参考:Qwen2.5 源码解读
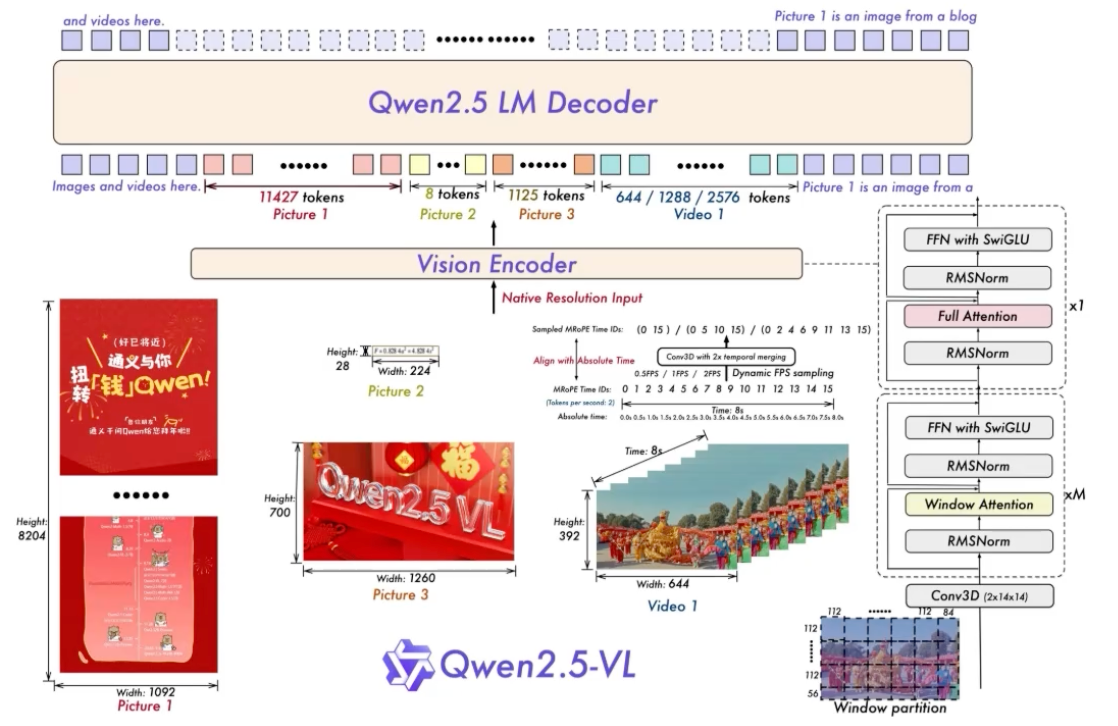
一. 数据处理
1. 图像预处理
1 . 动态分辨率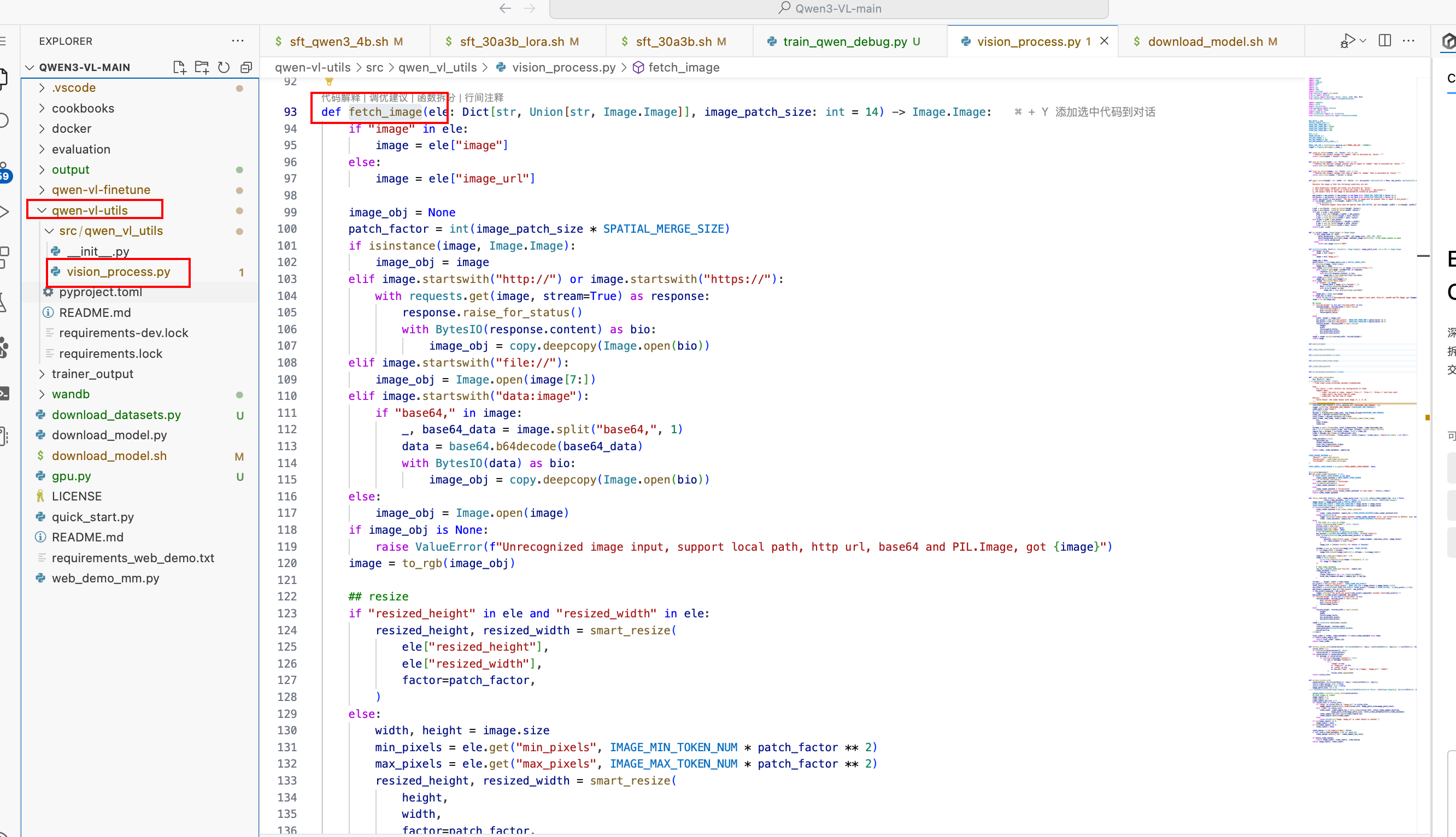
2 . 切分patch/ 归一化

具体分patch的过程如下:
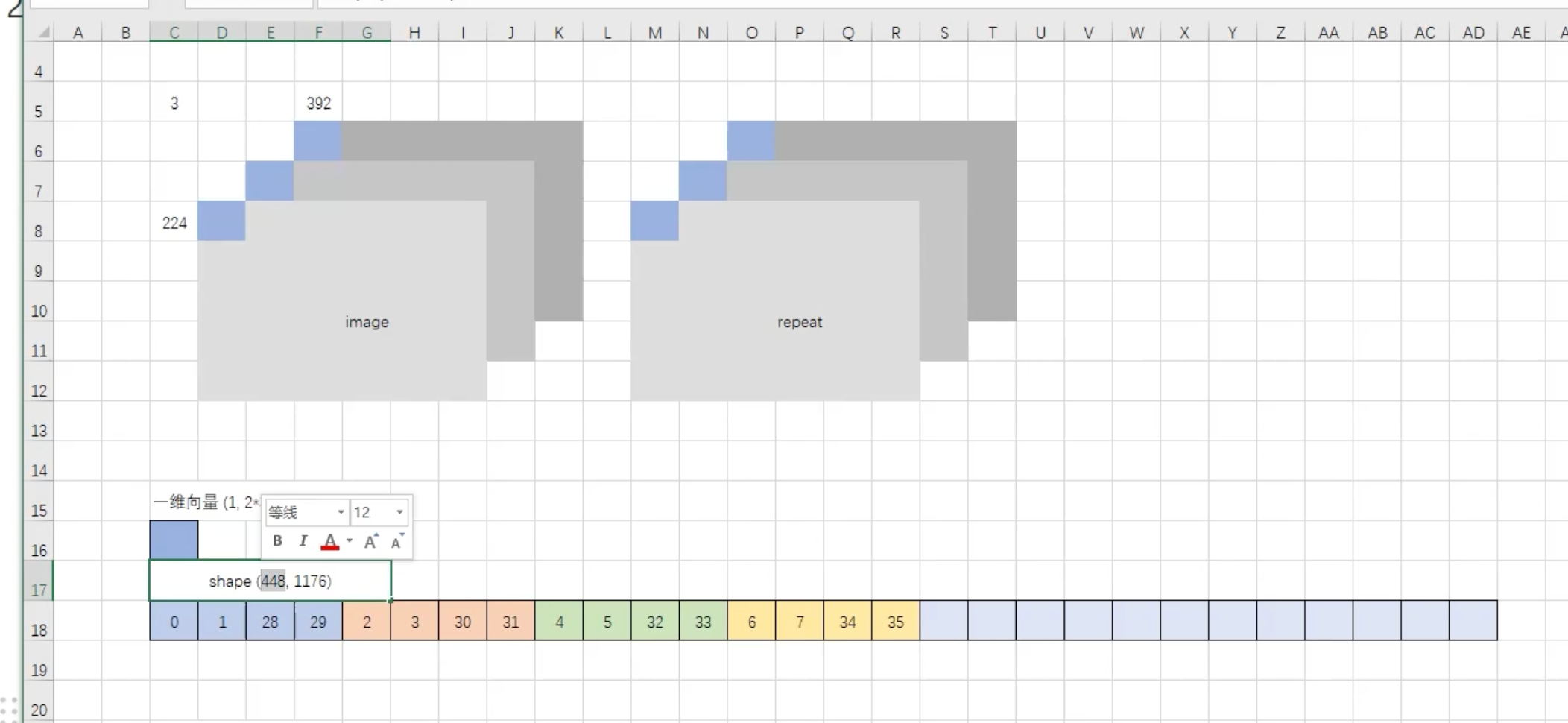
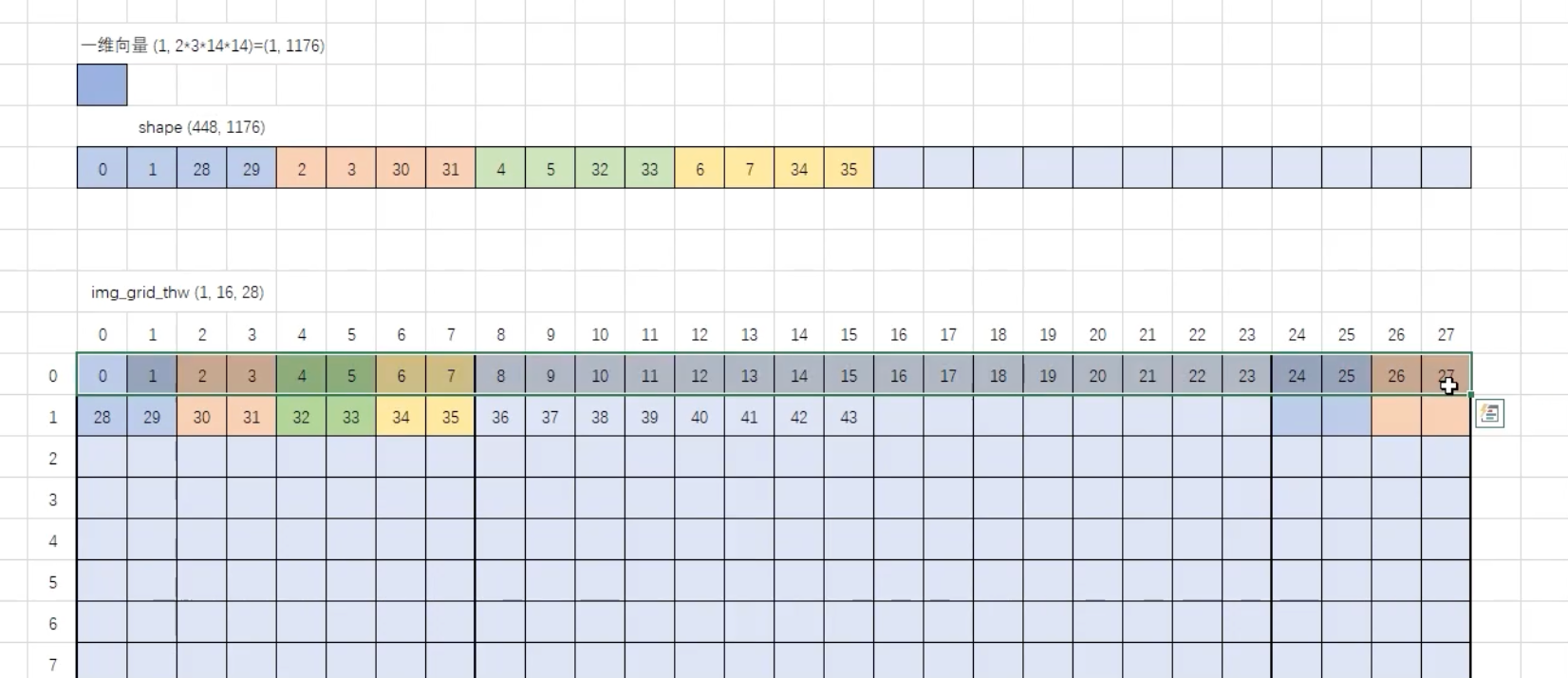
代码: 通过调用该类的 call方法 调用preprocess方法
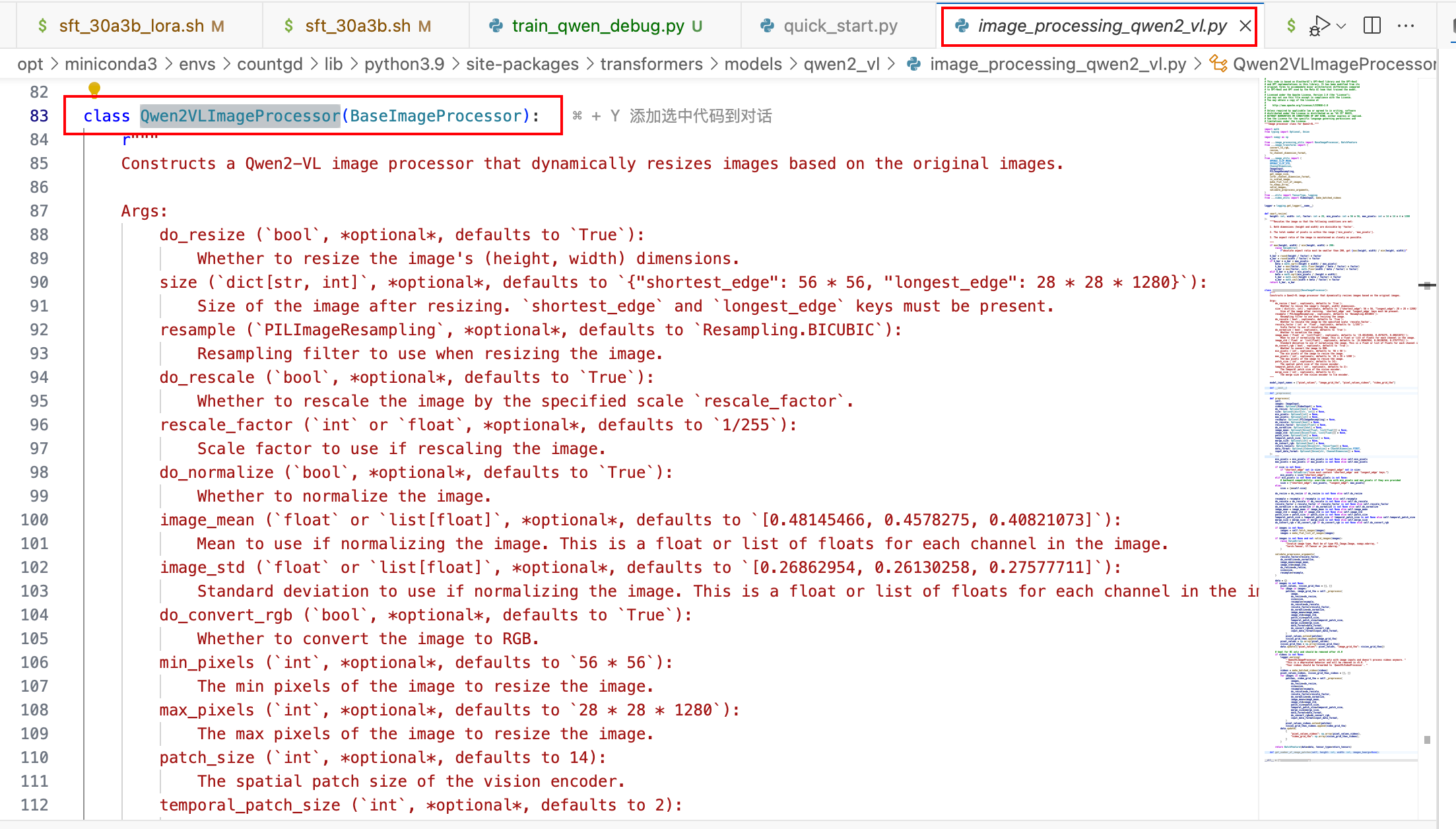
2. 视频预处理
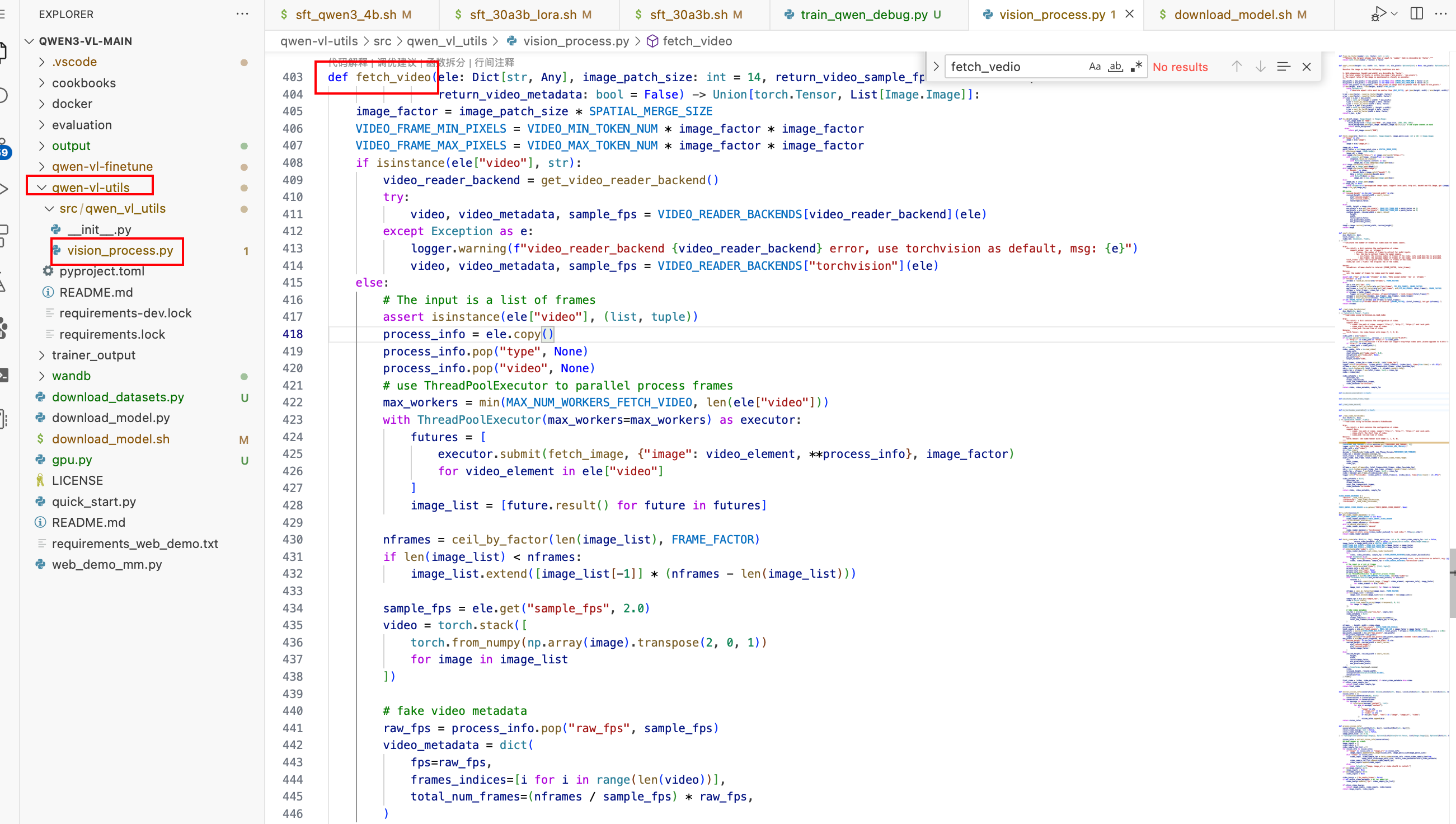
3. 文本预处理
- 套用模版,转换成一定的格式
- 分词器进行分词,转为token id的形式
模版化
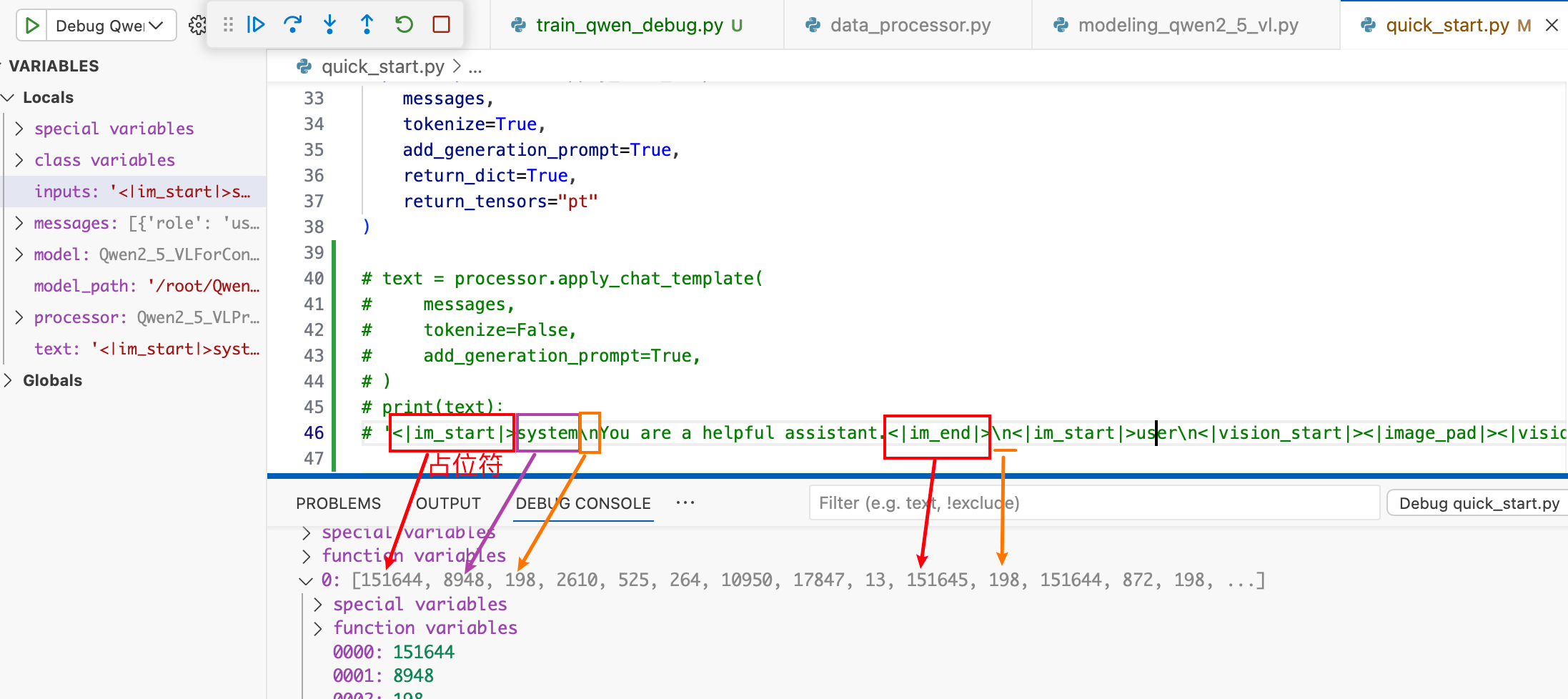
分词器分词
上述函数中的 tokenize = True , 即进行分词
二. ViT (视觉Embedding)
流程

对应的是下面的红框中的模块
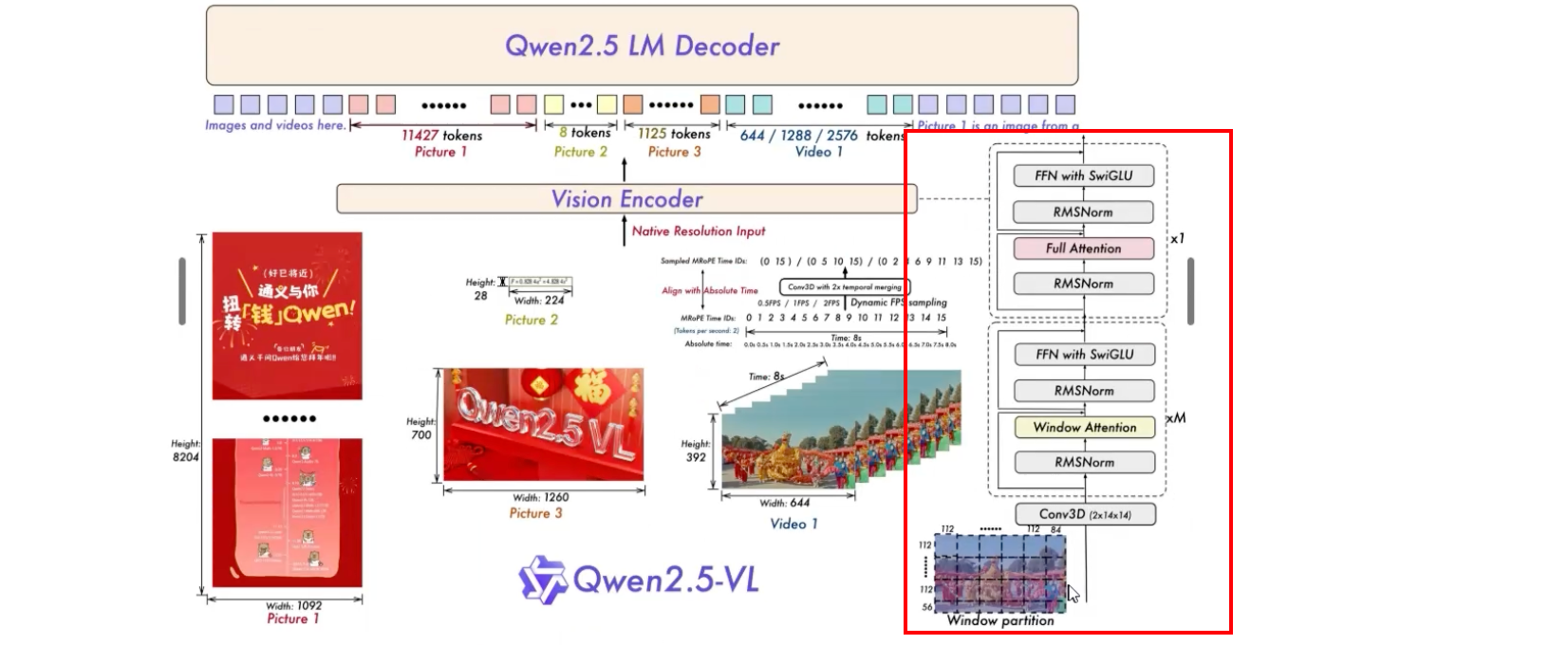
类名:Qwen2_5_VisionTransformerPretrainedModel
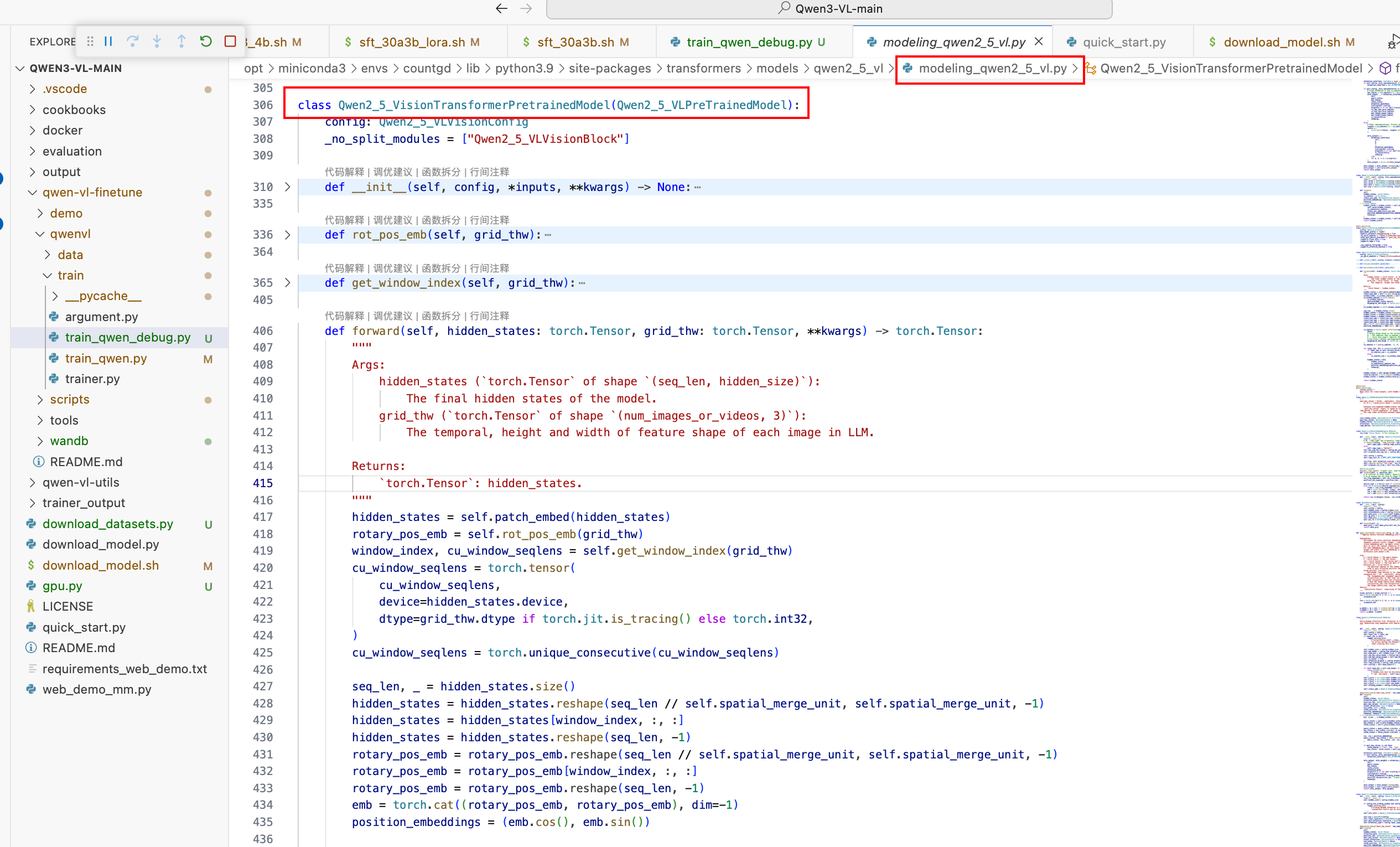
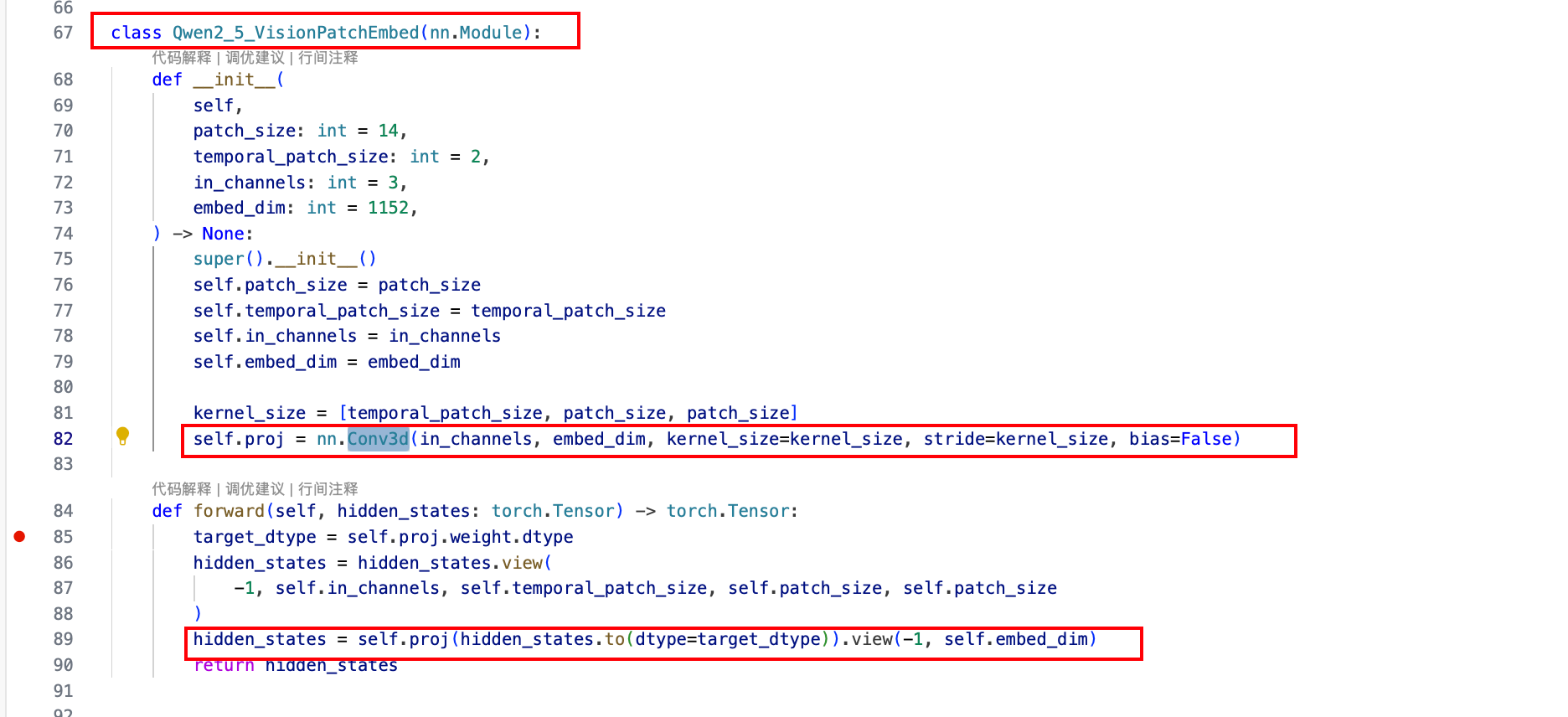
1 . Conv3D (PatchEmbed)
卷积核大小为 2 * 14 * 14
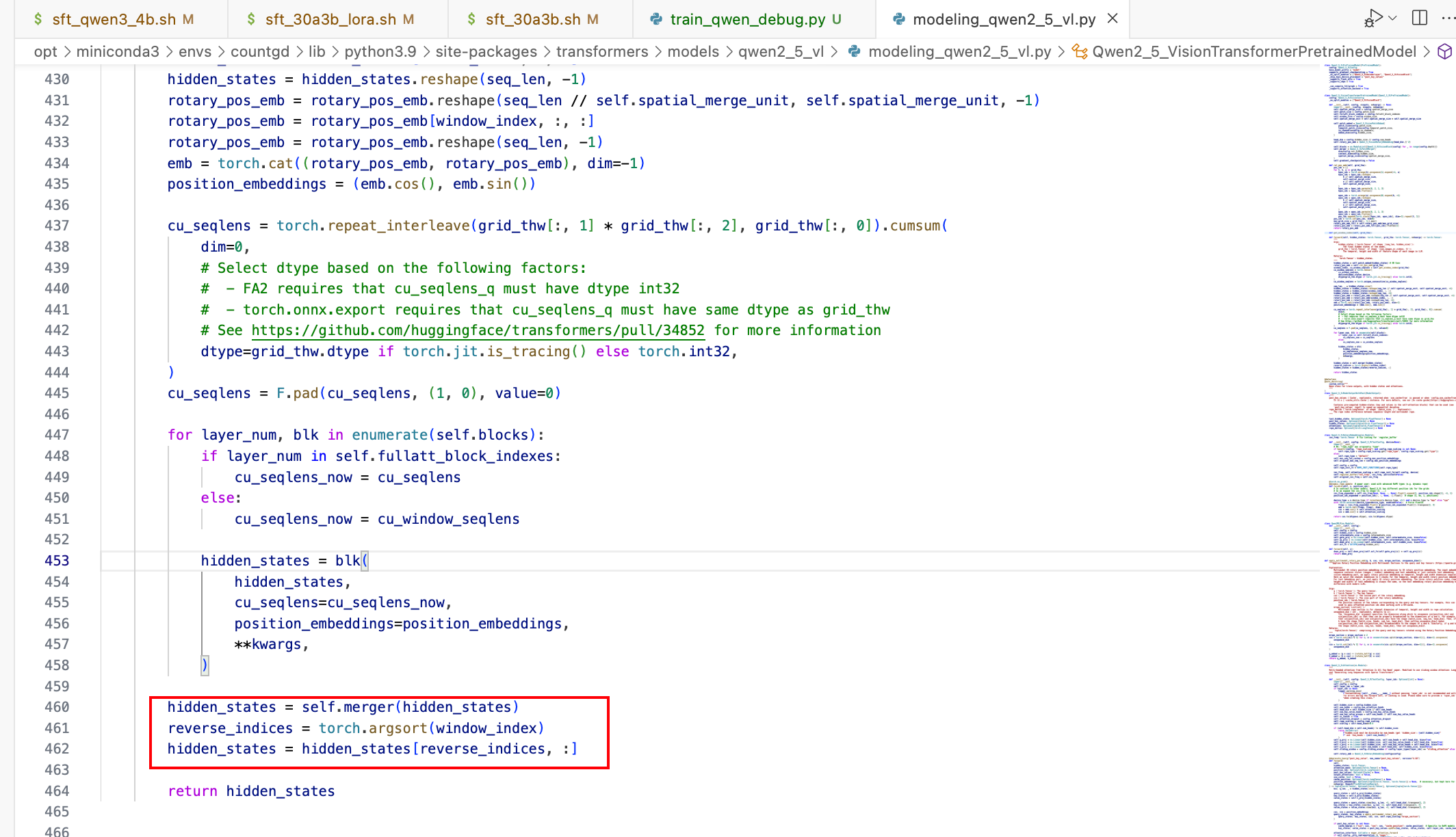
2 . 旋转位置编码
3 . 窗口注意力
(待更新)
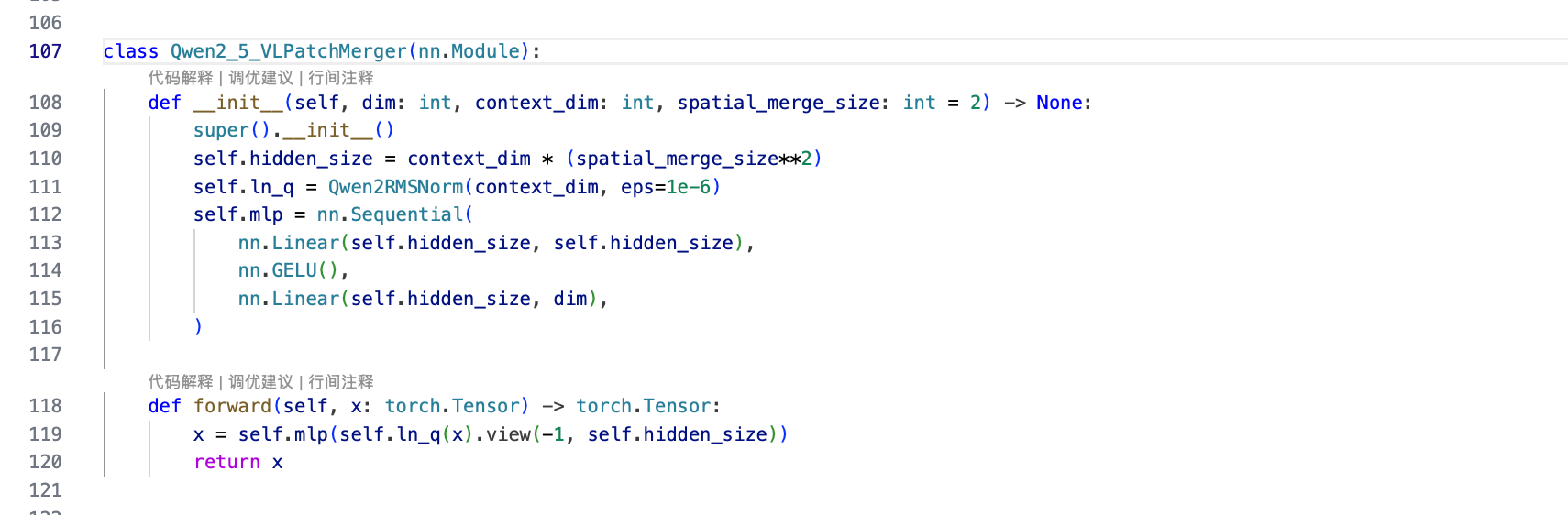
4 . Merger层
Qwen2_5_VLPatchMerger类,里面是一个mlp的操作
三. 文本Embedding
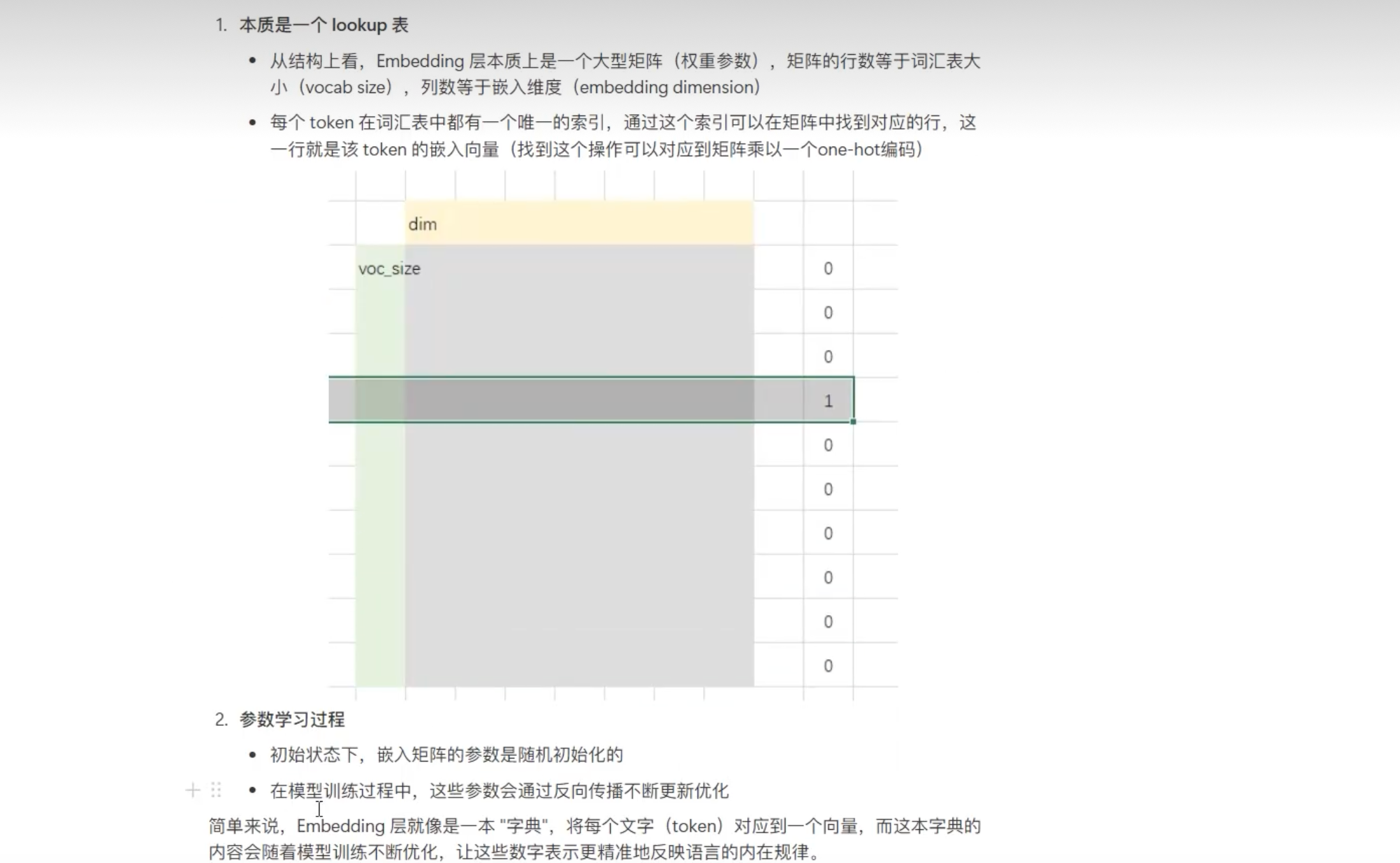
类名:Qwen2_5_VLTextModel
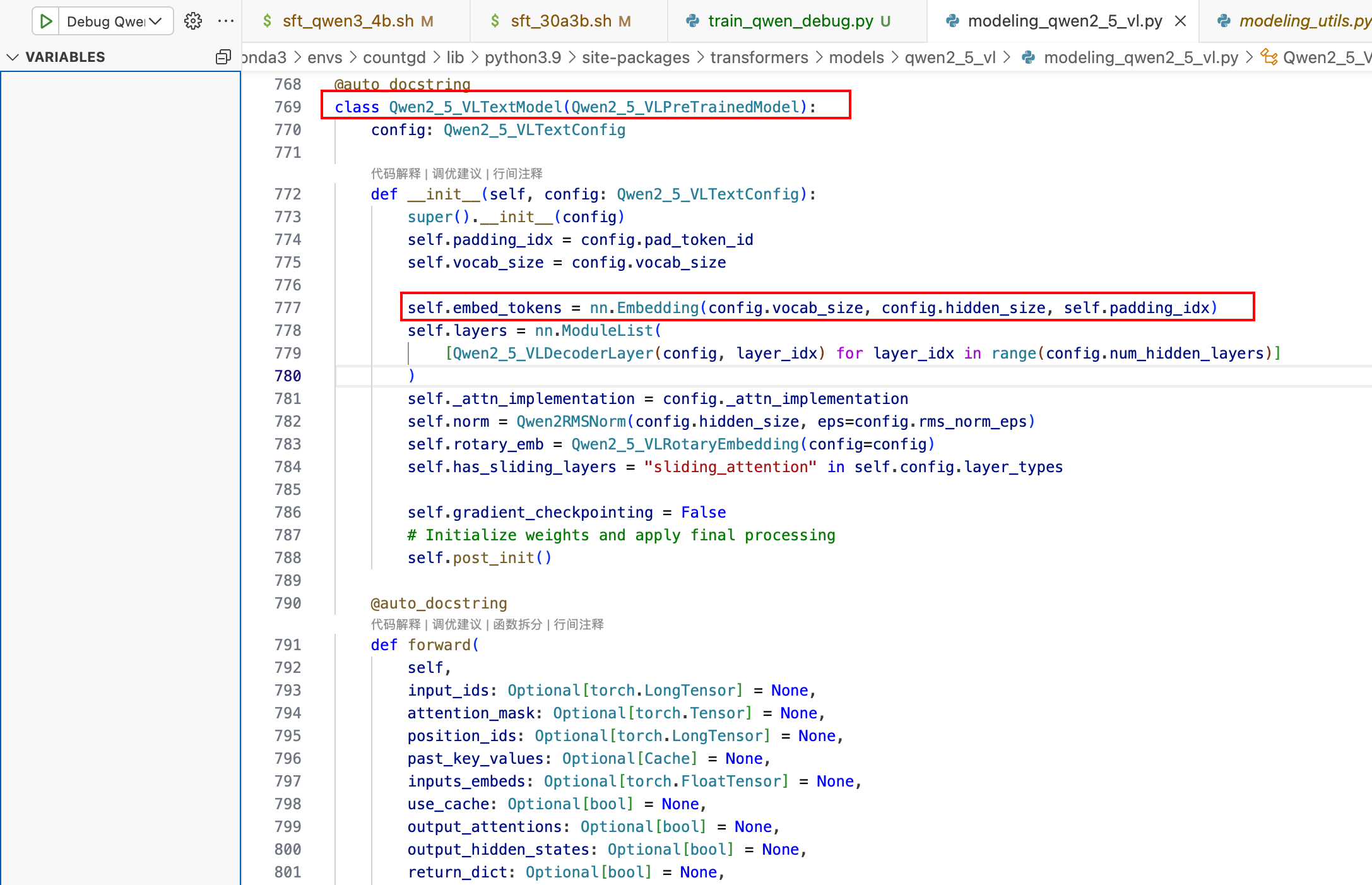
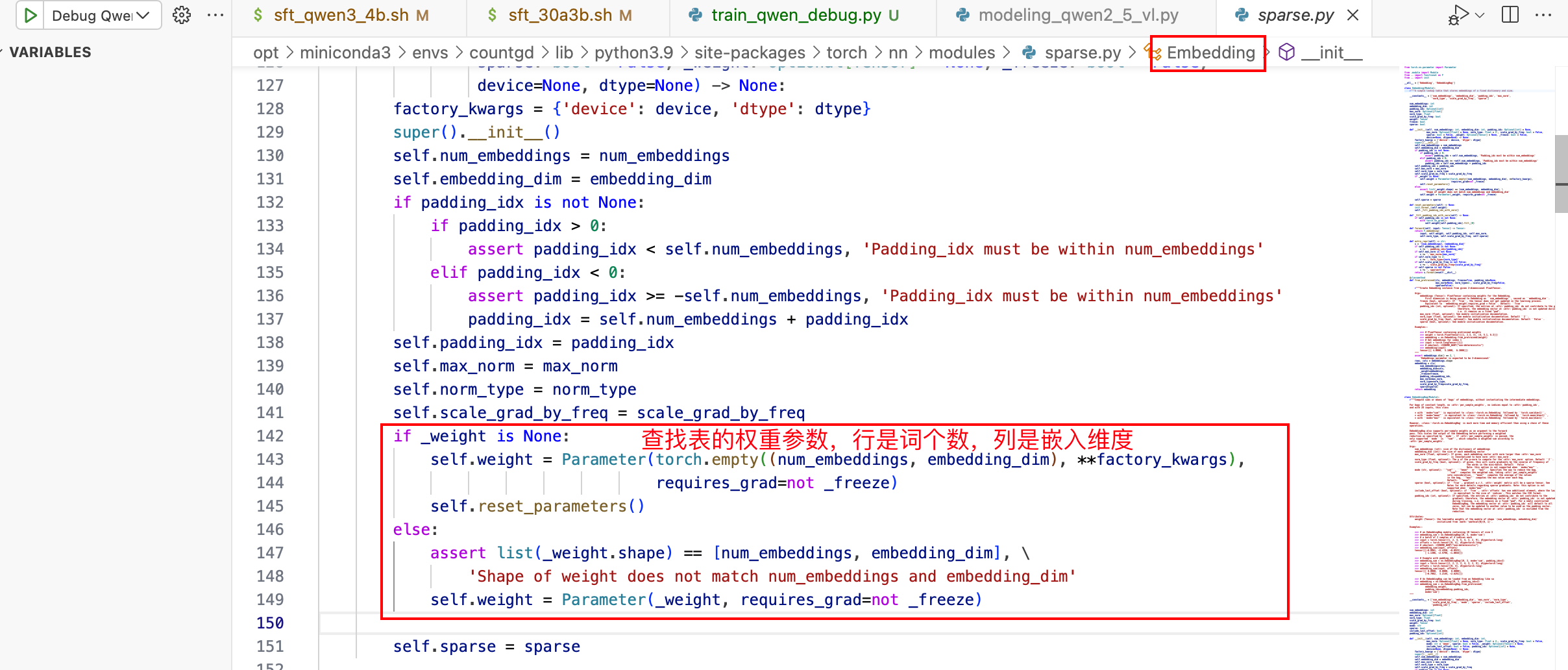
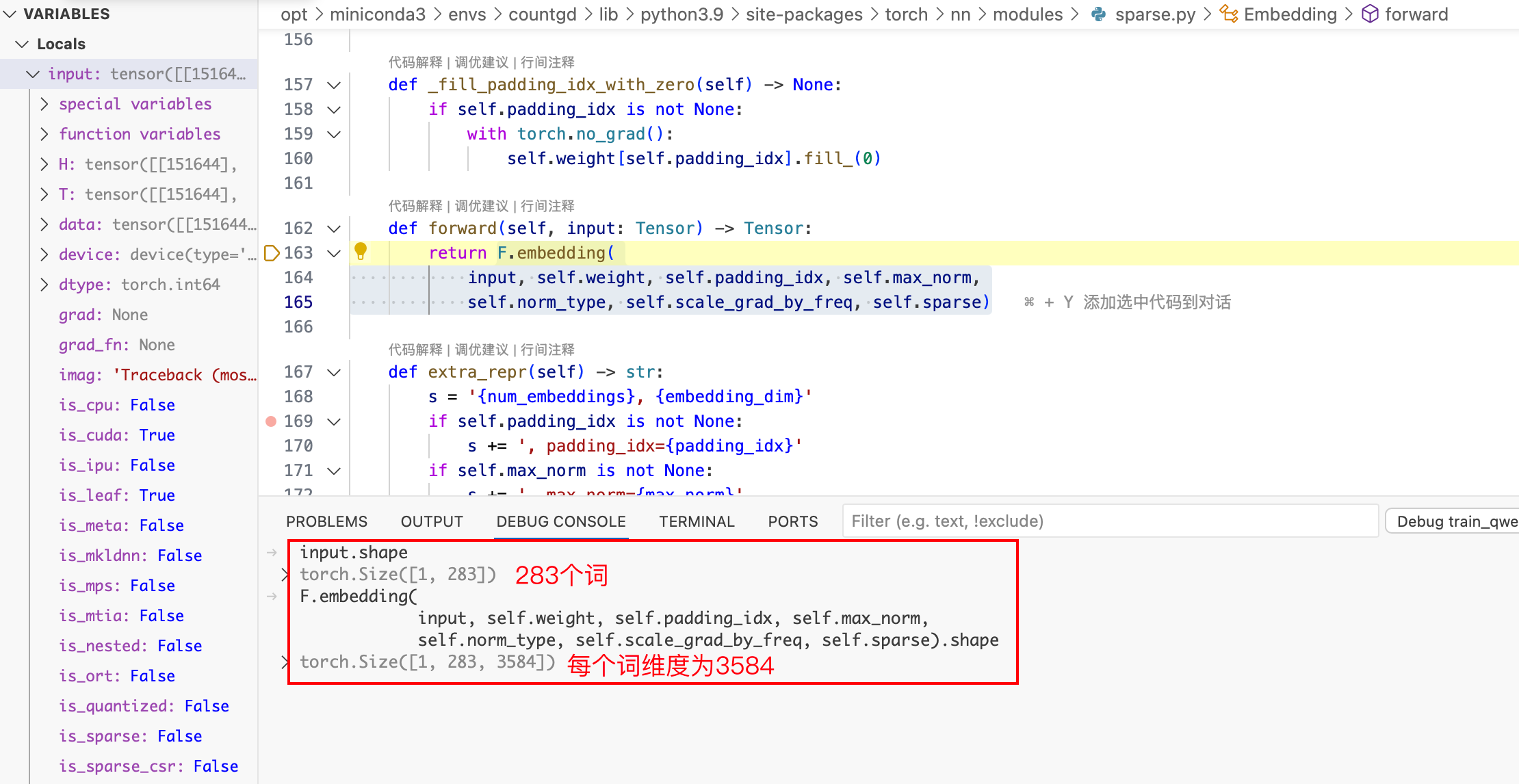
具体实现
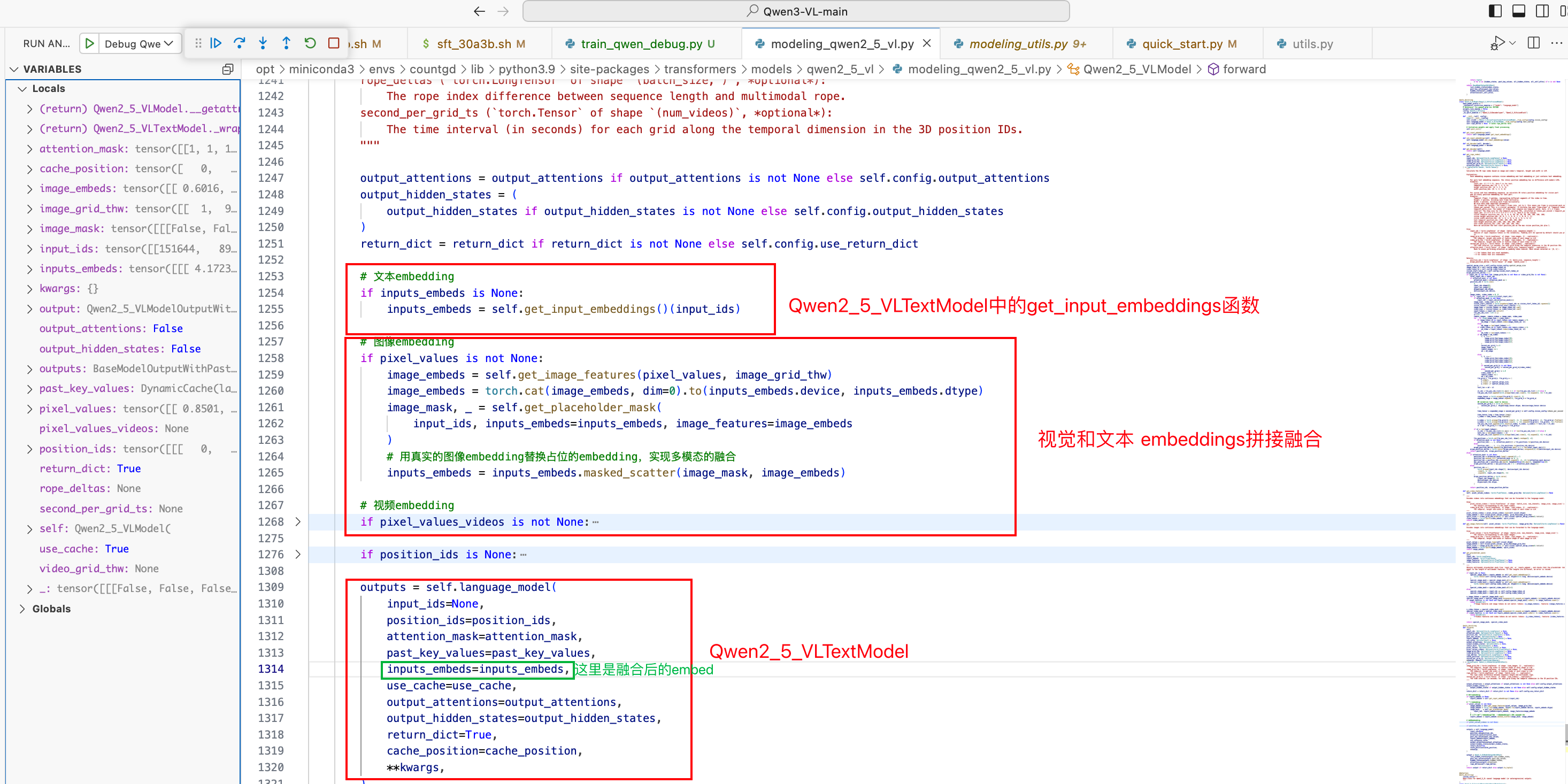
四. 视觉、文本embedding拼接(多模态融合)

类名:Qwen2_5_VLModel
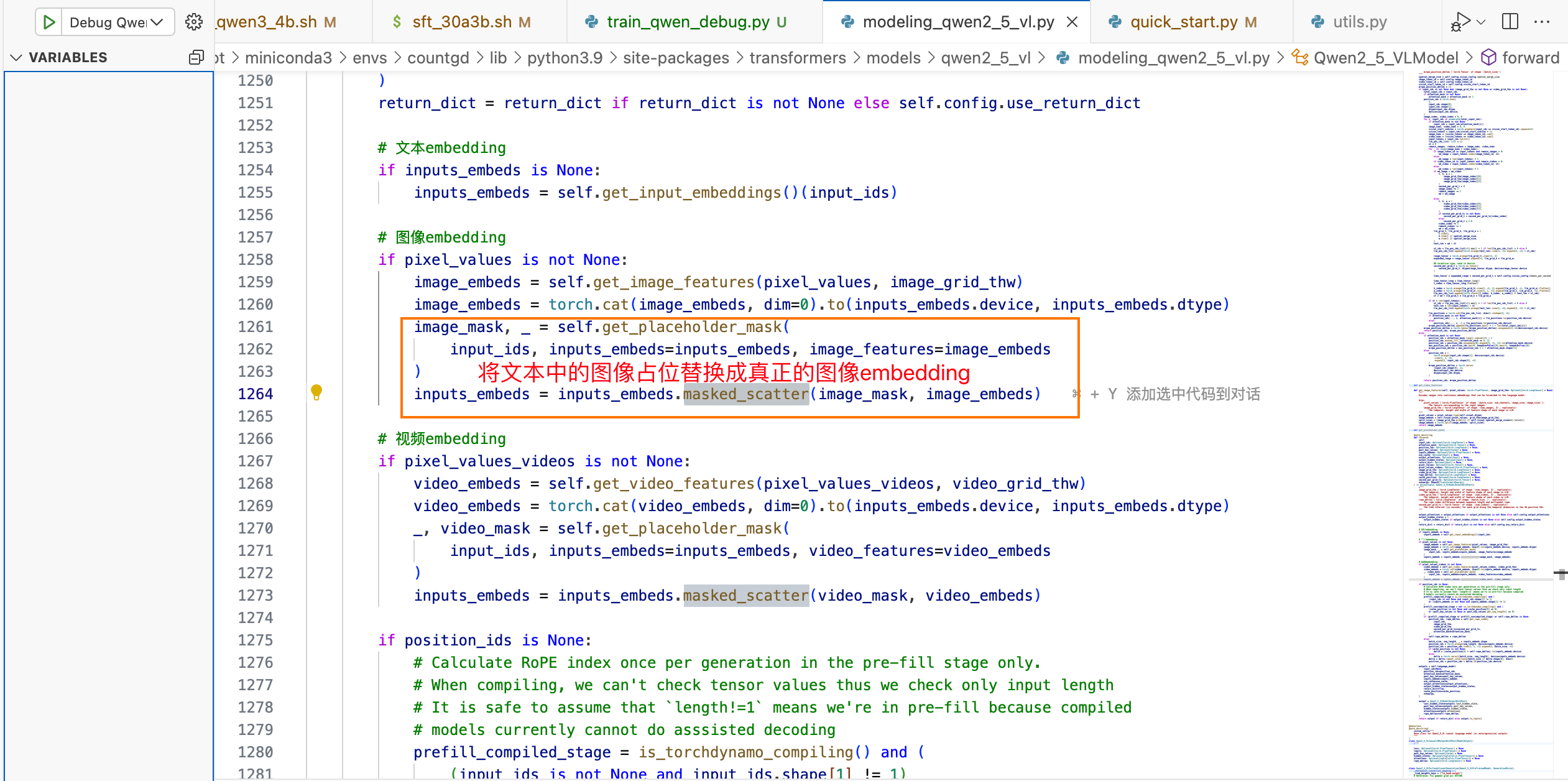
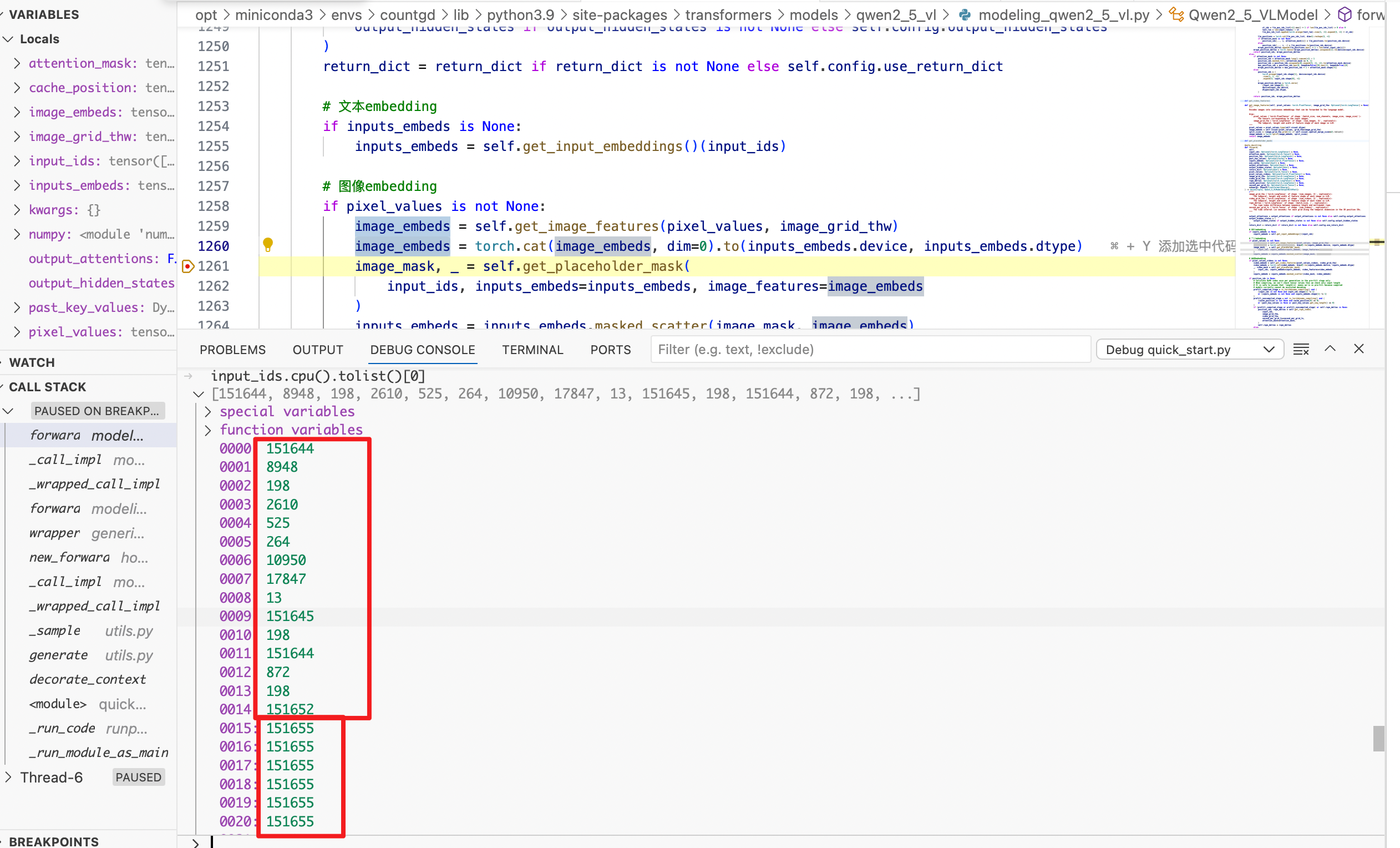
151655 均为图像占位的, 将这些值替换成 图像embedding
Qwen2_5_VLModel 实现了多模态的融合
五. 整体训练流程
python
def train(attn_implementation="flash_attention_2"):
# 1. 参数解析和初始化
'''
使用Hugging Face的ArgumentParser解析三类参数:
ModelArguments: 模型相关参数(模型路径、类型等)
DataArguments: 数据相关参数(数据集路径、处理方式等)
TrainingArguments: 训练相关参数(学习率、批次大小等)
'''
global local_rank
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments)
)
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
local_rank = training_args.local_rank
os.makedirs(training_args.output_dir, exist_ok=True)
# 2. 模型加载和类型判断
'''
检测路径中的关键词自动选择正确的模型类
支持Qwen3-VL、Qwen3-VL-MoE、Qwen2.5-VL、Qwen2-VL等多个版本
自动设置data_args.model_type用于后续数据处理
'''
if "qwen3" in model_args.model_name_or_path.lower() and "a" in Path(model_args.model_name_or_path.rstrip("/")).name.lower():
model = Qwen3VLMoeForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
dtype=(torch.bfloat16 if training_args.bf16 else None),
)
data_args.model_type = "qwen3vl"
elif "qwen3" in model_args.model_name_or_path.lower():
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
dtype=(torch.bfloat16 if training_args.bf16 else None),
)
data_args.model_type = "qwen3vl"
elif "qwen2.5" in model_args.model_name_or_path.lower():
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
dtype=(torch.bfloat16 if training_args.bf16 else None),
)
data_args.model_type = "qwen2.5vl"
else:
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
attn_implementation=attn_implementation,
dtype=(torch.bfloat16 if training_args.bf16 else None),
)
data_args.model_type = "qwen2vl"
print(f'the initlized model is {model_args.model_name_or_path} the class is {model.__class__.__name__}')
# 3. 处理器和配置设置
processor = AutoProcessor.from_pretrained(
model_args.model_name_or_path,
)
if data_args.data_flatten or data_args.data_packing:
replace_qwen2_vl_attention_class()
model.config.use_cache = False # 训练时禁用缓存提高效率
# 4. 梯度检查点配置
'''
启用梯度检查点,用计算时间换显存空间,大幅减少训练时的显存占用,增加约20%的计算时间
'''
if training_args.gradient_checkpointing:
if hasattr(model, "enable_input_require_grads"):
model.enable_input_require_grads()
else:
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
# 5. Tokenizer加载
tokenizer = transformers.AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=training_args.cache_dir,
model_max_length=training_args.model_max_length,
padding_side="right",# 填充在右侧,适合自回归模型
use_fast=False,# 使用标准tokenizer确保兼容性
)
# 6. LoRA配置(核心微调逻辑)
if training_args.lora_enable:
from peft import LoraConfig, get_peft_model, TaskType
print("LoRA enabled")
# 冻结所有原始参数
for p in model.parameters():
p.requires_grad = False
# 配置LoRA适配器
lora_config = LoraConfig(
r=training_args.lora_r or 64, # LoRA秩
lora_alpha=training_args.lora_alpha or 128, # 缩放参数
lora_dropout=training_args.lora_dropout or 0.05,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # # 注入位置, Qwen的attention线性层
bias="none",
task_type=TaskType.CAUSAL_LM,
)
model = get_peft_model(model, lora_config)
else:
# 全参数微调
set_model(model_args, model)
# 检查是否是主进程或单卡模式
if not torch.distributed.is_initialized() or torch.distributed.get_rank() == 0:
model.visual.print_trainable_parameters()
model.model.print_trainable_parameters()
# 7. 数据模块准备
'''
1. 加载和预处理多模态数据集
2. 应用对话模板格式化数据
3. 处理图像/视频特征提取
4. 构建训练所需的DataLoader
'''
data_module = make_supervised_data_module(processor, data_args=data_args)
# 8. 训练器创建和训练
trainer = Trainer(
model=model, processing_class=tokenizer, args=training_args, **data_module
)
##断点续训检查
if list(pathlib.Path(training_args.output_dir).glob("checkpoint-*")):
logging.info("checkpoint found, resume training")
trainer.train(resume_from_checkpoint=False) # 从检查点恢复
else:
trainer.train() # 从头开始训练
trainer.save_state()
# 9. 模型保存
'''
1. 安全保存模型权重
2. 保存处理器配置
3. 确保所有文件完整写入
'''
model.config.use_cache = True # 推理时候启用缓存
safe_save_model_for_hf_trainer(trainer=trainer, output_dir=training_args.output_dir)
processor.save_pretrained(training_args.output_dir)