1st author: Eric Zelikman
paper: STaR: Bootstrapping Reasoning With Reasoning | OpenReview NeurIPS 2022
code: ezelikman/STaR: Code for STaR: Bootstrapping Reasoning With Reasoning (NeurIPS 2022)
1. 当语言模型学会自我进化
Zelikman 等人提出的 STaR (Self-Taught Reasoner),旨在解决当前大型语言模型在复杂推理任务中,高质量"思维链"(Chain-of-Thought, CoT)数据获取的困境。目前主流方法要么依赖昂贵的人工标注,要么牺牲准确性采用少样本(few-shot)推理。STaR 独辟蹊径,提出一种迭代式自学习框架 ,让模型能够利用少量带推理过程的样本和大量无推理过程的问答对,自我生成并筛选推理过程,从而引导自身逐步提升推理能力。
1.1 问题根源与解法思路
当前,我们深知 CoT 能显著提升 LLM 在数学、常识问答等任务上的表现。然而,构建大规模、高质量的 CoT 数据集是瓶颈:
- 人工标注 (Manual Annotation): 成本高昂,难以覆盖所有领域。
- 模板化生成 (Template-based): 适用范围窄,依赖预先设计的启发式规则或已知解法。
- 少样本提示 (Few-shot Prompting with CoT): 虽然灵活,但通常性能远不如在完整 CoT 数据集上微调的模型。
STaR 的核心思想可以概括为一个 "生成 - 筛选 - 学习" 的迭代循环:
-
生成 (Generate): 利用现有的少量 CoT 样本作为提示 (prompt),引导模型为大量无 CoT 的问题生成推理过程和答案。
- 形式化地,给定问题 x i x_i xi,模型 M M M 生成推理 r i r_i ri 和答案 y ^ i \hat{y}_i y^i: ( r i , y ^ i ) ∼ M ( x i ∣ P ) (r_i, \hat{y}_i) \sim M(x_i | P) (ri,y^i)∼M(xi∣P), 其中 P P P 是少量 CoT 样本集合。
-
筛选 (Filter): 只保留那些最终能导出正确答案 y i y_i yi 的推理过程。
- 构建训练集 D c o r r e c t = { ( x i , r i , y i ) ∣ y ^ i = y i } D_{correct} = \{ (x_i, r_i, y_i) | \hat{y}_i = y_i \} Dcorrect={(xi,ri,yi)∣y^i=yi}。
-
学习 (Learn): 在筛选后的高质量 ( x i , r i , y i ) (x_i, r_i, y_i) (xi,ri,yi) 数据上微调 (fine-tune) 基础 LLM。
-
重复 (Repeat): 使用微调后的新模型,重复上述过程,期望能解决更复杂的问题,生成更高质量的推理。
1.2. 关键:"反思"与"合理化" (Rationalization)
上述循环存在一个问题:如果模型在某些问题上持续失败,它将无法从这些失败中获得新的学习信号。为了解决这个问题,STaR 引入了一个巧妙的机制------ "合理化" (Rationalization):
- 对于模型未能正确解答的问题 ( x j , y j ) (x_j, y_j) (xj,yj),STaR 会将正确答案 y j y_j yj 作为提示的一部分 ,再次引导模型生成一个能够"解释"或"推导出"这个正确答案的推理过程 r j r a t r_j^{rat} rjrat。
- ( r j r a t , y ^ j r a t ) ∼ M ( x j , hint = y j ∣ P ′ ) (r_j^{rat}, \hat{y}_j^{rat}) \sim M(x_j, \text{hint}=y_j | P') (rjrat,y^jrat)∼M(xj,hint=yj∣P′),其中 P ′ P' P′ 可能是包含答案提示格式的样本。
- 如果这个"事后诸葛亮"式的推理 y ^ j r a t \hat{y}_j^{rat} y^jrat 确实能导出 y j y_j yj,则将 ( x j , r j r a t , y j ) (x_j, r_j^{rat}, y_j) (xj,rjrat,yj) 加入训练集。
- 注意: 在微调时,这个"提示"信息(即正确答案 y j y_j yj)并不会包含在输入中,模型被训练得仿佛是它自己独立思考出 r j r a t r_j^{rat} rjrat 的。
这个"合理化"步骤,本质上是让模型学会 "向答案学习推理" ,从而攻克原本难以解决的难题,并扩大了有效训练数据的规模。
1.3. 数学视角的 STaR
论文指出,STaR 的过程可以视为一种对强化学习(RL)策略梯度目标的近似。
将模型 M M M 视为一个生成 ( r , y ^ ) (r, \hat{y}) (r,y^) 的策略。给定问题 x x x 和真实答案 y y y,我们可以定义一个奖励函数,例如指示函数 I ( y ^ = y ) \mathbb{I}(\hat{y} = y) I(y^=y),当模型生成的答案 y ^ \hat{y} y^ 与真实答案 y y y 相同时,奖励为 1,否则为 0。
目标是最大化期望奖励:
J ( M , X , Y ) = ∑ i E r i , y ^ i ∼ p M ( x i ) I ( y \^ i = y i ) J(M, X, Y) = \sum_i \mathbb{E}_{r_i, \hat{y}_i \sim p_M(x_i)} \\mathbb{I}(\\hat{y}_i = y_i) J(M,X,Y)=i∑Eri,y^i∼pM(xi)I(y\^i=yi)
其梯度可以写作:
∇ J ( M , X , Y ) = ∑ i E r i , y ^ i ∼ p M ( x i ) I ( y \^ i = y i ) ⋅ ∇ log p M ( y \^ i , r i ∣ x i ) \nabla J(M, X, Y) = \sum_i \mathbb{E}_{r_i, \hat{y}_i \sim p_M(x_i)} \\mathbb{I}(\\hat{y}_i = y_i) \\cdot \\nabla \\log p_M(\\hat{y}_i, r_i \| x_i) ∇J(M,X,Y)=i∑Eri,y^i∼pM(xi)I(y\^i=yi)⋅∇logpM(y\^i,ri∣xi)
STaR 的做法可以理解为:
- Greedy Decoding: 通过贪心解码(或低 temperature 采样)来近似采样 ( r i , y ^ i ) (r_i, \hat{y}_i) (ri,y^i),以减少方差(但可能引入偏差)。
- Filtering as Reward: I ( y ^ i = y i ) \mathbb{I}(\hat{y}_i = y_i) I(y^i=yi) 项使得只有导出正确答案的 ( r i , y ^ i ) (r_i, \hat{y}_i) (ri,y^i) 对梯度有贡献,这正是 STaR 中"筛选"步骤的体现。
- Supervised Fine-tuning: 对筛选出的样本进行微调,可以看作是在这个近似的策略梯度上进行多步优化。
"合理化"步骤则可以看作是从一个不同的、加入了提示(hint)的"教师"分布 p M ( r ∣ x , y ) p_M(r | x, y) pM(r∣x,y) 中采样高质量的轨迹,用于丰富训练数据,帮助模型探索更优的策略空间。
2. 算法流程
STaR 算法伪代码:
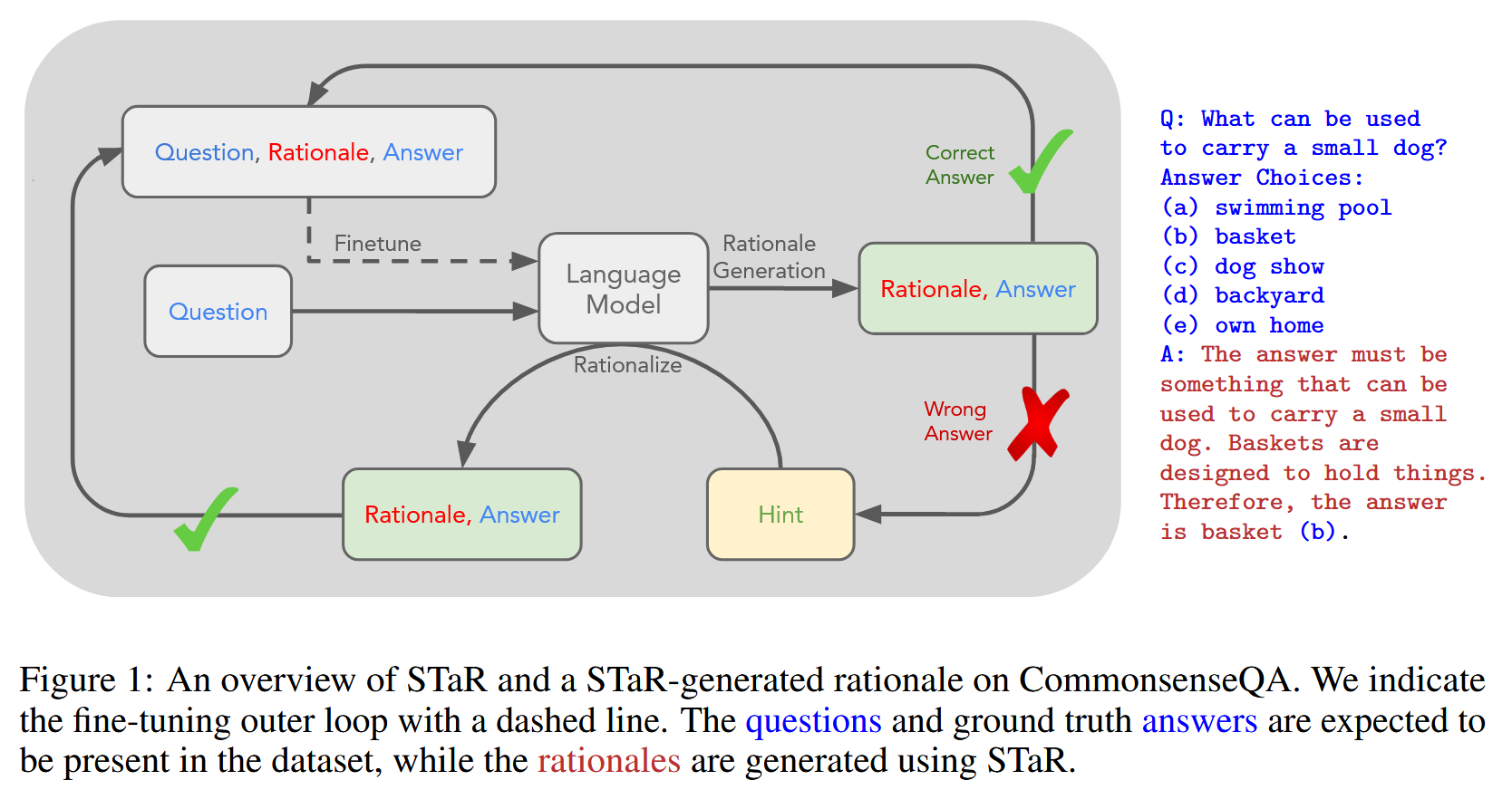
论文中给出了清晰的算法流程图(Figure 1)和伪代码(Algorithm 1)。我们可以将其逻辑概括如下:
Algorithm 1: STaR
输入:
- M pretrained M_{\text{pretrained}} Mpretrained: 预训练的大语言模型
- D = { ( x i , y i ) } i = 1 N D = \{(x_i, y_i)\}_{i=1}^N D={(xi,yi)}i=1N: 问题-答案数据集
- P few_shot P_{\text{few\_shot}} Pfew_shot: 少量带推理过程的示例
初始化:
M 0 ← M pretrained M_0 \leftarrow M_{\text{pretrained}} M0←Mpretrained // 复制原始模型
循环迭代 n = 1 n = 1 n=1 到 Max_Iterations \text{Max\_Iterations} Max_Iterations:
-
生成步骤 (Rationale Generation):
- 初始化生成的推理集合: G e n e r a t e d _ R a t i o n a l e s ← { } Generated\_Rationales \leftarrow \{\} Generated_Rationales←{}
- 对每个样本 ( x i , y i ) ∈ D (x_i, y_i) \in D (xi,yi)∈D:
- ( r gen i , y gen ^ i ) ← M n − 1 . generate ( prompt ( P few_shot , x i ) ) (r_{\text{gen}i}, y{\hat{\text{gen}}i}) \leftarrow M{n-1}.\text{generate}(\text{prompt}(P_{\text{few\_shot}}, x_i)) (rgeni,ygen^i)←Mn−1.generate(prompt(Pfew_shot,xi))
- 添加 ( x i , y i , r gen i , y gen ^ i ) (x_i, y_i, r_{\text{gen}i}, y{\hat{\text{gen}}_i}) (xi,yi,rgeni,ygen^i) 到 G e n e r a t e d _ R a t i o n a l e s Generated\_Rationales Generated_Rationales
-
生成推理过滤步骤:
- 初始化正确推理集合: D n correct ← { } D_n^{\text{correct}} \leftarrow \{\} Dncorrect←{}
- 对每个 ( x i , y i , r gen i , y gen ^ i ) ∈ G e n e r a t e d _ R a t i o n a l e s (x_i, y_i, r_{\text{gen}i}, y{\hat{\text{gen}}_i}) \in Generated\_Rationales (xi,yi,rgeni,ygen^i)∈Generated_Rationales:
- 若 y gen ^ i = y i y_{\hat{\text{gen}}_i} = y_i ygen^i=yi:
- 添加 ( x i , r gen i , y i ) (x_i, r_{\text{gen}_i}, y_i) (xi,rgeni,yi) 到 D n correct D_n^{\text{correct}} Dncorrect
- 若 y gen ^ i = y i y_{\hat{\text{gen}}_i} = y_i ygen^i=yi:
-
错误答案合理化步骤:
- 初始化合理化推理集合: R a t i o n a l i z e d _ R a t i o n a l e s ← { } Rationalized\_Rationales \leftarrow \{\} Rationalized_Rationales←{}
- 对每个 ( x i , y i , r gen i , y gen ^ i ) ∈ G e n e r a t e d _ R a t i o n a l e s (x_i, y_i, r_{\text{gen}i}, y{\hat{\text{gen}}_i}) \in Generated\_Rationales (xi,yi,rgeni,ygen^i)∈Generated_Rationales:
- 若 y gen ^ i ≠ y i y_{\hat{\text{gen}}_i} \neq y_i ygen^i=yi:
- ( r rat i , y rat ^ i ) ← M n − 1 . generate ( prompt ( P few_shot_with_hint , x i , hint = y i ) ) (r_{\text{rat}i}, y{\hat{\text{rat}}i}) \leftarrow M{n-1}.\text{generate}(\text{prompt}(P_{\text{few\_shot\_with\_hint}}, x_i, \text{hint}=y_i)) (rrati,yrat^i)←Mn−1.generate(prompt(Pfew_shot_with_hint,xi,hint=yi))
- 添加 ( x i , y i , r rat i , y rat ^ i ) (x_i, y_i, r_{\text{rat}i}, y{\hat{\text{rat}}_i}) (xi,yi,rrati,yrat^i) 到 R a t i o n a l i z e d _ R a t i o n a l e s Rationalized\_Rationales Rationalized_Rationales
- 若 y gen ^ i ≠ y i y_{\hat{\text{gen}}_i} \neq y_i ygen^i=yi:
-
合理化推理过滤步骤:
- 初始化合理化训练集: D n rationalized ← { } D_n^{\text{rationalized}} \leftarrow \{\} Dnrationalized←{}
- 对每个 ( x i , y i , r rat i , y rat ^ i ) ∈ R a t i o n a l i z e d _ R a t i o n a l e s (x_i, y_i, r_{\text{rat}i}, y{\hat{\text{rat}}_i}) \in Rationalized\_Rationales (xi,yi,rrati,yrat^i)∈Rationalized_Rationales:
- 若 y rat ^ i = y i y_{\hat{\text{rat}}_i} = y_i yrat^i=yi:
- 添加 ( x i , r rat i , y i ) (x_i, r_{\text{rat}_i}, y_i) (xi,rrati,yi) 到 D n rationalized D_n^{\text{rationalized}} Dnrationalized
- 若 y rat ^ i = y i y_{\hat{\text{rat}}_i} = y_i yrat^i=yi:
-
合并数据与微调:
- 合并训练集: D n train ← D n correct ∪ D n rationalized D_n^{\text{train}} \leftarrow D_n^{\text{correct}} \cup D_n^{\text{rationalized}} Dntrain←Dncorrect∪Dnrationalized
- 若 D n train = { } D_n^{\text{train}} = \{\} Dntrain={} 或 性能达到平台期:
- 终止迭代
- 微调模型: M n ← fine_tune ( M pretrained , D n train ) M_n \leftarrow \text{fine\tune}(M{\text{pretrained}}, D_n^{\text{train}}) Mn←fine_tune(Mpretrained,Dntrain)
- 关键: 每次从预训练模型微调,而非上一轮模型,避免过拟合
- 更新模型: M n − 1 ← M n M_{n-1} \leftarrow M_n Mn−1←Mn
输出: 基于验证性能选择最优模型 M n M_n Mn
3. 实验剖析
3.1. 参数与设置细节
- 基础模型 (Base Model): GPT-J (6B 参数 )。选择 GPT-J 是因为其开源且具备一定的推理能力基础。
- 迭代次数 (Iterations): 实验中通常运行到性能饱和为止。
- 训练步数 (Training Steps per Iteration): 初始迭代训练步数较少(如 40 步),后续迭代中逐步增加(如每轮增加 20%)。这种渐进式增加训练强度的方法,有助于模型在早期稳定学习,后期充分利用数据。
- Few-shot Prompts:
- Rationale Generation: 使用少量 ( 如 10 个 ) 固定的、高质量的 CoT 示例。
- Rationalization: 使用类似的 CoT 示例,但格式上会明确包含"正确答案提示"。例如,在 CommonsenseQA (CQA) 的例子中(Figure 2),提示是
(b) grocery cart (CORRECT)。
- 数据集 (Datasets):
- Arithmetic ( 算术 ): n 位数加法。评估模型对符号操作和步骤记忆的能力。
- CommonsenseQA (CQA): 常识问答选择题。评估自然语言理解和常识推理。
- GSM8K (Grade School Math): 小学数学应用题。评估结合算术和文本理解的复杂推理。
- 关键trick:从预训练模型重新微调: 每次迭代收集到新的训练数据后,STaR 从原始的预训练模型 M p r e t r a i n e d M_pretrained Mpretrained 开始微调 ,而不是在上一次迭代的模型 M n − 1 M_{n-1} Mn−1 基础上继续微调。这可以有效防止灾难性遗忘和过拟合到特定迭代生成的数据噪声。
3.2. 实验结果亮点:
-
显著优于基线:
- Arithmetic: STaR 能够从几乎为零的 few-shot 准确率(2 位数加法 < 1%)通过迭代学习达到很高的准确率(16 次迭代后整体 89.5%)。对比直接在无推理过程的 10,000 个样本上微调(76.3%),优势明显。
- CommonsenseQA (CQA):
- STaR (72.5% 准确率 ) 显著超过 few-shot CoT GPT-J (36.6%) 和直接微调 GPT-J (60.0%)。
- STaR (GPT-J 6B) 的性能逼近了在完整数据集上微调的 GPT-3 (175B,论文中提到的是 30x 更大的模型,应指 PaLM 或类似规模,CQA 上的 GPT-3 Finetuned 结果为 73.0%)。这表明 STaR 能够有效地从小模型中"榨取"出强大的推理能力。
- Rationalization 的作用: 在 CQA 上,加入 Rationalization 后,准确率从 68.8% (STaR without rationalization) 提升到 72.5%,证明了其在解决难题和提升上限方面的价值。
- GSM8K: STaR (10.7%) 同样远超 few-shot CoT GPT-J (3.1%) 和直接微调 GPT-J (5.8%)。
-
Rationalization 的加速与提升效果:
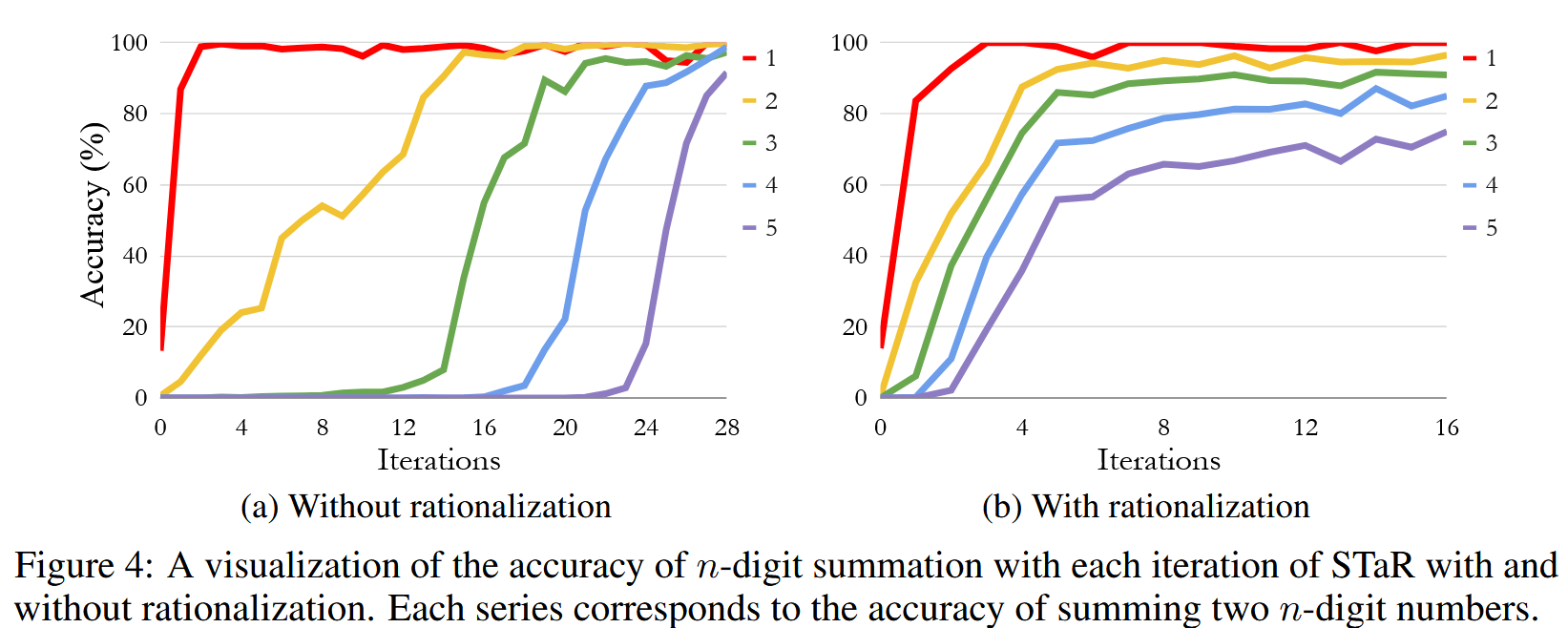
- Arithmetic ( Figure 4): 有 Rationalization 的 STaR ( Figure 4b) 相比无 Rationalization ( Figure 4a),在早期迭代中对多位数加法的学习速度更快,性能提升更平滑。无 Rationalization 的版本则呈现阶梯式提升,即模型通常在掌握 (n-1) 位数加法后才能较好地学习 n 位数加法。
- CommonsenseQA: Rationalization 带来了约 3.7% 的绝对提升。
-
数据效率: STaR 通常只使用了训练集的一部分(例如 CQA 上约 86.7% 的数据,其中 8.5% 来自 Rationalization),但取得了比使用完整数据集直接微调更好的性能。这说明 STaR 生成的 CoT 数据质量较高。
-
推理质量的提升 (Case Study & Human Evaluation on CQA):
- Case Study: 展示了 STaR 能够生成比 few-shot CoT 更合理、更连贯的推理过程,即使原始 few-shot 也能答对问题。(论文提到 Figure 7 展示, 但是作者可能忘了放这张图)
- Human Evaluation: 众包评估者认为 STaR 生成的推理过程比 few-shot CoT 生成的推理过程更具说服力(30% more likely to rank STaR higher, p=0.039)。甚至,STaR 生成的推理比一些人工标注的推理更受青睐(74% more likely, p < 0.001),这可能反映了众包标注本身的质量波动,但也侧面印证了 STaR 生成推理的潜力。
3.4. 对实验结果的初步思考
-
STaR 的成功,很大程度上依赖于基础 LLM 已具备一定的"潜在"推理能力。Few-shot CoT 能够激活这种能力,而 STaR 通过迭代微调,将这种"潜在"能力强化并泛化。
-
Rationalization 机制非常精妙,它相当于给模型提供了一个 "目标导向的逆向工程" 机会,让模型思考"为了得到这个答案,我应该如何推理?"
-
"从头微调"策略是控制训练稳定性和避免过拟合的关键。
4. 挑战、局限性与未来展望
4.1. STaR 面临的挑战与局限性
-
对初始 Few-shot 样本的依赖与敏感性:
- STaR 的启动依赖于少量高质量的 CoT 样本。这些样本的质量和风格可能会显著影响后续生成的推理过程的质量和多样性。
- 如果初始样本包含偏见或不完善的推理模式,STaR 可能会放大这些问题。
-
"正确答案但错误推理"的问题 (Filtering Imperfection):
- STaR 的核心筛选机制是基于最终答案的正确性。这意味着,如果模型通过一个错误的、不相关的或者仅仅是"碰巧"正确的推理过程得到了正确答案,这样的样本依然会被用于微调。
- 在多项选择题(如 CQA)中,随机猜对的概率不低 (20%),这使得该问题尤为突出。虽然论文提到一些简单启发式方法(如语义相似度)可以将随机猜测提升到约 30%,但 STaR 的目标是学习真正的推理。
- 这种"噪声"数据可能会污染训练集,限制模型学习到真正鲁棒和泛化的推理能力。
-
Rationalization 的提示工程:
- 如何设计"合理化"步骤中的提示(即如何将正确答案作为 hint 融入问题)可能并非易事,尤其对于更复杂的任务结构。
- 论文中对算术和 CQA 的提示方式相对直接,但其普适性有待验证。
-
计算成本:
- 迭代生成、筛选和微调的过程计算成本较高。尽管比标注大规模 CoT 数据集便宜,但对于资源受限的研究者而言仍是一个考量。
- 每次都从预训练模型重新微调,虽然能避免过拟合,但也增加了训练时间。
-
温度参数 (Temperature) 的影响:
- 论文提到,尝试使用更高的温度进行采样以增加数据多样性,结果适得其反,导致模型性能下降,尤其是在结构化任务(如算术)中,生成的"思维链"会变得无意义。
- 这表明 STaR 依赖于模型在低温度下生成相对"自信"且连贯的推理。如何平衡探索(高温度)和利用(低温度)仍然是一个开放问题。
-
可解释性与忠实度 (Faithfulness):
- 虽然 STaR 生成的推理看起来更合理,但我们无法保证这些推理过程真正反映了模型内部的"思考"过程。模型可能只是学会了生成"看起来像那么回事"的文本。
- 这是所有基于生成 CoT 方法的共同挑战。
-
偏见放大 (Bias Amplification):
- 如果原始数据集或 few-shot 样本中存在偏见(例如,CQA 中的性别偏见),STaR 的迭代学习过程可能会放大这些偏见,因为它倾向于强化那些能"成功"解决训练集问题的模式,即使这些模式是基于偏见的。
- 论文提到了一些初步的积极迹象(如模型在性别无关问题中似乎忽略了性别信息),但这需要更深入的研究。
-
对小模型和简单任务的适用性:
- STaR 的成功依赖于基础模型具备一定的 few-shot 推理能力。对于非常小的模型或无法通过 few-shot 激活推理能力的简单任务,STaR 可能难以启动。论文提到 GPT-2 在算术任务上无法通过 STaR 自举。
- 对于正确率本身就很高(例如二元决策)的任务,错误答案的样本过少,Rationalization 的作用会减弱。
4.2. STaR 的深远意义与未来展望
-
迈向模型自我改进的重要一步: STaR 最核心的贡献在于展示了一种让 LLM 通过自身的生成和推理来学习和改进自身推理能力的有效途径。这为实现更自主、更少依赖人工监督的 AI 系统提供了新的思路。
-
数据高效的推理能力获取: STaR 证明了可以利用大量无标注数据和少量有标注数据,以一种自举的方式生成高质量的推理训练数据,这对于解决许多领域标注数据稀缺的问题具有重要价值。
-
对"思维链"研究的推动: STaR 强调了推理过程本身作为学习信号的重要性。未来的研究可以探索更精细化的推理过程评估方法(超越最终答案的正确性),例如引入 token 级验证器(如论文 9 Cobbe et al. 中用于数学问题的验证器)。
-
结合强化学习的潜力: 论文中已将 STaR 与 RL 的策略梯度联系起来。未来可以探索更直接的 RL 方法,例如使用模型自身生成的推理作为轨迹,并设计更复杂的奖励函数来指导学习,或者结合基于模型的 RL 来规划推理步骤。
-
探索更优的 Rationalization 机制:
- 如何更有效地从"失败"中学习?除了提供正确答案,是否可以提供更细致的反馈或引导?
- 研究不同类型的"提示"对 Rationalization 效果的影响。
-
处理"正确答案但错误推理":
- 开发自动检测或过滤不合理推理的方法。
- 引入"负面样本"学习,即明确告诉模型哪些推理是错误的。
-
跨任务和跨领域泛化: STaR 在特定任务上学习到的推理能力,能否更好地泛化到新的、未见过的任务或领域?
-
与人类反馈的结合: STaR 的迭代过程可以与人类反馈回路(Human-in-the-loop)相结合,让人类专家在关键的筛选或 Rationalization 步骤提供指导,进一步提升学习效率和推理质量。
4.3. 总结
STaR 是一项具有开创性的工作,它巧妙地利用了大型语言模型自身的生成能力,通过迭代式的"生成 - 筛选(含合理化)- 学习"循环,实现了在复杂推理任务上显著的性能提升,并且在某些任务上逼近了远大于自身规模的模型。它不仅为解决 CoT 数据获取难题提供了有效方案,更为重要的是,它展示了语言模型 "自我教育"和"自我进化" 的巨大潜力。尽管存在一些挑战和局限,STaR 无疑为 LLM 的能力边界探索和未来发展开辟了新的道路。