23 Decision Trees
23.1 Decision Tree Model
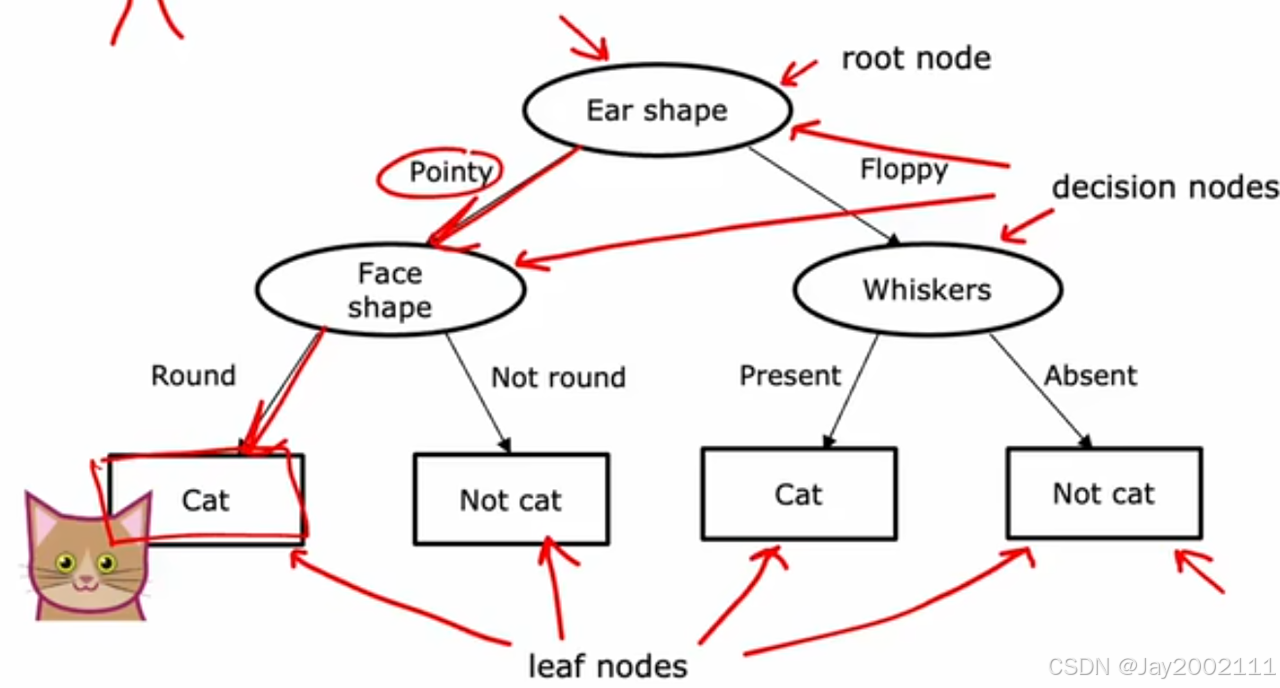
除了叶子节点,其他节点称为决策节点
23.2 Learning Process
- 如何选择在每个决策节点上,用哪一个特征来划分?
最大化纯度(Purity),之后会介绍 - 什么时候停止划分?
- 当某个节点已经完全是一类
- 设置最大深度(防止资源超限,并且较小的模型可以缓解过拟合问题)
- 纯度的提高低于某个阈值,或者划分甚至降低了纯度
- 当某个节点的样本数量已经很少了,低于某个设置的阈值
24 Decision Tree Learning
24.1 Measuring Purity
定义p1p_1p1为某个类别在样本中的比例
熵(Entropy)为H(p1)H(p_1)H(p1):
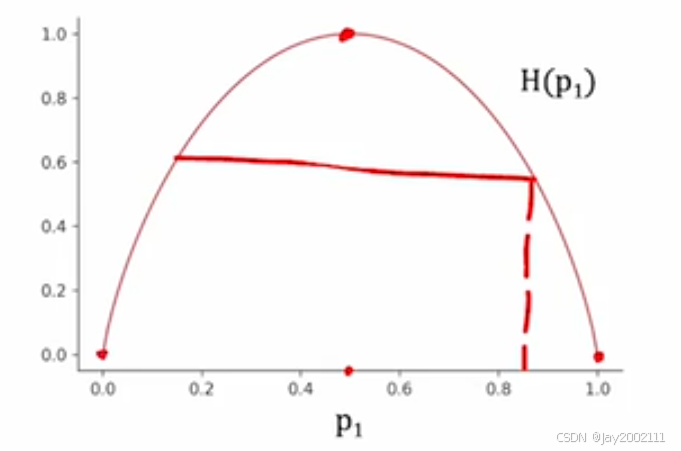
在p1=0.5p_1=0.5p1=0.5时,熵最大为1
熵的公式:
H(p1)=−p1log2(p1)−p0log2(p0)=−p1log2(p1)−(1−p1)log2(1−p1)\begin{aligned} H(p_1) &= -p_1log_2(p_1)-p_0log_2(p_0) \\ &=-p_1log_2(p_1)-(1-p_1)log_2(1-p_1) \end{aligned}H(p1)=−p1log2(p1)−p0log2(p0)=−p1log2(p1)−(1−p1)log2(1−p1)
注:
- 通常取以2为底数的对数,画出来的函数峰值为1
- 这里定义0log(0)=00log(0)=00log(0)=0
- 熵函数用来衡量不纯度(impurity)
- 还有Gini函数等衡量不纯度的函数
- 这里的熵实际上是香农定义的信息熵
24.2 Choosing a Split: Information Gain 选择split:信息增益
熵的减少被称为信息增益(Information Gain)
选择某个特征,split之后,可以算出左分支和右分支的熵
但是,不仅要考虑左右熵的大小,也要考虑左右分支中样本的数量。数量更多的那一边,熵的权重应该更大更期望被减小
由此,合二为一,计算加权平均熵值,例如左分支数量为n1n_1n1,熵为H1H_1H1,左分支数量为n2n_2n2,熵为H2H_2H2,加权平均熵值n1n1+n2⋅H1+n2n1+n2⋅H2\frac {n_1} {n_1+n_2} \cdot H_1 + \frac {n_2} {n_1+n_2} \cdot H_2n1+n2n1⋅H1+n1+n2n2⋅H2
但在实践中,我们不是计算加权平均熵值,而是相比于没有split之前的熵值减少量:
Hbefore split−(n1n1+n2⋅H1+n2n1+n2⋅H2)H_{\text{before split}} - (\frac {n_1} {n_1+n_2} \cdot H_1 + \frac {n_2} {n_1+n_2} \cdot H_2)Hbefore split−(n1+n2n1⋅H1+n1+n2n2⋅H2)
注:决定要不要继续split看熵的减小量
我们记wleft=n1n1+n2w^{\text{left}}=\frac {n_1} {n_1+n_2}wleft=n1+n2n1,wright=n2n1+n2w^{\text{right}}=\frac {n_2} {n_1+n_2}wright=n1+n2n2,信息增益公式:
Information Gain=H(p1root)−(wleft⋅H(p1left)+wright⋅H(p1right))\text{Information Gain} = H(p_1^{\text{root}}) - (w^{\text{left}} \cdot H(p_1^{\text{left}}) + w^{\text{right}} \cdot H(p_1^{\text{right}}))Information Gain=H(p1root)−(wleft⋅H(p1left)+wright⋅H(p1right))
最终选择可以让信息增益最大的那个特征作为split标准
24.3 Putting It Together
整体流程(递归):
- 从根节点开始
- 计算所有可能的特征作为split标准的信息增益
- 选择最大的,进行split,创建左右分支
- 重复过程直到达到终止条件:
- 节点里的样本全是一类(熵为0)
- 超过阈值深度
- 信息增益小于阈值
- 样本数量小于阈值
24.4 Using One-shot Encoding of Categorical Features
如果某个特征的取值多于2个离散值(多值特征)怎么办 --> 独热编码(当然也可以采用多分支的方法)
如果出现一个特征可能取k种值,那么就用k个二元特征去替代,用0/1来表示进行编码,最终可以发现每种取值的有且仅有一个二元特征取值为1,这就是独热编码名字的由来
注:独热编码的思想不仅适用于决策树,也适用于神经网络
24.5 Continuous Valued Features
如果特征取值不是若干个离散值,而是连续值,应该如何处理
设置一个阈值,大于等于该阈值和小于该阈值可以分为两类,即可计算信息增益
尝试不同的阈值,获得最大的信息增益
24.6 Regression Trees
回归树:决策树的推广,将分类算法泛化成回归算法
在这个场景下,我们用平均值当做某个节点的预测值,然后计算方差,用方差去衡量纯度
之后计算加权平均方差,然后计算方差减少量,即为信息增益:
Information Gain=Vroot−(wleft⋅Vleft+wright⋅Vright)\text {Information Gain} = V^{\text{root}}-(w^{\text{left}} \cdot V^{\text{left}} + w^{\text{right}} \cdot V^{\text{right}})Information Gain=Vroot−(wleft⋅Vleft+wright⋅Vright)
其中VVV为方差
25 Decision Tree Ensembles 决策树的集成
25.1 Using Multiple Decision Trees
使用单一的决策树可能对微小的变化敏感
使用多个决策树,被称为树集成(Tree Ensemble)
预测时,将多个决策树的预测结果进行投票,选择最多的预测值作为最终预测值
25.2 Sampling with Replacement 放回抽样
在已有训练集中,随机抽取,再放回,再随机抽取,这样放回抽样,得到一个新的训练集
注:新的训练集中可能有重复,也有可能有原始训练集中的数据没有取到,都很正常
25.3 Random Forest Algorithm
随机森林(Random Forest)算法是一种强大的树集成算法
Bagged Decision Tree(袋装决策树,装袋法+决策树):通过放回抽样得到的多个新数据集,训练B个决策树,,B的典型取值在64-128之间,更大的值可能有边际效应,浪费资源且模型效果不会有太大提升。最终由B个决策树投票决定预测值
随机森林算法是在袋装决策树的基础上,继续引入随机性:袋装决策树的B个树中,常常会出现根节点或根节点附近的节点的采用了相同的特征进行split,随机森林算法的核心思路是,假设有n个特征,定义k<nk<nk<n,每次从n个特征中随机选k个特征,节点的划分只能在这k个特征中选择信息增益最大的特征作为依据,而不是所有n个特征。
注:
- 随机森林算法适用于特征数量较大的数据集
- k的常用取值为k=nk=\sqrt{n}k=n
25.4 XGBoost
XGBoost(eXtreme Gradient Boosting,极端梯度提升)是目前最常用的决策树/树集成算法
核心思想:"刻意练习",袋装决策树和随机森林算法是每次等概率地放回抽样,而我们可以将那些在之前构建的决策树中预测效果不好的样本,加大他们的被抽取的概率
- 开源,高效
- 提供了默认的split和停止split的条件
- 内置正则化,缓解过拟合
- 会自动为不同的训练样本分配不同权重,所以实际上不需要生成大量随机选择的数据集,比放回采样更高效
注:XGBoost的效果很出众,很多比赛的优胜算法是XGBoost或深度学习
XGBoost的实现很复杂,大多数时候直接调用开源库实现。
将XGBoost用于分类任务:
python
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)将XGBoost用于回归任务:
python
from xgboost import XGBRegresser
model = XGBRegresser()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)25.5 When to Use Decision Trees
什么时候选择神经网络,什么时候选择决策树呢?
决策树/树集成算法:
- 擅长处理结构化数据 (换言之,可以存在电子表格里的数据,例如房价预测,每个特征和对应房价可以列在一个巨大的表格里)
- 对于文本、音频、图像、视频等非结构化数据,决策树通常表现不佳
- 训练速度非常快
- 可解释性更强,尤其是小型的单个决策树,可以直观地看到决策过程
神经网络:
- 几乎在所有类型的数据上都表现良好,包括结构化数据、非结构化数据、结构化和非结构化混合型数据
- 训练速度较慢
- 可以迁移学习,是神经网络的一大优势
- 多个神经网络可以很方便地串联 ,构成更大的机器学习系统,可以一起用梯度下降训练串联起来的所有神经网络