
一、模式(Schema)的核心概念
在 Milvus 中,Schema 就像是数据的 "蓝图",它定义了集合(Collection)的数据结构。如果把集合比作一个 "表格",那么 Schema 就是这个表格的 "表头设计"------ 规定了表格里有哪些字段、每个字段存什么类型的数据、哪些字段是核心标识等。
为什么 Schema 如此重要?
- 数据一致性:所有插入集合的实体都必须遵循 Schema,避免数据格式混乱;
- 搜索效率:合理的 Schema 设计能让数据存储更有序,索引结构更简洁,直接提升搜索性能;
- 业务适配:Schema 直接决定了能否通过搜索实现业务目标,比如能否按时间过滤、能否关联多维度信息等。
举个生活中的例子:如果我们要建一个 "图书档案库"(集合),Schema 就需要定义 "图书 ID"(主键)、"图书内容向量"(向量字段)、"出版时间"(标量字段)、"作者"(标量字段)等,这样才能规范地管理和检索图书。
二、Schema 的组成结构
一个完整的 Milvus Schema 由三部分组成:
-
主键字段:唯一标识每个实体(类似身份证号);
-
向量字段:存储向量嵌入(用于相似性搜索的核心数据);
-
标量字段:存储元数据(用于过滤、排序或结果展示)。
下图直观展示了一个文章搜索场景的 Schema 结构:文章集合 Schema
├─ 主键字段:article_id(唯一标识每篇文章)
├─ 向量字段:content_vector(文章内容的向量嵌入)
├─ 标量字段:
│ ├─ publish_time(发布时间,用于按时间过滤)
│ ├─ author(作者,用于按作者过滤)
│ ├─ title(标题,用于结果展示)
│ └─ is_published(是否发布,布尔类型过滤)
三、创建 Schema 的完整步骤
1. 初始化 Schema
首先需要创建一个空的 Schema 对象,后续再向其中添加字段。
python
from pymilvus import MilvusClient, DataType
# 初始化 Milvus 客户端
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
# 创建一个空的 Schema
schema = MilvusClient.create_schema()2. 添加主键字段
主键字段是集合中每个实体的唯一标识,相当于 "身份证号",必须设置且唯一。
主键字段的核心属性:
- 数据类型 :仅支持 INT64(整数)或 VARCHAR(字符串);
- is_primary :必须设为 True(标识为主键);
- auto_id :是否自动生成主键(True 则插入时无需指定,False 则需手动输入)。
示例 1:整数类型主键(手动指定 ID)
python
schema.add_field(
field_name="article_id", # 字段名:文章ID
datatype=DataType.INT64, # 数据类型:64位整数
is_primary=True, # 标识为主键
auto_id=False # 不自动生成,需手动输入
)此时插入数据时,必须指定 article_id 的值(如 1001、1002)。
示例 2:字符串类型主键(自动生成 ID)
python
schema.add_field(
field_name="user_id",
datatype=DataType.VARCHAR, # 数据类型:字符串
max_length=64, # 字符串最大长度(必填)
is_primary=True,
auto_id=True # 自动生成唯一字符串ID
)此时插入数据时,无需指定 user_id,Milvus 会自动生成类似 usr_6f2d9b 的唯一标识。
3. 添加向量字段
向量字段是 Milvus 用于相似性搜索的核心,存储将文本、图像等转化后的向量嵌入。一个集合最多可添加 4 个向量字段。
常见向量类型及适用场景:
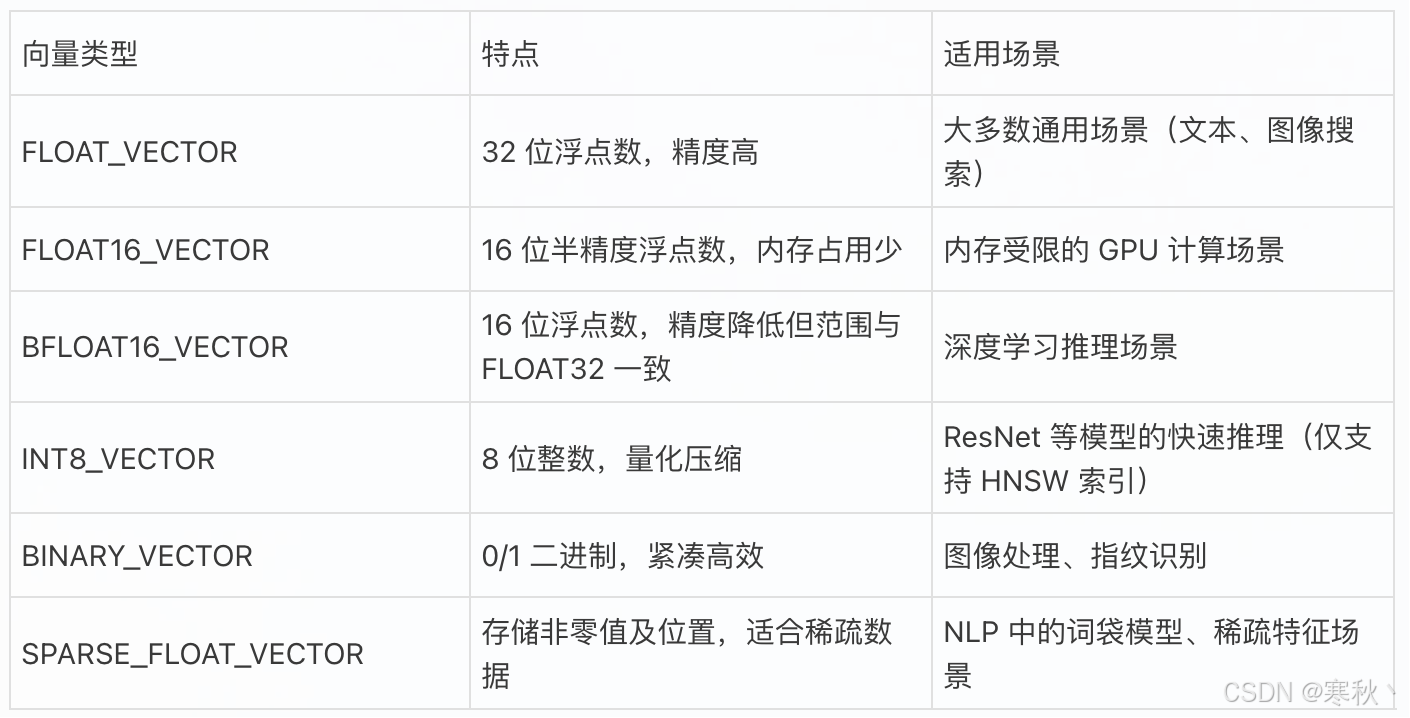
示例:添加文本向量字段
python
schema.add_field(
field_name="content_vector", # 字段名:内容向量
datatype=DataType.FLOAT_VECTOR, # 类型:32位浮点数向量
dim=768 # 向量维度(必填):如BERT模型生成的向量通常为768维
)这里的 dim 参数必须与实际生成的向量维度一致,否则插入会失败。
4. 添加标量字段
标量字段用于存储元数据,支持过滤、排序或结果展示。Milvus 支持多种标量类型,以下是常用类型的示例:
(1)字符串字段(VARCHAR)
用于存储文本信息(如标题、描述),需指定最大长度。
python
schema.add_field(
field_name="title", # 字段名:文章标题
datatype=DataType.VARCHAR,
max_length=512 # 最大长度512字符
)(2)数字字段(整数 / 浮点数)
用于存储数量、时间戳等,支持 INT8/INT16/INT32/INT64(整数)和 FLOAT/DOUBLE(浮点数)。
python
# 示例:添加发布时间戳(整数类型)
schema.add_field(
field_name="publish_timestamp",
datatype=DataType.INT64 # 存储Unix时间戳(毫秒级)
)
# 示例:添加评分(浮点数类型)
schema.add_field(
field_name="rating",
datatype=DataType.FLOAT # 如3.5、4.2等评分
)(3)布尔字段(BOOL)
用于存储 "是 / 否" 类信息(如是否发布、是否推荐)。
python
schema.add_field(
field_name="is_recommended",
datatype=DataType.BOOL # 值为True或False
)(4)JSON 字段
用于存储半结构化数据(如复杂的属性配置)。
python
schema.add_field(
field_name="metadata",
datatype=DataType.JSON # 可存储{"source": "web", "tags": ["tech", "ai"]}等
)(5)数组字段(ARRAY)
用于存储同类型元素的列表(如标签列表、作者列表),需指定元素类型和最大容量。
python
schema.add_field(
field_name="tags",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR, # 数组元素为字符串
max_capacity=10, # 最多存储10个标签
max_length=64 # 每个标签最大长度64字符
)此时该字段可存储类似 "机器学习", "Milvus", "向量数据库" 的数据。
5. 完整 Schema 示例(文章搜索场景)
python
from pymilvus import MilvusClient, DataType
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
# 创建Schema
schema = MilvusClient.create_schema(
description="Schema for article search", # 可选:添加描述
enable_dynamic_field=False # 关闭动态字段(严格遵循定义的字段)
)
# 添加主键字段
schema.add_field(
field_name="article_id",
datatype=DataType.INT64,
is_primary=True,
auto_id=False
)
# 添加向量字段(文章内容向量)
schema.add_field(
field_name="content_vector",
datatype=DataType.FLOAT_VECTOR,
dim=768
)
# 添加标量字段
schema.add_field(
field_name="title",
datatype=DataType.VARCHAR,
max_length=512
)
schema.add_field(
field_name="publish_timestamp",
datatype=DataType.INT64
)
schema.add_field(
field_name="author",
datatype=DataType.VARCHAR,
max_length=128
)
schema.add_field(
field_name="is_published",
datatype=DataType.BOOL
)
schema.add_field(
field_name="tags",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=10,
max_length=64
)
# 查看Schema结构
print("Schema详情:")
for field in schema.fields:
print(f"字段名:{field.name},类型:{field.dtype},是否主键:{field.is_primary}")四、Schema 设计的注意事项
- 提前规划字段:Schema 一旦创建(集合创建后),字段类型和主键属性无法修改,需提前确认业务需求;
- 向量维度匹配 :向量字段的 dim 必须与实际生成的向量维度一致(如模型输出为 1024 维,则 dim=1024);
- 合理设置长度 :VARCHAR 和数组的 max_length 不宜过大(避免浪费空间),也不宜过小(避免数据截断);
- 动态字段开关 :enable_dynamic_field=True 时允许插入未定义的字段,但会影响性能,建议关闭。
五、总结
Schema 是 Milvus 集合的 "骨架",它决定了数据的组织方式和搜索能力。设计时需结合业务场景,明确主键、向量字段和标量字段的用途,确保既能满足相似性搜索需求,又能通过元数据过滤提升结果准确性,后续会针对每种类型进行详细介绍。