一篇来自清华大学和北京大学的最新研究,它给热门的Vision Transformer(ViT)带来了一次相当漂亮的"线性提速"。
这篇被NeurIPS 2025录用的论文,标题为 《Linear Differential Vision Transformer:Learning Visual Contrasts via Pairwise Differentials》 ,提出了一种名为 "视觉对比注意力"(Visual-Contrast Attention,VCA) 的新模块。

论文链接:
项目链接:
简单来说,VCA就像是给ViT装上了一双"火眼金睛",让它不再是"一视同仁"地看图中所有内容,而是学会了主动"找不同",聚焦于那些真正具有区分度的信息。
最关键的是,这个新模块几乎不增加计算量,却能实打实地提升模型性能。
ViT的"甜蜜烦恼"与VCA的诞生
熟悉计算机视觉的朋友们都知道,Vision Transformer(ViT)现在已遍地开花,无论图像识别还是图像生成,都能看到它的身影。
但ViT也有个"甜蜜的烦恼"------它的核心部件,多头自注意力(Multi-Head Self-Attention,MHSA),计算量太大了。
MHSA会对图像中的每一对图块(token)都进行相似度计算,这是一个平方级别的复杂度(O(N²))。这意味着,图像越大、图块越多,计算成本就呈指数级增长。
很多时候,模型把大量的算力都浪费在了计算那些没啥信息量或者重复的区域关系上。
为了解决这个问题,研究者们想了不少办法。有的方法限制注意力范围,比如只在局部窗口内计算,但这又可能丢失全局信息。有的方法用低秩分解或傅里叶变换来近似注意力矩阵,但它们还是平等地对待所有信息,没能抓住重点。
而这篇论文的作者们另辟蹊径,他们认为,与其被动地处理所有信息,不如让模型主动去发现"对比"和"差异"。这个想法催生了视觉对比注意力(VCA)。
VCA如何实现"找不同"?
VCA的设计非常巧妙,可以即插即用地替换掉原来ViT中的MHSA模块。它的核心思想分为两步:
- 第一阶段:生成全局对比信息
首先,VCA不再让所有的查询(query)都去和键(key)直接硬碰硬。它选择了一种更聪明的方式:
信息压缩:对于每个注意力头,VCA先把整个图像的查询特征图通过平均池化操作,压缩成一个很小的网格(比如8x8)。这样,原来成百上千的图块就被浓缩成了几十个"视觉对比令牌"。
创建正负"视角":接下来是关键一步。VCA为这些浓缩后的令牌添加两种不同的、可学习的位置编码,从而创造出两个"流":一个"正向流"和一个"负向流"。你可以把它们想象成从两个略有不同的角度去观察同一份浓缩信息。
差分交互:这两个流分别与全局的键和值进行交互,然后将得到的结果相减。这一减,神奇的事情发生了------那些在两个"视角"下都差不多的普通信息被抵消了,而那些有显著差异的、真正重要的对比信息就被凸显了出来。
通过这个过程,VCA用很小的计算代价,就提炼出了一份信息量极高的"全局对比图"。
- 第二阶段:基于对比图进行精细化注意力
有了这份"全局对比图",第二阶段就简单高效多了。原始的每个图块查询不再需要跟所有其他图块去比较,而是直接与这份浓缩的"对比图"进行交互。
这个交互同样是差分式的,查询会同时关注对比图的"正向"和"负向"信息,最终计算出每个图块在"对比"视角下的重要性。
整个过程下来,VCA成功地将计算复杂度从O(N²C)降低到了O(NnC),其中n是对比令牌的数量,远小于N。这意味着计算成本与图块数量N之间变成了线性关系,ViT终于可以"减负"了。
效果如何?数据说话
理论说得再好,还得看实际效果。作者们在图像分类和图像生成两大任务上对VCA进行了充分验证。
- 图像分类:精度显著提升
在ImageNet-1K分类任务上,VCA的效果非常惊人。
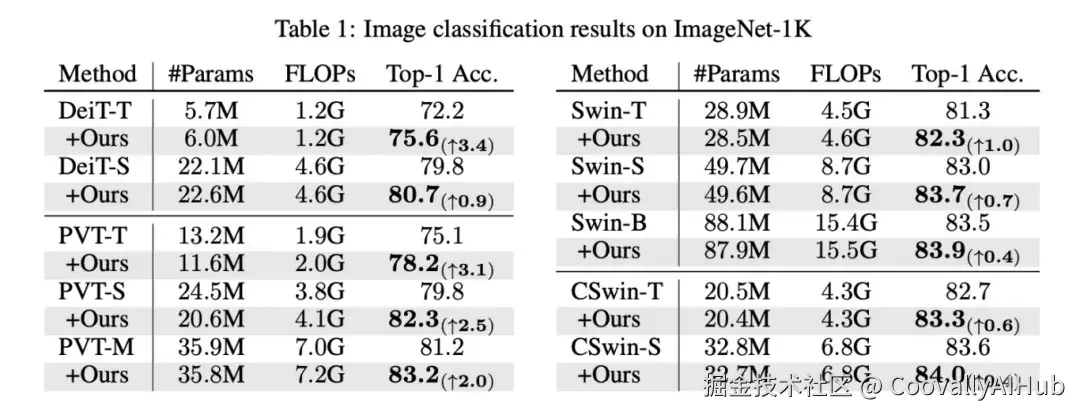
从上表可以看到:
给轻量的DeiT-Tiny模型换上VCA后,参数量只增加了0.3M,计算量不变,但Top-1准确率直接从72.2%提升到了75.6%,足足高了3.4个百分点!
即使对于Swin Transformer这类已经经过优化的层级式ViT,VCA同样能带来稳定的性能提升,最高提升了3.1个百分点(在PVT-Tiny上)。
这个结果说明VCA的"对比"机制确实抓住了图像识别的关键,而且它的普适性很好,能给各种ViT架构带来增益。
- 图像生成:生成质量更高
在类条件图像生成任务上,作者们将VCA应用到了DiT(Diffusion Transformer)和SiT(Flow Transformer)模型上。评价指标是FID,这个值越低说明生成图像的质量越高。
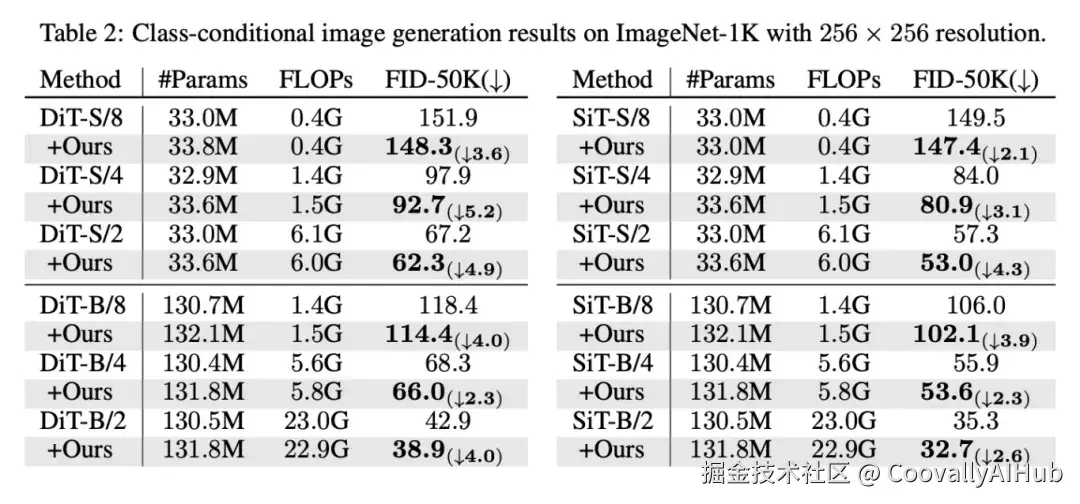
结果同样令人印象深刻:
在各种模型尺寸和配置下,VCA都稳定地降低了FID分数。
对于DiT-S/4模型,FID分数降低了5.2点;对于DiT-S/2模型,FID降低了4.9点。
无论是基于扩散的DiT还是基于流的SiT,VCA都能起作用,证明了它对生成范式的普适性。
消融实验:每个设计都不可或缺
为了证明VCA的设计不是"玄学",作者还做了详尽的消融实验。
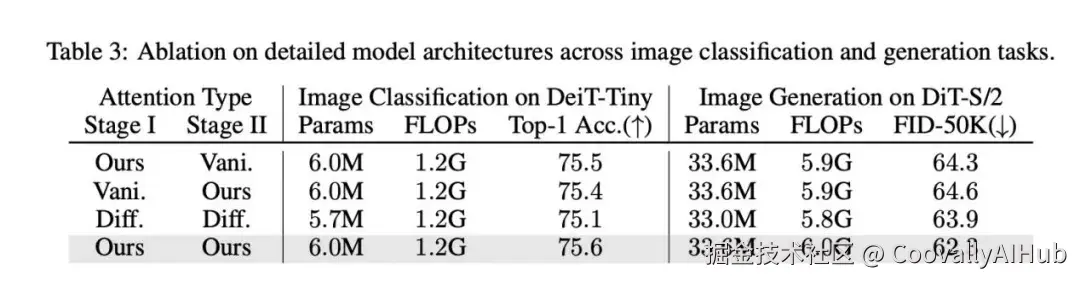
上表验证了VCA两个阶段的协同作用。无论是只用第一阶段的全局对比,还是只用第二阶段的差分注意力,性能都有提升,但将两者结合起来效果最好。
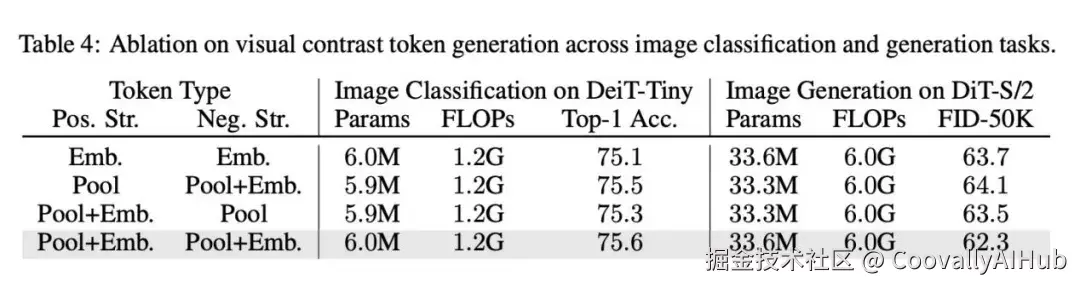
而这张表则证明了"空间池化"和"双位置编码"这两个设计的必要性。简单地使用可学习的嵌入虽然也有效果,但远不如从图像本身通过池化获取信息,并用正负位置编码来区分"视角"来得有效。这说明,让模型从数据中学习对比线索,才是VCA成功的关键。
总结
总的来说,VCA用一个简单、轻量且高效的"差分"思想,漂亮地解决了ViT的计算瓶颈,并带来了实实在在的性能飞跃。
它提醒我们,有时候注意力机制不一定非得是"相似性"的度量,也可以是"差异性"的发现者。这种思维转变,可能会为未来的Transformer架构设计开辟新的道路。
这项研究已经开源,感兴趣的朋友可以访问项目主页,亲自体验这一"火眼金睛"的神奇效果。