
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
中间件就像是连接各个系统组件的神经网络,它不仅承担着数据传输 的重任,更是系统稳定性、可扩展性和高可用性的关键保障。
在我参与的众多项目中,从电商平台的订单处理系统到金融机构的实时交易平台,中间件都扮演着不可或缺的角色。它们如同隐形的桥梁,让原本孤立的服务能够协同工作,形成一个有机的整体。无论是消息队列中间件 如RabbitMQ、Apache Kafka,还是数据库中间件 如MyCAT、Sharding-JDBC,亦或是缓存中间件Redis、Memcached,每一种中间件都有其独特的应用场景和技术特点。
通过多年的实践经验,我发现中间件的选型和架构设计往往决定了整个系统的性能上限。一个设计良好的中间件架构能够让系统在面对高并发、大数据量的挑战时游刃有余,而错误的选择则可能成为系统的瓶颈。本文将从中间件的核心概念出发,深入探讨其分类、设计原则、实现技术,并结合实际案例分析如何在生产环境中构建高性能的中间件架构。我希望通过这篇文章,能够帮助更多的开发者和架构师掌握中间件的精髓,在技术的星海中找到属于自己的航向。
1. 中间件概述与核心价值
1.1 中间件的本质定义
中间件(Middleware)是位于操作系统和应用程序之间的软件层,它为分布式应用提供通信、数据管理、消息传递等基础服务。从技术角度来看,中间件实现了系统间的解耦,提供了标准化的接口和协议。
java
/**
* 中间件抽象接口定义
* 展示中间件的核心职责和标准化接口
*/
public interface Middleware {
/**
* 初始化中间件服务
* @param config 配置参数
* @return 初始化结果
*/
boolean initialize(MiddlewareConfig config);
/**
* 处理请求的核心方法
* @param request 请求对象
* @param response 响应对象
* @param next 下一个处理器
*/
void handle(Request request, Response response, NextHandler next);
/**
* 获取中间件状态信息
* @return 状态信息
*/
MiddlewareStatus getStatus();
/**
* 优雅关闭中间件服务
*/
void shutdown();
}这段代码定义了中间件的标准接口,其中handle方法体现了中间件的链式处理特性,initialize和shutdown方法确保了生命周期管理的完整性。
1.2 中间件分类体系
根据功能特性和应用场景,中间件可以分为以下几个主要类别:
中间件分类体系 通信中间件 数据中间件 应用服务器中间件 集成中间件 消息队列
RabbitMQ/Kafka RPC框架
Dubbo/gRPC API网关
Kong/Zuul 数据库中间件
MyCAT/Sharding-JDBC 缓存中间件
Redis/Memcached 搜索中间件
Elasticsearch/Solr Web服务器
Tomcat/Jetty 应用容器
Spring Boot/Quarkus ESB企业服务总线 工作流引擎
Activiti/Camunda
图1:中间件分类体系架构图
2. 消息中间件深度解析
2.1 消息队列核心机制
消息中间件是分布式系统中最常用的组件之一,它通过异步消息传递实现系统解耦。以下是一个基于Spring Boot的消息生产者实现:
java
/**
* 高性能消息生产者实现
* 支持批量发送、事务保证、失败重试
*/
@Component
@Slf4j
public class MessageProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 发送单条消息
* @param exchange 交换机名称
* @param routingKey 路由键
* @param message 消息内容
*/
public void sendMessage(String exchange, String routingKey, Object message) {
try {
// 消息唯一ID生成
String messageId = UUID.randomUUID().toString();
// 构建消息属性
MessageProperties properties = new MessageProperties();
properties.setMessageId(messageId);
properties.setTimestamp(new Date());
properties.setDeliveryMode(MessageDeliveryMode.PERSISTENT);
// 序列化消息
String jsonMessage = JSON.toJSONString(message);
Message msg = new Message(jsonMessage.getBytes(), properties);
// 发送前缓存消息(用于重试机制)
cacheMessage(messageId, exchange, routingKey, message);
// 发送消息
rabbitTemplate.send(exchange, routingKey, msg);
log.info("消息发送成功: messageId={}, exchange={}, routingKey={}",
messageId, exchange, routingKey);
} catch (Exception e) {
log.error("消息发送失败: exchange={}, routingKey={}, error={}",
exchange, routingKey, e.getMessage());
throw new MessageSendException("消息发送失败", e);
}
}
/**
* 批量发送消息(提高吞吐量)
*/
@Async("messageExecutor")
public CompletableFuture<Void> batchSendMessages(List<MessageDTO> messages) {
return CompletableFuture.runAsync(() -> {
messages.parallelStream().forEach(msg -> {
sendMessage(msg.getExchange(), msg.getRoutingKey(), msg.getPayload());
});
});
}
/**
* 缓存消息用于重试机制
*/
private void cacheMessage(String messageId, String exchange,
String routingKey, Object message) {
MessageCache cache = MessageCache.builder()
.messageId(messageId)
.exchange(exchange)
.routingKey(routingKey)
.payload(message)
.createTime(System.currentTimeMillis())
.build();
redisTemplate.opsForValue().set(
"message:cache:" + messageId,
cache,
Duration.ofHours(24)
);
}
}这个生产者实现了消息的可靠发送,包括消息缓存、批量处理和异步发送等关键特性。
2.2 消息消费者设计模式
java
/**
* 高可用消息消费者实现
* 支持幂等性保证、死信处理、限流控制
*/
@Component
@RabbitListener(queues = "${app.queue.order}")
@Slf4j
public class OrderMessageConsumer {
@Autowired
private OrderService orderService;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 处理订单消息
* 实现幂等性和异常处理
*/
@RabbitHandler
@Retryable(value = {Exception.class}, maxAttempts = 3, backoff = @Backoff(delay = 1000))
public void handleOrderMessage(@Payload String message,
@Header Map<String, Object> headers,
Channel channel,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag) {
String messageId = (String) headers.get("messageId");
try {
// 幂等性检查
if (isMessageProcessed(messageId)) {
log.info("消息已处理,跳过: messageId={}", messageId);
channel.basicAck(deliveryTag, false);
return;
}
// 解析消息
OrderMessage orderMsg = JSON.parseObject(message, OrderMessage.class);
// 业务处理
processOrder(orderMsg);
// 标记消息已处理
markMessageProcessed(messageId);
// 手动确认消息
channel.basicAck(deliveryTag, false);
log.info("订单消息处理成功: messageId={}, orderId={}",
messageId, orderMsg.getOrderId());
} catch (BusinessException e) {
// 业务异常,直接拒绝消息
log.error("业务处理异常: messageId={}, error={}", messageId, e.getMessage());
channel.basicReject(deliveryTag, false);
} catch (Exception e) {
// 系统异常,重试处理
log.error("系统异常,消息重试: messageId={}, error={}", messageId, e.getMessage());
channel.basicNack(deliveryTag, false, true);
}
}
/**
* 检查消息是否已处理(幂等性保证)
*/
private boolean isMessageProcessed(String messageId) {
return redisTemplate.hasKey("processed:message:" + messageId);
}
/**
* 标记消息已处理
*/
private void markMessageProcessed(String messageId) {
redisTemplate.opsForValue().set(
"processed:message:" + messageId,
true,
Duration.ofDays(7)
);
}
/**
* 处理订单业务逻辑
*/
@Transactional(rollbackFor = Exception.class)
private void processOrder(OrderMessage orderMsg) {
// 订单状态更新
orderService.updateOrderStatus(orderMsg.getOrderId(), orderMsg.getStatus());
// 库存扣减
if (OrderStatus.PAID.equals(orderMsg.getStatus())) {
orderService.deductInventory(orderMsg.getOrderId());
}
// 发送通知
orderService.sendNotification(orderMsg);
}
}消费者实现了完整的消息处理流程,包括幂等性保证、异常处理和事务管理。
3. 数据中间件架构设计
3.1 分库分表中间件实现
数据中间件解决了大数据量场景下的存储和查询问题。以下是一个分库分表路由器的实现:
java
/**
* 智能分库分表路由器
* 支持多种分片策略和动态扩容
*/
@Component
@Slf4j
public class ShardingRouter {
private final Map<String, DataSource> dataSourceMap = new ConcurrentHashMap<>();
private final ShardingStrategy shardingStrategy;
public ShardingRouter(ShardingStrategy shardingStrategy) {
this.shardingStrategy = shardingStrategy;
initializeDataSources();
}
/**
* 根据分片键路由到具体数据源
* @param shardingKey 分片键
* @param tableName 表名
* @return 路由结果
*/
public RouteResult route(String shardingKey, String tableName) {
// 计算数据库分片
int dbIndex = shardingStrategy.calculateDbShard(shardingKey);
String dbKey = "db_" + dbIndex;
// 计算表分片
int tableIndex = shardingStrategy.calculateTableShard(shardingKey);
String actualTableName = tableName + "_" + tableIndex;
// 获取数据源
DataSource dataSource = dataSourceMap.get(dbKey);
if (dataSource == null) {
throw new ShardingException("数据源不存在: " + dbKey);
}
return RouteResult.builder()
.dataSource(dataSource)
.tableName(actualTableName)
.dbIndex(dbIndex)
.tableIndex(tableIndex)
.build();
}
/**
* 批量路由(用于跨分片查询)
*/
public List<RouteResult> batchRoute(List<String> shardingKeys, String tableName) {
return shardingKeys.stream()
.map(key -> route(key, tableName))
.collect(Collectors.toList());
}
/**
* 初始化数据源配置
*/
private void initializeDataSources() {
// 从配置中心获取数据源配置
List<DataSourceConfig> configs = getDataSourceConfigs();
configs.forEach(config -> {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(config.getUrl());
dataSource.setUsername(config.getUsername());
dataSource.setPassword(config.getPassword());
dataSource.setMaximumPoolSize(config.getMaxPoolSize());
dataSource.setMinimumIdle(config.getMinIdle());
dataSource.setConnectionTimeout(config.getConnectionTimeout());
dataSourceMap.put(config.getName(), dataSource);
log.info("数据源初始化完成: {}", config.getName());
});
}
}3.2 分片策略实现
java
/**
* 一致性哈希分片策略
* 支持动态扩容和数据迁移
*/
@Component
public class ConsistentHashShardingStrategy implements ShardingStrategy {
private final TreeMap<Long, Integer> hashRing = new TreeMap<>();
private final int virtualNodes = 150; // 虚拟节点数量
private final int dbCount;
private final int tableCount;
public ConsistentHashShardingStrategy(@Value("${sharding.db.count}") int dbCount,
@Value("${sharding.table.count}") int tableCount) {
this.dbCount = dbCount;
this.tableCount = tableCount;
initializeHashRing();
}
@Override
public int calculateDbShard(String shardingKey) {
long hash = hash(shardingKey);
Map.Entry<Long, Integer> entry = hashRing.ceilingEntry(hash);
if (entry == null) {
entry = hashRing.firstEntry();
}
return entry.getValue() % dbCount;
}
@Override
public int calculateTableShard(String shardingKey) {
// 使用不同的哈希算法避免热点
long hash = hash(shardingKey + "_table");
return (int) (Math.abs(hash) % tableCount);
}
/**
* 初始化哈希环
*/
private void initializeHashRing() {
for (int i = 0; i < dbCount; i++) {
for (int j = 0; j < virtualNodes; j++) {
String virtualNodeName = "db_" + i + "_virtual_" + j;
long hash = hash(virtualNodeName);
hashRing.put(hash, i);
}
}
log.info("哈希环初始化完成,数据库数量: {}, 虚拟节点数量: {}",
dbCount, virtualNodes);
}
/**
* 一致性哈希算法
*/
private long hash(String key) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5算法不可用", e);
}
byte[] digest = md5.digest(key.getBytes(StandardCharsets.UTF_8));
long hash = 0;
for (int i = 0; i < 4; i++) {
hash <<= 8;
hash |= ((int) digest[i]) & 0xFF;
}
return hash;
}
}这个分片策略使用一致性哈希算法,能够在扩容时最小化数据迁移量。
4. 中间件性能优化策略
4.1 连接池优化配置
客户端应用 连接池管理器 性能监控 数据库集群 请求数据库连接 记录连接请求 返回可用连接 更新活跃连接数 等待连接释放 返回连接(超时检查) alt 连接池有空闲连接 连接池已满 执行SQL查询 返回查询结果 释放连接 更新连接状态 性能指标统计 监控指标包括: - 连接获取时间 - 连接使用率 - 慢查询统计 - 异常连接数 客户端应用 连接池管理器 性能监控 数据库集群
图2:数据库连接池管理时序图
4.2 缓存中间件优化
java
/**
* 多级缓存管理器
* 实现L1本地缓存 + L2分布式缓存的架构
*/
@Component
@Slf4j
public class MultiLevelCacheManager {
private final Cache<String, Object> localCache;
private final RedisTemplate<String, Object> redisTemplate;
private final CacheMetrics cacheMetrics;
public MultiLevelCacheManager(RedisTemplate<String, Object> redisTemplate,
CacheMetrics cacheMetrics) {
this.redisTemplate = redisTemplate;
this.cacheMetrics = cacheMetrics;
// 配置本地缓存
this.localCache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(Duration.ofMinutes(10))
.expireAfterAccess(Duration.ofMinutes(5))
.recordStats()
.removalListener(this::onRemoval)
.build();
}
/**
* 获取缓存数据
* 优先从L1缓存获取,未命中则查询L2缓存
*/
public <T> T get(String key, Class<T> type, Supplier<T> dataLoader) {
// L1缓存查询
Object value = localCache.getIfPresent(key);
if (value != null) {
cacheMetrics.recordHit("L1", key);
return type.cast(value);
}
// L2缓存查询
value = redisTemplate.opsForValue().get(key);
if (value != null) {
// 回填L1缓存
localCache.put(key, value);
cacheMetrics.recordHit("L2", key);
return type.cast(value);
}
// 缓存未命中,加载数据
cacheMetrics.recordMiss(key);
T data = dataLoader.get();
if (data != null) {
// 同时写入L1和L2缓存
put(key, data, Duration.ofHours(1));
}
return data;
}
/**
* 写入多级缓存
*/
public void put(String key, Object value, Duration ttl) {
try {
// 写入L1缓存
localCache.put(key, value);
// 写入L2缓存
redisTemplate.opsForValue().set(key, value, ttl);
cacheMetrics.recordPut(key);
} catch (Exception e) {
log.error("缓存写入失败: key={}, error={}", key, e.getMessage());
}
}
/**
* 缓存失效处理
*/
public void evict(String key) {
localCache.invalidate(key);
redisTemplate.delete(key);
cacheMetrics.recordEviction(key);
}
/**
* 批量预热缓存
*/
@Async("cacheExecutor")
public CompletableFuture<Void> warmUp(Map<String, Object> data) {
return CompletableFuture.runAsync(() -> {
data.entrySet().parallelStream().forEach(entry -> {
put(entry.getKey(), entry.getValue(), Duration.ofHours(2));
});
log.info("缓存预热完成,数据量: {}", data.size());
});
}
/**
* 缓存移除监听器
*/
private void onRemoval(String key, Object value, RemovalCause cause) {
log.debug("L1缓存移除: key={}, cause={}", key, cause);
cacheMetrics.recordRemoval(key, cause.toString());
}
/**
* 获取缓存统计信息
*/
public CacheStats getStats() {
com.github.benmanes.caffeine.cache.stats.CacheStats stats = localCache.stats();
return CacheStats.builder()
.hitCount(stats.hitCount())
.missCount(stats.missCount())
.hitRate(stats.hitRate())
.evictionCount(stats.evictionCount())
.averageLoadTime(stats.averageLoadPenalty())
.build();
}
}5. 中间件监控与运维
5.1 性能指标监控体系
| 监控维度 | 核心指标 | 告警阈值 | 监控工具 | 处理策略 |
|---|---|---|---|---|
| 吞吐量 | QPS/TPS | > 10000/s | Prometheus | 自动扩容 |
| 延迟 | P99响应时间 | < 100ms | Grafana | 性能调优 |
| 可用性 | 服务可用率 | > 99.9% | Alertmanager | 故障转移 |
| 资源使用 | CPU/内存使用率 | < 80% | Node Exporter | 资源调度 |
| 错误率 | 异常请求比例 | < 0.1% | ELK Stack | 问题定位 |
5.2 分布式链路追踪
java
/**
* 分布式链路追踪实现
* 基于OpenTracing标准,支持跨服务调用追踪
*/
@Component
@Slf4j
public class DistributedTracer {
private final Tracer tracer;
private final SpanRepository spanRepository;
public DistributedTracer(Tracer tracer, SpanRepository spanRepository) {
this.tracer = tracer;
this.spanRepository = spanRepository;
}
/**
* 创建根Span
*/
public Span createRootSpan(String operationName, Map<String, String> tags) {
SpanBuilder spanBuilder = tracer.buildSpan(operationName);
// 添加标签
tags.forEach(spanBuilder::withTag);
Span span = spanBuilder.start();
// 设置基础信息
span.setTag("service.name", getServiceName());
span.setTag("service.version", getServiceVersion());
span.setTag("trace.id", span.context().toTraceId());
return span;
}
/**
* 创建子Span
*/
public Span createChildSpan(String operationName, Span parentSpan) {
return tracer.buildSpan(operationName)
.asChildOf(parentSpan)
.start();
}
/**
* 记录中间件调用
*/
public <T> T traceMiddlewareCall(String middlewareName,
String operation,
Supplier<T> supplier) {
Span span = tracer.buildSpan("middleware." + middlewareName)
.withTag("middleware.type", middlewareName)
.withTag("operation", operation)
.start();
try (Scope scope = tracer.scopeManager().activate(span)) {
long startTime = System.currentTimeMillis();
T result = supplier.get();
// 记录执行时间
long duration = System.currentTimeMillis() - startTime;
span.setTag("duration.ms", duration);
span.setTag("success", true);
return result;
} catch (Exception e) {
// 记录异常信息
span.setTag("error", true);
span.setTag("error.message", e.getMessage());
span.log(Map.of(
"event", "error",
"error.object", e,
"message", e.getMessage()
));
throw e;
} finally {
span.finish();
// 异步保存Span信息
saveSpanAsync(span);
}
}
/**
* 异步保存Span信息
*/
@Async("tracingExecutor")
private void saveSpanAsync(Span span) {
try {
SpanData spanData = SpanData.builder()
.traceId(span.context().toTraceId())
.spanId(span.context().toSpanId())
.operationName(span.getBaggageItem("operation.name"))
.startTime(span.getBaggageItem("start.time"))
.duration(span.getBaggageItem("duration"))
.tags(extractTags(span))
.build();
spanRepository.save(spanData);
} catch (Exception e) {
log.error("保存Span数据失败: {}", e.getMessage());
}
}
private String getServiceName() {
return System.getProperty("spring.application.name", "unknown-service");
}
private String getServiceVersion() {
return System.getProperty("service.version", "1.0.0");
}
}6. 中间件架构演进趋势
6.1 云原生中间件架构
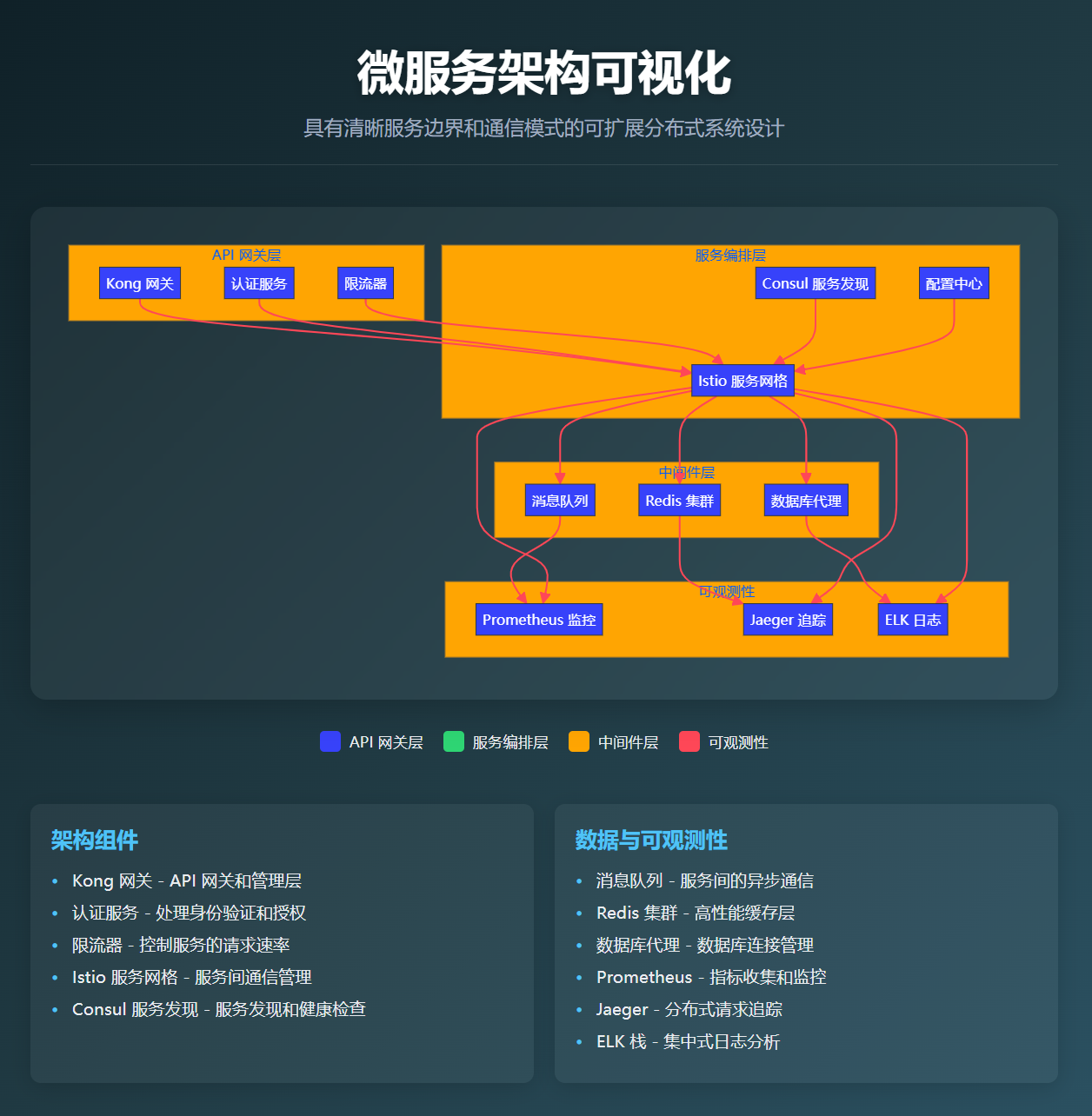
图3:云原生中间件架构图
6.2 性能优化对比分析
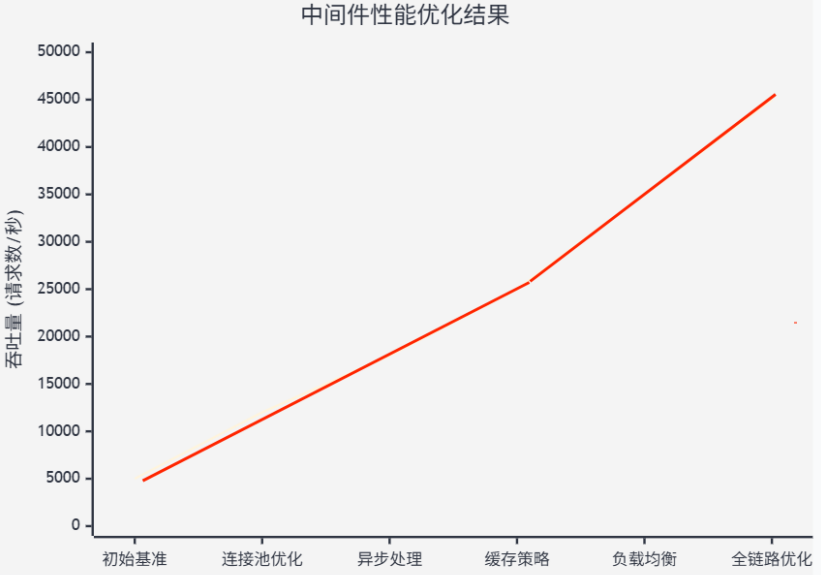
图4:中间件性能优化效果对比图
7. 实战案例:电商平台中间件架构
7.1 整体架构设计
架构设计原则
"在分布式系统设计中,中间件不仅是技术组件的连接器,更是业务逻辑的协调者。一个优秀的中间件架构应该具备高可用、高性能、易扩展的特性,同时要能够适应业务的快速变化和技术的持续演进。"
------ Martin Fowler, 《企业应用架构模式》
7.2 核心业务流程实现
java
/**
* 电商订单处理中间件
* 整合消息队列、缓存、数据库等多种中间件
*/
@Service
@Transactional
@Slf4j
public class OrderProcessingMiddleware {
@Autowired
private MessageProducer messageProducer;
@Autowired
private MultiLevelCacheManager cacheManager;
@Autowired
private ShardingRouter shardingRouter;
@Autowired
private DistributedTracer tracer;
/**
* 处理订单创建流程
* 集成多个中间件实现完整的业务流程
*/
public OrderResult processOrder(OrderRequest request) {
return tracer.traceMiddlewareCall("order-processing", "create-order", () -> {
// 1. 参数验证和预处理
validateOrderRequest(request);
// 2. 库存检查(使用缓存中间件)
boolean stockAvailable = checkInventory(request);
if (!stockAvailable) {
throw new InsufficientStockException("库存不足");
}
// 3. 创建订单(使用分库分表中间件)
Order order = createOrder(request);
// 4. 发送异步消息(使用消息中间件)
sendOrderMessages(order);
// 5. 更新缓存
updateOrderCache(order);
return OrderResult.success(order);
});
}
/**
* 库存检查(集成缓存中间件)
*/
private boolean checkInventory(OrderRequest request) {
return request.getItems().stream().allMatch(item -> {
String cacheKey = "inventory:" + item.getProductId();
Integer stock = cacheManager.get(cacheKey, Integer.class, () -> {
// 缓存未命中时从数据库查询
return inventoryService.getStock(item.getProductId());
});
return stock >= item.getQuantity();
});
}
/**
* 创建订单(集成分库分表中间件)
*/
private Order createOrder(OrderRequest request) {
String shardingKey = request.getUserId().toString();
RouteResult route = shardingRouter.route(shardingKey, "t_order");
// 使用路由结果执行数据库操作
return executeWithDataSource(route.getDataSource(), () -> {
Order order = Order.builder()
.orderId(generateOrderId())
.userId(request.getUserId())
.items(request.getItems())
.totalAmount(calculateTotalAmount(request.getItems()))
.status(OrderStatus.CREATED)
.createTime(LocalDateTime.now())
.build();
orderRepository.save(order, route.getTableName());
return order;
});
}
/**
* 发送订单相关消息
*/
private void sendOrderMessages(Order order) {
// 发送订单创建消息
OrderCreatedMessage createdMsg = OrderCreatedMessage.builder()
.orderId(order.getOrderId())
.userId(order.getUserId())
.totalAmount(order.getTotalAmount())
.createTime(order.getCreateTime())
.build();
messageProducer.sendMessage("order.exchange", "order.created", createdMsg);
// 发送库存扣减消息
order.getItems().forEach(item -> {
InventoryDeductMessage deductMsg = InventoryDeductMessage.builder()
.orderId(order.getOrderId())
.productId(item.getProductId())
.quantity(item.getQuantity())
.build();
messageProducer.sendMessage("inventory.exchange", "inventory.deduct", deductMsg);
});
}
/**
* 更新订单缓存
*/
private void updateOrderCache(Order order) {
String cacheKey = "order:" + order.getOrderId();
cacheManager.put(cacheKey, order, Duration.ofHours(24));
// 更新用户订单列表缓存
String userOrdersKey = "user:orders:" + order.getUserId();
cacheManager.evict(userOrdersKey); // 失效缓存,下次查询时重新加载
}
}7.3 系统容量规划
25% 30% 20% 15% 10% 中间件资源分配占比 消息队列集群 缓存集群 数据库中间件 API网关 监控系统
图5:电商平台中间件资源分配饼图
总结
通过多年的实践经验,我深刻认识到中间件在现代分布式系统中的核心价值。从最初的单体应用到如今的微服务架构,中间件始终扮演着系统架构演进的推动者角色。它不仅解决了系统间的通信问题,更重要的是为我们提供了构建高可用、高性能、可扩展系统的基础设施。
在技术选型方面,我们需要根据具体的业务场景和技术要求来选择合适的中间件。消息中间件如Kafka适合高吞吐量的场景,而RabbitMQ则在可靠性要求较高的场景中表现出色。数据中间件的选择更需要考虑数据一致性、分片策略和扩容能力。缓存中间件的设计则要平衡命中率、一致性和性能之间的关系。
在架构设计上,我始终坚持"简单优于复杂"的原则。虽然中间件能够解决很多问题,但过度的抽象和复杂的架构往往会带来维护成本的增加。我们需要在功能完整性和系统复杂度之间找到平衡点,确保架构既能满足当前需求,又具备未来扩展的灵活性。
性能优化是中间件应用中的永恒话题。通过连接池优化、批量处理、异步化改造、多级缓存等手段,我们可以显著提升系统的处理能力。但更重要的是建立完善的监控体系,通过数据驱动的方式来指导优化工作,避免盲目的性能调优。
展望未来,云原生技术的发展为中间件带来了新的机遇和挑战。Service Mesh、Serverless、边缘计算等新兴技术正在重新定义中间件的边界和职责。作为技术从业者,我们需要保持学习的热情,紧跟技术发展的步伐,在变化中寻找不变的本质。
最后,我想说的是,技术的价值在于解决实际问题。无论中间件技术如何发展,我们都应该以业务需求为导向,以用户体验为目标,用技术的力量创造真正的价值。在这个充满挑战和机遇的时代,让我们继续在技术的海洋中探索前行,用代码书写属于我们这一代程序员的精彩篇章。
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
参考链接
- Apache Kafka官方文档 - 高性能消息队列架构设计
- Redis官方指南 - 分布式缓存最佳实践
- Spring Cloud Gateway - 微服务网关解决方案
- Istio Service Mesh - 云原生服务治理平台
- Prometheus监控系统 - 中间件性能监控实践
关键词标签
#中间件架构 #分布式系统 #消息队列 #数据库中间件 #性能优化
数学公式补充:
中间件性能评估公式:
P e r f o r m a n c e = T h r o u g h p u t × A v a i l a b i l i t y L a t e n c y × E r r o r R a t e Performance = \frac{Throughput \times Availability}{Latency \times ErrorRate} Performance=Latency×ErrorRateThroughput×Availability
分片路由哈希函数:
S h a r d I n d e x = h a s h ( s h a r d i n g K e y ) m o d S h a r d C o u n t ShardIndex = hash(shardingKey) \bmod ShardCount ShardIndex=hash(shardingKey)modShardCount
缓存命中率计算:
H i t R a t e = C a c h e H i t s C a c h e H i t s + C a c h e M i s s e s × 100 % HitRate = \frac{CacheHits}{CacheHits + CacheMisses} \times 100\% HitRate=CacheHits+CacheMissesCacheHits×100%