State 状态
智能体的位置就是状态
State Space
状态的集合
Action
对每个状态来说,可能发出的行为
Action Space of a state
一个状态发出所有动作的集合。
State transition
状态变换的过程
Policy
在每个状态应该采取什么动作
tells the agent what actions to take at a state
确定性策略概率为1,随机粗略采集动作为概率和为1
Reward
采取一个动作后得到数字。
trajectory
一个状态行为回报链
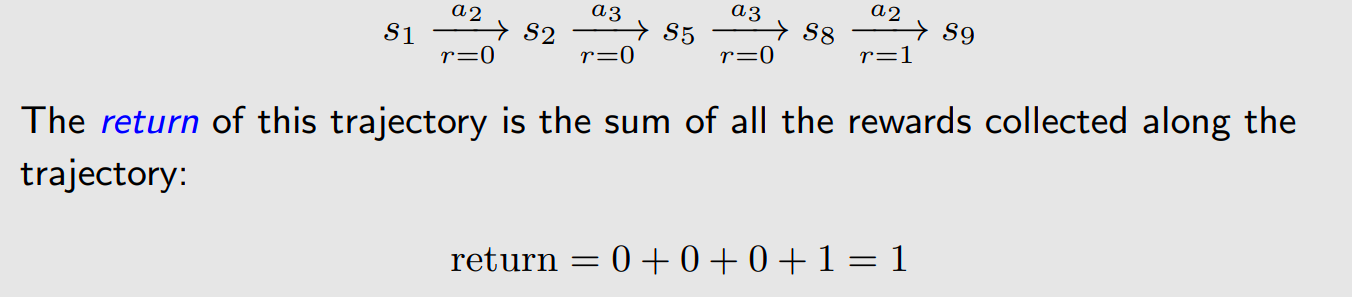
return
return 就是所有的rewards加在一起的总和。
discount return,当前的奖励r不加γ,后面乘以γ,按照次数多少进行加倍进行乘以伽马,然后所有的求和就是discount return。也就是打了折的return.
episode
有限的trajectory。
continuing tasks
无线的trajectory,一直跟环境进行交互。
MDP
Markov decision process,马尔科夫决策过程。
Sets:
- State
- Action
- Reward
Probability:
- 状态转移概率,
状态s,采取动作a,转移到s'的概率。 - 回报概率
- 状态s,采取动作a,获得回报r的概率
Policy
Markov Property
只跟上一时刻相关。
State Value
说白了就是reward的总和,带有discount的return
以上以为一个trajectory。不确定是否有限,如果有限就是episode。

按照策略π,带有discount的return总和。