最近,在AI顶会ICLR 2026的Open Review阶段,一篇匿名提交的论文 《 SAM 3: Segment Anything with Concepts 》 引发网友广泛关注。
对于AI圈的家人们来说,ICLR(International Conference on Learning Representations)无疑是每年必须关注的最重要顶会之一。而这篇论文的出现无疑将会引爆讨论。
SAM 3 为何震撼?
对SAM系列熟悉的朋友应该知道,前两个版本 SAM 与 SAM 2 均由 Meta 推出,对于 SAM 3 大家也是纷纷猜测,这篇论文出自 Meta,毕竟文风和 Meta 以前发布的论文非常相似。而且发布时间节点上,这篇论文的出现也几乎完美契合 Meta 的节奏。
- SAM 1(2023年4月)
获得当年 ICCV 最佳论文提名,将图像分割这个专业任务,变成了像"切水果"一样简单交互。用户通过点、框等提示,就能从任何图片中精准分割出任何物体,开启了提示式分割的新纪元。并且被誉为 CV 领域的「GPT-3 时刻」。
- SAM 2(2024年7月)

二代模型在继承SAM 1所有能力的基础上,实现了对视频的实时分割与追踪。它将静态图像与动态视频的分割融为一体,让"视频抠图"变得轻而易举。
这两代模型都引发了圈内很大的轰动,已经强大到足够突破传统 CV 模型的能力天花板,而如今,时隔一年,那么这次 SAM 3 又会带来什么新进展呢?
SAM 3 带来"概念分割"
SAM 3论文中定义了一个全新的任务:Promptable Concept Segmentation(PCS ,可提示概念分割)。
一句话概括PCS: 给定一张图或一段短视频,以及一个由简短名词短语(如"黄色校车")或图像示例定义的概念,模型需要检测、分割并追踪画面中所有匹配该概念的物体实例。

- 这与SAM 1的文本功能有何不同?
论文明确指出,SAM 1的文本提示"并未被完全开发"。其核心仍是基于视觉提示分割单个实例。而SAM 3实现了从"一"到"多"的根本性跨越,真正让模型学会了基于语言概念进行全局视觉理解。
SAM 3如何实现这一切?
为了实现PCS这一复杂任务,SAM 3在架构上进行了大刀阔斧的改革。
- 解耦的架构设计:检测与追踪各司其职
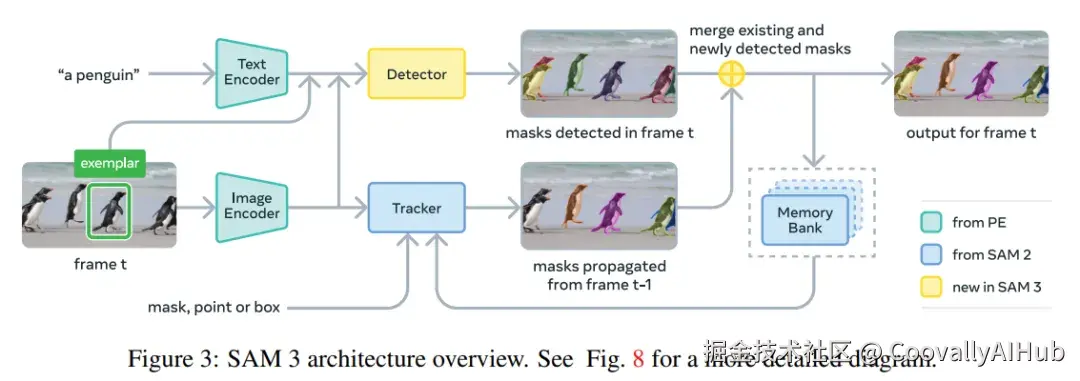
SAM 3的架构由一个检测器(Detector) 和一个追踪器(Tracker) 组成,二者共享一个强大的视觉主干网络(Perception Encoder)。
- 检测器: 身份无关,只负责在单帧图像中找出所有符合文本/示例概念的目标。
- 追踪器: 继承自SAM 2,核心职责是在视频序列中维持物体的身份一致性。
这种"术业有专攻"的设计,有效避免了任务目标之间的冲突,让模型在图像级识别和视频级追踪上都能达到最佳状态。
- "灵魂"设计:Presence Token(存在性令牌)

这是SAM 3一项堪称"点睛之笔"的创新。在开放词汇检测中,让每个检测框同时负责"识别是什么"和"定位在哪里"非常困难。
SAM 3引入了一个全局的Presence Token,专门用于预测"目标概念是否存在于画面中"。而每个检测框只需专注于解决"如果概念存在,我是不是其中一个实例的位置"这个更简单的定位问题。
最终得分 = 存在性分数 × 定位分数
这种方法极大地解耦了识别与定位,显著提升了模型在复杂场景下的鲁棒性和准确率。
- 强大的数据引擎:Scale is All You Need的背后
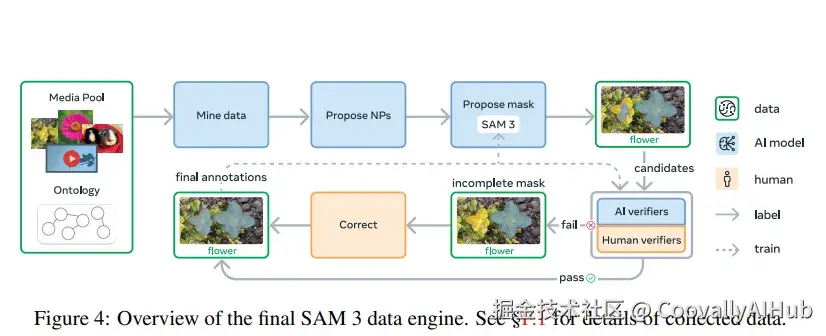
任何一个顶尖模型的诞生,都离不开高质量、大规模的数据。SAM 3构建了一个高效的人机协作数据引擎,其流程如下:
- 媒体与概念挖掘: 从海量、多样的图像视频库中,利用LLM和精心构建的SA-Co ontology(包含2240万个节点的概念本体) 来挖掘名词短语。
- 掩码提议: 使用SAM 3自身生成候选分割掩码。
- AI验证: 微调LLaMA模型作为"AI审核员",自动进行掩码质量验证和完整性检查,效率超越人类。
- 人工校正: 人类标注员只需专注于AI难以处理的失败案例。
通过这个引擎,团队构建了史上最大的高质量分割数据集SA-Co,包含400万个独特概念,为SAM 3的卓越性能奠定了坚实基础。
实验结果
在零样本设置下,SAM 3 在封闭词汇数据集 COCO、COCO-O 和 LVIS 的边界框检测任务中具有竞争力,在 LVIS 掩码任务上表现显著更好。
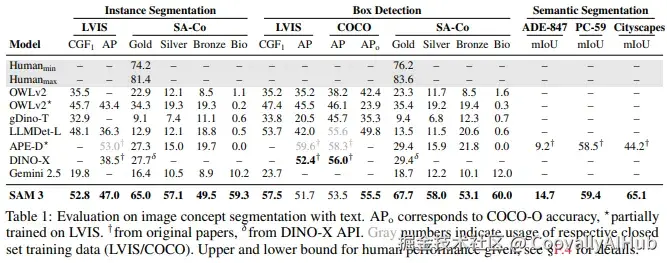
图像分割上,SAM 3在LVIS数据集上的零样本mask AP达到47.0,远超之前的SOTA模型。在其提出的SA-Co基准上,其CGF₁指标更是达到最强基线的2倍以上。
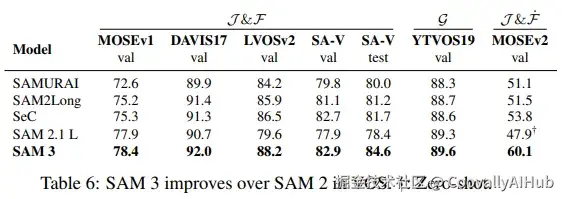
在视频分割上,SAM 3同样全面超越SAM 2,尤其在极具挑战性的MOSEv2数据集上,性能提升超过12个点。
同时,模型在单个 H200 GPU 上处理一张有超过 100 个物体的图像仅需 30 毫秒 。
SAM 3 Agent与"组合式AI"
SAM 3的意义远不止于一个更强大的分割模型。研究者将其与多模态大模型(MLLM)结合,构建了SAM 3 Agent。


在这个范式中:
- MLLM是"大脑",负责理解复杂指令、规划任务步骤、进行逻辑推理。
- SAM 3是"眼睛"和"手",负责执行精确的视觉感知和分割任务。
例如,当接到指令"分割出图中坐着但手里没拿礼物盒的人"时:
- MLLM将指令分解为"找出所有人"和"找出所有礼物盒"。
- MLLM调用SAM 3执行这两个子任务。
- MLLM对返回的掩码进行空间和逻辑推理,找出最终目标。
结果是: 这种组合在零样本情况下,就在ReasonSeg、OmniLabel等多个需要复杂推理的分割基准上超越了专门优化的模型。
这清晰地预示了一个 "组合式AI" 的未来:通过将SAM 3这类强大的垂直领域模型作为基础工具,由MLLM作为调度中枢,我们可以灵活组合出能够解决任意复杂任务的智能体。
争议与思考
尽管SAM 3表现惊艳,但Open Review的评论区也出现了不少冷静的质疑声。这些声音主要围绕两点:
- "概念分割"并非新概念?
有评论者犀利地指出,根据文本描述分割物体的任务,在学术界早已有之,并被广泛称为 "指代分割"。因此,他们认为SAM 3更像是给一个已有的研究领域换上了"Promptable Concept Segmentation"这个新名字,并利用Meta的工程和数据优势进行了大规模包装和实现,其核心思想并非从零开始的颠覆。
- Meta 是在"追赶"开源社区?
另一种代表性的观点认为,Meta 此举更像是在"追赶"开源社区的步伐。因为在此之前,开源社区早已通过"组合模型" 的方式实现了类似功能------例如,用一个开源的开放词汇检测模型(如OWL-ViT或GroundingDINO)生成边界框,再将其输入SAM 1或SAM 2来生成掩码。评论认为,SAM 3无非是将这个"流水线"集成进一个统一的、端到端的模型中,提升了效率和性能,但功能上并无本质不同。
面对这些质疑,我们应如何看待SAM 3的价值?
它或许不是那个从零到一的"发明者",但它极有可能是那个从"可用"到"好用"的定义者。
对于学术界,质疑是健康的,它推动我们更严谨地思考创新的边界。但SAM 3通过一个统一的架构,在规模和性能上将其推向了新的高度,并提出了更清晰的任务定义和评估基准,这本身就是一种贡献。
对于产业界和开发者,无论其思想是否绝对新颖,一个端到端的、高性能的、统一解决该问题的模型,其价值远超一个需要拼凑、调试多个模型的复杂流程。SAM 3降低了技术使用的门槛和成本。
最后,回到那个"组合式AI"的未来。SAM 3与MLLM组成的Agent确实与开源社区的思路异曲同工,但这也印证了模型协作是未来的趋势。
所以,这场争论的答案或许不是非此即彼的。它提醒我们,在AI领域,卓越的集成与实现,本身就是一种强大的创新。
论文地址
bash
论文链接:https://openreview.net/forum?id=r35clVtGzw