文章目录
- 摘要
- 一、引言
- 二、VLA模型的国内外现状
- 三、八个不确定指标
-
- [动作位置不稳定性(Action Position Instability,A-PI)](#动作位置不稳定性(Action Position Instability,A-PI))
- [动作速度不稳定性(Action Velocity Instability,A-VI)](#动作速度不稳定性(Action Velocity Instability,A-VI))
- [动作加速不稳定性(Action Acceleration Instability,A-AI)](#动作加速不稳定性(Action Acceleration Instability,A-AI))
- [令牌概率(Token Probability,TB-TP)](#令牌概率(Token Probability,TB-TP))
- [预测置信度得分(Prediction Confidence Score,TB-PCS)](#预测置信度得分(Prediction Confidence Score,TB-PCS))
- DeepGini(DeepGini,TB-D)
- 熵(Entropy,TB-E)
- [可变概率(Execution Variability,EV)](#可变概率(Execution Variability,EV))
- 四、五个质量指标
-
- [轨迹位置不稳定性(Trajectory Position Instability,TCP-PI)](#轨迹位置不稳定性(Trajectory Position Instability,TCP-PI))
- 轨迹速度不稳定性(TCP-VI)
- [轨迹加速度不稳定性(Trajectory Acceleration Instability,TCP-AI)](#轨迹加速度不稳定性(Trajectory Acceleration Instability,TCP-AI))
- 轨迹不稳定性 (Trajectory Instability,TI)
- [最优轨迹差(Optimal Trajectory Difference,OT)](#最优轨迹差(Optimal Trajectory Difference,OT))
- 实验
- 个人思考
为什么国庆还要上班😭
Evaluating Uncertainty and Quality of Visual Language Action-enabled Robots
题目:VLA机器人的不确定性和质量评估
摘要
视觉语言动作(VLA)模型介绍 :VLA很屌
评估方式的缺陷 :这类模型通常通过任务成功率来评估,但这无法捕捉任务执行的质量和模型对其决策的信心。
本文创新 :本文提出了专门为机器人操作任务的VLA模型设计的八个不确定性度量和五个质量度量,并通过大规模的实证研究评估了它们的有效性涉及908个成功的任务执行从三个国家的最先进的VLA模型在四个代表性的机器人操作任务。
人类领域的专家手动标记的任务质量,使我们能够分析我们提出的指标和专家判断之间的相关性。
结果显示,一些指标显示出中度到强烈的相关性与人类的评估,强调了它们在评估任务质量和模型置信度方面的实用性。此外,我们发现一些指标可以区分高、中、低质量的执行和不成功的任务,我们的研究结果挑战了当前仅依赖于二进制成功率的评估实践的充分性,并为改进VLA启用机器人系统的实时监控和自适应增强铺平了道路。
一、引言
简介 :
VLA模型代表了一个有前途的方向,使机器人能够解释视觉场景,理解自然语言命令,并在动态环境中无缝地执行复杂任务。
输入:图像、自然语言指令和受控机器人的状态。
输出:它们生成一组动作块,这些动作块被直接转换为机器人的动作和操纵命令。
效果:VLA将高级认知指令与低级机器人动作连接起来,简化了机器人编程,促进了人机交互。
国内外VLA
GR 00 T-N1 4
π0 5
OpenVLA 6
SpatialVLA 7
评估VLA的方法介绍
模型的评估缺乏标准化指标(每个VLA模型开发者通常会提出自己的评估基准)
目前的方法:
VLATEST,这是一个评估具有模糊化的最新VLA模型的基准框架。与提出新VLA模型的研究类似,第8话使用符号预言器来确定任务的成功。这些预言器通过检查目标对象的最终状态来评估VLA模型是否实现了它们的目标(例如,其最终位置)。
VLATEST充分说明了这些VLA操作中有许多质量很低,而且通常不清楚任务是由于模型能力还是仅仅是偶然成功完成的。
本文贡献
- 首创八个不确定性指标和五个质量指标。
- 我们在四个任务中手动评估了三个最先进的VLA模型的质量。为此,三位领域专家手动分析并标记了来自三个VLA模型的908个成功测试执行。
- 我们通过测量它们与人工注释的相关性来评估所提出的质量和不确定性度量。结果表明,一些度量与人类判断具有中等到高度的相关性,因此在实践中是有用的。
- 我们提供了一个完整的复制包9,包括代码,配置文件和说明,以促进可重复性和进一步研究。此外,我们提供了一个Zenodo包10,其中包括我们实验的所有结果。
虽然传统的评估主要依赖于二进制任务完成的成功,但我们对三种主要VLA模型的908次成功执行的彻底分析发现了任务执行质量的显着差异。
例如,π0模型表现出较差的执行质量,这是一个与他们普遍乐观的自我评估形成鲜明对比的重要发现(笑死)。
我们的领域专家对成功任务的标记发现了明显的差异,强调成功率单独作为可靠的评估指标的不足。
此外,我们提出的八个不确定性指标和五个质量指标显示与专家评估的中度到高度相关性,这些发现不仅对现有的评估框架提出了挑战,而且为未来改进真实的性能提供了重要的途径。机器人系统中的时间监控和自适应增强。
二、VLA模型的国内外现状
传统的深度神经网络(DNN)通常是为单域任务设计的。例如,卷积架构擅长从图像中提取分层特征11,12,13,14,14,而基于transformer的15语言模型捕获文本中的长距离依赖关系16,17,18,19,20。相比之下,VLA模型编码视觉观察(例如,图像或视频帧)和文本指令到共享嵌入空间中,这种方法允许VLA模型在场景的上下文中解释诸如"拿起苹果"的指令,其中他们必须使用视觉注意机制来解决对象引用中的歧义,并将指令转换为精确的物理运动序列。
训练VLA模型通常遵循以下两种方法之一:(1)从头开始训练或(2)利用大规模预训练,然后进行有针对性的微调。在前一种情况下,模型在针对特定机器人或任务环境定制的数据集上进行初始化和训练,确保学习的策略与此类系统的独特约束一致22,23。在后者中,这是一种更好扩展的方法,VLA模型在广泛的多模式数据集(例如Open X-Embodiment数据集24)上进行预训练,包括不同的语言命令、视觉观察,这个预训练阶段为模型提供了可转移的表示和一般推理能力。随后,模型在机器人特定的数据集上进行微调,以使其动作解码器适应硬件的独特约束(例如,运动学或关节限制)。这种精细-调谐对于确保预测的动作不仅有意义而且在机器人的物理约束内可执行和安全是至关重要的。
三、八个不确定指标
具体来说,我们采用了深度学习模型中常用的四个基于置信度的度量,例如
Token Probability(词元概率)
在语言模型里,就是模型对输出token的预测概率。概率越高,说明模型对这个 token 越自信。
在 VLA 里,他们可能用类似的输出概率来衡量模型的动作或指令置信度。
PCS(Prediction Confidence Score 或 Prediction Consistency Score)
一般指预测结果的置信分数或一致性指标。比如多个采样结果是否高度一致。
迁移到 VLA 时,就是看模型对某个动作/轨迹预测是否稳定。
Entropy(熵)
反映概率分布的不确定性。分布越平均(高熵),说明模型越不确定;如果分布非常尖锐(低熵),说明模型很自信。
VLA 中可用来衡量动作选择或语言解析时的不确定性。
DeepGini
原本用于深度学习测试的一种置信度指标,计算方式和基尼不纯度类似。值越高说明模型越不确定。
VLA模型的上下文。选择这些是因为它们直接反映了预测置信度,并且具有可解释的概率原则,当扩展到VLA模型的输出时仍然相关。除此之外,由于VLA模型的输出涉及结构化的决策序列,我们还引入了四个专门设计用于测量生成动作中的不确定性的新度量。这些新度量与更传统的基于令牌的度量不同但互补,旨在捕获动作可变性和模型一致性中的细微差异。通过将适应性度量和新度量相结合,我们的目标是提供一套广泛的指标来评估VLA模型中的不确定性。
动作位置不稳定性(Action Position Instability,A-PI)
动作位置不稳定性(A-PI)是通过检查模型的推断动作或预测状态的时间演变来量化不确定性的。为了有效地测量这种不确定性,我们通过计算连续步骤之间的差异来评估动作序列内的平滑性和一致性。显著波动或突变,可观察到这些差异中的明显峰值,这种突然的转变可能反映了模型在给定任务上表现的犹豫不决或不稳定。
对于VLA模型预测的推理动作序列{a1,a2,.,aT },我们计算时间t处的一阶差分,其中t > 1,如下所示:
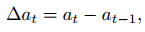
其中, |∆at| 测量提供给机器人的动作的瞬时变化率。 |∆at| 在连续的步骤中,表明模型行为的突然变化,可能反映了不确定性。为了量化这种不确定性,我们采用了Matinnejad等人25提出的不稳定性度量,最初是为了测量信号中的振荡而开发的。因此,在任何给定的时间t,其中t > 1,我们测量VLA模型的不确定性如下:
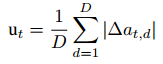
动作速度不稳定性(Action Velocity Instability,A-VI)
以前的度量在某些情况下有一些缺点。例如,高速移动的机器人自然会表现出一致的大的不稳定性值,而不一定反映不稳定的行为。为了更准确地描述机器人的动态行为,我们引入了动作速度不稳定性(A-VI)度量。该度量定义为动作序列的二阶差分,对应于离散的二阶导数:(就是前面求导)
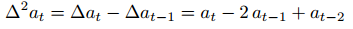
速度差异越大,表明运动的突变越多,反映了不确定性的增加和机器人行为的潜在不稳定性。我们使用以下度量来量化这种不确定性:
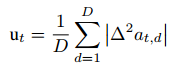
动作加速不稳定性(Action Acceleration Instability,A-AI)
三阶导数
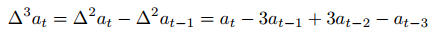
较高的A-AI值表明行为更加突然且不那么平滑,反映了机器人决策过程中更大的不稳定性和更大的不确定性。与之前的指标类似,我们计算不确定性值如下:
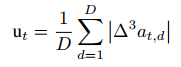
令牌概率(Token Probability,TB-TP)
VLA 模型在决策时使用VLM作为 backbone。
VLM 输出 离散 token(类似文字或指令符号),这些 token 会被后续 diffusion model 处理生成动作。因此,token 的概率分布可以反映模型对当前决策的信心程度。
如果模型输出某个动作的 token 概率很集中(比如某个 token 的概率 0.9),说明模型很自信;如果概率分布比较平均(0.3、0.3、0.4),说明模型不确定该选哪个动作。
Token-Based Token Probability (TBTP) 不确定性
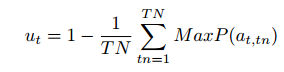
TN = 当前动作的 token 数量
对动作中的每个 token 都算 MaxP,然后求平均,再用 1 减去平均值 → 得到 不确定性度量 u_t
逻辑:平均最大概率越高 → 1-平均值越小 → 不确定性越低
TBTP = 平均最大 token 概率的反向度量
用来衡量模型在某一步动作的 整体决策不确定性
低 TBTP → 高自信
高 TBTP → 模型不确定,可能容易出错
预测置信度得分(Prediction Confidence Score,TB-PCS)
通过计算预测概率**最高的类别(max)与第二高类别(second-max)**之间的差值来衡量不确定性。
差值大 → 模型对最优预测非常自信;差值小 → 模型在前两候选之间犹豫,不确定性高。
和前面那个差不多
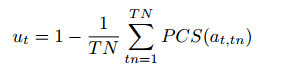
TN = 动作中 token 的数量
tn = 动作中具体的 token 索引
解释:如果 PCS 值大 → 1-PCS 值小 → 不确定性低;如果 PCS 值小 → 1-PCS 值大 → 不确定性高
对每个动作 token,如果模型对"最可能类别"和"次可能类别"的差距大,就说明模型很自信。
TB-PCS 会把每个 token 的 PCS 平均,并通过 1-平均值映射到不确定性指标:
低 u_t → 模型自信
高 u_t → 模型不确定
DeepGini(DeepGini,TB-D)
DeepGini (TB-D) 不确定性指标利用模型为动作每个组成部分(token)生成的概率分布来衡量不确定性。
核心思想是 分布越集中 → 自信越高;分布越均匀 → 不确定性越大
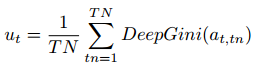
TN = 动作中 token 的数量
tn = 动作中具体 token 的索引
解释:把动作中每个 token 的 DeepGini 值取平均 → 得到整个动作的不确定性
高 u_t → 模型不确定性大
低 u_t → 模型较自信
熵(Entropy,TB-E)
和前面相同
当模型对多个可能输出类别给出的概率相近(分布平坦)时 → 不确定性高 → 熵大
当模型对某个类别概率很高,其他类别概率低(分布尖锐)时 → 不确定性低 → 熵小
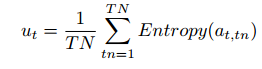
TN = 动作中 token 的数量
tn = 动作中具体 token 的索引
高 u_t → 模型对动作选择不确定性高
低 u_t → 模型自信
TB-E 衡量模型输出的"概率分布混乱程度"
分布越平坦 → 熵越高 → 模型难以判断最优动作
分布越尖锐 → 熵越低 → 模型对动作选择很自信
可变概率(Execution Variability,EV)
VLA 模型本身具有随机性,同一个输入可能生成不同输出 。
如果模型对输入很自信 → 多次推理结果应该比较一致
如果模型不确定 → 多次推理结果差异大
因此,EV 指标就是通过 同一个输入多次推理输出的波动程度(标准差) 来量化模型的不确定性。
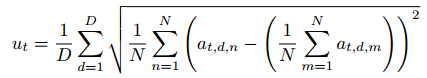
N = 每个步骤的推理次数
D = 动作维度数
at,d,m = 第 n 次推理在时间 t 第 d 个维度上的动作值
累加求平均
这些指标都是比较容易想到的,确实比较全面
四、五个质量指标
传统的性能指标(像 API, A-VI, A-AI)通常关注的是任务 结果 或 动作层面的性能,比如:
任务有没有完成?
规划的动作序列是否正确?
速度、加速度是否合理?
但这些指标并没有直接反映 机器人实际执行过程中运动的质量。但我们提出的5个质量指标可老牛逼了,如下
轨迹位置不稳定性(Trajectory Position Instability,TCP-PI)
TCP-PI 专门用来评估机器人末端执行器(TCP, Tool Center Point)的轨迹平滑度与稳定性。
输入:一段执行过程中 TCP 的位置序列{ p1, p2, ..., pt}
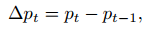
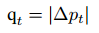
如果 qt很小:
→ 说明相邻时刻的运动变化平缓,轨迹光滑稳定。
如果 qt很大:
→ 说明机器人动作突然、急促或不稳定,可能存在轨迹抖动或控制不精确。
轨迹速度不稳定性(TCP-VI)
和上面一样,就是求个导
轨迹加速度不稳定性(Trajectory Acceleration Instability,TCP-AI)
同上
轨迹不稳定性 (Trajectory Instability,TI)
关注机器人在整个任务中的轨迹平滑度 。
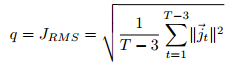
RMS jerk 小:轨迹很平滑,机器人动作像人类,自然、不突兀。
RMS jerk 大:轨迹有明显的"顿挫感",动作急促、不稳定。
最优轨迹差(Optimal Trajectory Difference,OT)
OT (Optimal Trajectory Difference) → 关注的是动作的"目标导向性" ------ 机器人是不是 越来越靠近目标,在一步步接近任务的完成。
也就是说,OT不是看"动作好不好看",而是看"动作是不是朝正确方向努力"。
Pick Up 任务(抓取)
计算 机械臂末端(TCP) 到 目标物体位置 的欧氏距离:
Move / Put In / Put On 任务(搬运/放置)
分两阶段:
没抓住物体之前:要考虑
TCP → 目标物体的距离
TCP → 目标放置点的距离(确保找对物体并有正确目标)
抓住物体之后:只考虑
TCP → 最终目标点 的距离
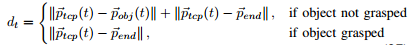
取距离序列{d1,d2,...dt},计算一阶差分:
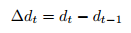
归一化到 0,1 区间,值越小说明执行越好。
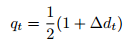
实验
研究问题
在三个VLA模型和四个任务中,选取研究问题:
RQ 1-复制 :VLATest中的成功任务在多大程度上与人类对任务质量的判断一致?我们复制了Wang等人8进行的实验,以评估成功任务的质量。为此,我们使用人类专家 对VLATest 8归类为成功的测试用例进行了更详细的分析。
RQ 2-相关性 :提出的不确定性和质量度量如何准确地反映机器人的性能?我们评估提出的不确定性和质量度量是否可以用作机器人性能退化的指标 。为此,我们研究了第三节和第四节中提出的度量与领域专家标记的质量水平的相关性。
RQ 3-辨别力 :建议的指标在多大程度上可以区分成功和失败的任务?我们调查所提出的指标是否与机器人的任务成功。通过分析每个指标在任务中的分布和效应大小,我们的目标是评估它们作为任务成功或失败的指标的潜力。
RQ 4-开销:集成这些度量如何影响推理时间?VLA模型的推理时间对于机器人系统的实时控制至关重要。因此,研究不同度量产生的开销以指导未来的从业者采用它们是至关重要的。这个RQ研究了每个建议的不确定性和质量度量的计算成本。
我们的指标虽然不是乱提的,但是我们也不确定指标的有效性,所以我们设置了各种研究问题来确认。
VLA模型选取
VLA模型在我们的评估中,我们使用了三种最先进的VLA模型,OpenVLA 6,SpatialVLA 7和π0 5。选择这三种模型是因为(1)它们相对较新,(2)它们相对知名,(3)它们在研究6,5,7中报告的性能相当高。此外,这三个模型是可用的,并为开源模拟器的机器人进行了微调。我们使用了适应两个基准数据集的微调版本,每个基准数据集对应于我们评估套件中的两个任务类别。拾取和移动近距离任务的模型是为Google机器人训练的,而那些用于Put on和Put in任务的任务是为WidowX机器人训练的。每个模型使用的特定模型检查点如下所述:·
OpenVLA:我们使用了作者在HuggingFace上发布的基本检查点31。
π0:我们使用SpatialVLA作者提供的检查点,这些检查点用于他们的评估。
使用了两个版本的模型,每个数据集一个。Fractal数据集的检查点可在32中找到,Bridge数据集的检查点可在33中找到。
SpatialVLA:我们使用了模型的检查点,该检查点是在模型7的论文中提供的两个数据集34的混合数据上预训练的。
附录A-A中提供了每个模型架构的扩展解释。请注意,空间VLA和π0未用于VLATEST 8,因此我们的研究提供了这两个模型的新结果。
实验场景
环境与VLATest 8一样,我们使用SimplerEnv基准35进行评估,评估我们在两个机器人平台和四个不同任务中的指标有效性。第一个机器人手臂是所谓的Google机器人,一个Everyday Robot 3,使用Fractal数据集23训练VLA模型。第二个机器人手臂是WidowX机器人,Bridge V2数据集36用于训练VLA模型。为了进行评估,我们使用了8中选择的相同的四个任务,其中两个用于一个机器人,另两个用于另一个机器人
任务一:拾取物体。VLA模型必须识别目标物体,并生成控制信号来抓住和举起它。成功完成要求机器人抓住正确的物体,并连续五帧将其举起至少0.02米。这项任务是使用Google机器人进行评估的。
任务2:将对象A移动到对象B附近。VLA模型必须定位源对象A并生成控制信号以将其移动到目标对象B附近。如果对象A位于距离对象B 0.05米或更近的范围内,则任务被视为成功。此任务使用Google机器人进行评估。
任务3:将对象A堆叠在对象B上。VLA模型必须将对象A稳定地放置在对象B的顶部。成功定义为对象A在对象B的顶部保持平衡而不倾倒。此任务使用WidowX机器人进行评估。
任务4:将对象A放置在对象B内。VLA模型必须生成控制信号以将对象A完全放置在对象B内(例如,"将苹果放入篮子")。如果对象A完全位于对象B内,则任务被视为成功。此任务使用WidowX机器人进行评估。
对于每个任务,我们使用VLATest 等人8生成的前500个场景。在这些场景中,随机选择目标对象,伴随着0到3个混淆对象。每个对象的位置和姿态随机分配,遵循8中解释的某些约束。为了避免碰撞重叠,在放置过程中,对象之间保持0.15米的最小距离。2关于环境,使用默认的照明和相机姿势设置。
基本和VLATest的场景一样。
配置
我们设置了统一的随机种子、限定了 EV 采样次数为 4,并通过实验确定时间差分指标的最佳窗口为 8 步,以在稳定性与计算效率间取得平衡。"
人类标签评估
用专家打标签,建立一个人类参考标准,用来验证模型输出质量评估指标(如不确定性与动作质量指标)的可靠性和有效性。
解决的问题:
机械臂动作虽然平滑,但在快接近苹果时偏了一点点位置,结果没抓到苹果,又重新调整、再试了一次才抓起。整个过程动作优雅,但任务表现"犹豫""低效"。
从指标角度看(A-PI、TCP-VI),一切都很平滑、很稳定。
但从人类角度看,这样的执行过程并不"高质量"------它是平滑但低效的。
所以需要人类评估。
个人思考
基于VLATest提出的改进
前文提到,虽然VLATest的场景覆盖全面,但指标太过简答和单一,无法全面覆盖,这马上又发了篇论文😂而且实验相当的丰富,设计的算法非常多,虽然论文本身不难,但是也需要对算法有着深度的了解,从缺陷倒退分析指标。
所有人都在抢时间。。。要抓紧了。。