什么是 MySQL?
难度:简单
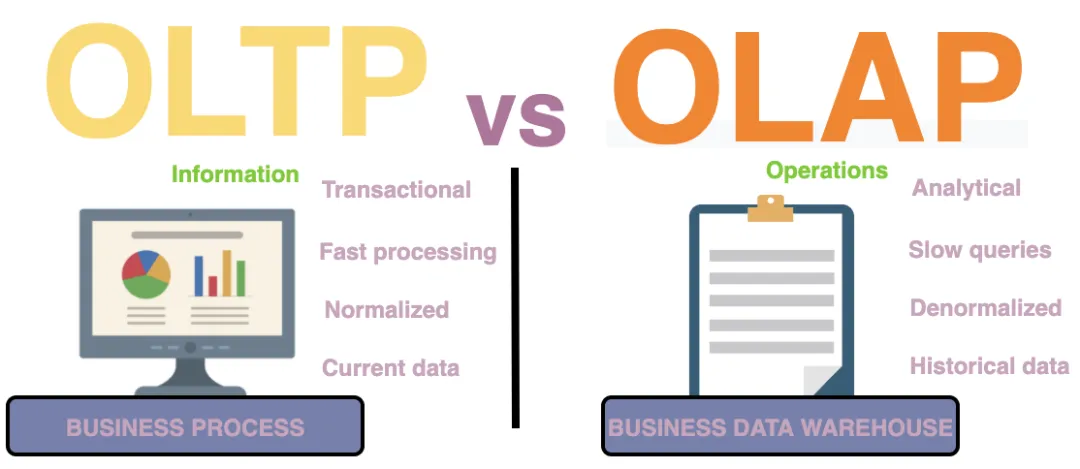
MySQL是一个传统的 RDBM 数据库 ,也就是关系型数据库 ,广泛应用于 OLTP 场景。
追问: OLTP 和 OLAP 的区别
难度:简单
OLTP(在线事务处理) 是++传统的关系型数据库++的主要应用,用于基本的、日常的事务处理,例如银行的交易记录;
而 OLAP(在线分析处理) 是++数据仓库系统++ 的主要应用,支持++复杂的分析操作++,侧重决策支持,并且提供了直观易懂的查询结果。最常见的应用就是复杂的动态报表系统。
总结下来,就是说:
- OLTP 面向日常的业务操作,强调"小、快、准"。
- 而 OLAP 面向数据分析,强调"大、重、广"。
OLTP,Online Transaction Processing,在线事务处理。
主要面向++业务系统++,比如下单、支付、库存更新这类操作。
特点是:
- 请求量大、并发高
- 每次操作很小、很快
- 强调实时性、一致性、可靠性
- 底层通常用行存储、索引优化、事务隔离等提高性能
场景就是银行转账、电商下单、App 登录这些典型业务动作。
OLAP,Online Analytical Processing,在线分析处理。
主要用于++数据分析++,比如报表、数据统计、趋势分析。
特点是:
- 查询量少,但一次查询非常重
- 更关注吞吐量与分析速度
- 对实时性要求没那么高
- 底层偏向列存储、分布式存储、批处理
场景就是 BI 报表、数据仓库、年销售分析等。
一句话总结:
- OLTP 面向业务操作,强调"小、快、准";
- OLAP 面向分析统计,强调"大、重、广"。
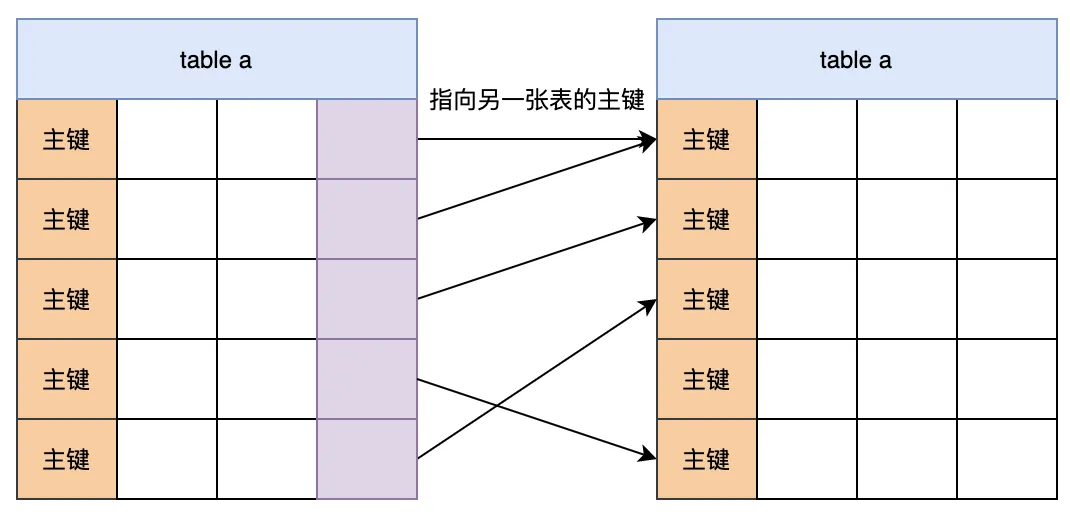
主键和外键是什么?
主键 就是++表中的一个或多个字段++ ,用来++唯一标识一条记录++,不能重复,也不能为 NULL。
外键 就是++另一张表的主键,在当前表中被引用++。
- 当前表中该字段的使用范围,取决于之前的表。
- 外键主要是用来++维护表与表之间的++ ++数据一致性++。</font
分析:
主键和外键是关系型数据库 里保证**++数据唯一性++ 和 ++关系一致性++**的两个重要概念。
- 主键(Primary Key)就是++表里的一个或多个字段++,用来唯一标识一条记录 ,不能重复,也不能为 NULL。比如学生表的
student_id字段,每个学生都有唯一 ID,用来区分不同记录。 - 外键(Foreign Key) 是指 ++另一张表的主键++在当前表中被引用 。外键的作用是++建立表与表之间的关系++ ,并++保证数据的一致性++ 。
一句话总结:
主键负责标识唯一记录;外键负责维护表与表之间的引用关系,确保数据一致性。
示例:
1)user 表(用户表)
| id(主键) | name |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
user 表中的 id 就是主键,每个用户都有唯一的 id。
2)order 表(订单表)
| order_id | user_id | amount |
|---|---|---|
| 1001 | 1 | 99 |
| 1002 | 3 | 299 |
| 1003 | 2 | 50 |
order 表中的** user_id 就是 外键**,user_id 引用了 user 表的主键 id。
order 表中 user_id 的使用范围,取决于 user 表。
++为什么要有外键?++
这个问题等价于:如果没有外键,会发生什么?
在没有外键的情况,我们往 order 表中插入:
sql
INSERT INTO order(user_id, amount)
VALUES (99999, 100);order 表中会多一条下列的记录:
| order_id | user_id | amount |
|---|---|---|
| 1004 | 9999 | 100 |
可是 user 表中根本没有 id = 9999 的人,订单找不到对应的用户,这就属于孤儿订单。
上述情况也就属于数据不一致。
而有外键的情况下,****我们往 order 表中插入:
sql
INSERT INTO order(user_id, amount)
VALUES (99999, 100);数据库就会直接报错:
go
cannot add or update a child row: a foreign key constraint fails因为 外键要求 user_id 必须在 user 表里存在。
一张表一定会有主键吗?
是的,一张表一定会有主键,用来唯一标识一行数据。
如果开发者没有手动设置主键,MySQL 的 InnoDB
引擎也会自动帮我们生成一个隐藏主键 row_id.
追问:InnoDB 是如何自动选择主键的?(3条规则)
InnoDB 自动选择主键遵循三个规则:
- 如果开发者给表手动指定了主键,那就用这个手动指定的。
- 没有指定主键,但有唯一索引,并且所有字段都非 NULL,那就用这个唯一索引当主键。
- 如果以上都没有,就自动生成一个 6 字节的
row_id作为隐藏主键。
追问: 隐藏主键是什么?
隐藏主键 就是** InnoDB 自动给你补的一个 内部行标识,用来当 聚簇索引的主键。** 当你没有主动设置主键的时候,InnoDB
也必须有一个唯一标识来组织数据页,于是它会自动生成一个看不见的主键,这就是隐藏主键。 这个字段你在表结构里看不到,但在数据页里确实存在。
追问:InnoDB 为什么必须要主键?(聚簇索引原因)
因为InnoDB 的表是按照主键顺序存储的,这是典型的聚簇索引结构 。
数据行存储在主键索引的叶子节点上,所以每一行都必须有主键作为定位依据。如果没有主键,InnoDB
根本没法构建聚簇索引,也没法在页内部快速定位记录,所以它必须选一个字段作为主键,就算开发者不设置也会自动生成。
一句话总结:InnoDB 的存储格式决定它必须要主键。
++追问:自动生成的 row_id 长什么样?++_
自动生成的 row_id 是个 6 字节(48 bit)的整数,递增生成,不会重复。 这个字段不会出现在表结构里,只存在于 InnoDB
的数据页里,用来唯一标识行。
- 不是你能看到的字段
- 不是 int,也不是 bigint
- 不会通过 SQL 直接访问
- 只在物理存储层使用
怎么查看有多少个 SQL 语句在执行?
可以用
SHOW PROCESSLIST命令来查看当前正在执行的 SQL。这个命令会列出++当前数据库里的活动线程++,包括执行中的 SQL、等待状态、连接信息等。
需要注意的是:
- 普通用户只能看到自己的线程;
- **root 或有 PROCESS 权限的用户 **才能看到所有会话的执行情况。
数据库的三大范式是什么?
第一范式: 要求所有字段都是++不可再分的原子数据项++,强调的是列的原子性,
第二范式: 要求++非主键字段必须"++ ++完全依赖++ ++"主键++ ,++而不是"++ ++部分依赖++ ++"++
第二范式主要就是为了解决"联合主键导致的部分依赖问题"。
第三范式: ++非主键字段之间不能++ ++传递依赖++ ++,也就是说非主键字段不能相互依赖++ ,++非主键字段只能++ ++直接依赖++ ++于主键字段++。
在实际开发中没必要严格遵循三大范式,而是在++性能和一致性之间++找到平衡。
分析: 数据库的三大范式
数据库的三大范式是数据库设计中常见的++规范化原则++ ,主要用于++减少冗余、避免异常更新、提升数据一致性++。
第一范式(1NF)------字段必须不可再分(原子性)
核心要求:
- 每个字段必须是不可再拆分的最小数据项。
- 即字段值不能再继续拆成多个部分。
示例:
| 学号 | 姓名 | 性别 | 出生年月日 |
|---|
"出生年月日"如果还能拆成++出生年++ 、++出生月++ 、++出生日++ → 违反 1NF。
**如何满足 1NF?**拆成:出生年、出生月、出生日。
第二范式(2NF)------非主键字段必须"完全依赖"主键,而不是"部分依赖"
第二范式就是为了解决"联合主键导致的部分依赖问题"的。
示例:
| 学号 | 课程号 | 姓名 | 学分 |
|---|
这张表的使用的是联合主键,主键 =(学号,课程号)
**为什么要设置联合主键? **
因为:
- 一个学生可以选多门课
- 一门课也可以被很多学生选
因此要唯一标识一条"学生选课关系",必须用:
同一个"学号 + 课程号"组合,才能唯一标识一条记录。
上面的这个表不符合 2NF,因为:
- "姓名"只依赖"学号",不依赖"课程号",即不依赖整个主键。
- "学分"只依赖"课程号",不依赖"学名",即不依赖整个主键。
正确做法------拆表,将上述表拆成三张表:
表1:学生表(Student)
| 学号 | 姓名 |
|---|
表2:课程表(Course)
| 课程号 | 学分 |
|---|
表3:选课关系表(StudentCourse)
| 学号 | 课程号 |
|---|
第三范式(3NF)------非主键字段之间不能存在传递依赖
√ 正确的依赖关系:直接依赖 ,就是++非主键只依赖主键++ ;
× 错误的依赖关系:传递依赖,非主键不是直接依赖主键,而是依赖另一个非主键,"绕了一圈"最后依赖关系才传递到主键。
示例:
| 学号(A) | 姓名 | 年龄 | 所在学院(B) | 学院电话© |
|---|
传递关系是:学号A → 所在学院B → 学院电话C
C 不是直接依赖 A,是通过 B 间接依赖 A → 这就是传递依赖 → 违反第三范式
如何改?
拆成两张表:
1)学生:学号、姓名、年龄、所在学院
2)学院:学院名、学院电话
三范式总结表
| 范式 | 存在问题 | 解决问题 |
|---|---|---|
| 1NF | 字段可再拆 | 字段要原子化 |
| 2NF | 部分依赖 | 非主键字段必须完全依赖主键 |
| 3NF | 传递依赖 | 非主键字段不能依赖其他非主键字段 |
💡注意:范式判断是++设计层面的逻辑++,数据库不能自动推断是否违反了三大范式。
因为数据库无法知道:
- 哪个字段是"业务上"的主键
- 哪些字段"业务上"应该依赖谁
- 哪些字段"业务上"有计算关系
追问1:范式设计是为了解决什么问题?
数据库范式的目的,是为了解决几类典型的数据问题:
- 数据冗余------避免同一份数据被重复存多次,浪费空间,也容易产生不一致。
- 数据不一致(更新异常)------当同一份信息存多处、更新时只改了一部分,就会出现数据不一致的问题;范式化通过拆分表来保证更新一致性。
- 插入异常------某些字段因为结构不合理导致必须填冗余字段,否则插不进去;范式避免这种情况。
- 删除异常------删除一条记录时可能误删其他重要信息;范式通过拆分相关数据避免级联丢失。
简单说,范式就是通过减少冗余、消除依赖,保证数据的一致性、完整性和可维护性。
追问2:范式设计有什么缺点?
范式化的确能减少冗余、保持数据一致性,但它也有明显的缺点。 因为范式会把数据拆成多个表,所以很多查询都需要做 联表查询(JOIN),
这在实际业务中成本很高:查询慢、索引利用率低,而且联表查询很不适合做 分库分表,会让架构复杂度增加。
所以在真实项目里,很多时候我们会做
反范式设计。也就是说,适当冗余一些字段,让查询直接在单表内完成,避免大量的联表查询,提高性能和可扩展性。所以,在实际开发中,++性能和一致性需要平衡,而不是盲目追求范式化++。
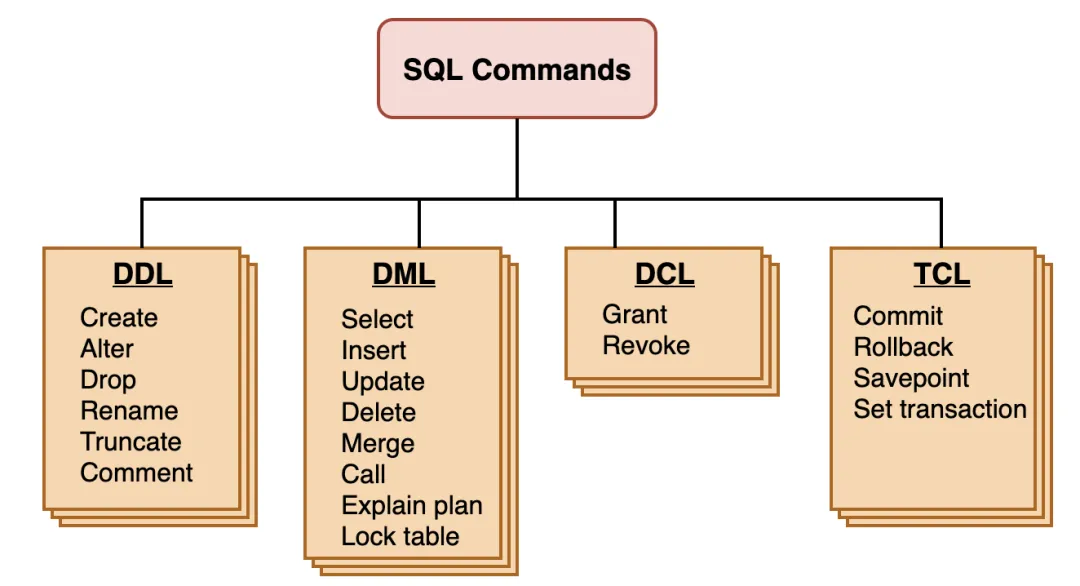
DDL、DML、DDL、DCL 分别是什么?
分析:以上三个问题,是针对数据库操作分类的考察。我们不能只知道增删查改,还要知道它们属于哪类。
从事务的角度来看,数据库的操作主要分成四类:
DDL(Data Definition Language)数据定义语言,
- 用来++定义数据库对象++,比如创建数据库、创建表、删除表等。
DML(Data Manipulation Language)数据操作语言
- 用来++对表里的数据进行++增删改++++
DQL(Data Query Language)数据查询语言
- 用来++查询数据++ ,比如我们最常写的
SELECT。DCL(Data Control Language)数据控制语言
- 用来++控制数据库用户的权限++,比如创建用户、授权用户、回收权限。
- 比如:
GRANT、REVOKE总结: DDL 管结构、DML 改数据、DQL 查数据、DCL管权限。