你有没有想过,一个拥有700亿参数的大模型,居然可以在一台普通笔记本上运行?
这不是科幻,而是模型量化带来的现实。
曾经,大模型只能运行在动辄几十万元的GPU集群上,普通人望尘莫及。但现在,借助一种叫"模型量化 "的技术,我们已经能让像 Llama 3-70B、Qwen-72B 这样的庞然大物,在一台MacBook Air上安静地推理、对话、写代码。
这背后,靠的不是硬件升级,而是一场精妙的"减肥手术"------给模型瘦身,却不让它"失智"。
今天,我们就来揭开这场"AI减肥术"的神秘面纱:
从原理到工具,从INT4到GGUF,带你一步步把大模型塞进你的笔记本。
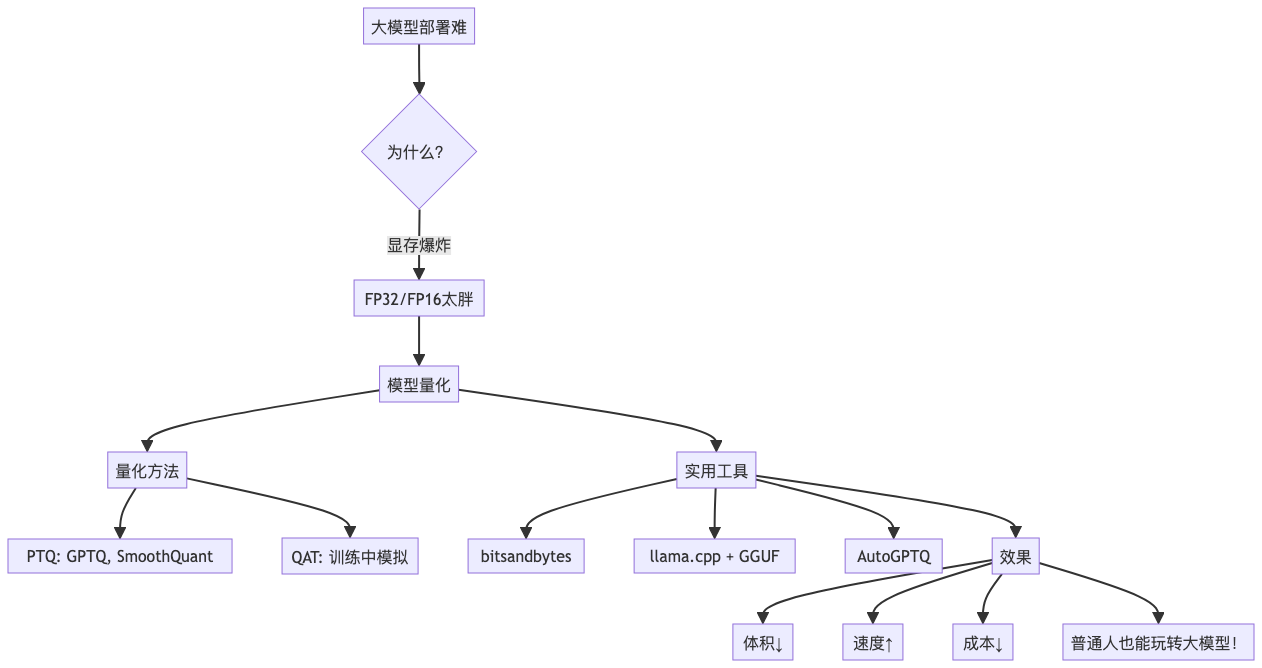
一、为什么大模型"胖"得难以部署?
先来看一组数据:
|----------------|------------------------|--------------|
| 模型精度 | 参数大小(以70B为例) | 所需显存 |
| FP32(32位浮点) | 70B × 4字节 ≈ 280GB | ❌ 几乎无法部署 |
| FP16/BF16(半精度) | 70B × 2字节 ≈ 140GB | 需要多张A100 |
| INT8(8位整数) | 70B × 1字节 ≈ 70GB | 高端显卡勉强运行 |
| INT4(4位整数) | 70B × 0.5字节 ≈ 35GB | 消费级显卡或CPU可运行 |
看到没?从FP16到INT4,模型体积直接压缩75%!
但这还不止是"省空间"。更关键的是------显存占用下降,推理门槛骤降。
原本需要百万级算力集群的任务,现在你家的笔记本也能试试了。
二、什么是模型量化?从FP32到INT4的"减肥之路"
模型量化(Model Quantization),本质上就是一场"数据降维"。
我们知道,神经网络中的权重和激活值,默认是用 32位浮点数(FP32) 存储的。它们精度高,但也"占地"。
量化做的,就是把这些高精度数值,映射到更低精度的整数表示,比如:
- FP32 → FP16(半精度)
- FP32 → INT8(8位整数)
- FP32 → INT4(4位整数)
🧠 举个通俗例子:
原来模型记账用的是"元角分厘"四位小数(FP32),现在改成只记"元和角"(INT8),甚至只记"整数元"(INT4)。虽然损失了点细节,但整体账目依然对得上。
量化压缩原理图
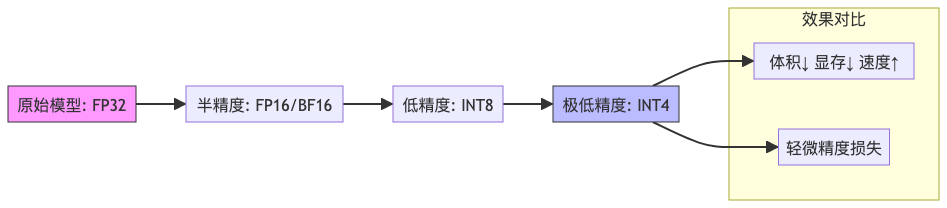
这个过程就像压缩照片:JPG格式虽然有损,但你看不出太大区别,文件却小了很多。
三、量化方式大解析:对称 vs 非对称,Tensor-wise vs Group-wise
不同的"减肥方式",效果大不相同。我们来看看常见的量化策略:
1. 对称量化 vs 非对称量化
|-----------|------------------|-------------|
| 类型 | 特点 | 适用场景 |
| 对称量化 | 数值范围关于0对称,仅用缩放因子 | 计算快,适合GPU |
| 非对称量化 | 支持偏移,能更好拟合非对称分布 | 精度更高,常用于激活值 |
🔍 举例:
如果一组权重集中在 [0.1, 0.9],对称量化会浪费大量表示空间;非对称可以"平移+缩放",更高效利用4位空间。
2. Tensor-wise vs Group-wise
|-----------------|--------------|-----------|--------|
| 策略 | 说明 | 优点 | 缺点 |
| Tensor-wise | 整个张量共用一个缩放因子 | 简单高效 | 精度损失大 |
| Group-wise | 将权重分组,每组独立量化 | 更精细,精度保持好 | 计算开销略高 |
✅ 当前主流(如GPTQ、SmoothQuant)都采用 Group-wise + 非对称 组合,在压缩与精度间取得平衡。
四、主流量化方法一览
1. PTQ(Post-Training Quantization,训练后量化)
✅ 无需重新训练,直接压缩已有模型
- GPTQ:逐层量化,使用少量校准数据优化误差,支持INT4。
- SmoothQuant:通过"通道平滑"技术,将激活值的极端值分散,使INT8量化更稳定。
- AWQ(Activation-aware Weight Quantization):保护"重要权重",提升低比特下的推理质量。
🛠️ 适合大多数用户:下载模型 → 一键量化 → 推理。
2. QAT(Quantization-Aware Training,量化感知训练)
🔁 在训练时模拟量化过程,让模型"习惯低精度"
- 更高精度保持
- 但需要原始训练代码和数据
- 成本高,适合大厂定制模型
💡 类比:运动员提前适应高原训练,比赛时表现更稳。
五、实战工具推荐:谁让你的笔记本跑起70B?
别再以为只有服务器才能玩大模型。以下工具,已让无数开发者在本地跑起LLaMA、Qwen、ChatGLM。
1. bitsandbytes ------ 4-bit加载神器(GPU)
-
支持Hugging Face模型 4-bit 和 8-bit 加载
-
集成简单,一行代码启用:
from transformers import BitsAndBytesConfig
import torchbnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B", quantization_config=bnb_config)
⚡ 效果:显存占用减少75%,适合RTX 3090/4090等消费级显卡。
2. llama.cpp ------ CPU也能跑大模型!
- 纯C/C++实现,支持 GGUF格式 模型
- 可在Mac M1/M2、Windows笔记本上运行INT4模型
- 支持Metal、CUDA、Vulkan加速
🧩 典型流程:
LLaMA模型 → 转为GGUF格式 → 用llama.cpp加载 → CPU推理
./main -m ./models/llama-3-8b-Q4_K_M.gguf -p "你是谁?" -n 128✅ 实测:M2 MacBook Air 上运行 Llama-3-8B-INT4,响应流畅,风扇都不怎么转。
3. AutoGPTQ ------ 一键生成GPTQ量化模型
-
支持Hugging Face生态
-
可将FP16模型量化为INT4,并导出为GGUF或HF格式
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized("TheBloke/Llama-3-8B-GPTQ", device="cuda")
🎯 适合想自己量化模型的进阶用户。
六、效果对比:FP16 vs INT8 vs INT4
我们以 Llama-3-8B 为例,测试不同量化级别的表现:
|------|----------|----------------|-------------|---------|
| 精度 | 显存占用 | 推理速度(tokens/s) | 任务准确率(MMLU) | 是否推荐 |
| FP16 | ~14 GB | 45 | 68.5% | ❌ 仅训练 |
| INT8 | ~8 GB | 52 | 67.9% | ✅ 平衡选择 |
| INT4 | ~4.5 GB | 60 | 66.1% | ✅✅ 强烈推荐 |
🔍 结论:INT4几乎无感降级,但资源消耗砍半!
七、总结:不是模型太大,是你没学会"减肥"
🔔 最后送你一句金句:
"不是模型太大,是你没学会'减肥'。"
当你还在为买不起A100发愁时,有人已经用INT4 + GGUF,在咖啡馆里跑起了70B模型。
技术的民主化,从来不是靠堆硬件,而是靠聪明的方法。
现在,你也有机会成为那个"轻装上阵"的人。
下一步行动建议:
- 安装
llama.cpp,试试在本地运行Llama-3-8B-Q4_K_M.gguf - 用
bitsandbytes在Colab上加载一个4-bit模型 - 关注 TheBloke(Hugging Face)------ 他把几乎所有主流模型都量化好了,免费下载!
参考资料:
如果你觉得这篇文章有帮助,欢迎点赞、转发,让更多人看懂AI背后的逻辑