目录
[>输出重定向 >>追加重定向](#>输出重定向 >>追加重定向)
[open close](#open close)
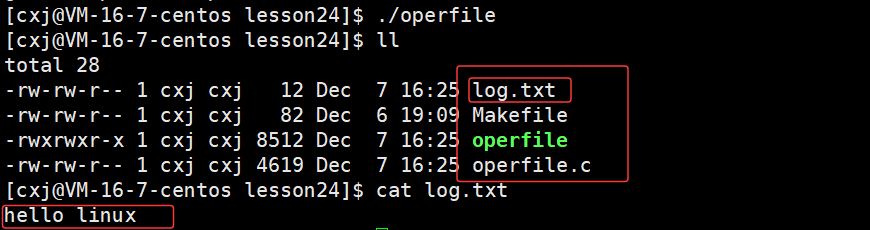
使用一下stdin,stdout,stderr对应的文件描述符0,1,2
一、对文件的理解
关于文件,我们已经有了一些共识性的知识
首先,文件 = 内容 + 属性 (元数据),所以对文件的操作只有两类------操作内容、操作属性。
在访问文件之前,必须要先打开文件 ,更需要先找到对应的文件
- 找文件 需要路径+文件名 ,有时在写代码时并没显式写路径(比如 "log.txt" ),但这并不代表着不需要路径,而是默认用了进程的当前工作路径(cwd)(进程会动态维护自己的cwd),最终实际路径是 cwd/log.txt ;
- 执行打开文件 是进程在执行 fopen 等这类函数打开文件( fopen 是动态打开,程序运行后才执行)。
而**"打开文件"的本质,是把磁盘上的文件加载到内存** ;后续对文件的操作,其实是进程通过CPU访问"内存里的文件副本"对文件进行操作。
从系统视角看,Linux里的文件分两类:打开的文件、未打开的文件:
- 未打开的文件存在磁盘(由文件系统管理);
- 打开的文件会被加载到内存 (属于"内存级打开的文件")。
Linux中可以同时存在大量"打开的文件",操作系统需要对这些文件做管理吗?如果需要,该怎么管理呢?
OS要管理被打开的文件,核心思路仍然是**"先描述,再组织"** :
1. 先描述:OS会为每个"打开的文件"创建一个结构体(比如Linux中的 struct file ),用这个结构体来记录文件的关键信息------包括文件属性(权限、大小等)、文件内容在内存中的位置、当前读写位置等,相当于给文件"建个档案"。
cppstruct file { //文件属性1; //文件属性2; //文件属性3; //文件属性... struct file* next; //链表 };2. 再组织 :把所有打开文件对应的结构体,用数据结构(比如链表)串联起来管理。这样OS就能通过遍历链表,快速找到、操作所有打开的文件(比如查找某个文件、关闭文件等)。
简单说,OS靠"结构体记录文件信息 + 链表(或其他结构)串联这些结构体",实现对所有打开文件的统一管理。
而本篇我们学习的文件是第二种内存级被打开的文件
二、C语言标准库文件接口
操作文件的接口分C语言标准库接口 和Linux系统调用接口两类
我们先来看C语言标准库的文件接口:
fopen

对于 fopen 函数本身而言:
- path :要打开的文件路径(可以是相对路径,也可以是绝对路径);
- mode :打开文件的模式(决定是读、写还是追加等);
- 返回值:打开成功返回 FILE* 指针 (指向一个记录文件信息的结构体,叫"文件指针/文件句柄");打开失败返回 NULL 。
- C语言中字符串本质是 char 数组,传参时会退化为 char* 指针。const 修饰 char* ,表示 fopen 函数不会通过这个指针去修改字符串的内容(比如不会改你的文件路径、不会改打开模式)。
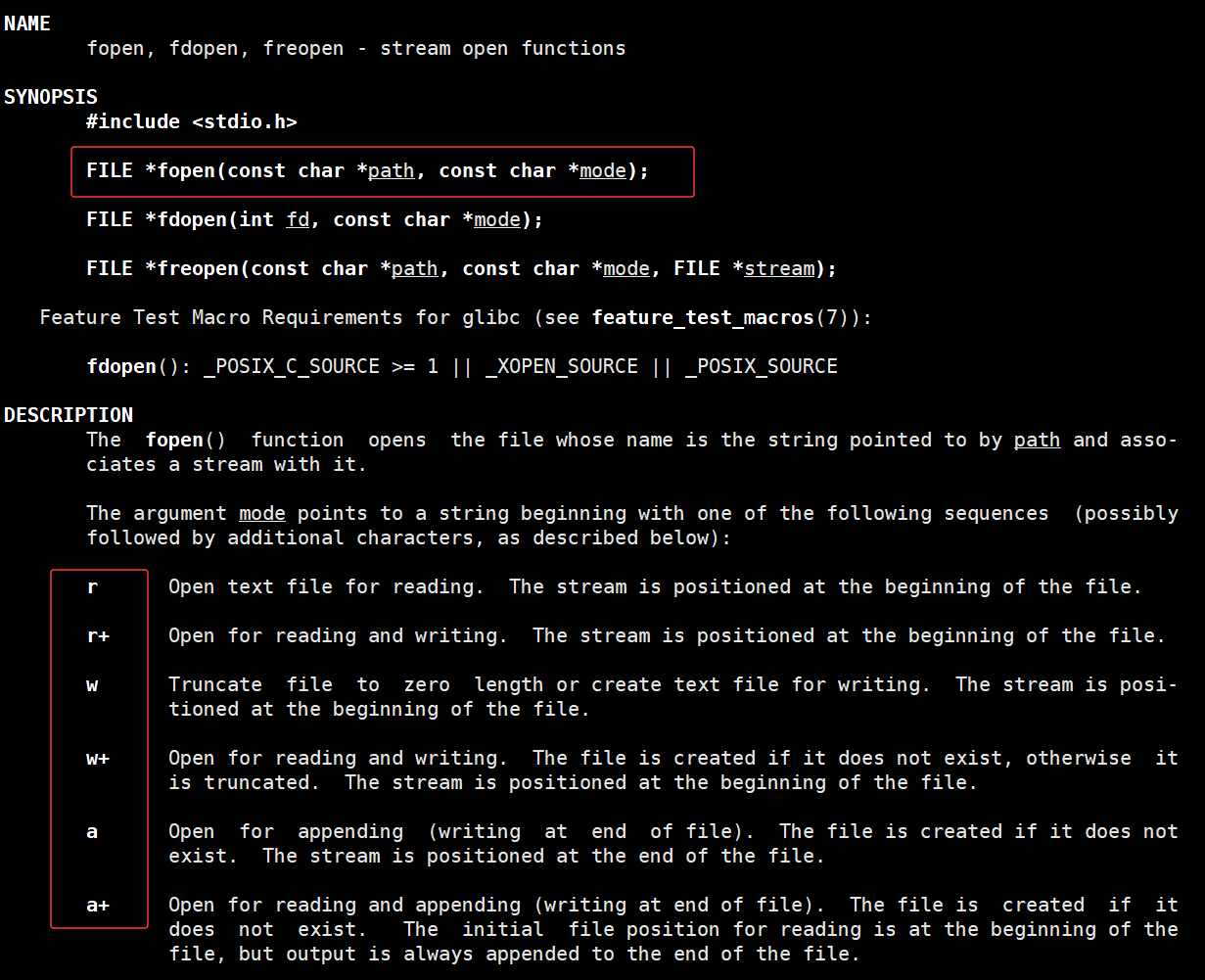
再看下面的关于 mode 参数的不同取值 : mode 的开头字符决定了文件执行的基本行为 :
1. r (只读)
- 打开已存在的文件++进行读取操作++
- 若文件不存在则打开失败
- 文件指针默认定位在文件起始位置
2. r+ (读写)
- ++以读写模式打开现有文件++
- 文件不存在时操作失败
- 文件指针初始位于文件起始位置
3. w (只写) 相当于 >log.txt
- 若文件已存在,则清空其内容 (截断为零长度);若不存在,则创建新文件
- 仅支持写入操作
- 文件指针始终位于文件起始位置
4. w+ (读写)
- 如果文件已存在,则清空其内容;若不存在,则创建新文件
- 支持读写操作
- 文件流指针始终位于起始位置
5. a (追加写) 相当于 echo "aaaaa" >>log.txt 追加重定向
- 若文件不存在,则自动创建新文件
- 仅支持写入模式,且内容将自动追加至文件末尾
- ++文件指针始终位于末尾位置++
6. a+ (读写+追加写)
- 若文件不存在,则创建新文件
- 支持读取和追加写入模式(读取时指针位于文件开头,写入时始终追加至文件末尾)
- 读取位置固定为文件起始处,写入位置始终为文件末尾
简单说: r 开头是"读优先", w 开头是"写优先(会清空)", a 开头是"追加写"。
本文主要研究 w只写和a追加写这两种方式,在后面都会一一验证
fclose
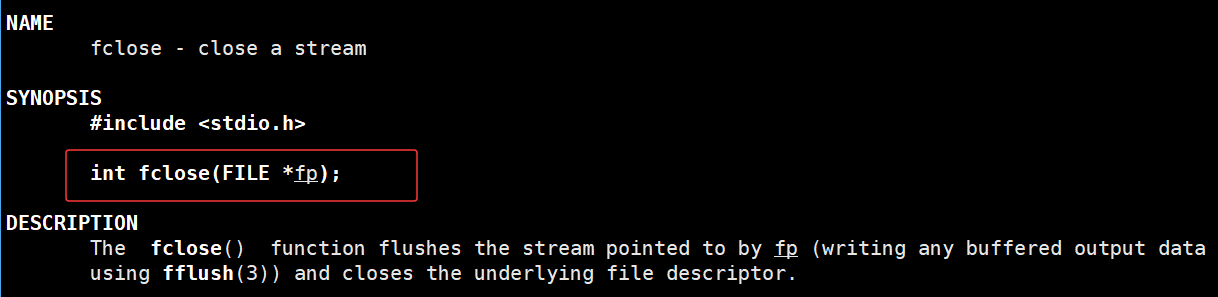
fclose 函数的参数 fp 是 fopen 打开文件后返回的 FILE* 指针(也就是要关闭的文件流);
返回值如果关闭成功返回 0 ;失败则返回 -1 。fclose 的两个核心作用主要是:
- 刷新缓冲区:把文件流中尚未写入磁盘 的缓存数据(比如用 fwrite 写了但没实际存到磁盘的内容)强制写入磁盘(相当于自动调用了 fflush );
- 关闭文件:释放 FILE* 对应的资源,同时关闭底层的文件描述符(系统层面的文件标识),让OS回收这个文件的管理资源。
如果不调用 fclose ,可能会导致:缓存数据丢失(没来得及写入磁盘);系统资源泄漏(打开的文件太多会耗尽OS的文件描述符限额)。
所以 fclose 是"收尾操作",打开的文件流用完后一定要用它关闭
除此之外,C语言的相关文件操作函数还有很多 fputc,fgetc,fputs,fgets,fprintf,fscanf,fwrite,fread等等... 这里就不过多赘述了

那么我们首先使用 fopen 和 w(只写) 的方式打开一个不存在的文件log.txt
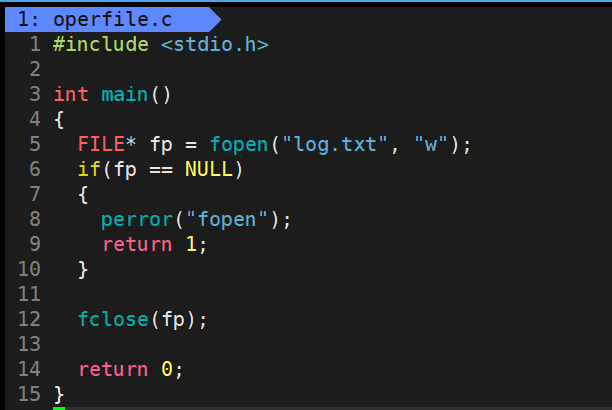
运行结果:
- 先查看我们的目录,当前目录下并没有log.txt文件,当我们运行之后目录下有了log.txt文件了
- 说明当我们使用 fopen 以 w 的方式打开文件,如果当前目录下没有该文件,那么就会在当前目录下创建这个文件
添加log.txt文件的当前路径是什么?当前路径是当前进程的工作路径,即当前进程的cwd,那么我更改一下当前进程的cwd是不是就可以将文件新建到其它目录呢?下面我们来验证一下
同样的,在上面代码的基础上,打印出当前进程的pid,并且关闭文件之后让进程休眠1000秒,便于我们查看进程的当前工作目录
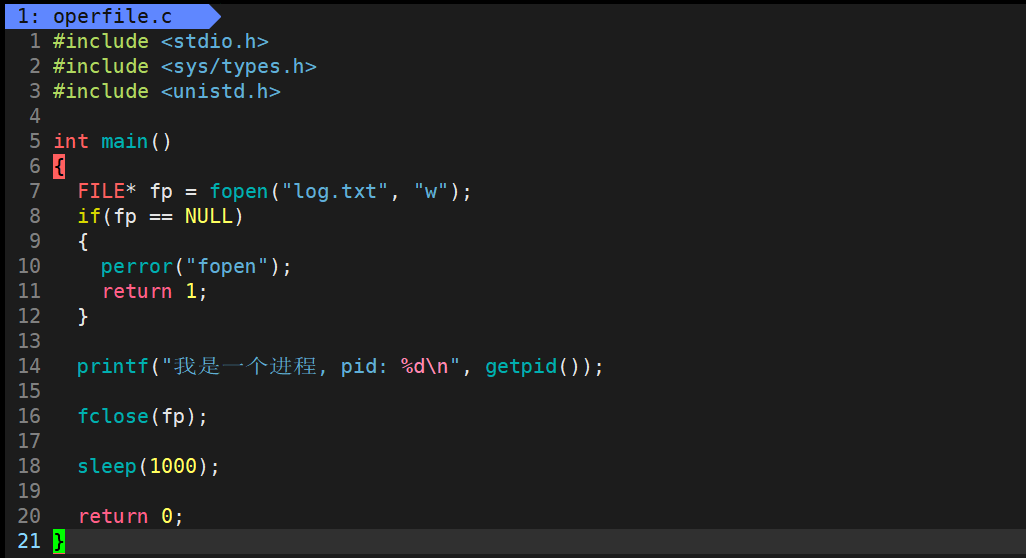
运行结果:
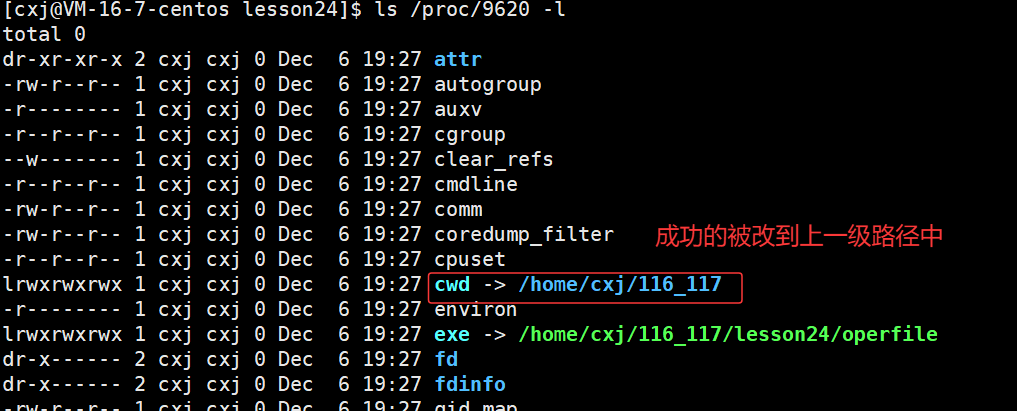
- 在根目录的/proc目录中,存储着当前运行进程的PID信息。通过 ls -l 命令查看特定PID目录,可以获取该进程的各项属性,包括cwd(当前工作目录)。
- 我们当前处于休眠状态的进程PID已经显示出来,因此可以在/proc目录中找到对应的PID信息,查看其cwd属性。当使用 fopen 以写入模式("w")打开不存在的文件时,系统会在当前目录创建该文件。操作系统之所以知道创建位置,正是依赖于进程的cwd属性。
- 若未指定文件绝对路径,系统会自动将进程的cwd与文件名拼接,作为文件创建路径。反之,若指定了绝对路径,系统则直接在给定路径创建文件,不再涉及工作目录拼接操作。
- 因此,当我们退出当前进程时,由于创建文件时未使用绝对路径而仅指定了文件名,操作系统会自动将当前进程的工作目录与文件名拼接,导致文件默认被创建在当前进程的工作目录下。


那我们可不可以将当前进程的cwd工作目录改掉,让新创建的文件创建到更改后的进程的工作目录下呢? 答案是可以的,我们学过一个系统调用 chdir 可以更改当前进程的工作目录,那么下面就演示一下
由于我们使用的是普通用户,由于权限的问题,操作系统不会允许,同时我们也不能将这个进程工作目录更改到任意目录,否则会出现问题,但是却可以将进程的工作目录更改到当前普通用户的家目录下即/home/cxj/116_117,因为我普通用户可以将进程的工作路径更改到当前普通用户的家目录的任意路径下,即/home/cxj/116_117这个路径下
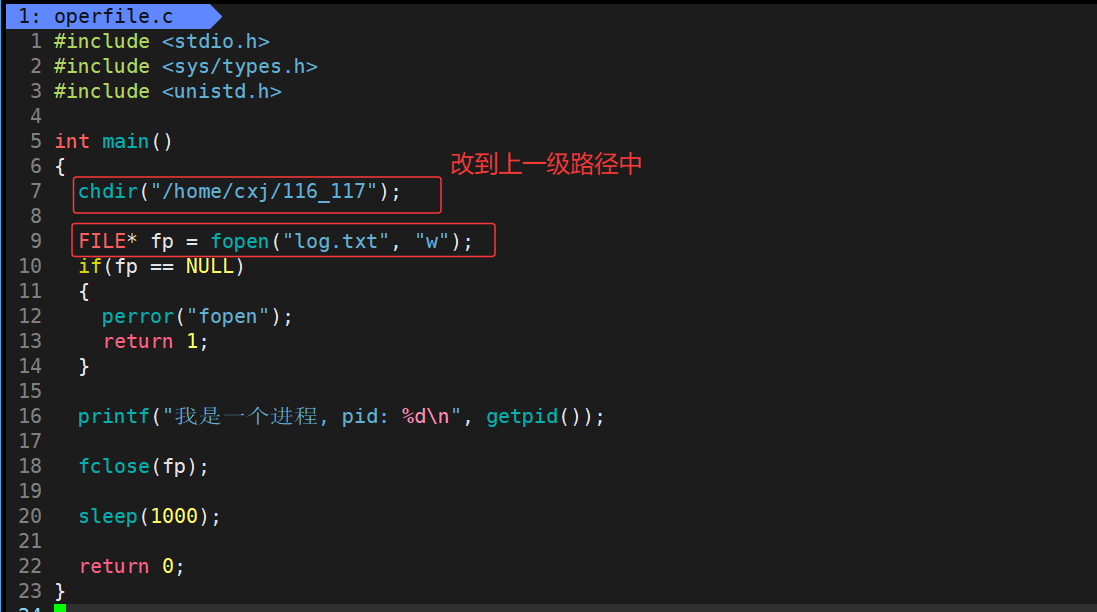
运行结果:
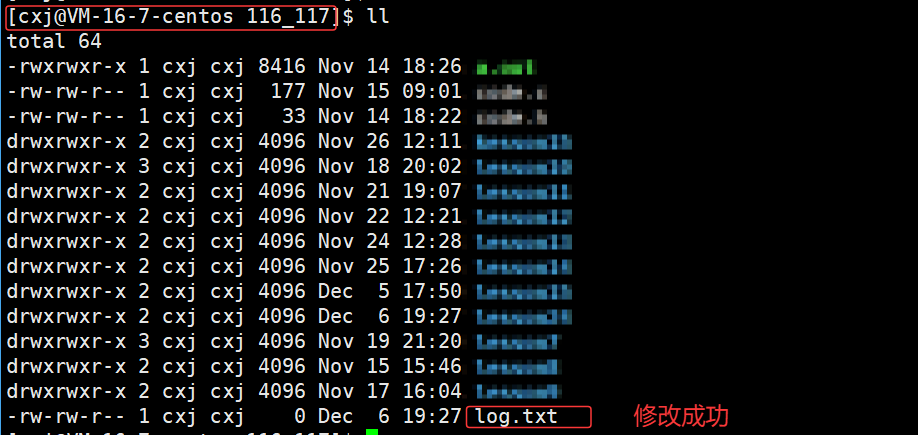
我们可以看到 cwd 路径已经成功地被改到上一级中,那我们可以返回上一级路径来验证查看 log.txt 文件是否打开成功:
可以看出 /home/cxj/116_117 这个上级路径中已经有了 log.txt 文件,也就说明了若未指定文件绝对路径,系统会自动将进程的cwd与文件名拼接,作为文件创建路径。
同时也能说在使用 fopen 以 w 的方式打开一个不存在的文件,就会在该路径下创建该文件
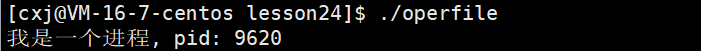
fwrite
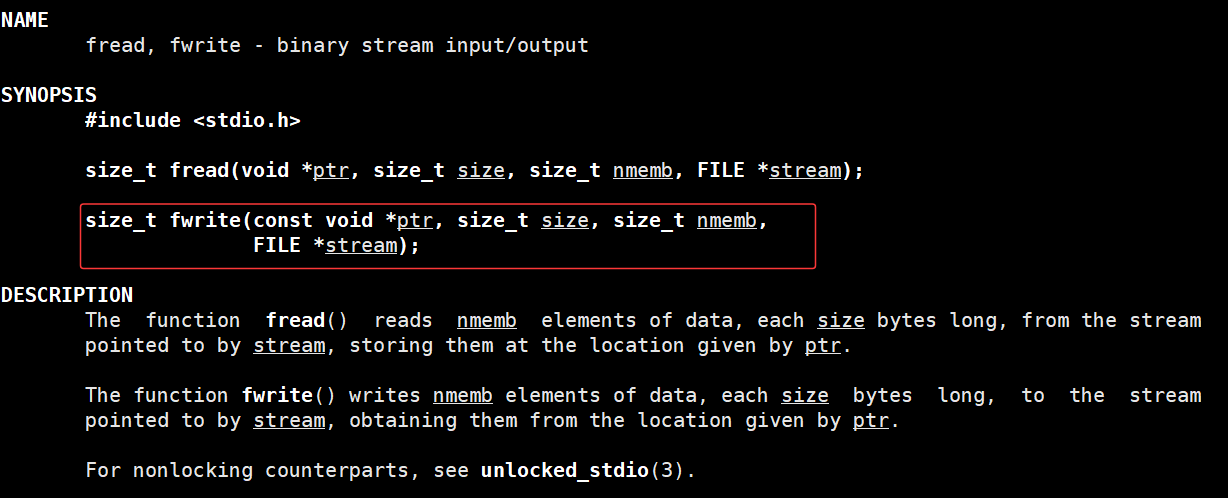
fwrite 函数是C标准库中用来向文件(或流)中写入数据的函数:
- ptr :要写入的数据的内存地址(比如数组、结构体的首地址);
- size :单个数据元素的字节大小(比如写 int 数组, size 就是 sizeof(int) );
- nmemb :要写入的数据元素个数(比如写5个 int , nmemb 就是5);
- stream :目标文件流( fopen 返回的 FILE* 指针);
- 返回值:实际成功写入的元素个数(不是字节数);如果写入失败,返回值会小于 nmemb 。
使用 fopen 以写入("w")或追加("a")模式打开文件时,fwrite 可以向文件中写入内容。该函数需要传入待写入的字符串、字符串大小(可用 strlen 计算)、字符串份数以及文件流。
我们知道,在c语言中字符串是包含结尾的\0的,所以在fwrite传入写入字符串的大小的时候,要不要将计算后的strlen进行加1将\0也算进去呢?
- 实际上不需要。
\0是C语言用来标识字符串结束的特殊字符,但文件存储的是原始字节流,并不遵循特定语言的字符串约定。C语言中由于缺乏原生字符串类型,才需要通过\0来区分字符和字符串。 - 文件内容应保持语言无关性,能被各种编程语言读取。不同语言对字符串的处理方式各异,并非都采用
\0结尾的约定。因此,使用 fwrite 写入文件时,只需写入字符串的实际内容,无需包含结尾的\0字符。
那么下面我们先以w的方式fopen打开文件,接下来使用一下fwrite接口向文件中写入一些信息:
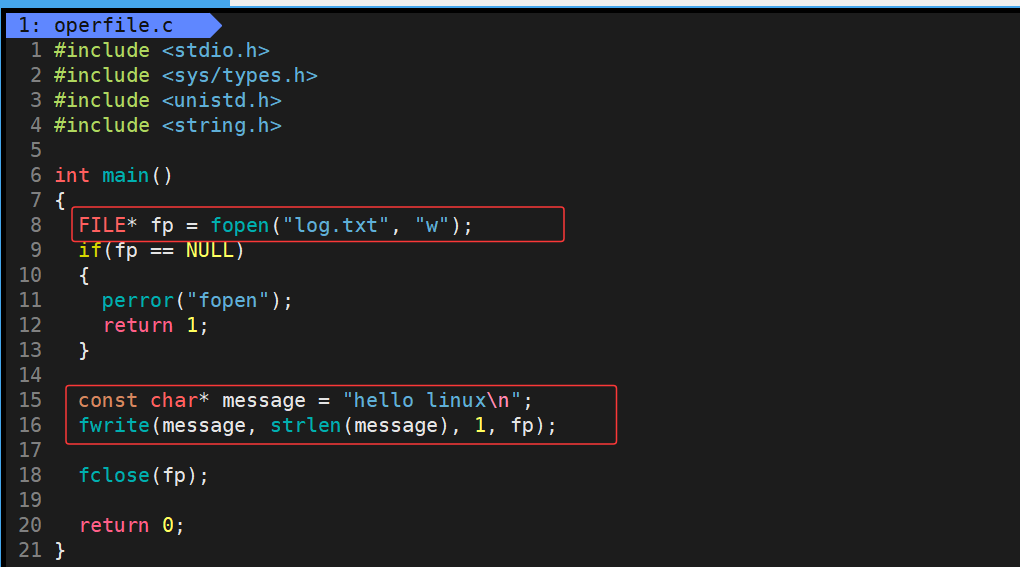
运行结果:
此时已经成功的hello linux写入到log.txt文件中了

那么下面继续同样以w的方式fopen打开文件,使用fwrite接口向文件中写入不同的信息
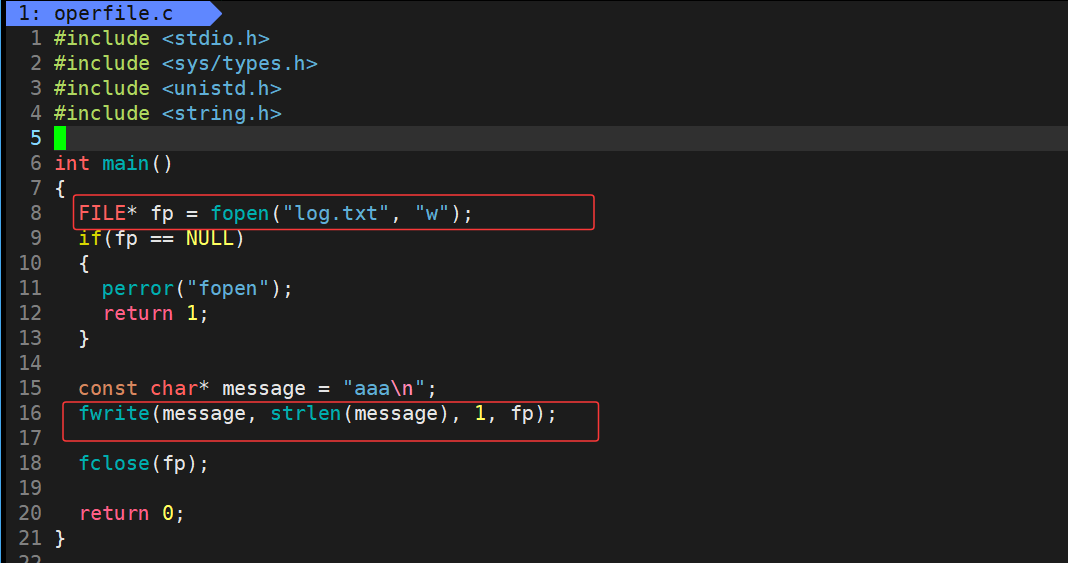
运行结果:
运行程序后,原内容"hello linux"已被修改为"aaa"。值得注意的是,这里的修改不是简单的追加(不会变成"hello linuxaaa"),也不是部分覆盖(不会变成"aaalo linux"),而是完全替换为新内容 。这是因为当我们使用"w"模式通过fopen打开文件时,在写入操作开始前,系统会自动清空文件原有内容。"w"模式会先清空文件再从头开始写入,文件指针始终位于文件起始位置,因此最终只保留了新写入的"aaa"。

那 fopen 的 w 只写模式和 fwrite 的写入操作是同一回事吗?
不是一回事,它们是文件操作的两个不同环节:
1. fopen("xxx", "w") 是打开文件的操作, w 的作用是:
- 若文件存在,清空其内容(变成空文件);
- 若文件不存在,创建新文件;
- 打开后,文件流处于"只写状态"。
它的核心是初始化文件的状态,为后续写入做准备。
2. fwrite 是具体的写入操作,负责把内存中的数据(比如数组、结构体)以二进制形式写到"已经打开的文件流"里。它的前提是:文件已经通过 fopen (用 w / w+ / a 等可写模式)打开了。
说完 fopen 中的 w 只写模式,那么接下来我们看一下重新以 a追加方式的 fopen 打开会发生什么?
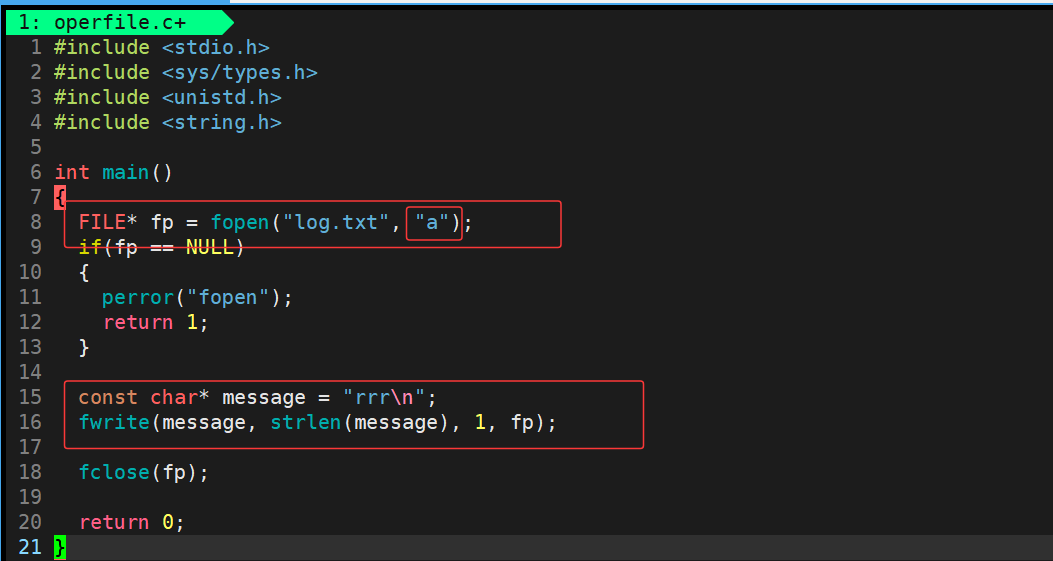
运行结果:
可以看出 log.txt 文件已经重新的写入字符串"rrr"
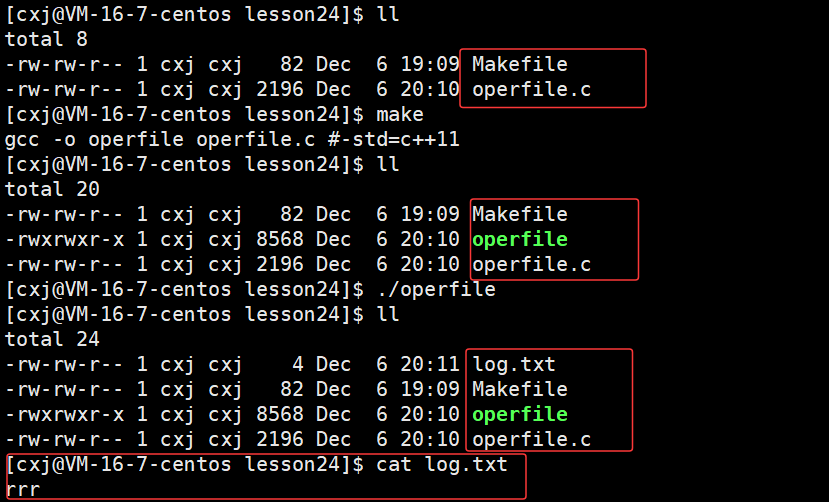
那么下面继续同样以 a 的方式 fopen 打开文件,使用fwrite接口向文件中写入不同的信息,观察 log.txt 文件中的内容是被完全替换掉还是继续叠加:
运行结果:
可以观察到当使用"a"模式通过 fopen 打开文件进行写入时,log.txt文件中原有的"aaa\n"内容不会被清空或覆盖,而是会在文件末尾追加写入 。需要注意的是,"w"和"a"模式虽然都用于写入,但存在区别:"w"模式会清空文件内容并从头开始写入,而"a"模式则会在文件末尾追加写入。

fprintf
fprintf是向文件流中格式化输入,fprintf的使用方法和printf类似,只不过fprintf的输入文件是我们显示指定的文件流
在Linux系统中,一切皆文件 的概念贯穿始终。C语言程序启动时,默认会打开三个标准I/O流:stdin对应键盘输入 (C++中的cin),stdout对应显示器输出 (C++中的cout),stderr对应的也是显示器输出(C++中的cerr)。因此,我们可以直接使用fprintf函数向stdout或stderr输出内容,观察其在显示器上的显示效果。
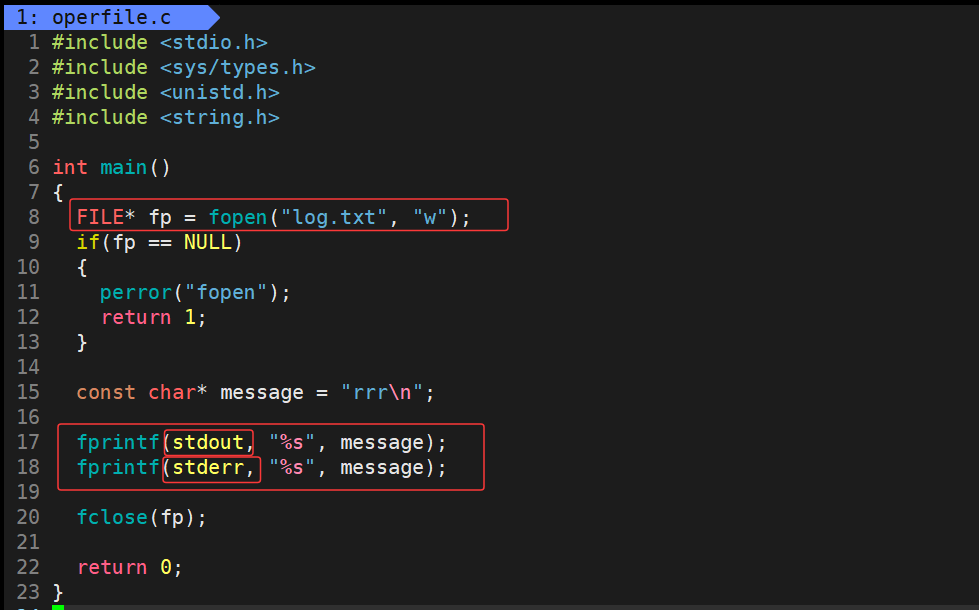
运行结果:
显示器上确实显示了打印的信息。虽然我们没有显式地用fp打开stdout和stderr这两个文件流,但仍然可以直接使用它们。这说明C语言程序在启动时会默认打开三个标准输入输出流(文件)。

>输出重定向 >>追加重定向
让我们回顾一下输出重定向操作符> 的使用。这个操作符能够将程序的输出内容重定向到指定文件中 。当目标文件不存在时,系统会自动在当前工作目录下创建该文件。
以echo命令为例,它主要用于输出字符串内容。我们可以利用这个特性,尝试将echo输出的字符串重定向到一个尚未存在的文件中。
- 我们第一次用 echo "hello linux" > log.txt 时, > 是覆盖重定向:它会清空 log.txt 原有内容(如果文件不存在则创建),再写入新内容,所以 log.txt 里只有 hello linux 。
- 第二次用 echo "aaa" > log.txt ,同样触发覆盖 :清空原有的 hello linux ,写入 aaa ,所以文件内容被替换成了 aaa (没有叠加)。
联系上面的内容,其实Linux里的 > (覆盖重定向),和C语言中 fopen 的 w 模式是完全一致的逻辑------都是"清空原有内容(或新建文件),写入新内容"。
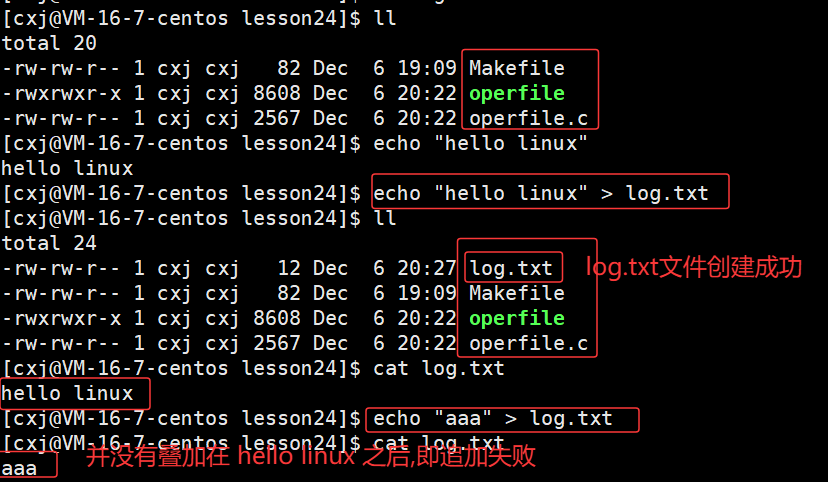
同时还有追击重定向>> ,此时我们回过头来看这个追加重定向,那么如果我们要追加重定向的文件不存在,这个追加重定向要先在当前路径下创建这个文件,之后再向这个文件的结尾,再追加写入,会不会对应的就是 fopen 中的 a 模式呢------保留原有内容,新内容追加到末尾,我们再来验证:
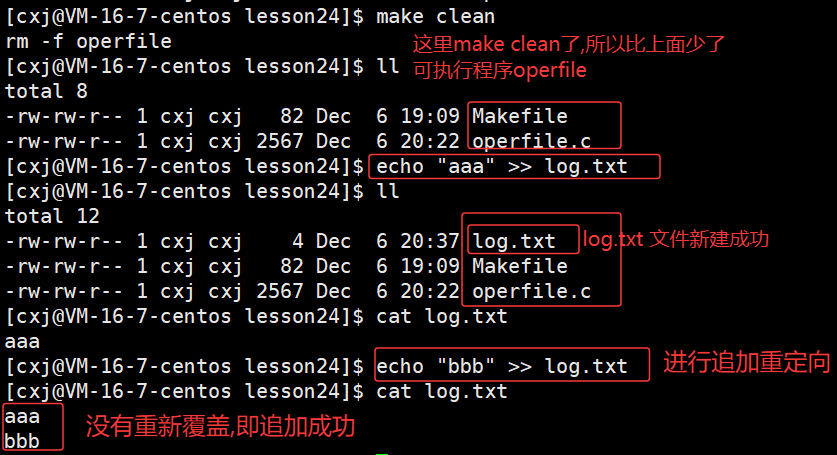
- 第一次执行 echo "aaa" >> log.txt :因为 log.txt 不存在,所以先创建文件 ,再把 aaa 写入(对应 fopen("log.txt", "a") 的"文件不存在则创建");
- 第二次执行 echo "bbb" >> log.txt :直接把 bbb 追加到 log.txt 末尾,没有覆盖 原有内容(对应 fopen 的 a 模式"追加写")。
同样,>> (追加重定向),对应的就是 fopen 的a模式------保留原有内容,新内容追加到末尾。
以上内容是站在C语言层面上对文件操作的理解
下面站在Linux系统调用接口的角度对文件操作再次理解
三、文件系统调用
Linux层面上对文件进行操作: 即站在OS角度理解如何进行文件操作
过渡到OS系统角度
文件存储在磁盘这一硬件设备上,因此访问文件本质上就是访问硬件设备。
程序调用标准库函数(如C/C++库)时,需要通过以下层级访问硬件:
- 程序调用标准库函数
- 库函数通过系统调用接口
- 操作系统内核处理请求
- 硬件驱动程序执行操作
- 最终访问物理硬件
由于操作系统对硬件访问有严格管控,所有程序必须通过系统调用 这一受控接口来访问硬件。因此,像printf、fprintf、fscanf、fwrite、fread、fgets等涉及文件操作的库函数,其底层都封装并调用了相应的文件系统调用。
总的来说,C语言的文件操作函数(如fopen、fwrite等),是对Linux操作系统提供的文件系统调用接口的封装;编程语言层面的文件操作,底层最终要通过OS的系统调用接口,才能完成对硬件(如磁盘文件)的实际访问。
比如C语言的文件操作函数(比如 fopen / fwrite / fclose ),本质是对Linux系统调用接口的"上层封装"------流程是这样的:
- 我们写C代码调用 fopen ,这是"编程语言层面的接口";
- fopen 内部会去调用Linux的系统调用接口(比如 open );
- 系统调用会让OS内核处理请求,最终通过硬件驱动访问磁盘文件。
简单说:C标准库的文件函数是"用户友好的包装",底层依赖OS提供的系统调用才能真正操作文件------相当于C库帮我们把复杂的系统调用逻辑"打包"成了简单的函数接口。
同时这也让我们对操作系统的系统调用接口产生了进一步深刻的理解:**系统调用是OS给应用程序(包括编程语言库)提供的"受控接口"------因为OS要管控硬件访问(不能让程序直接操作磁盘),所以所有硬件相关操作(比如文件读写),都得通过系统调用这个"中间层"完成。**而C语言文件函数的封装,正好体现了系统调用的核心作用:把复杂、危险的底层硬件操作,包装成应用层能安全、简单使用的接口。
这也解释了"为什么不同语言的文件操作逻辑相似"------因为它们最终都依赖OS的系统调用。
那么接下来我们将深入探讨Linux操作系统提供的文件系统调用接口的实现原理。
既然C语言中的 fopen / fclose 是对系统调用的封装,那OS原生提供的"文件操作接口"是什么呢?
答案就是Linux的文件系统调用------比如open (对应 fopen )、close (对应 fclose )、read (对应 fread )、 write(对应 fwrite )。
这些接口是OS直接暴露给程序的"底层入口",C标准库的文件函数就是基于它们实现的。
比特位方式传递标志位
由于open需要使用到比特位方式传递标志位的方式,所以在这里我们先学习一下如何使用比特位方式传递标志位。
在系统编程中,经常需要通过标志位来控制函数行为。传统做法是为每个标志单独设置参数,但当标志数量较多时,这种方式会显得非常繁琐。更高效的做法是利用整数的比特位来传递多个标志。
一个32位整数包含32个独立的比特位,每个位都可以表示一个标志的状态(0或1)。我们可以通过宏定义和位运算来管理这些标志位:
- 定义标志位:使用 1<<n 的方式为每个标志分配唯一的比特位位置
- 组合标志:通过按位或 (|) 运算将多个标志合并为一个整数参数
- 检测标志:在函数内部使用按位与 (&) 运算检查特定标志是否被设置
这种方法最多可支持32个互不冲突的标志位,既节省内存又提高效率。例如,要传递5个标志,只需将它们按位或运算后作为单个整数参数传递即可。函数内部通过按位与运算就能准确识别每个标志的状态。
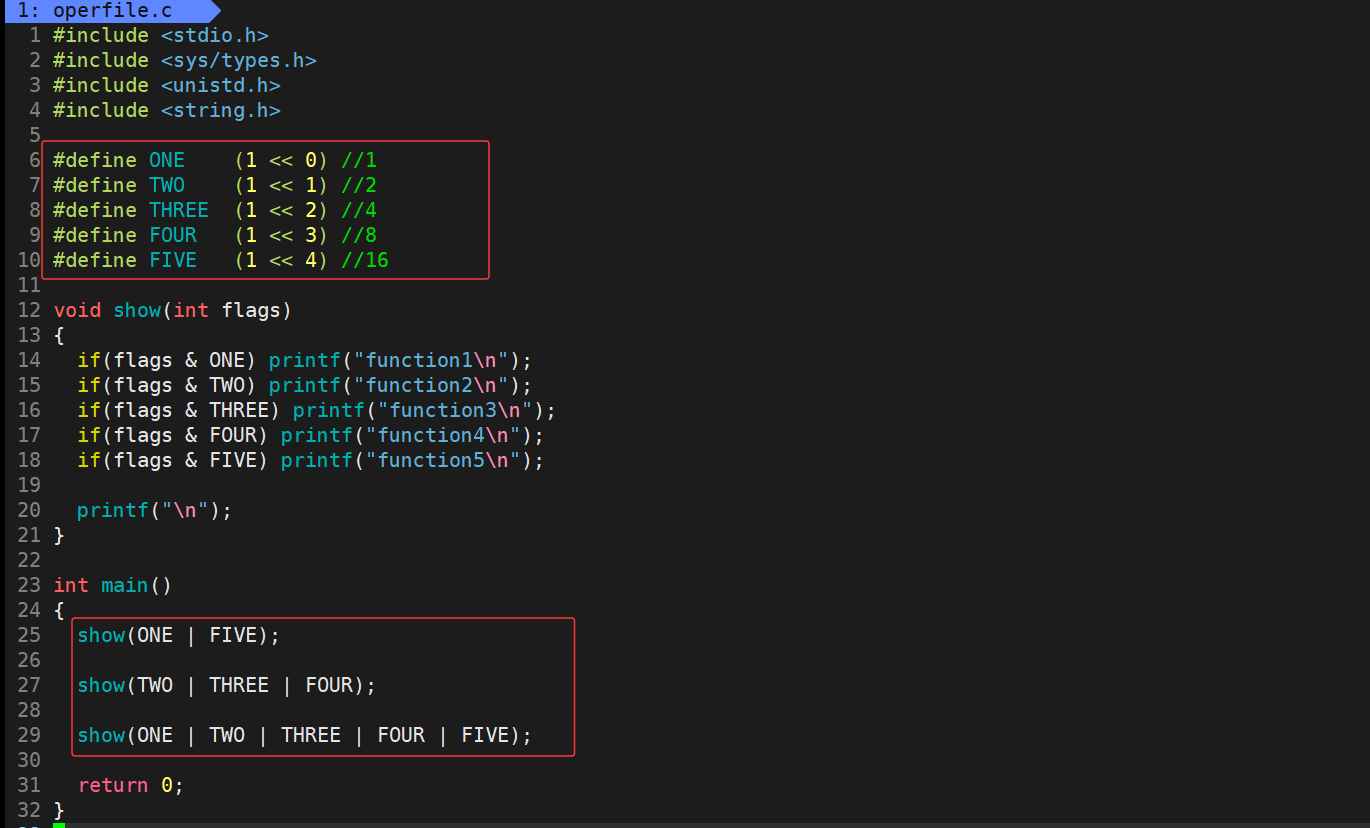
"二进制位标记法",核心是3点:
- 给每个功能分配"唯一二进制位" : 通过 1 << n (左移运算),让每个宏对应一个"只有某一位是1"的二进制数(比如 ONE=00001 、 FIVE=10000 ),确保每个宏的标识不重叠。
- 用 | 组合多个功能 : 多个宏用 | (按位或)拼接后,二进制里的"1"会保留各自的位置(比如 ONE|FIVE=10001 ),相当于同时选中多个功能。
- 用 & 判断功能是否被选中 : 通过 flags & 宏 的运算,检查对应二进制位是否为1,以此判断该功能是否需要执行(比如 flags&ONE 就是看"第1位是否为1")。
本质是用一个整数的不同二进制位,同时标记多个功能的"开关状态",既节省空间又能快速判断。
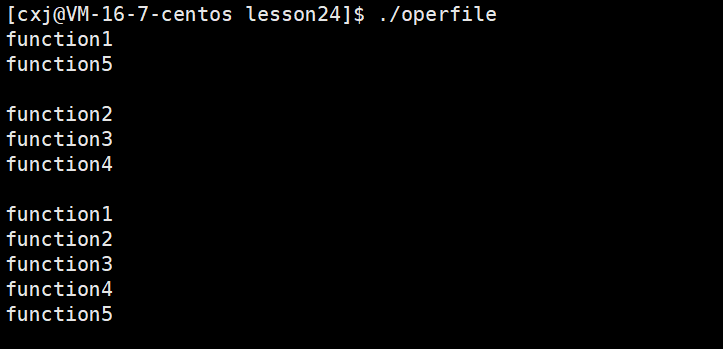
运行结果:
从运行结果中就能看出代码中 | 组合了哪些宏(功能标识),运行时就会输出对应的 function 提示,完全匹配"位标记控制功能"的设计预期。
open close
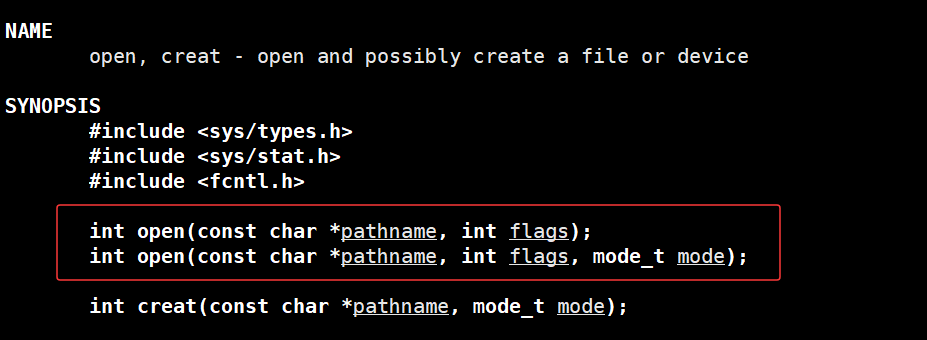
open 是定义在 Linux 系统调用手册第 2 章(即 2 号手册)中的一个重要文件系统调用函数。它主要用于打开或创建文件 ,并返回一个整数形式的文件描述符(file descriptor, 简称 fd),这个 fd 是后续进行文件读写操作的重要关键标识。
在 Linux 系统中,open系统调用实际上有两个版本,两个版本的主要区别在于参数个数:
- 第一个参数
pathname是要打开的文件路径字符串 - 第二个参数
flags是打开文件的标志位 - 第三个参数
mode(仅第二个版本有) 是在创建新文件时指定的默认权限
标志位 flag 实际上是由多个预定义的宏通过位运算组合而成的,这些宏定义在 <fcntl.h> 头文件中。我们可以使用按位或运算符 | 来组合多个标志位,原理我们已经在比特位方式传递标志位中讲解过了,下面使用红色框框出来的是我们比较常用的一些标志位
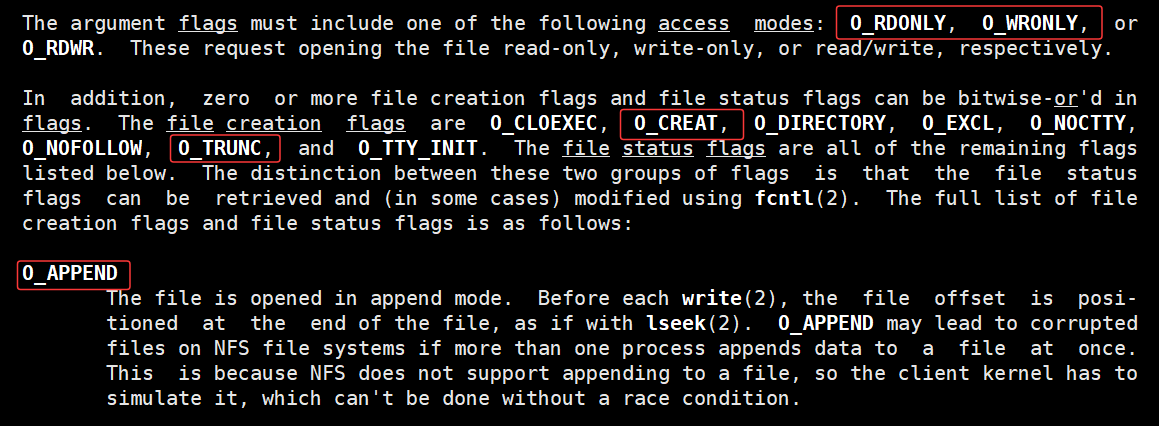
O_RDONLY 是只读,O_WRONLY 是只写 (O_RDONLY 和 O_WRONLY 和O_RDWR可读可写,这三个标志位传入的时候只能传入一个),O_CREA T 是文件不存在则在当前工作路径下创建文件 ,O_TRUNC 是将文件内容截取为0,也就是打开文件后清除文件内容 ,O_APPEND 是打开文件后从文件末尾开始追加式写入
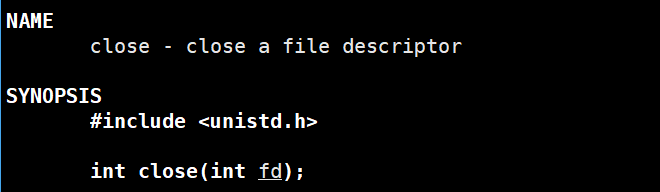
close
close 需要包含 <unistd.h> 头文件;参数 fd 是要关闭的文件描述符(由 open 等函数返回的非负整数);成功返回 0 ,失败返回 -1 。close 的作用是释放已打开的文件描述符(fd),同时会终止当前进程与该文件/设备的关联。
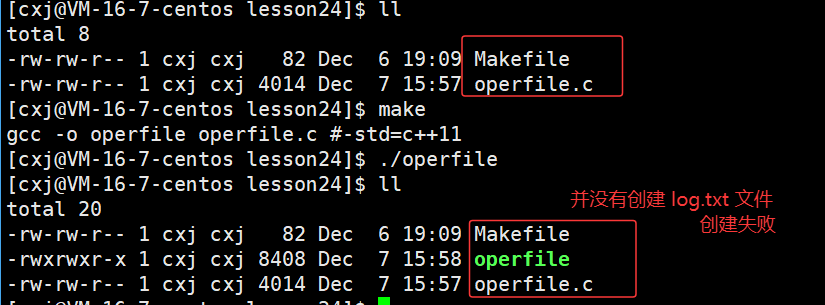
接下来我们将逐步演示如何创建、打开和关闭文件。首先,我们使用带两个参数的open函数尝试打开一个不存在的文件,并以O_WRONLY(只写)模式进行操作,观察系统是否能在当前工作目录下自动创建该文件:
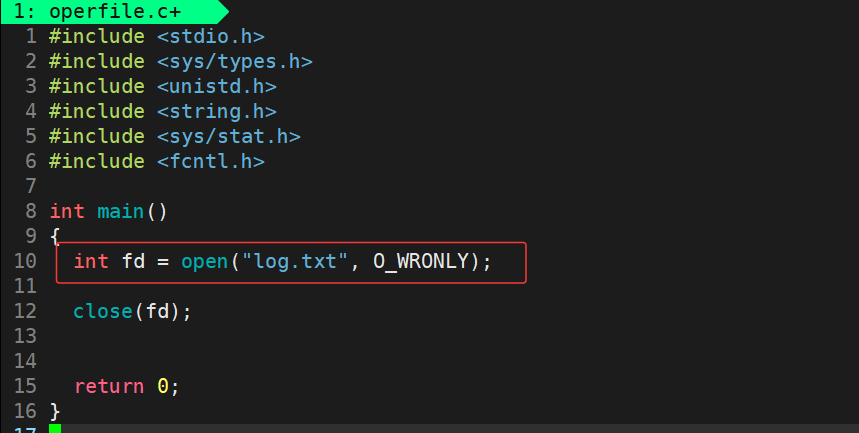
运行结果:
可以看出创建失败
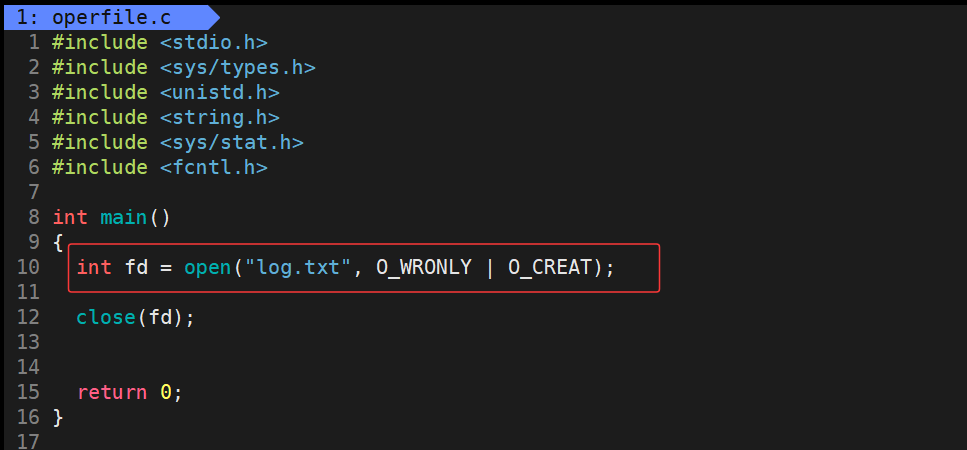
那接下来带上 O_CREAT,把这个选项通过按位与 | 的方式也带上,看看是否可以打开一个不存在的文件:
运行结果:
文件确实被创建出来了,但是,观察一下,运行后 log.txt 文件的权限是 -rws-wx--T (7531),而非预期的普通权限(如 0644 ),说明这个log.txt 文件的权限和普通文件的权限不一样,为什么呢?
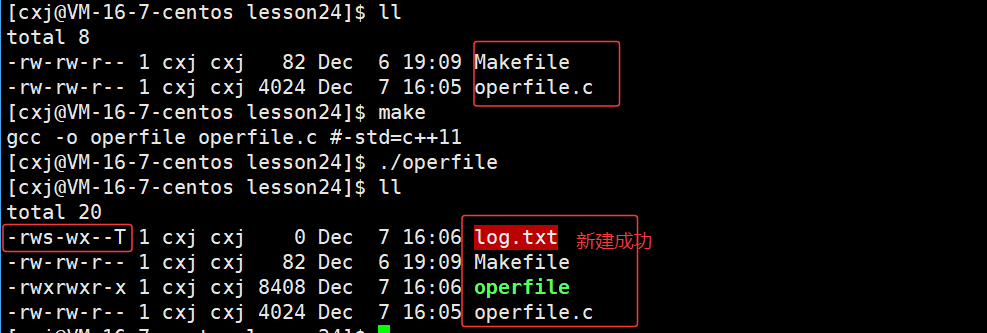
其实使用两个参数的open函数无法正确创建文件,因为文件系统调用在创建文件时需要指定默认权限 。此时应改用三个参数的open函数,其第三个参数专门用于设置文件权限 。系统默认会赋予新文件0666权限,应用在原本默认的umask掩码0002后,实际权限将变为0664。

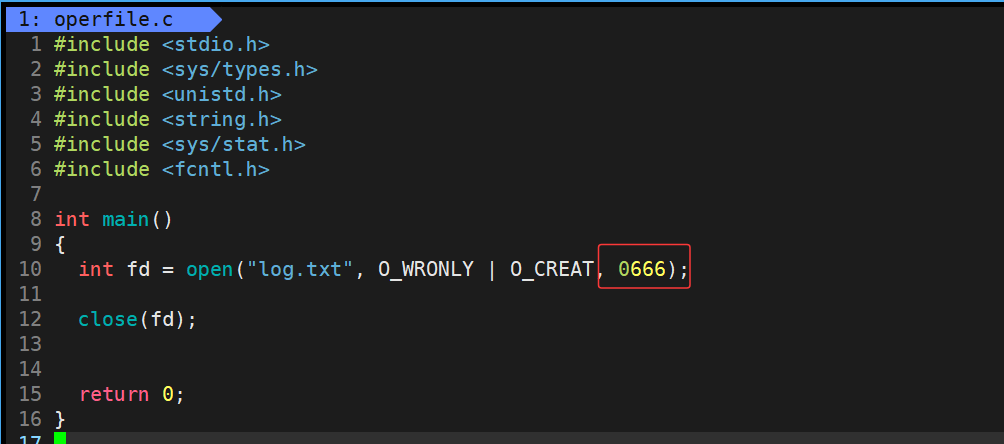
运行结果:
此时使用三个参数的open就可以成功创建一个文件了
umask
umask不仅可以查看文件掩码,而且也可以修改文件掩码,如果我们将文件掩码修改为0之后,那么新创建的文件的权限就为0666了
write
接下来,我们需要将内容写入文件。此时可以使用文件系统调用 write,只需依次传入文件描述符 fd、要写入的字符串内容以及字符串长度即可完成写入操作。
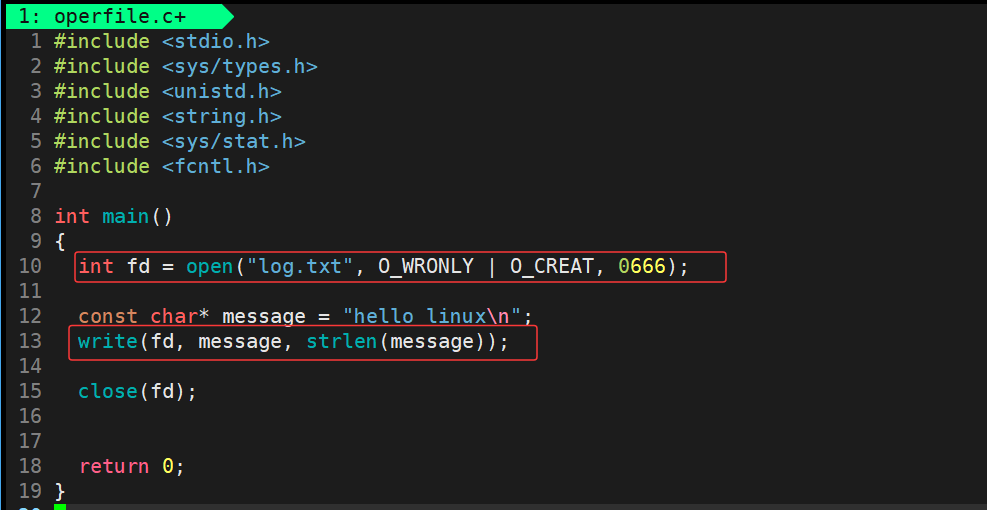
运行结果:
此时我们向文件中写入成功
可是现在我们真的实现了类似于以w方式fopen打开文件的方式了吗?实则不然,下面修改一下写入信息,我们再来观察一下现象
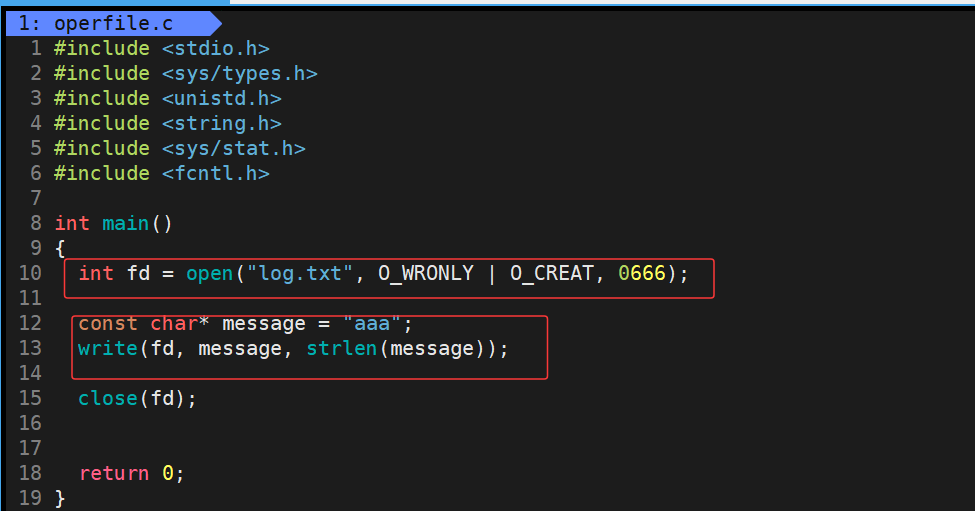
运行结果:
此时运行程序之后,原本文件的内容并没有进行清空,而是直接在文件开头覆盖式的去写,那么并不能达到类似于以w方式fopen打开文件的方式
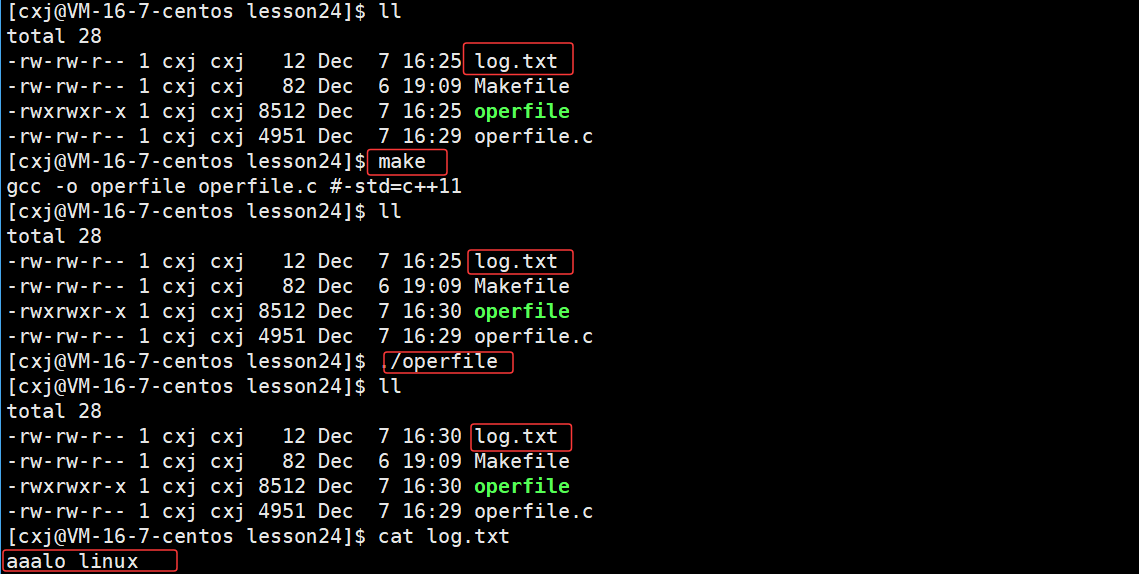
那么如果想要打开文件前对文件内容进行清空应该再使用位运算按位与 | 上宏O_TRUNC即可
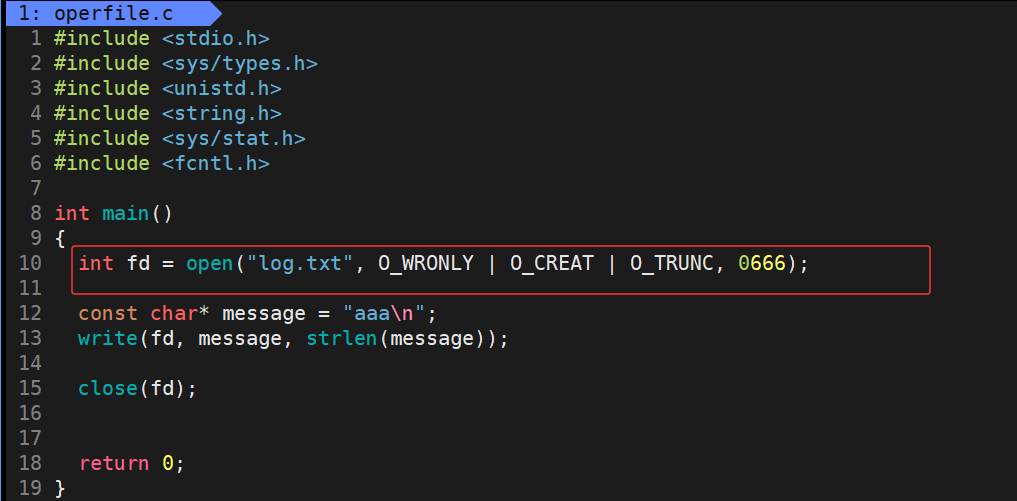
运行结果:
此时就可以达到和C语言中的以w方式fopen打开文件 的方式 (若文件已存在,则清空其内容 (截断为零长度);若不存在,则创建新文件)
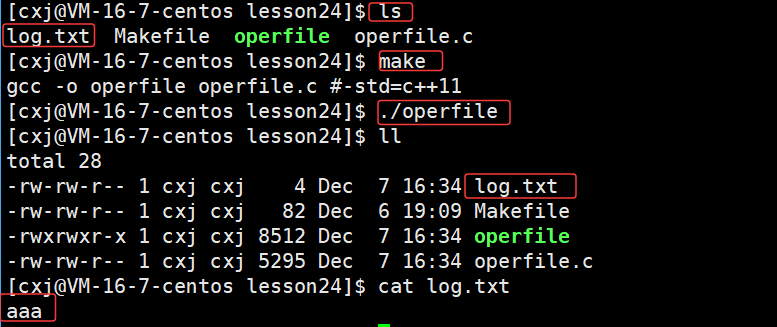
那么接下来我们尝试一下使用文件系统调用模拟实现C语言中的有以a方式fopen打开文件的方式,我们知道a方式fopen对于打开不存在的文件会在当前路径下创建一个文件 ,并且也是对文件进行写入,并且在文件结尾进行追加式的写入
所以我们在原来的基础上将宏O_TRUNC清空修改为宏O_APPEND在结尾追加即可
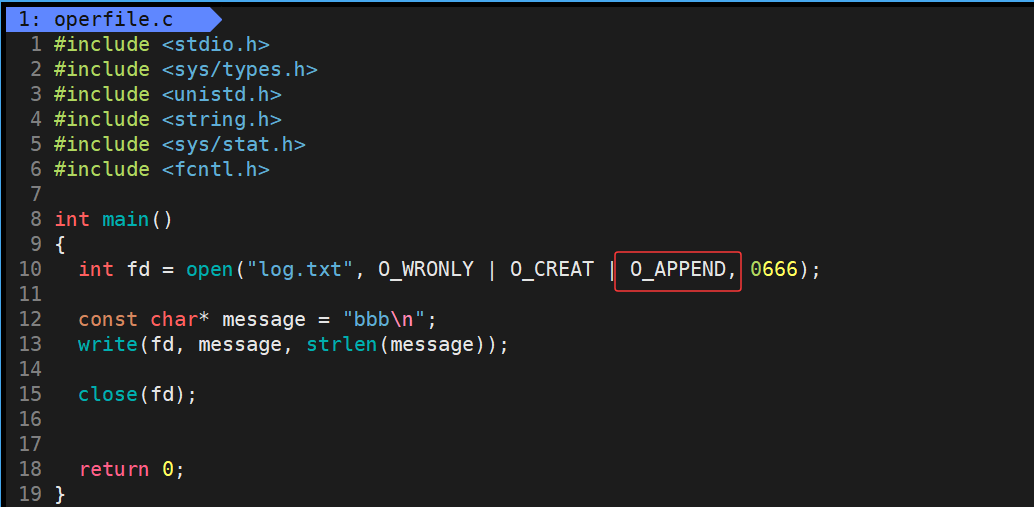
运行结果:
此时就达到了使用文件系统调用模拟实现C语言中的a方式fopen打开文件的方式,当文件不存在的时候,在当前工作路径下创建一个文件,并且写入的时候在文件的结尾,追加式的写入
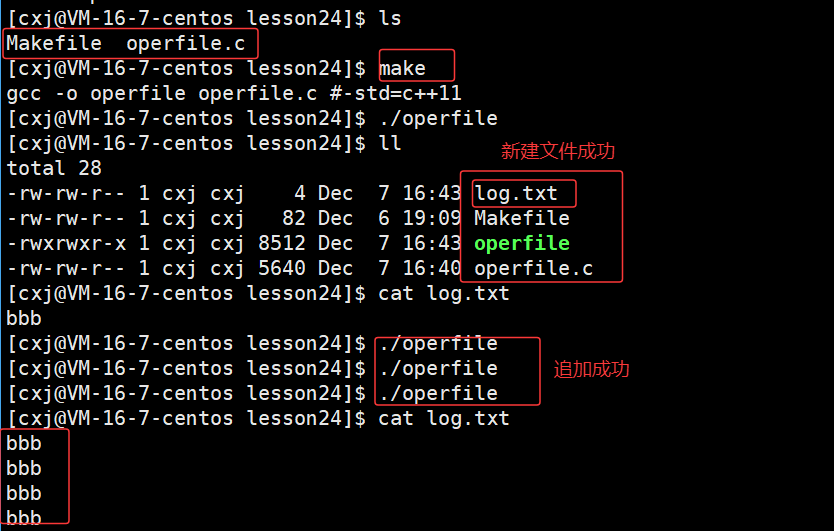
得出结论

所以根据上面,我们可以推断出,这个FILE结构体中必然封装了文件描述符fd。因为包括C语言在内的所有编程语言都是基于操作系统实现的,需要遵循系统调用规则。因此,C语言中fopen返回的FILE*指针所指向的FILE结构体,必定包含文件描述符fd。
接下来我们首先查看系统调用open的返回值,即文件描述符fd的具体数值:
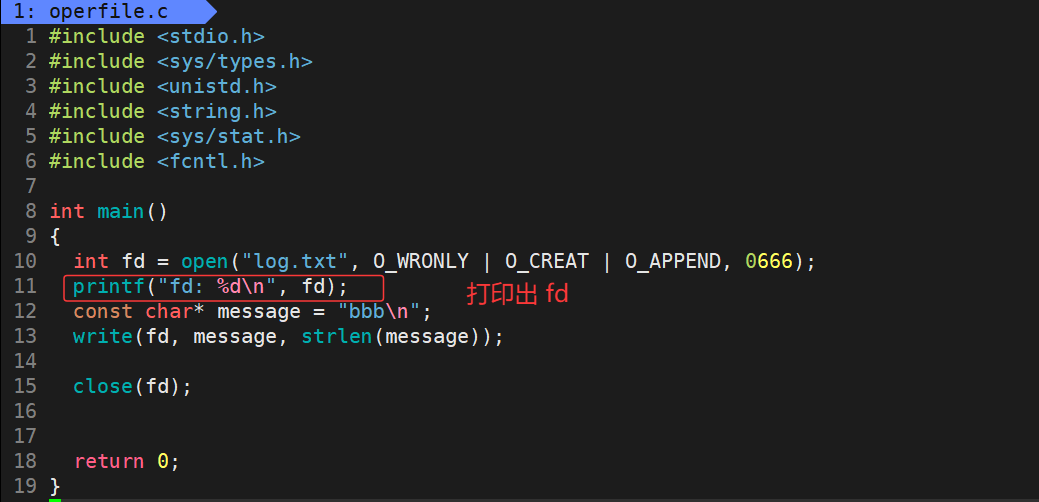
运行结果:
可以看出我们在进程内打开的这个文件的返回值,即文件描述符fd的值居然是3

下面我们再多打开几个文件,看看其返回的文件描述符fd的值是多少
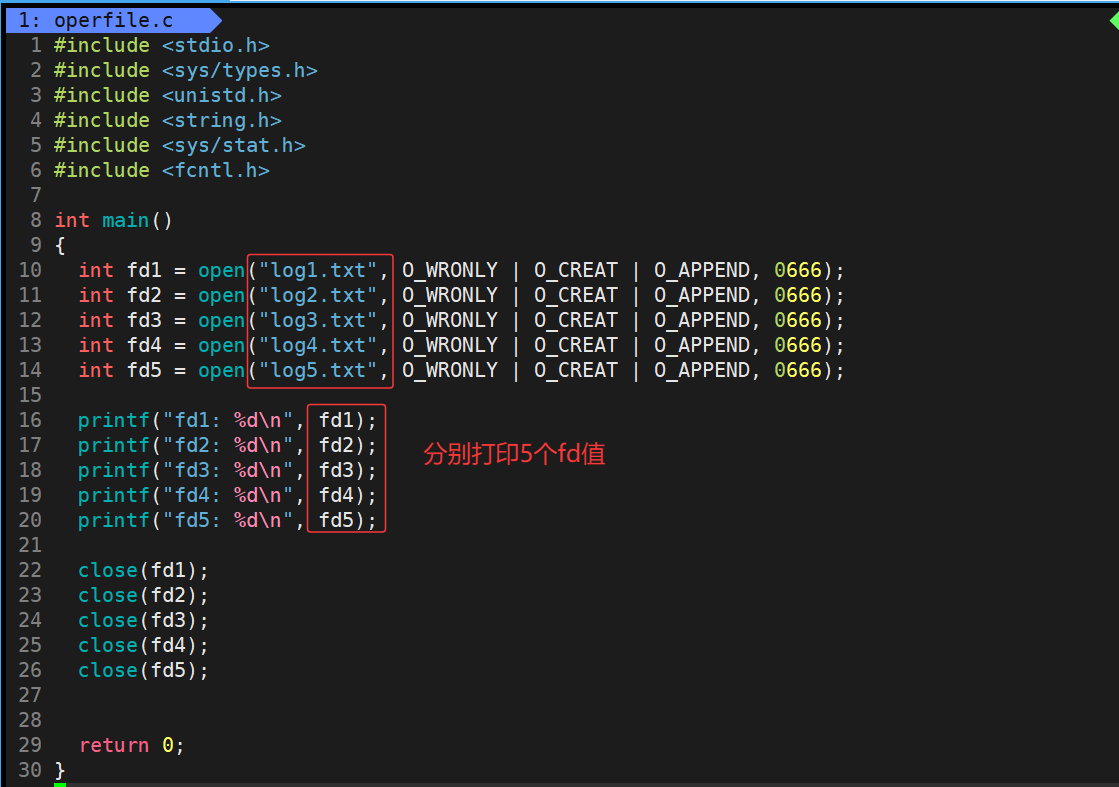
运行结果:
3,4,5,6,7这个顺序很类似于数组下标
那么前三个文件描述符(0、1、2)呢?
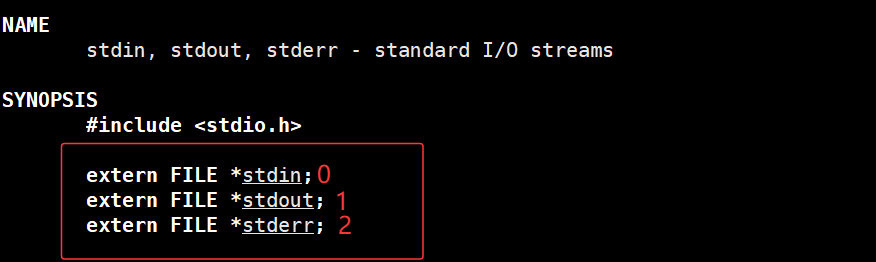
细心的我们可能已经猜到了答案:其实当程序启动时C语言默认会打开三个标准文件流,分别是stdin、stdout和stderr,对应的文件描述符正好是0、1、2。
当然这也仅仅是我们的猜测,这三个文件流的的类型是FILE*,我们知道FILE是一个C库定义的一个struct结构体,而这三个文件流的类型就是结构体指针,所以我们可以使用箭头 -> 去访问它的成员,由于FILE这个结构体封装了文件描述符fd,所以我们必然可以使用箭头 -> 去访问到它内部封装的文件描述符fd,其中这个文件描述fd对应的是一个_fileno的成员
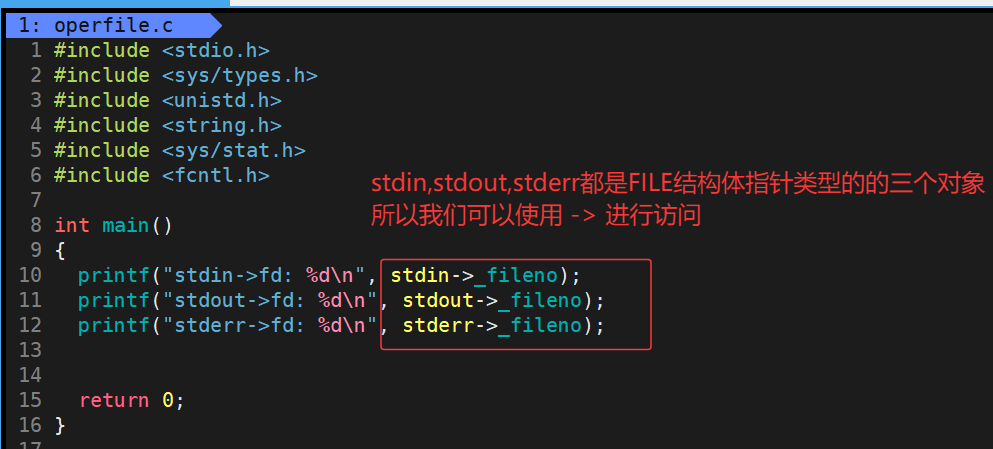
运行结果:
通过打印结果我们可以看出,噢,原来前三个0,1,2对应的真的是stdin,stdout,stderr这三个文件流
之前我们将:C程序默认在启动的时候,会为我们打开三个输入输出流(文件),也就是stdin(键盘文件),stdout(显示器文件),stderr(显示器文件)这三个文件流,但是这是C语言程序的特性吗?
C程序默认启动时会打开stdin(对应键盘) 、stdout(对应显示器)、**stderr(对应显示器)**这三个输入输出流,但这并非C语言本身的特性。
本质上,这是操作系统的进程管理特性:当计算机启动后,操作系统会先完成键盘、显示器等硬件设备的初始化;而当我们运行程序(无论是C、Python还是其他语言编写的程序)时,操作系统在创建新进程的过程中,会自动为这个进程分配3个默认的"文件描述符"(fd 0、fd 1、fd 2),并将它们分别与键盘、显示器、显示器关联------这是操作系统为了让进程能"开箱即用"地进行输入输出,提前搭建的基础通信通道。
C语言的作用,只是把操作系统提供的这3个底层文件描述符,封装成了 stdin 、 stdout 、 stderr 这三个 FILE* 类型的流指针,让程序员可以通过 printf 、 scanf 等函数更便捷地调用这些输入输出通道。
所以,这三个流的"默认打开",是操作系统给进程的基础资源,C语言只是对其做了接口层面的封装。
为什么stdout和srderr都对应的是显示器?功能上,stdout输正常内容(如printf结果),stderr输错误信息(如报错),同显于显示器让用户兼顾两类信息,拆分则避免错误被正常内容淹没;
机制上,stdout缓冲输出(攒批打印提效),stderr无缓冲(错误即时显示防丢失),确保错误信息优先、不遗漏------二者虽终点都是显示器,但分工和优先级不同,是操作系统平衡"显示需求"与"信息可靠性"的设计。

使用一下stdin,stdout,stderr对应的文件描述符0,1,2
既然我们知道其实stdin对应的文件描述符是1(对应键盘),stdout对应的文件描述符是2(对应显示器),stderr对应文件描述符的是3(对应显示器)
那么我们就可以使用文件系统调用去直接对这些文件描述符0,1,2进行使用,例如使用write直接对文件描述符1,2对应的显示器文件进行打印
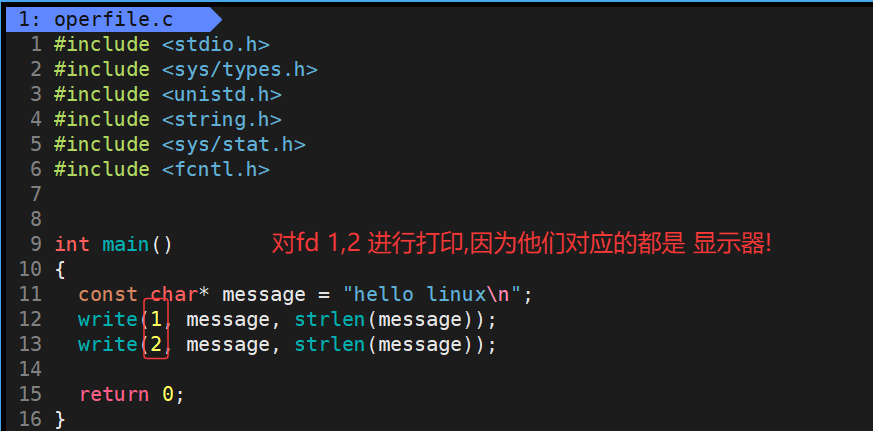
运行结果:
我们可以看出分别向fd1和fd2进行打印,均会在显示器上打印出 hello linux

read
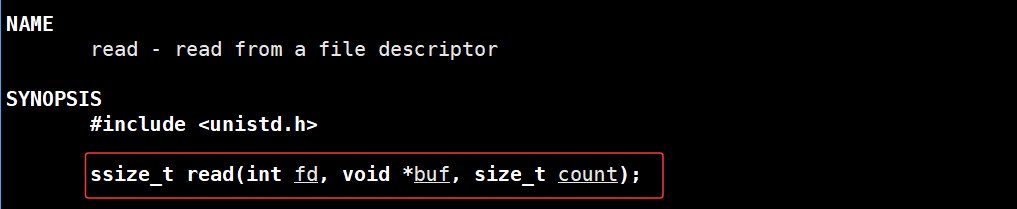
那么我们就可以使用read,从文件描述符0(对应键盘输入)读取数据,如果读取成功read会返回读取字符的个数,如果读取失败,那么会返回一个小于0的数,即-1
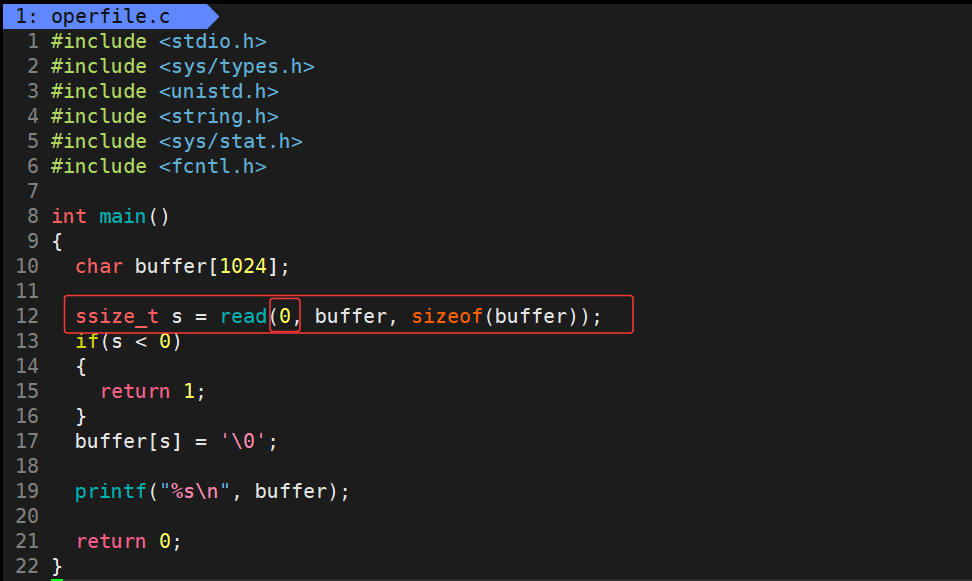
运行结果:
运行后,此时由于要从文件描述符0对应的键盘中读取数据,但是此时我们并没有进行输入数据,所以进程就会等待我们输入,即键盘资源就绪
此时我们输入数据,按下回车
此时数据就被read将数据读取进buffer字符数组内了,由于文件中并没有对于字符串以\0结尾的规定 ,由于我们使用的是C语言,c语言在内存中无法区分出字符串,所以要在字符串的结尾处添加\0作为字符串结尾的标志,此时字符串才可以正常被打印出来,需要注意的是,最后输入的换行符同样会被当作有效字符读取,所以也会被读取,所以才会出现两个换行


四、访问文件的本质
当一个进程要操作文件时,整个思路逻辑是这样的:
- 第一步:进程默认自带3个"文件描述符",每个进程启动时,内核会自动帮它打开3个基础文件:标准输入( fd=0 )、标准输出( fd=1 )、标准错误( fd=2 )。
- 第二步:进程通过"文件描述符表"管理打开的文件,进程的核心控制块PCB task_struct 里,有个 *files 指针,指向文件描述符表(struct files_struct)。这个表本质是个 struct file *fd_array\[\] 数组,当打开新文件时,内核会给这个数组分配一个"空闲下标"------这个下标就是文件描述符(fd)。
- 第三步:文件描述符对应"文件的元信息结构体",通过 fd (数组下标),能从 fd_array 里找到对应的 struct file 结构体 ------这个结构体是文件的"身份证":它直接/间接包含了文件的几乎所有属性(比如文件在磁盘的位置、读写权限、当前读写到哪了等)。这里要注意:一个进程可以打开多个文件(进程:打开的文件=1:n),所以 fd_array 会有多个下标对应不同的 struct file 。
- 第四步:操作文件前,必须把文件"加载到内存",不管是读还是写文件,都不能直接操作磁盘里的文件------内核会先把磁盘中文件的"属性+内容"加载到内存的缓冲区。后续进程对文件的读写,实际是和内存里的缓冲区交互。
- 第五步:"语言操作"和"系统操作"的底层统一,我们使用C语言的 fopen/fread/fwrite 这些函数时,底层其实是封装了系统调用;而Linux内核只认"文件描述符(fd)"------不管是语言层面还是系统层面的文件操作,最终都会落到"通过fd找到struct file,再操作内存缓冲区/磁盘文件"的逻辑上。
整个流程总结就是:进程→task_struct→文件描述符表→fd(数组下标)→struct file→内存缓冲区→磁盘文件,这就是Linux中文件操作的底层串联逻辑。
更详细点的可以拆分成下图:
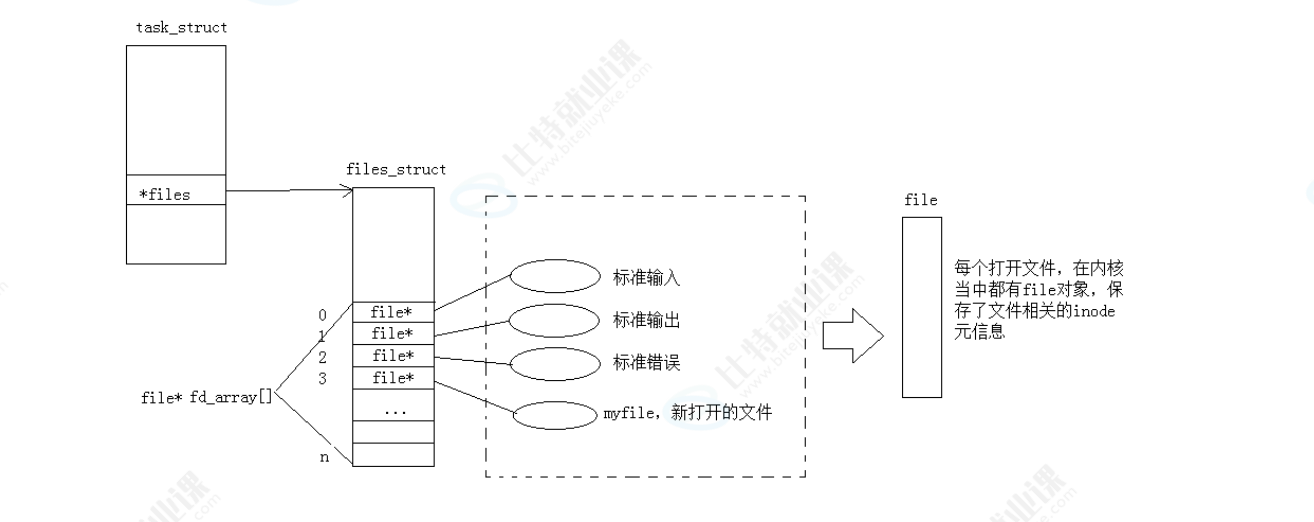
当一个进程启动后,内核会自动完成以下关联:
进程的 task_struct (控制块)通过 #files 指针,绑定到 files_struct (文件描述符表);
files_struct 里的 file* fd_array\[\] 数组 ,默认初始化前3个下标(fd):
fd=0 → 指向"标准输入"对应的 struct file ;
fd=1 → 指向"标准输出"对应的 struct file ;
fd=2 → 指向"标准错误"对应的 struct file 。
当你在进程中打开新文件(比如 myfile )时:
内核会在 fd_array 中找一个空闲下标(比如图里的 fd=3 );
同时在内核中创建一个新的 struct file 对象,用来存储 myfile 的inode元信息(磁盘位置、权限等);
把 fd_array3 的指针指向这个新的 struct file ------此时 fd=3 就成为 myfile 的文件描述符。
后续你操作 myfile 时,只需要通过 fd=3 (数组下标),就能从 fd_array 找到对应的 struct file ,再基于这个结构体操作文件的实际内容。
整个流程的核心是:进程通过"文件描述符表的数组下标(fd)",关联到内核中代表文件的 struct file ,最终实现对文件的管理。
struct file 和 FILE* 两个结构体一样吗?struct file 和 FILE* 是完全不同的两个东西,分属"内核层"和"用户层":
1. struct file :内核空间的结构体
- 它是Linux内核内部用来描述"打开的文件"的结构体(对应前两张图里的内核对象),只存在于内核空间,用户程序(比如C语言代码)无法直接访问它。
- 作用:内核通过 struct file 管理文件的元信息(如文件位置、权限、读写偏移等),文件描述符(fd)是用户层访问它的"下标索引"。
2. FILE* :用户空间的结构体
- 它是C标准库(比如glibc)在用户空间定义的结构体(属于 stdio.h 头文件),是对"文件描述符(fd)"的封装。
- 作用:fopen/fclose/fread/fwrite 这些C库函数,底层是通过 FILE* 里封装的 fd ,间接调用内核的文件操作接口(比如 open/read/write/close 系统调用),进而操作内核中的 struct file 。
联系:
- FILE* (用户层) → 封装了 fd (文件描述符) → fd 对应内核中 struct file 的数组下标 → 最终关联到内核的 struct file 。
五、总结
本文深入探讨了文件操作的系统原理和实现机制。首先从C语言层面分析了文件操作接口,包括fopen、fwrite等函数的底层实现原理,揭示了文件描述符与进程工作目录的关系。然后从Linux系统调用角度解析了open、write等接口,展示了如何使用比特位传递标志位。文章详细阐述了文件访问的本质:进程通过文件描述符表管理打开的文件,最终关联到内核的struct file结构体。同时区分了内核层的struct file和用户层的FILE*结构体,说明了两者的联系与区别。通过对比C标准库函数和系统调用,揭示了文件操作从用户空间到内核空间的完整流程。