
1.摘要
background
现有的vLLMs在数以百万计的短视频上训练仍然难以应对包含显著更多帧的分钟级视频
innovation
为了解决上述问题,论文提出了一个名为Koala的轻量级、自监督微调方法,用于适配预训练的vLLM以理解长视频。
核心思想: 创新性地提出使用稀疏采样的关键帧来为整个长视频提供一个高层次的全局上下文 (global context)。
关键组件: 基于全局上下文,设计了两种新的条件化视频编码器 (tokenizer):
条件化片段编码器 (Conditioned Segment, CS): 利用全局上下文,引导模型关注每个视频片段内部与整体目标最相关的视觉概念。
条件化视频编码器 (Conditioned Video, CV): 在全局上下文的指导下,对不同视频片段之间的时序关系和上下文依赖进行建模。
- 方法 Method
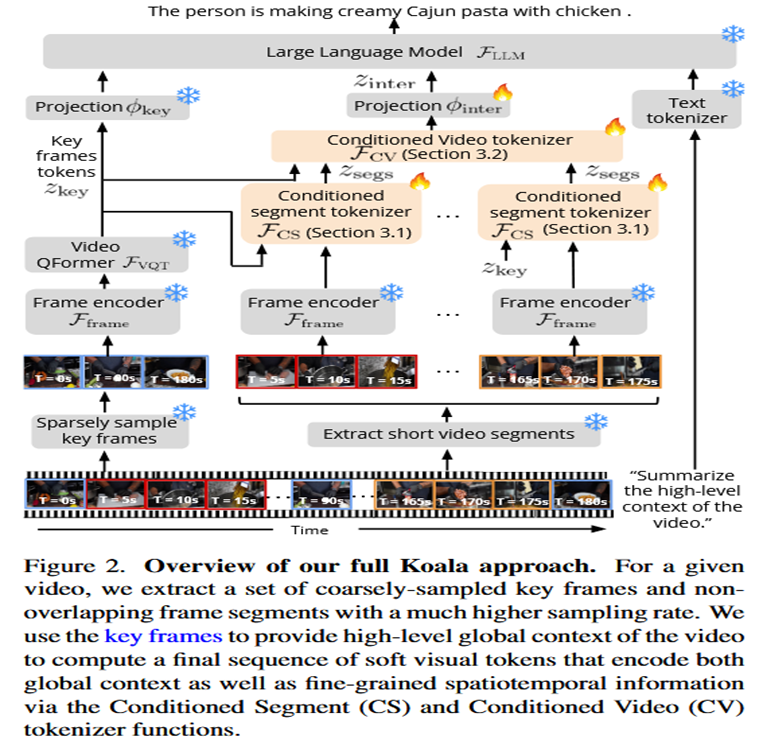
输入处理: 对于一个长视频,模型会进行两种采样:
稀疏采样,获得少量关键帧(Key frames),用于捕捉全局信息。
密集采样,获得多个连续且不重叠的短视频片段(Segments),用于捕捉局部细节。
全局上下文编码: 将稀疏的关键帧送入预训练的视频编码器(如Video QFormer),生成一组关键帧Token (z_key),这组Token代表了整个视频的全局上下文。
局部信息编码 (CS): 逐个处理每个短视频片段。将该片段的帧和上一步得到的全局z_key一起送入条件化片段编码器 (CS tokenizer) 。CS编码器会输出与全局上下文相关的片段Token (z_segs)。
跨片段关系建模 (CV): 将所有片段的z_segs收集起来,与全局z_key一同送入条件化视频编码器 (CV tokenizer) 。CV编码器负责建模这些片段之间的时序关系,并输出最终的、融合了全局和局部上下文的视频Token (z_inter)。
生成回答: 最后,将代表全局上下文的z_key、代表跨片段上下文的z_inter以及用户问题的文本Token拼接在一起,送入大语言模型(LLM)中,生成最终的答案。
各模块详解
输入: 一个长视频(分钟级)和一个文本问题。
输出: 一段自然语言文本作为回答。
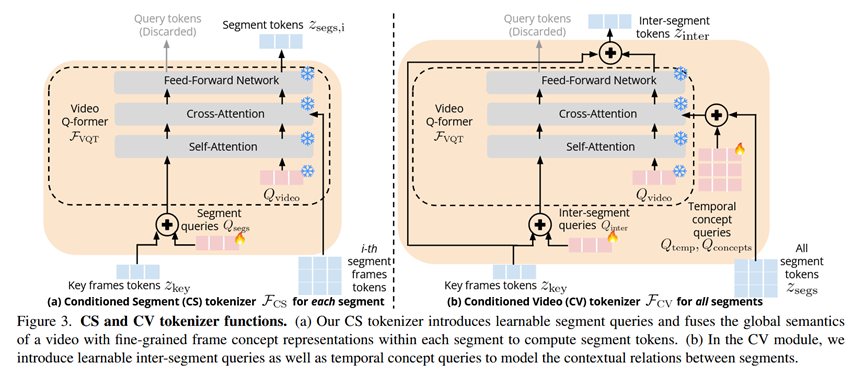
条件化片段编码器 (CS Tokenizer): 其核心是复用并改造了预训练vLLM中的Video QFormer。通过将全局上下文z_key与一组可学习的"片段查询向量"相加,并注入到QFormer的查询(Query)中,迫使模型在处理当前片段时,能主动关注那些与视频整体目标相关的视觉特征。
条件化视频编码器 (CV Tokenizer): 同样改造自Video QFormer。它引入了可学习的"时间查询向量"和"概念查询向量",用于捕捉跨片段的时序流动和核心概念。它将所有片段的Token作为输入,并再次以z_key为条件,最终生成能够概括整个视频动态过程的视觉表示。
- 实验 Experimental Results
数据集:
训练数据: 使用了HowTo100M数据集的一个子集,包含了约25万个时长从4分钟到30分钟不等的教学视频。
评测数据 (零样本Zero-shot):
EgoSchema: 一个专门用于评测超长视频(人机交互视角)问答能力的基准。
Seed-Bench: 一个综合性多模态评测基准,本文主要使用了其中的**"过程理解"(长视频任务)和"动作识别"**(短视频任务)两个子任务。
实验结论:
长视频问答能力验证 (EgoSchema): Koala的准确率达到40.42%,显著超过了其基座模型Video-Llama(33.25%)和强大的纯语言基线Flan-T5-xl(35.92%)。这证明了Koala在长时序推理上的有效性。
过程理解和动作识别能力验证 (Seed-Bench): 在"过程理解"任务上,Koala以35.91%的成绩远超基座模型的25.42%。更重要的是,在"动作识别"这个短视频任务上,Koala(41.26%)同样比基座模型(35.52%)有显著提升。这个结果表明,Koala提出的全局上下文感知机制不仅不损害模型原有的细粒度识别能力,反而能进一步增强它。
消融实验: 实验证明CS和CV两个模块都是有效且必要的。单独加入CS模块(只用全局上下文指导局部)已经能带来巨大提升,再加入CV模块(建模片段间关系)能获得更好的性能。
- 总结 Conclusion
当前vLLM难以理解长视频的核心原因是缺乏有效的长时序上下文聚合机制。本文提出的Koala通过"全局上下文(稀疏关键帧)指导局部理解(密集视频片段)"的核心思想,巧妙地解决了这个问题。这是一种轻量级的微调方法,不仅显著提升了模型的长视频理解能力,还意外地增强了其短视频识别能力,证明了该方法的普适性和有效性。