数据库初识
- 数据库初识
- github地址
- [0. 前言](#0. 前言)
- [1. MySQL的登录](#1. MySQL的登录)
- [2. 什么是数据库](#2. 什么是数据库)
- [3. 为什么要用数据库存储数据](#3. 为什么要用数据库存储数据)
- [4. Linux中MySQL数据库的使用样例](#4. Linux中MySQL数据库的使用样例)
- [5. 常见主流数据库](#5. 常见主流数据库)
- [6. 服务器,数据库,表关系](#6. 服务器,数据库,表关系)
- [7. MySQL整体架构](#7. MySQL整体架构)
-
- [1. 最上层:客户端连接层(Client Connectors)](#1. 最上层:客户端连接层(Client Connectors))
- [2. MySQL Server 层(核心层)](#2. MySQL Server 层(核心层))
-
- [(1)Connection Pool(连接池)](#(1)Connection Pool(连接池))
- [(2)SQL Interface(SQL 接口)](#(2)SQL Interface(SQL 接口))
- (3)Parser(解析器)
- (4)Optimizer(优化器)
- (5)Caches(缓存)
- [(6)Services & Utilities(服务与工具)](#(6)Services & Utilities(服务与工具))
- [3. 存储引擎层(Pluggable Storage Engines)](#3. 存储引擎层(Pluggable Storage Engines))
- [4. 最底层:文件系统与日志层](#4. 最底层:文件系统与日志层)
- [📝 总结一句话](#📝 总结一句话)
- [8. SQL语句分类和存储引擎](#8. SQL语句分类和存储引擎)
- [9. 结语](#9. 结语)
数据库初识
github地址
0. 前言
数据库 是现代应用的核心,它为数据的安全存储、高效查询和便捷管理 提供了解决方案。本文以 MySQL 为例,从基础概念到实际操作,带你快速入门并理解数据库的整体架构与常见用法。
1. MySQL的登录
命令 :mysql -h 127.0.0.1 -P 3306 -u_root-p
命令中选项的解释:
-
-h:指明登录部署了mysql服务的主机ip地址 ,这里127.0.0.1表示本机 -
-P:指明我们要访问的端口号,不输入-P时,默认使用配置文件中的端口 -
-u:指明登陆用户 -
-p:指明登录时需要输入密码
密码输入后,不会回显
- 登入
mysql后,输入quit退出
2. 什么是数据库
mysql与mysqld
mysql:是数据库服务的客户端mysqld:是数据库服务的服务器端 。可执行程序带上d,表示这是一个守护进程。mysql本质:是基于C(mysql)S(mysqld)模式的一种网络服务- Cilent
- Server
mysql是一套提供数据存取的服务 的网络程序
-
口语中说的数据库,一般指的是,在磁盘或者内存 中存储的特定结构组织的数据,也就是将来在磁盘上存储的一套数据库方案
-
数据库服务 ,可以特指
mysqld
3. 为什么要用数据库存储数据
- 数据库:结构化的存储在磁盘上的文件
- 数据库 :为用于提供数据存储服务的一整套解决方案
为什么要有数据库?
- 提升数据安全性 :文件方式存储 容易丢失或损坏,安全性差,缺少完整的访问控制和权限管理。数据库提供访问控制、备份与恢复机制,更安全可靠。
- 便于数据查询和管理 :文件只能顺序读取或简单查找,而数据库支持高效的查询语言(SQL)、索引、事务管理,极大提高数据管理能力。
- 支持海量数据存储 :文件在面对海量数据时效率低下,不易扩展。数据库可以高效组织、分片和扩展,满足大规模应用需求。数据库能够同时支持磁盘存储和内存优化,实现大数据量下的高效操作。
- 方便程序操作 :使用文件存放存储,程序员需要自己维护文件的读写、索引、并发控制,开发复杂。数据库提供统一的接口和 API,用户只需提出"存储字段"和"查询需求",数据库就能高效返回结果,减少开发者对底层存储的直接管理,使应用更易维护和扩展。
为什么用数据库存储数据
- 安全性:数据库支持用户权限、加密、备份与恢复机制,保障数据不丢失、不泄露。
- 高效性 :数据库利用索引 和优化器快速定位数据,比单纯的文件操作更快。
- 可扩展性:支持存储海量数据,并能通过分库分表、集群扩展性能,可灵活扩展容量和性能。
- 易管理性:通过 SQL 或 API,开发者可以方便地进行增删改查、统计分析,减少冗余和不一致。
- 一致性与可靠性:数据库事务机制保证数据在并发操作下仍然正确可靠。
- 支持并发,多个用户或程序可同时安全访问数据。
- 保障完整性,通过约束和事务机制保证数据正确性。
📌 总结一句话:数据库是为了解决文件存储在安全性、管理性、查询效率、扩展性和程序操作上的不足,使数据能够更安全、更高效、更可控地存储与使用。
4. Linux中MySQL数据库的使用样例
Ubuntu 22.04中mysql服务中配置文件存放的路径:/etc/mysql/mysql.conf.d/mysqld.cnf- 打开
Ubuntu 22.04中MySQL的配置文件:vim /etc/mysql/mysql.conf.d/mysqld.cnf
sql
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql # mysql服务中数据存放的路径
log-error = /var/log/mysql/error.log
character-set-server = utf8
default-storage-engine = innodb
bind-address = 0.0.0.0- 查看已有的数据库
sql
show databases;数据库中数据在磁盘中存储的位置:
sql
datadir = /var/lib/mysql # mysql服务中数据存放的路径- 在数据库中建表:
sql
create database helloWorld; # 建立名为 helloWorld 的表建立数据库的本质是在磁盘中建立了一个文件夹:
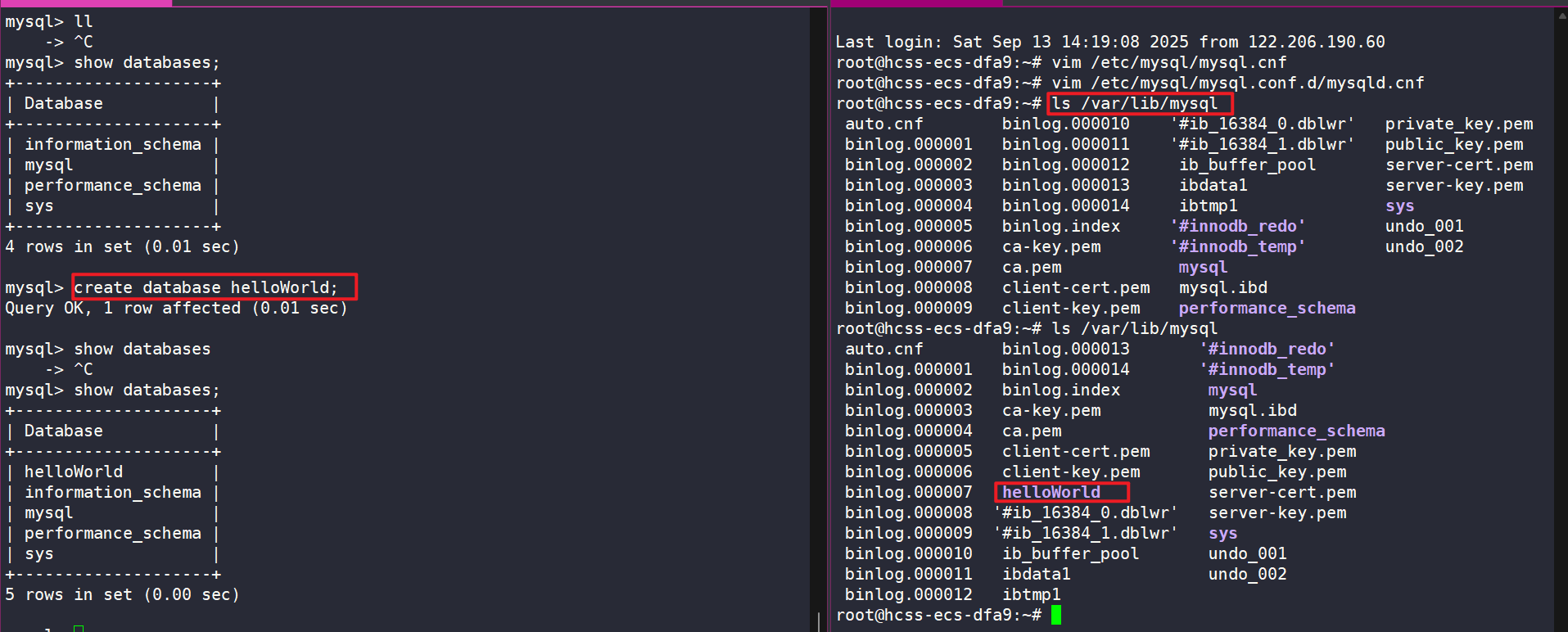
- 创建数据库表
sql
create table student(
id int,
name varchar(32),
gender varchar(2)
);- 表中插入数据
sql
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');- 查询表中的数据
sql
select * from student;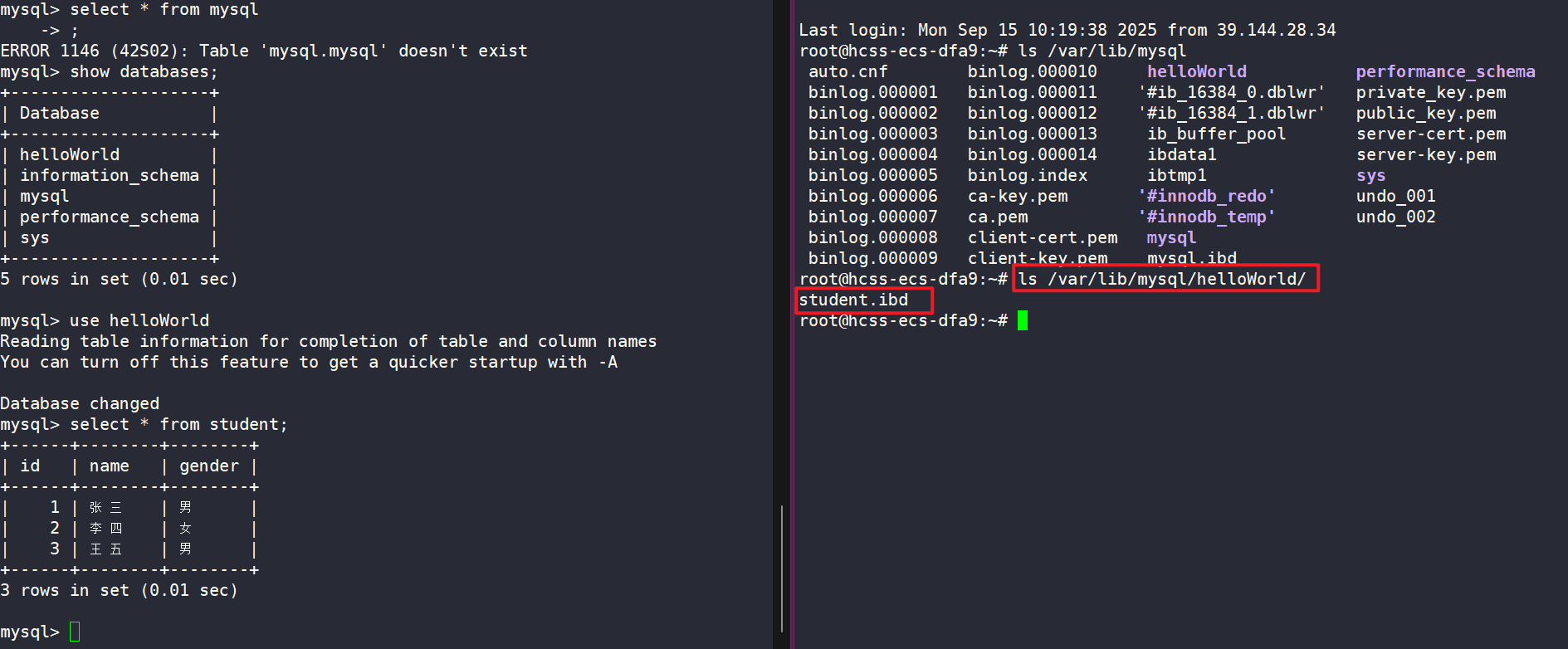
总结结论:
- 建立一个数据库,本质是在
Linux下建立一个目录 - 在数据库内建立表,本质就是在Linux下创建对应的文件!
- **数据库本质其实也是文件!!**只不过这些文件并不由程序员直接操作,而是由数据库服务帮我们进行操作
以上工作是谁做的?是mysqld服务帮我们做的
5. 常见主流数据库
- SQL Sever : 微软的产品,
.Net程序员的最爱,中大型项目。 - Oracle : 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如
MySQL。 - MySQL :世界上最受欢迎的数据库,属于甲骨文,并发性好 ,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的
SQL处理效果好。 - PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
- SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
- H2 : 是一个用
Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中
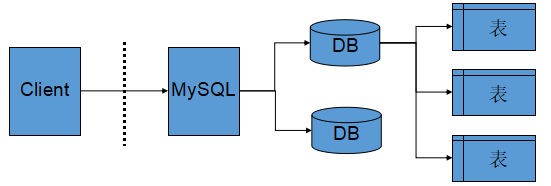
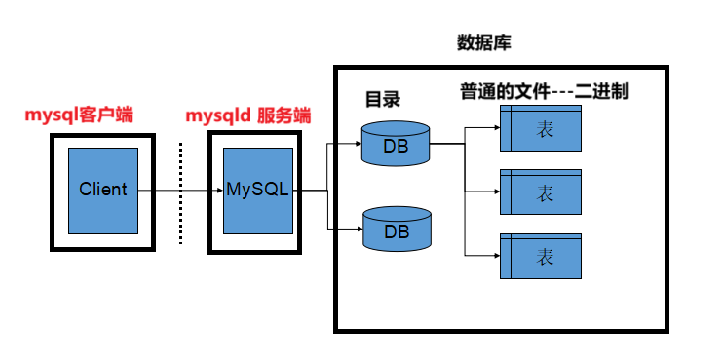
6. 服务器,数据库,表关系
- 所谓安装数据库服务 只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库
- 为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
- 数据库服务器、数据库和表的关系如下:
7. MySQL整体架构
- MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如
Unix/Linux、Windows、Mac 和 Solaris。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性
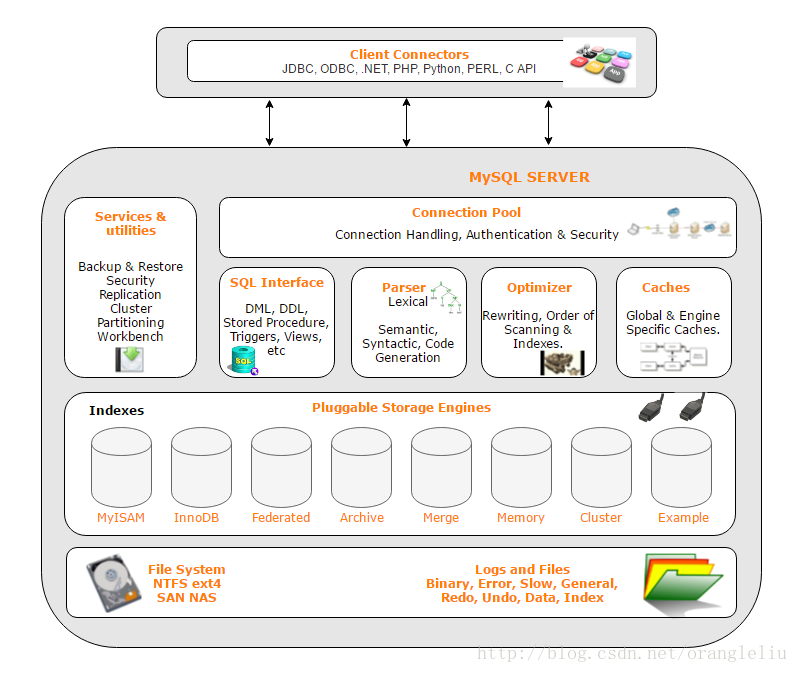
这张图大致把 MySQL 分为 四层结构:
1. 最上层:客户端连接层(Client Connectors)
- 包括 JDBC、ODBC、.NET、PHP、Python、Perl、C API 等。
- 作用:为不同的编程语言或应用程序提供访问 MySQL 的接口。
- 用户通过这些驱动或 API 与 MySQL 进行通信,发送 SQL 语句、获取结果。
2. MySQL Server 层(核心层)
这是 MySQL 的"大脑",处理请求、解析 SQL、优化执行。它又分为几个模块:
(1)Connection Pool(连接池)
- 负责 客户端连接管理:建立连接、用户认证(用户名、密码)、权限校验。
- 处理连接复用、安全性、并发控制。
(2)SQL Interface(SQL 接口)
- 提供执行 SQL 的入口,支持 DML(增删改查)、DDL(建表/改表)、存储过程、视图、触发器等。
(3)Parser(解析器)
- 词法解析(Lexical):把 SQL 语句分解成一个个词法单元。
- 语法解析(Syntactic):检查 SQL 是否符合语法规则。
- 语义解析:检查 SQL 是否合理,例如表名是否存在。
(4)Optimizer(优化器)
- 选择最优的 SQL 执行方案。
- 例如:决定走哪个索引、选择连接顺序、是否使用全表扫描等。
- 优化器的好坏直接影响查询效率。
(5)Caches(缓存)
- 全局缓存和引擎特定缓存。
- 常见如 Query Cache(在 MySQL 8.0 已废弃)、InnoDB Buffer Pool(页缓存、索引缓存)。
- 缓存能减少磁盘 IO,提高查询性能。
(6)Services & Utilities(服务与工具)
- 提供数据库的周边功能:
- 备份与恢复
- 安全机制
- 主从复制、集群
- 分区表
- 可视化工具(Workbench)
3. 存储引擎层(Pluggable Storage Engines)
- MySQL 的 核心特点之一:存储引擎可插拔。
- 常见存储引擎:
- InnoDB(默认,支持事务、外键,行级锁)
- MyISAM(轻量级,读多写少场景)
- Memory(数据存放在内存,速度快,但不持久化)
- Archive(适合归档存储,压缩高效)
- Federated(访问远程 MySQL 数据库)
- Merge、Cluster、Example 等
👉 不同存储引擎可以共享 MySQL 上层的 SQL 接口,但负责数据的实际存储与读取。
4. 最底层:文件系统与日志层
- File System(文件系统)
- 数据最终存放到操作系统文件系统(如 NTFS、ext4、SAN、NAS)。
- Logs and Files(日志与文件)
- MySQL 运行时生成各种日志:
- Binary log(二进制日志,用于复制与恢复)
- Error log(错误日志)
- Slow log(慢查询日志)
- General log(通用日志,记录所有语句)
- Redo log(InnoDB 用于崩溃恢复)
- Undo log(事务回滚用)
- Data files、Index files(实际数据和索引文件)
- MySQL 运行时生成各种日志:
📝 总结一句话
MySQL 的整体架构是 "连接层 → SQL 执行层 → 存储引擎层 → 文件系统层"。
- 上层(Server 层)处理 SQL 解析、优化、缓存、安全。
- 中间(存储引擎层)负责数据的存取方式(可插拔)。
- 底层(文件系统)最终把数据写入磁盘,并通过日志保证事务一致性与高可用性。
8. SQL语句分类和存储引擎
SQL分类
DDL【data definition language】数据定义语言,用来维护存储数据的结构
代表指令 :create, drop, alterDML【data manipulation language】数据操纵语言,用来对数据 进行操作
代表指令 :insert,delete,updateDML中又单独分了一个DQL,数据查询语言 ,代表指令 :select
DCL【Data Control Language】数据控制语言,主要负责权限管理和事务
代表指令 :grant,revoke,commit
存储引擎
- 存储引擎 是:数据库管理系统如何存储数据 、如何为存储的数据建立索引 和如何更新、查询数据等技术的实现方法
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
查看存储引擎:
sql
show engines;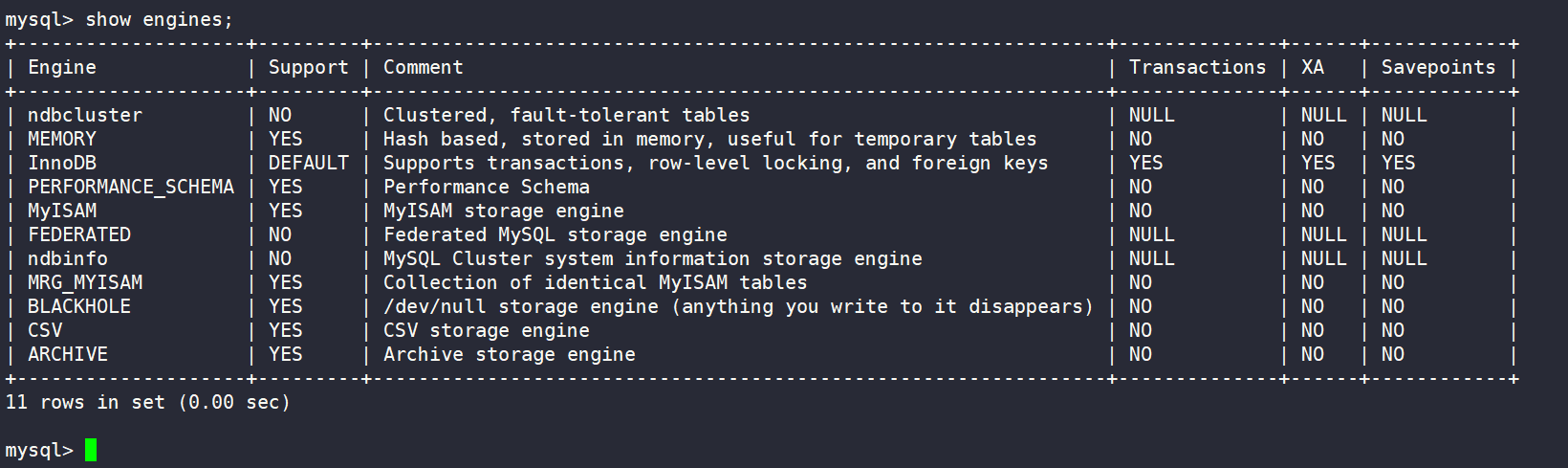
MySQL 存储引擎对比
| Feature | MyISAM | BDB | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|---|
| Storage Limits | No | No | Yes | 64TB | No | Yes |
| Transactions (commit, rollback, etc.) | ✘ | ✔ | ✘ | ✔ | ✘ | ✔ |
| Locking granularity | Table | Page | Table | Row | Row | Row |
| MVCC/Snapshot Read | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Geospatial support | ✔ | ✘ | ✘ | ✔ | ✘ | ✘ |
| B-Tree indexes | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
| Hash indexes | ✘ | ✘ | ✔ | ✔ | ✘ | ✔ |
| Full text search index | ✔ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Clustered index | ✘ | ✘ | ✘ | ✔ | ✘ | ✔ |
| Data Caches | ✘ | ✘ | ✘ | ✔ | ✘ | ✔ |
| Index Caches | ✔ | ✘ | ✘ | ✔ | ✘ | ✔ |
| Compressed data | ✘ | ✘ | ✘ | ✔ | ✔ | ✘ |
| Encrypted data (via function) | ✔ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Storage cost (space used) | Low | Low | N/A | High | Very Low | Low |
| Memory cost | Low | Low | Medium | High | Low | High |
| Bulk Insert Speed | High | High | High | Low | Very High | High |
| Cluster database support | ✘ | ✘ | ✘ | ✘ | ✘ | ✔ |
| Replication support | ✔ | ✘ | ✘ | ✔ | ✘ | ✔ |
| Foreign key support | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ |
| Backup/Point-in-time recovery | ✔ | ✘ | ✘ | ✔ | ✘ | ✔ |
| Query cache support | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Update Statistics for Data Dictionary | ✔ | ✘ | ✘ | ✔ | ✘ | ✔ |
📌 总结要点:
- InnoDB:MySQL 默认引擎,支持事务、行级锁、外键,适合大多数应用。
- MyISAM:读写性能高,支持全文索引,但不支持事务,表级锁。
- Memory:数据存储在内存中,速度快,但断电数据丢失。
- Archive:高压缩率,适合日志、归档数据存储。
- NDB (Cluster):支持分布式集群,适合高可用、高并发场景。
- BDB:较旧的事务引擎,现在已基本弃用。
9. 结语
通过本文的学习,我们了解了数据库的作用、MySQL 的基本使用方式及其架构特点。数据库不仅是数据存放的工具,更是应用高效运行的关键。
以上就是本文的所有内容了,如果觉得文章对你有帮助,欢迎 点赞⭐收藏 支持!如有疑问或建议,请在评论区留言交流,我们一起进步
分享到此结束啦
一键三连,好运连连!你的每一次互动,都是对作者最大的鼓励!
征程尚未结束,让我们在广阔的世界里继续前行!🚀