在昨天的内容里,我们已经围绕 Subword 分词体系中最基础的两类算法 ------BPE(字节对编码)与 BBPE(双向字节对编码)展开了详细拆解:从 BPE 的 "训练 - 编码" 核心逻辑切入,用具体案例还原了它如何通过迭代合并高频字节对构建词汇表,也分析了其在控制词汇表规模、处理未登录词上的优势与局限;随后又聚焦 BBPE 与 BPE 的差异,通过预处理、多轮字节对统计与合并的完整实例,清晰呈现了 BBPE 的工作原理,以及它在特定场景下的应用价值。
但 Subword 分词的技术版图远不止于此。BPE 与 BBPE 虽为经典方案,却仍有各自的适用边界,而在实际的 NLP 任务中,还需要更灵活、更适配不同模型需求的分词算法。今天,我们就顺着 Subword 的技术脉络继续深入,带大家认识另外三款极具代表性的算法 ------WordPiece 、Unigram 与SentencePiece,看看它们如何在 BPE/BBPE 的基础上优化改进,又分别能为文本处理带来哪些新的可能性。
目录
[1.1 基本原理](#1.1 基本原理)
[1.2 训练过程](#1.2 训练过程)
[1.2.1 初始化词汇表](#1.2.1 初始化词汇表)
[1.2.2 迭代与合并](#1.2.2 迭代与合并)
[1.2.3 终止](#1.2.3 终止)
[1.3 案例助解](#1.3 案例助解)
[1.4 编码过程](#1.4 编码过程)
[1.5 特殊符号](#1.5 特殊符号)
[1.5.1 常见符号](#1.5.1 常见符号)
[1.5.2 关键说明](#1.5.2 关键说明)
[1.5.3 存在意义](#1.5.3 存在意义)
[1.5.4 其它特殊符号](#1.5.4 其它特殊符号)
[1.6 小结](#1.6 小结)
[2.1 基本思想](#2.1 基本思想)
[2.2 初始化词表](#2.2 初始化词表)
[2.2.1 预料词频统计](#2.2.1 预料词频统计)
[2.2.2 基本词表构建](#2.2.2 基本词表构建)
[2.2.3 词表token频率](#2.2.3 词表token频率)
[2.3 算法过程](#2.3 算法过程)
[2.3.1 EM](#2.3.1 EM)
[2.3.2 评估Loss](#2.3.2 评估Loss)
[2.3.3 模拟删除](#2.3.3 模拟删除)
[2.3.4 词表更新](#2.3.4 词表更新)
[2.3.5 继续EM](#2.3.5 继续EM)
[2.3.6 词表剪枝](#2.3.6 词表剪枝)
[2.4 小结](#2.4 小结)
[3.1 BWU缺点](#3.1 BWU缺点)
[3.2 基本思想](#3.2 基本思想)
[3.3 工作流程](#3.3 工作流程)
[3.4 案例助解](#3.4 案例助解)
[3.4.1 步骤 1](#3.4.1 步骤 1)
[3.4.3 步骤 3](#3.4.3 步骤 3)
[3.4.4 步骤 4](#3.4.4 步骤 4)
[3.5 小结](#3.5 小结)
[3.6 代码实现](#3.6 代码实现)
一、WordPiece
WordPiece是BPE的变种,被应用于BERT等模型中。
1.1 基本原理
WordPiece是一种基于统计的子词分词算法,它将单词分解为更小的子词单元,主要特点包括:
-
将罕见词分解为更小的已知子词
-
保留常见词作为完整单元
-
词汇表通过训练数据学习得到
1.2 训练过程
WordPiece是如何完成词汇表的构建的呢?
1.2.1 初始化词汇表
-
将所有字符加入初始词汇表
-
将训练语料中的所有单词按字符拆分并统计频率
"low" → ["l", "##o", "##w"] -
在单词开头添加一个特殊的子词前缀(如
##),表示这是一个词的中间或尾部片段。
1.2.2 迭代与合并
与BPE类似,但是算法略有不同:将 pair 的频率除以其单个 token 的频率乘积(互信息)
\\text{pair 得分} = \\frac{\\text{pair 出现的次数}}{\\text{token1 出现的次数} \\times \\text{token2 出现的次数}}
这个公式衡量的是A和B的互信息。如果A和B经常在一起出现(freq_of_pair 高),而它们各自又不是很常见的字符(freq_of_token1 和 freq_of_token2 不高),那么它们的得分就会很高。这意味着A和B的组合具有很高的"粘性",应该被合并成一个新的子词单元。
该算法优先考虑单个 token 在词表中不太频繁的 pair 进行合并。
1.2.3 终止
重复步骤3,直到词汇表达到预定大小,或者下一次合并的得分低于某个阈值。
1.3 案例助解
通过一个小小的案例帮助大家理解WordPiece算法过程。
-
词频统计:
对语料库进行词频统计:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5) -
基本词表构建:
基于语料库构建词表如下:
['b', 'h', 'p', '##g', '##n', '##s', '##u'] -
根据基本词表切词:
('h' '##u' '##g', 10), ('p' '##u' '##g', 5), ('p' '##u' '##n', 12), ('b' '##u' '##n', 4), ('h' '##u' '##g' '##s', 5) -
统计频率:
-
词内相邻Token组成的pair出现频率
hu:15, ug:20, pu:17, un:16, bu:4, gs:5 -
每个token出现频率
h:15, u:36, g:20, p:17, n:16, b:4, s:5
-
-
计算pair得分
符号对 计算公式 得分(近似值) hu \frac{15}{15 \times 36} 0.0278 ug \frac{20}{36 \times 20} 0.0278 pu \frac{17}{17 \times 36} 0.0278 un \frac{16}{36 \times 16} 0.0278 bu \frac{4}{4 \times 36} 0.0278 gs \frac{5}{20 \times 5} 0.05 -
词表合并:
添加概率 pair 到词表:应该可以看的出来,gs:0.05 词频最高
合并 gs 到词表,于是词表变成了:
['b', 'h', 'p', '##g', '##n', '##s', '##u', '##gs']同步语料库切词,变成了:
('h' '##u' '##g', 10), ('p' '##u' '##g', 5), ('p' '##u' '##n', 12), ('b' '##u' '##n', 4), ('h' '##u' '##gs', 5)
以此类推,最终我们会得到一个包含常见子词的词表,如:
['b', 'h', 'p', '##g', '##n', '##s', '##u','hugs', 'hu', 'pu', ''##gs']学到的合并规则:
-
##g+##s→##gs -
p+##u→pu -
h+##u→hu -
hu+##gs→hugs
1.4 编码过程
训练完成后,对新的单词bug进行分词的算法如下:
使用学到的合并规则进行编码:
步骤1:初始拆分 "bug" → ['b', '##u', '##g']
步骤2:应用合并规则 检查是否有可应用的规则:
-
b+##u?没有对应的合并规则 -
##u+##g?没有对应的合并规则
步骤3:最终编码 因为没有适用的合并规则,保持初始拆分: ['b', '##u', '##g']
对于新单词lower:
步骤1:初始字符级拆分
"lower" → ['l', '##o', '##w', '##e', '##r']
步骤2:应用合并规则
检查可能的合并:
-
l+##o?无对应规则 -
##o+##w?无对应规则 -
##w+##e?无对应规则 -
##e+##r?无对应规则
步骤3:最终编码
因为没有适用的合并规则,保持字符级拆分: "lower" → ['l', '##o', '##w', '##e', '##r']
综上所述,体现了WordPiece的优势:即使遇到完全没见过的单词,也能通过字符级回退进行编码 !理论上永远不会出现OOV(Out-of-Vocabulary)问题!
1.5 特殊符号
在WordPiece/BPE等子词分词器中,特殊符号(Special Tokens)起着关键作用。以下是常见特殊符号(Special Tokens)及其处理的总结:
1.5.1 常见符号
| 特殊符号 | 名称 | 用途 | 典型场景 | 示例 |
|---|---|---|---|---|
| UNK | Unknown Token | 表示词汇表中不存在的词 | 当输入无法拆分为任何子词时 | "鞲韫"→ "\[UNK"] |
| CLS | Classification Token | 用于分类任务的聚合表示 | 文本分类、句子匹配任务 | CLS Paris is capital SEP |
| SEP | Separator Token | 分隔句子或文本片段 | 多句子输入任务,如推理、问答 | CLS How old? SEP I'm 20 SEP |
| MASK | Mask Token | 在预训练中遮盖部分词,让模型预测被遮盖内容 | BERT的掩码语言模型训练 | "The MASK sat on mat." → 模型预测MASK为cat。 |
| PAD | Padding Token | 将输入填充到相同长度 | 批量训练时对齐序列长度。 | "Hello", "world", "\[PAD", "PAD"](填充长度4) |
| BOS | Beginning of Sequence | 标记序列的开始 | 自回归生成任务,如文本生成 | GPT输入:BOS Once upon a time... |
| EOS | End of Sequence | 标记序列的结束 | 文本生成终止、多轮对话结束。 | "Goodbye. EOS" |
1.5.2 关键说明
-
模型依赖性
-
BERT类模型:主要使用
[CLS],[SEP],[MASK],[PAD]。 -
GPT类模型:常用
[BOS],[EOS],[PAD]。
-
-
分词策略
[UNK]应尽量避免,WordPiece/BPE会优先拆分子词(如"happiness"→["happy", "##ness"])。
-
特殊符号的嵌入
- 这些符号在模型中有对应的嵌入向量,与普通词同等处理,但功能不同。
1.5.3 存在意义
-
结构化输入:明确序列边界(如SEP)和任务类型(如CLS)。
-
鲁棒性:处理变长输入(PAD)、未知词(UNK)。
-
任务适配:支持分类(CLS)、生成(EOS)、预训练(MASK)等不同需求。
1.5.4 其它特殊符号
GPT系列使用的BBPE分词器,其特殊符号更倾向于使用简洁的符号,并且在训练开始时就被永久地加入词汇表。
-
<|endoftext|>: 这是GPT系列中一个多功能的特殊符号。它同时充当:
-
文档分隔符:在训练时,用于拼接多个独立文档。
-
序列结束: 表示一个序列或回合的结束。
-
在聊天模型中,它常被用作"轮次"的分隔符。
-
系统、用户、助手角色标记: 在ChatGPT等对话模型中,会使用特殊的符号来标记对话中的不同角色,例如:
-
system: 表示系统提示。
-
user: 表示用户说的话。
-
assistant: 表示模型(助手)的回复。
这些符号帮助模型理解对话的轮次和上下文,从而生成符合其"助手"身份的回复。
1.6 小结
WordPiece 核心是把单词拆成有语义的子词(如 "unhappiness" 拆成 "un""happy""ness"),平衡词汇表大小与未登录词问题,是 BERT 等模型的核心分词方案,关键特点可简单概括为:
- 核心逻辑:不盲目合并高频子词对,而是优先合并 "能让训练数据概率(似然)最大化" 的对子,保证子词更贴合语义(比如优先合并 "##happy" 和 "##ness",而非随机高频组合);
- 关键标识:非单词开头的子词会加 "##" 前缀(如 "happiness" 拆成 "happy""##ness"),帮模型区分词边界;
- 优劣势:语义关联性强,适配 BERT 等上下文模型,但计算比 BPE 复杂(需算概率得分),且依赖初始字符拆分;
二、Unigram
与 BPE 和 WordPiece这两种常见的分词算法相比,Unigram 的工作方式恰恰相反:它首先构建一个庞大的词汇表,而后从词汇表中逐步删除词元 (token),直到达到预期的词汇表规模。
构建这个初始词汇表有几种方法:
-
选取已经分好词的单词中最常见的子串
-
在原始语料库上应用 BPE 算法,并设置一个较大的词汇表阈值。
在训练阶段的每一轮:
-
Unigram 算法都会根据当前词汇表计算整个语料库的损失值 (loss)。
-
对词汇表中的每个词元,算法会计算如果移除该词元,整体损失值会增加多少
-
并找出那些移除后损失增加最少的词元。
整个训练过程相当耗费计算资源,为加快训练速度,每次不只删除一个词元,而是会删除前p%造成损失增加最小的 的词元 (p 是超参数,通常设为 10% 或 20%)。这个过程会不断重复,直到词汇表缩小到目标大小。
2.1 基本思想
从大词汇表开始,逐步删除低概率的子词,保留最有效的组合。
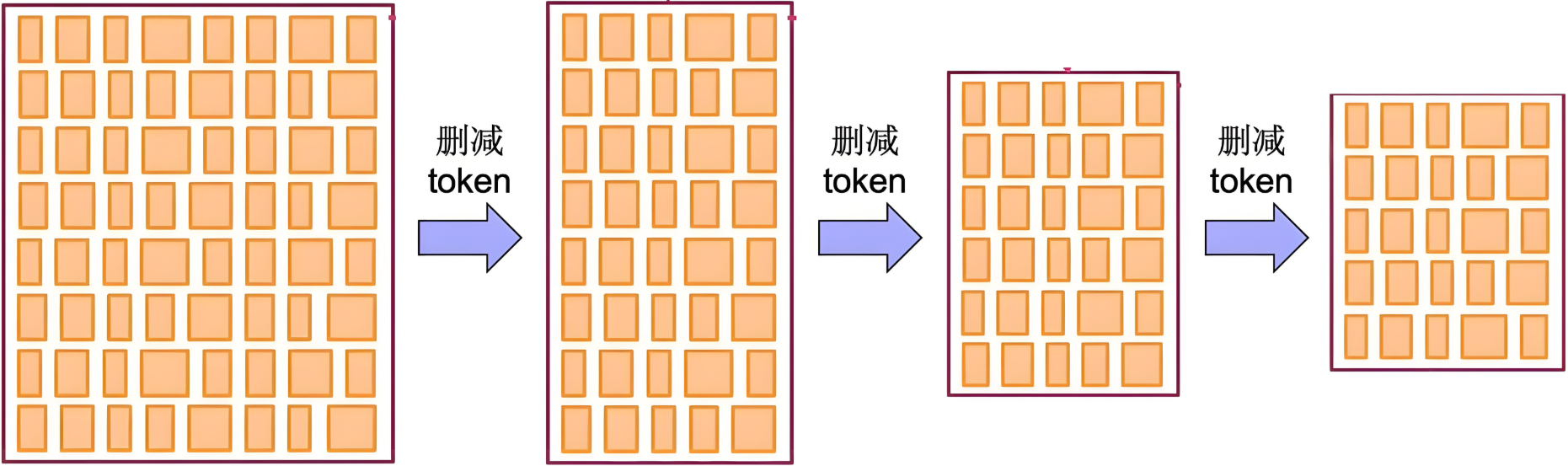 |
|---|
| 初始化一个很大的词表,然后通过算法删减为较小的高质量词表 |
2.2 初始化词表
Unigram从一个较大的初始词汇表开始,初始化方式:
-
使用所有单个字符作为初始词汇表
-
使用 BPE 算法先训练一个较大的词汇表
-
使用高频词和字符的组合
2.2.1 预料词频统计
对语料库进行词频统计:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5) 2.2.2 基本词表构建
基于语料库构建词表如下:
["h", "u", "g", "hu", "ug", "p", "pu", "n", "un", "b", "bu", "s", "hug", "gs", "ugs"]
[ 15, 36, 20, 15, 20, 17, 17, 16, 16, 4, 4, 5, 15, 5, 5 ]2.2.3 词表token频率
词元的概率是它在原始文本数据集中的出现频次除以词表中所有词元的总频次,从而确保所有概率之和为 1。
("h", 15/210) ("u", 36/210) ("g", 20/210) ("hu", 15/210) ("ug", 20/210) ("p", 17/210) ("pu", 17/210) ("n", 16/210) ("un", 16/210) ("b", 4/210) ("bu", 4/210) ("s", 5/210) ("hug", 15/210) ("gs", 5/210) ("ugs", 5/210) 2.3 算法过程
在逐步压缩词表大小的过程中,Unigram使用了"最小化损失增量"进行子词筛选和删除的策略,尽量保留对模型整体分词概率贡献最大的子词。
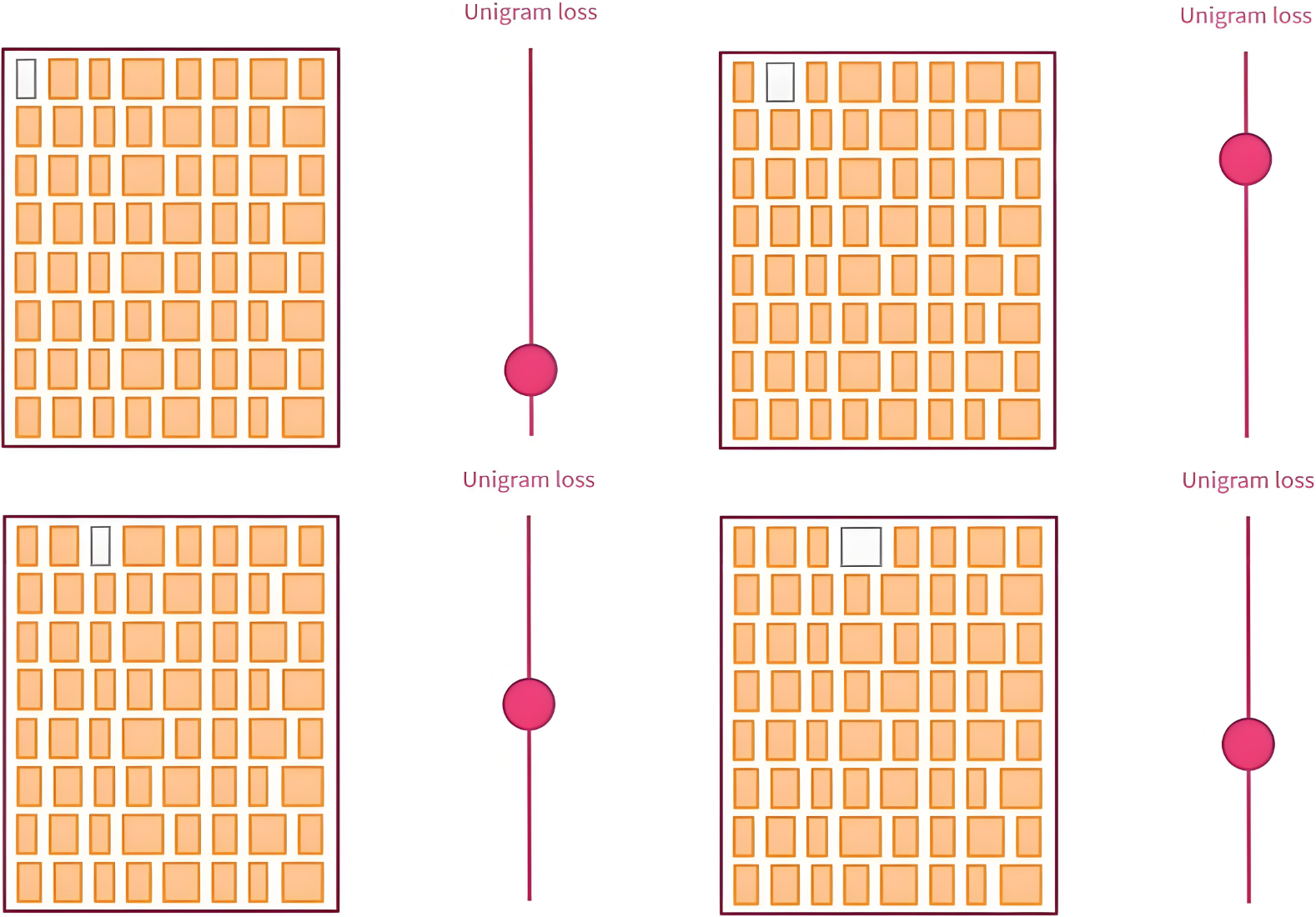 |
 |
|---|---|
| 模拟删除每个Token,并计算 unigram loss | 删除损失增量最小的前 10\% |
2.3.1 EM
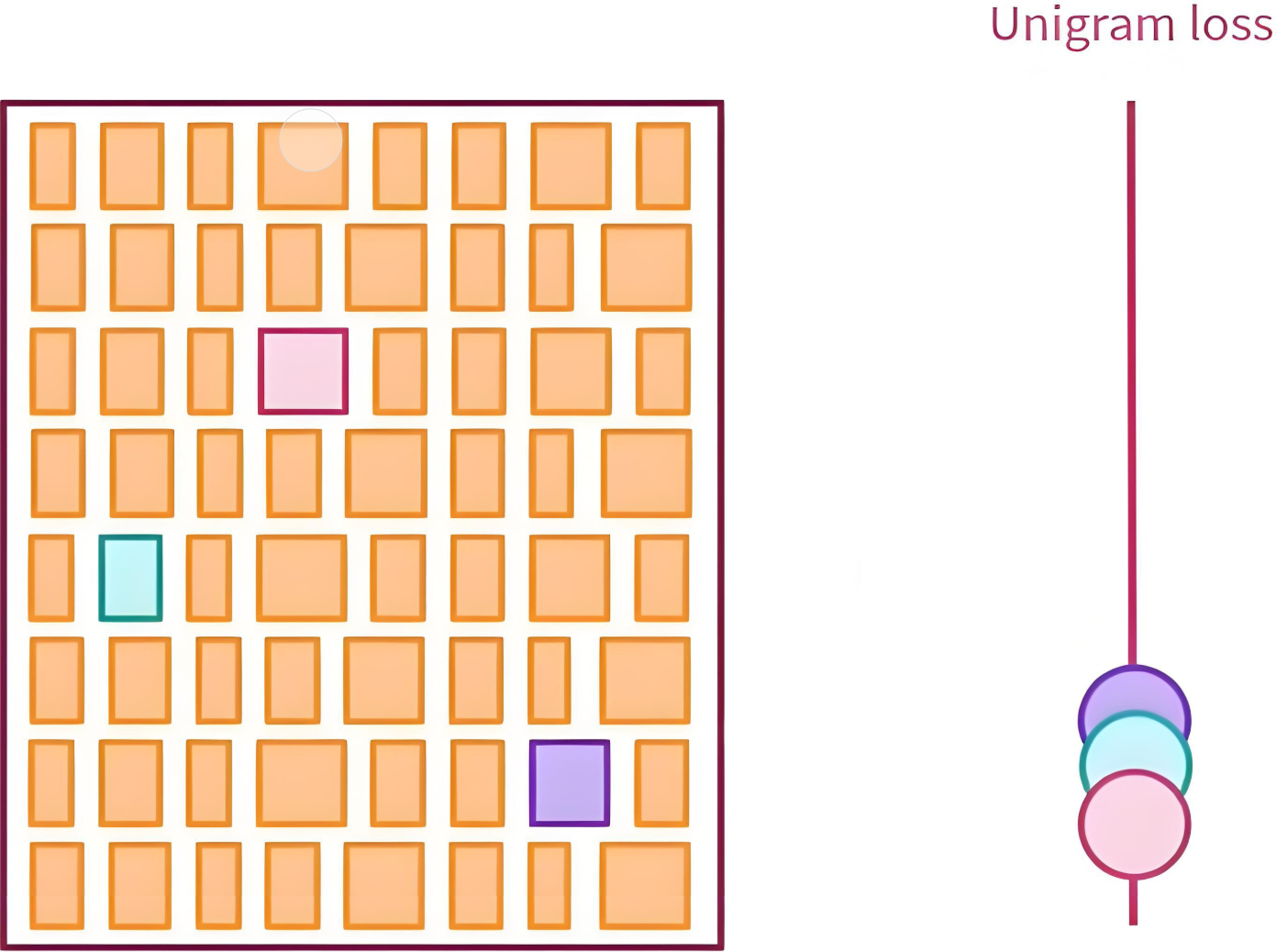
使用EM(期望最大化)算法训练子词概率:
-
unigram模型假设每个词都是独立的。
-
根据分词计算hug所有可能的概率:
\\textbf{h \\: u \\:g} \\: \\: : \\quad \\frac{15}{210} \\times \\frac{36}{210} \\times \\frac{20}{210} = 1.17 \\times 10\^{-3} \\\\ \\textbf{hu\\: g} \\: \\: : \\quad \\frac{15}{210} \\times \\frac{20}{210} = 6.8 \\times 10\^{-3} \\\\ \\textbf{h\\: ug} \\: \\: : \\quad \\frac{15}{210} \\times \\frac{20}{210} = 6.8 \\times 10\^{-3} \\\\ \\textbf{hug} \\: \\: : \\quad \\frac{15}{210} = 7.14 \\times 10\^{-2}
-
用 Viterbi 算法(动态规划)找出最大概率路径。Viterbi 算法参考:https://blog.csdn.net/ERAtime/article/details/148390734
S\^\* = \\arg\\max_S \\prod_{i=1}\^{n} P(w_i)
即找出概率最大的分词方案。
如果遇到概率相等的则随机选一个:
| Corpus | Splits | Scores |
|---|---|---|
| "hug", 10 | hug | 7.14e-02 |
| "pug", 5 | pu g | 7.71e-03 |
| "pun", 12 | pu n | 6.16e-03 |
| "bun", 4 | bu n | 1.45e-03 |
| "hugs", 5 | hug s | 0.17 |
说明:这里是根据sentencepiece算法实际使用的硬EM,即用 Viterbi 算法(动态规划)找出最大概率路径。
如果使用软EM计算逻辑更加复杂,需要计算所有分词可能的概率之和,这里不再介绍。
2.3.2 评估Loss
使用负对数最大似然,对所有可能切分路径的概率总和计算 loss,即:
\\text{Unigram loss} = - \\sum_{x \\in \\text{Corpus}} \\log P(x)
其中:P(x) = \max_{S \in \text{All Segmentations of } x} \prod_{w_i \in S} P(w_i)
于是就可以评估loss了:
10 \\times (-\\log(7.14 \\times 10\^{-2})) \\\\ + 5 \\times (-\\log(7.71 \\times 10\^{-3})) \\\\ + 12 \\times (-\\log(6.16 \\times 10\^{-3})) \\\\ + 4 \\times (-\\log(1.45 \\times 10\^{-3})) \\\\ + 5 \\times (-\\log(0.17)) \\\\ = \\mathbf{63.76}
2.3.3 模拟删除
对于词表中每个子词 w,假设将其删除,评估其对整体损失的影响:
-
模拟删除 w,重新运行EM,并得到新的 loss。
-
记录该子词的 "损失增量":
\\Delta L(w) = L_{\\text{new}} - L_{\\text{old}}
这是原始词表:
("h", 15/210) ("u", 36/210) ("g", 20/210) ("hu", 15/210) ("ug", 20/210) ("p", 17/210) ("pu", 17/210) ("n", 16/210) ("un", 16/210) ("b", 4/210) ("bu", 4/210) ("s", 5/210) ("hug", 15/210) ("gs", 5/210) ("ugs", 5/210)第一次迭代:
模拟删除 ug:20/210 ,那么 ug 的概率就是 0,于是就有了:
\\textbf{h \\: u \\:g} \\: \\: : \\quad \\frac{15}{210} \\times \\frac{36}{210} \\times \\frac{20}{210} = 1.17 \\times 10\^{-3} \\\\ \\textbf{hu\\: g} \\: \\: : \\quad \\frac{15}{210} \\times \\frac{20}{210} = 6.8 \\times 10\^{-3} \\\\ \\textbf{h\\: ug} \\: \\: : \\quad \\frac{15}{210} \\times 0 = 0 \\\\ \\textbf{hug} \\: \\: : \\quad \\frac{15}{210} = 7.14 \\times 10\^{-2}
最大概率路径得分:
| Corpus | Splits | Scores |
|---|---|---|
| "hug", 10 | hug | 7.14e-02 |
| "pug", 5 | pu g | 7.71e-03 |
| "pun", 12 | pu n | 6.16e-03 |
| "bun", 4 | bu n | 1.45e-03 |
| "hugs", 5 | hug s | 0.17 |
计算loss:
10 \\times (-\\log(7.14 \\times 10\^{-2})) \\\\ + 5 \\times (-\\log(7.71 \\times 10\^{-3})) \\\\ + 12 \\times (-\\log(6.16 \\times 10\^{-3})) \\\\ + 4 \\times (-\\log(1.45 \\times 10\^{-3})) \\\\ + 5 \\times (-\\log(0.17)) \\\\ = \\mathbf{63.76}
loss无变化,那就删除掉。
2.3.4 词表更新
这是更新后的词表:
("h", 15/190) ("u", 36/190) ("g", 20/190) ("hu", 15/190) ("p", 17/190) ("pu", 17/190) ("n", 16/190) ("un", 16/190) ("b", 4/190) ("bu", 4/190) ("s", 5/190) ("hug", 15/190) ("gs", 5/190) ("ugs", 5/190)然后基于新词表继续模拟删除: hu
\\textbf{h \\: u \\:g} \\: \\: : \\quad \\frac{15}{190} \\times \\frac{36}{190} \\times \\frac{20}{190} = 1.57 \\times 10\^{-3} \\\\ \\textbf{hu\\: g} \\: \\: : \\quad 0 \\times \\frac{20}{190} = 0 \\\\ \\textbf{h\\: ug} \\: \\: : \\quad \\frac{15}{190} \\times 0 = 0 \\\\ \\textbf{hug} \\: \\: : \\quad \\frac{15}{190} = 7.89 \\times 10\^{-2}
最大概率路径得分:
| Corpus | Splits | Scores |
|---|---|---|
| "hug", 10 | hug | 7.89e-02 |
| "pug", 5 | pu g | 9.42e-03 |
| "pun", 12 | pu n | 9.42e-03 |
| "bun", 4 | bu n | 1.77e-03 |
| "hugs", 5 | hug s | 0.17 |
计算loss:
10 \\times (-\\log(7.89\\times 10\^{-2})) \\\\ + 5 \\times (-\\log(9.42 \\times 10\^{-3})) \\\\ + 12 \\times (-\\log(9.42 \\times 10\^{-3})) \\\\ + 4 \\times (-\\log(1,77 \\times 10\^{-3})) \\\\ + 5 \\times (-\\log(0.17) \\\\ = \\mathbf{60.33}
2.3.5 继续EM
-
在剪枝后的词表上重新运行 EM 迭代几轮,使概率重新收敛。
-
如此反复,直到达到目标词表大小。
2.3.6 词表剪枝
词表剪枝 指的是在算法运行结束后,进一步清理和优化最终词表,从一个大型的、可能过拟合的词汇表中,系统地移除那些"不重要"或"低效用"的子词单元,从而得到一个更小、更高效、更健壮的词汇表。
常见的剪枝规则包括:
-
单字符词 :强制保留所有单字符词。这是为了保证任何单词最终都能被分解(OOV问题),所以通常不会剪枝单字符词。
-
频率过低:删除在训练语料中出现频率低于某个阈值的词。即使某个词根据似然损失计算不是最差的,但如果它只出现了一两次,也可能被剪掉以避免过拟合。
-
子串关系 :如果两个词存在包含关系(例如,"abc"和"abcd"),并且较短的词出现的频率远高于长的词,可能会考虑剪掉长的那个,因为它的增益不大。
2.4 小结
Unigram 是一种 "反向操作" 的子词分词算法,核心是从大词表中筛选高价值子词,关键特点简单总结为:
- 核心逻辑:和 BPE/WordPiece "从字符合并成子词" 的思路相反,它先建一个包含所有可能子词的超大初始词表,再反复删掉那些对整体语义损失影响最小的子词,直到词表大小符合要求。
- 分词方式:对一句话有多种拆分可能,比如 "今天真高兴" 可拆成 "今天 真 高兴" 或 "今 天 真 高 兴",最终用算法选概率最高的组合。
- 优劣势:灵活性强,能适配多语言和小语种场景,但训练时要反复计算概率,比 BPE 复杂且耗时。
三、SentencePiece
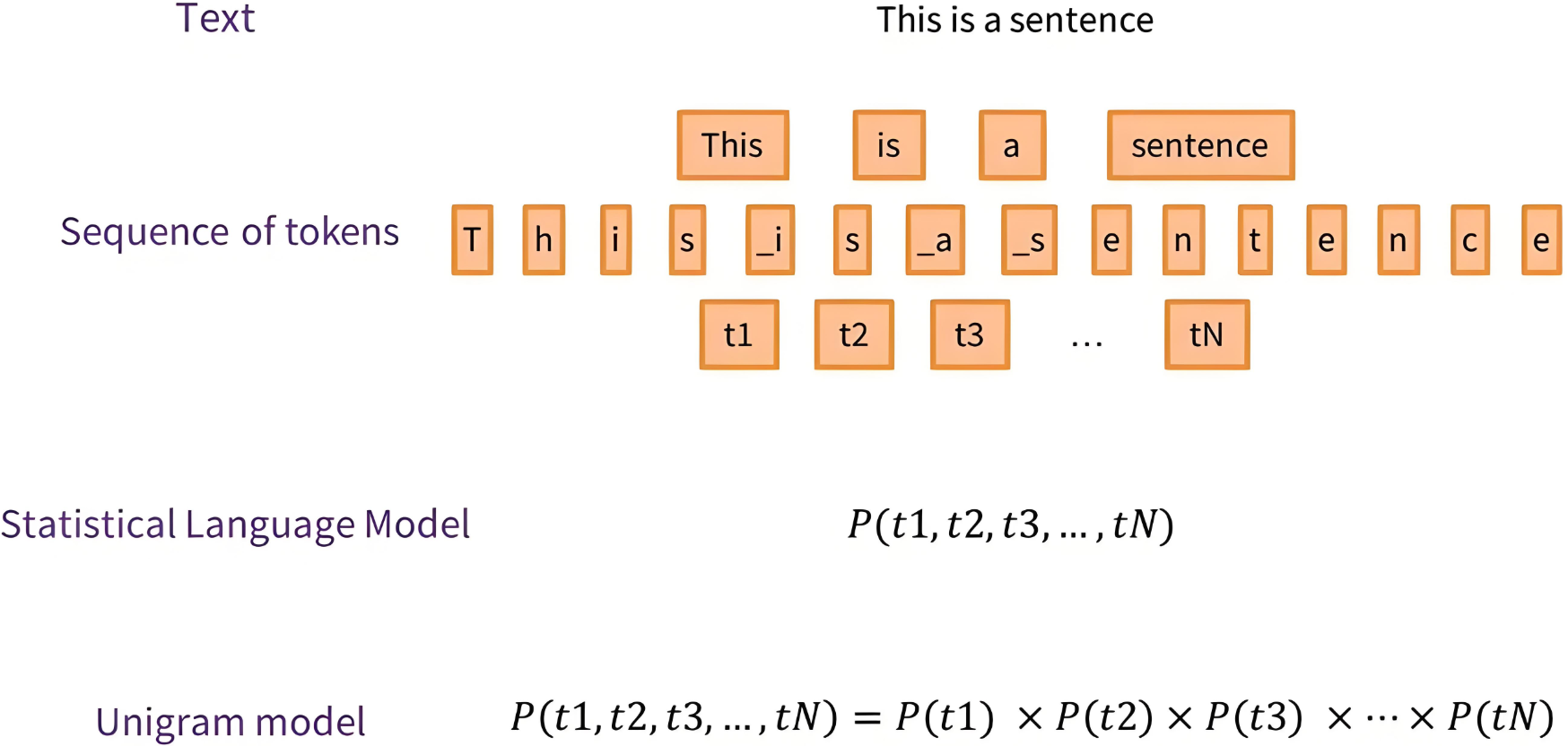
把一个句子当成一个词来分成多个subword。
SentencePiece是一种子词分词算法,广泛用于NLP预处理阶段,尤其适用于如BERT、T5、GPT等模型的训练数据构建。它的核心思想是:不依赖于空格等人为定义的分词边界,而是通过概率建模自动学习最优的子词单元,以提升模型对OOV和低频词的鲁棒性。
3.1 BWU缺点
-
BPE、WordPiece、Unigram假设输入文本使用空格来分隔,但并非所有语言都如此,如中文、韩文、日文等。
-
可以使用特定语言的pre-tokenizer分词,但每种语言都要学习一个,不太通用。
3.2 基本思想
-
统一处理:SentencePiece将整个文本视为一个字符序列,包括空格,避免语言特有的预处理步骤。
-
学习子词:SentencePiece使用 Unigram 或 BPE 算法自动学习最优"子词"词汇表,这些子词诸如字符、常见词根、词缀等。
-
概率建模:如Unigram会学一个子词表,计算句子在不同子词组合下的概率,并保留能最大化语料可能性的子词拆分方式。
-
句子表示:训练好模型后,可将任意输入句子拆分成词表中的子词序列,这就避免了OOV问题。
3.3 工作流程
-
替换空格:将文本中的空格替换为特殊符号 ▁。现在文本变成了一个长的、包含 ▁ 的字符串。
-
输入: "I love machine learning."
-
转换: "I▁love▁machine▁learning."
-
-
字符拆分:将整个字符串分解成单个字符的列表(包括 ▁)。
-
分解:
['I', '▁', 'l', 'o', 'v', 'e', '▁', 'm', 'a', 'c', 'h', 'i', 'n', 'e', '▁', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', '.']
-
-
应用子词算法(以BPE为例):
-
统计所有相邻字符对的频率。
-
合并最高频的对,比如 'l' 和 'o' -> 'lo'。
-
更新序列为
['I', '▁', 'lo', 'v', 'e', '▁', 'm', 'a', 'c', 'h', 'i', 'n', 'e', '▁', 'l', 'e', 'a', 'r', 'n', 'i', 'n', 'g', '.'] -
不断重复此过程,合并出如 'lo' 和 've' -> 'love','le' 和 'ar' -> 'lear',最终 'lear' 和 'n' -> 'learn' 等。
-
-
生成词汇表:经过成千上万次合并后,我们会得到一个包含基础字符和所有高频片段的最终词汇表。例如,词汇表可能包含:
["I", "▁", "love", "▁m", "achine", "▁l", "earn", "ing", ".", ...] -
编码与解码:
-
编码(Tokenize):对于一个新句子,先进行空格替换和字符拆分,然后应用学习到的合并规则,贪婪地尝试用词汇表中最大的可能单元来切分它。
-
输入: "I learn." -> "I▁learn."
-
分词结果: "I", "▁l", "earn", "." (假设 "▁l" 和 "earn" 在词汇表中)
-
-
解码(Detokenize):将分词结果简单连接起来:"I" + "▁l" + "earn" + "." = "I▁learn.",然后将 ▁ 替换回空格,得到 "I learn."。
-
3.4 案例助解
原始语料:
我喜欢机器学习。我也喜欢深度学习。以BPE算法为例
3.4.1 步骤 1
将原文中可能存在的英文空格替换为特殊符号 ▁(U+2581)。在句首添加下划线 _ 表示单词边界
"我喜欢机器学习。我也喜欢深度学习。" → ["_我喜欢机器学习。我也喜欢深度学习。"]初始序列:
[▁, 我, 喜, 欢, 机, 器, 学, 习, 。, 也, 喜, 欢, 深, 度, 学, 习, 。]3.4.2 步骤 2
将文本按字符分割,得到的子词词表:
[▁, 我, 喜, 欢, 机, 器, 学, 习, 。, 也, 深, 度]3.4.3 步骤 3
-
第一轮合并 :统计发现
"学"和"习"出现了2次,频率最高。合并它们。-
新序列:
['▁', '我', '喜', '欢', '机', '器', '学习', '。', '我', '也', '喜', '欢', '深', '度', '学习', '。'] -
新词汇表新增:
学习
-
-
第二轮合并 :
"喜"和"欢"出现了2次,合并它们。-
新序列:
['▁', '我', '喜欢', '机', '器', '学习', '。', '我', '也', '喜欢', '深', '度', '学习', '。'] -
新词汇表新增:
喜欢
-
-
第三轮合并 :
"机"和"器"出现了1次(但其他对出现频率也不高),合并它们。-
新序列:
['▁', '我', '喜', '欢', '机器', '学习', '。', '我', '也', '喜', '欢', '深', '度', '学习', '。'] -
新词汇表新增:
机器
-
-
第四轮合并 :
"深"和"度"出现了1次,合并它们。-
新序列:
['▁', '我', '喜欢', '机器', '学习', '。', '我', '也', '喜欢', '深度', '学习', '。'] -
新词汇表新增:
深度
-
-
停止 :假设词汇表大小设置得较小,训练到此为止。最终词汇表包含了单字 和高频组合 :
['▁', 我, 喜, 欢, 机, 器, 学, 习, 。, 也, 深, 度, 学习, 机器, 喜欢, 深度]
3.4.4 步骤 4
对新句子进行编码(Tokenize):
-
输入:
"你喜欢深度学习吗?" -
处理流程:算法会尝试用词汇表中最长的可能单元来切分。
-
"你"-> 不在词汇表?不,"你"会被视为一个未知字符(UNK),因为它在训练时没见过。这说明我们的训练语料太小了。在实际大规模语料上,"你"这种常见字肯定在词汇表里。我们假设它在。 -
"喜欢"-> 在词汇表中,匹配成功。 -
"深度"-> 在词汇表中,匹配成功。 -
"学习"-> 在词汇表中,匹配成功。 -
"吗"-> 在词汇表中(假设)。 -
"?"-> 在词汇表中(假设)。
-
-
最终分词结果:
["你", "喜欢", "深度", "学习", "吗", "?"]
3.5 小结
SentencePiece是谷歌推出的子词分词工具包,核心是给 BPE、Unigram 等经典算法套上 "通用外壳",关键特点简单说:
- 核心定位:不发明新逻辑,而是把 BPE、Unigram 等算法打包成易用工具,能直接选 "SentencePiece 的 BPE 模式" 或 "Unigram 模式" 训练分词模型。
- 最大亮点:彻底不依赖空格,直接把整段文本当字符流处理(比如中文不用先分词),还会用 "▁" 标记词开头,完美适配中文、日文等无空格语言。
- 关键优势:支持多语言混合处理(如中英混排文本),分词后能精准还原原始内容,还能手动添加不可拆分的专业术语(如 "机器学习")。
3.6 代码实现
SentencePiece 是一个独立的库 :它并不是 PyTorch 内置的模块。你需要先安装和使用 sentencepiece 库来训练 和使用 分词器模型(.model 文件)。
安装 SentencePiece
pip install sentencepiece数据准备
准备一个纯文本文件(例如 corpus.txt)作为训练数据
# 创建示例语料库文件
corpus_content = """
自然语言处理是人工智能领域的一个重要方向。
机器学习让计算机能够自动学习和改进。
深度学习基于神经网络,能够处理复杂模式识别。
Python是一种流行的编程语言,广泛用于AI开发。
TensorFlow和PyTorch是两大主流深度学习框架。
Hello world! This is a sample text for training.
The quick brown fox jumps over the lazy dog.
Artificial intelligence is changing the world.
中文和English混合的文本是很常见的场景。
我喜欢用Python写代码,因为它很强大。
北京是中国的首都,Beijing is the capital of China.
深度学习模型需要大量的training data。
神经网络neural network由多个层组成。
数据预处理data preprocessing非常重要。
标点符号测试:,。!?;:“”‘’()【】《》
数字测试:123 456 7890 3.14 2023年
特殊符号:@#$%^&*()_+-=[]{}|;:,.<>?
这是一个较长的段落,用于测试模型处理连续文本的能力。自然语言处理技术正在快速发展,越来越多的应用场景被开发出来。从智能客服到机器翻译,从文本生成到情感分析,NLP技术无处不在。我们需要更好的模型来理解和生成人类语言。
样本重复出现一些重要词汇:模型、训练、数据、学习、智能、处理、语言、网络、算法、框架、开发、应用、分析、生成、识别、技术。
结束语:这份语料库虽然很小,但包含了多种语言元素,适合演示SentencePiece的训练过程。在实际项目中,你需要使用大规模的真实文本数据来训练有效的模型。
"""
# 将内容写入文件
with open('corpus.txt', 'w', encoding='utf-8') as f:
f.write(corpus_content.strip())
print("corpus.txt 文件已生成成功!")训练你自己的 SentencePiece 模型
import sentencepiece as spm
# 定义训练参数
spm.SentencePieceTrainer.train(
input='corpus.txt', # 你的训练语料文件
model_prefix='sp_model', # 输出模型文件的前缀(将生成 sp_model.model 和 sp_model.vocab)
vocab_size=1000, # 词汇表大小
model_type='bpe', # 算法类型:可选 'bpe', 'unigram'等
character_coverage=1.0, # 字符覆盖度,对于中文字符集建议设为 1.0
pad_id=0, # 将这些特殊Token的ID固定下来,方便与PyTorch配合
unk_id=1,
bos_id=2,
eos_id=3,
pad_piece='[PAD]', # 定义这些特殊Token的字符串表示
unk_piece='[UNK]',
bos_piece='[BOS]',
eos_piece='[EOS]'
)
# 训练完成后,你会得到两个文件:
# - sp_model.model: 模型文件(用于加载分词器)
# - sp_model.vocab: 词汇表文件(可查看词汇)使用训练好的模型进行分词
sp = spm.SentencePieceProcessor()
sp.load('sp_model.model')
# 示例文本
text = "我喜欢用Java写代码,因为它很强大。"
# 编码为 tokens
tokens = sp.encode_as_pieces(text)
print("Tokens:", tokens)
# Tokens: ['▁我喜欢用', 'J', 'a', 'v', 'a', '写代码', ',', '因为它很强大', '。']
# 编码为 IDs (这个才是要送入PyTorch的)
ids = sp.encode_as_ids(text)
print("IDs:", ids)
# IDs: [365, 1, 741, 883, 741, 265, 744, 401, 738]
# 解码
original_text = sp.decode_ids(ids)
print("Original:", original_text)
# Original: 我喜欢用 ⁇ ava写代码,因为它很强大。
# 查看词汇表大小(这在定义PyTorch Embedding层时至关重要)
vocab_size = sp.get_piece_size()
print(f"Vocabulary size: {vocab_size}") # 1000说明:
1.character_coverage=1.0
-
作用:字符覆盖度,控制未知字符的处理
-
说明:
-
1.0:覆盖所有字符(适合中文、日文等字符集) -
0.9995:默认值,适合英文等小字符集 -
对于中文,每个字符都承载语义信息,丢失任何字符都可能导致意义改变,因此必须设置为 1.0 来保证字符完整性。
-
2.特殊符号ID
pad_id=0, # 填充Token ID
unk_id=1, # 未知Token ID
bos_id=2, # 句子开始Token ID
eos_id=3, # 句子结束Token ID-
作用:固定特殊Token的ID编号
-
重要性:与深度学习框架(PyTorch/TensorFlow)配合时必需
-
行业标准:通常采用这个编号顺序
pad_piece='[PAD]', # 填充符号
unk_piece='[UNK]', # 未知词符号
bos_piece='[BOS]', # 句子开始符号
eos_piece='[EOS]' # 句子结束符号-
作用:定义这些特殊Token的字符串表示
-
兼容性:与Hugging Face等库的标准保持一致
3.在代码中IDs: 365, 1, 741, 883, 741, 265, 744, 401, 738,其中第二个元素的ID为1,在 SentencePiece 中,1 通常是 [UNK] (Unknown) Token 的默认 ID,即模型中的unk_id=1。表示编码器在编码时,无法将文本中的某些部分映射到词汇表中的已知 Token,于是用 [UNK] 来代替。
4.在解码时,值1相当于遇到了一个无法映射回任何已知字符或字符串的 ID,则使用?表示,它是一个可视化占位符,向用户清晰地表明这里有一个解码错误。
四、如何选择
-
BPE/WordPiece:适合通用场景,BPE更简单,WordPiece更注重语义。
-
Unigram:需要概率化分词时使用。
-
SentencePiece:处理非空格分隔语言(如中文)或需要端到端分词时。
技术分享是一个相互学习的过程。关于本文的主题,如果你有不同的见解、发现了文中的错误,或者有任何不清楚的地方,都请毫不犹豫地在评论区留言。我很期待能和大家一起讨论,共同补充更多细节。