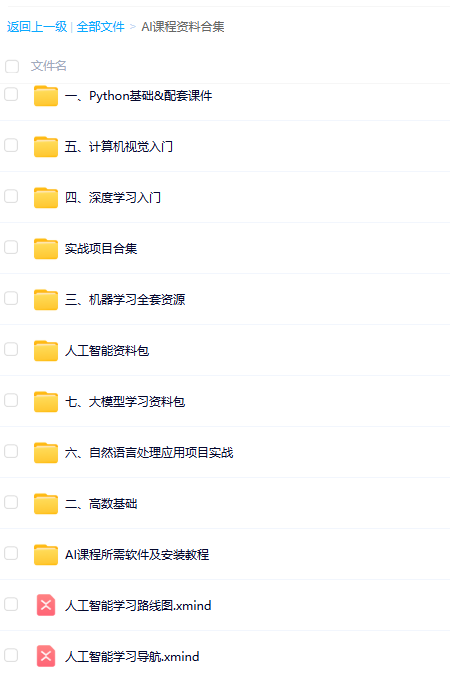
需要的兄弟可以按照这个图的方式免费获取
三、实操教程
该教程以提取文档文件信息为例,准备好要进行信息提取的文件和提示词,就可以开始我们的信息提取之旅啦。
资源部署
在文档信息提取的流程中,需要使用计算资源构建的 Web 服务来接收请求,再将文档和提示词发送至百炼模型服务,由百炼调用qwen-long文本模型处理后,最终返回处理结果。
-
创建阿里云百炼应用:前往百炼控制台,开通百炼的模型服务,开通服务可以使用免费额度
-
创建并部署默认环境:部署函数计算应用模板,参数配置可参考下表
|------------|-------------------------------|--------------------|
| 项目 | 说明 | 示例值 |
| 部署类型 | 选择部署类型。 | 直接部署 |
| 应用名称 | 自动生成。 | 默认 |
| 角色名称 | 模板所需的角色(如果需要授权,请按照控制台提示进行授权)。 | 默认 |
| 地域 | FC部署地域。 | 默认 华东1(杭州) |
| 百炼 API-KEY | 百炼 API-KEY。 | 部署资源中获取的百炼 API-KEY |
访问示例应用
-
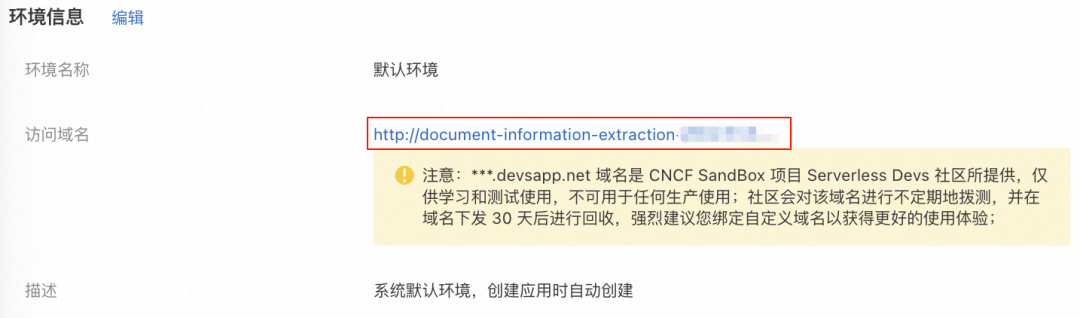
上述应用部署完成后,就可以在环境详情的环境信息中找到示例网站的访问域名,如下图所示:
-
点击访问域名,即可打开示例应用。参考下图:
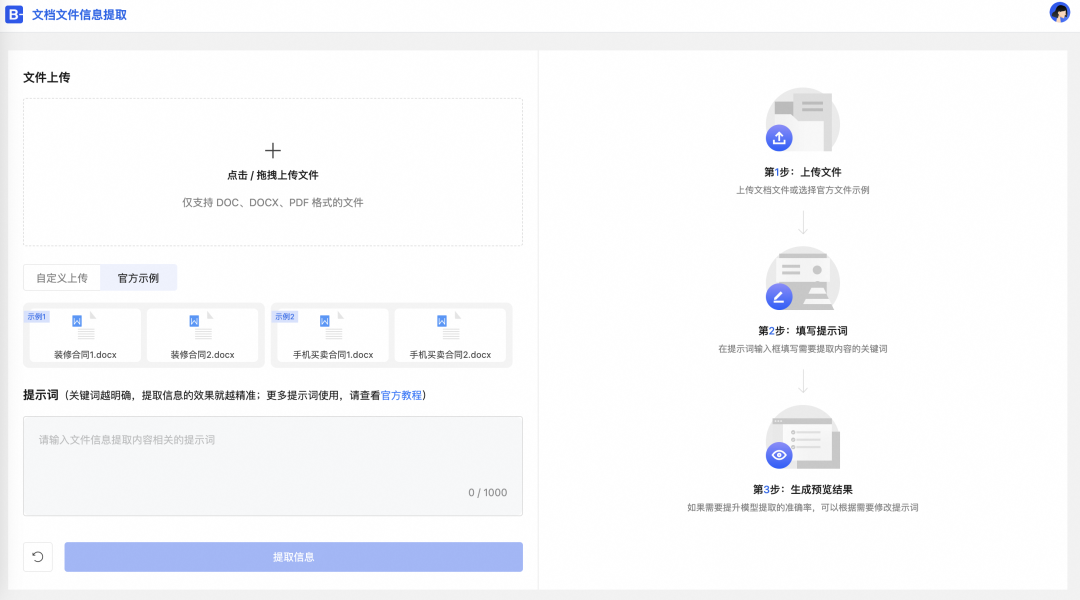
使用官方示例,进行信息提取
- 信息提取时,使用默认填写的关键词,模型会根据给出的关键词提取出对应的信息。
a.鼠标移动到示例1,然后单击使用该示例。
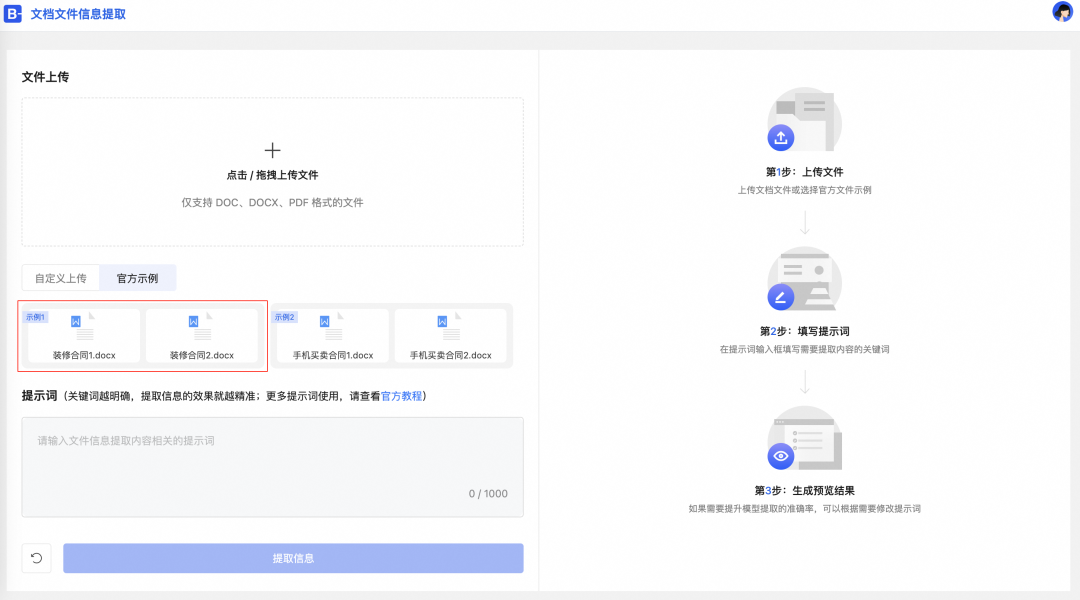
b.单击提取信息,等待片刻查看结果。
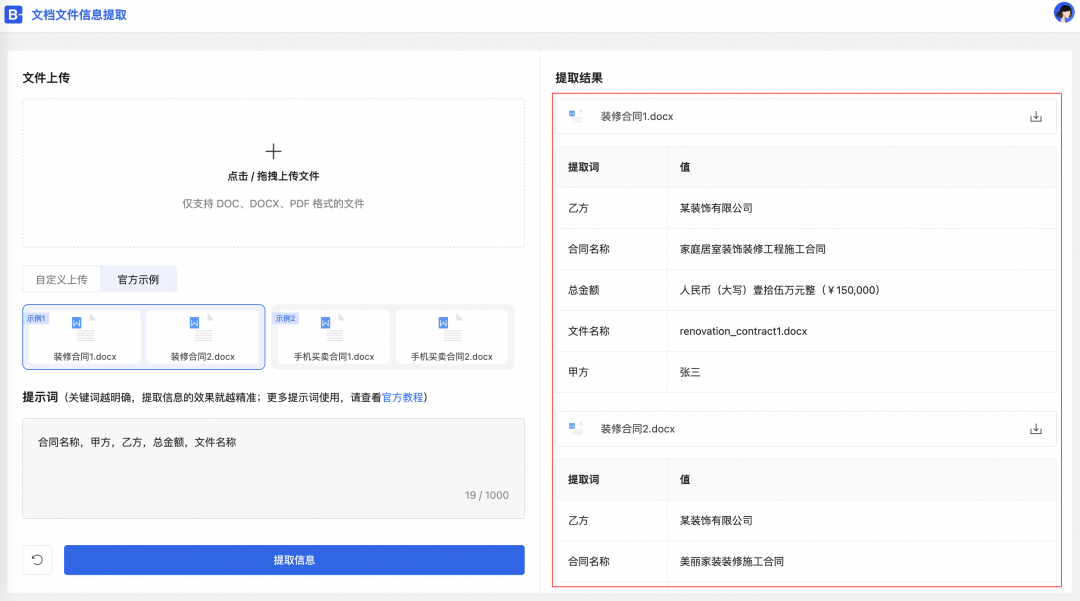
2.在信息提取时,不使用关键词,模型会自动分析理解,可能会出现每次返回的差异性。
a.鼠标移动到示例1,然后单击使用该示例。
b.删除关键词描述内容。
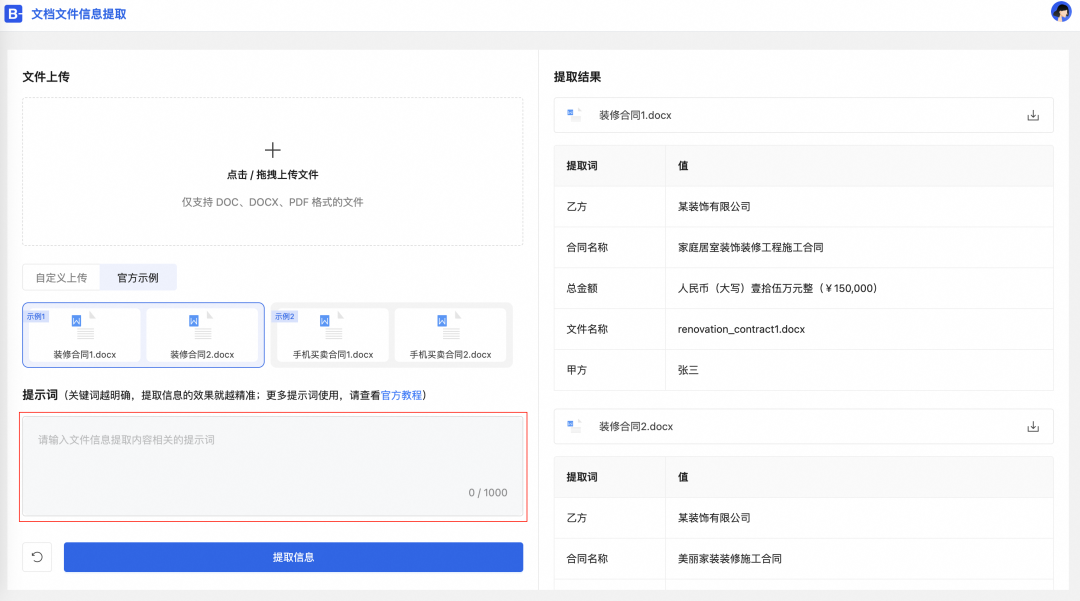
c.单击提取信息,等待片刻查看结果。
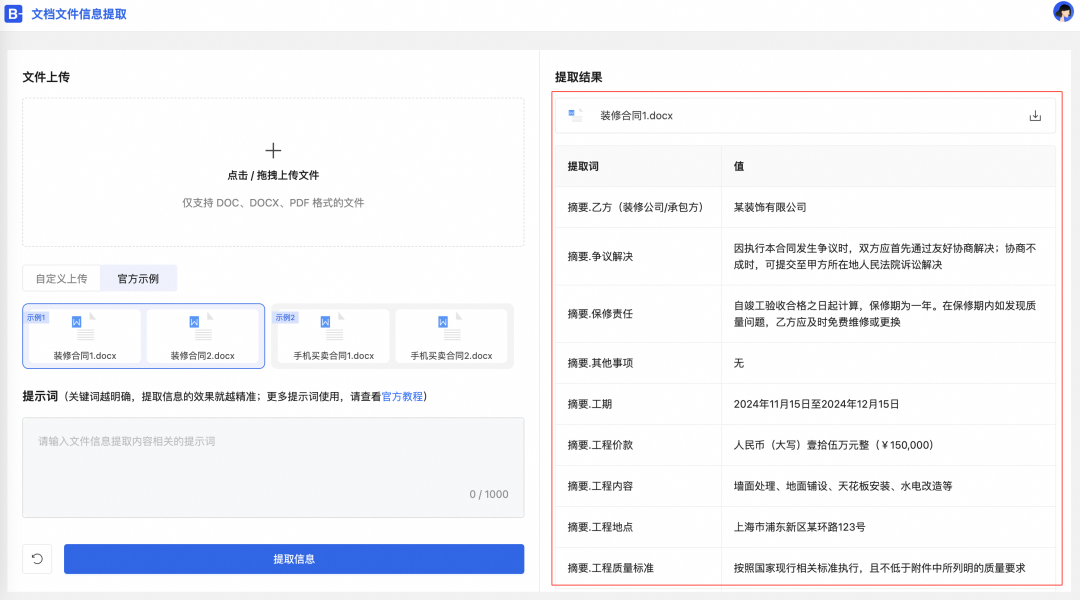
若想用于生产环境,还可以点击链接:
https://atomgit.com/aliyun_solution/document-information-extraction.git
下载源码,再进行二次开发。