方案1:将杂波数据分为16段分别进行存储,当接收到脉冲信号后,利用FIR滤波器实现卷积,再将多各段数据进行延时存储,进行数据的叠加输出。
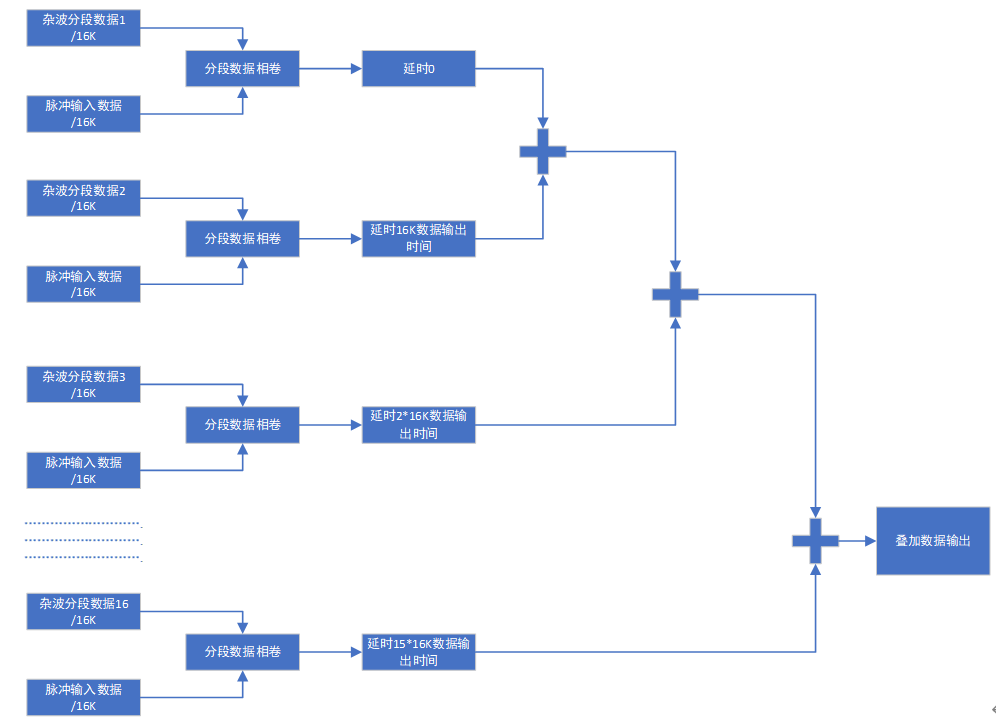
优点:速度快,从接收到信号后,经过1/fs*16k时间后就能输出第一个有效数据,能在1ms内将所有叠加后的信号输出。
缺点:使用FIR架构使用DSP资源多,需多块FPGA并行工作。并且是复数卷积,需要在上面的资源上增加4倍。
方案2:将杂波数据分为16段,在上位机补足32K做FFT,将生成好的数据分别存储在ROM中,当接收到脉冲信号后,将数据扩展成32K做FFT,当FFT数据输出时分别与存储在ROM中的杂波数据进行点乘,点乘之后再做IFFT,之后将各段数据进行存储,再能过延时模块将数据叠加输出。
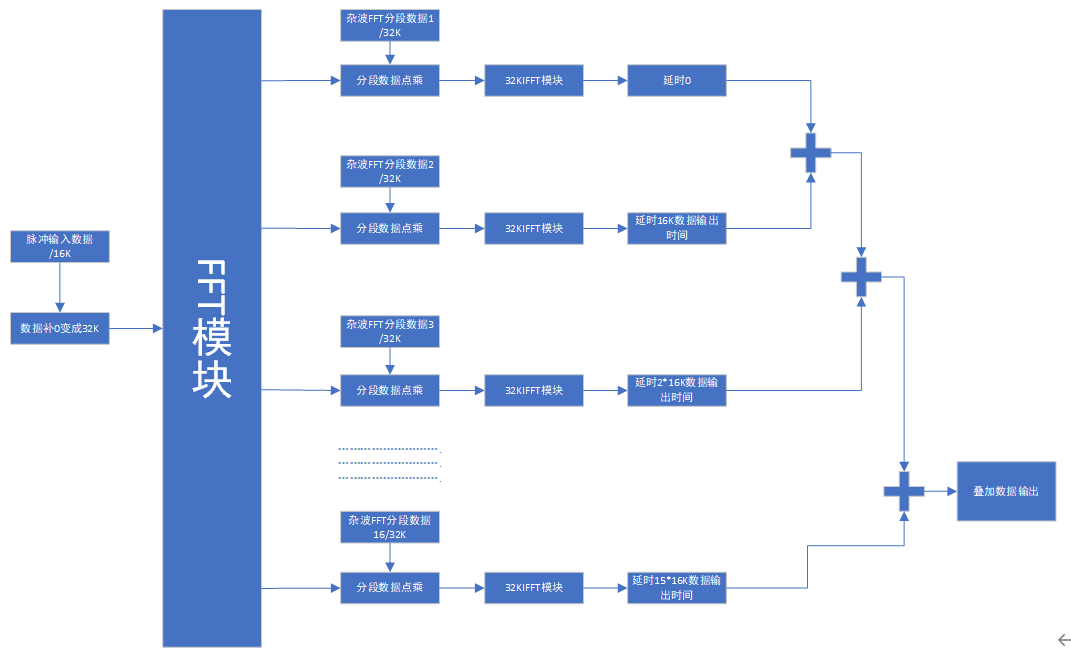
优点:将接收到的信号转换成频域计算,可节省大量的DPS资源,
缺点:使用FFT及IFFT使用RAM资源多,并且输出第一个数据的沿时是在FFT和IFF后,按32k的流水型FFT设计,第一个数据需要在500us后才能输出,不能在1ms内将所有叠加后的信号输出。并且同时使用16路32k的IFFT资源不够。
方案3:将杂波数据分为16段,在上位机补足32K做FFT,将生成好的数据分别存储在ROM中,当接收到脉冲信号后,将数据扩展成32K做FFT,当FFT数据输出时分两路处理,第一路与预存在本地256k的FFT数据的第一段和FFT输出的数据时序一样,送入频域卷积模块的乒部分进行卷积,同时也将FFT后的数据存入到2个16k的存储空间,当存入16k数据后,将剩余的数据存入另一个16k的数据存储空间,同时将存入的第1个16k的数据读出来与频域卷积模块的乓部分进行卷积
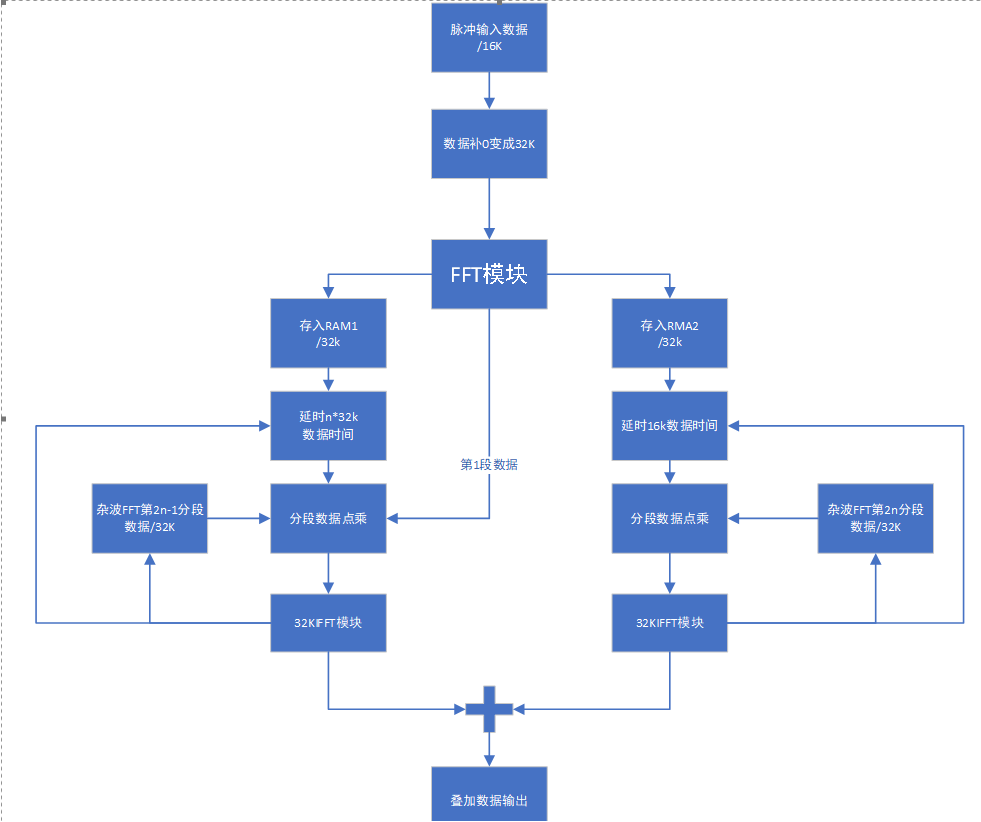
当乓模块在第1个16k数据读完时,也就是做完16k点时,这时频域卷积模块的乒部分刚好做完,又重新开始读第一个16k区域的数据,进行第二次卷积运算,当乓模块在第1个32k数据读完时,乒模块又刚好做到一半,因此将乒乓频域卷积模块的卷积数据可直接进行叠加,依次输出。输出数据流如下图所示:
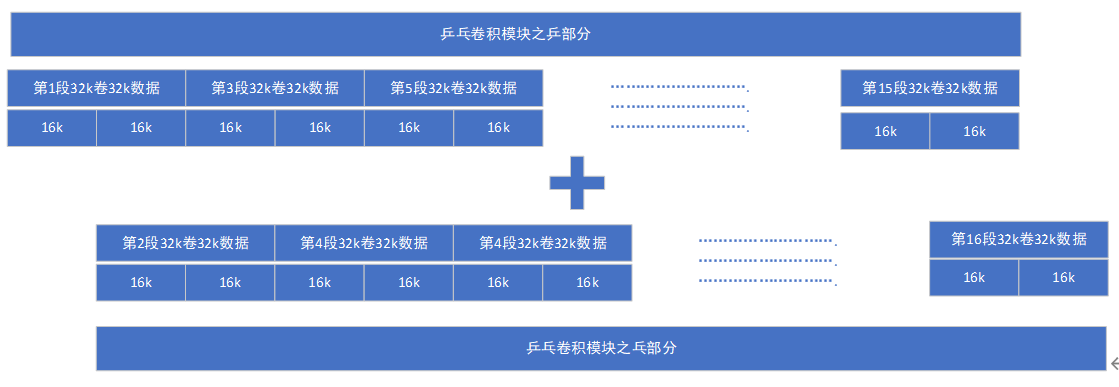
优点:将接收到的信号转换成频域计算,可节省大量的DPS资源,并使用乒乓操作分时进行卷积节约资源,并且用这种方式后续可考虑将256的FFT数据存储在PS端。
缺点:不能在1ms内将所有叠加后的信号输出。
1/300*(256+16)=0.9067
首先存储256k的16bit位宽卷积数据需要BRAM的个数为:
15*2*16=480个
15------(32k的16位数据)
2------IQ数据
16------共分为16段(256k/16k)
原始数据16k需转换成32k的数据做FFT,需要BRAM的个数为:
105个
原始数据做完FFT后的数据需要存储进行乒乓卷积运算,需要BRAM的个数为:
57*2=104个
卷积后的数据需使用32768点的IFFT转换成时域的数据,需要BRAM的个数为:
98*2=196个
RF47DR总共的RAM有1080个,卷积模块现计共使用
480+105+104+196=885个,约占资源总数82%。
成都荣鑫科技原创内容,欢迎技术交流及合作,盗者必追究