- 模型评估指标可以分为优化指标(需要不断优化)和满意指标(满足条件即可)。
- 在设置验证集和测试集时,我们需要将它们随机打乱,最好三个数据集都是同一个分布,以免造成验证、测试之间的割裂;选择一个验证集和测试集来反映将来获取的数据,验证集和测试集应该来自相同的分布。
- 设置交叉验证集和评估指标是为模型设置目标,我们需要根据算法的结果去进一步调整目标,以保证模型不仅仅是为了解决某一问题,更需要保证伦理道德。
- 指标和开发测试集失效:开发测试集中模型a的错误率比模型b 的低,但是实际应用中b却表现得更好,示例如下。

在这样的情况下,我们就需要修改我们的目标以及开发测试集。
-
贝叶斯最优误差(最佳可能误差):达到理论最优水平,随时间训练,算法可能更大、更多数据,性能不断接近人类水平,但从不超越理论极限。
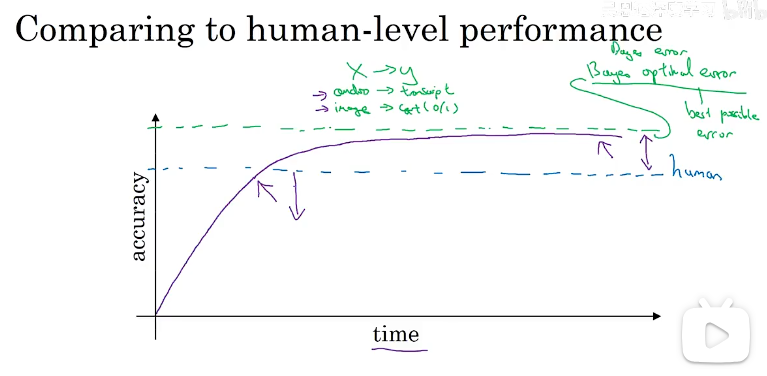 理解贝叶斯误差估计,人类水平可能稍微劣于贝叶斯误差,人类水平错误是估计贝叶斯错误的一种方式,所以我们可以通过贝叶斯误差以及我们算法的误差来解决我们使用什么策略去改进我们的算法。如何定义人类水平视我们实际要解决的问题而定。而贝叶斯误差一定是小于等于人类水平中最小的那个误差。
理解贝叶斯误差估计,人类水平可能稍微劣于贝叶斯误差,人类水平错误是估计贝叶斯错误的一种方式,所以我们可以通过贝叶斯误差以及我们算法的误差来解决我们使用什么策略去改进我们的算法。如何定义人类水平视我们实际要解决的问题而定。而贝叶斯误差一定是小于等于人类水平中最小的那个误差。 -
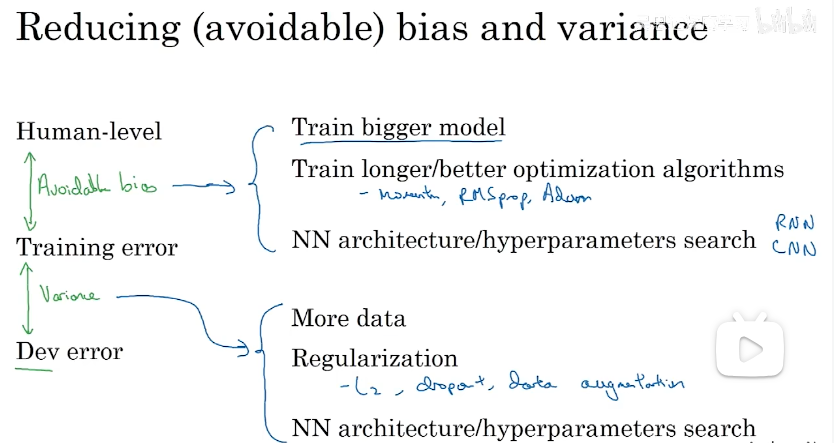
根据贝叶斯误差、训练误差、验证误差来指定策略(解决高方差或者高偏差)
-
监督学习问题的数据由输入𝑥和输出标签 𝑦 构成,如果你观察一下你的数据,并发现有些输出标签 𝑦 是错的,你的数据有些标签是错的,是否值得花时间去修正这些标签呢?深度学习算法对于训练集中的随机错误是相当健壮的(robust)。只要你的标记出错的样本,只要这些错误样本离随机错误不太远,有时可能做标记的人没有注意或者不小心,按错键了,如果错误足够随机,那么放着这些错误不管可能也没问题,而不要花太多时间修复它们。但是如果在进行错误分析时发现好多错误是由于标注出错,这时候就有必要修正这些错误了。
-
当训练集和开发测试集来自不同的分布,我们应该如何做?
 总之,目标设定很重要,目标不要偏移了。
总之,目标设定很重要,目标不要偏移了。 -
当我们的训练集、开发测试集来自不同分布时,偏差和方差分析也会变得不同。在这种情况下通常会造成训练误差和验证误差差别较大,即模型具有较高的方差,这时候我们可以新增一个数据集,叫做训练开发集(打乱训练集,从训练集中截取一部分作为训练开发集),开发集和测试集的分布相同,训练集和训练开发集的分布相同,我们用剩下的训练集训练验证模型,会得到三个误差(训练误差、训练开发误差、开发(即验证)误差),这样我们进能够进行误差分析,得到模型的问题所在(示例如下)。
 人类水平误差和训练误差的差值可以看出偏差的程度,训练误差到训练开发误差的差值可以看出方差的大小,训练开发误差和开发误差的差值可以看出数据不匹配问题的程度。而开发误差与测试误差的差值可以看出过度拟合的程度。
人类水平误差和训练误差的差值可以看出偏差的程度,训练误差到训练开发误差的差值可以看出方差的大小,训练开发误差和开发误差的差值可以看出数据不匹配问题的程度。而开发误差与测试误差的差值可以看出过度拟合的程度。
-
如何解决第9点说到的数据不匹配问题。我们可以对开发集进行错误分析,了解到开发集和训练集具体的不同之处,尝试是训练集与开发集更加相似。或者尝试收集更多类似于开发测试集的数据。比如说,如果模型在开发集中很难识别清楚数字,那么我们可以在训练集中多加入一些有关数字的数据。还有其他的方法吗?我们可以使用人工数据合成,示例如下:

-
迁移学习:进行一个初识的预训练:进行图像识别训练,训练完成之后更改数据集重新训练整合神经网络或者重新训练神经网络最后几层,更新权重,以适应新的数据集(微调)。意味着将从图像识别中学到的知识(学习到图像的结构和外形)应用到其他数据中去。迁移学习适用于源问题有大量数据而目标问题数据相对较少。示例如下:
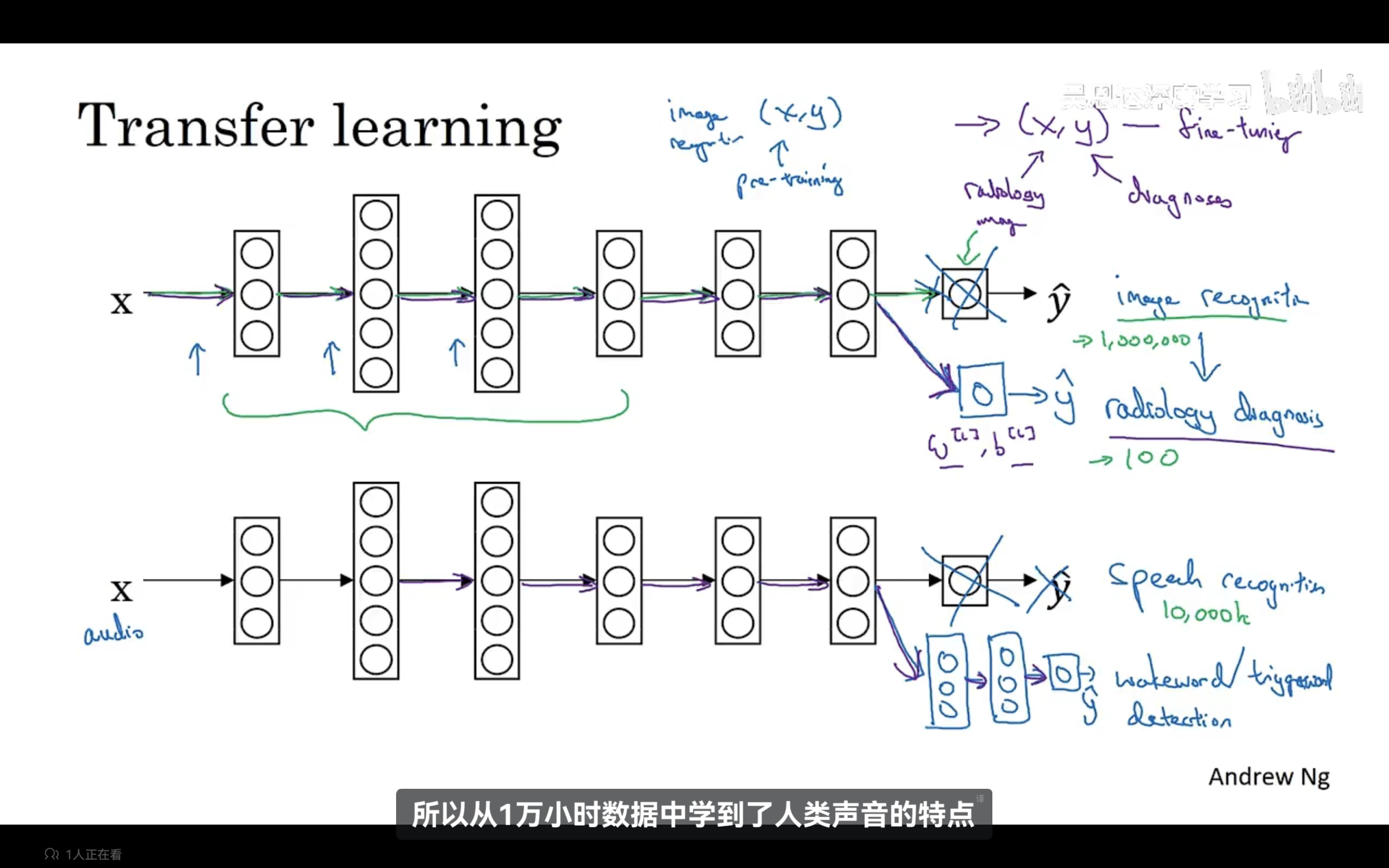 什么时候迁移学习有效呢?
什么时候迁移学习有效呢?
-
多任务学习:它与softmax不同之处在于它可以有多个标签,尽管里面有些标签可以缺失了,我们仍然可以用一个神经网络来训练数据,同时做多个识别任务。示例如下:
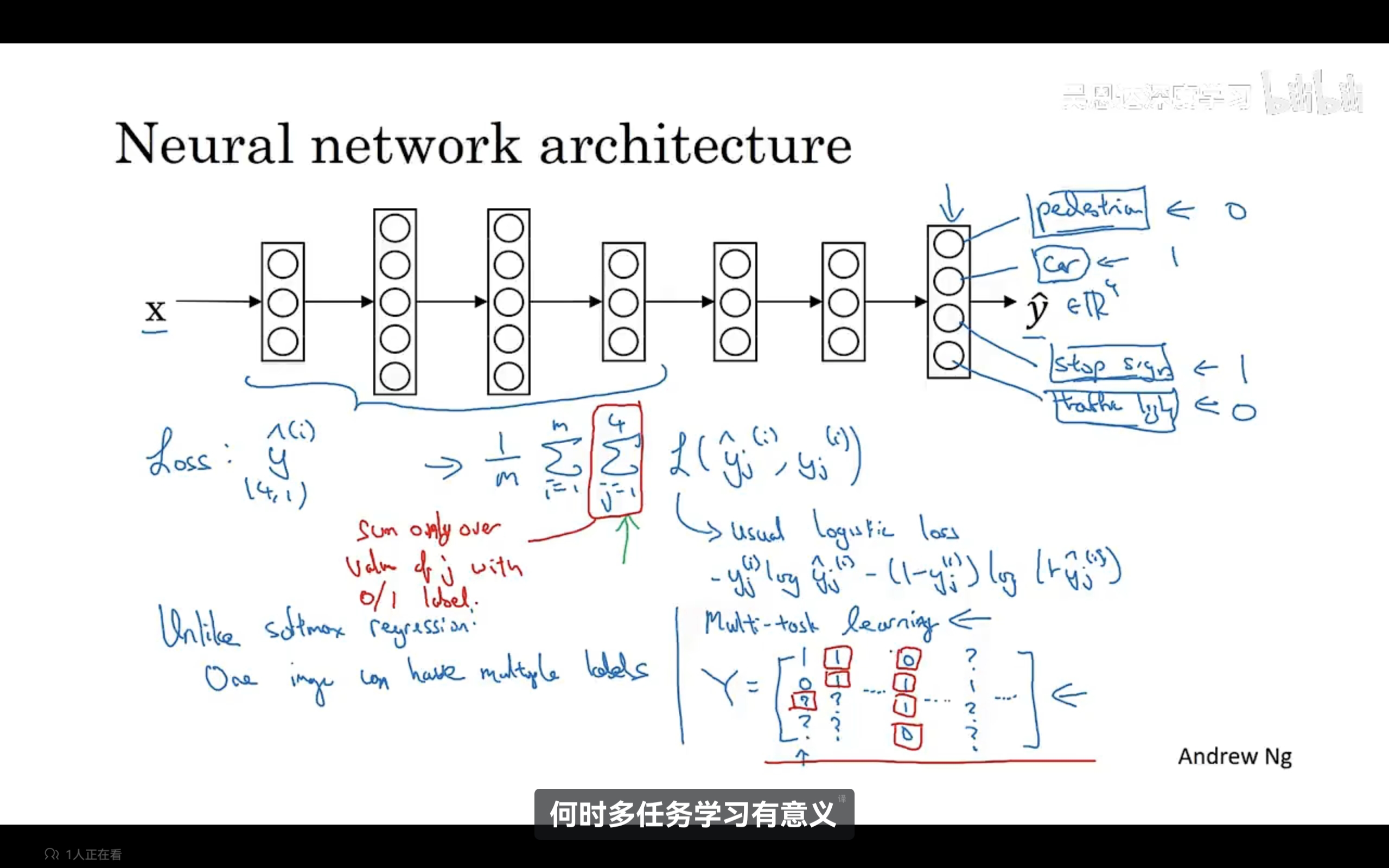 什么时候多任务学习有意义呢?有三个条件:1、能从低级共享特征中受益;2、每个任务的数据量相当;(不是必须的)3、多任务学习在大神经网络上训练时更有意义,使用多任务学习训练一个神经网络,可以等价于训练解决单个任务的多个神经网络模型。研究证明,多任务学习唯一损害性能相比单独训练神经网络就是神经网络不够大。
什么时候多任务学习有意义呢?有三个条件:1、能从低级共享特征中受益;2、每个任务的数据量相当;(不是必须的)3、多任务学习在大神经网络上训练时更有意义,使用多任务学习训练一个神经网络,可以等价于训练解决单个任务的多个神经网络模型。研究证明,多任务学习唯一损害性能相比单独训练神经网络就是神经网络不够大。 -
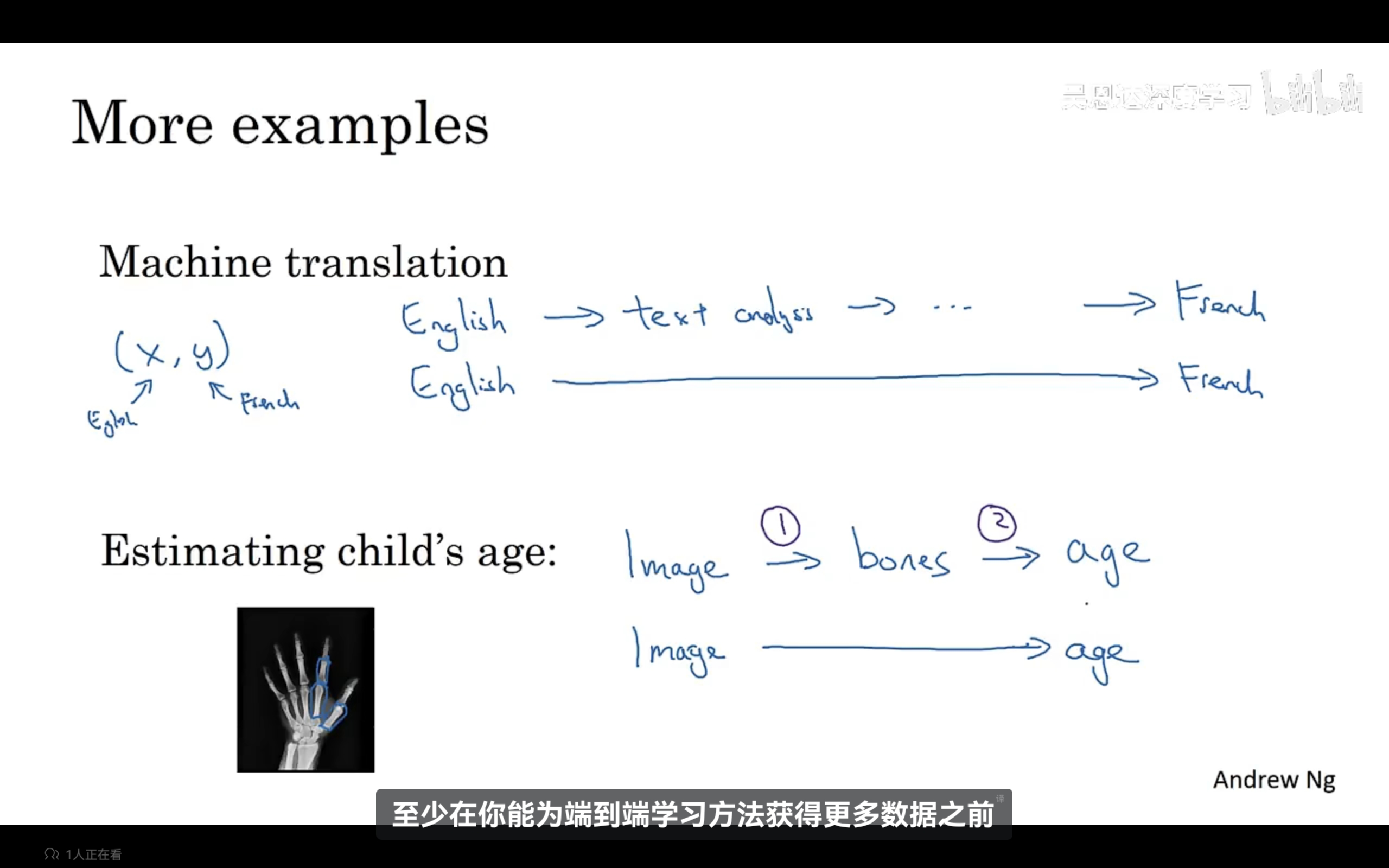
端到端深度学习:通常一个学习任务可能需要多个处理阶段,那么端到端深度学习可以训练一个巨大的神经网络,只需要输入数据,然后直接输出,神经网络真正绕过了了许多中间步骤,直接是x到y的函数映射。端到端深度学习的一个挑战是需要大量数据,需要大量数据端到端方法才真正出色。

 当端到端数据不够时,也许将任务分为多个步骤,每个步骤的数据足够,这样的效果更好,示例如下:
当端到端数据不够时,也许将任务分为多个步骤,每个步骤的数据足够,这样的效果更好,示例如下: 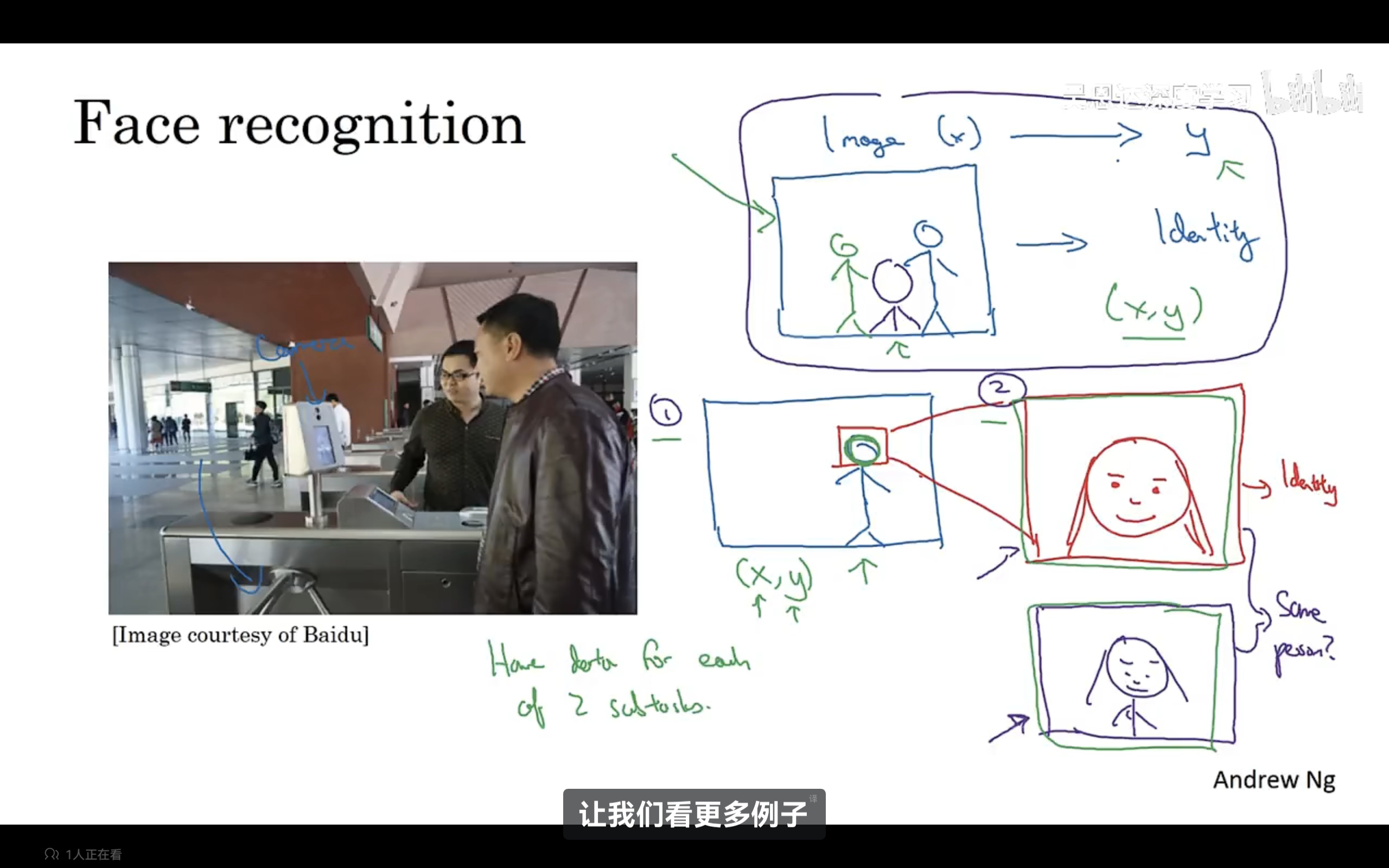
-
端到端深度学习的优缺点:
