模型的优势
- 能力提升方面
- 文档智能 和 视频理解
- Object grounding 通用性
- 长视频理解 与 定位
- 技术细节
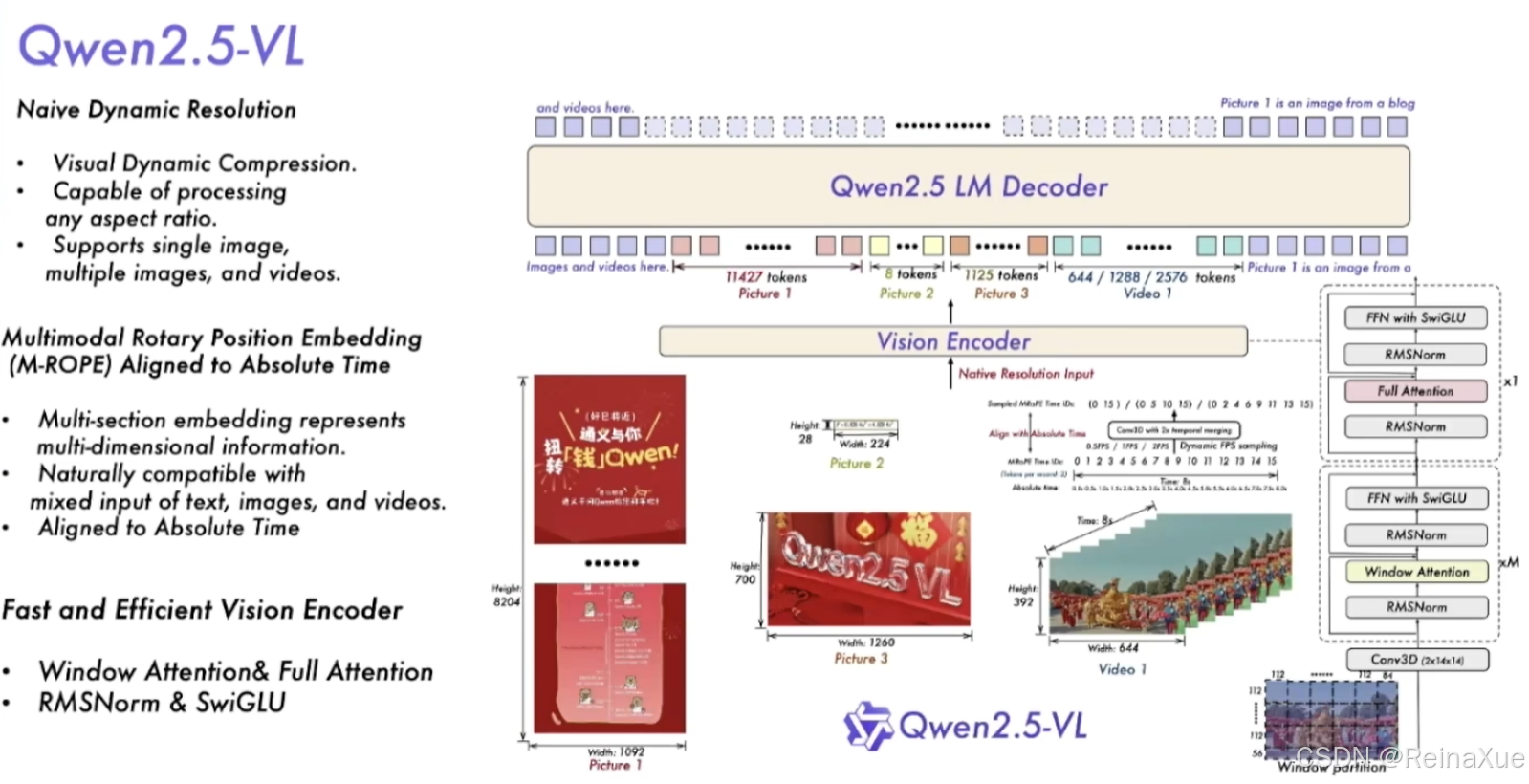
- 原生动态分辨率
- 动态 FPS 采样训练
- M-ROPE 对齐绝对位置时间
- position id (time width height )
- 更快更高效的视觉编码器
模型结构与训练策略
模型架构:视觉编码器(ViT) + 语言模型

1. 朴素动态分辨率(Naive Dynamic Resolution)

2.多模态旋转位置编码嵌入(M-RoPE)
position id :(temporal,height,width)
texts input id:相同的 position IDs,eg. (4,4,4)...
images position id:(temporal,height,width),eg. (0,0,0)、(0,0,1)...
videos position id:(temporal,height,width),eg. (0,0,0)、(0,0,1)、(1,0,0)、(1,0,1)...
3. 统一图像和视频理解(Unified Image and Video Understanding)
训练方案:图像和视频混合数据
视频采样:两帧/second,
卷积:深度为2的3D卷积
一致性:每个图像 视为 两个相同的帧
平衡长视频处理效率:每个视频的token总数限制为16384

训练数据拓展与模型性能验证
QWen2-VL-7B

- info VQA,比如高密度文字的图片
- 需要更高的分辨率,以获得更全面的信息,从而达到更准确的表现
- HallBench,处理自然图片
- 分辨率合适就可以达到好的效果
- OCRBench,小截图
- 更小的分辨率上表现更好
- MMMU,学科类问题
- 有最佳分辨率

- token 达到 80k依然保持优秀的增长

QWen2.5-VL能力应用案例









使用的提示
- 由于支持动态的分辨率,所以到底应该输入怎么样的分辨率合适
- min_pixels 和 max_poxels 用于限制最大像素和最大像素
- 模型 最少能支持 4 token,最大 16384 token (训练有达到32k)
- 实际使用中可以调到合适的范围,默认是(256~1280)
- 视频的输入:长视频输入采用短FPS,短视频输入可用更高的FPS
- 对于定位任务,可能会存在缩放分辨率大小,这里会造成模型输出的坐标定位是reset的关系,和实际会有差别。