TL;DR
- 场景:图数据库项目中高频用到的字符串函数、聚合、关系函数与 shortestPath,多跳查询易踩坑。
- 结论:以 Cypher 5/Neo4j 5.x 为基线,先掌握 toLower/trim/replace/split/substring/size、startNode/endNode、可变长度路径;避免一次多语句与未绑定变量。
- 产出:函数清单与示例整理、版本兼容矩阵、错误速查卡(覆盖 WITH 传参、shortestPath 约束、属性缺失、类型不匹配等)。

CQL函数
字符串函数
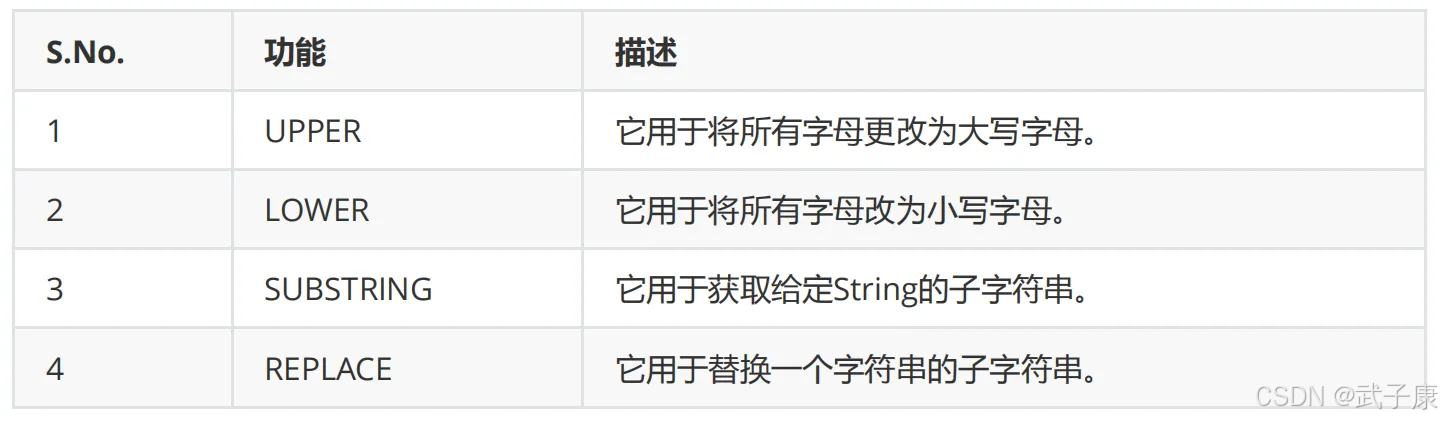
基本字符串函数
-
toString()
- 功能:将任意类型的值转换为字符串形式
- 示例:
RETURN toString(123)→ 返回 "123" - 应用场景:将数值、布尔值等非字符串类型转换为字符串以便与其他字符串连接或比较
-
toUpper()
- 功能:将字符串转换为大写形式
- 示例:
RETURN toUpper("neo4j")→ 返回 "NEO4J" - 应用场景:统一大小写格式进行字符串比较或显示
-
toLower()
- 功能:将字符串转换为小写形式
- 示例:
RETURN toLower("Neo4J")→ 返回 "neo4j" - 应用场景:同上,用于标准化字符串格式
字符串操作函数
-
trim()
- 功能:去除字符串两端的空白字符
- 示例:
RETURN trim(" Neo4j ")→ 返回 "Neo4j" - 变体:
lTrim()- 仅去除左侧空白rTrim()- 仅去除右侧空白
-
replace()
- 功能:替换字符串中的子串
- 语法:
replace(原始字符串, 要替换的子串, 替换为的子串) - 示例:
RETURN replace("Hello World", "World", "Neo4j")→ 返回 "Hello Neo4j" - 应用场景:批量修改数据中的特定文本
-
substring()
- 功能:提取字符串的一部分
- 语法:
substring(字符串, 起始位置)(从0开始计数)substring(字符串, 起始位置, 长度)
- 示例:
RETURN substring("Neo4j", 3)→ 返回 "4j"RETURN substring("Neo4j", 1, 3)→ 返回 "eo4"
字符串信息函数
-
size()
- 功能:返回字符串的字符长度
- 示例:
RETURN size("Neo4j")→ 返回 5 - 注意:与
length()函数功能相同,可以互换使用
-
split()
- 功能:按分隔符将字符串分割为字符串数组
- 示例:
RETURN split("one,two,three", ",")→ 返回 "one", "two", "three" - 应用场景:处理CSV格式的数据或路径字符串
-
reverse()
- 功能:反转字符串字符顺序
- 示例:
RETURN reverse("Neo4j")→ 返回 "j4oeN"
字符串匹配函数
-
contains()
- 功能:检查字符串是否包含子串
- 示例:
RETURN contains("Neo4j", "4j")→ 返回 true - 应用场景:数据筛选或条件判断
-
startsWith()
- 功能:检查字符串是否以指定前缀开头
- 示例:
RETURN startsWith("Neo4j", "Neo")→ 返回 true
-
endsWith()
- 功能:检查字符串是否以指定后缀结尾
- 示例:
RETURN endsWith("Neo4j", "4j")→ 返回 true
-
left() / right()
- 功能:
left(字符串, 长度)- 返回字符串左侧指定长度的子串right(字符串, 长度)- 返回字符串右侧指定长度的子串
- 示例:
RETURN left("Neo4j", 3)→ 返回 "Neo"RETURN right("Neo4j", 2)→ 返回 "4j"
- 功能:
特殊字符串处理
-
toStringOrNull()
- 功能:尝试将输入转换为字符串,失败则返回null
- 与
toString()的区别:不会抛出异常,处理更安全
-
toStringList()
- 功能:将列表中的元素转换为字符串列表
- 示例:
RETURN toStringList([1, 2, true])→ 返回 "1", "2", "true"
实际应用示例
cypher
// 查询名称以特定前缀开头且经过标准化的用户
MATCH (u:User)
WHERE startsWith(toLower(u.name), 'alex')
RETURN u.name, size(u.name) as nameLength
cypher
// 处理地址数据,标准化格式
MATCH (a:Address)
SET a.city = toUpper(trim(a.city)),
a.street = replace(a.street, "St.", "Street")语法实例
基本的语法如下所示:
shell
MATCH (p:Person)
RETURN ID(p),LOWER(p.character)尝试一个例子:
shell
match(person:Person) RETURN ID(person), UPPER(person.character);执行的结果如下所示,可以看到 UPPER 函数已经将结果转换为大写了:

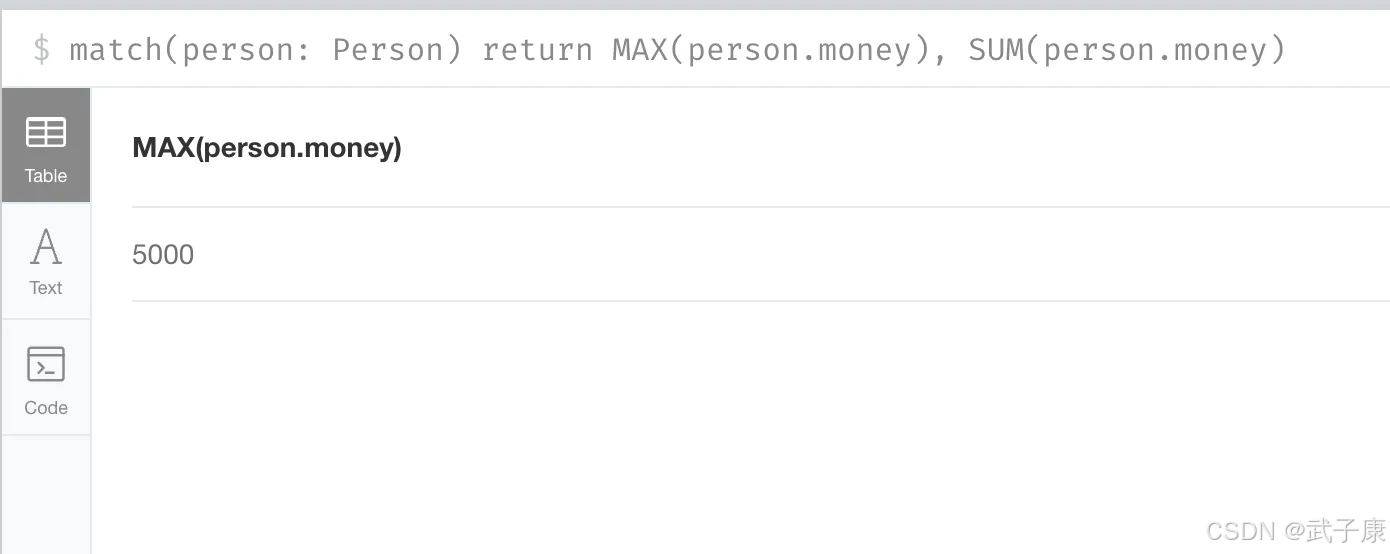
聚合函数

对应的语法格式如下所示:
shell
MATCH (p:Person)
RETURN MAX(p.money),SUM(p.money)执行结果可以看到已经计算出来了,后半段截图没有截到:
关系函数
这里我们元数据长这个样子:
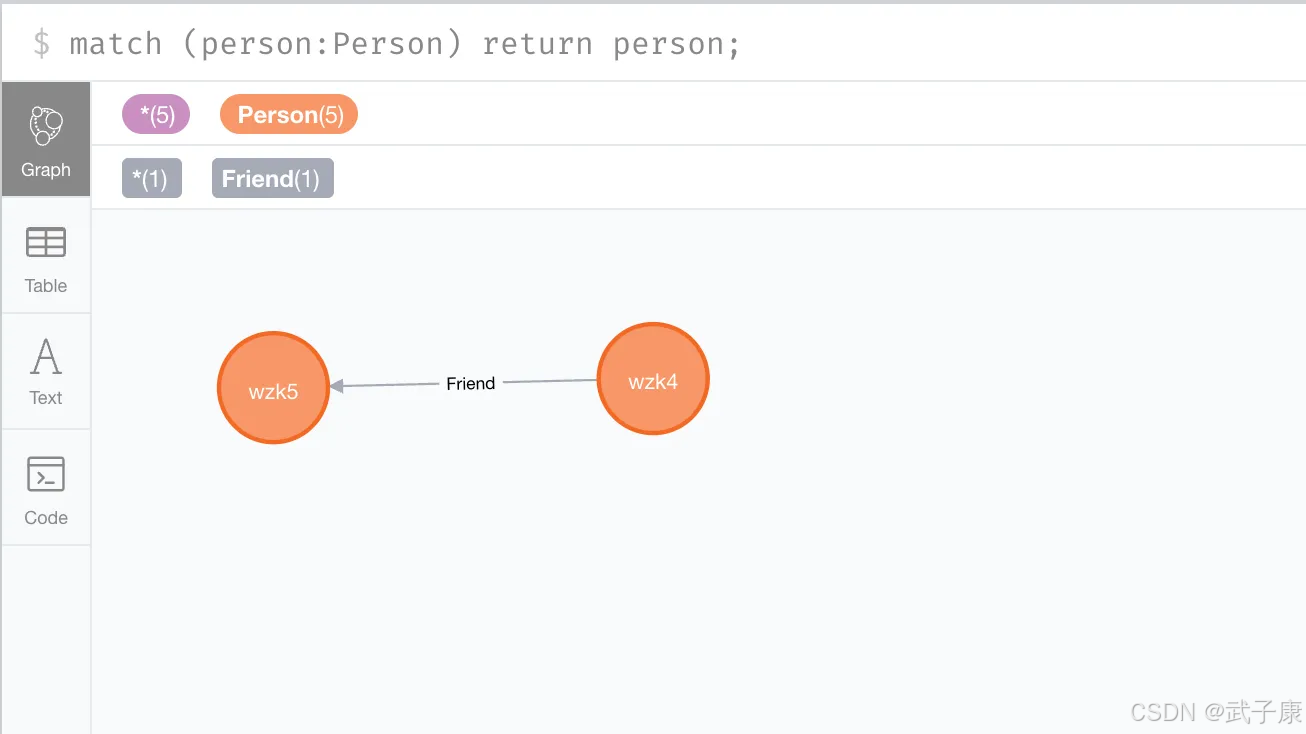
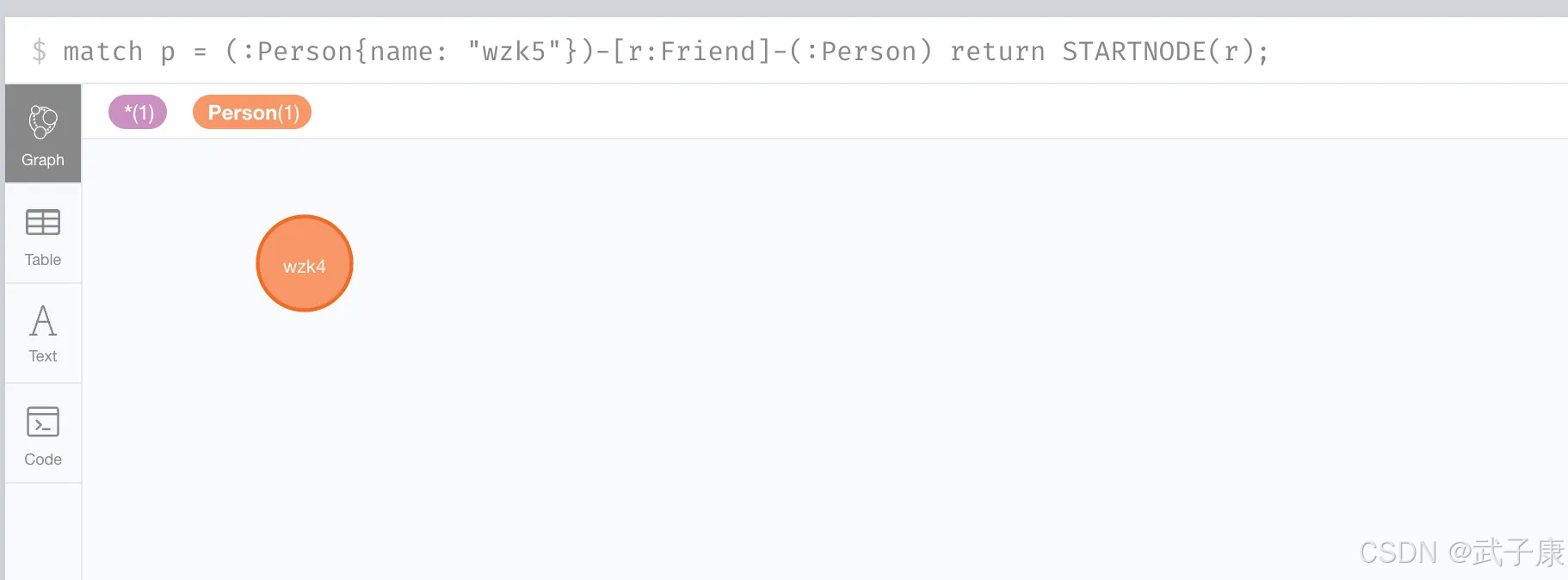
然后我们查询 wzk5 的 friend 关系的:
shell
match p = (:Person{name: "wzk5"})-[r:Friend]-(:Person) return STARTNODE(r);可以看到查询到了 wzk4 的内容:
最短Path
shell
MATCH p=shortestPath( (node1)-[*]-(node2) )
RETURN length(p), nodes(p)CQL多深度关系点
with关键字
这里我们加入一些内容,让整体变得复杂起来:
shell
// 清理旧数据 (可选)
// MATCH (n:Person) WHERE n.name STARTS WITH "wzk" DETACH DELETE n;
// ====== 创建节点 =======
UNWIND range(1, 10) AS i
MERGE (:Person {name:"wzk" + i});
// ====== 创建多样关系 =======
// 1)链式关系(长链)
MATCH (a:Person {name:"wzk1"}), (b:Person {name:"wzk2"})
MERGE (a)-[:Follow]->(b);
MATCH (b:Person {name:"wzk2"}), (c:Person {name:"wzk3"})
MERGE (b)-[:Friends]->(c);
MATCH (c:Person {name:"wzk3"}), (d:Person {name:"wzk4"})
MERGE (c)-[:Colleague]->(d);
MATCH (d:Person {name:"wzk4"}), (e:Person {name:"wzk5"})
MERGE (d)-[:Knows]->(e);
// 2)三角结构(循环)
MATCH (p1:Person {name:"wzk3"}),(p2:Person {name:"wzk6"}),(p3:Person {name:"wzk7"})
MERGE (p1)-[:Friends]->(p2)
MERGE (p2)-[:Friends]->(p3)
MERGE (p3)-[:Friends]->(p1);
// 3)星型关系(hub-and-spoke)
MATCH (c:Person {name:"wzk5"}), (n:Person)
WHERE n.name IN ["wzk6","wzk7","wzk8","wzk9"]
MERGE (c)-[:Follow]->(n)
MERGE (n)-[:Knows]->(c);
// 4)双向 Couple(特意制造有向+无向混合)
MATCH (a:Person {name:"wzk1"}),(b:Person {name:"wzk8"})
MERGE (a)-[:Couple]->(b)
MERGE (b)-[:Couple]->(a);
// 5)复杂跨层跳跃
MATCH (x:Person {name:"wzk9"}),(y:Person {name:"wzk10"})
MERGE (x)-[:Colleague]->(y);
MATCH (y:Person {name:"wzk10"}),(z:Person {name:"wzk2"})
MERGE (y)-[:Follow]->(z);
// 6)制造稠密关系(高节点度,用于性能测试)
MATCH (p:Person), (p2:Person)
WHERE p.name STARTS WITH "wzk"
AND p2.name STARTS WITH "wzk"
AND p <> p2
AND rand() < 0.15 // 15% 概率生成一条边
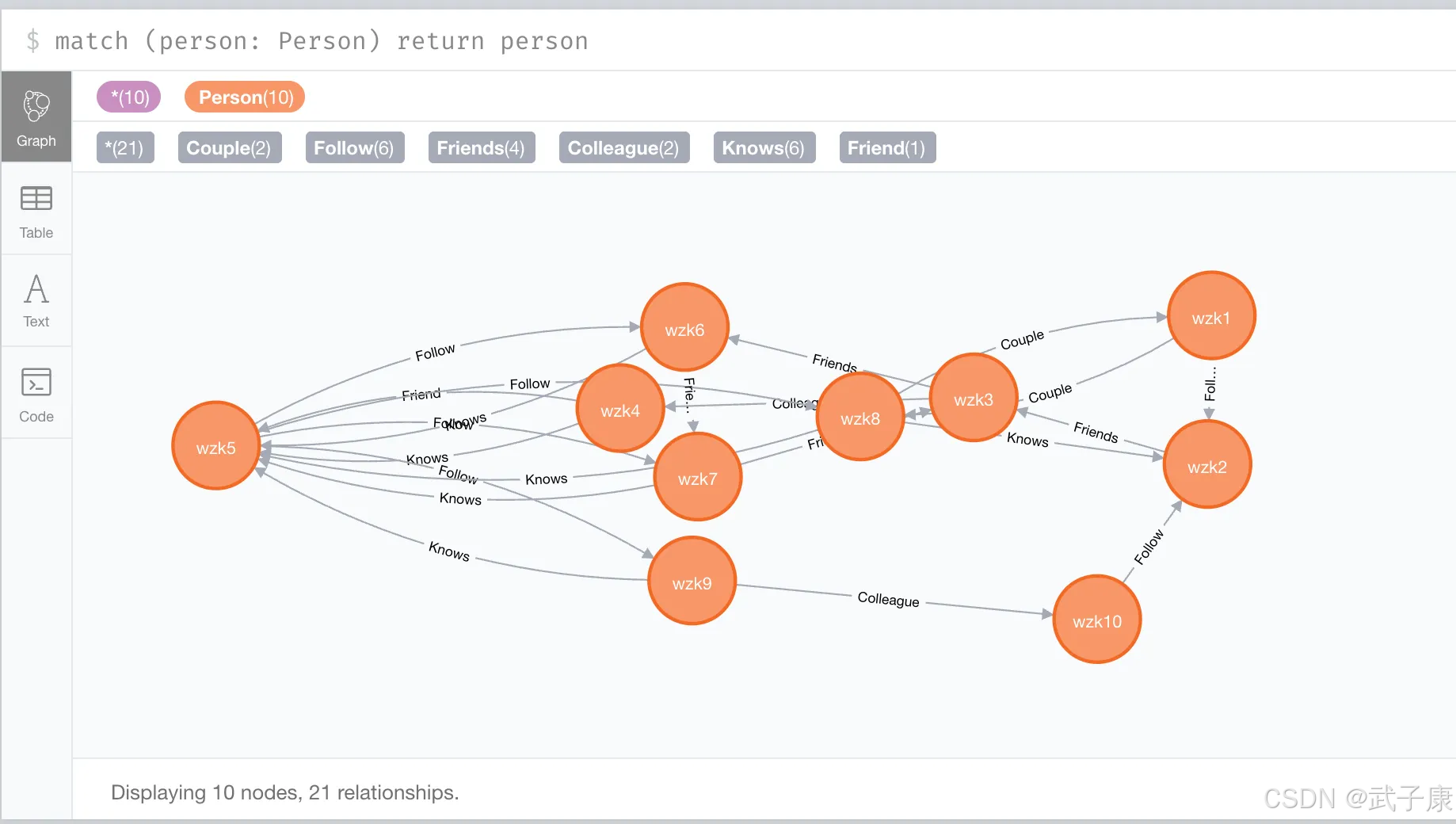
MERGE (p)-[:Knows]->(p2);整体执行完之后,会生成类似这样的结构:
直接拼接关系节点查询
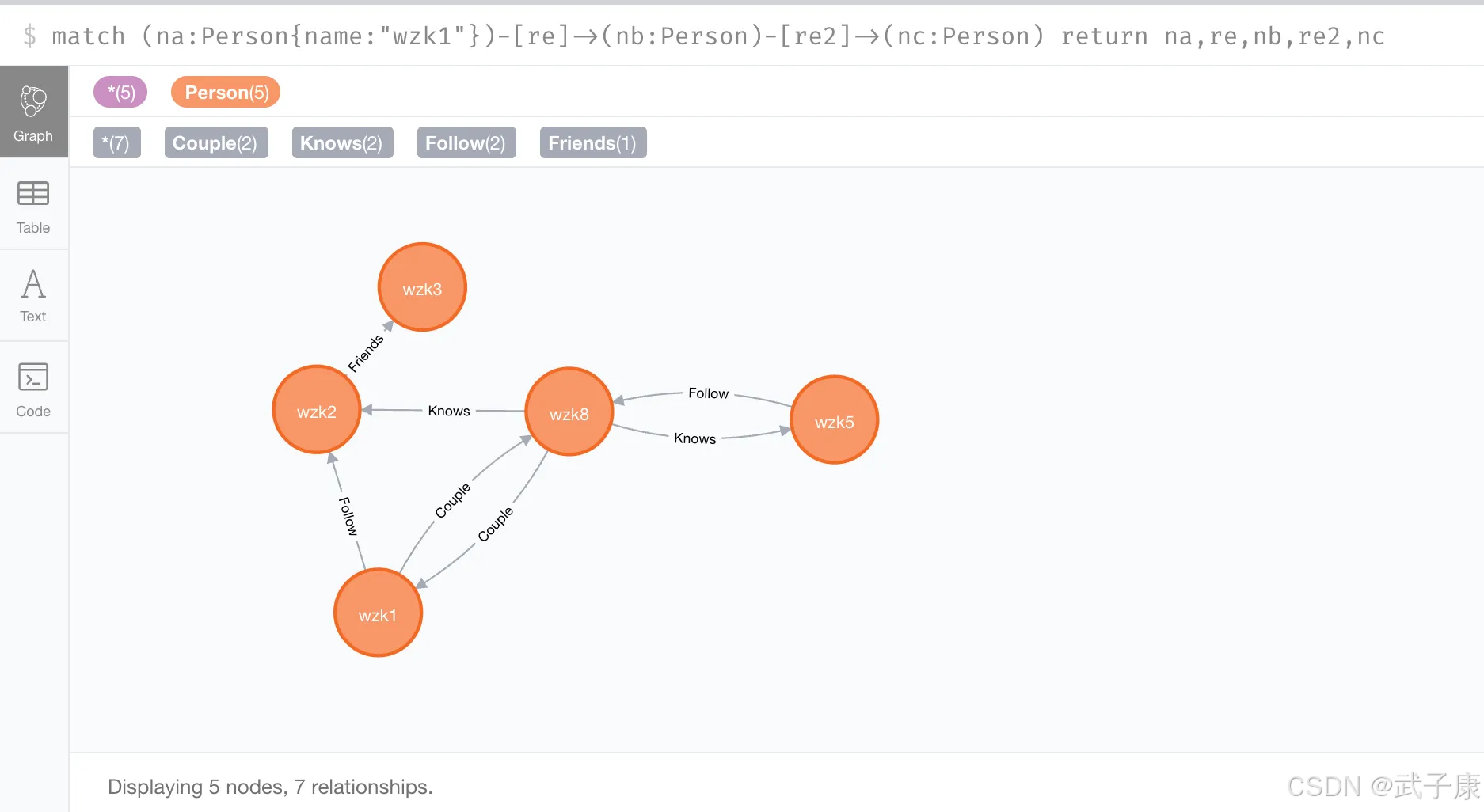
shell
match (na:Person{name:"wzk1"})-[re]->(nb:Person)-[re2]->(nc:Person) return na,re,nb,re2,nc运行结果如下所示:
使用深度运算符
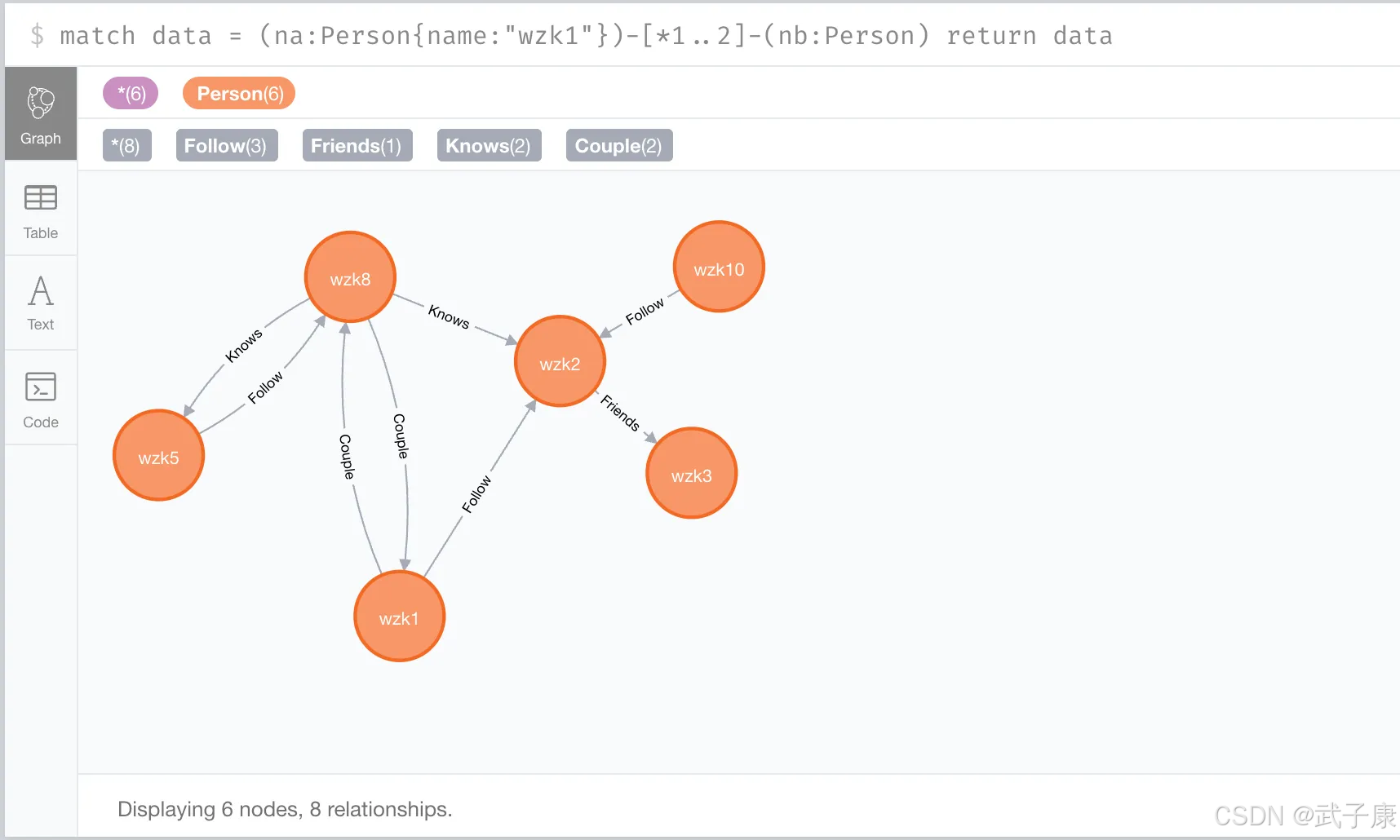
当实现多深度关系节点查询时,显然使用以上方式比较繁琐。
shell
match data = (na:Person{name:"wzk1"})-[*1..2]-(nb:Person) return data执行结果如下所示:
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接