7.网络优化与正则化
文章目录
- 7.网络优化与正则化
-
- 7.1神经网络优化的特点
- [7.2 优化算法改进](#7.2 优化算法改进)
- [7.3 动态学习率](#7.3 动态学习率)
- [7.4 梯度方向优化](#7.4 梯度方向优化)
- [7.5 参数初始化](#7.5 参数初始化)
- [7.6 数据预处理](#7.6 数据预处理)
- [7.7 逐层规范化](#7.7 逐层规范化)
- [7.8 超参数优化](#7.8 超参数优化)
- [7.9 正则化](#7.9 正则化)
- [7.10 暂退法](#7.10 暂退法)
- [7.11 l1和l2正则化](#7.11 l1和l2正则化)
- [7.12 数据增强](#7.12 数据增强)


7.1神经网络优化的特点



所以找个平坦最小值就好了,不一定需要全局最小值


7.2 优化算法改进





7.3 动态学习率




总体趋势还是减少的。时不时变大是为了找到更好的局部最优



7.4 梯度方向优化

效果比随机梯度要好



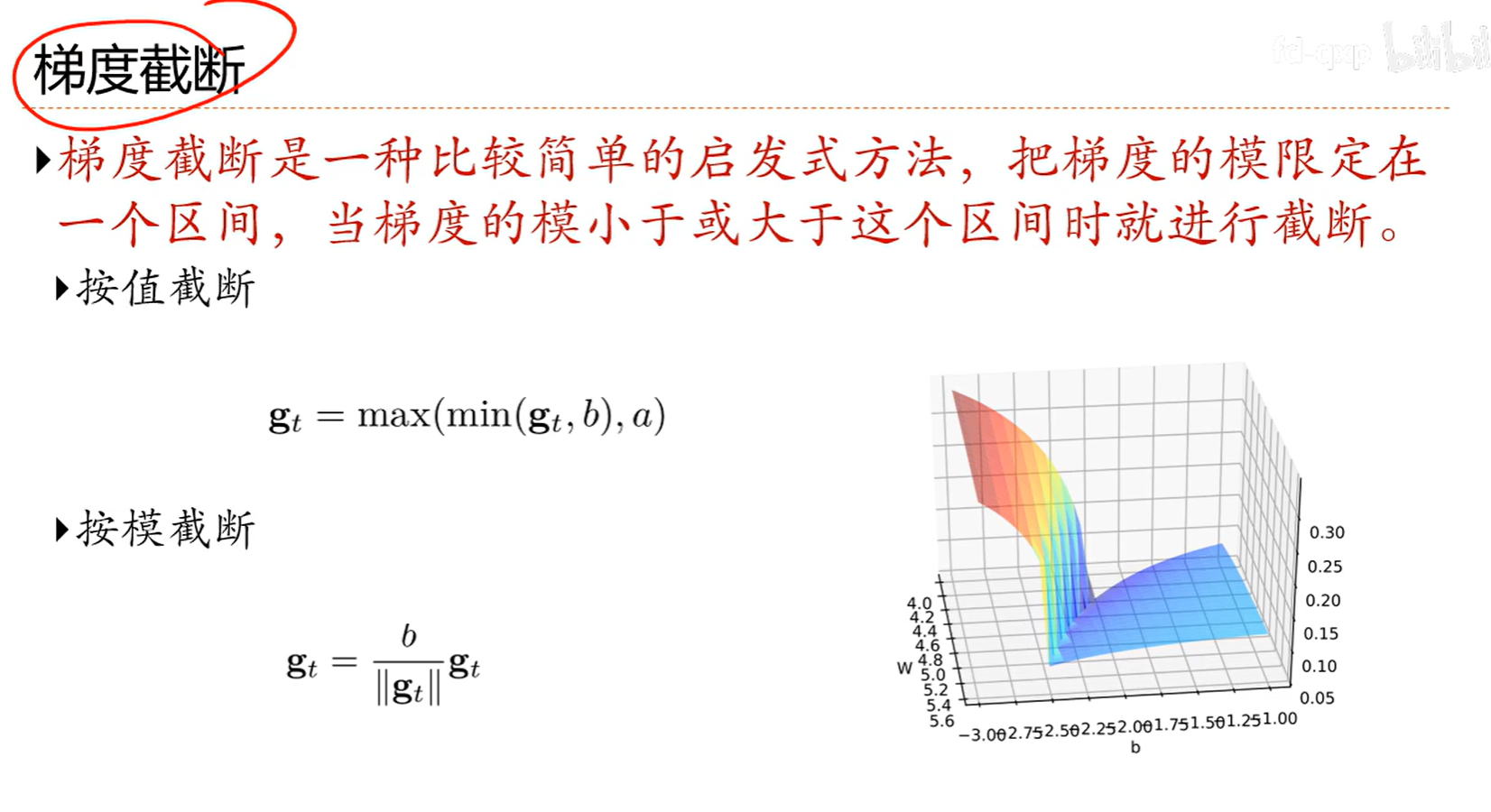

7.5 参数初始化





上图通常用在循环网络中
7.6 数据预处理

问题就是会对参数初始化产生一定的影响,也会对优化产生一定的影响


标准差为0的数据没啥意义,直接就扔了
7.7 逐层规范化




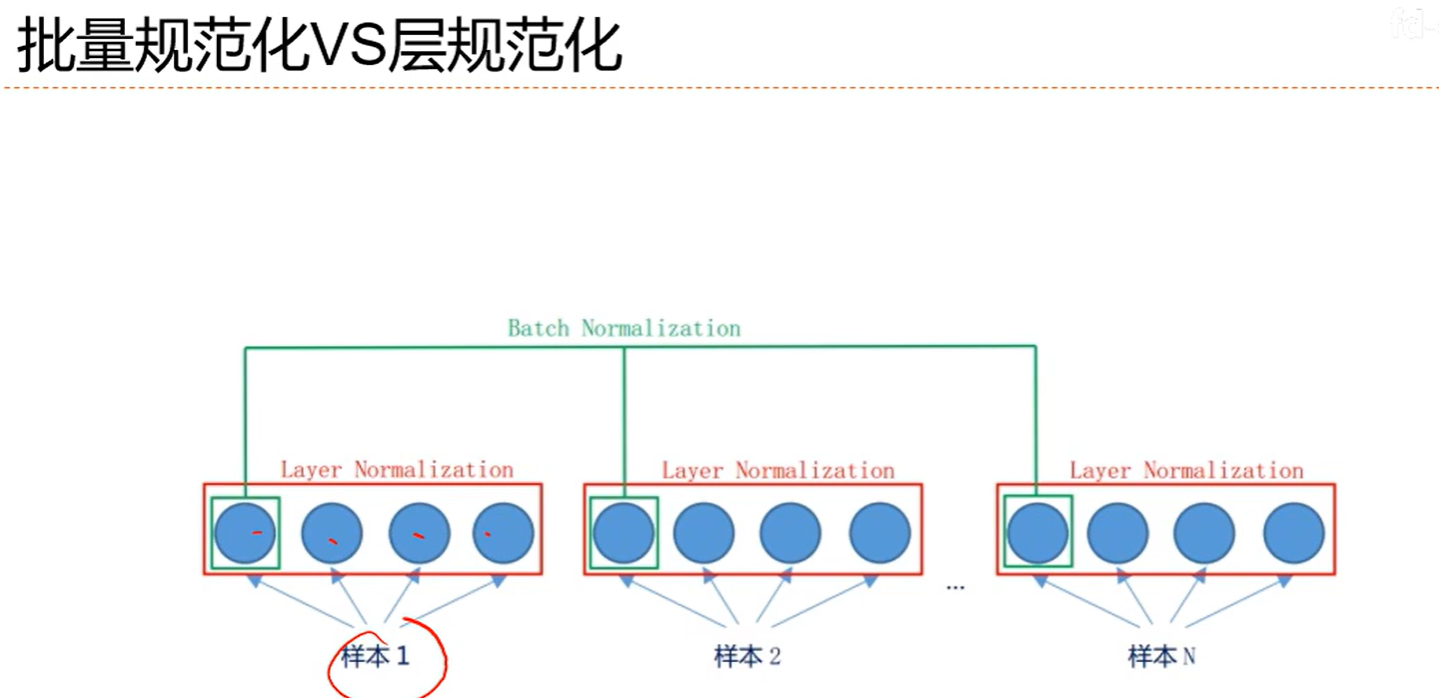

7.8 超参数优化



7.9 正则化





7.10 暂退法
可以提高网络的泛化能力




7.11 l1和l2正则化




7.12 数据增强
可以增强模型泛化能力


