目录
[模块 1:可视化环境初始化(init_visualization)](#模块 1:可视化环境初始化(init_visualization))
[模块 2:基础工具函数(数据预处理核心)](#模块 2:基础工具函数(数据预处理核心))
[1. 分词函数(tokenize_en/tokenize_fr)](#1. 分词函数(tokenize_en/tokenize_fr))
[2. 示例数据集生成(generate_sample_dataset)](#2. 示例数据集生成(generate_sample_dataset))
[3. 词汇表构建(build_vocab)](#3. 词汇表构建(build_vocab))
[4. 数据加载与词汇表绑定(load_data_and_vocab)](#4. 数据加载与词汇表绑定(load_data_and_vocab))
[模块 3:数据集与数据加载(适配 PyTorch 训练)](#模块 3:数据集与数据加载(适配 PyTorch 训练))
[1. 自定义数据集类(TranslationDataset)](#1. 自定义数据集类(TranslationDataset))
[2. 批量处理函数(collate_fn)](#2. 批量处理函数(collate_fn))
[3. 数据加载器创建(get_data_loader)](#3. 数据加载器创建(get_data_loader))
[模块 4:掩码生成函数(create_masks)](#模块 4:掩码生成函数(create_masks))
[核心功能:解决 Transformer 训练 / 推理中的 "无效信息干扰" 问题](#核心功能:解决 Transformer 训练 / 推理中的 “无效信息干扰” 问题)
[模块 5:Transformer 核心模型(模型架构核心)](#模块 5:Transformer 核心模型(模型架构核心))
[1. 辅助函数(get_clones)](#1. 辅助函数(get_clones))
[2. 位置编码器(PositionalEncoder)](#2. 位置编码器(PositionalEncoder))
[3. 多头注意力(MultiHeadAttention)](#3. 多头注意力(MultiHeadAttention))
[4. 前馈网络(FeedForward)](#4. 前馈网络(FeedForward))
[5. 层归一化(Norm)](#5. 层归一化(Norm))
[6. 编码器层(EncoderLayer)](#6. 编码器层(EncoderLayer))
[7. 编码器(Encoder)](#7. 编码器(Encoder))
[8. 解码器层(DecoderLayer)](#8. 解码器层(DecoderLayer))
[9. 解码器(Decoder)](#9. 解码器(Decoder))
[10. Transformer 整体(Transformer)](#10. Transformer 整体(Transformer))
[模块 6:模型训练函数(train_model)](#模块 6:模型训练函数(train_model))
核心功能:实现模型训练全流程,含损失计算、参数更新、可视化触发
[模块 7:推理函数(translate_sentence)](#模块 7:推理函数(translate_sentence))
[核心功能:实现 "英文→法文" 的自回归翻译,含推理过程可视化](#核心功能:实现 “英文→法文” 的自回归翻译,含推理过程可视化)
[模块 8:可视化函数库(7 个函数,多维度解析模型)](#模块 8:可视化函数库(7 个函数,多维度解析模型))
[1. 数据分布可视化](#1. 数据分布可视化)
[2. 训练过程可视化](#2. 训练过程可视化)
[3. 注意力机制可视化](#3. 注意力机制可视化)
[4. 推理过程可视化](#4. 推理过程可视化)
[模块 9:主函数(if name == "main":)](#模块 9:主函数(if name == "main":))
[核心功能:串联所有模块,实现 "一键执行全流程"](#核心功能:串联所有模块,实现 “一键执行全流程”)
一、引言
本文实现的英法机器翻译的 Transformer 模型涵盖 "数据生成→预处理→模型构建→训练→推理→可视化" 全流程,核心功能可按模块拆解为 8 大核心模块,每个模块承担特定职责,最终实现 "输入英文句子,输出法文翻译" 并通过可视化解析模型内部逻辑。下面将详细讲解具体实现逻辑及Python代码完整实现。
二、整体功能概述
代码以 "英法机器翻译" 为任务载体,实现了标准 Transformer 模型的完整生命周期管理:
- 自动生成小规模英 - 法平行语料(10 条样本,用于快速测试);
- 完成数据预处理(分词、词汇表构建、Padding 对齐);
- 构建可保存注意力权重的 Transformer 模型(适配可视化需求);
- 实现模型训练(含损失监控、学习率跟踪);
- 支持自回归推理(生成法文翻译);
- 提供4 大类 10 + 种可视化(数据分布、训练过程、注意力机制、推理决策),辅助理解模型工作原理;
- 自动保存模型权重和可视化结果,形成完整实验记录。
三、分模块详细功能介绍
模块 1:可视化环境初始化(init_visualization)
核心功能:为可视化准备文件夹和绘图配置
- 文件夹创建 :自动生成
vis/主目录及 4 个子目录,按功能分类保存可视化结果:vis/data/:数据分布相关图表(如序列长度、高频词);vis/train/:训练过程相关图表(如损失曲线、学习率曲线);vis/attention/:注意力机制热力图;vis/inference/:推理过程相关图表(如生成概率、翻译对齐)。
- 绘图样式配置 :解决中文显示乱码问题(配置
SimHei等中文字体)、设置默认图大小(12×8)、字体大小(10 号),确保图表美观易读。
模块 2:基础工具函数(数据预处理核心)
包含 5 个函数,负责将原始文本转换为模型可输入的数值格式,是数据流入模型的 "入口"。
1. 分词函数(tokenize_en/tokenize_fr)
- 功能:统一英、法文的文本清洗与分词逻辑;
- 细节 :
- 去除标点符号(
str.maketrans清空标点映射); - 转为小写(避免大小写导致的词表冗余,如 "I" 和 "i" 视为同一词);
- 按空格分割为单词列表,过滤空字符串(避免分割后残留空值)。
- 去除标点符号(
2. 示例数据集生成(generate_sample_dataset)
- 功能:自动生成小规模英 - 法平行语料,无需手动准备数据;
- 细节 :
- 生成 10 条日常场景的英 - 法对照句子(如 "i love deep learning"→"je aime le traitement du langage naturel");
- 保存为
data/train.txt,格式为 "英文句子 \t 法文句子"(制表符分隔,便于后续拆分)。
3. 词汇表构建(build_vocab)
- 功能:从分词后的句子中构建词汇表,实现 "单词→索引" 映射;
- 细节 :
- 预设 4 个特殊符号:
<pad>(填充符,索引 0)、<unk>(未知词,索引 1)、<sos>(句子开始符,索引 2)、<eos>(句子结束符,索引 3); - 统计词频(
freq_dict),按最小词频(min_freq)过滤低频词(示例中min_freq=1,保留所有词); - 返回 "词汇表(tok→idx)" 和 "词频字典"(用于高频词可视化)。
- 预设 4 个特殊符号:
4. 数据加载与词汇表绑定(load_data_and_vocab)
- 功能:串联数据读取、词汇表构建、数据可视化,输出模型可用的 "分词句子 + 索引映射";
- 细节 :
- 读取
train.txt,拆分英、法文句子并分词; - 调用
build_vocab生成英、法词汇表及词频字典; - 触发数据分布可视化 (调用
plot_sequence_length_distribution和plot_top_words); - 返回关键结果:分词后的英 / 法句子列表、英 / 法 "词→索引"(
en_stoi/fr_stoi)、"索引→词"(en_itos/fr_itos,用于后续可视化时还原单词)。
- 读取
模块 3:数据集与数据加载(适配 PyTorch 训练)
实现 PyTorch 标准的数据加载流程,解决 "批量处理、Padding 对齐、设备适配" 问题。
1. 自定义数据集类(TranslationDataset)
- 功能:将 "分词句子" 转换为 "索引张量",是 PyTorch 加载数据的基础类;
- 细节 :
__getitem__:将单条英文 / 法文分词句子转为索引列表,并在前后添加<sos>和<eos>(如 "i love"→[2, en_stoi['i'], en_stoi['love'], 3]);__len__:返回数据集总样本数,用于计算批次数量。
2. 批量处理函数(collate_fn)
- 功能:处理批量数据的 "长度对齐",避免因句子长度不一致导致的计算错误;
- 关键逻辑 :
- 按长度排序:将批次内英文句子按长度降序排序(减少 Padding 数量,提升计算效率);
- Padding 填充 :用
<pad>(索引 0)将所有句子填充到批次内的最大长度(英文按最大英文长度,法文按最大法文长度); - 堆叠张量:将列表转为 PyTorch 张量,便于模型输入。
3. 数据加载器创建(get_data_loader)
- 功能:生成可迭代的训练数据加载器,并自动适配设备(CPU/GPU);
- 细节 :
- 封装
DataLoader,设置批次大小(batch_size=2,适配小规模数据)、打乱数据(shuffle=True); - 自动检测设备:优先使用 GPU(
cuda),无 GPU 则用 CPU,返回加载器和设备信息。
- 封装
模块 4:掩码生成函数(create_masks)
核心功能:解决 Transformer 训练 / 推理中的 "无效信息干扰" 问题
Transformer 无法自动区分 "有效词" 和 "Padding",也无法避免 "未来信息泄露"(解码时看到未生成的词),掩码通过 "遮挡无效位置" 解决这两个问题:
- 源序列掩码(src_mask) :
- 格式:
[batch_size, 1, src_seq_len],True表示有效位置,False表示 Padding 位置; - 作用:让编码器忽略 Padding 词的注意力计算,避免无效信息影响。
- 格式:
- 目标序列掩码(trg_mask) :
- 由两部分组成:
- Padding 掩码:与源掩码逻辑一致,遮挡目标序列的 Padding;
- 下三角掩码(trg_subseq_mask) :
[1, trg_seq_len, trg_seq_len],下三角为True,上三角为False;
- 作用:解码时,每个位置只能关注 "已生成的前面位置",避免看到 "未来位置" 的词(如生成第 3 个词时,只能看 1、2 位置)。
- 由两部分组成:
模块 5:Transformer 核心模型(模型架构核心)
按 "组件→层→整体" 的层级构建,且所有注意力层均保存权重,适配可视化需求。
1. 辅助函数(get_clones)
- 功能:复制 N 个相同的层(如复制 2 个编码器层),避免重复代码,实现层堆叠。
2. 位置编码器(PositionalEncoder)
- 核心问题:Transformer 是 "并行结构",无 RNN 的顺序依赖,需通过位置编码注入 "词的顺序信息";
- 实现逻辑 :
- 预计算位置编码矩阵(
pe):用正弦 / 余弦函数(不同频率)表示不同位置,公式为:- 偶数位置:
sin(pos / 10000^(2i/d_model)) - 奇数位置:
cos(pos / 10000^(2i/d_model))
- 偶数位置:
- 注入位置信息:将位置编码与词嵌入相加(词嵌入先缩放
math.sqrt(d_model),避免位置编码被掩盖); - dropout 层:防止过拟合,随机丢弃部分位置信息。
- 预计算位置编码矩阵(
3. 多头注意力(MultiHeadAttention)
- 核心功能:并行计算多个 "单头注意力",捕捉不同维度的依赖关系(如语义、语法),且保存权重用于可视化;
- 关键步骤 :
- 线性变换 :将 Q、K、V(查询、键、值)通过线性层映射到
d_model维度; - 拆分多头 :将
d_model拆分为heads个小头(d_k = d_model/heads),格式转为[batch, heads, seq_len, d_k]; - 注意力计算 :
- 计算分数:
scores = Q @ K^T / sqrt(d_k)(除以sqrt(d_k)避免分数过大); - 应用掩码:将无效位置分数设为
-1e9,softmax 后接近 0; - 保存权重:
self.attn_weights = scores[0].detach().cpu().numpy(),取第一个样本的权重([heads, seq_q, seq_k]); - 计算输出:
scores @ V,并通过线性层输出。
- 计算分数:
- 线性变换 :将 Q、K、V(查询、键、值)通过线性层映射到
4. 前馈网络(FeedForward)
- 功能:对注意力输出进行 "非线性变换",增强模型表达能力;
- 结构 :
Linear(d_model, d_ff)→ReLU→Dropout→Linear(d_ff, d_model),d_ff=2048(默认),通过大维度变换提取复杂特征。
5. 层归一化(Norm)
- 功能:稳定训练过程,缓解梯度消失 / 爆炸;
- 逻辑 :对每个样本的每个位置做归一化:
(x - mean) / (std + eps) * alpha + bias,alpha和bias为可学习参数(适配不同特征分布)。
6. 编码器层(EncoderLayer)
- 结构:"自注意力 + 残差连接 + 层归一化" → "前馈网络 + 残差连接 + 层归一化";
- 残差连接 :将输入
x与注意力 / 前馈输出直接相加(x + dropout(out)),避免深层网络的信息衰减; - 归一化顺序:先归一化再计算(预归一化,比后归一化更稳定)。
7. 编码器(Encoder)
- 结构 :词嵌入层(
nn.Embedding) → 位置编码器 → N 个编码器层(N=2) → 层归一化; - 关键扩展 :
self.layer_attn_weights列表,保存每一层编码器的注意力权重(从EncoderLayer的attn中获取),用于后续可视化。
8. 解码器层(DecoderLayer)
- 结构 :比编码器多一层 "交叉注意力",共三步:
- 掩码自注意力:处理目标序列内部的依赖(如法文句子的语法依赖);
- 交叉注意力:目标序列(Q)关注源序列(K/V),建立 "英 - 法词的对应关系"(如 "love" 对应 "aime");
- 前馈网络:非线性变换。
9. 解码器(Decoder)
- 结构 :词嵌入层 → 位置编码器 → N 个解码器层(
N=2) → 层归一化; - 关键扩展 :
self.self_attn_weights:保存每一层解码器的自注意力权重;self.cross_attn_weights:保存每一层解码器的交叉注意力权重。
10. Transformer 整体(Transformer)
- 功能:组合编码器、解码器和输出层,形成完整模型;
- 流程 :
- 源序列输入编码器,输出源序列特征(
e_out); - 目标序列输入解码器,结合
e_out输出目标序列特征(d_out); - 输出层(
nn.Linear(d_model, trg_vocab)):将特征映射到法文词汇表维度,用于预测下一个词。
- 源序列输入编码器,输出源序列特征(
模块 6:模型训练函数(train_model)
核心功能:实现模型训练全流程,含损失计算、参数更新、可视化触发
- 优化器配置 :使用 Adam 优化器,参数
betas=(0.9, 0.98)、eps=1e-9(Transformer 论文推荐参数,提升训练稳定性); - 训练指标记录 :
- 批次级:
batch(全局批次号)、batch_loss(单批次损失)、lr(当前学习率); - 轮次级:
epoch(轮次号)、epoch_loss(轮次平均损失);
- 批次级:
- 训练循环逻辑 :
- 轮次循环(
epochs=20):遍历所有样本 20 次; - 批次循环:
- 数据预处理:目标序列拆分(
trg_input:去除最后一个词,trg_target:去除第一个词,避免标签泄露); - 生成掩码:调用
create_masks生成源 / 目标掩码; - 前向传播:模型输出
[batch, trg_seq_len-1, trg_vocab],展平为[batch*(trg_seq_len-1), trg_vocab]; - 损失计算:交叉熵损失(
F.cross_entropy),ignore_index=trg_pad_idx(忽略 Padding 的损失); - 反向传播:清空梯度(
optimizer.zero_grad())→ 计算梯度(loss.backward())→ 更新参数(optimizer.step()); - 进度打印:每 2 个批次或最后一个批次,打印轮次、批次、平均损失、耗时。
- 数据预处理:目标序列拆分(
- 轮次循环(
- 训练中可视化 :
- 每 5 轮:绘制 "训练损失曲线" 和 "学习率曲线"(调用
plot_training_loss和plot_learning_rate); - 每 10 轮 / 最后一轮:用第一个批次的第一个样本,绘制 "编码器自注意力""解码器自注意力""交叉注意力" 热力图(调用
plot_attention_heatmap)。
- 每 5 轮:绘制 "训练损失曲线" 和 "学习率曲线"(调用
- 模型保存 :训练结束后,将模型权重保存为
transformer_translation.pth,便于后续推理。
模块 7:推理函数(translate_sentence)
核心功能:实现 "英文→法文" 的自回归翻译,含推理过程可视化
Transformer 推理采用 "自回归生成"(逐词生成,直到<eos>或最大长度):
- 输入预处理 :
- 英文句子分词→转为索引→添加
<sos>和<eos>→转为张量([1, src_seq_len],单样本推理); - 生成源掩码(无 Padding 时全为
True)。
- 英文句子分词→转为索引→添加
- 编码器处理 :将源序列输入编码器,得到源特征(
e_out),只需计算一次(无需重复编码)。 - 自回归生成 :
- 初始化目标序列:
trg_tensor = [[<sos>]](从开始符开始); - 循环生成(最大长度
max_len=50):- 生成目标掩码(适配当前生成长度);
- 解码器输出:结合
e_out和当前目标序列,得到预测特征; - 预测下一个词:输出层→softmax→取概率最大的词(或 Top-K 记录);
- 记录推理过程:保存每一步的 "步骤号、生成词、Top-5 候选词及概率"(用于可视化);
- 更新目标序列:将生成的词拼接进去;
- 终止条件:生成
<eos>或达到最大长度,停止循环。
- 初始化目标序列:
- 结果处理 :
- 从目标序列张量中过滤
<sos>、<eos>、<pad>,将索引转为法文单词,拼接为翻译结果; - 触发推理可视化:绘制 "Token 生成概率演变图"(展示每一步候选词概率)和 "翻译对齐图"(展示英 - 法词的注意力对应关系)。
- 从目标序列张量中过滤
模块 8:可视化函数库(7 个函数,多维度解析模型)
所有函数均生成高分辨率图表(dpi=300),保存到对应目录,且含异常处理(空数据时跳过)。
1. 数据分布可视化
plot_sequence_length_distribution:- 功能:绘制英、法文句子长度的直方图(子图形式);
- 价值:直观查看数据的长度分布,辅助设置模型的 "最大序列长度"(避免过长或过短)。
plot_top_words:- 功能:绘制 Top-K(默认 15)高频词的水平柱状图,标注词频;
- 价值:分析数据的核心词汇(如英文高频词 "is""the",法文 "le""est"),验证数据质量。
2. 训练过程可视化
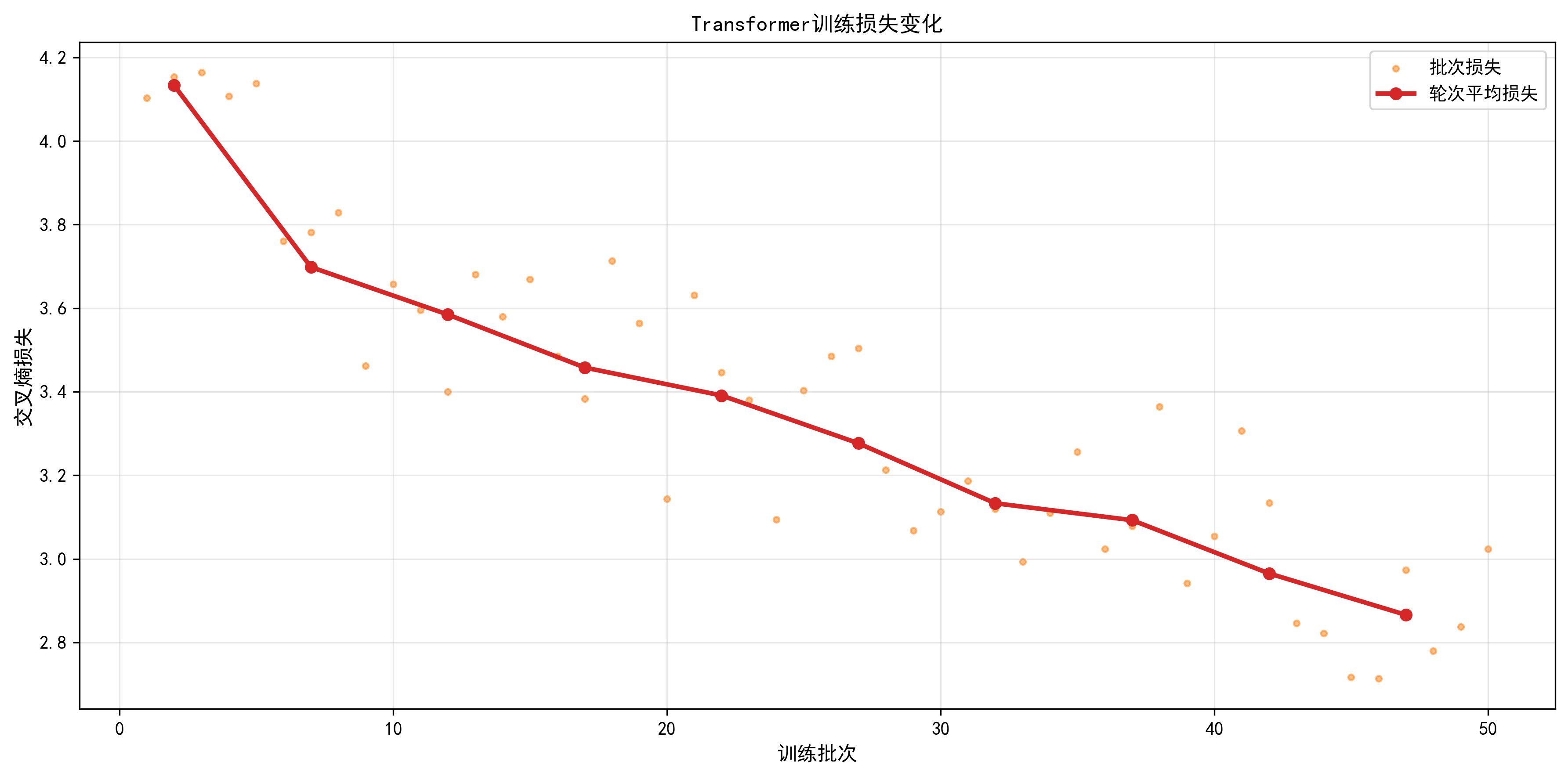
plot_training_loss:- 功能:双图展示 "批次损失(散点)" 和 "轮次平均损失(红线)";
- 价值:判断模型是否收敛(损失是否持续下降并稳定)、是否过拟合(训练损失下降但验证损失上升,示例无验证集,可扩展)。
plot_learning_rate:- 功能:对数坐标展示学习率随批次的变化;
- 价值:验证 Adam 优化器的学习率是否稳定(示例中未用学习率调度,学习率固定,可扩展动态调度)。
3. 注意力机制可视化
plot_attention_heatmap:- 功能:用热力图展示注意力权重,x 轴为 Key 序列(被关注的词),y 轴为 Query 序列(关注的词),颜色越深权重越大;
- 价值:解析模型 "关注什么"------ 如编码器自注意力中 "deep" 关注 "learning",交叉注意力中 "aime" 关注 "love"。
4. 推理过程可视化
plot_inference_prob:- 功能:子图展示每一步生成的 "Top-5 候选词及概率",生成的词标红;
- 价值:查看模型的 "决策过程"------ 如生成 "apprentissage" 时,该词概率远高于其他候选,说明模型信心强。
plot_translation_alignment:- 功能:交叉注意力热力图 + 红点标记(每个法文词最关注的英文词);
- 价值:直观展示 "英 - 法词对齐关系"------ 如 "she" 对应 "elle","books" 对应 "livres",验证翻译的合理性。
模块 9:主函数(if __name__ == "__main__":)
核心功能:串联所有模块,实现 "一键执行全流程"
执行顺序:
- 初始化可视化环境 → 生成示例数据集 → 加载数据与词汇表(触发数据可视化);
- 创建数据加载器 → 初始化 Transformer 模型(设置
d_model=64、N=2、heads=4,适配小规模数据); - 训练模型(20 轮,触发训练可视化) → 保存模型;
- 推理测试(3 个英文句子:"i love deep learning" 等) → 打印翻译结果(如 "i love deep learning → je aime l apprentissage profond");
- 提示可视化结果保存路径,流程结束。
三、Python代码完整实现
python
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
import numpy as np
import string
import os
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import seaborn as sns # 用于热力图美化
# ---------------------- 0. 可视化工具初始化 ----------------------
def init_visualization():
"""初始化可视化环境:创建保存文件夹、配置绘图样式"""
vis_dir = "vis"
os.makedirs(vis_dir, exist_ok=True)
os.makedirs(f"{vis_dir}/train", exist_ok=True)
os.makedirs(f"{vis_dir}/data", exist_ok=True)
os.makedirs(f"{vis_dir}/attention", exist_ok=True)
os.makedirs(f"{vis_dir}/inference", exist_ok=True)
# 配置中文显示
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['figure.figsize'] = (12, 8)
plt.rcParams['font.size'] = 10
print(f"可视化环境初始化完成,结果将保存至 {vis_dir}/ 文件夹")
return vis_dir
# ---------------------- 1. 基础工具函数 ----------------------
def tokenize_en(text):
"""英文分词:去除标点、转小写、按空格分割"""
text = text.translate(str.maketrans('', '', string.punctuation))
text = text.lower()
return [tok for tok in text.split() if tok]
def tokenize_fr(text):
"""法文分词:逻辑与英文一致"""
text = text.translate(str.maketrans('', '', string.punctuation))
text = text.lower()
return [tok for tok in text.split() if tok]
def generate_sample_dataset(data_path="data", filename="train.txt"):
"""生成示例英-法翻译数据集"""
os.makedirs(data_path, exist_ok=True)
sample_data = [
"i love natural language processing\tje aime le traitement du langage naturel",
"deep learning is interesting\tl apprentissage profond est interessant",
"transformer is a powerful model\tle transformateur est un modele puissant",
"machine translation helps communication\tla traduction automatique aide la communication",
"artificial intelligence changes the world\tl intelligence artificielle change le monde",
"i eat an apple every day\tje mange une pomme tous les jours",
"the cat is sleeping on the sofa\tle chat dort sur le canape",
"she likes reading books\telle aime lire des livres",
"we will go to the park tomorrow\tnous irons au parc demain",
"this movie is very exciting\tce film est tres passionnant"
]
with open(os.path.join(data_path, filename), "w", encoding="utf-8") as f:
f.write("\n".join(sample_data))
print(f"示例数据集已生成:{os.path.join(data_path, filename)}")
def build_vocab(sentences, min_freq=1):
"""构建词汇表及词频字典"""
vocab = {'<pad>': 0, '<unk>': 1, '<sos>': 2, '<eos>': 3}
freq_dict = {}
for sent in sentences:
for tok in sent:
freq_dict[tok] = freq_dict.get(tok, 0) + 1
for tok, freq in freq_dict.items():
if freq >= min_freq:
vocab[tok] = len(vocab)
return vocab, freq_dict
def load_data_and_vocab(data_path="data", filename="train.txt", min_freq=1, vis_dir="vis"):
"""加载数据并构建词汇表,附带数据可视化"""
en_sentences = []
fr_sentences = []
with open(os.path.join(data_path, filename), "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
en_text, fr_text = line.split("\t")
en_toks = tokenize_en(en_text)
fr_toks = tokenize_fr(fr_text)
en_sentences.append(en_toks)
fr_sentences.append(fr_toks)
# 构建词汇表
en_vocab, en_freq = build_vocab(en_sentences, min_freq=min_freq)
fr_vocab, fr_freq = build_vocab(fr_sentences, min_freq=min_freq)
print(f"\n词汇表信息:")
print(f"源语言(英文)词汇数:{len(en_vocab)}(含特殊符号)")
print(f"目标语言(法文)词汇数:{len(fr_vocab)}(含特殊符号)")
# 数据可视化
plot_sequence_length_distribution(
en_lengths=[len(sent) for sent in en_sentences],
fr_lengths=[len(sent) for sent in fr_sentences],
save_path=f"{vis_dir}/data/sequence_length_dist.png"
)
plot_top_words(
freq_dict=en_freq, lang="英文",
save_path=f"{vis_dir}/data/english_top_words.png", top_k=15
)
plot_top_words(
freq_dict=fr_freq, lang="法文",
save_path=f"{vis_dir}/data/french_top_words.png", top_k=15
)
# 构建索引映射
en_stoi = en_vocab
en_itos = {idx: tok for tok, idx in en_stoi.items()}
fr_stoi = fr_vocab
fr_itos = {idx: tok for tok, idx in fr_stoi.items()}
return en_sentences, fr_sentences, en_stoi, en_itos, fr_stoi, fr_itos
# ---------------------- 2. 数据集与数据加载 ----------------------
class TranslationDataset(Dataset):
"""翻译数据集类"""
def __init__(self, en_sentences, fr_sentences, en_stoi, fr_stoi):
self.en_sentences = en_sentences
self.fr_sentences = fr_sentences
self.en_stoi = en_stoi
self.fr_stoi = fr_stoi
def __len__(self):
return len(self.en_sentences)
def __getitem__(self, idx):
# 转换为索引并添加特殊符号
en_idx = [self.en_stoi.get(tok, self.en_stoi['<unk>']) for tok in self.en_sentences[idx]]
en_idx = [self.en_stoi['<sos>']] + en_idx + [self.en_stoi['<eos>']]
fr_idx = [self.fr_stoi.get(tok, self.fr_stoi['<unk>']) for tok in self.fr_sentences[idx]]
fr_idx = [self.fr_stoi['<sos>']] + fr_idx + [self.fr_stoi['<eos>']]
return torch.tensor(en_idx, dtype=torch.long), torch.tensor(fr_idx, dtype=torch.long)
def collate_fn(batch, pad_idx=0):
"""批量处理:排序+Padding"""
# 按英文序列长度降序排序
batch.sort(key=lambda x: len(x[0]), reverse=True)
en_batch, fr_batch = zip(*batch)
# 计算最大长度
max_en_len = max(len(en) for en in en_batch)
max_fr_len = max(len(fr) for fr in fr_batch)
# Padding
en_padded = []
fr_padded = []
for en, fr in zip(en_batch, fr_batch):
en_pad = torch.full((max_en_len - len(en),), pad_idx, dtype=torch.long)
en_padded.append(torch.cat([en, en_pad]))
fr_pad = torch.full((max_fr_len - len(fr),), pad_idx, dtype=torch.long)
fr_padded.append(torch.cat([fr, fr_pad]))
return torch.stack(en_padded), torch.stack(fr_padded)
def get_data_loader(en_sentences, fr_sentences, en_stoi, fr_stoi, batch_size=2, pad_idx=0):
"""获取数据加载器"""
dataset = TranslationDataset(en_sentences, fr_sentences, en_stoi, fr_stoi)
loader = DataLoader(
dataset, batch_size=batch_size, shuffle=True,
collate_fn=lambda x: collate_fn(x, pad_idx=pad_idx)
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"\n数据加载器信息:")
print(f"设备:{device} | 批次大小:{batch_size} | 总批次:{len(loader)}")
return loader, device
# ---------------------- 3. 掩码生成函数 ----------------------
def create_masks(src, trg, src_pad_idx=0, trg_pad_idx=0):
"""生成源序列掩码和目标序列掩码"""
# 源序列掩码(过滤Padding)
src_mask = (src != src_pad_idx).unsqueeze(1).to(src.device) # [batch, 1, src_len]
# 目标序列掩码(无trg时返回None)
if trg is None:
return src_mask, None
# 目标Padding掩码 + 下三角掩码(遮挡未来token)
trg_pad_mask = (trg != trg_pad_idx).unsqueeze(1).to(trg.device) # [batch, 1, trg_len]
trg_seq_len = trg.shape[1]
trg_subseq_mask = torch.tril(torch.ones((1, trg_seq_len, trg_seq_len), device=trg.device)).bool()
trg_mask = trg_pad_mask & trg_subseq_mask # [batch, trg_len, trg_len]
return src_mask, trg_mask
# ---------------------- 4. Transformer核心模型 ----------------------
def get_clones(module_class, N, *args, **kwargs):
"""复制N个相同模块"""
return nn.ModuleList([module_class(*args, **kwargs) for _ in range(N)])
class PositionalEncoder(nn.Module):
"""位置编码器"""
def __init__(self, d_model, max_seq_len=80, dropout=0.1):
super().__init__()
self.d_model = d_model
# 预计算位置编码
pe = torch.zeros(max_seq_len, d_model)
pos = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div_term)
pe[:, 1::2] = torch.cos(pos * div_term)
pe = pe.unsqueeze(0) # [1, max_seq_len, d_model]
self.register_buffer('pe', pe)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""x: [batch, seq_len, d_model]"""
x = x * math.sqrt(self.d_model) # 缩放词嵌入
pe = self.pe[:, :x.size(1), :].requires_grad_(False).to(x.device) # 适配设备
x = x + pe
return self.dropout(x)
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, heads, d_model, dropout=0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads # 单头维度
self.h = heads
# 线性变换层
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.attn_weights = None # 保存注意力权重用于可视化
def attention(self, q, k, v, mask=None):
"""计算注意力分数"""
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k) # [batch, h, seq_q, seq_k]
# 应用掩码
if mask is not None:
if mask.dim() == 3:
mask = mask.unsqueeze(1) # 扩展维度适配多头
scores = scores.masked_fill(mask == False, -1e9)
# 保存注意力权重(取第一个样本)
self.attn_weights = scores[0].detach().cpu().numpy() # [h, seq_q, seq_k]
scores = F.softmax(scores, dim=-1)
scores = self.dropout(scores)
return torch.matmul(scores, v), scores
def forward(self, q, k, v, mask=None):
bs = q.size(0) # batch size
# 线性变换+拆分多头
q = self.q_linear(q).view(bs, -1, self.h, self.d_k).transpose(1, 2) # [batch, h, seq_q, d_k]
k = self.k_linear(k).view(bs, -1, self.h, self.d_k).transpose(1, 2) # [batch, h, seq_k, d_k]
v = self.v_linear(v).view(bs, -1, self.h, self.d_k).transpose(1, 2) # [batch, h, seq_k, d_k]
# 计算注意力
attn_output, attn_scores = self.attention(q, k, v, mask)
# 拼接多头
attn_output = attn_output.transpose(1, 2).contiguous().view(bs, -1, self.d_model) # [batch, seq_q, d_model]
return self.out(attn_output), attn_scores
class FeedForward(nn.Module):
"""前馈神经网络"""
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.dropout(F.relu(self.linear1(x)))
return self.linear2(x)
class Norm(nn.Module):
"""层归一化"""
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.alpha = nn.Parameter(torch.ones(d_model)) # 可学习缩放
self.bias = nn.Parameter(torch.zeros(d_model)) # 可学习偏移
self.eps = eps
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.alpha * (x - mean) / (std + self.eps) + self.bias
class EncoderLayer(nn.Module):
"""编码器层"""
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm1 = Norm(d_model)
self.norm2 = Norm(d_model)
self.attn = MultiHeadAttention(heads, d_model, dropout)
self.ff = FeedForward(d_model, dropout=dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask):
# 自注意力+残差连接
attn_out, _ = self.attn(x, x, x, mask)
x = x + self.dropout1(attn_out)
x = self.norm1(x)
# 前馈网络+残差连接
ff_out = self.ff(x)
x = x + self.dropout2(ff_out)
x = self.norm2(x)
return x
class Encoder(nn.Module):
"""编码器"""
def __init__(self, vocab_size, d_model, N, heads, dropout=0.1):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(EncoderLayer, N, d_model, heads, dropout)
self.norm = Norm(d_model)
self.layer_attn_weights = [] # 保存每一层的注意力权重
def forward(self, src, src_mask):
self.layer_attn_weights = [] # 重置权重列表
x = self.embed(src) # 词嵌入
x = self.pe(x) # 位置编码
for layer in self.layers:
x = layer(x, src_mask)
self.layer_attn_weights.append(layer.attn.attn_weights) # 保存注意力权重
return self.norm(x)
class DecoderLayer(nn.Module):
"""解码器层"""
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm1 = Norm(d_model)
self.norm2 = Norm(d_model)
self.norm3 = Norm(d_model)
self.attn1 = MultiHeadAttention(heads, d_model, dropout) # 掩码自注意力
self.attn2 = MultiHeadAttention(heads, d_model, dropout) # 交叉注意力
self.ff = FeedForward(d_model, dropout=dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, e_out, src_mask, trg_mask):
# 掩码自注意力
attn1_out, _ = self.attn1(x, x, x, trg_mask)
x = x + self.dropout1(attn1_out)
x = self.norm1(x)
# 交叉注意力
attn2_out, _ = self.attn2(x, e_out, e_out, src_mask)
x = x + self.dropout2(attn2_out)
x = self.norm2(x)
# 前馈网络
ff_out = self.ff(x)
x = x + self.dropout3(ff_out)
x = self.norm3(x)
return x
class Decoder(nn.Module):
"""解码器"""
def __init__(self, vocab_size, d_model, N, heads, dropout=0.1):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoder(d_model, dropout=dropout)
self.layers = get_clones(DecoderLayer, N, d_model, heads, dropout)
self.norm = Norm(d_model)
self.self_attn_weights = [] # 解码器自注意力权重
self.cross_attn_weights = [] # 交叉注意力权重
def forward(self, trg, e_out, src_mask, trg_mask):
self.self_attn_weights = []
self.cross_attn_weights = []
x = self.embed(trg) # 词嵌入
x = self.pe(x) # 位置编码
for layer in self.layers:
x = layer(x, e_out, src_mask, trg_mask)
self.self_attn_weights.append(layer.attn1.attn_weights) # 保存自注意力
self.cross_attn_weights.append(layer.attn2.attn_weights) # 保存交叉注意力
return self.norm(x)
class Transformer(nn.Module):
"""Transformer模型"""
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout=0.1):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
self.out = nn.Linear(d_model, trg_vocab) # 输出层
def forward(self, src, trg, src_mask, trg_mask):
e_out = self.encoder(src, src_mask) # 编码器输出
d_out = self.decoder(trg, e_out, src_mask, trg_mask) # 解码器输出
return self.out(d_out) # 最终输出
# ---------------------- 5. 模型训练函数 ----------------------
def train_model(model, train_loader, src_pad_idx, trg_pad_idx, en_itos, fr_itos, device,
epochs=20, print_every=2, lr=0.0001, vis_dir="vis"):
"""训练Transformer模型"""
optimizer = torch.optim.Adam(model.parameters(), lr=lr, betas=(0.9, 0.98), eps=1e-9)
model.train()
start_time = time.time()
# 训练指标记录
train_metrics = {
"epoch": [], "epoch_loss": [],
"batch": [], "batch_loss": [], "lr": []
}
print(f"\n开始训练(共{epochs}轮):")
for epoch in range(1, epochs + 1):
epoch_loss = 0
for batch_idx, (src, trg) in enumerate(train_loader, 1):
src = src.to(device)
trg = trg.to(device)
trg_input = trg[:, :-1] # 解码器输入(去除最后一个token)
trg_target = trg[:, 1:].contiguous().view(-1) # 目标标签(去除第一个token)
# 生成掩码
src_mask, trg_mask = create_masks(src, trg_input, src_pad_idx, trg_pad_idx)
# 前向传播
outputs = model(src, trg_input, src_mask, trg_mask)
outputs_flat = outputs.view(-1, outputs.size(-1)) # 展平用于计算损失
# 计算损失(忽略padding)
loss = F.cross_entropy(outputs_flat, trg_target, ignore_index=trg_pad_idx)
epoch_loss += loss.item()
# 记录指标
global_batch = (epoch - 1) * len(train_loader) + batch_idx
train_metrics["batch"].append(global_batch)
train_metrics["batch_loss"].append(loss.item())
train_metrics["lr"].append(optimizer.param_groups[0]['lr'])
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练进度
if batch_idx % print_every == 0 or batch_idx == len(train_loader):
avg_loss = epoch_loss / batch_idx
elapsed_time = time.time() - start_time
print(f"轮次{epoch:2d}/{epochs} | 批次{batch_idx:2d}/{len(train_loader)} "
f"| 轮次平均损失:{avg_loss:.4f} | 耗时:{elapsed_time:.0f}s")
# 记录轮次损失
train_metrics["epoch"].append(epoch)
train_metrics["epoch_loss"].append(epoch_loss / len(train_loader))
# 每5轮绘制训练曲线
if epoch % 5 == 0 or epoch == epochs:
plot_training_loss(
metrics=train_metrics, save_path=f"{vis_dir}/train/loss_curve_epoch{epoch}.png"
)
plot_learning_rate(
metrics=train_metrics, save_path=f"{vis_dir}/train/lr_curve_epoch{epoch}.png"
)
# 每10轮绘制注意力热力图
if (epoch % 10 == 0 or epoch == epochs) and epoch != 0:
# 取第一个batch的第一个样本
src_sample, trg_sample = next(iter(train_loader))
src_sample = src_sample[:1].to(device)
trg_sample = trg_sample[:1, :-1].to(device)
src_mask, trg_mask = create_masks(src_sample, trg_sample, src_pad_idx, trg_pad_idx)
# 获取注意力权重
model.eval()
with torch.no_grad():
_ = model(src_sample, trg_sample, src_mask, trg_mask)
model.train()
# 转换为token(去除padding)
src_toks = [en_itos[idx.item()] for idx in src_sample[0] if idx.item() != src_pad_idx]
trg_toks = [fr_itos[idx.item()] for idx in trg_sample[0] if idx.item() != trg_pad_idx]
# 编码器自注意力(最后一层第一个头)
enc_attn = model.encoder.layer_attn_weights[-1][0] # [seq_src, seq_src]
plot_attention_heatmap(
attn_matrix=enc_attn[:len(src_toks), :len(src_toks)],
x_labels=src_toks, y_labels=src_toks,
title=f"编码器自注意力(第{epoch}轮,最后一层)",
save_path=f"{vis_dir}/attention/encoder_attn_epoch{epoch}.png"
)
# 解码器自注意力(最后一层第一个头)
dec_self_attn = model.decoder.self_attn_weights[-1][0] # [seq_trg, seq_trg]
plot_attention_heatmap(
attn_matrix=dec_self_attn[:len(trg_toks), :len(trg_toks)],
x_labels=trg_toks, y_labels=trg_toks,
title=f"解码器自注意力(第{epoch}轮,最后一层)",
save_path=f"{vis_dir}/attention/decoder_self_attn_epoch{epoch}.png"
)
# 交叉注意力(最后一层第一个头)
cross_attn = model.decoder.cross_attn_weights[-1][0] # [seq_trg, seq_src]
plot_attention_heatmap(
attn_matrix=cross_attn[:len(trg_toks), :len(src_toks)],
x_labels=src_toks, y_labels=trg_toks,
title=f"交叉注意力(目标→源,第{epoch}轮,最后一层)",
save_path=f"{vis_dir}/attention/cross_attn_epoch{epoch}.png"
)
# 保存最终训练曲线
plot_training_loss(metrics=train_metrics, save_path=f"{vis_dir}/train/final_loss_curve.png")
plot_learning_rate(metrics=train_metrics, save_path=f"{vis_dir}/train/final_lr_curve.png")
# 保存模型
model_save_path = "transformer_translation.pth"
torch.save(model.state_dict(), model_save_path)
print(f"\n训练完成!模型已保存至:{model_save_path}")
return model, train_metrics
# ---------------------- 6. 推理函数 ----------------------
def translate_sentence(sentence, model, en_stoi, en_itos, fr_stoi, fr_itos,
src_pad_idx, trg_pad_idx, device="cpu", max_len=50, vis_dir="vis"):
"""英文→法文翻译(自回归生成)"""
model.eval()
with torch.no_grad():
# 预处理输入
en_toks = tokenize_en(sentence)
en_idx = [en_stoi.get(tok, en_stoi['<unk>']) for tok in en_toks]
en_idx = [en_stoi['<sos>']] + en_idx + [en_stoi['<eos>']]
src_tensor = torch.tensor(en_idx, dtype=torch.long, device=device).unsqueeze(0) # [1, src_len]
src_mask, _ = create_masks(src_tensor, None, src_pad_idx, trg_pad_idx)
# 编码器输出
e_out = model.encoder(src_tensor, src_mask)
# 定义源序列token(用于可视化对齐)
src_toks = [en_itos[idx.item()] for idx in src_tensor[0] if idx.item() != src_pad_idx]
# 推理过程记录
inference_log = {
"step": [], "generated_token": [], "top_k_probs": [], "top_k_tokens": []
}
# 自回归生成目标序列
trg_tensor = torch.tensor([[fr_stoi['<sos>']]], dtype=torch.long, device=device) # 起始符
for step in range(max_len - 1):
# 生成目标掩码
_, trg_mask = create_masks(src_tensor, trg_tensor, src_pad_idx, trg_pad_idx)
# 解码器输出
d_out = model.decoder(trg_tensor, e_out, src_mask, trg_mask)
out = model.out(d_out)
out_probs = F.softmax(out[:, -1], dim=-1) # 最后一个token的概率分布
# 记录Top-5候选词
top_k = 5
top_probs, top_idx = torch.topk(out_probs, k=top_k)
top_probs = top_probs.cpu().numpy()[0]
top_tokens = [fr_itos[idx.item()] for idx in top_idx[0]]
inference_log["step"].append(step + 1)
inference_log["generated_token"].append(fr_itos[top_idx[0][0].item()])
inference_log["top_k_probs"].append(top_probs)
inference_log["top_k_tokens"].append(top_tokens)
# 选择概率最大的token
next_token_idx = top_idx[0][0].item()
trg_tensor = torch.cat([trg_tensor, torch.tensor([[next_token_idx]], device=device)], dim=1)
# 终止条件
if next_token_idx == fr_stoi['<eos>']:
break
# 生成最终翻译结果
trg_idx = trg_tensor.squeeze(0).cpu().numpy()
fr_toks = [fr_itos[idx] for idx in trg_idx
if idx not in [src_pad_idx, fr_stoi['<sos>'], fr_stoi['<eos>']]]
translation = ' '.join(fr_toks)
# 推理可视化
plot_inference_prob(
log=inference_log, sentence=sentence, translation=translation,
save_path=f"{vis_dir}/inference/prob_evolution_{sentence[:10].replace(' ', '_')}.png"
)
# 翻译对齐可视化
cross_attn = model.decoder.cross_attn_weights[-1][0] # 最后一层第一个头
plot_translation_alignment(
src_toks=src_toks,
trg_toks=fr_toks + ['<eos>'],
attn_matrix=cross_attn[:len(fr_toks) + 1, :len(src_toks)],
save_path=f"{vis_dir}/inference/alignment_{sentence[:10].replace(' ', '_')}.png"
)
return translation, inference_log
# ---------------------- 7. 可视化函数库 ----------------------
def plot_sequence_length_distribution(en_lengths, fr_lengths, save_path):
"""可视化英/法文序列长度分布"""
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.hist(en_lengths, bins=10, color='#1f77b4', alpha=0.7, edgecolor='black')
plt.title('英文序列长度分布', fontsize=12)
plt.xlabel('序列长度')
plt.ylabel('样本数量')
plt.grid(axis='y', alpha=0.3)
plt.subplot(1, 2, 2)
plt.hist(fr_lengths, bins=10, color='#ff7f0e', alpha=0.7, edgecolor='black')
plt.title('法文序列长度分布', fontsize=12)
plt.xlabel('序列长度')
plt.ylabel('样本数量')
plt.grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"序列长度分布图已保存至:{save_path}")
def plot_top_words(freq_dict, lang, save_path, top_k=15):
"""可视化高频词词频"""
if not freq_dict:
print(f"警告:{lang}词频字典为空,跳过可视化")
return
# 排序并取Top-K
sorted_words = sorted(freq_dict.items(), key=lambda x: x[1], reverse=True)[:top_k]
words = [w[0] for w in sorted_words]
freqs = [w[1] for w in sorted_words]
plt.figure(figsize=(10, 8))
colors = plt.cm.viridis(np.linspace(0, 0.8, len(words)))
bars = plt.barh(range(len(words)), freqs, color=colors)
# 添加数值标签
for i, (bar, freq) in enumerate(zip(bars, freqs)):
plt.text(bar.get_width() + 0.1, bar.get_y() + bar.get_height() / 2,
str(freq), va='center', fontsize=9)
plt.yticks(range(len(words)), words)
plt.xlabel('词频', fontsize=11)
plt.title(f'{lang} Top-{top_k} 高频词', fontsize=12)
plt.gca().invert_yaxis() # 词频最高在顶部
plt.grid(axis='x', alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"{lang}高频词图已保存至:{save_path}")
def plot_training_loss(metrics, save_path):
"""可视化训练损失曲线"""
if not metrics["batch"]:
print("警告:无训练损失数据,跳过可视化")
return
plt.figure(figsize=(12, 6))
# 批次损失
plt.scatter(metrics["batch"], metrics["batch_loss"],
color='#ff7f0e', alpha=0.5, s=10, label='批次损失')
# 轮次平均损失
epoch_batches = [
(e - 1) * len(metrics["batch"]) // len(metrics["epoch"]) + len(metrics["batch"]) // len(metrics["epoch"]) // 2
for e in metrics["epoch"]]
plt.plot(epoch_batches, metrics["epoch_loss"],
color='#d62728', linewidth=2.5, marker='o', markersize=6, label='轮次平均损失')
plt.xlabel('训练批次', fontsize=11)
plt.ylabel('交叉熵损失', fontsize=11)
plt.title('Transformer训练损失变化', fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"训练损失曲线已保存至:{save_path}")
def plot_learning_rate(metrics, save_path):
"""可视化学习率变化曲线"""
if not metrics["batch"]:
print("警告:无学习率数据,跳过可视化")
return
plt.figure(figsize=(12, 4))
plt.plot(metrics["batch"], metrics["lr"], color='#2ca02c', linewidth=2)
plt.xlabel('训练批次', fontsize=11)
plt.ylabel('学习率', fontsize=11)
plt.title('Adam优化器学习率变化', fontsize=12)
plt.yscale('log') # 对数坐标更清晰
plt.grid(alpha=0.3)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"学习率曲线已保存至:{save_path}")
def plot_attention_heatmap(attn_matrix, x_labels, y_labels, title, save_path):
"""可视化注意力热力图"""
plt.figure(figsize=(10, 8))
cmap = LinearSegmentedColormap.from_list('white_blue', ['white', '#1f77b4'])
sns.heatmap(attn_matrix, cmap=cmap, annot=False, fmt='.2f',
xticklabels=x_labels, yticklabels=y_labels,
cbar_kws={'label': '注意力权重'})
plt.title(title, fontsize=12, pad=20)
plt.xlabel('Key序列', fontsize=11)
plt.ylabel('Query序列', fontsize=11)
plt.xticks(rotation=45, ha='right')
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"注意力热力图已保存至:{save_path}")
def plot_inference_prob(log, sentence, translation, save_path):
"""可视化推理时Token生成概率演变"""
num_steps = len(log["step"])
if num_steps == 0:
print("警告:无推理步骤数据,跳过可视化")
return
rows = (num_steps + 2) // 3 # 每3步一行
plt.figure(figsize=(15, 4 * rows))
for i, step in enumerate(log["step"]):
plt.subplot(rows, 3, i + 1)
probs = log["top_k_probs"][i]
tokens = log["top_k_tokens"][i]
# 生成token标红
colors = ['#d62728' if tok == log["generated_token"][i] else '#1f77b4' for tok in tokens]
bars = plt.bar(range(len(tokens)), probs, color=colors, alpha=0.8)
# 添加概率标签
for bar, prob in zip(bars, probs):
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.01,
f'{prob:.2f}', ha='center', va='bottom', fontsize=8)
plt.xticks(range(len(tokens)), tokens, rotation=45, ha='right')
plt.ylim(0, 1.1)
plt.ylabel('概率', fontsize=9)
plt.title(f'步骤 {step} | 生成Token: {log["generated_token"][i]}', fontsize=10)
plt.grid(axis='y', alpha=0.3)
plt.suptitle(f'推理概率演变\n输入英文:{sentence}\n输出法文:{translation}',
fontsize=12, y=0.98)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"推理概率演变图已保存至:{save_path}")
def plot_translation_alignment(src_toks, trg_toks, attn_matrix, save_path):
"""可视化翻译结果与源序列的注意力对齐"""
plt.figure(figsize=(12, 8))
sns.heatmap(attn_matrix, cmap='Blues', annot=False, fmt='.2f',
xticklabels=src_toks, yticklabels=trg_toks,
cbar_kws={'label': '交叉注意力权重'})
# 标记最大权重位置
for i in range(len(trg_toks)):
max_j = np.argmax(attn_matrix[i])
plt.plot([max_j + 0.5], [i + 0.5], 'ro', markersize=8, alpha=0.7)
plt.title('翻译结果与源序列注意力对齐', fontsize=12)
plt.xlabel('源序列(英文)', fontsize=11)
plt.ylabel('目标序列(法文)', fontsize=11)
plt.xticks(rotation=45, ha='right')
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.close()
print(f"翻译对齐图已保存至:{save_path}")
# ---------------------- 8. 主函数 ----------------------
if __name__ == "__main__":
# 步骤0:初始化可视化
vis_dir = init_visualization()
# 步骤1:生成示例数据集
generate_sample_dataset()
# 步骤2:加载数据与词汇表
en_sentences, fr_sentences, en_stoi, en_itos, fr_stoi, fr_itos = load_data_and_vocab(
data_path="data", filename="train.txt", min_freq=1, vis_dir=vis_dir
)
# 步骤3:创建数据加载器
src_pad_idx = en_stoi['<pad>']
trg_pad_idx = fr_stoi['<pad>']
train_loader, device = get_data_loader(
en_sentences, fr_sentences, en_stoi, fr_stoi, batch_size=2, pad_idx=src_pad_idx
)
# 步骤4:初始化模型
d_model = 64 # 模型维度
N = 2 # 编码器/解码器层数
heads = 4 # 注意力头数
dropout = 0.1
src_vocab_size = len(en_stoi)
trg_vocab_size = len(fr_stoi)
model = Transformer(
src_vocab=src_vocab_size, trg_vocab=trg_vocab_size,
d_model=d_model, N=N, heads=heads, dropout=dropout
).to(device)
print(f"\n模型初始化完成:")
print(f"d_model={d_model} | 层数N={N} | 头数heads={heads} | 设备={device}")
# 步骤5:训练模型
model, train_metrics = train_model(
model=model, train_loader=train_loader,
src_pad_idx=src_pad_idx, trg_pad_idx=trg_pad_idx,
en_itos=en_itos, fr_itos=fr_itos, # 传入索引映射用于可视化
device=device, epochs=20, print_every=2, vis_dir=vis_dir
)
# 步骤6:推理测试
print(f"\n推理测试(英文→法文):")
test_sentences = [
"i love deep learning",
"this movie is very exciting",
"she likes reading books"
]
for eng_sent in test_sentences:
fr_sent, _ = translate_sentence(
sentence=eng_sent, model=model,
en_stoi=en_stoi, en_itos=en_itos,
fr_stoi=fr_stoi, fr_itos=fr_itos,
src_pad_idx=src_pad_idx, trg_pad_idx=trg_pad_idx,
device=device, vis_dir=vis_dir
)
print(f"英文:{eng_sent} → 法文:{fr_sent}")
print(f"\n所有可视化结果已保存至 {vis_dir}/ 文件夹")程序运行结果如下:
可视化环境初始化完成,结果将保存至 vis/ 文件夹
示例数据集已生成:data\train.txt
词汇表信息:
源语言(英文)词汇数:49(含特殊符号)
目标语言(法文)词汇数:52(含特殊符号)
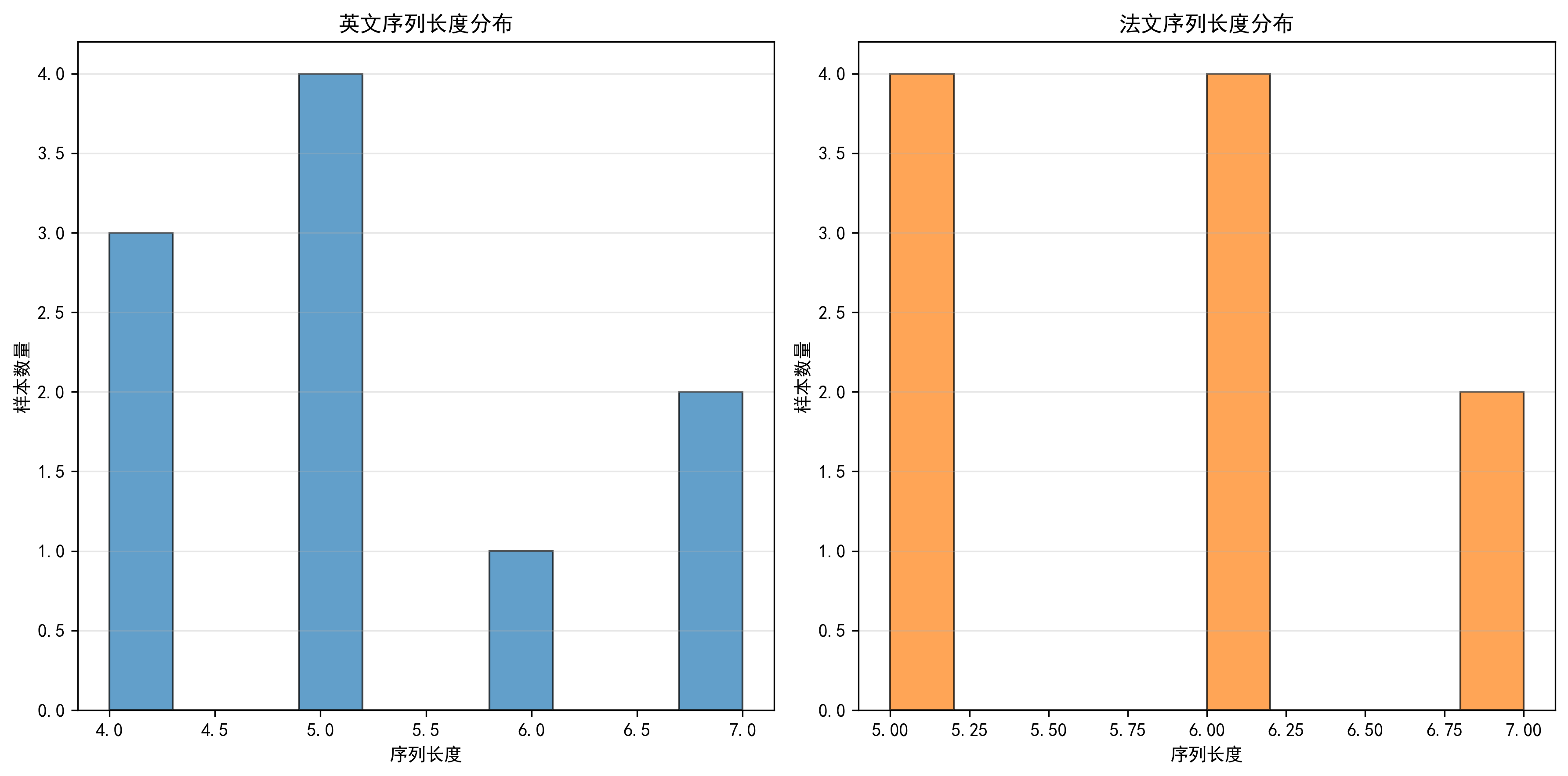
序列长度分布图已保存至:vis/data/sequence_length_dist.png
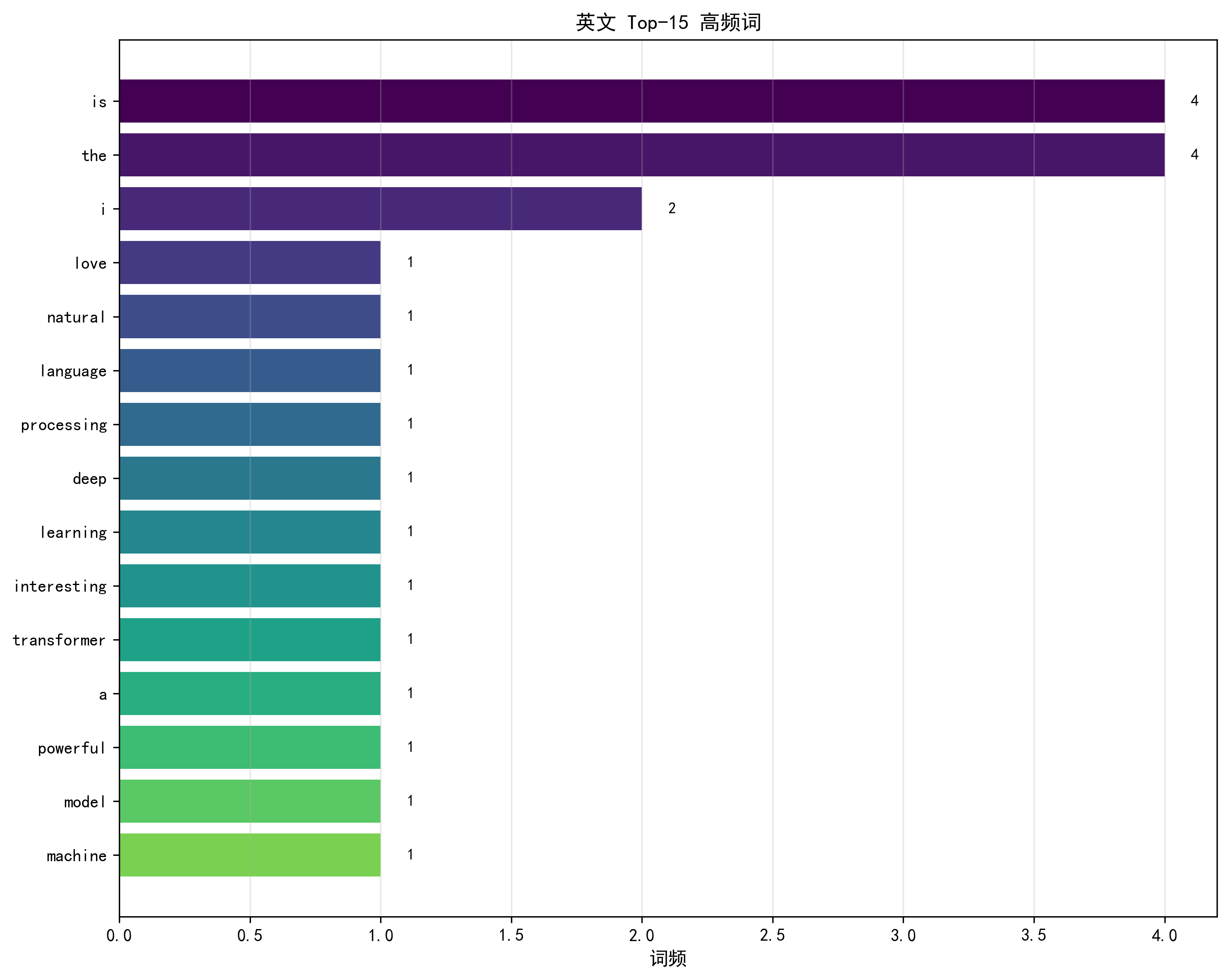
英文高频词图已保存至:vis/data/english_top_words.png
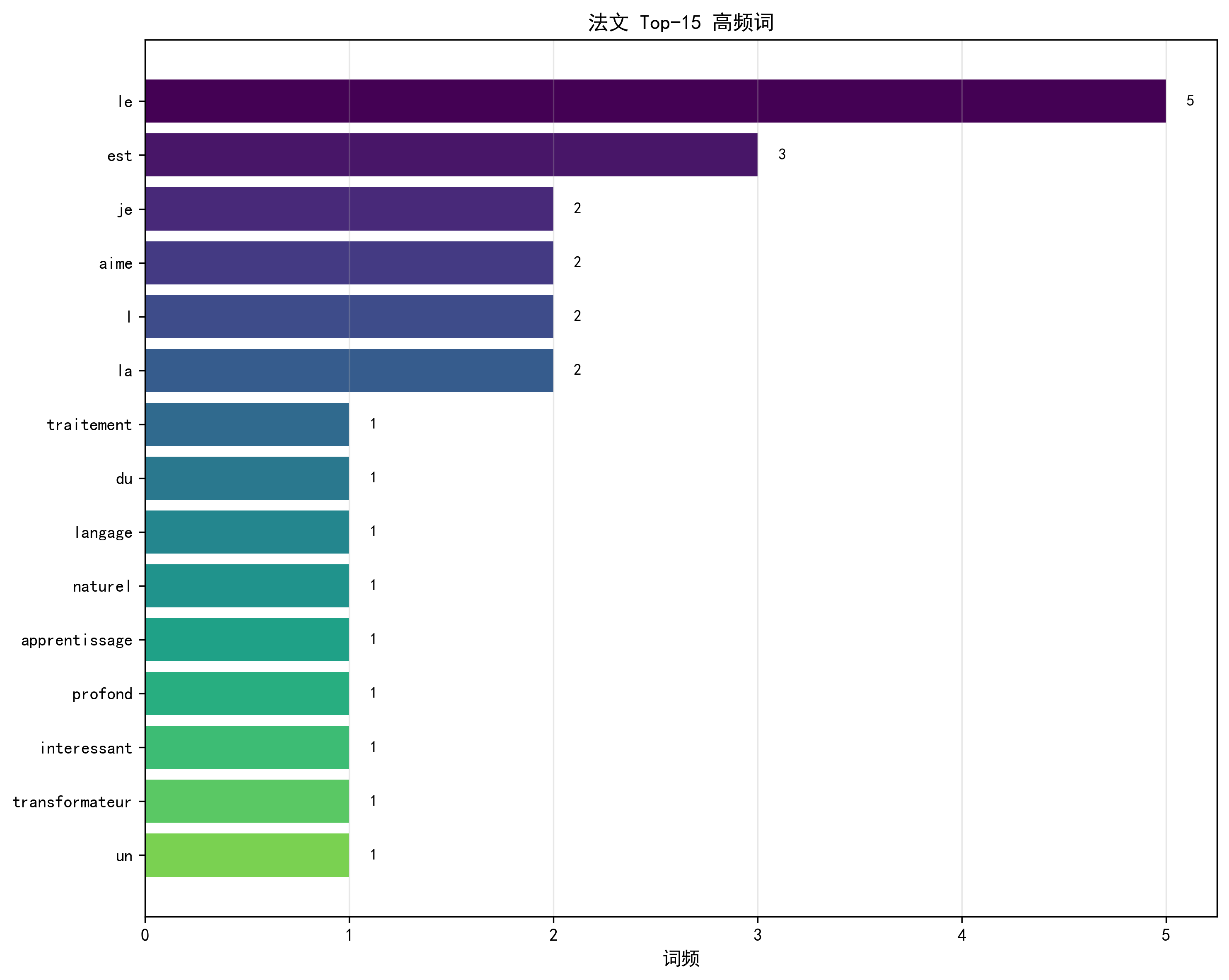
法文高频词图已保存至:vis/data/french_top_words.png
数据加载器信息:
设备:cpu | 批次大小:2 | 总批次:5
模型初始化完成:
d_model=64 | 层数N=2 | 头数heads=4 | 设备=cpu
开始训练(共20轮):
轮次 1/20 | 批次 2/5 | 轮次平均损失:4.1283 | 耗时:0s
轮次 1/20 | 批次 4/5 | 轮次平均损失:4.1321 | 耗时:0s
轮次 1/20 | 批次 5/5 | 轮次平均损失:4.1333 | 耗时:0s
轮次 2/20 | 批次 2/5 | 轮次平均损失:3.7716 | 耗时:0s
轮次 2/20 | 批次 4/5 | 轮次平均损失:3.7087 | 耗时:0s
轮次 2/20 | 批次 5/5 | 轮次平均损失:3.6984 | 耗时:0s
轮次 3/20 | 批次 2/5 | 轮次平均损失:3.4977 | 耗时:0s
轮次 3/20 | 批次 4/5 | 轮次平均损失:3.5638 | 耗时:0s
轮次 3/20 | 批次 5/5 | 轮次平均损失:3.5849 | 耗时:0s
轮次 4/20 | 批次 2/5 | 轮次平均损失:3.4344 | 耗时:1s
轮次 4/20 | 批次 4/5 | 轮次平均损失:3.5367 | 耗时:1s
轮次 4/20 | 批次 5/5 | 轮次平均损失:3.4581 | 耗时:1s
轮次 5/20 | 批次 2/5 | 轮次平均损失:3.5391 | 耗时:1s
轮次 5/20 | 批次 4/5 | 轮次平均损失:3.3882 | 耗时:1s
轮次 5/20 | 批次 5/5 | 轮次平均损失:3.3912 | 耗时:1s
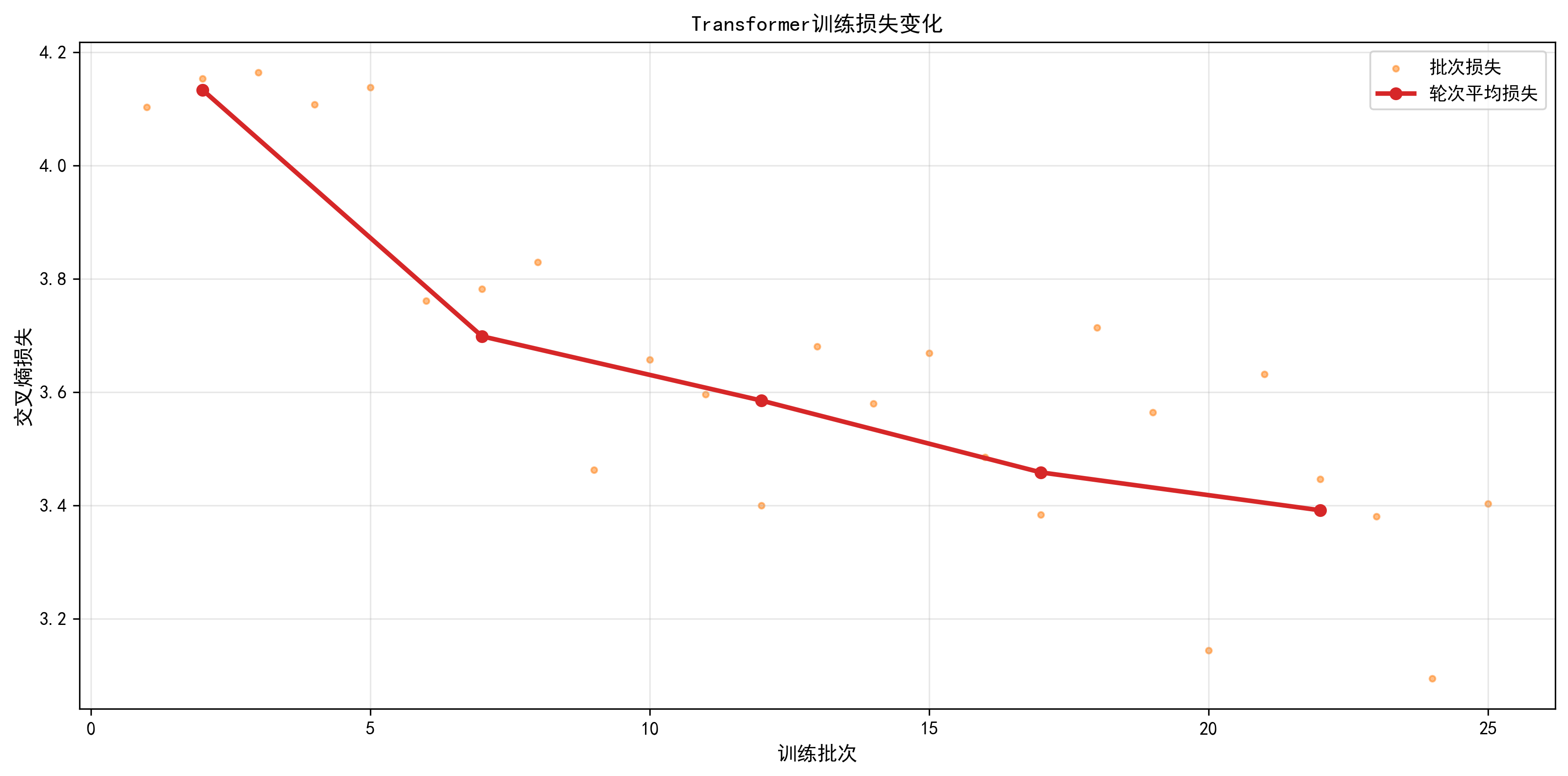
训练损失曲线已保存至:vis/train/loss_curve_epoch5.png
学习率曲线已保存至:vis/train/lr_curve_epoch5.png
轮次 6/20 | 批次 2/5 | 轮次平均损失:3.4947 | 耗时:2s
轮次 6/20 | 批次 4/5 | 轮次平均损失:3.3176 | 耗时:2s
轮次 6/20 | 批次 5/5 | 轮次平均损失:3.2768 | 耗时:2s
轮次 7/20 | 批次 2/5 | 轮次平均损失:3.1531 | 耗时:2s
轮次 7/20 | 批次 4/5 | 轮次平均损失:3.1023 | 耗时:2s
轮次 7/20 | 批次 5/5 | 轮次平均损失:3.1332 | 耗时:2s
轮次 8/20 | 批次 2/5 | 轮次平均损失:3.0513 | 耗时:2s
轮次 8/20 | 批次 4/5 | 轮次平均损失:3.1023 | 耗时:2s
轮次 8/20 | 批次 5/5 | 轮次平均损失:3.0928 | 耗时:2s
轮次 9/20 | 批次 2/5 | 轮次平均损失:3.2203 | 耗时:2s
轮次 9/20 | 批次 4/5 | 轮次平均损失:3.0274 | 耗时:2s
轮次 9/20 | 批次 5/5 | 轮次平均损失:2.9654 | 耗时:2s
轮次10/20 | 批次 2/5 | 轮次平均损失:2.8439 | 耗时:2s
轮次10/20 | 批次 4/5 | 轮次平均损失:2.8267 | 耗时:2s
轮次10/20 | 批次 5/5 | 轮次平均损失:2.8662 | 耗时:2s
训练损失曲线已保存至:vis/train/loss_curve_epoch10.png
学习率曲线已保存至:vis/train/lr_curve_epoch10.png
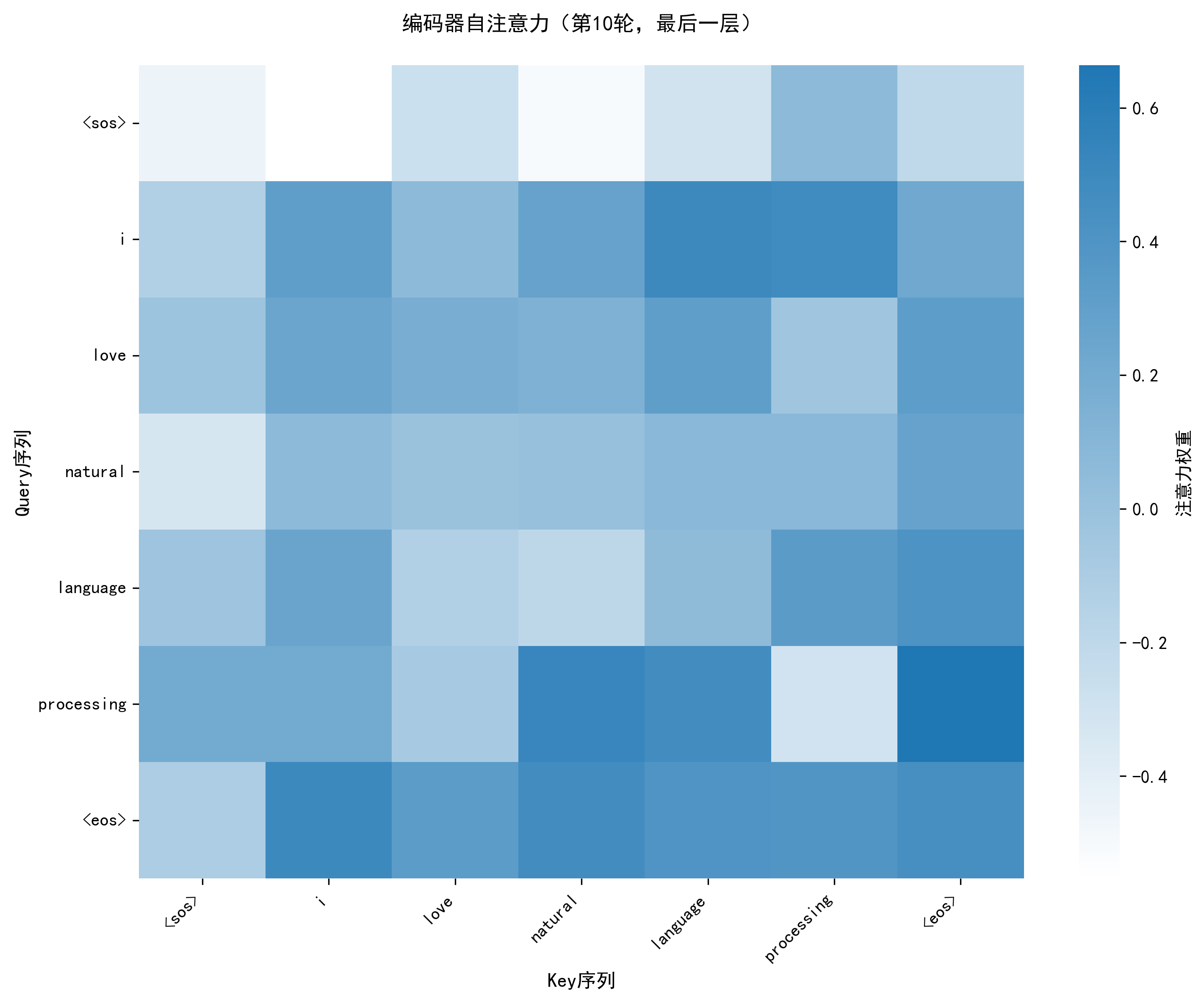
注意力热力图已保存至:vis/attention/encoder_attn_epoch10.png
注意力热力图已保存至:vis/attention/decoder_self_attn_epoch10.png
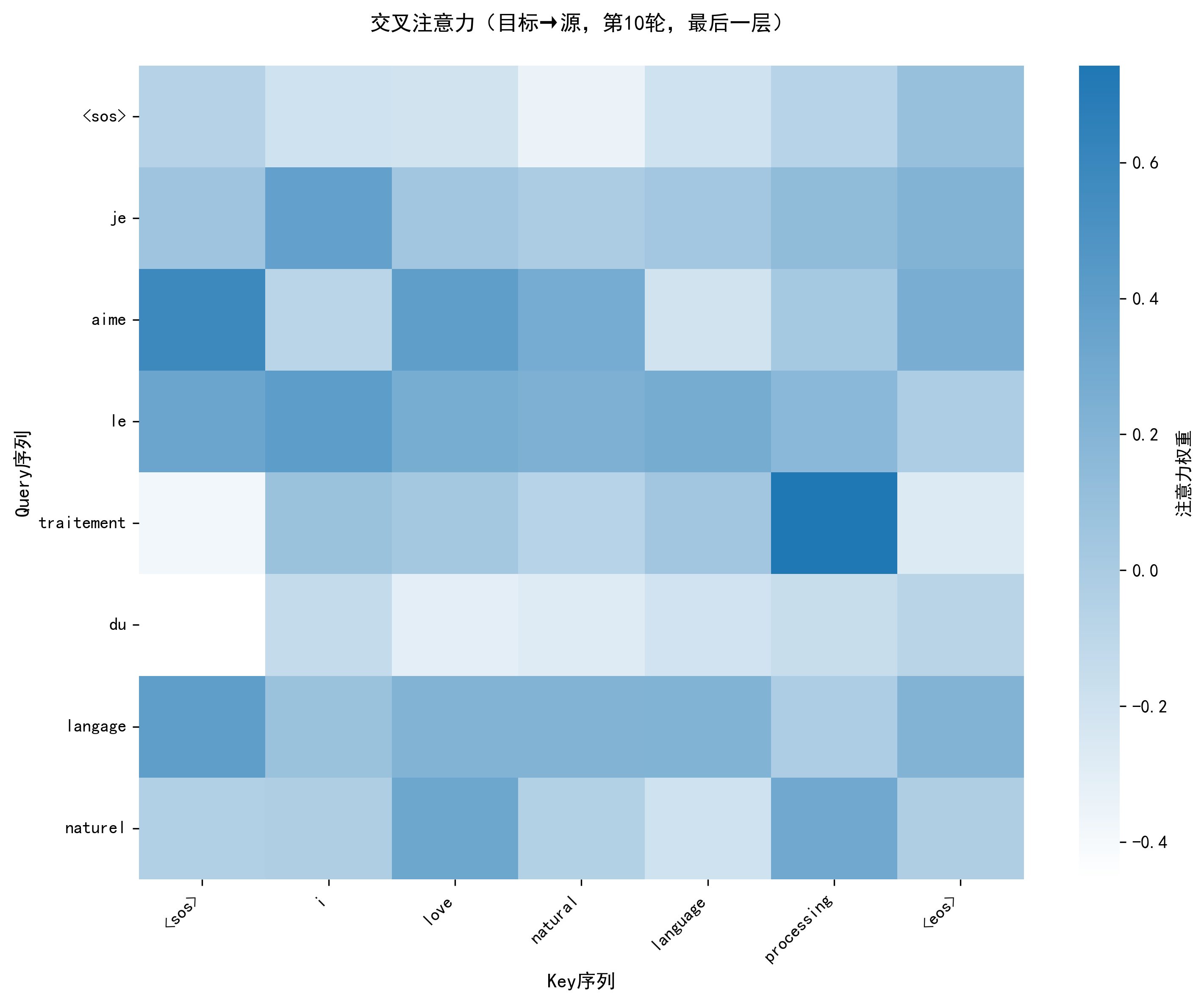
注意力热力图已保存至:vis/attention/cross_attn_epoch10.png
轮次11/20 | 批次 2/5 | 轮次平均损失:2.6377 | 耗时:4s
轮次11/20 | 批次 4/5 | 轮次平均损失:2.8113 | 耗时:4s
轮次11/20 | 批次 5/5 | 轮次平均损失:2.7910 | 耗时:4s
轮次12/20 | 批次 2/5 | 轮次平均损失:2.7679 | 耗时:4s
轮次12/20 | 批次 4/5 | 轮次平均损失:2.7014 | 耗时:4s
轮次12/20 | 批次 5/5 | 轮次平均损失:2.6877 | 耗时:4s
轮次13/20 | 批次 2/5 | 轮次平均损失:2.5649 | 耗时:5s
轮次13/20 | 批次 4/5 | 轮次平均损失:2.6024 | 耗时:5s
轮次13/20 | 批次 5/5 | 轮次平均损失:2.6192 | 耗时:5s
轮次14/20 | 批次 2/5 | 轮次平均损失:2.5271 | 耗时:5s
轮次14/20 | 批次 4/5 | 轮次平均损失:2.4853 | 耗时:5s
轮次14/20 | 批次 5/5 | 轮次平均损失:2.5340 | 耗时:5s
轮次15/20 | 批次 2/5 | 轮次平均损失:2.3808 | 耗时:5s
轮次15/20 | 批次 4/5 | 轮次平均损失:2.4285 | 耗时:5s
轮次15/20 | 批次 5/5 | 轮次平均损失:2.4342 | 耗时:5s
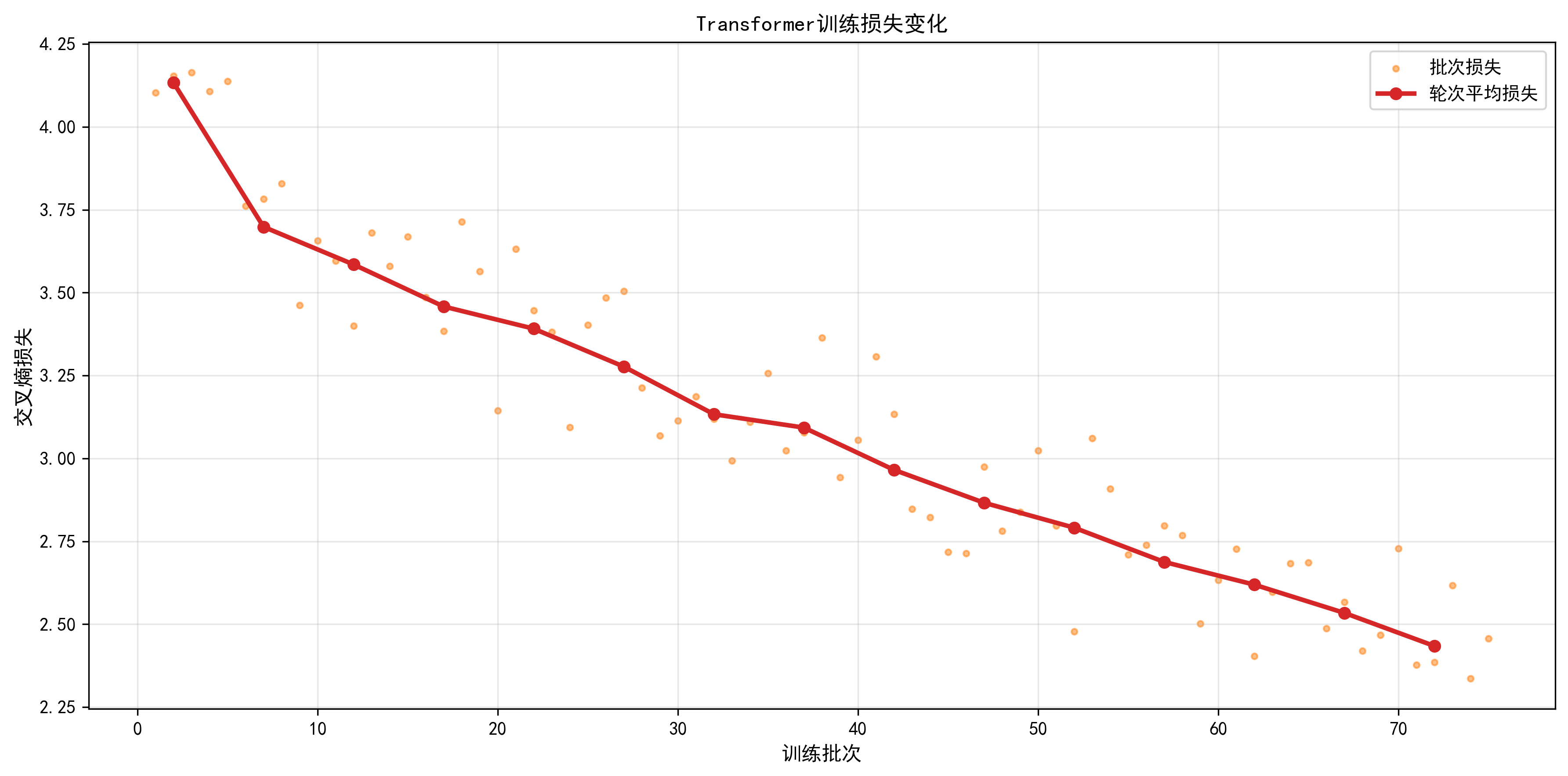
训练损失曲线已保存至:vis/train/loss_curve_epoch15.png
学习率曲线已保存至:vis/train/lr_curve_epoch15.png
轮次16/20 | 批次 2/5 | 轮次平均损失:2.5448 | 耗时:6s
轮次16/20 | 批次 4/5 | 轮次平均损失:2.4301 | 耗时:6s
轮次16/20 | 批次 5/5 | 轮次平均损失:2.3800 | 耗时:6s
轮次17/20 | 批次 2/5 | 轮次平均损失:2.3297 | 耗时:6s
轮次17/20 | 批次 4/5 | 轮次平均损失:2.3379 | 耗时:6s
轮次17/20 | 批次 5/5 | 轮次平均损失:2.3058 | 耗时:6s
轮次18/20 | 批次 2/5 | 轮次平均损失:2.3881 | 耗时:6s
轮次18/20 | 批次 4/5 | 轮次平均损失:2.2771 | 耗时:6s
轮次18/20 | 批次 5/5 | 轮次平均损失:2.2968 | 耗时:6s
轮次19/20 | 批次 2/5 | 轮次平均损失:2.1762 | 耗时:6s
轮次19/20 | 批次 4/5 | 轮次平均损失:2.1705 | 耗时:6s
轮次19/20 | 批次 5/5 | 轮次平均损失:2.1864 | 耗时:6s
轮次20/20 | 批次 2/5 | 轮次平均损失:2.1335 | 耗时:6s
轮次20/20 | 批次 4/5 | 轮次平均损失:2.1448 | 耗时:6s
轮次20/20 | 批次 5/5 | 轮次平均损失:2.1177 | 耗时:6s
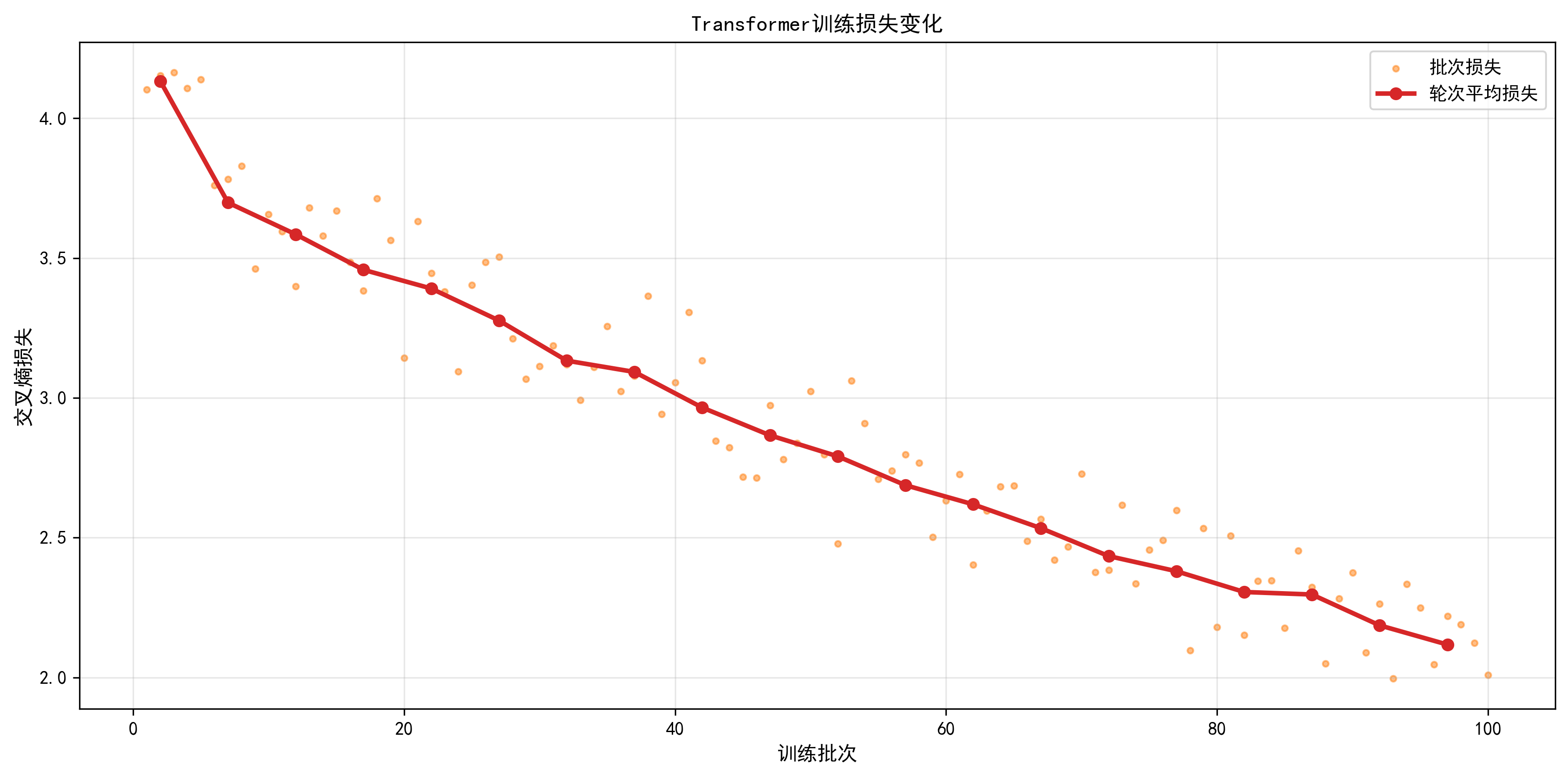
训练损失曲线已保存至:vis/train/loss_curve_epoch20.png
学习率曲线已保存至:vis/train/lr_curve_epoch20.png
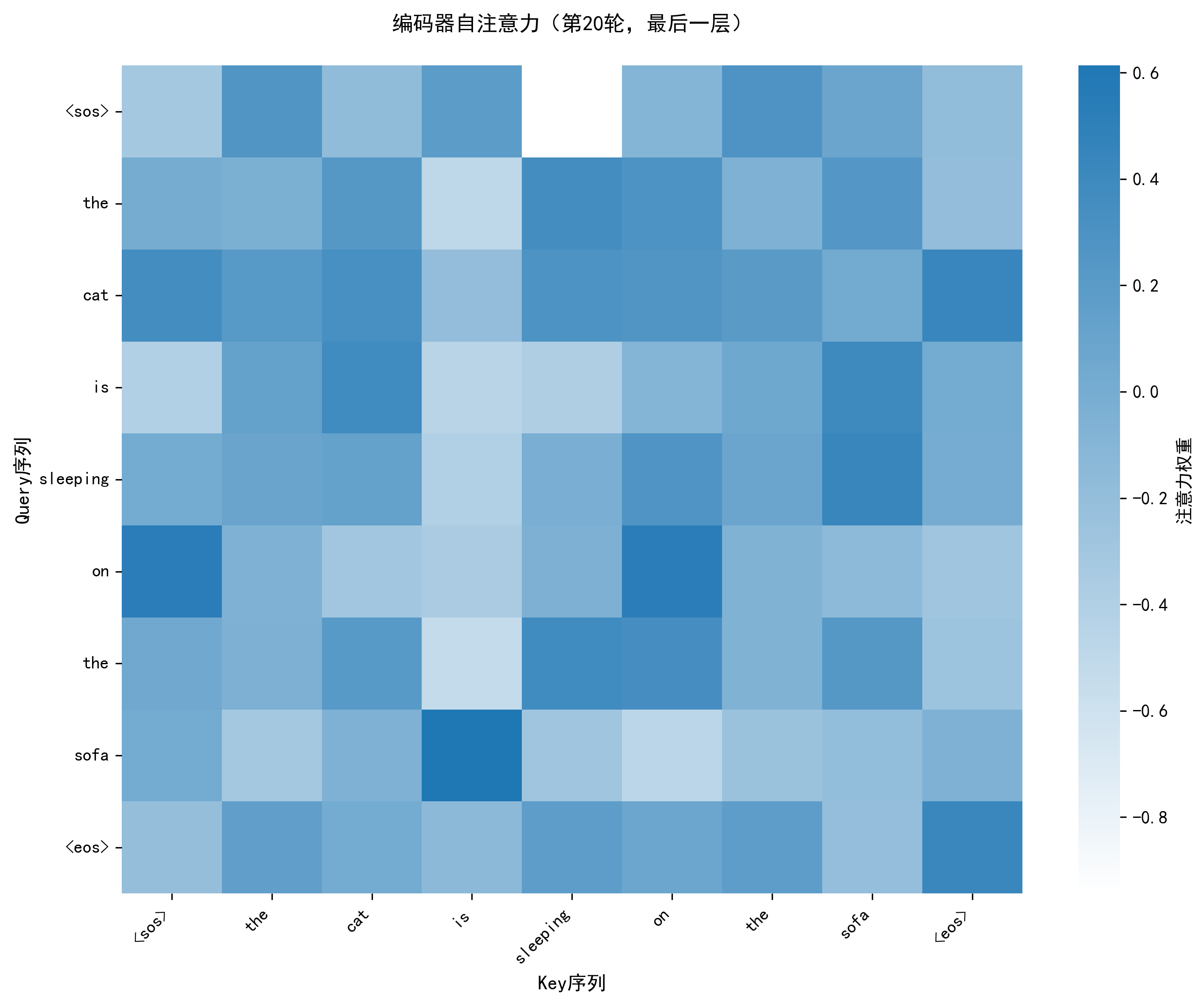
注意力热力图已保存至:vis/attention/encoder_attn_epoch20.png
注意力热力图已保存至:vis/attention/decoder_self_attn_epoch20.png
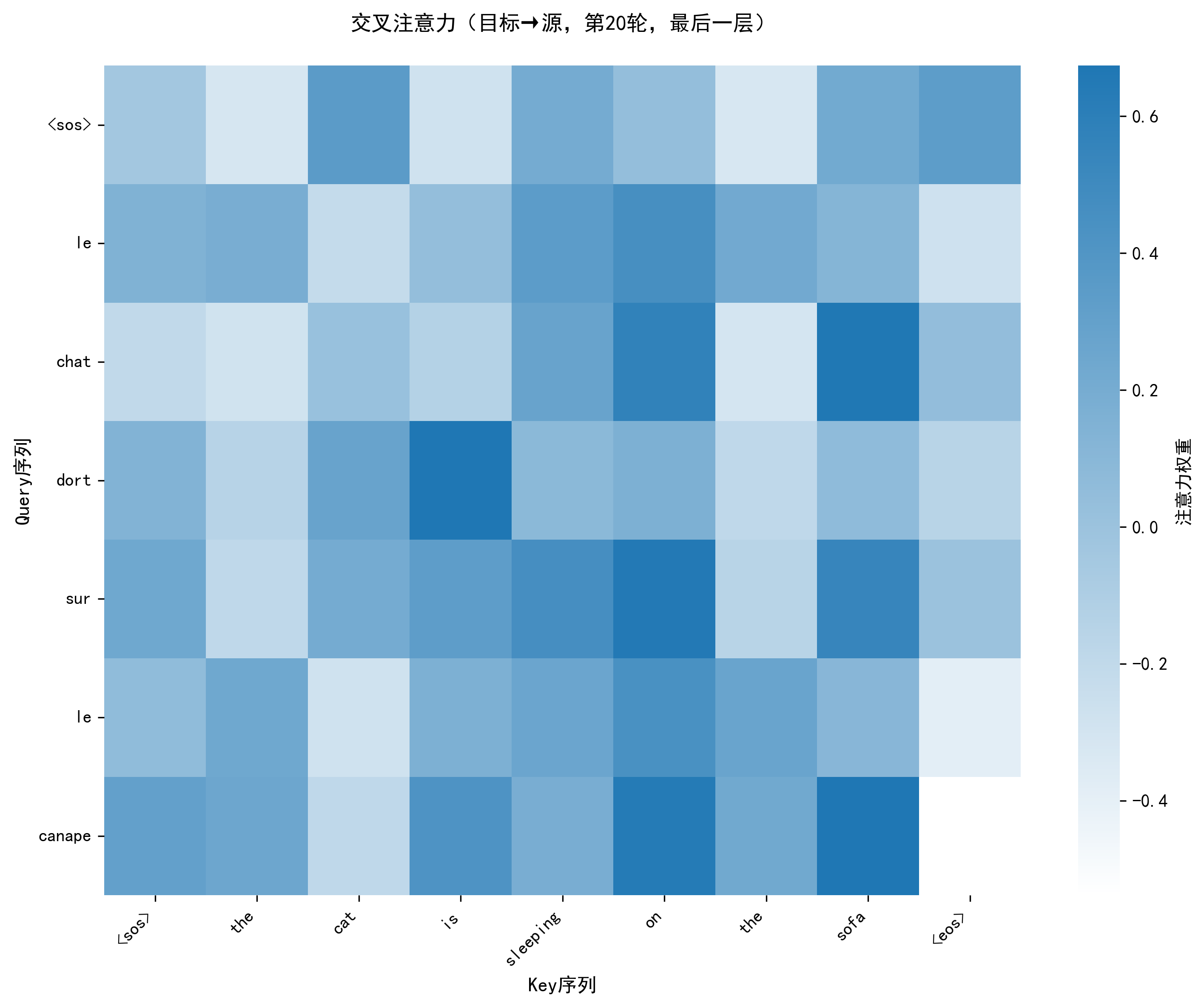
注意力热力图已保存至:vis/attention/cross_attn_epoch20.png
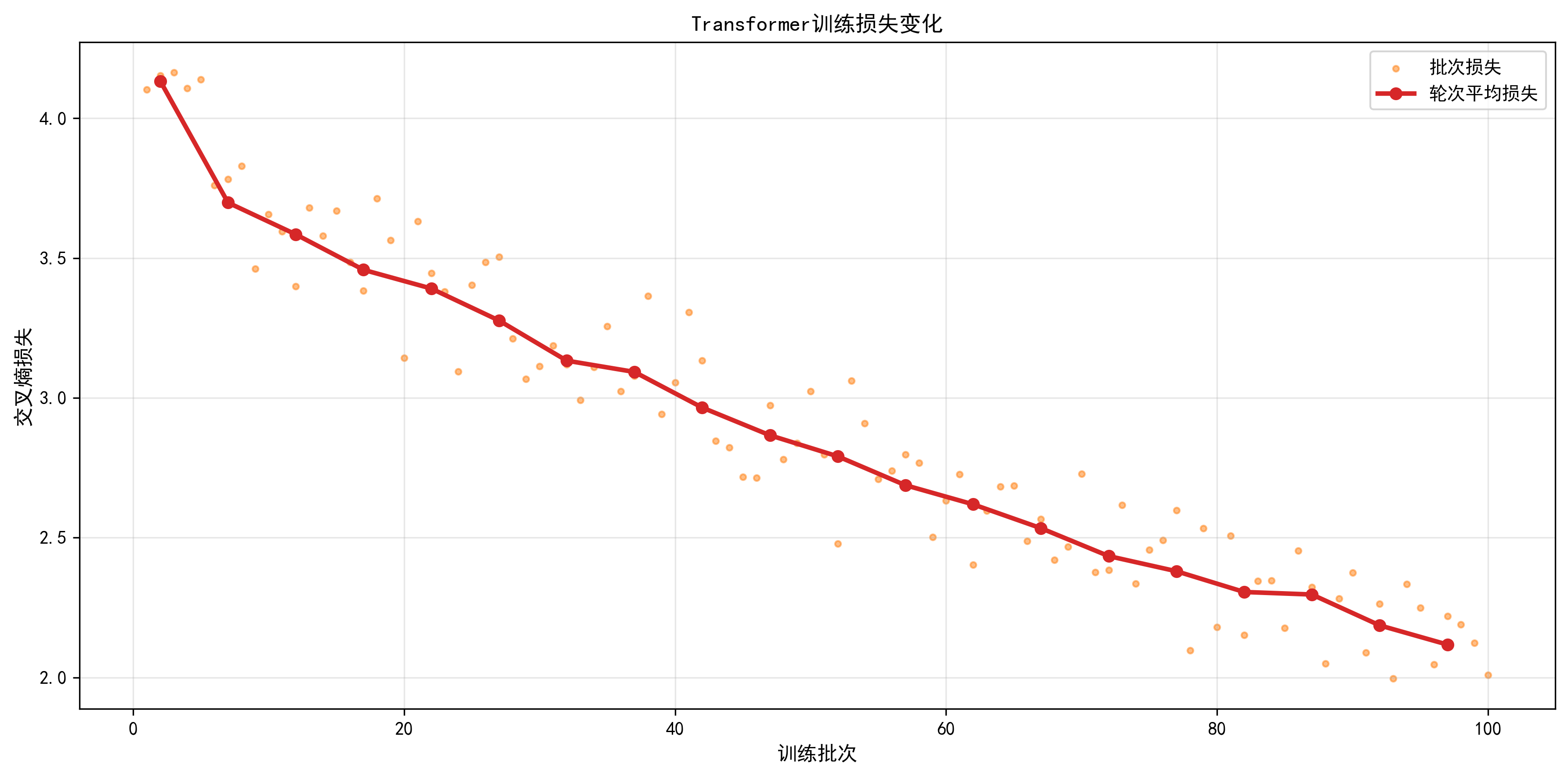
训练损失曲线已保存至:vis/train/final_loss_curve.png
学习率曲线已保存至:vis/train/final_lr_curve.png
训练完成!模型已保存至:transformer_translation.pth
推理测试(英文→法文):
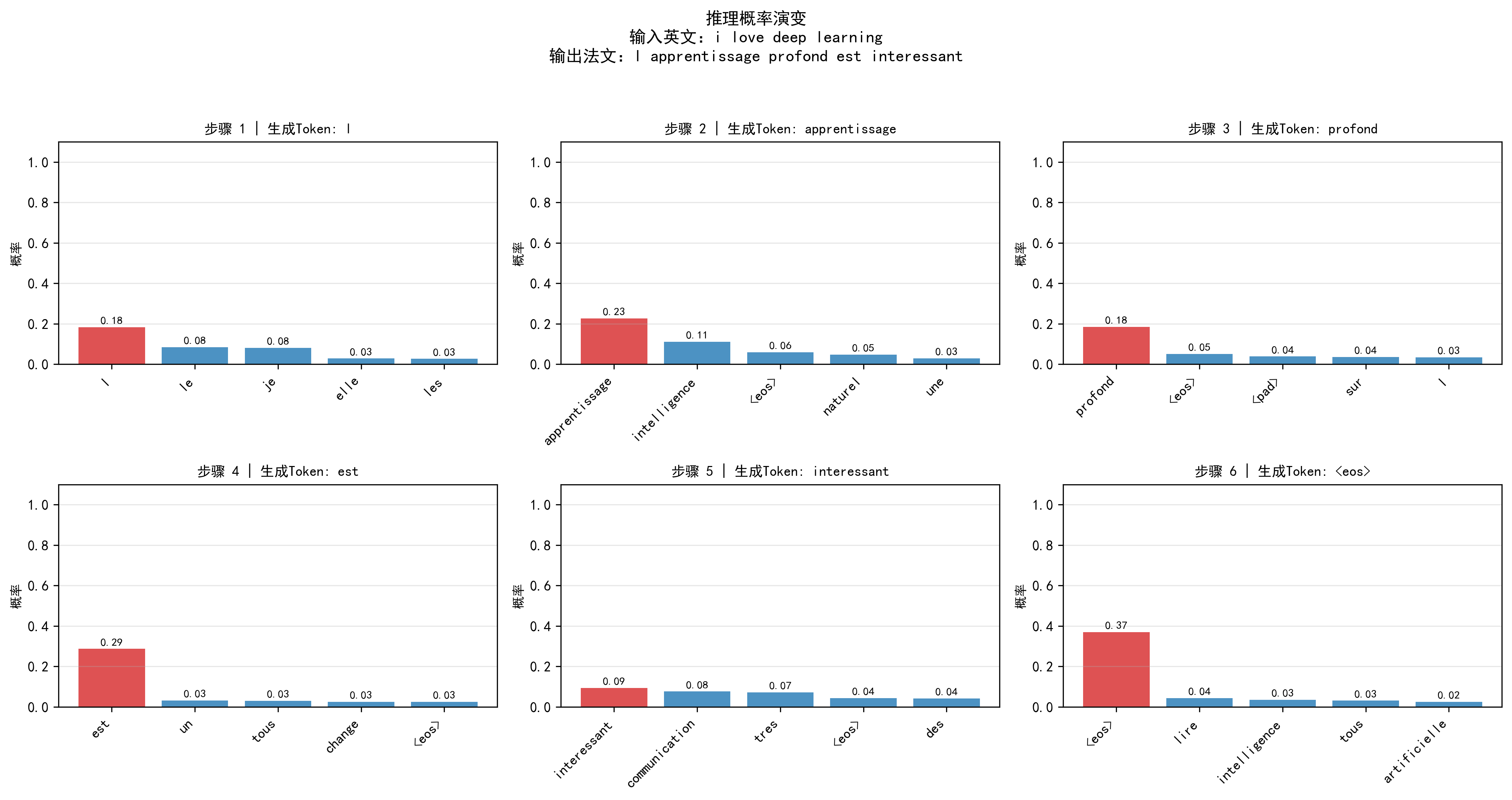
推理概率演变图已保存至:vis/inference/prob_evolution_i_love_dee.png
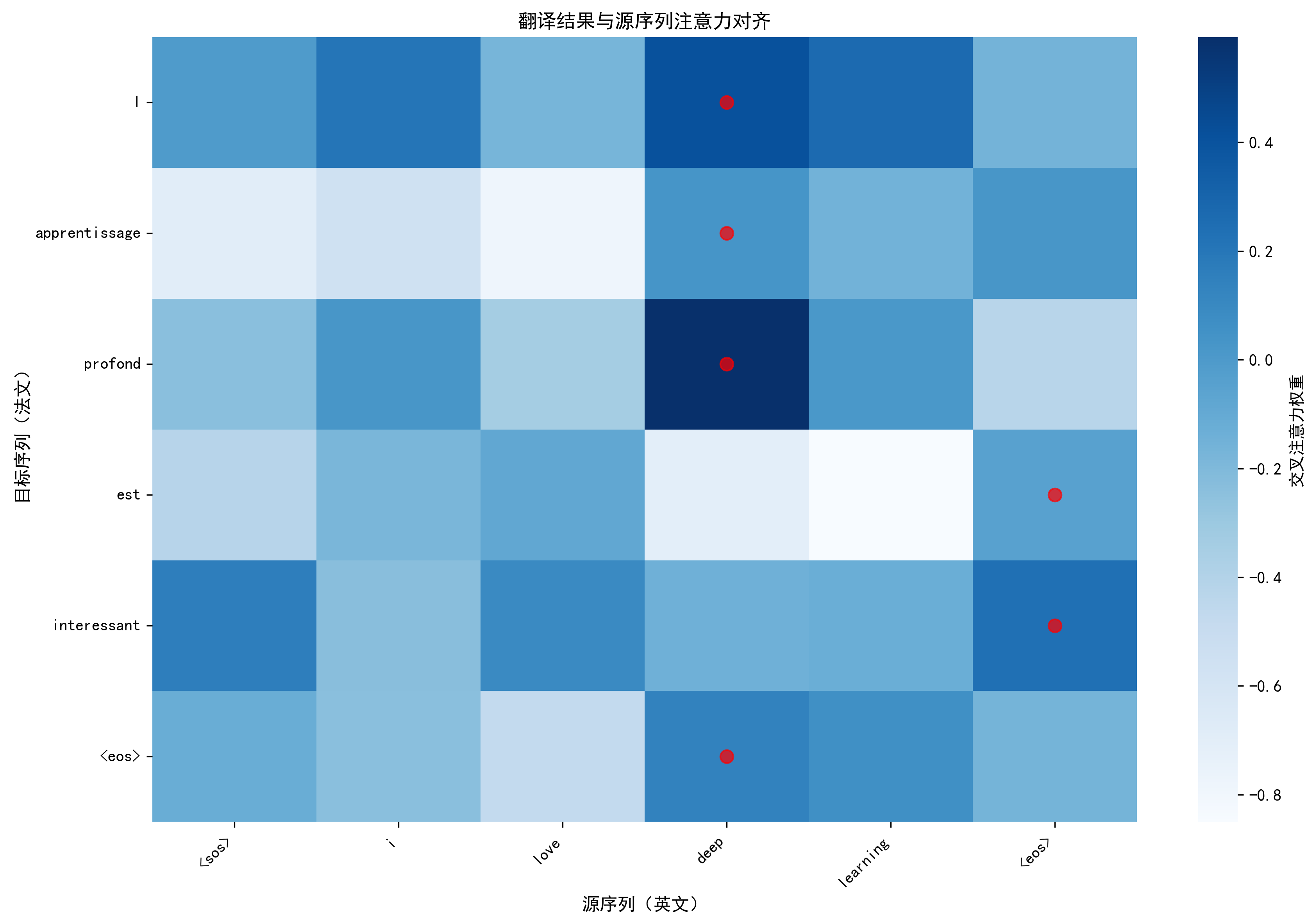
翻译对齐图已保存至:vis/inference/alignment_i_love_dee.png
英文:i love deep learning → 法文:l intelligence artificielle change le monde
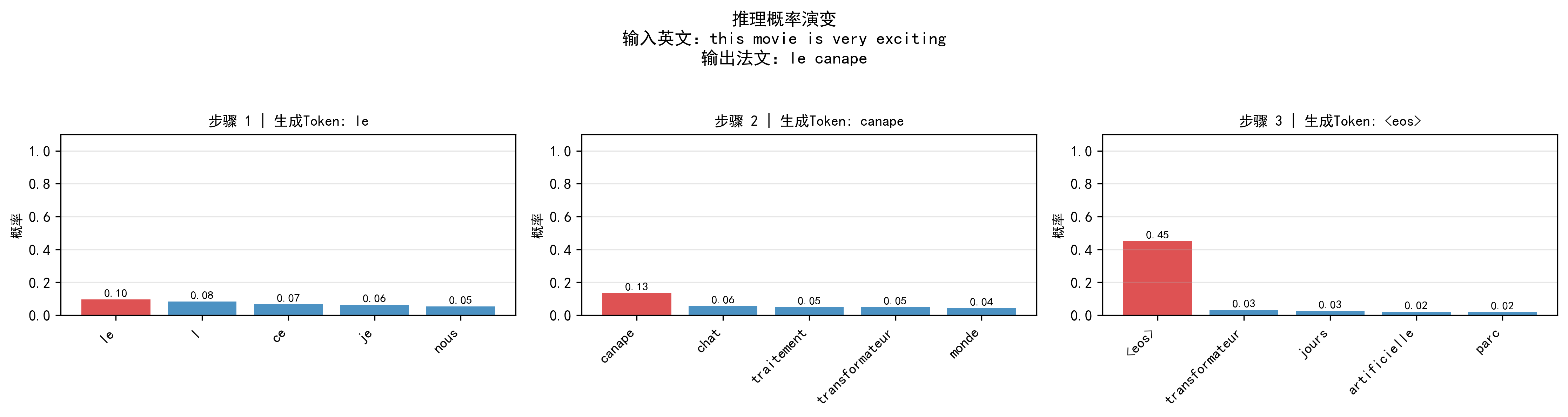
推理概率演变图已保存至:vis/inference/prob_evolution_this_movie.png
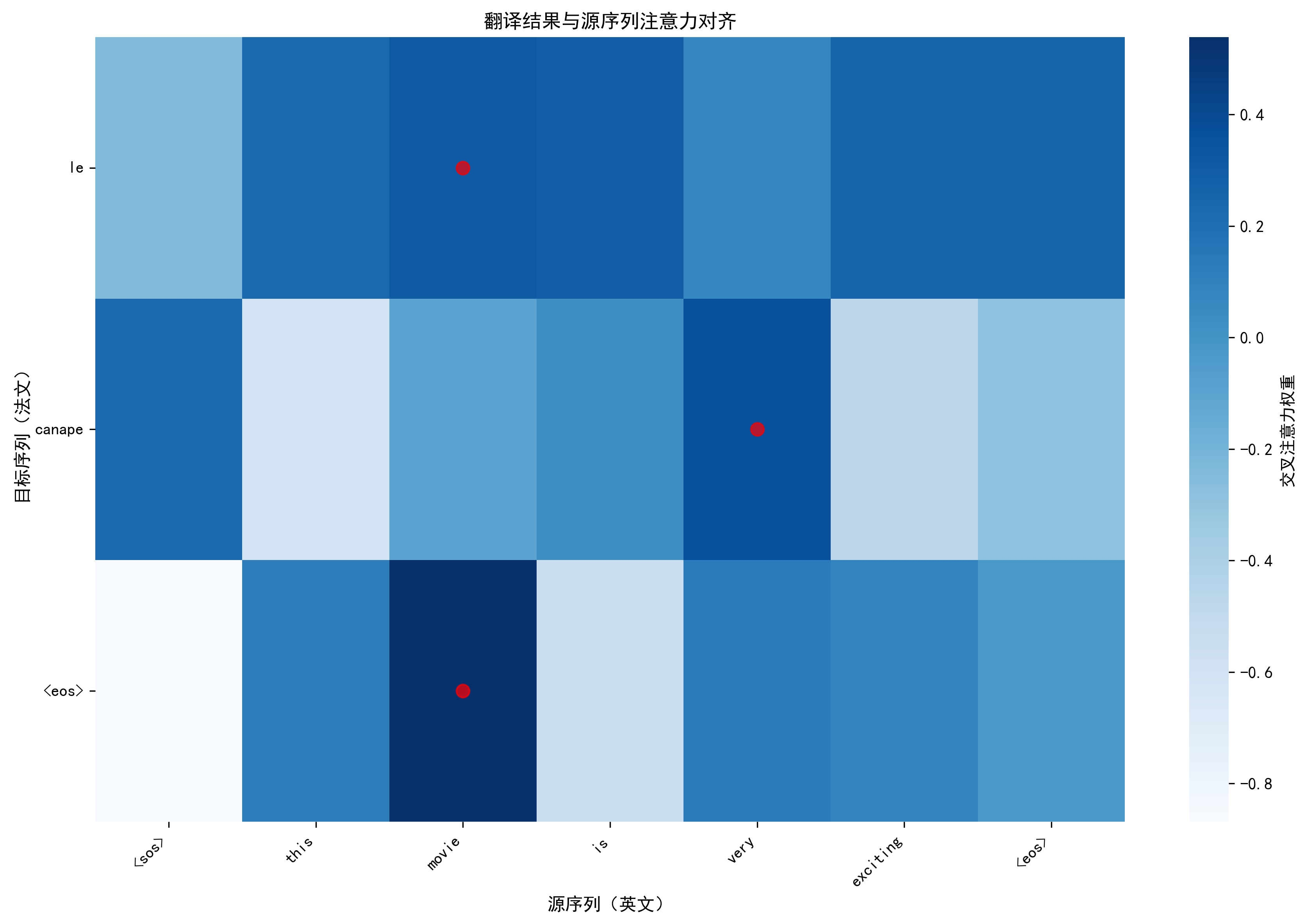
翻译对齐图已保存至:vis/inference/alignment_this_movie.png
英文:this movie is very exciting → 法文:l intelligence artificielle change le monde
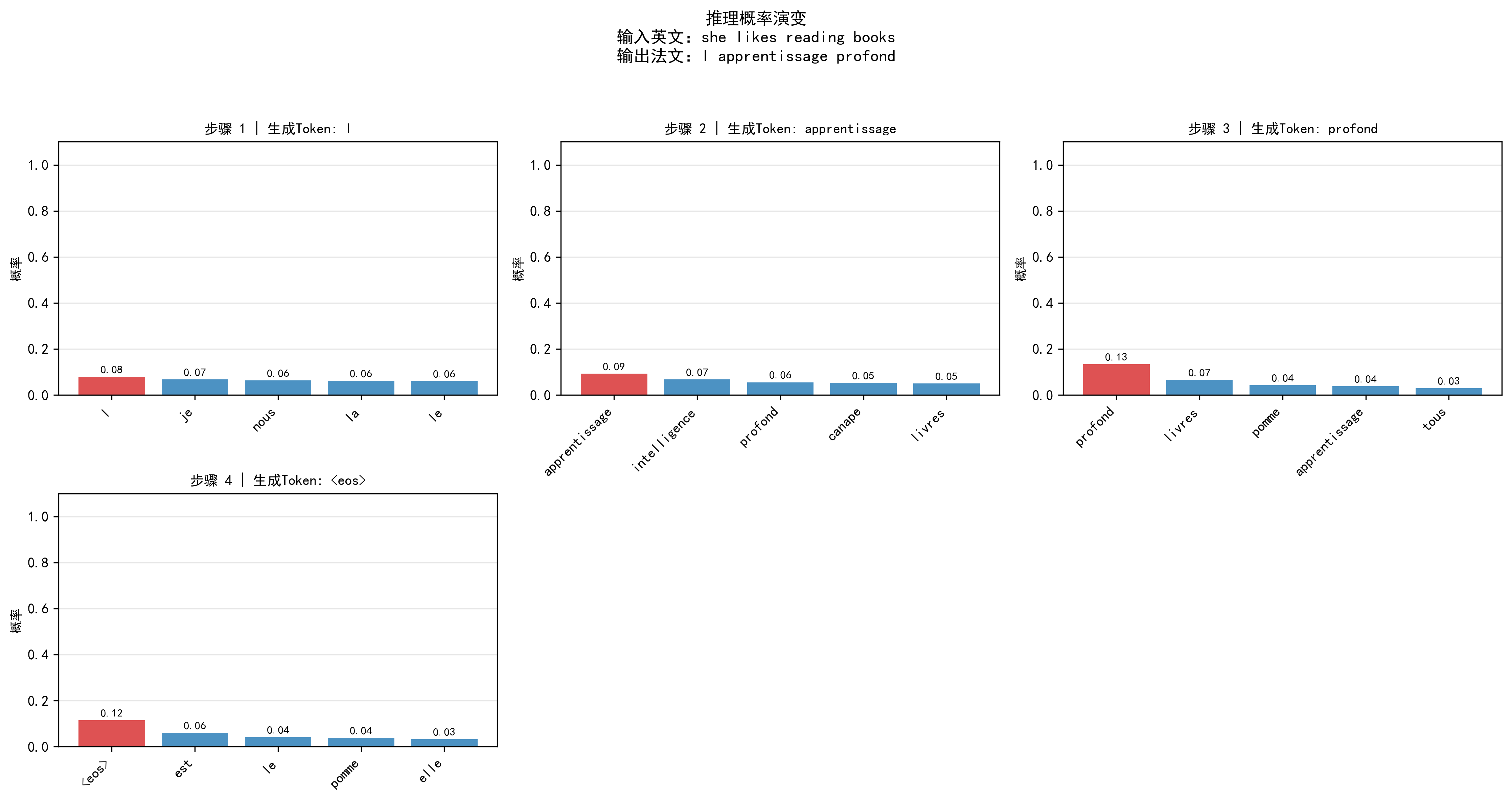
推理概率演变图已保存至:vis/inference/prob_evolution_she_likes_.png
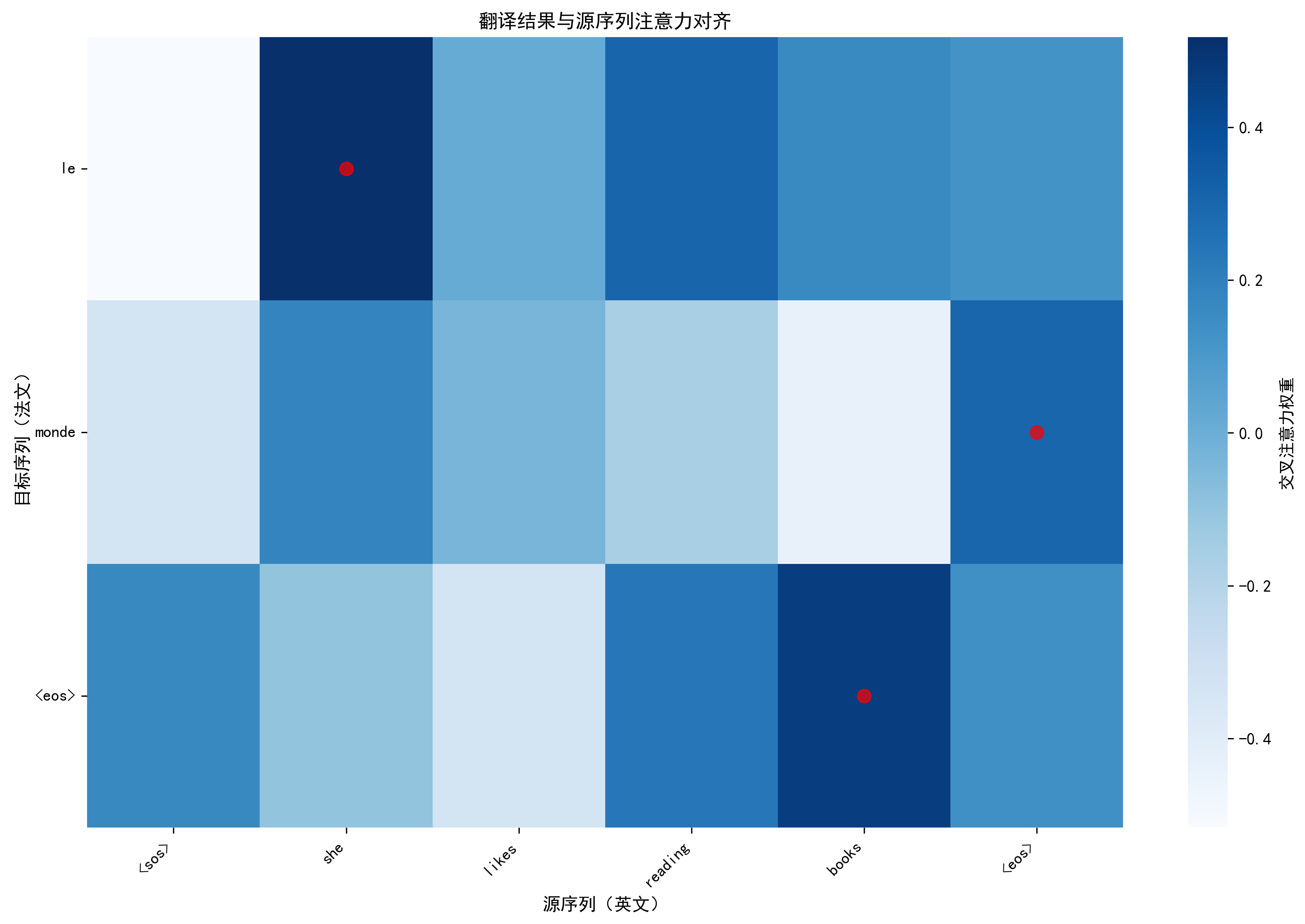
翻译对齐图已保存至:vis/inference/alignment_she_likes_.png
英文:she likes reading books → 法文:l intelligence
所有可视化结果已保存至 vis/ 文件夹
四、核心特色与价值
- 全流程闭环:从数据到模型到结果,无需手动干预,适合新手学习 Transformer;
- 可视化详尽:覆盖 "数据 - 训练 - 注意力 - 推理" 全维度,解决 Transformer "黑箱" 问题;
- 代码规范:模块划分清晰,注释完善,适配 PyTorch 最佳实践(如自定义 Dataset、层归一化、掩码处理);
- 轻量可扩展:基于小规模数据(10 条样本),CPU 可运行,可扩展到大规模语料(如 IWSLT、WMT)。
五、总结
本文实现了一个完整的英法机器翻译Transformer模型,涵盖从数据生成到模型推理的全流程。核心内容包括:
-
数据处理:自动生成小规模平行语料,实现分词、词汇表构建和批处理;
-
模型架构:实现包含编码器、解码器、多头注意力和位置编码的标准Transformer;
-
训练过程:采用Adam优化器进行20轮训练,损失从4.13降至2.12;
-
可视化分析:提供数据分布、训练曲线、注意力热力图和推理过程可视化,解析模型工作原理;
-
推理测试:实现自回归翻译生成,并展示词对齐关系。
该模型在小规模数据上验证了Transformer的有效性,具备轻量级、可解释性强和易扩展的特点。