REF:视觉和激光 SLAM 发展综述与展望
1. 基础框架
视觉和激光 SLAM 基本框架,包括前端里程计、后端优化、回环检测以及地图构建这四个模块
-
1.1 前端里程计:主要功能是估计传感器的运动信息,以提供准确的姿态估计
-
b-1 点云预处理:通过体素滤波、最小二乘法、RANSAC 算法等方法删除原始点云数据的离群点
-
b-2 点云配准:利用大量点云信息求出相邻帧之间的转换关系,使得两帧点云之间的距离无限接近
-
ICP 算法:对全局点位姿采用暴力匹配来找到最优点,为了增加鲁棒性及运行速度,衍生出GICP、PP-ICP、PL-ICP
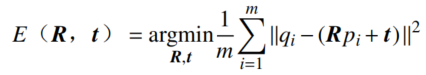
-
NDT 算法:将目标点云按照分辨率分成具有分布特性的网格,根据网格块对不同帧点云进行匹配
-
深度学习:使用神经网络来计算点云的变换矩阵
-
a-1 数学推导:
-
a-2 深度学习:
-
特征点法:检测和匹配特征点获取相机的位姿,工作流程包括特征提取、特征匹配、运动估计、三角化、局部地图构建几个步骤
-
直接法:基于连续图像帧之间的像素灰度值差异进行图像配准,采用光度一致性假设或最小化光度误差的策略
-
DeepVO:使用卷积神经网络(CNN)直接从原始图像帧中预测位姿
-
DeepVIO:在 DeepVO 的基础上耦合 IMU 估计位姿运动状态
-
a. 视觉里程计VO:分析连续图像帧来估计设备在场景中的运动和位置,具体实现方法包括数学推导、深度学习
-
b. 激光里程计LiO:分析激光雷达扫描到的数据之间的变化来计算激光雷达在运动中的位姿变化
-
-
1.2 后端优化:解决系统长时间运行中累积误差,一般采用基于滤波器和图优化的方法
-
a. 滤波器:假设当前时刻状态仅与上一时刻的状态有关,源于贝叶斯估计理论

-
b. 图优化算法:将问题表达为图模型(因子图或权重图),将状态变量作为图中的节点,将约束信息作为连接节点的边,通过求解误差最小化的最优状态估计获得机器人的最优轨迹地图
-
-
1.3 回环检测:通过全局数据分析来识别是否到达过历史场景,从而修正漂移误差并构建全局一致的轨迹地图
-
a. 视觉 SLAM:词袋模型构建由视觉单词组成的字典,将每帧图像表示为单词向量,当两帧图像的单词向量高度相似,便判定发生了回环
-
b. 激光SLAM:通过比较两帧点云数据的相似性来判断是否处在同一位置
-
-
1.4 地图构建:根据从环境中收集到的数据生成地图,常见地图类型有栅格地图、特征地图、点云地图等
2. 视觉SLAM
在视觉 SLAM 中 2D 通常使用单目或双目摄像头,而立体相机、RGB-D 相机等获取深度信息则用于 3D-SLAM,算法包括基于特征点、直接法和深度学习的方法

3. 激光 SLAM
激光 SLAM 按照维度可分为 2D-SLAM 和 3DSLAM,2D-SLAM 构建的地图主要形式为栅格地图,将环境分割成网格,每个网格表示一个特定区域的状态,易于表示和处理,栅格地图适用于平面环境。

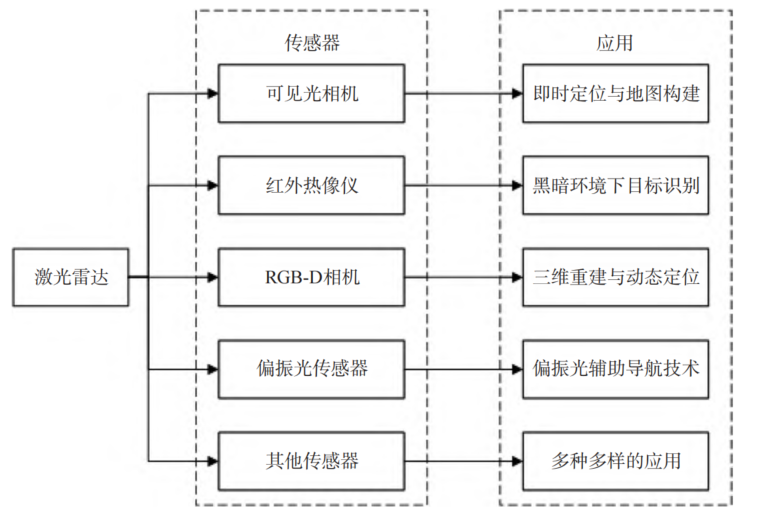
4. 多传感器融合 SLAM
不同类型的传感器,激光雷达、相机、红外热像仪、偏振光传感器等都有其独特的感知优势和局限,激光雷达与可见光相机、红外热像仪、RGB-D相机、偏振光传感器乃至震动传感器融合可以产生不一样的结果,从而应对复杂多变的外部环境
-
激光雷达:能够提供精确的距离信息和高分辨的空间信息
-
热像仪:能够在视野受限时捕捉环境中的热能分布
-
偏振光传感器:能提供关于光线散射与反射的独特信息