文章目录
- 【1】背景与动机:发现问题与解决问题
-
- [1.1 面临的问题](#1.1 面临的问题)
- [1.2 本文的贡献](#1.2 本文的贡献)
- [【2】 数据集介绍](#【2】 数据集介绍)
- [【3】 模型架构](#【3】 模型架构)
-
- [3.1 总体设计思想:双流架构](#3.1 总体设计思想:双流架构)
- [3.2 单流内部结构](#3.2 单流内部结构)
-
- [A. 瓶颈层编码器](#A. 瓶颈层编码器)
- [B. 动态特征增强 ( Δ \Delta Δ and Δ Δ \Delta\Delta ΔΔ Features)](#B. 动态特征增强 ( Δ \Delta Δ and Δ Δ \Delta\Delta ΔΔ Features))
- [C. 时序建模 (LSTM)](#C. 时序建模 (LSTM))
- [3.3 融合与分类](#3.3 融合与分类)
- [【4】 实验设置与训练策略](#【4】 实验设置与训练策略)
-
- [4.1 数据预处理](#4.1 数据预处理)
- [4.2 关键训练技巧](#4.2 关键训练技巧)
- [4.3 架构有效性验证](#4.3 架构有效性验证)
原文标题 :End-to-End Visual Speech Recognition with LSTMs
发表年份 :2017
核心思想:如何显式地让网络同时关注唇部的"形状"和"运动",实现从像素到语义的端到端识别。
【1】背景与动机:发现问题与解决问题
1.1 面临的问题
- 传统方法 :
- 流程:分为两阶段,先进行人工特征提取(如 DCT,离散余弦变换),再使用动态分类器(如 HMM 或 LSTM)进行分类。
- 局限:依赖手工设计的特征,泛化能力弱。
- 早期深度学习方法(两阶段法) :
- 流程 :利用深度网络提取瓶颈特征,再送入分类器。
- 手段 :提取瓶颈特征有两类方法,一类是对嘴部 ROI 降维(PCA/LBP)后由深度自动编码器压缩;另一类是直接从像素提取特征。
- 痛点 :特征提取 和分类是分开训练的,无法进行端到端的联合优化 。
- 端到端方法的空白 :
- 当时仅有 Wand et al.尝试过端到端唇读系统,但未能超越当时的 SOTA。【Audio-visual speech recognition using deep learning】
1.2 本文的贡献
针对上述痛点,本文做出了以下贡献:
- 首创性 :提出了首个从原始像素直接到分类结果的端到端 (End-to-End) 视觉语音识别模型。
- 联合学习:模型能够同时学习"如何提取特征"和"如何进行分类" 。
- 性能突破:在 OuluVS2 和 CUAVE 公开数据集上达到了最先进性能 (SOTA) 。
【2】 数据集介绍
为了验证模型的有效性,使用了两个公开数据集:
- OuluVS2 数据库 :
- 规模:包含 52 位说话者。
- 内容:每人说 10 个日常短语(如 "Excuse me", "Goodbye"),每句话重复 3 次。
- CUAVE 数据库 :
- 规模:包含 36 个受试者。
- 内容:每个人说出数字 0 到 9,每个数字重复 5 次,总计每个数字有 180 个样本。
【3】 模型架构
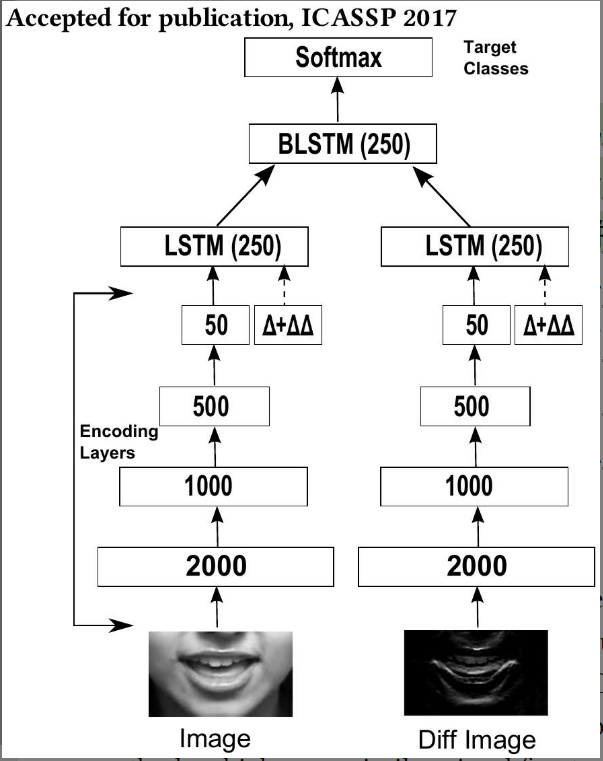
3.1 总体设计思想:双流架构
本文模型的核心在于设计了两条独立的并行处理流,分别捕捉静态信息和动态变化,最后进行融合。
- 静态流 :
- 输入:原始嘴部感兴趣区域。
- 作用 :主要编码静态信息,即嘴巴在当前帧的形状、张开程度等外观特征。
- 动态流 :
- 输入:差分图像 (Diff Image),即当前帧与上一帧的像素差。
- 作用 :主要编码局部时间动态,捕捉嘴部运动的细微变化。
3.2 单流内部结构
每一条流内部都遵循"特征压缩 -> 动态补充 -> 时序建模"的流程:
A. 瓶颈层编码器
-
结构:采用深度全连接网络,层级节点数递减(2000 -> 1000 -> 500),最后接一个线性的瓶颈层。
- 前三层:是非线性的(使用 Sigmoid 激活函数)。
- 最后一层 (瓶颈层) :是线性的,直接输出实数特征。
-
目的:将高维输入(像素级)强制压缩为低维表示。
-
RBM 初始化:
使用了 受限玻尔兹曼机 (RBMs) 进行贪婪的逐层预训练。
AT Note: 虽然 RBM 现在用得少了,但在当时,它是帮助深层网络找到良好初始参数、避免局部最优的关键"热身"手段。
B. 动态特征增强 ( Δ \Delta Δ and Δ Δ \Delta\Delta ΔΔ Features)
为了强化对运动轨迹的理解,作者在瓶颈层特征后显式拼接了:
- 一阶特征 ( Δ \Delta Δ):特征的变化率(速度)。
- 二阶特征 ( Δ Δ \Delta\Delta ΔΔ):变化率的变化率(加速度)。
这两个特征被直接计算并附加到瓶颈层,强迫编码层学习那些能产生良好动态特性的特征。
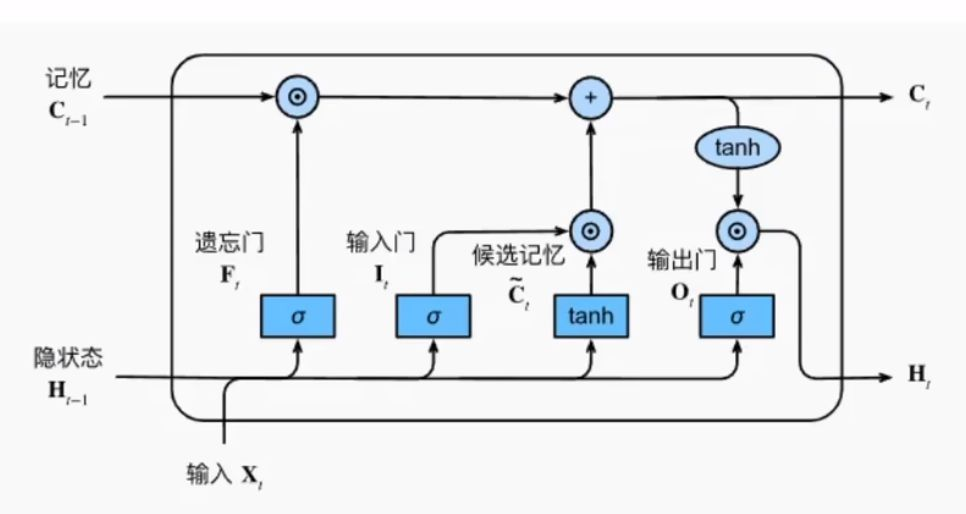
C. 时序建模 (LSTM)
在编码层之上,每个流各接一个 LSTM 层。LSTM 负责处理特征在时间维度上的演变,每一时刻都输出对应的隐藏状态 。(LSTM架构如下图所示)
3.3 融合与分类
-
融合机制:
将两个流(静态流 + 动态流)的 LSTM 输出在特征维度 上进行连接。
AT : 注意,这里拼接的是特征向量,时间序列的长度(帧数)保持不变。
-
全局推断:
连接后的向量输入到一个双向 LSTM 中。
优势:BLSTM 能同时利用"过去"和"未来"的上下文信息,对整个序列进行综合判断。 -
输出与决策策略:
结构上 :输出层是 Softmax,它为每一个输入帧都提供一个标签 。
训练上 :在计算 Loss 和最终分类时,只使用每个话语最后一帧的标签来标记整个话语。
AT Note: 这是一个关键点!虽然每帧都有输出,但模型认为读到最后一帧时,积累的信息最全,决策最准。
【4】 实验设置与训练策略
4.1 数据预处理
为了消除个体差异并适应网络需求,预处理分为两步:
- 去受试者特征 :
- 对象:整个话语。
- 做法:计算整句话的"平均图像",每一帧减去该均值 。
- 目的:消除"长相"差异(如脸型、肤色),只保留相对于平均脸的动作变化。
- 数据标准化 :
- 对象:每一张单独的图像。
- 做法:将像素值标准化为均值0、方差1。
- 目的:满足 RBM 线性输入单元的训练要求,防止网络难以收敛 。
4.2 关键训练技巧
本文采用了一系列组合拳来稳定深层网络的训练:
1.RBM 初始化类型:
- 第一层(输入为像素实数):使用 Gaussian-Bernoulli RBM。(高斯-伯努利RBM)
- 中间层(因为隐藏层神经元使用 Sigmoid 激活函数,输出在 0-1 之间):使用 Bernoulli-Bernoulli RBM。(伯努利-伯努利RBM)
- 瓶颈层(线性输出):使用 Bernoulli-Gaussian RBM。(高斯-伯努利RBM)
2.优化器 :使用 AdaDelta 算法,自动调整学习率。
3.梯度裁剪 (Gradient Clipping):应用于 LSTM 层,防止梯度爆炸。
4.3 架构有效性验证
实验结论 :单独使用"静态流"或"动态流"均优于传统基线,但双流融合模型 (Two-Stream) 的性能显著优于任何单流模型。
核心启示 :证明了静态外观特征与动态运动特征具有互补性,联合学习是提升性能的关键。
总结
这篇文章是端到端唇读领域的经典之作。它利用双流架构 (Raw + Diff)结合 LSTM/BLSTM ,在 2017 年就实现了从像素到语义的端到端识别。对于后续研究,其最大的借鉴意义在于:如何显式地让网络同时关注"形状"和"运动"。