一、单链表初步了解
1.1、概念与结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
逻辑结构:线性的
物理结构:不一定是线性的
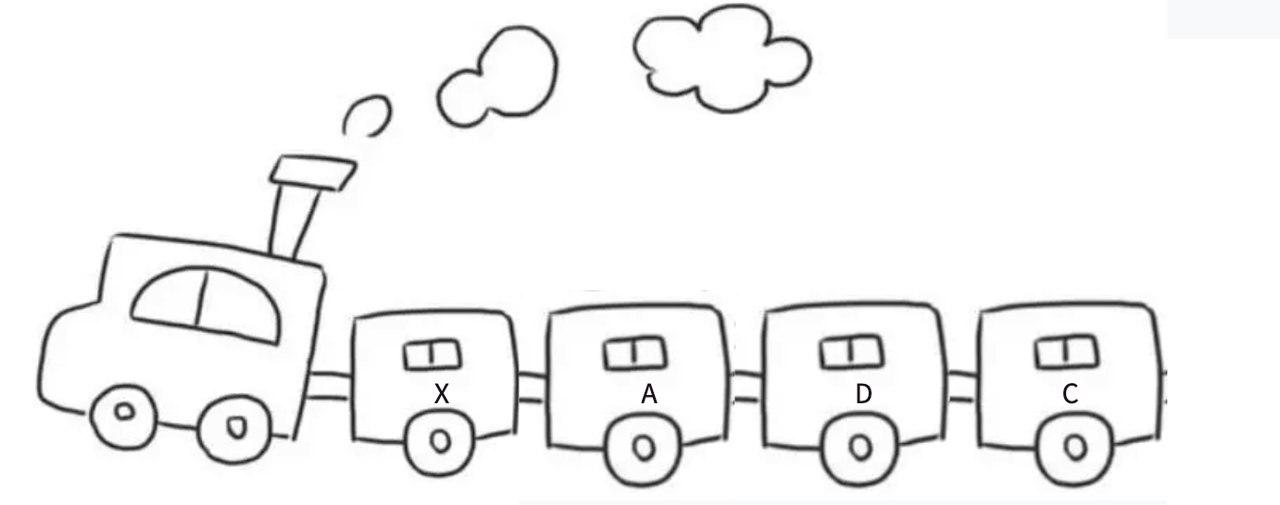
淡季时车次的车厢会相应减少,旺季时车次的车厢会额外增加几节。只需要将火车里的某节车厢去掉 / 加上,不会影响其他车厢,每节车厢都是独立存在的。
在链表里,每节 " 车厢 " 是什么样的呢?

链表是由一个一个结点组成的
1.1.1、结点
与顺序表不同的是,链表里的每节 "车厢" 都是独立申请下来的空间,我们称之为 "结点"。
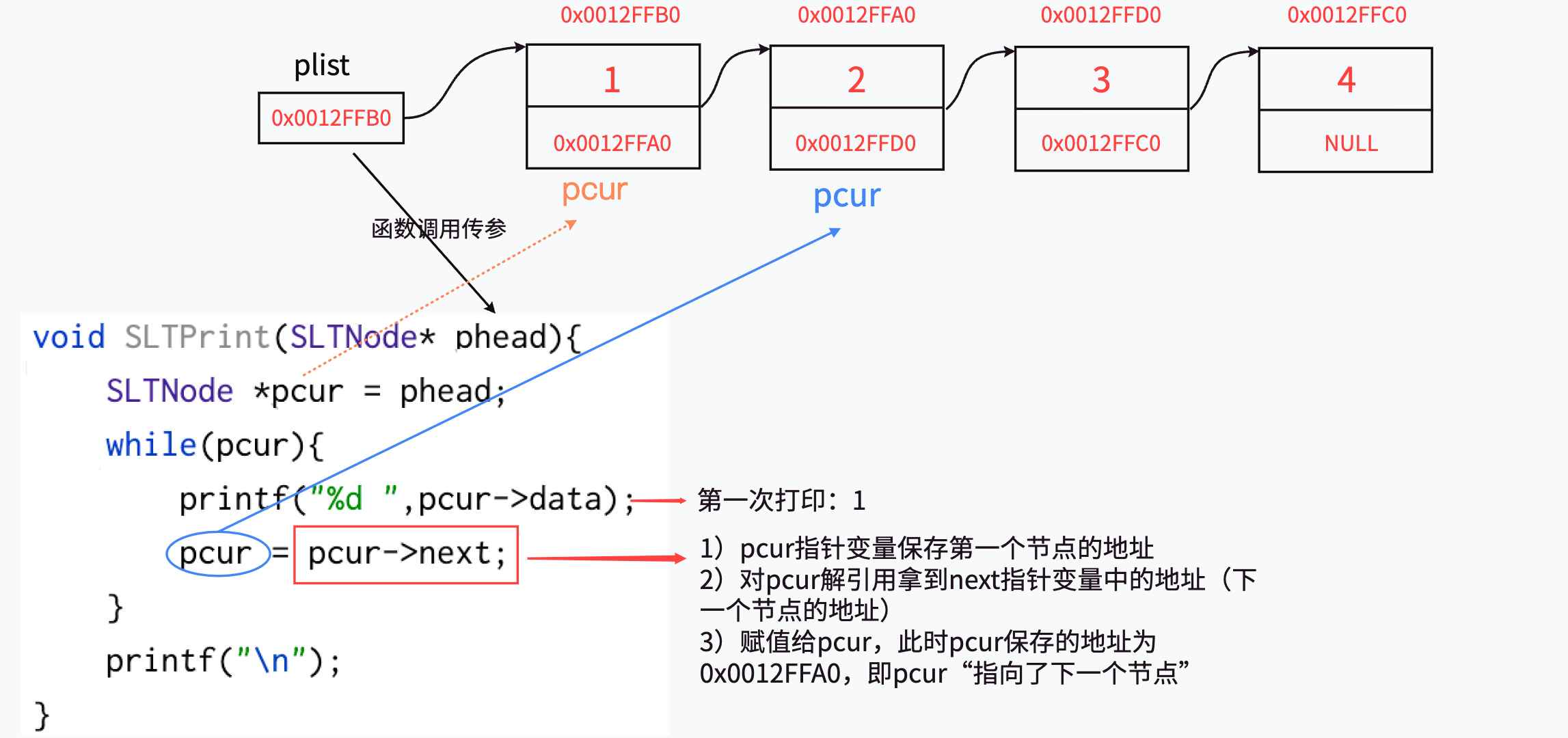
结点的组成主要有两个部分:当前结点要保存的数据和保存下⼀个结点的地址(指针变量)。图中指针变量 plist 保存的是第⼀个结点的地址,我们称 plist 此时 "指向" 第一个结点,如果我们希望 plist "指向" 第二个结点时,只需要修改 plist 保存的内容为 0x0012FFA0。
链表中每个结点都是独立申请的(即需要插入数据时才去申请一块结点的空间),我们需要通过指针变量来保存下一个结点位置才能从当前结点找到下一个结点。
1.1.2、链表的性质
- 链式结构逻辑上连续(即从逻辑角度,数据是依次连接的),但物理存储(实际内存分布)不一定连续。
- 链表的结点(组成链表的单个单元)通常是从堆内存中申请的。
- 堆内存的分配是遵循一定策略的,每次申请的空间可能连续,也可能不连续。
结合前面学到的结构体知识,我们可以给出每个结点对应的结构体代码:
假设当前保存的结点为整型:
cpp
struct SListNode
{
int data; //结点数据
struct SListNode* next; //指针变量⽤保存下⼀个结点的地址
};当我们想要保存一个整型数据时,实际是向操作系统申请了一块内存,这个内存不仅要保存整型数 据,也需要保存下一个结点的地址(当下一个结点为空时保存的地址为空)。当我们想要从第一个结点走到最后一个结点时,只需要在当前结点拿上下一个结点的地址就可以了。
1.1.3、链表的打印
给定的链表结构中,如何实现结点从头到尾的打印?
思考:当我们想保存的数据类型为字符型、浮点型或者其他自定义的类型时,该如何修改?
二、实现单链表(重点)
2.1、SList.h
cpp
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//链表的结构
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;//指向下一个结点的地址
//这里不可以写成SLTNode* next
//因为C语言编译器是向上编译的,他会向上去找为什么这样写,找不到
}SLTNode;
//打印链表
void SLTPrint(SLTNode* phead);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDestroy(SLTNode** pphead);2.2、SList.c
cpp
#include"SList.h"
//打印链表
void SLTPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur != NULL)
{
printf("%d -> ", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
//申请新结点
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//一级指针的地址,pphead要是都为空一级指针则解引不了
//我们要先申请一块新的结点空间(申请新结点)
SLTNode* newnode = SLTBuyNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//我要找到之前链表的尾结点
SLTNode* ptail = *pphead;
while (ptail->next != NULL)
{
ptail = ptail->next;
}
//找到了尾结点,将newnode赋给ptail
ptail->next = newnode;
}
}
//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//一级指针的地址,pphead要是都为空一级指针则解引不了
//申请新结点
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
//phead代表的是第一个结点,我们为这个链表赋予了一个新的结点在前
//phead位置也要换到最前面
*pphead = newnode;
}
//尾删
void SLTPopBack(SLTNode** pphead)
{
//链表为空不能删除
//第一个结点的地址不能为空,即*pphead不能为空
assert(pphead && *pphead);
//链表只有一个结点的情况
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;//prev是尾结点的前一个结点
SLTNode* ptail = *pphead;//ptail就是尾结点
while (ptail->next != NULL)
{
prev = ptail;
ptail = ptail->next;
}
prev->next = NULL;
free(ptail);
ptail = NULL;
}
}
//头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
//定义一个指针用来存头结点的下一个结点
SLTNode* next = (*pphead)->next;
free(*pphead);//free头结点
*pphead = next;//头结点就变成了next指针的结点
}
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* pcur = phead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
//未找到
return NULL;
}
//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead && pos);
SLTNode* newnode = SLTBuyNode(x);
//pos指向头结点,需要特殊处理
if (pos == *pphead)
{
//头插
SLTPushFront(pphead, x);
}
else
{
//找pos前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
//我们根据pos可以找到他的下一个结点,所有不需要去遍历
assert(pos);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && pos);
//如果pos是头结点就是头删
if (pos == *pphead)
{
//头删
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
//删除pos之后的结点
void SLTEraseAfter(SLTNode* pos)
{
assert(pos && pos->next);
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}
//销毁链表
void SListDestroy(SLTNode** pphead)
{
assert(pphead);
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}2.3、test.c
cpp
#include"SList.h"
void test01()
{
//创建一个链表
SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));
SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));
//给每一个结点赋个值
node1->data = 1;
node2->data = 2;
node3->data = 3;
node4->data = 4;
//保存下一个结点的地址
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
SLTNode* plist = node1;
//打印链表
SLTPrint(plist);
}
void test02()
{
//创建空链表
SLTNode* plist = NULL;
////尾插
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPrint(plist);
////头插
//SLTPushFront(&plist, 1);
//SLTPrint(plist);
//SLTPushFront(&plist, 2);
//SLTPrint(plist);
//SLTPushFront(&plist, 3);
//SLTPrint(plist);
//SLTPushFront(&plist, 4);
//SLTPrint(plist);
//尾删(假设现在有1 2 3 4)
/*SLTPopBack(&plist);
SLTPrint(plist);*/
//...
//我们发现删到最后一个NULL的时候并不会打印NULL
//所以我们要处理链表只有一个结点的情况
//这样删除最后一个结点才会打印NULL
//再删就会断言报错
//头删
/*SLTPopFront(&plist);
SLTPrint(plist);*/
//查找
SLTNode* pos = SLTFind(plist, 3);
/*if (pos)
{
printf("找到了\n");
}
else
{
printf("未找到\n");
}*/
//在指定位置之前插入
/*SLTInsert(&plist, pos, 100);
SLTPrint(plist);*/
//如果我们想要在1之前插入就相当于头插
//需要我们去特殊处理
//在指定位置之后插入数据
/*SLTInsertAfter(pos, 100);
SLTPrint(plist);*/
//删除pos结点
/*SLTErase(&plist, pos);
SLTPrint(plist);*/
//删除pos之后的结点
/*SLTEraseAfter(pos);
SLTPrint(plist);*/
//销毁链表
SListDestroy(&plist);
}
int main()
{
//test01();
test02();
return 0;
}三、链表的分类
链表的结构非常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
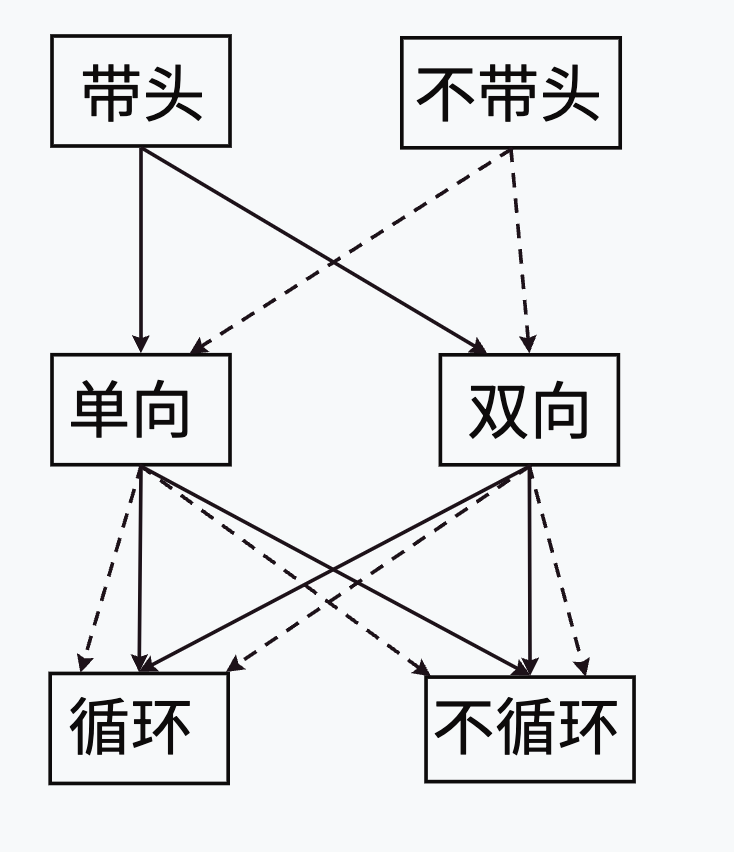
链表说明:
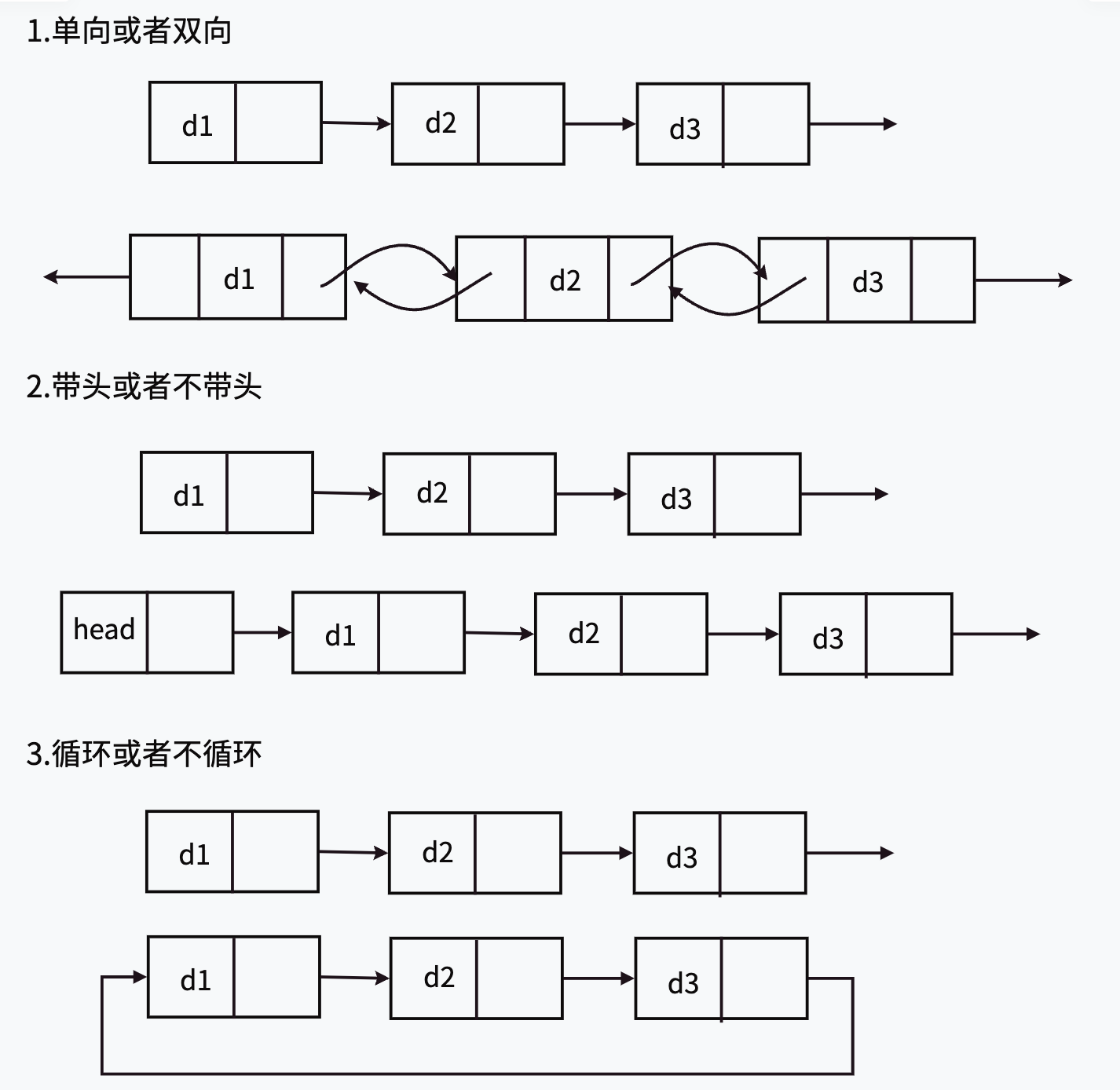
带头链表中的头结点,不存储任何有效的数据,只是用来占位子 -- "哨兵位"
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:单链表和双向带头循环链表
1.不带头单向非循环链表:结构简单 ,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2.带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
第一个不带头单向不循环链表就是我们所熟知的单链表,第二个则是下篇博客我们要讲的双向链表。
四、单链表算法题(难点)
4.1、移除链表元素
https://leetcode.cn/problems/remove-linked-list-elements/description/
思路一:查找值为val的结点并且返回结点,删除指定位置的结点
时间复杂度:O(N)
我们的思路如下:
cpp
while (遍历链表)
{
//查找值为val的结点---if判断
//删除值为val的结点---O(N)
}接下来我们可以利用之前学过的单链表的知识来进行实现:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* curr = head;
struct ListNode* prev = NULL;
while (curr != NULL) {
// 查找值为val的结点
if (curr->val == val) {
// 删除当前结点
if (prev == NULL) {
// 删除头结点
head = curr->next;
free(curr);
curr = head;
} else {
// 删除中间或尾结点
prev->next = curr->next;
free(curr);
curr = prev->next;
}
} else {
// 继续遍历
prev = curr;
curr = curr->next;
}
}
return head;
}思路二:创建新链表,将原链表中不为val的结点拿下来进行尾插
时间复杂度:O(N)
我们思路如下:
cpp
while(遍历原链表)
{
//新链表中尾插
}接下来我们可以利用之前学过的单链表的知识来进行实现:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {
//创建新链表
ListNode* newhead , *newtail;
newhead = newtail = NULL;
ListNode* pcur = head;
while(pcur)
{
//判断pcur结点的值是否为val
if(pcur->val!=val)
{
//尾插
//链表为空
if(newhead == NULL)
{
newhead = newtail = pcur;
}
else//链表非空
{
newtail->next = pcur;
newtail = newtail->next;
}
}
pcur = pcur->next;
}
if(newtail)
newtail->next = NULL;
return newhead;
}4.2、反转链表
https://leetcode.cn/problems/reverse-linked-list/description/
思路一:创建新链表,遍历原链表将结点头插到新链表中
时间复杂度:O(N)
我们可以遍历原链表,然后创建一个新链表,不断头插去实现反转链表,代码如下:
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {
ListNode* pcur = head;//用于遍历原链表
ListNode* next = NULL;//临时保存下一个结点
ListNode* newhead = NULL;//新链表的头指针
//链表为空
if(head == NULL)
{
return NULL;
}
else
{
while(pcur!=NULL)
{
next = pcur->next; // 保存当前节点的下一个节点
pcur->next = newhead; // 将当前节点插入到新链表的头部
newhead = pcur; // 更新新链表的头指针
pcur = next; // 移动到下一个节点
}
}
return newhead;
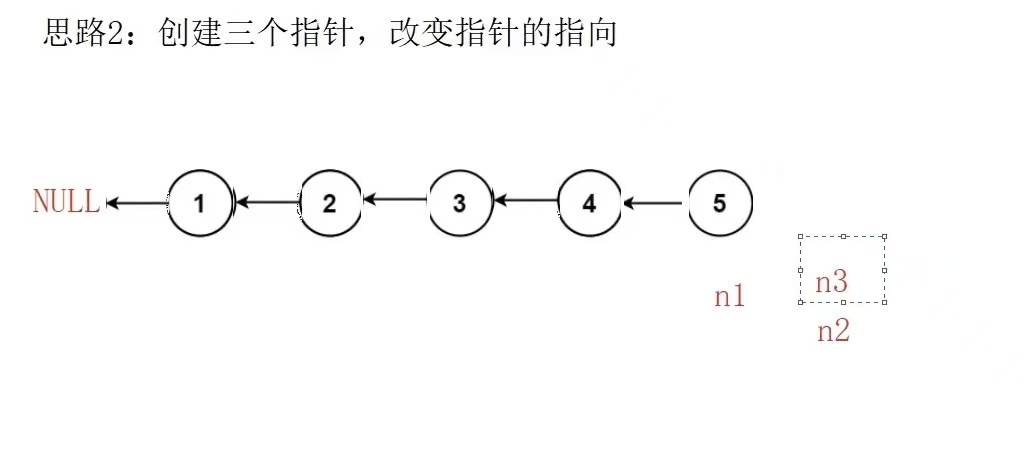
}思路二:创建三个指针,改变指针指向
时间复杂度:O(N)
初始时候三个指针,n1为NULL,n2指向n1,n3指向n2,若n2不为NULL,我们让n2的next指针指向n1,然后n1指向n2,n2指向n3,以此往复在循环中n2为空跳出循环,新链表的头便是n1这样就可以实现数组的反转
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {
if(head == NULL)
{
return head;
}
//创建三个指针
ListNode* n1, *n2, *n3;
n1 = NULL;
n2 = head;
n3 = n2->next;
while(n2)
{
n2->next = n1;
n1 = n2;
n2 = n3;
if(n3 != NULL)
n3 = n3->next;
}
return n1;
}4.3、链表的中间节点
https://leetcode.cn/problems/middle-of-the-linked-list/description/
思路一:求链表总长度,总长度/2取整就是链表中间结点的位置,遍历找中间结点
时间复杂度:O(N)
cpp
while(求链表总长度)
{}
size/2 = mid
while(mid) -- 根据mid找中间位置
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
// 计算链表的长度
int length = 0;
ListNode* current = head;
while (current != NULL)
{
length++;
current = current->next;
}
// 找到中间节点的位置
int middle = length / 2;
// 再次遍历链表,找到中间节点
current = head;
for (int i = 0; i < middle; i++)
{
current = current->next;
}
return current;
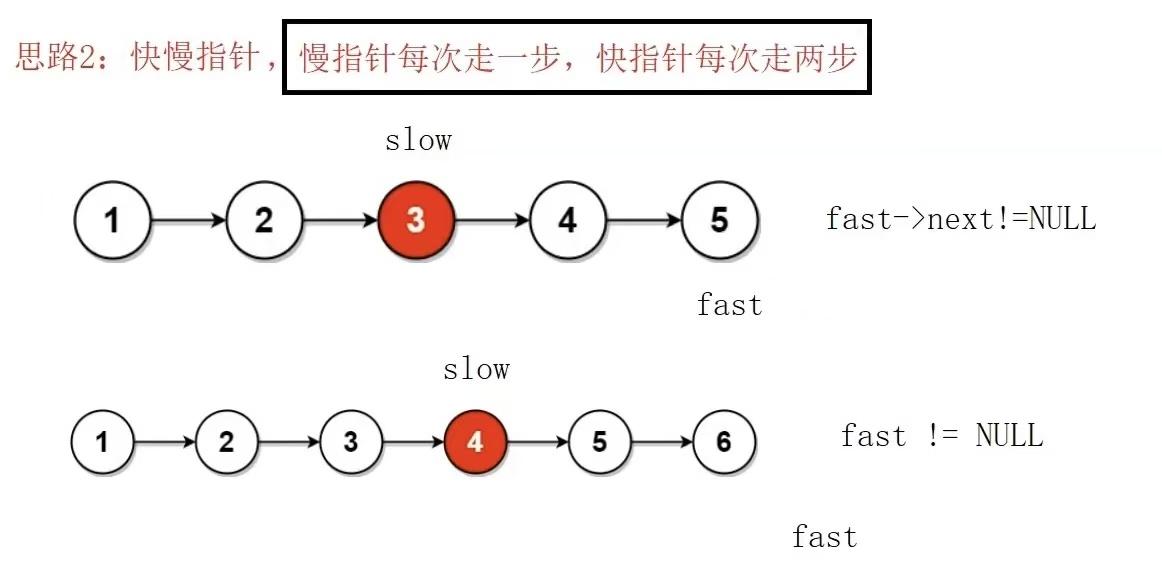
}思路二:快慢指针(很重要),慢指针每次走一步,快指针每次走俩步
时间复杂度:O(N)
我们可以定义俩个指针,一个fast,一个slow,fast每次走俩步,slow每次就走一步
当结点数为奇数的时候,fast->next != NULL为循环条件;当结点数为偶数时候,fast != NULL为循环条件
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head)
{
//创建俩个指针
ListNode* slow = head;
ListNode* fast = head;
while(fast != NULL && fast->next != NULL)
//这里的俩个顺序不能换位置,因为偶数情况下会先发生fast走完了的情况
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
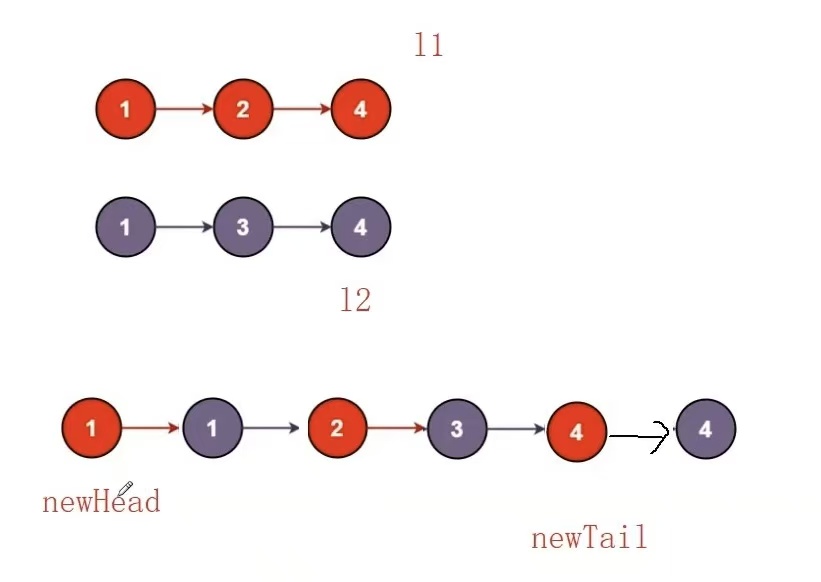
}4.4、合并两个有序链表
https://leetcode.cn/problems/merge-two-sorted-lists/description/
思路:创建新链表,遍历并比较原链表中结点的值,小的尾插到新链表中
时间复杂度:O(N)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
//处理其中一个或者俩个都为空的情况
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
//创建空链表
ListNode* newhead;
ListNode* newtail;
newhead = newtail = NULL;
//遍历原链表
ListNode* l1 = list1;
ListNode* l2 = list2;
while(l1 != NULL && l2 != NULL)
//只有俩个都不为空的时候我们才可以进行比较
{
if(l1->val < l2->val)
{
//l1尾插
if(newhead == NULL)
{
//空链表
newhead = newtail = l1;
}
else
{
//非空链表
newtail->next = l1;
newtail = newtail->next;
}
l1 = l1->next;
}
else
{
//l2尾插
if(newhead == NULL)
{
//空链表
newhead = newtail = l2;
}
else
{
//非空链表
newtail->next = l2;
newtail = newtail->next;
}
l2 = l2->next;
}
}
//l1为空||l2为空
if(l1 != NULL)
{
newtail->next = l1;
}
if(l2 != NULL)
{
newtail->next = l2;
}
return newhead;
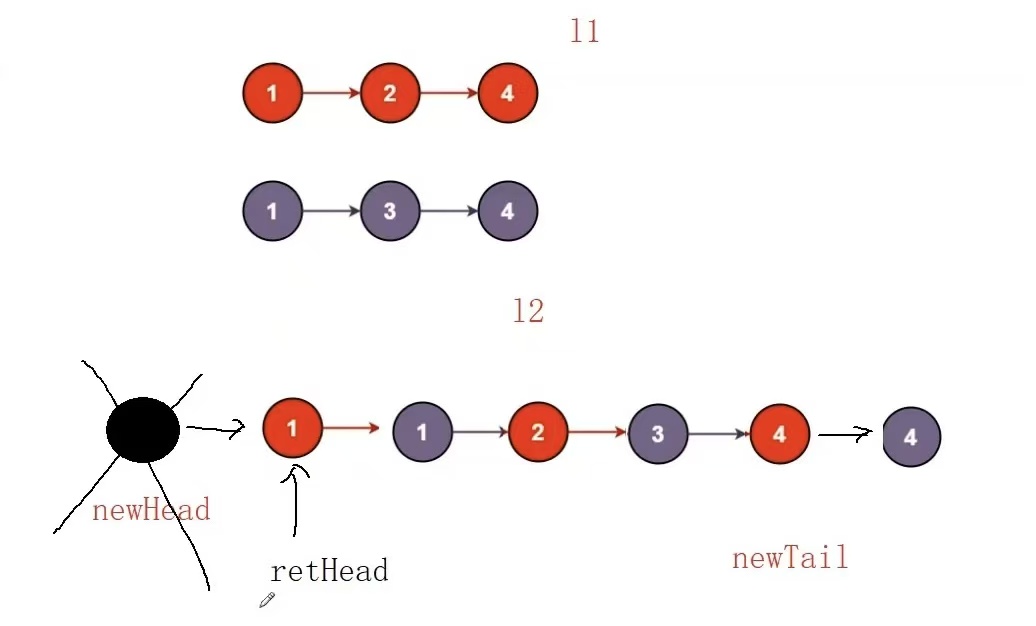
}但是我们会发现这段代码有点冗余了,这其中的根本原因就是链表存在为空的特殊情况,我们要进行特殊处理,我们可以优化一下(创建非空链表)
优化:创建非空链表
时间复杂度:O(N)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
//处理其中一个或者俩个都为空的情况
if(list1 == NULL)
{
return list2;
}
if(list2 == NULL)
{
return list1;
}
//创建非空链表
ListNode* newhead;
ListNode* newtail;
newhead = newtail = (ListNode*)malloc(sizeof(ListNode));
//遍历原链表
ListNode* l1 = list1;
ListNode* l2 = list2;
while(l1 != NULL && l2 != NULL)
//只有俩个都不为空的时候我们才可以进行比较
{
if(l1->val < l2->val)
{
//l1尾插
newtail->next = l1;
newtail = newtail->next;
l1 = l1->next;
}
else
{
//l2尾插
newtail->next = l2;
newtail = newtail->next;
l2 = l2->next;
}
}
//l1为空||l2为空
if(l1 != NULL)
{
newtail->next = l1;
}
if(l2 != NULL)
{
newtail->next = l2;
}
ListNode* rethead = newhead->next;
free(newhead);
newhead == NULL;
return rethead;
}我们没有对newhead的val初始化也没有对他的next指针进行初始化,意味着这个结点没有保存有效数据,我们称这个结点为" 哨兵位 ",此题中他只需要充当头结点就可以了。
4.5、链表的回文结构
https://www.nowcoder.com/practice/d281619e4b3e4a60a2cc66ea32855bfa
思路一:创建新链表保存原链表所有的结点,对新链表进行反转,比较新旧链表中的结点的值是否一样
时间复杂度:O(N)
cpp
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// 定义链表节点结构
struct ListNode {
int val;
struct ListNode* next;
};
// 创建新节点
struct ListNode* createNode(int val) {
struct ListNode* node = (struct ListNode*)malloc(sizeof(struct ListNode));
node->val = val;
node->next = NULL;
return node;
}
// 复制原链表
struct ListNode* copyList(struct ListNode* head) {
if (head == NULL) return NULL;
struct ListNode* newHead = NULL;
struct ListNode* tail = NULL;
struct ListNode* curr = head;
while (curr != NULL) {
struct ListNode* newNode = createNode(curr->val);
if (newHead == NULL) {
newHead = newNode;
tail = newNode;
} else {
tail->next = newNode;
tail = tail->next;
}
curr = curr->next;
}
return newHead;
}
// 反转链表
struct ListNode* reverseList(struct ListNode* head) {
struct ListNode* prev = NULL;
struct ListNode* curr = head;
struct ListNode* next = NULL;
while (curr != NULL) {
next = curr->next; // 保存下一个节点
curr->next = prev; // 反转当前节点的指针
prev = curr; // prev指针后移
curr = next; // curr指针后移
}
return prev; // prev成为新的头节点
}
// 检查是否为回文链表
bool isPalindrome(struct ListNode* head) {
if (head == NULL || head->next == NULL) {
return true; // 空链表或单个节点都是回文
}
// 复制原链表
struct ListNode* copyHead = copyList(head);
// 反转复制的链表
struct ListNode* reversedHead = reverseList(copyHead);
// 比较原链表和反转后的链表
struct ListNode* curr1 = head;
struct ListNode* curr2 = reversedHead;
while (curr1 != NULL && curr2 != NULL) {
if (curr1->val != curr2->val) {
// 释放复制链表的内存
struct ListNode* temp;
while (reversedHead != NULL) {
temp = reversedHead;
reversedHead = reversedHead->next;
free(temp);
}
return false;
}
curr1 = curr1->next;
curr2 = curr2->next;
}
// 释放复制链表的内存
struct ListNode* temp;
while (reversedHead != NULL) {
temp = reversedHead;
reversedHead = reversedHead->next;
free(temp);
}
return true;
}
// 测试函数:创建链表
struct ListNode* createTestList(int* arr, int size) {
if (size == 0) return NULL;
struct ListNode* head = createNode(arr[0]);
struct ListNode* curr = head;
for (int i = 1; i < size; i++) {
curr->next = createNode(arr[i]);
curr = curr->next;
}
return head;
}
// 打印链表
void printList(struct ListNode* head) {
struct ListNode* curr = head;
while (curr != NULL) {
printf("%d ", curr->val);
curr = curr->next;
}
printf("\n");
}
// 释放链表内存
void freeList(struct ListNode* head) {
struct ListNode* temp;
while (head != NULL) {
temp = head;
head = head->next;
free(temp);
}
}
int main() {
// 测试用例1: 回文链表 1->2->2->1
int arr1[] = {1, 2, 2, 1};
struct ListNode* list1 = createTestList(arr1, 4);
printf("链表1: ");
printList(list1);
printf("是否为回文: %s\n", isPalindrome(list1) ? "是" : "否");
// 测试用例2: 非回文链表 1->2->3->4
int arr2[] = {1, 2, 3, 4};
struct ListNode* list2 = createTestList(arr2, 4);
printf("链表2: ");
printList(list2);
printf("是否为回文: %s\n", isPalindrome(list2) ? "是" : "否");
// 释放原链表内存
freeList(list1);
freeList(list2);
return 0;
}思路二:创建数组大小为900,遍历链表将结点的值依次存储在数组中,若数组为回文结构,则链表为回文结构
时间复杂度:O(N)
空间复杂度:O(1)
cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
bool chkPalindrome(ListNode* A) {
int arr[900] = {0};
//遍历链表,将链表中结点的值依次存储到数组中
ListNode* pcur = A;
int i = 0;
while(pcur){
arr[i++] = pcur->val;
pcur = pcur->next;
}
//判断数组是否为回文结构
int left = 0;
int right = i-1;
while(left < right){
if(arr[left] != arr[right])
{
return false;
}
left++;
right--;
}
return true;
}
};思路三:找链表的中间结点,将中间结点作为新链表的头结点,反转链表,遍历原链表和反转后链表结点的值是否相等
时间复杂度:O(N)
cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};*/
class PalindromeList {
public:
//找中间结点
ListNode* middleNode(ListNode* head) {
//创建俩个指针
ListNode* slow = head;
ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
//反转链表
ListNode* reverseList(ListNode* head) {
if (head == NULL) {
return head;
}
//创建三个指针
ListNode* n1, *n2, *n3;
n1 = NULL;
n2 = head;
n3 = n2->next;
while (n2) {
n2->next = n1;
n1 = n2;
n2 = n3;
if (n3 != NULL)
n3 = n3->next;
}
return n1;//链表的新的头结点
}
bool chkPalindrome(ListNode* A) {
//1.找中间结点
ListNode* mid = middleNode(A);
//2.反转以中间结点为头的链表
ListNode* right = reverseList(mid);
//遍历原链表反转后的链表,比较结点的值是否相等
ListNode* left = A;
while(right){
if(left->val != right->val){
return false;
}
left = left->next;
right = right->next;
}
return true;
}
};4.6、相交链表
https://leetcode.cn/problems/intersection-of-two-linked-lists/description/
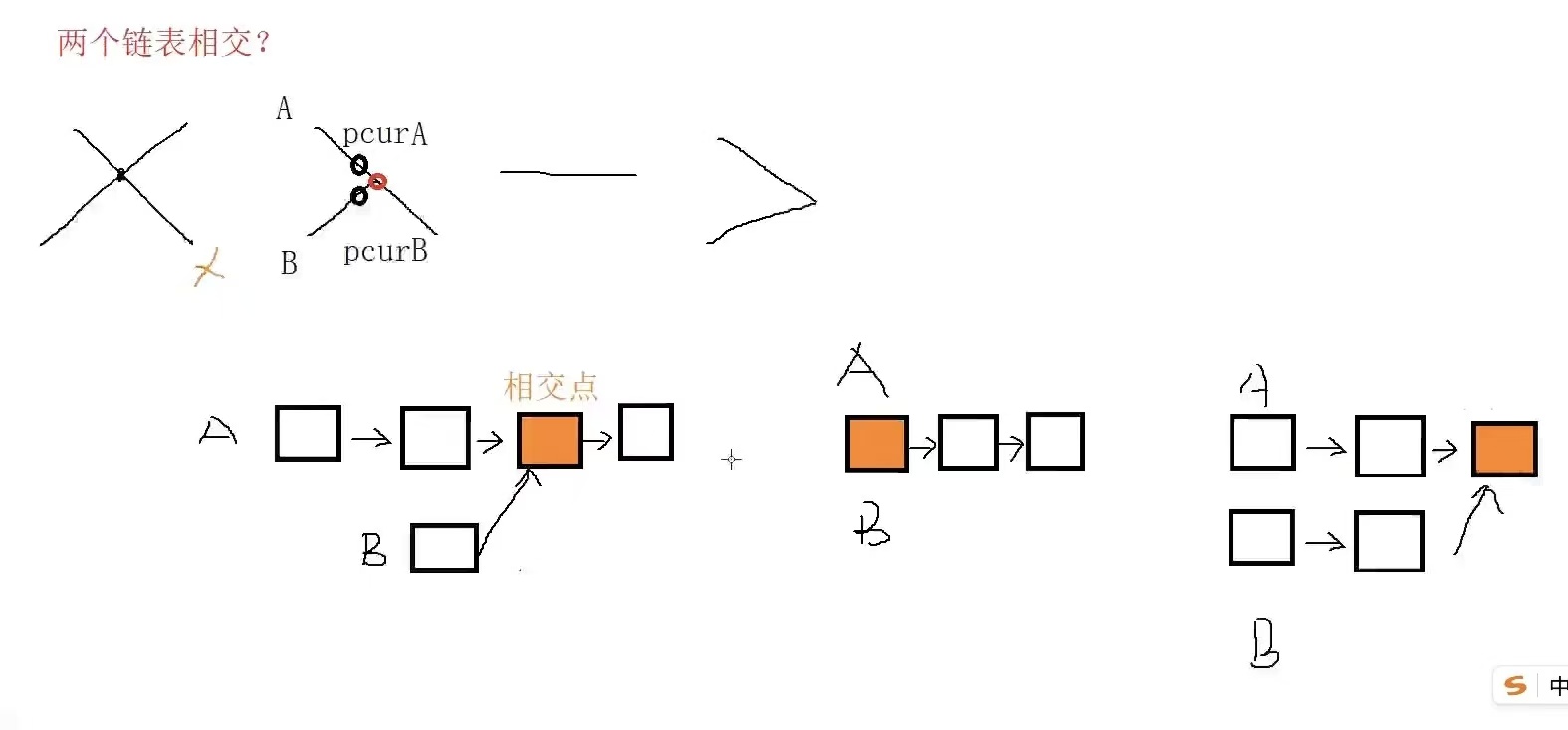
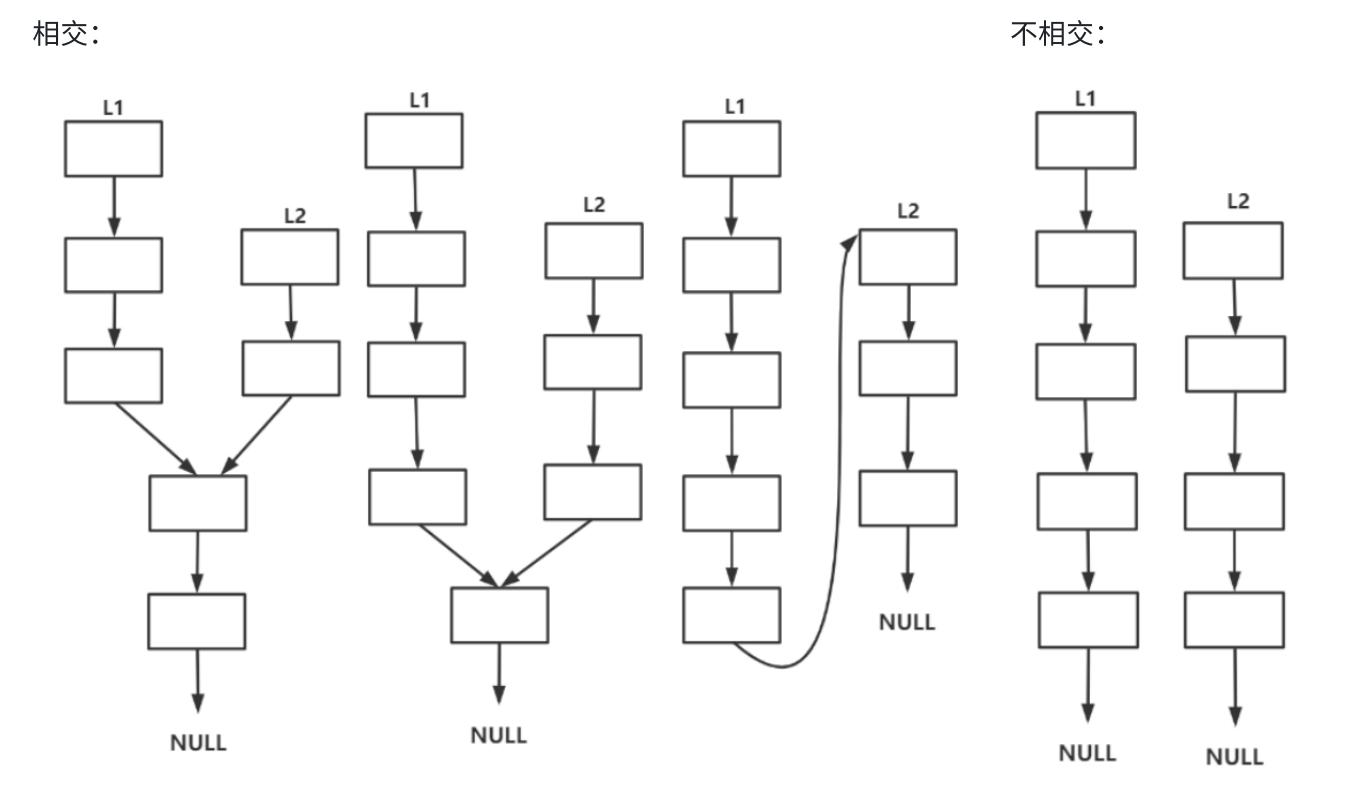
链表的相交一共就只有三种方式,一种是图一所示的中间位置相交,一种是起始位置就相交,最后一种就是尾部相交。
判断链表是否相交:他们的尾结点相同
思路:求俩个链表的长度,长链表先走长度差步,长短链表开始同步遍历,找相同的结点
这里我们需要用到C语言中的一个函数abs,他是用来计算绝对值的
时间复杂度:O(N)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
//求链表的长度
ListNode* pa = headA;
ListNode* pb = headB;
int sizeA = 0, sizeB = 0;
while(pa)
{
++sizeA;
pa = pa->next;
}
while(pb)
{
++sizeB;
pb = pb->next;
}
//求长度差
int gap = abs(sizeA - sizeB);//求绝对值
//求一下谁是长链表,定义长短链表
ListNode* shortList = headA;
ListNode* longList = headB;
if(sizeA > sizeB)
{
longList = headA;
shortList = headB;
}
//长链表先走gap
while(gap--)
{
longList = longList->next;
}
//shortList longList就在同一起跑线
while(shortList) //或者用while(longList)
{
if(shortList == longList)
{
return shortList; //也可以return longList;
}
shortList = shortList->next;
longList = longList->next;
}
//链表不相交
return NULL;
}4.7、环形链表I
https://leetcode.cn/problems/linked-list-cycle/description/
特点:尾结点的next指针不为NULL
思路:快慢指针,慢指针每次走一步,快指针每次走俩步,如果slow和fast指向同一个结点,说明链表带环
时间复杂度:O(N)

cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
bool hasCycle(struct ListNode *head) {
//创建快慢指针
ListNode* fast = head;
ListNode* slow = head;
while(fast != NULL && fast->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
{
//相遇
return true;
}
}
//链表不带环
return false;
}思考1:为什么快指针每次走两步,慢指针走一步可以相遇,有没有可能遇不上,请推理证明!
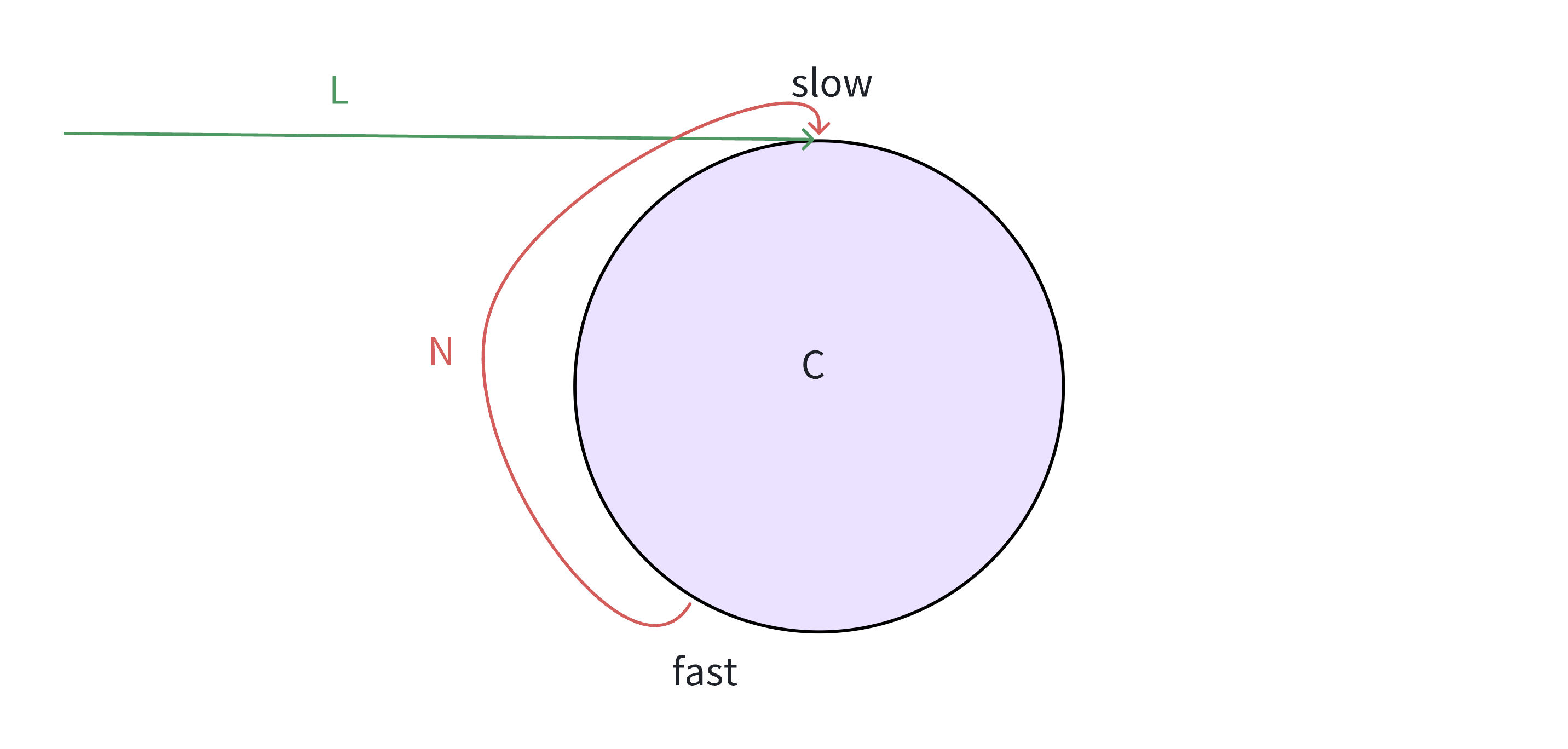
slow一次走一步,fast一次走2步,fast先进环,假设slow也走完入环前的距离,准备进环,此时fast 和slow之间的距离为N,接下来的追逐过程中,每追击一次,他们之间的距离缩小1步
追击过程中fast和slow之间的距离变化:

因此,在带环链表中慢指针走一步,快指针走两步最终一定会相遇。
思考2:快指针一次走3步,走4步,...n步行吗?
step1:
按照上面的分析,慢指针每次走一步,快指针每次走三步,此时快慢指针的最大距离为N,接下来的追逐过程中,每追击一次,他们之间的距离缩小2步追击过程中fast和slow之间的距离变化:
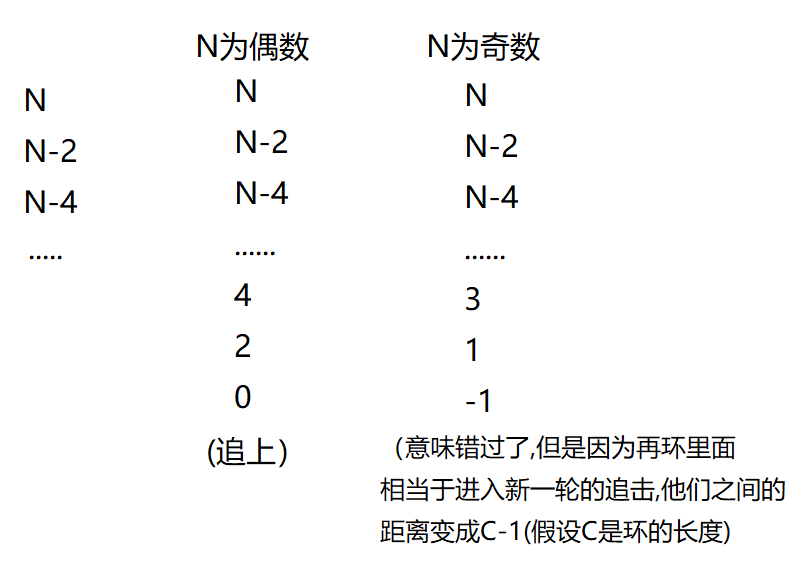
分析:
1、如果 N 是偶数,第一轮就追上了
2、如果N 是奇数,第一轮追不上,快追上,错过了,距离变成 - 1,即 C-1,进入新的一轮追击
a、C-1 如果是偶数,那么下一轮就追上了
b、C-1 如果是奇数,那么就永远都追不上
总结一下追不上的前提条件:N 是奇数,C 是偶数
step2:
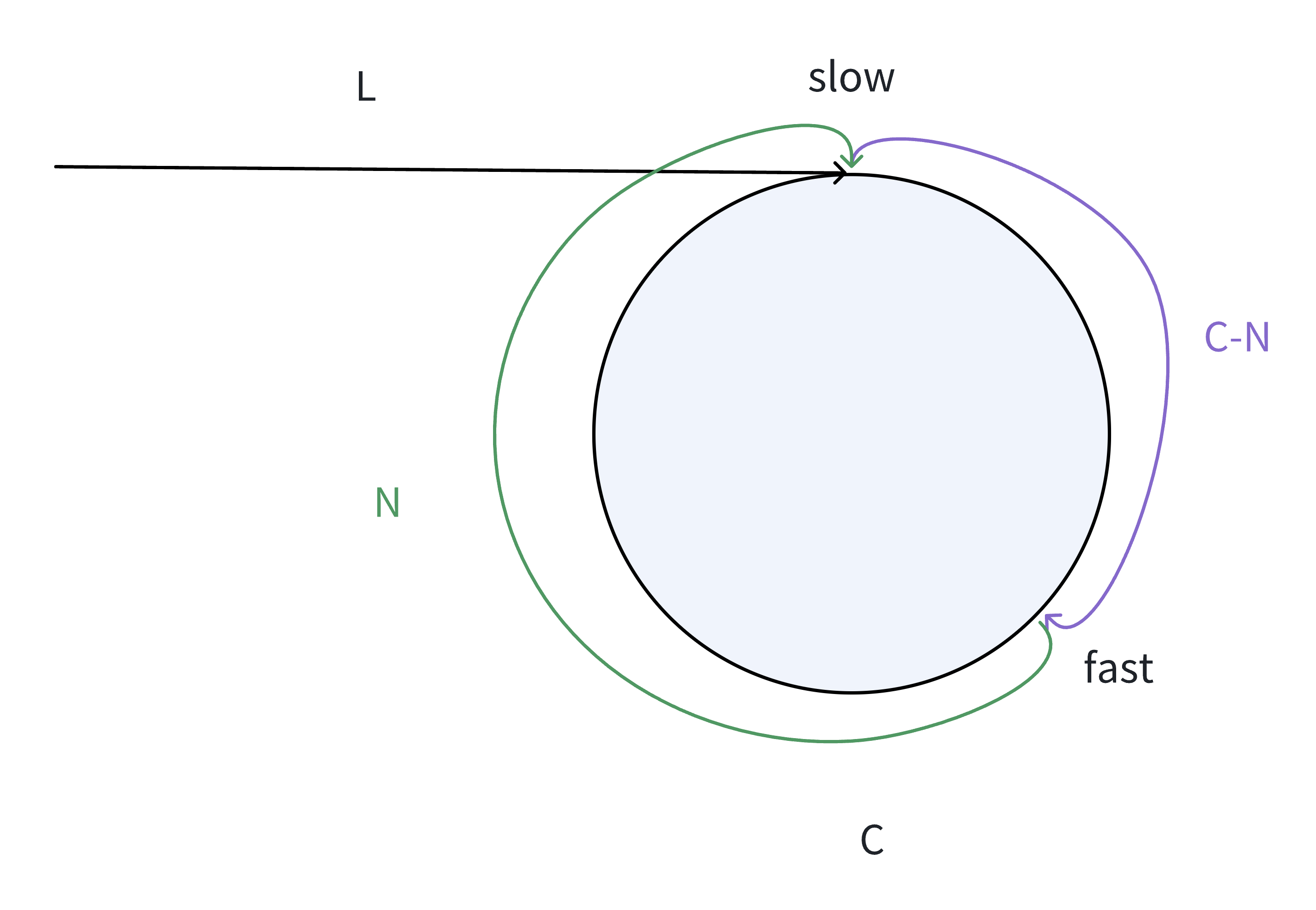
假设:
环的周长为 C,头结点到 slow 结点的长度为 L,slow 走一步,fast 走三步,当 slow 指针入环后,slow 和 fast 指针在环中开始进行追逐,假设此时 fast 指针已经绕环 x 周。在追逐过程中,快慢指针相遇时所走的路径长度:
fast: L + xC + C - N
slow: L
由于慢指针走一步,快指针要走三步,因此得出:3 * 慢指针路程 = 快指针路程即:
3L = L + xC + C - N2L = (x + 1) C - N
对上述公式继续分析:由于偶数乘以任何数都为偶数,因此 2L 一定为偶数,则可推导出可能得情况:
- 情况 1: 偶数 = 偶数 - 偶数
- 情况 2: 偶数 = 奇数 - 奇数
- 由 step1 中(1)得出的结论,如果 N 是偶数,则第一圈快慢指针就相遇了。由 step1 中(2)得出的结论,如果 N 是奇数,则 fast 指针和 slow 指针在第一轮的时候套圈了,开始进行下一轮的追逐;当 N 是奇数,要满足以上的公式,则 (x + 1) C 必须也要为奇数,即 C 为奇数,满足(2)a 中的结论,则快慢指针会相遇
因此,step1 中的 N 是奇数,C 是偶数不成立,既然不存在该情况,则快指针一次走 3 步最终一定也可以相遇。快指针一次走 4、5...... 步最终也会相遇,其证明方式同上。
cpp
typedef struct ListNode ListNode;
bool hasCycle(struct ListNode* head) {
ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)
{
slow = slow->next;
int n = 3; //fast每次⾛三步
while (n--)
{
if (fast->next)
fast = fast->next;
else
return false;
}
if (slow == fast)
{
return true;
}
}
return false;
}4.8、环形链表II
https://leetcode.cn/problems/linked-list-cycle-ii/description/
思路:快慢指针,在环里一定会相遇
小结论:相遇点到入环结点的距离 == 头结点到入环结点的距离
时间复杂度:O(N)
cpp
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode *detectCycle(struct ListNode *head) {
//创建快慢指针
ListNode* slow = head;
ListNode* fast = head;
while(fast != NULL && fast->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
if(slow == fast)
{
//相遇点 -- 找入环结点(相遇点到入环结点的距离 == 头结点到入环结点的距离)
ListNode* pcur = head;
while(pcur != slow)
{
pcur = pcur->next;
slow = slow->next;
}
//跳出循环就代表走到了入环结点,他俩相遇了
return pcur;
}
}
//链表不带环
return NULL;
}证明:为什么在带环链表中,快慢指针相遇点到入环结点的距离 == 头结点到相遇点的距离

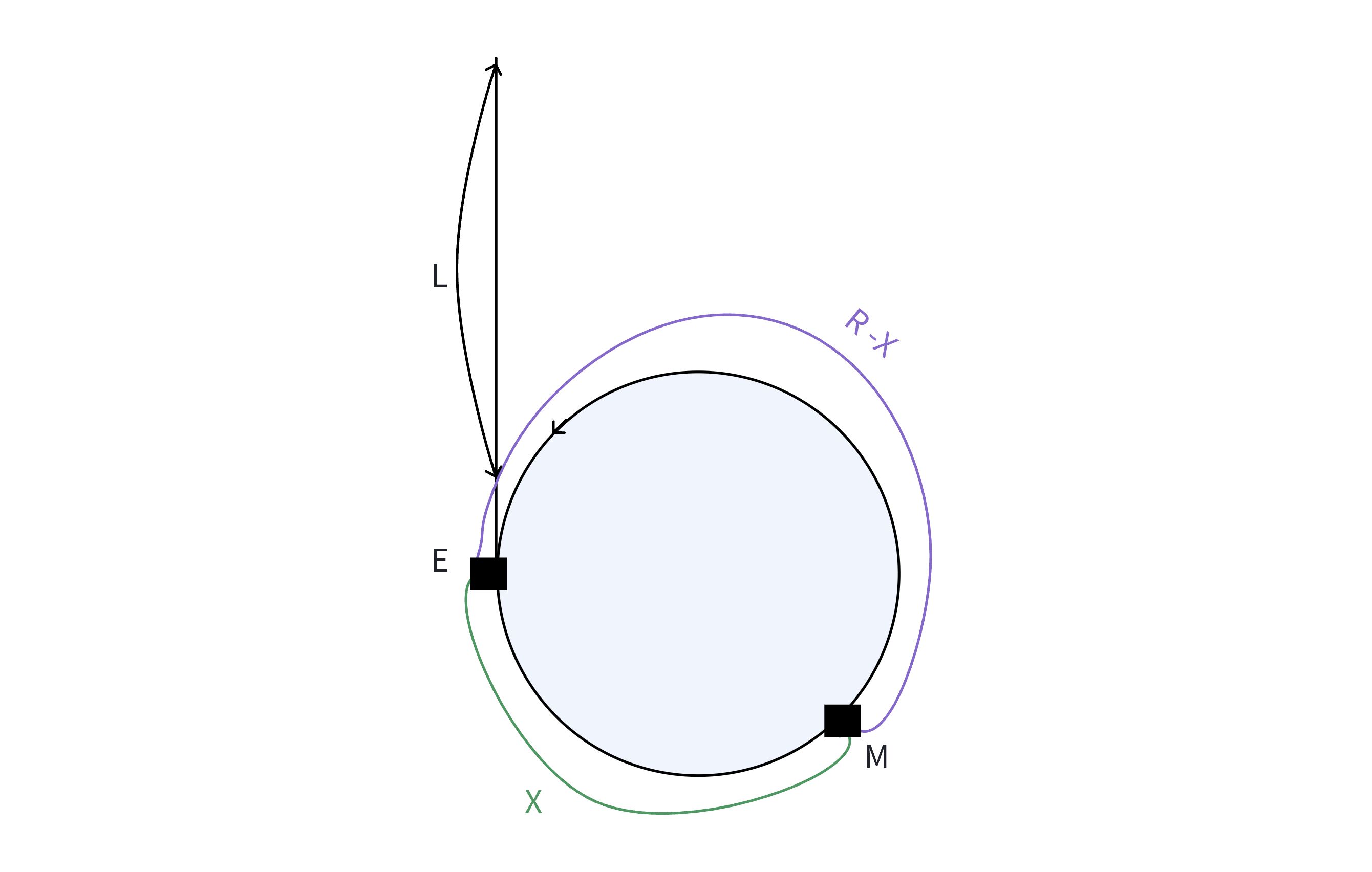
说明:
H 为链表的起始点,E 为环入口点,M 与判环时候相遇点
设:
环的长度为 R,H 到 E 的距离为 L,E 到 M 的距离为 X,则:M 到 E 的距离为 R - X在判环时,快慢指针相遇时所走的路径长度:
fast:L + X + nR slow:L + X
注意:
- 当慢指针进入环时,快指针可能已经在环中绕了 n 圈了,n 至少为 1
因为:快指针先进环走到 M 的位置,最后又在 M 的位置与慢指针相遇
- 慢指针进环之后,快指针肯定会在慢指针走一圈之内追上慢指针
因为:慢指针进环后,快慢指针之间的距离最多就是环的长度,而两个指针在移动时,每次它们至今的距离都缩减一步,因此在慢指针移动一圈之前快,指针肯定是可以追上慢指针的,而快指针速度是满指针的两倍,因此有如下关系是:
2 * (L + X) = L + X + nR
L + X = nRL = nR - X
L = (n - 1) R + (R - X)(n 为 1,2,3,4......,n 的大小取决于环的大小,环越小 n 越大)
极端情况下,假设 n=1,此时: L = R - X
即:一个指针从链表起始位置运行,一个指针从相遇点位置绕环,每次都走一步,两个指针最终会在入口点的位置相遇