在AI算力快速演进的今天,用户对GPU的需求已经从单一性能转向显存容量、吞吐效率与稳定能效的综合考量。
随着RTX 5090的到来,我们看到了一款在AI模型推理、微调与中型训练任务中表现出色的全能GPU。与此同时,RTX 4090 48GB凭借更大的显存,在长上下文与多任务并发下仍具优势。
为此,我们基于赋创自研整机平台,对8× RTX 5090(32GB)与8× RTX 4090(48GB)进行了系统性实测对比 ,并同步参考24GB标准版4090的表现,希望能够帮助各位更客观地选择最合适的AI服务器方案。

一、单卡性能与显存差异
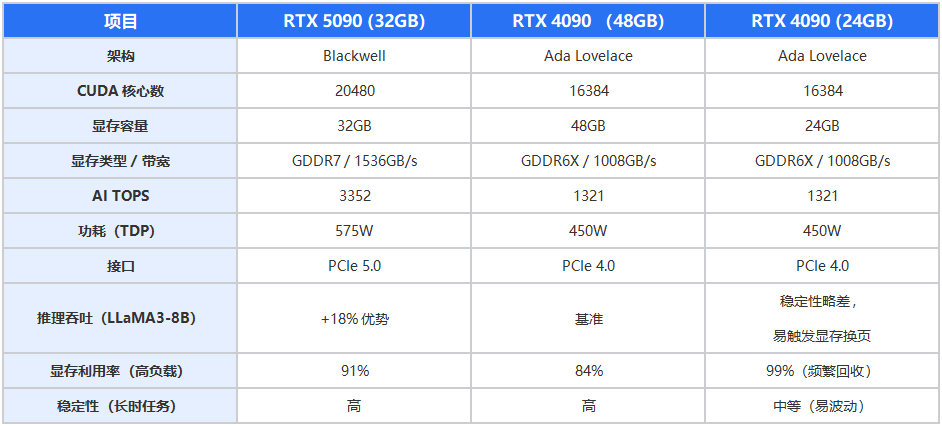
分析说明:
●32GB的RTX 5090在带宽与能效上具备显著优势,适合模型推理、参数微调及高并发多实例部署。
●48GB 的RTX 4090在长上下文与多会话并发中更具稳定性:
○更大显存允许单卡容纳更完整的KV Cache与更长输入序列;
○避免24GB版本常见的页外KV/CPU Offload与调度延迟;
○Flash-Attention等高效内核能以更大Tile运行,减少同步与重排次数。
●24GB版本在显存边缘运行时,容易出现反复内存回收与性能抖动。
二、8卡整机实测结果
测试内容
1)模型与精度:DeepSeek-R1-Distill-Llama-70B,BF16。
2)度量口径:测试工具采用evalscope,评测指标包括首token时延,吞吐等。
3)输入规模:典型长上下文推理,固定 prompt 长度与采样参数,输入输出长度覆盖1K到4K。
4)系统环境:同一机房、同一操作系统镜像与驱动;功耗墙、散热条件一致;关闭除监控外的其它高负载服务。
5)图中数据:仅展示核心指标,完整环境版本与运行日志可按需补充。
测试数据
实测平台均基于赋创4U高密度AI服务器 ,采用PCIe 5.0总线与全闪NVMe阵列,分别搭载8张5090(涡轮版)与8张48G 4090(风扇版)进行压力测试。
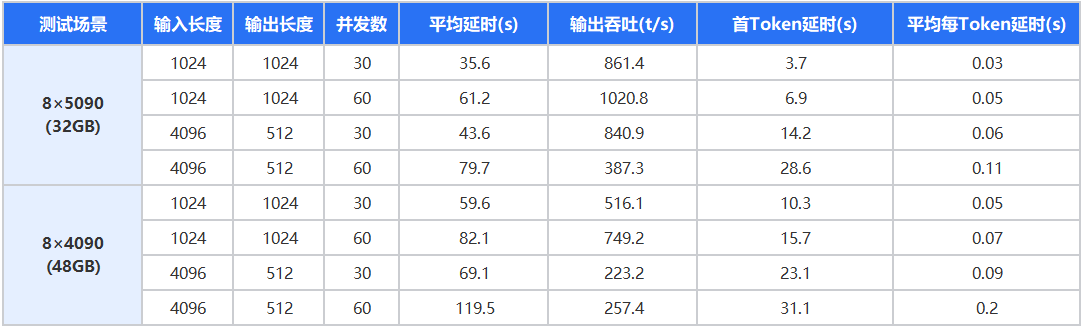
性能分析:
●在中等输入长度(1024 tokens)与高并发(60线程)下,5090整机平均延时较48G版4090低 28.6% ,吞吐提升 约36.3% 。
●在长上下文(4096 tokens)下,48GB显存的优势开始显现,任务更稳定,延迟波动更小。
●整体来看:
○5090整机适合主流推理、微调、批量生成任务;
○48G 4090整机更适合大上下文与复杂输入任务。
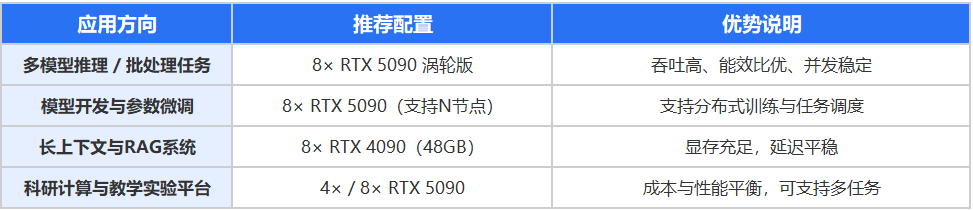
三、推荐方案与适用场景
四、总结
本次实测结果显示:
●RTX 5090在AI推理与中型模型训练中具备明显的吞吐与能效优势,是当前最具性价比的全能选择;
●48GB版 RTX 4090在长上下文、复杂输入任务中表现更稳定,能有效支撑多会话并发场景;