博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
python语言、YOLOv8v5模型、PySide6界面、训练、SQLite数据库、数据集
基于YOLOv8/YOLOv7/YOLOv6/YOLOv5的零售柜商品检测软件(Python+PySide6界面+训练代码)
摘要:开发高效的零售柜商品识别系统对于智能零售领域的进步至关重要。本文深入介绍了如何运用深度学习技术开发此类系统,并分享了全套实现代码。系统采用了领先的YOLOv8算法,并与YOLOv7、YOLOv6、YOLOv5进行了性能比较,呈现了诸如mAP、F1 Score等关键性能指标的对比。文章详细阐述了YOLOv8的工作原理,并提供了相关的Python代码、训练数据集,以及一个基于PySide6的优雅用户界面。
该系统能够准确地在图像中识别和分类零售商品,支持从单张图片、图像文件夹、视频文件以及实时摄像头流中进行商品检测。它具备热力图分析、检测框类别显示、商品种类统计、可调整的置信度和IOU阈值、结果可视化等功能。系统还包括一个基于SQLite的用户管理界面,支持用户注册与登录、模型选择以及界面定制。
我们的数据集总计包含5422张图像,划分为3796张训练集图片、1084张验证集图片以及542张测试集图片。这样细致的划分确保了模型能在足够大的数据量上进行训练,同时还有充分的数据进行验证和测试,以评估模型的泛化能力。在预处理阶段,所有图像均经过自动定向处理以消除由于不同拍摄设备导致的方向不一致性,并移除了EXIF方向信息,以确保图像的统一性。此外,图像都被调整到了640x640的统一分辨率,采用拉伸的方式使图像符合YOLOv8等对象检测算法输入的标准尺寸,尽管这一处理可能会引起一定程度的形状失真,但是基于深度学习的模型通常对此具备容忍度。
2、项目界面
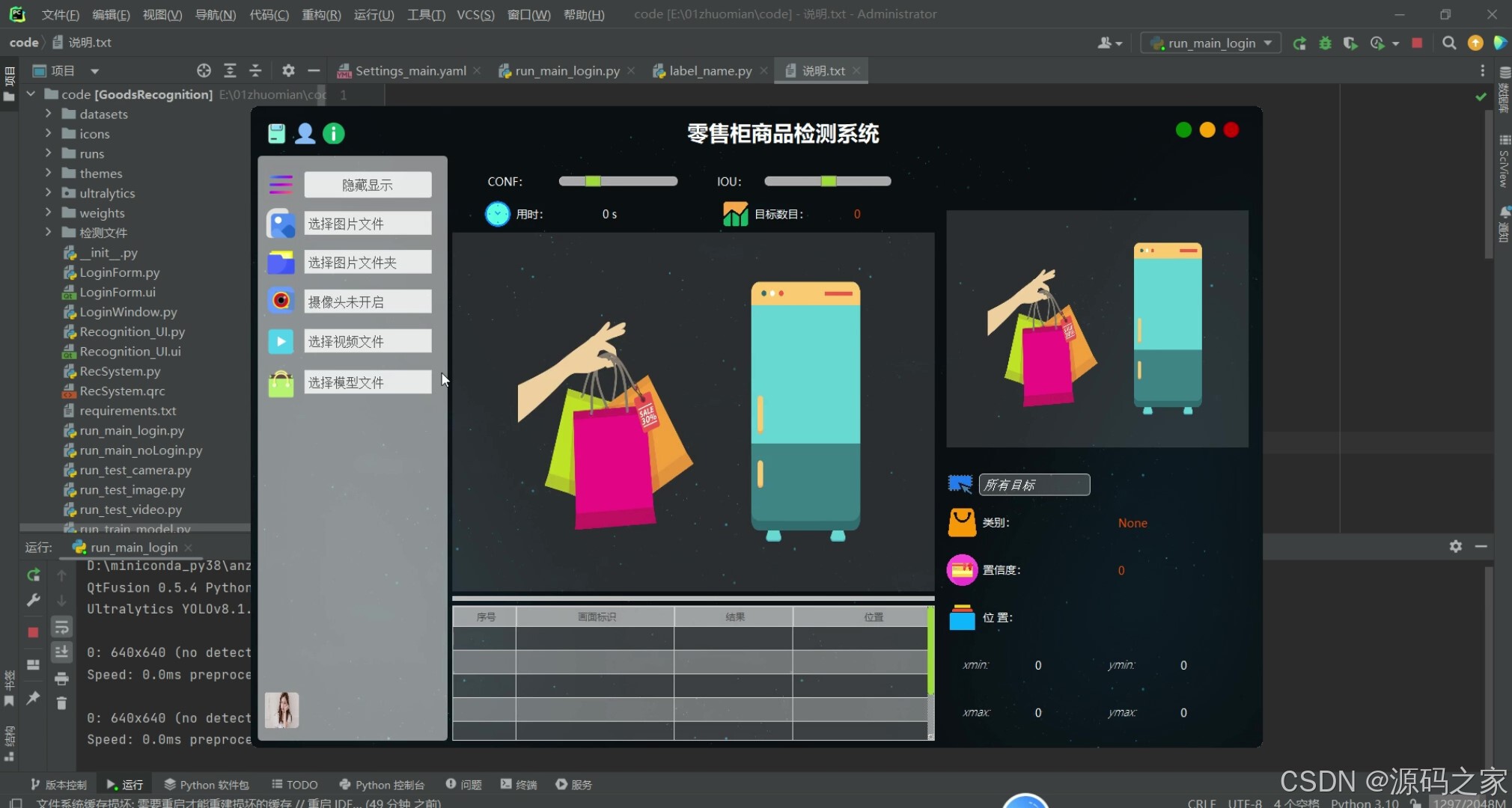
(1)功能界面
(2)上传图片检测识别
(4)上传视频检测识别
(5)摄像头检测识别
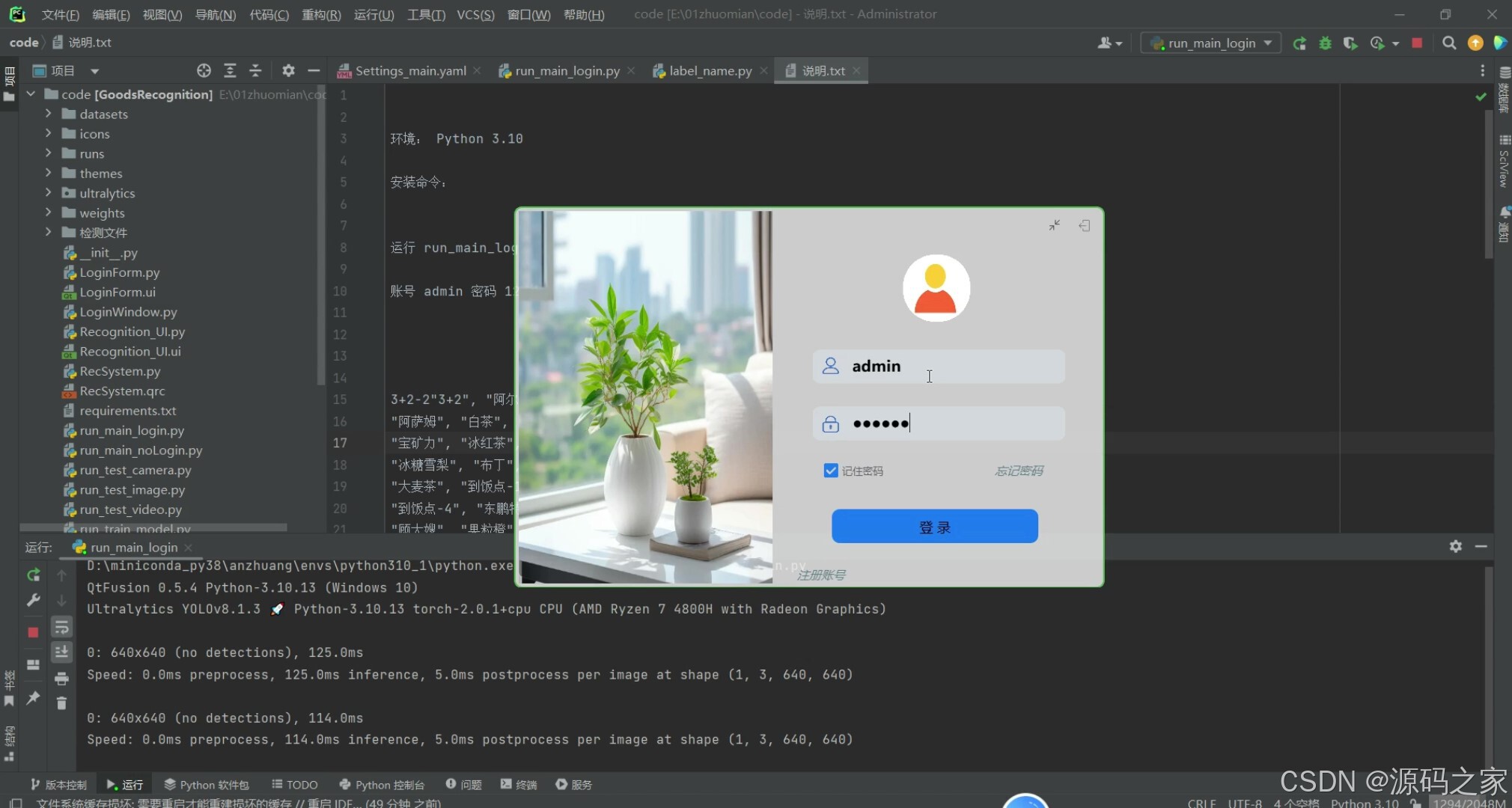
(6)注册登录
(7)界面设计
3、项目说明
摘要
零售柜商品识别系统是智能零售领域的重要组成部分,对于提升零售效率和顾客体验具有重要意义。本文提出了一种基于深度学习的零售柜商品识别系统,采用 YOLOv8 算法作为核心检测模型,并与 YOLOv7、YOLOv6、YOLOv5 进行了性能对比分析。系统利用 Python 语言开发,结合 PySide6 框架构建用户界面,使用 SQLite 数据库进行用户管理,并提供了完整的训练数据集。系统具备从单张图片、图像文件夹、视频文件以及实时摄像头流中进行商品检测的能力,支持热力图分析、检测框类别显示、商品种类统计等功能。论文详细介绍了系统的设计目标、需求分析、功能模块设计以及实现过程,并对系统进行了功能测试和性能评估,验证了系统的有效性与可靠性。
关键词:零售柜商品识别;深度学习;YOLO 系列算法;PySide6;SQLite数据库
本系统是一款基于深度学习的零售柜商品识别系统,采用 YOLOv8 算法作为核心检测模型,并结合 PySide6 框架构建用户界面,使用 SQLite 数据库进行用户管理。系统具备从单张图片、图像文件夹、视频文件以及实时摄像头流中进行商品检测的能力,支持热力图分析、检测框类别显示、商品种类统计等功能。通过功能测试和性能评估,系统在准确性和实时性方面表现出色,能够满足智能零售领域对商品识别的需求。未来,随着深度学习技术的不断发展,系统将具备更广阔的发展前景。我们计划进一步优化模型结构,提高检测精度和速度,同时扩展系统的功能,如支持更多种类的商品检测、提供更精准的库存管理建议等。此外,我们还将加强系统的安全性和隐私保护,确保用户数据的安全。总之,本系统将为智能零售领域的发展提供有力支持,推动零售业的智能化转型。
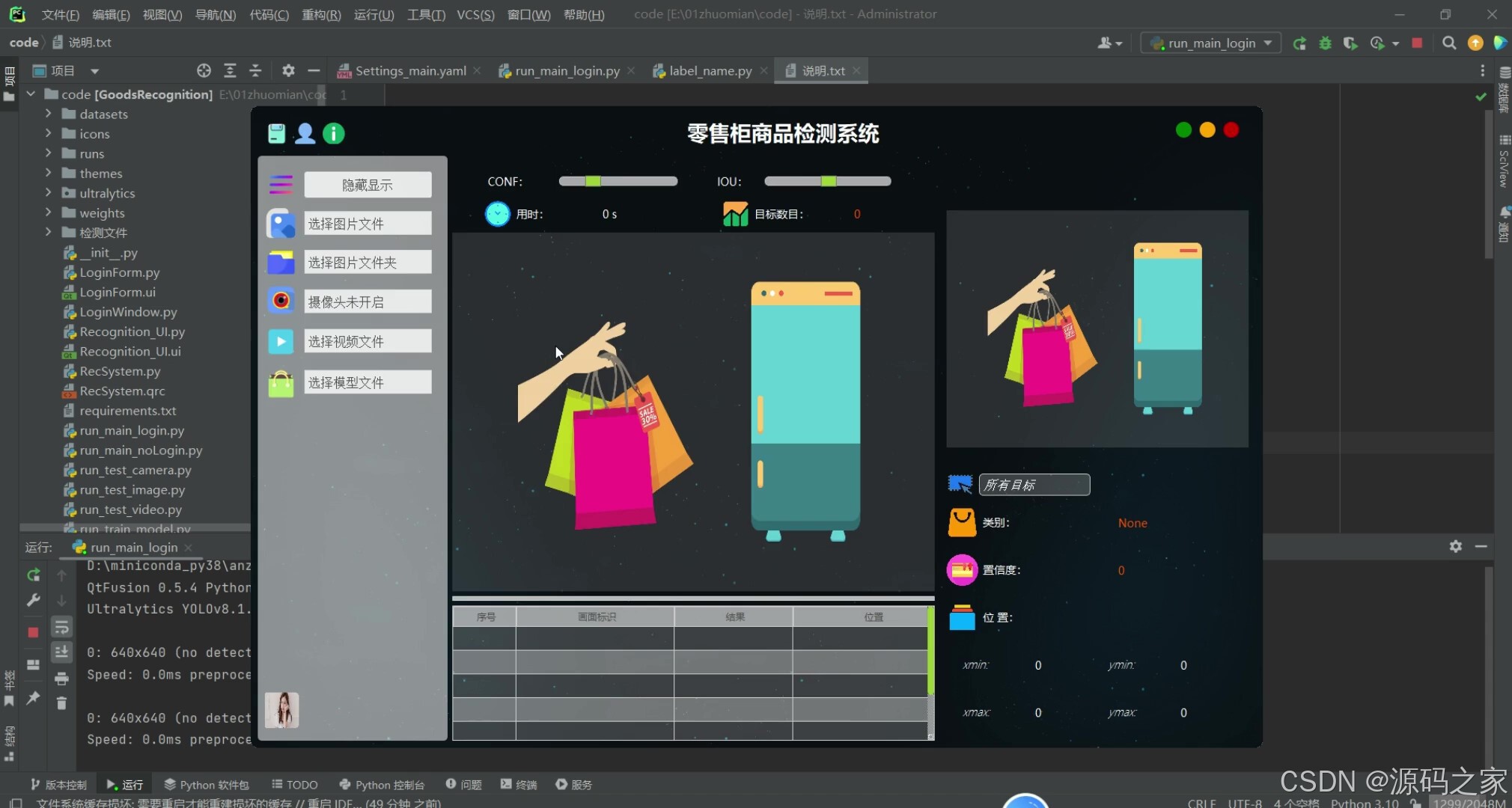
在主界面上,系统提供了支持图片、视频、实时摄像头和批量文件输入的功能。用户可以通过点击相应的按钮,选择要进行零售柜商品检测的图片或视频,或者启动摄像头进行实时检测。在进行零售柜商品检测时,系统会实时显示检测结果,并将检测记录存储在数据库中。
图5-3 系统界面
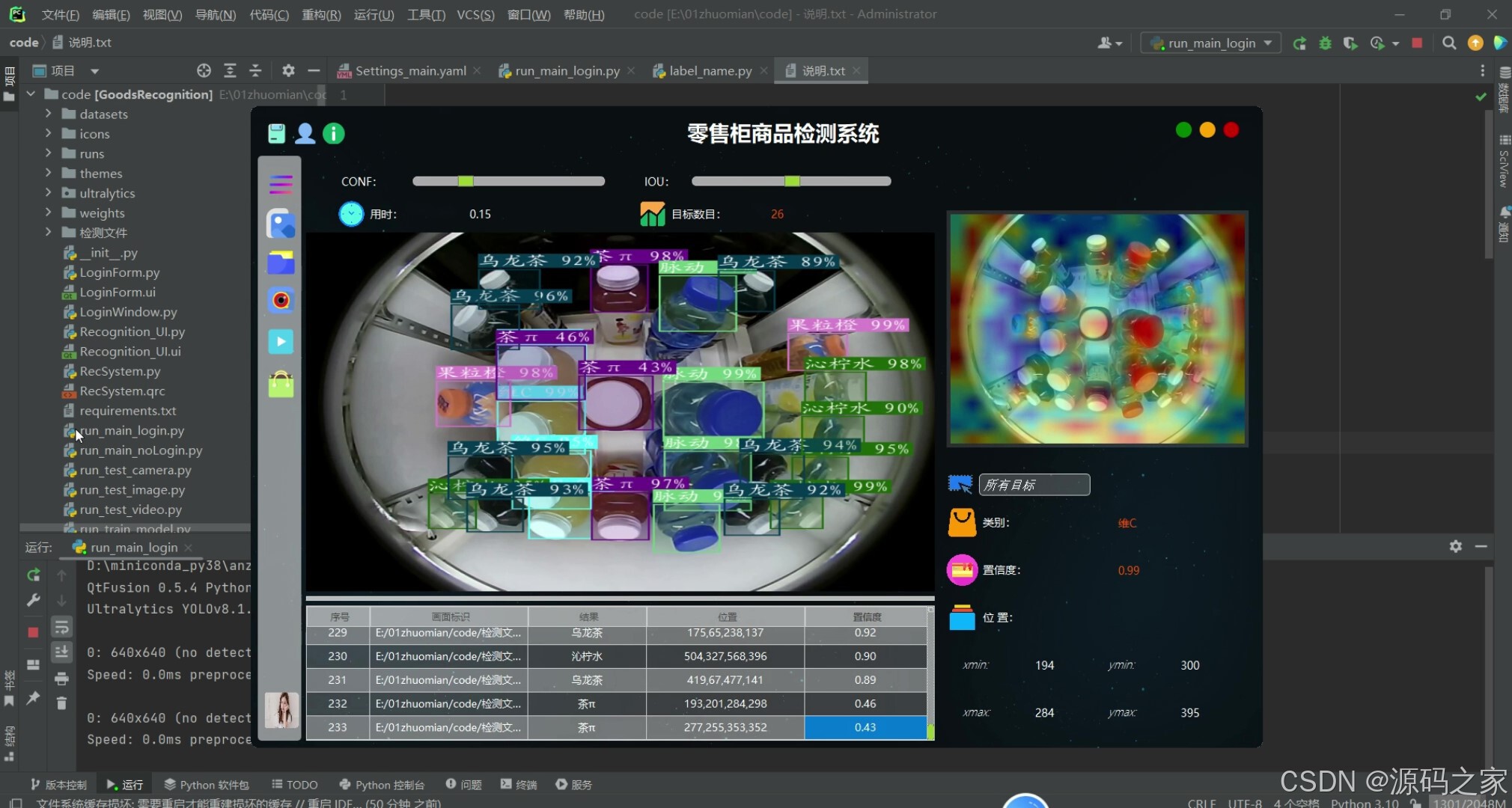
图片检测识别模块允许用户从本地文件系统选择单张图片进行零售商品检测。用户点击"图片检测"按钮后,系统会弹出一个文件选择对话框,用户从中挑选一张包含零售商品的图片。系统随后利用已训练的YOLOv8模型对图片进行处理,快速准确地识别出图片中的所有零售商品,并在界面上以检测框的形式标注出每个商品的类别和置信度。此外,系统还会将检测结果保存至数据库。
图5-4 图片检测识别模块
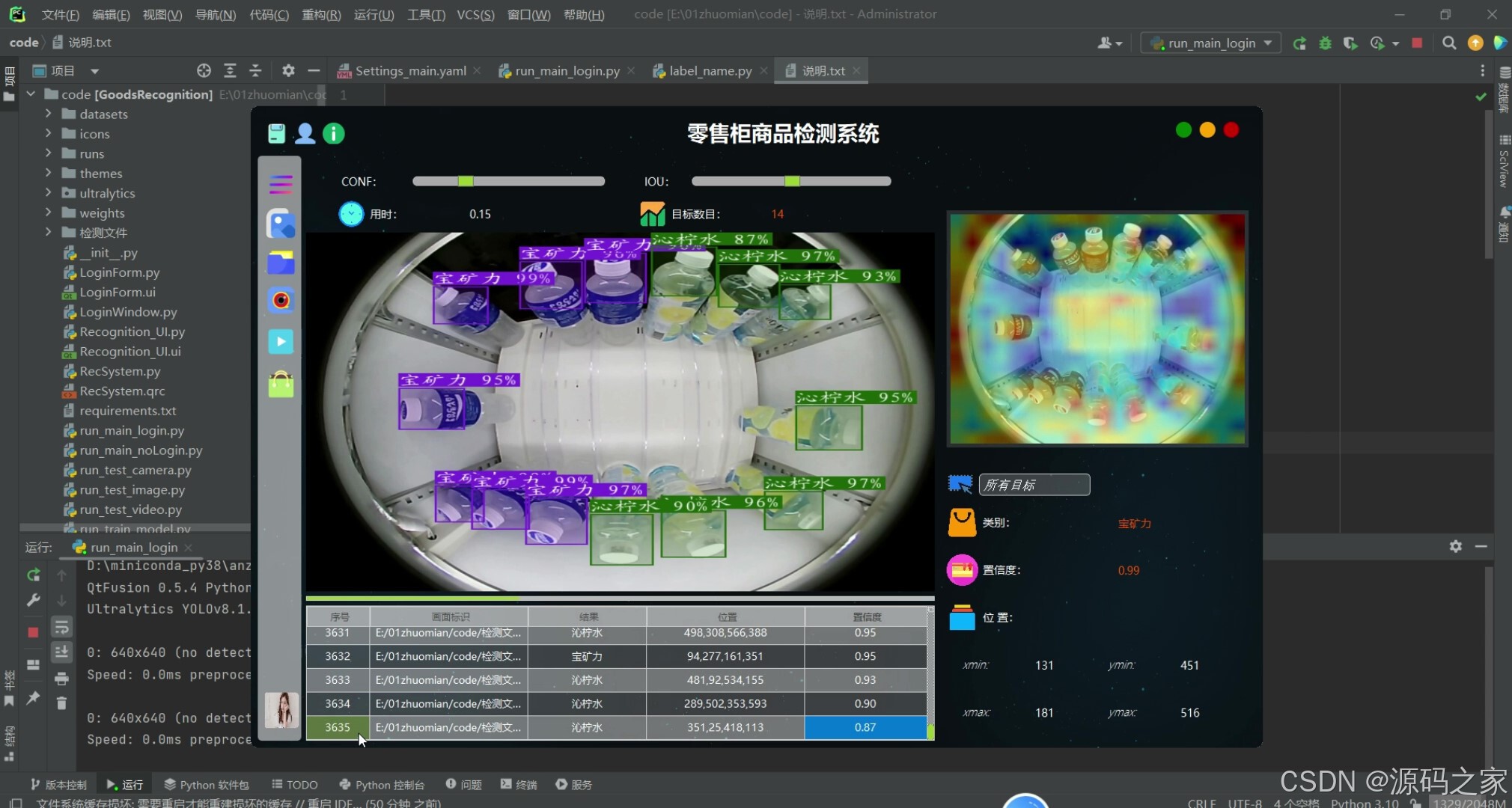
5.4 视频检测识别模块
视频检测识别模块支持用户对视频文件中的零售商品进行检测。用户通过点击"视频检测"按钮,选择一个包含零售商品场景的视频文件。系统开始播放视频的同时,会对每一帧画面进行实时检测,识别出视频中出现的所有零售商品,并在播放界面上叠加显示检测框、类别标签和置信度信息。此模块特别适用于监控视频分析,能够帮助零售商监控库存状态、顾客行为等关键信息。检测结果同样会被记录到数据库中,便于后续查询和分析。
图5-5 视频检测识别模块
5.5 摄像头检测识别模块
摄像头检测识别模块允许系统实时接入摄像头设备,对摄像头捕捉到的画面进行零售商品检测。用户点击"摄像头检测"按钮后,系统会请求访问摄像头权限(如适用),并开始从摄像头获取实时视频流。系统对每一帧视频流进行处理,识别出画面中的零售商品,并在界面上以检测框形式展示结果。此功能非常适合于智能零售柜、无人超市等场景,能够即时监测商品状态,提高运营效率。此外,系统还提供了调节置信度和IOU(交并比)阈值的选项,以便用户根据实际需求调整检测灵敏度。
图5-6 摄像头检测识别模块
5.6 模型更换模块
此外,系统还提供了一键更换YOLOv8/v5模型的功能。用户可以通过点击界面上的"更换模型"按钮,选择不同的YOLOv8模型进行检测。与此同时,系统附带的数据集也可以用于重新训练模型,以满足用户在不同场景下的检测需求。
图5-7 模型更换模块
4、核心代码
python
# -*- coding: utf-8 -*-
import cv2 # 导入OpenCV库,用于处理图像和视频
import torch
from QtFusion.models import Detector, HeatmapGenerator # 从QtFusion库中导入Detector抽象基类
from datasets.Goods.label_name import Chinese_name # 从datasets库中导入Chinese_name字典,用于获取类别的中文名称
from ultralytics import YOLO # 从ultralytics库中导入YOLO类,用于加载YOLO模型
from ultralytics.utils.torch_utils import select_device # 从ultralytics库中导入select_device函数,用于选择设备
device = "cuda:0" if torch.cuda.is_available() else "cpu"
ini_params = {
'device': device, # 设备类型,这里设置为CPU
'conf': 0.5, # 物体置信度阈值
'iou': 0.5, # 用于非极大值抑制的IOU阈值
'classes': None, # 类别过滤器,这里设置为None表示不过滤任何类别
'verbose': False
}
def count_classes(det_info, class_names):
"""
Count the number of each class in the detection info.
:param det_info: List of detection info, each item is a list like [class_name, bbox, conf, class_id]
:param class_names: List of all possible class names
:return: A list with counts of each class
"""
count_dict = {name: 0 for name in class_names} # 创建一个字典,用于存储每个类别的数量
for info in det_info: # 遍历检测信息
class_name = info['class_name'] # 获取类别名称
if class_name in count_dict: # 如果类别名称在字典中
count_dict[class_name] += 1 # 将该类别的数量加1
# Convert the dictionary to a list in the same order as class_names
count_list = [count_dict[name] for name in class_names] # 将字典转换为列表,列表的顺序与class_names相同
return count_list # 返回列表
class YOLOv8v5Detector(Detector): # 定义YOLOv8Detector类,继承自Detector类
def __init__(self, params=None): # 定义构造函数
super().__init__(params) # 调用父类的构造函数
self.model = None
self.img = None # 初始化图像为None
self.names = list(Chinese_name.values()) # 获取所有类别的中文名称
self.params = params if params else ini_params # 如果提供了参数则使用提供的参数,否则使用默认参数
# 创建heatmap
self.heatmap = HeatmapGenerator(heatmap_intensity=0.4, hist_eq_threshold=200)
def load_model(self, model_path): # 定义加载模型的方法
self.device = select_device(self.params['device']) # 选择设备
self.model = YOLO(model_path, )
layer = list(self.model.model.children())[0][-3]
self.heatmap.register_hook(reg_layer=layer)
names_dict = self.model.names # 获取类别名称字典
self.names = [Chinese_name[v] if v in Chinese_name else v for v in names_dict.values()] # 将类别名称转换为中文
self.model(torch.zeros(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
self.model(torch.rand(1, 3, *[self.imgsz] * 2).to(self.device).
type_as(next(self.model.model.parameters()))) # 预热
def preprocess(self, img): # 定义预处理方法
self.img = img # 保存原始图像
return img # 返回处理后的图像
def predict(self, img): # 定义预测方法
results = self.model(img, **ini_params)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
superimposed_img = self.heatmap.get_heatmap(img)
return results, superimposed_img
def postprocess(self, pred): # 定义后处理方法
results = [] # 初始化结果列表
for res in pred[0].boxes:
for box in res:
# 提前计算并转换数据类型
class_id = int(box.cls.cpu())
bbox = box.xyxy.cpu().squeeze().tolist()
bbox = [int(coord) for coord in bbox] # 转换边界框坐标为整数
result = {
"class_name": self.names[class_id], # 类别名称
"bbox": bbox, # 边界框
"score": box.conf.cpu().squeeze().item(), # 置信度
"class_id": class_id, # 类别ID
}
results.append(result) # 将结果添加到列表
return results # 返回结果列表
def set_param(self, params):
self.params.update(params)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻