PyTorch 机器学习工作流程 - 完整教程
文档信息
来源: Learn PyTorch for Deep Learning - Chapter 01
作者: Daniel Bourke (Zero to Mastery)
GitHub: pytorch-deep-learning
适用 PyTorch 版本: 1.12+
🎯 学习目标
完成本教程后,你将能够:
✅ 理解完整的 PyTorch 机器学习工作流程
✅ 构建、训练和评估 PyTorch 模型
✅ 实现高效的训练循环
✅ 应用最佳实践优化模型性能
✅ 保存和部署训练好的模型
✅ 调试和监控训练过程
✅ 处理实际项目中的常见问题
第一部分:核心工作流程
PyTorch 工作流程概览
机器学习的本质:从过去的数据中学习模式,用这些模式预测未来
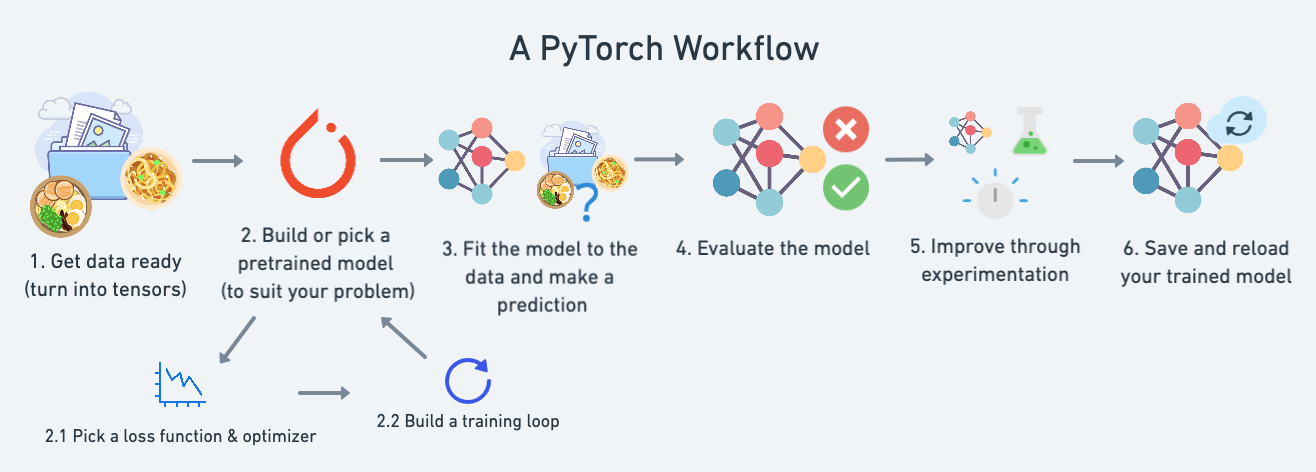
完整工作流程图
┌─────────────────────────────────────────────────────────────────┐
│ PyTorch 机器学习工作流程 │
└─────────────────────────────────────────────────────────────────┘
1. 数据准备 (Data Preparation)
├── 收集和加载数据
├── 数据清洗和转换
├── 划分训练/验证/测试集
└── 数据可视化
↓
2. 构建模型 (Build Model)
├── 定义模型架构
├── 初始化参数
└── 设置前向传播
↓
3. 训练模型 (Train Model)
├── 选择损失函数
├── 选择优化器
├── 实现训练循环
└── 实现验证循环
↓
4. 评估与预测 (Evaluate & Predict)
├── 在测试集上评估
├── 计算评估指标
├── 可视化结果
└── 进行推理预测
↓
5. 保存与部署 (Save & Deploy)
├── 保存模型参数
├── 加载模型
└── 部署到生产环境1. 数据准备与加载
1.1 机器学习的两个核心任务
任务一: 将数据转换为数字表示 (数值化)
任务二: 构建或选择模型来学习这些数字表示
1.2 环境准备
python
# 导入必要的库
import torch
from torch import nn # nn = neural networks
import matplotlib.pyplot as plt
import numpy as np
from pathlib import Path
# 检查 PyTorch 版本
print(f"PyTorch version: {torch.__version__}")
# 设置随机种子以确保可重复性
torch.manual_seed(42)1.3 创建数据集
示例: 线性回归数据
python
# 定义真实的参数 (我们的目标是让模型学习到这些值)
weight = 0.7
bias = 0.3
# 创建数据: y = wx + b (线性关系)
start = 0
end = 1
step = 0.02
# 创建特征 X
X = torch.arange(start, end, step).unsqueeze(dim=1) # shape: [50, 1]
# 创建标签 y
y = weight * X + bias # shape: [50, 1]
print(f"X shape: {X.shape}")
print(f"y shape: {y.shape}")
print(f"Number of samples: {len(X)}")
print(f"\nFirst 5 X values:\n{X[:5]}")
print(f"\nFirst 5 y values:\n{y[:5]}")输出示例:
bash
X shape: torch.Size([50, 1])
y shape: torch.Size([50, 1])
Number of samples: 50
First 5 X values:
tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800]])
First 5 y values:
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560]])1.4 数据集划分
训练集/验证集/测试集的作用
| 数据集 | 用途 | 建议比例 | 使用频率 |
|---|---|---|---|
| 训练集 (Training) | 模型从中学习模式 | 60-80% | 必须 |
| 验证集 (Validation) | 调整超参数,选择最佳模型 | 10-20% | 推荐 |
| 测试集 (Testing) | 最终评估模型性能 | 10-20% | 必须 |
实现数据划分
python
# 80% 训练, 20% 测试
train_split = int(0.8 * len(X))
# 划分数据
X_train = X[:train_split] # 前 80%
y_train = y[:train_split]
X_test = X[train_split:] # 后 20%
y_test = y[train_split:]
print(f"训练集样本数: {len(X_train)}")
print(f"测试集样本数: {len(X_test)}")更完整的数据划分<------>三分法 (推荐用于大型项目)
python
def split_data(X, y, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""
将数据集划分为训练集、验证集和测试集
参数:
X: 特征数据
y: 标签数据
train_ratio: 训练集比例 (默认 0.7, 即 70%)
val_ratio: 验证集比例 (默认 0.15, 即 15%)
test_ratio: 测试集比例 (默认 0.15, 即 15%)
返回:
X_train, y_train, X_val, y_val, X_test, y_test
"""
# 验证三个比例之和是否等于 1.0
# 使用 1e-6 作为容差值来处理浮点数精度问题
assert abs(train_ratio + val_ratio + test_ratio - 1.0) < 1e-6, \
"比例之和必须等于 1"
# 获取数据集的总样本数
n = len(X)
# 计算训练集的结束索引 (例如: 1000 * 0.7 = 700)
train_end = int(n * train_ratio)
# 计算验证集的结束索引 (例如: 1000 * (0.7 + 0.15) = 850)
val_end = int(n * (train_ratio + val_ratio))
# 划分训练集: 从开始到 train_end
X_train, y_train = X[:train_end], y[:train_end]
# 划分验证集: 从 train_end 到 val_end
X_val, y_val = X[train_end:val_end], y[train_end:val_end]
# 划分测试集: 从 val_end 到结束
X_test, y_test = X[val_end:], y[val_end:]
# 返回划分后的六个数据集
return X_train, y_train, X_val, y_val, X_test, y_test
# 使用示例: 调用函数进行数据划分
X_train, y_train, X_val, y_val, X_test, y_test = split_data(X, y)
# 打印各数据集的样本数量,验证划分结果
print(f"训练: {len(X_train)}, 验证: {len(X_val)}, 测试: {len(X_test)}")1.5 数据可视化(非常重要)
数据探索者的座右铭: "可视化,可视化,可视化!"
python
# 导入 matplotlib 并设置中文字体 解决中文乱码问题
import matplotlib.pyplot as plt
# 设置默认字体为黑体,用于正确显示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
# 解决坐标轴负号 '-' 显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
def plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
"""
绘制训练数据、测试数据和预测结果
参数:
train_data: 训练特征
train_labels: 训练标签
test_data: 测试特征
test_labels: 测试标签
predictions: 模型预测 (可选,默认为 None)
"""
# 创建图形,设置画布大小为 10x7 英寸
plt.figure(figsize=(10, 7))
# 绘制训练数据散点图
# c="b": 蓝色, s=4: 点的大小, label: 图例标签
plt.scatter(train_data, train_labels, c="b", s=4, label="训练数据")
# 绘制测试数据散点图 (绿色)
plt.scatter(test_data, test_labels, c="g", s=4, label="测试数据")
# 如果提供了预测结果,则绘制预测散点图
if predictions is not None:
# 绘制预测结果 (红色),用于对比真实测试数据
plt.scatter(test_data, predictions, c="r", s=4, label="预测")
# 添加图例,设置字体大小为 14
plt.legend(prop={"size": 14})
# 设置 X 轴标签
plt.xlabel("X")
# 设置 Y 轴标签
plt.ylabel("y")
# 设置图表标题
plt.title("数据和预测可视化")
# 添加网格线,alpha=0.3 设置透明度使网格不会过于突出
plt.grid(True, alpha=0.3)
# 调用函数可视化原始数据 (不包含预测结果)
plot_predictions()
# 显示图形
plt.show()1.6 数据加载最佳实践
使用 DataLoader 处理大型数据集
python
# 导入 PyTorch 数据加载工具
from torch.utils.data import TensorDataset, DataLoader
# 创建 Dataset 对象,将特征和标签封装在一起
# TensorDataset 会自动将 X 和 y 配对,方便批量加载
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
# 设置批次大小 (每次训练使用的样本数量)
BATCH_SIZE = 8
# 创建训练数据加载器
train_loader = DataLoader(
train_dataset, # 要加载的数据集
batch_size=BATCH_SIZE, # 每个批次的样本数量
shuffle=True, # 每个 epoch 开始时打乱数据,避免模型记住数据顺序
num_workers=2, # 使用 2 个子进程并行加载数据,加快速度
pin_memory=True # 将数据固定在内存中,加快 CPU 到 GPU 的传输速度
)
# 创建测试数据加载器
test_loader = DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
shuffle=False # 测试时不打乱数据,保持评估的一致性
)
# 查看一个 batch 的数据形状
# 使用 break 只查看第一个批次
for batch_X, batch_y in train_loader:
print(f"Batch X shape: {batch_X.shape}") # 输出: torch.Size([8, 1])
print(f"Batch y shape: {batch_y.shape}") # 输出: torch.Size([8, 1])
break # 只查看第一个批次后退出循环2. 构建模型
2.1 PyTorch 模型构建核心组件
| PyTorch 模块 | 功能说明 |
|---|---|
torch.nn |
包含构建神经网络的所有模块 |
torch.nn.Parameter |
可训练的参数,会自动计算梯度 |
torch.nn.Module |
所有神经网络的基类,神经网络的所有构建块都是子类。 |
torch.optim |
包含各种优化算法 (这些算法告诉存储在如何最好地改变以改善梯度下降,进而减少损失)中存储的模型参数。 |
def forward() |
定义前向传播的计算过程 |
2.2 线性回归模型 (手动参数版本)
python
import torch
from torch import nn
class LinearRegressionModel(nn.Module):
"""
简单的线性回归模型: y = wx + b
这是手动定义参数的版本,用于理解 PyTorch 模型的基本构建方式
继承自 nn.Module,这是所有 PyTorch 神经网络的基类
"""
def __init__(self):
# 调用父类的初始化方法,这是必须的
# 它会设置模型的基础功能(如参数追踪、设备管理等)
super().__init__()
# 初始化权重参数 (斜率 w)
# nn.Parameter: 将张量注册为模型的可学习参数
# torch.randn(1): 从标准正态分布中随机初始化一个值
# requires_grad=True: 告诉 PyTorch 在反向传播时计算此参数的梯度
self.weight = nn.Parameter(
torch.randn(1, dtype=torch.float), # 形状为 [1],单个浮点数
requires_grad=True # 启用梯度计算,使其可以通过优化器更新
)
# 初始化偏置参数 (截距 b)
# 同样使用 nn.Parameter 包装,使其成为可学习参数
self.bias = nn.Parameter(
torch.randn(1, dtype=torch.float), # 形状为 [1],单个浮点数
requires_grad=True # 启用梯度计算
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播: 定义模型如何从输入计算输出
这个方法在调用 model(x) 时会被自动执行
实现线性方程: y = weight * x + bias
参数:
x: 输入特征张量,形状可以是 [batch_size, 1] 或 [n_samples]
返回:
预测值张量,与输入形状相同
"""
# 执行线性变换: y = wx + b
# PyTorch 会自动进行广播 (broadcasting)
return self.weight * x + self.bias
# ==================== 使用模型 ====================
# 设置随机种子,确保每次运行结果一致(可重复性)
torch.manual_seed(42)
# 创建模型实例
model_0 = LinearRegressionModel()
# 打印模型结构,显示模型的层次和参数
print(f"模型结构:\n{model_0}")
# 打印初始参数值(随机初始化的)
print(f"\n初始参数:")
print(f" 权重 (weight): {model_0.weight}")
print(f" 偏置 (bias): {model_0.bias}")
# 获取所有可学习参数的列表
# 返回一个迭代器,包含所有 requires_grad=True 的参数
list(model_0.parameters())
# 获取模型的状态字典
# 返回一个字典,键是参数名,值是参数张量
# 常用于保存和加载模型
model_0.state_dict()2.3 线性回归模型 (使用 nn.Linear)
python
class LinearRegressionModelV2(nn.Module):
"""
使用 nn.Linear 的线性回归模型 (推荐方式)
nn.Linear 是 PyTorch 内置的线性层,会自动处理权重和偏置的初始化
这是实际开发中的标准做法,比手动定义参数更简洁且更不容易出错
"""
def __init__(self):
# 调用父类初始化
super().__init__()
# 创建线性层
# nn.Linear 会自动创建并初始化 weight 和 bias 参数
# 内部实现: y = x @ weight.T + bias
self.linear_layer = nn.Linear(
in_features=1, # 输入特征的维度(每个样本有 1 个特征)
out_features=1 # 输出特征的维度(预测 1 个值)
)
# 注意: nn.Linear 的 weight 形状是 [out_features, in_features]
# 这里是 [1, 1],bias 形状是 [out_features],这里是 [1]
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播: 将输入传递给线性层
参数:
x: 输入特征张量
返回:
线性层的输出(预测值)
"""
# 直接调用线性层进行计算
# 等价于: weight * x + bias
return self.linear_layer(x)
# ==================== 使用模型 ====================
# 设置随机种子以保证可重复性
torch.manual_seed(42)
# 创建模型实例
model_1 = LinearRegressionModelV2()
# 打印模型结构
# 会显示 LinearRegressionModelV2 包含一个 Linear 层
print(f"模型结构:\n{model_1}")
# 打印线性层的参数信息
print(f"\nLinear 层参数:")
# named_parameters() 返回参数名称和参数张量的迭代器
for name, param in model_1.named_parameters():
print(f" {name}: {param.shape}")
# 输出示例:
# linear_layer.weight: torch.Size([1, 1])
# linear_layer.bias: torch.Size([1])2.4 查看模型信息
python
def model_info(model):
"""
打印模型的详细信息
这个工具函数用于检查模型的结构、参数和状态
在调试和理解模型时非常有用
参数:
model: PyTorch 模型实例 (nn.Module)
"""
print("=" * 70)
print("模型信息")
print("=" * 70)
# ==================== 1. 模型结构 ====================
# 打印模型的层次结构和组成
# 会显示模型类名和所有子模块
print(f"\n模型结构:\n{model}\n")
# ==================== 2. 参数详情 ====================
print("参数详情:")
total_params = 0 # 用于累计总参数数量
# named_parameters() 返回 (参数名, 参数张量) 的迭代器
# 只包含 requires_grad=True 的参数
for name, param in model.named_parameters():
print(f" {name}:") # 参数名称,如 'linear_layer.weight'
# param.shape: 参数张量的形状,如 torch.Size([1, 1])
print(f" 形状: {param.shape}")
# param.numel(): 参数中元素的总数 (number of elements)
# 例如 [3, 4] 形状的张量有 12 个元素
print(f" 数量: {param.numel()}")
# param.requires_grad: 是否需要计算梯度
# True 表示这个参数会在训练中被更新
print(f" 需要梯度: {param.requires_grad}")
# param.data: 参数的实际数值(不带梯度信息)
# 直接访问张量的值,不会构建计算图
print(f" 当前值: {param.data}\n")
# 累加参数数量
total_params += param.numel()
# 打印总参数量
# 对于复杂模型,这个数字可能达到数百万甚至数十亿
print(f"总参数量: {total_params}")
# ==================== 3. 状态字典 ====================
# state_dict() 返回模型所有参数的字典
# 键是参数名(字符串),值是参数张量
# 这是保存和加载模型的标准方式
print(f"\n状态字典:\n{model.state_dict()}")
# 输出示例: OrderedDict([('linear_layer.weight', tensor([[...]]),
# ('linear_layer.bias', tensor([...]))])
print("=" * 70)
# ==================== 使用示例 ====================
# 调用函数查看 model_1 的详细信息
# 这会显示 LinearRegressionModelV2 的所有参数和结构
model_info(model_1)2.5 使用未训练模型进行预测
python
# ==================== 使用未训练模型进行预测 ====================
# 目的: 查看随机初始化的模型预测效果(作为基线对比)
# 将模型设置为评估模式
# eval() 会关闭某些训练时才需要的功能(如 Dropout、BatchNorm)
# 虽然这个简单模型没有这些层,但养成好习惯很重要
model_1.eval()
# 使用推理模式进行预测
# torch.inference_mode() 是推荐的推理上下文管理器
# 作用:
# 1. 禁用梯度计算,节省内存和计算资源
# 2. 比 torch.no_grad() 更快,因为它完全禁用了自动求导引擎
# 3. 适用于不需要反向传播的场景(如预测、验证)
# 4. 以加快前向传播 (数据通过 forward() 方法)的速度
with torch.inference_mode():
# 将测试数据传入模型进行预测
# model_1(X_test) 会自动调用 forward() 方法
y_preds = model_1(X_test)
# 打印前 5 个预测值
# 由于模型未训练,参数是随机的,预测结果会很差
print(f"预测值 (前5个):\n{y_preds[:5]}")
# 打印前 5 个真实值,用于对比
print(f"\n真实值 (前5个):\n{y_test[:5]}")
# ==================== 可视化预测结果 ====================
# 调用之前定义的绘图函数,可视化预测效果
# 未训练的模型预测应该是一条随机的直线,与真实数据相差很远
plot_predictions(predictions=y_preds)
plt.title("未训练模型的预测 (应该很差)")
plt.show()
# 注意: 这个可视化展示了训练的必要性
# 通过对比训练前后的预测,可以直观看到模型学习的效果2.6 模型设备管理
python
# ==================== 设备检测 ====================
# 检查是否有 NVIDIA GPU 可用
# torch.cuda.is_available() 返回 True 表示系统有可用的 CUDA GPU
# GPU 可以大幅加速深度学习训练(通常快 10-100 倍)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备: {device}")
# 其他设备选项:
# - "mps": Apple Silicon (M1/M2) 的 Metal Performance Shaders
# - "cpu": CPU(所有系统都支持,但速度较慢)
# ==================== 将模型移动到设备 ====================
# .to(device) 方法将模型的所有参数和缓冲区移动到指定设备
# 这是一个就地操作(in-place),但通常习惯重新赋值
# 注意: 模型和数据必须在同一设备上才能进行计算
model_1 = model_1.to(device)
# ==================== 将数据移动到设备 ====================
# 同样需要将训练和测试数据移动到相同设备
# 如果模型在 GPU 上,数据也必须在 GPU 上
# .to() 会创建数据的副本并移动到目标设备
# 移动训练数据
X_train = X_train.to(device)
y_train = y_train.to(device)
# 移动测试数据
X_test = X_test.to(device)
y_test = y_test.to(device)
# ==================== 验证设备位置 ====================
# 检查模型参数所在的设备
# next(model_1.parameters()) 获取模型的第一个参数
# .device 属性显示张量所在的设备
print(f"模型设备: {next(model_1.parameters()).device}")
# 检查数据所在的设备
# 确保模型和数据在同一设备上,否则会报错
print(f"数据设备: {X_train.device}")
# 常见错误: RuntimeError: Expected all tensors to be on the same device
# 解决方法: 确保模型和所有输入数据都在同一设备上3. 训练模型
3.1 损失函数
损失函数 (Loss Function): 衡量模型预测与真实值之间的差距
常用损失函数(torch.nn 中内置了许多损失函数)
| 损失函数 | PyTorch 实现 | 数学公式 | 适用场景 | 特点 |
|---|---|---|---|---|
| 均方误差 (MSE) | nn.MSELoss() |
(1/n)Σ(ŷ-y)² |
回归问题 | 对异常值敏感、梯度平滑 |
| 平均绝对误差 (MAE) | nn.L1Loss() |
`(1/n)Σ | ŷ-y | ` |
| Huber 损失 | nn.HuberLoss() |
MSE+MAE 结合 | 回归(有异常值) | 结合 MSE 和 MAE 优点 |
| 交叉熵损失 | nn.CrossEntropyLoss() |
-Σy·log(ŷ) |
多分类问题 | 包含 Softmax,输入为 logits |
| 负对数似然 | nn.NLLLoss() |
-log(ŷ) |
多分类(已 Softmax) | 需要先手动 Softmax |
| 二元交叉熵 | nn.BCELoss() |
-[y·log(ŷ)+(1-y)·log(1-ŷ)] |
二分类(已 Sigmoid) | 输入需在 0,1 范围 |
| 二元交叉熵 (带 logits) | nn.BCEWithLogitsLoss() |
BCE + Sigmoid | 二分类 | 更稳定(数值稳定性) |
| 平滑 L1 损失 | nn.SmoothL1Loss() |
Huber 变体 | 目标检测、回归 | 用于 Faster R-CNN 等 |
选择建议:
- 回归任务(无异常值) :
nn.MSELoss() - 回归任务(有异常值) :
nn.L1Loss()或nn.HuberLoss() - 多分类 :
nn.CrossEntropyLoss()(最常用) - 二分类 :
nn.BCEWithLogitsLoss()(推荐)或nn.BCELoss()
python
# ==================== 创建损失函数 ====================
# 损失函数用于量化模型预测与真实值之间的差距
# 训练的目标就是最小化这个损失值
# nn.L1Loss() 计算平均绝对误差 (Mean Absolute Error, MAE)
# 公式: MAE = (1/n) * Σ|y_pred - y_true|
# 特点:
# - 对所有误差一视同仁(线性惩罚)
# - 对异常值不敏感(相比 MSE)
# - 适合回归问题
loss_fn = nn.L1Loss()
# 另一个常用选项: nn.MSELoss() - 均方误差
# 公式: MSE = (1/n) * Σ(y_pred - y_true)²
# 特点: 对大误差惩罚更重(平方惩罚),对异常值敏感
# ==================== 手动计算初始损失 ====================
# 在训练前先看看未训练模型的损失有多大(作为基线)
# 使用推理模式进行预测(不需要梯度)
with torch.inference_mode():
# 前向传播: 使用训练数据进行预测
y_pred = model_1(X_train)
# 计算损失: 比较预测值和真实值
# loss_fn 接收两个参数: (预测值, 真实值)
loss = loss_fn(y_pred, y_train)
# 打印初始损失值
# 这个值应该比较大,因为模型参数是随机初始化的
print(f"初始损失: {loss}")
# 训练的目标就是让这个损失值尽可能小
# 注意: 损失值的大小取决于:
# 1. 数据的尺度(值的范围)
# 2. 损失函数的类型
# 3. 模型的初始化3.2 优化器(torch.optim 中找到各种优化函数的实现。)
优化器 (Optimizer): 使用梯度来更新模型参数,以降低损失值。
常用优化器
| 优化器 | PyTorch 实现 | 特点 | 适用场景 | 典型学习率 |
|---|---|---|---|---|
| SGD | torch.optim.SGD() |
最基础、稳定、需要手动调整学习率 | 简单任务、计算机视觉 | 0.01 - 0.1 |
| SGD + Momentum | torch.optim.SGD(momentum=0.9) |
加速收敛、减少震荡 | CV 任务、ResNet 等 | 0.01 - 0.1 |
| Adam | torch.optim.Adam() |
自适应学习率、最流行、收敛快 | 大多数任务(2024推荐) | 0.001 - 0.0001 |
| AdamW | torch.optim.AdamW() |
Adam + 正确的权重衰减 | NLP、Transformers(2024推荐) | 0.001 - 0.0001 |
| RMSprop | torch.optim.RMSprop() |
自适应学习率、适合非平稳目标 | RNN、强化学习 | 0.001 - 0.01 |
| Adagrad | torch.optim.Adagrad() |
自适应学习率、适合稀疏梯度 | 稀疏数据、NLP | 0.01 |
选择建议:
- 初学者/不确定 :使用
Adam,lr=0.001 - 计算机视觉 :
SGD + Momentum,lr=0.01 - NLP/Transformers :
AdamW,lr=0.0001 - 简单回归/分类 :
SGD,lr=0.01
python
# ==================== 创建优化器 ====================
# 优化器负责根据梯度更新模型参数
# 它决定了参数如何朝着减小损失的方向移动
# torch.optim.SGD: 随机梯度下降 (Stochastic Gradient Descent)
# 这是最基础的优化算法,更新公式: θ = θ - lr * ∇θ
# 其中 θ 是参数,lr 是学习率,∇θ 是梯度
optimizer = torch.optim.SGD(
params=model_1.parameters(), # 传入模型的所有可训练参数
# model_1.parameters() 返回所有 requires_grad=True 的参数
lr=0.01 # 学习率 (learning rate) - 控制参数更新的步长
# 太大: 可能错过最优解,训练不稳定
# 太小: 训练速度慢,可能陷入局部最优
# 典型值: 0.001 到 0.1 之间
)
# 其他常用参数:
# - momentum: 动量,帮助加速收敛和跳出局部最优 (如 momentum=0.9)
# - weight_decay: 权重衰减,L2 正则化,防止过拟合 (如 weight_decay=1e-4)
# ==================== 查看优化器信息 ====================
# 打印优化器的配置信息
print(f"优化器: {optimizer}")
# 获取学习率
# param_groups 是一个列表,包含参数组的配置
# 通常只有一个组 (索引 0),但可以为不同层设置不同的学习率
print(f"学习率: {optimizer.param_groups[0]['lr']}")
# 注意: 优化器必须知道要优化哪些参数
# 如果模型参数改变了(如添加新层),需要重新创建优化器3.3 训练循环 (核心)
训练循环的标准步骤
训练阶段(Training Loop):
-
前向传播 (Forward Pass)
- 将数据传入模型:
y_pred = model(X_train) - 模型计算预测值
- 自动调用
forward()方法
- 将数据传入模型:
-
计算损失 (Calculate Loss)
- 比较预测值和真实值:
loss = loss_fn(y_pred, y_train) - 量化模型的预测误差
- 损失值越小,模型越好
- 比较预测值和真实值:
-
清零梯度 (Zero Gradients) ⚠️ 关键步骤
- 调用:
optimizer.zero_grad() - 原因:PyTorch 默认会累积梯度
- 如果不清零,梯度会叠加,导致错误的参数更新
- 调用:
-
反向传播 (Backpropagation)
- 调用:
loss.backward() - 计算损失相对于每个参数的梯度(∂loss/∂θ)
- 使用链式法则自动计算梯度
- 梯度存储在
parameter.grad中
- 调用:
-
更新参数 (Optimizer Step)
- 调用:
optimizer.step() - 使用计算出的梯度更新参数
- 更新公式(SGD):
θ = θ - lr * ∇θ - 参数朝着减小损失的方向移动
- 调用:
评估阶段(Evaluation/Testing):
-
前向传播(不计算梯度)
- 使用
torch.inference_mode()或torch.no_grad() - 节省内存,加快速度
- 不构建计算图
- 使用
-
计算损失
- 评估模型在测试集上的表现
- 用于监控过拟合
关键区别:
- 训练阶段:需要梯度,更新参数
- 评估阶段:不需要梯度,只计算损失
基础训练循环实现
python
# ==================== 训练设置 ====================
# 设置训练轮数(epoch)
# 一个 epoch 表示模型看过所有训练数据一次
epochs = 100
# ==================== 初始化记录列表 ====================
# 用于记录训练过程中的指标,便于后续可视化和分析
epoch_count = [] # 记录 epoch 编号
train_loss_values = [] # 记录每个 epoch 的训练损失
test_loss_values = [] # 记录每个 epoch 的测试损失
# ==================== 打印训练信息表头 ====================
print("开始训练...")
print(f"{'Epoch':<6} {'训练损失':<12} {'测试损失':<12}")
print("-" * 35)
# ==================== 主训练循环 ====================
for epoch in range(epochs):
# ========== 训练阶段 ==========
# 将模型设置为训练模式
# train() 会启用 Dropout、BatchNorm 等训练时才需要的层
model_1.train()
# 步骤 1: 前向传播
# 将训练数据传入模型,计算预测值
y_pred = model_1(X_train)
# 步骤 2: 计算损失
# 比较预测值和真实值,量化模型的预测误差
loss = loss_fn(y_pred, y_train)
# 步骤 3: 清零梯度 ⚠️ 重要!
# PyTorch 默认会累积梯度,必须在每次反向传播前清零
# 否则梯度会叠加,导致错误的参数更新
optimizer.zero_grad()
# 步骤 4: 反向传播
# 计算损失相对于每个参数的梯度
# 使用链式法则自动计算 ∂loss/∂θ
loss.backward()
# 步骤 5: 更新参数
# 优化器使用计算出的梯度更新模型参数
# SGD 更新: θ = θ - lr * ∇θ
optimizer.step()
# ========== 评估阶段 ==========
# 将模型设置为评估模式
# eval() 会关闭 Dropout、BatchNorm 等训练专用功能
model_1.eval()
# 使用推理模式进行评估(不需要计算梯度)
with torch.inference_mode():
# 步骤 1: 前向传播(测试集)
# 使用测试数据进行预测
test_pred = model_1(X_test)
# 步骤 2: 计算测试损失
# 评估模型在未见过的数据上的表现
test_loss = loss_fn(test_pred, y_test)
# ========== 记录和打印 ==========
# 每 10 个 epoch 记录一次损失值
if epoch % 10 == 0:
epoch_count.append(epoch)
# .item() 将张量转换为 Python 标量
# 用于记录和打印,避免保存整个计算图
train_loss_values.append(loss.item())
test_loss_values.append(test_loss.item())
# 打印当前训练进度
# .4f 表示保留 4 位小数
print(f"{epoch:<6} {loss.item():<12.4f} {test_loss.item():<12.4f}")
print("\n训练完成!")
# 注意事项:
# 1. 训练损失应该逐渐下降
# 2. 如果测试损失开始上升,可能出现过拟合
# 3. 如果两者都不下降,可能需要调整学习率或模型结构3.4 可视化训练过程
python
def plot_loss_curves(epoch_count, train_loss, test_loss):
"""
绘制训练和测试损失曲线
这个函数用于可视化模型的训练过程,帮助诊断训练问题:
- 训练损失和测试损失都下降:模型正常学习 ✓
- 训练损失下降,测试损失上升:过拟合 ⚠️
- 两者都不下降:欠拟合或学习率问题 ⚠️
- 损失震荡:学习率可能太大 ⚠️
参数:
epoch_count: epoch 编号列表
train_loss: 训练损失列表
test_loss: 测试损失列表
"""
# 创建画布,设置图形大小(宽10英寸,高7英寸)
plt.figure(figsize=(10, 7))
# 绘制训练损失曲线
# label: 图例标签
# color: 线条颜色
plt.plot(epoch_count, train_loss, label="训练损失", color="blue")
# 绘制测试损失曲线
plt.plot(epoch_count, test_loss, label="测试损失", color="orange")
# 设置图表标题
plt.title("训练和测试损失曲线", fontsize=14)
# 设置 x 轴标签(训练轮数)
plt.xlabel("Epoch", fontsize=12)
# 设置 y 轴标签(损失值)
plt.ylabel("损失", fontsize=12)
# 显示图例(区分训练损失和测试损失)
plt.legend()
# 添加网格线,alpha 控制透明度(0-1)
# 网格线帮助更准确地读取数值
plt.grid(True, alpha=0.3)
# 显示图形
plt.show()
# ==================== 绘制损失曲线 ====================
# 调用函数,可视化训练过程
# 通过观察曲线可以判断:
# 1. 模型是否收敛
# 2. 是否需要更多训练轮数
# 3. 是否出现过拟合
plot_loss_curves(epoch_count, train_loss_values, test_loss_values)3.5 完整的训练函数 (生产级)
python
def train_model(model,
train_loader,
test_loader,
loss_fn,
optimizer,
epochs,
device="cpu",
print_every=10):
"""
训练 PyTorch 模型的完整函数(生产级实现)
这是一个通用的训练函数,支持:
- 批量训练(使用 DataLoader)
- 设备管理(CPU/GPU)
- 训练历史记录
- 定期评估和打印
参数:
model: PyTorch 模型(nn.Module 实例)
train_loader: 训练数据加载器(DataLoader)
test_loader: 测试数据加载器(DataLoader)
loss_fn: 损失函数(如 nn.L1Loss())
optimizer: 优化器(如 torch.optim.SGD)
epochs: 训练轮数(整数)
device: 训练设备,"cpu" 或 "cuda"(默认 "cpu")
print_every: 每隔多少个 epoch 打印一次(默认 10)
返回:
results: 字典,包含训练历史
- "train_loss": 训练损失列表
- "test_loss": 测试损失列表
- "epoch": epoch 编号列表
"""
# ==================== 初始化设置 ====================
# 将模型移动到指定设备(CPU 或 GPU)
# 这确保模型参数和输入数据在同一设备上
model = model.to(device)
# 初始化结果字典,用于记录训练历史
# 这些数据可用于后续的可视化和分析
results = {
"train_loss": [], # 每个 epoch 的平均训练损失
"test_loss": [], # 每个 epoch 的平均测试损失
"epoch": [] # epoch 编号
}
# ==================== 主训练循环 ====================
for epoch in range(epochs):
# ========== 训练阶段 ==========
# 设置模型为训练模式
# 启用 Dropout、BatchNorm 等训练专用层
model.train()
# 初始化训练损失累加器
# 用于计算整个 epoch 的平均损失
train_loss = 0
# 遍历训练数据的所有批次
# enumerate 返回 (批次索引, (特征, 标签))
for batch, (X, y) in enumerate(train_loader):
# 将当前批次的数据移动到设备
# 确保数据和模型在同一设备上
X, y = X.to(device), y.to(device)
# 步骤 1: 前向传播
# 将批次数据传入模型,计算预测值
y_pred = model(X)
# 步骤 2: 计算损失
# 比较预测值和真实值
loss = loss_fn(y_pred, y)
# 累加当前批次的损失
# .item() 将张量转换为 Python 数值
train_loss += loss.item()
# 步骤 3: 清零梯度
# 清除上一批次的梯度,防止累积
optimizer.zero_grad()
# 步骤 4: 反向传播
# 计算损失相对于每个参数的梯度
loss.backward()
# 步骤 5: 更新参数
# 使用计算出的梯度更新模型参数
optimizer.step()
# 计算平均训练损失
# len(train_loader) 返回批次数量
train_loss /= len(train_loader)
# ========== 测试/评估阶段 ==========
# 设置模型为评估模式
# 关闭 Dropout、BatchNorm 等训练专用功能
model.eval()
# 初始化测试损失累加器
test_loss = 0
# 使用推理模式(不计算梯度)
# 节省内存和计算资源
with torch.inference_mode():
# 遍历测试数据的所有批次
for X, y in test_loader:
# 将数据移动到设备
X, y = X.to(device), y.to(device)
# 前向传播:计算预测值
test_pred = model(X)
# 计算测试损失
loss = loss_fn(test_pred, y)
# 累加当前批次的测试损失
test_loss += loss.item()
# 计算平均测试损失
test_loss /= len(test_loader)
# ========== 记录和打印 ==========
# 每隔 print_every 个 epoch 记录和打印一次
if epoch % print_every == 0:
# 记录当前 epoch 的结果
results["train_loss"].append(train_loss)
results["test_loss"].append(test_loss)
results["epoch"].append(epoch)
# 打印训练进度
# .5f 表示保留 5 位小数
print(f"Epoch: {epoch} | "
f"Train loss: {train_loss:.5f} | "
f"Test loss: {test_loss:.5f}")
# 返回训练历史,用于后续分析和可视化
return results
# 使用示例:
# results = train_model(
# model=model_1,
# train_loader=train_dataloader,
# test_loader=test_dataloader,
# loss_fn=nn.L1Loss(),
# optimizer=torch.optim.SGD(model_1.parameters(), lr=0.01),
# epochs=100,
# device="cuda" if torch.cuda.is_available() else "cpu",
# print_every=10
# )4.1 推理模式 (Inference Mode)
python
# 方法 1: torch.inference_mode() (推荐,更快)
with torch.inference_mode():
y_preds = model_1(X_test)
# 方法 2: torch.no_grad() (旧版,仍然支持)
with torch.no_grad():
y_preds = model_1(X_test)为什么使用推理模式?
- ✅ 关闭梯度追踪 (节省内存)
- ✅ 加快前向传播速度
- ✅
torch.inference_mode()比torch.no_grad()更快
4.2 评估模型性能
python
# ==================== 设置评估模式 ====================
# 将模型设置为评估模式
# eval() 会关闭 Dropout、BatchNorm 等训练专用层
# 确保模型以一致的方式进行推理
model_1.eval()
# ==================== 进行预测和评估 ====================
# 使用推理模式进行预测
# 优点:不计算梯度,节省内存,加快速度
with torch.inference_mode():
# 使用训练好的模型对测试集进行预测
# 此时模型已经学习了数据的模式
y_preds = model_1(X_test)
# 计算最终测试损失
# 这个损失值反映了模型在未见过的数据上的表现
final_loss = loss_fn(y_preds, y_test)
# 打印最终损失,保留 4 位小数
# 与训练前的损失对比,可以看到训练效果
print(f"最终测试损失: {final_loss:.4f}")
# ==================== 检查学到的参数 ====================
# 查看模型通过训练学到的参数
print(f"\n学到的参数:")
# 从状态字典中获取权重参数
# state_dict() 返回所有参数的字典
# ['linear_layer.weight'] 访问线性层的权重
# .item() 将单元素张量转换为 Python 标量
print(f" 权重: {model_1.state_dict()['linear_layer.weight'].item():.4f}")
# 获取偏置参数
print(f" 偏置: {model_1.state_dict()['linear_layer.bias'].item():.4f}")
# ==================== 对比真实参数 ====================
# 打印用于生成数据的真实参数
# 理想情况下,学到的参数应该接近这些真实值
print(f"\n真实参数:")
print(f" 权重: {weight}")
print(f" 偏置: {bias}")
# 注意:
# - 如果学到的参数接近真实参数,说明模型训练成功
# - 如果差距较大,可能需要:
# 1. 更多训练轮数
# 2. 调整学习率
# 3. 更多训练数据
# ==================== 可视化预测结果 ====================
# 绘制训练后的预测结果
# 与训练前的预测对比,应该能看到明显改善
plot_predictions(predictions=y_preds)
plt.title("训练后的预测结果")
plt.show()
# 预期结果:
# - 预测线应该与真实数据点非常接近
# - 与训练前的随机预测相比有显著改善5. 保存与加载模型
5.1 PyTorch 模型保存方法
PyTorch 提供三种主要方法:
| 方法 | 说明 | 用途 |
|---|---|---|
torch.save() |
将 Python 对象序列化并保存到磁盘 | 保存模型、参数、优化器状态等 |
torch.load() |
从磁盘加载序列化的对象 | 加载之前保存的对象 |
model.load_state_dict() |
将参数字典加载到模型中 | 恢复模型的参数值 |
两种保存方式对比:
| 保存方式 | 保存内容 | 优点 | 缺点 | 推荐度 |
|---|---|---|---|---|
| 保存 state_dict | 只保存参数(权重和偏置) | 文件小、灵活、兼容性好 | 需要先创建模型实例 | ⭐⭐⭐⭐⭐ 推荐 |
| 保存整个模型 | 保存模型结构和参数 | 加载方便,不需要模型定义 | 文件大、可能有兼容性问题 | ⭐⭐⭐ 不推荐 |
最佳实践:
- ✅ 推荐 :保存
state_dict()(只保存参数) - ❌ 不推荐:保存整个模型(使用 pickle)
- 💡 原因:state_dict 更灵活、文件更小、更容易调试
5.2 保存和加载 state_dict (推荐)
python
from pathlib import Path
# ==================== 步骤 1: 创建模型目录 ====================
# 使用 pathlib.Path 创建路径对象(推荐方式,跨平台兼容)
MODEL_PATH = Path("models")
# 创建目录
# parents=True: 如果父目录不存在,也会创建
# exist_ok=True: 如果目录已存在,不会报错
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# ==================== 步骤 2: 定义保存路径 ====================
# 定义模型文件名
# 约定:使用 .pth 或 .pt 扩展名表示 PyTorch 模型文件
MODEL_NAME = "01_pytorch_workflow_model.pth"
# 使用 / 运算符拼接路径(pathlib 的便捷特性)
# 等价于: MODEL_PATH / MODEL_NAME
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# ==================== 步骤 3: 保存模型参数 ====================
print(f"保存模型到: {MODEL_SAVE_PATH}")
# torch.save() 将对象序列化并保存到磁盘
# obj: 要保存的对象,这里是 state_dict(参数字典)
# f: 文件路径
# state_dict() 只包含模型参数(权重和偏置),不包含模型结构
torch.save(obj=model_1.state_dict(), # 只保存参数,不保存模型结构
f=MODEL_SAVE_PATH)
# 注意:state_dict 是一个 OrderedDict,键是参数名,值是参数张量
# ==================== 步骤 4: 加载模型 ====================
# 重要:加载 state_dict 需要先创建相同结构的模型实例
# 这就是为什么推荐保存 state_dict 而不是整个模型
# 因为你需要有模型的定义代码
loaded_model = LinearRegressionModelV2()
# 加载保存的参数到模型中
# torch.load() 从磁盘加载对象
# load_state_dict() 将参数字典加载到模型中
loaded_model.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# 此时 loaded_model 的参数与 model_1 完全相同
# ==================== 步骤 5: 设置为评估模式 ====================
# 加载后务必设置为评估模式
# 这会关闭 Dropout、BatchNorm 等训练专用层
loaded_model.eval()
# ==================== 步骤 6: 验证加载的模型 ====================
# 使用推理模式进行预测
with torch.inference_mode():
# 使用加载的模型进行预测
loaded_preds = loaded_model(X_test)
# ==================== 检查预测是否一致 ====================
# 打印前 3 个预测值进行对比
print(f"原始模型预测: {y_preds[:3]}")
print(f"加载模型预测: {loaded_preds[:3]}")
# torch.allclose() 检查两个张量是否在数值上接近
# 考虑浮点数精度问题,使用 allclose 而不是 ==
# 返回 True 表示加载成功,模型参数完全一致
print(f"预测是否相同: {torch.allclose(y_preds, loaded_preds)}")
# 如果输出 True,说明模型保存和加载成功!5.3 保存完整模型 (不推荐但有时有用)
python
# 保存完整模型
FULL_MODEL_PATH = MODEL_PATH / "full_model.pth"
torch.save(model_1, FULL_MODEL_PATH)
# 加载完整模型
loaded_full_model = torch.load(FULL_MODEL_PATH)
loaded_full_model.eval()5.4 保存和加载检查点 (Checkpoint)
python
def save_checkpoint(model, optimizer, epoch, loss, filepath):
"""
保存训练检查点(Checkpoint)
检查点包含恢复训练所需的所有信息:
- 模型参数
- 优化器状态(包括动量等)
- 当前 epoch
- 当前损失
用途:
- 长时间训练时定期保存,防止意外中断
- 实验对比和模型版本管理
- 从最佳性能点恢复训练
参数:
model: PyTorch 模型
optimizer: 优化器
epoch: 当前训练轮数
loss: 当前损失值
filepath: 保存路径
"""
# 创建检查点字典,包含所有训练状态
checkpoint = {
'epoch': epoch, # 当前训练到第几轮
'model_state_dict': model.state_dict(), # 模型参数
'optimizer_state_dict': optimizer.state_dict(), # 优化器状态
# 优化器状态包括:学习率、动量缓存、Adam 的一阶和二阶矩估计等
'loss': loss, # 当前损失值,用于监控训练进度
}
# 可以添加更多信息,例如:
# 'learning_rate': optimizer.param_groups[0]['lr'],
# 'best_loss': best_loss,
# 'train_history': train_loss_values,
# 'test_history': test_loss_values,
# 保存检查点到磁盘
torch.save(checkpoint, filepath)
print(f"检查点已保存到 {filepath}")
def load_checkpoint(filepath, model, optimizer):
"""
加载训练检查点
从检查点恢复训练状态,可以继续之前的训练
参数:
filepath: 检查点文件路径
model: 要加载参数的模型实例
optimizer: 要加载状态的优化器实例
返回:
model: 加载了参数的模型
optimizer: 加载了状态的优化器
epoch: 保存时的 epoch
loss: 保存时的损失值
"""
# 从磁盘加载检查点字典
checkpoint = torch.load(filepath)
# 恢复模型参数
# 将保存的权重和偏置加载到模型中
model.load_state_dict(checkpoint['model_state_dict'])
# 恢复优化器状态
# 这很重要!优化器的内部状态(如动量)也需要恢复
# 否则训练可能不稳定或效果变差
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 获取保存时的 epoch 和 loss
epoch = checkpoint['epoch']
loss = checkpoint['loss']
# 返回恢复后的对象和训练状态
return model, optimizer, epoch, loss
# ==================== 使用示例 ====================
# ---------- 保存检查点 ----------
# 在训练过程中定期保存检查点
# 例如:每 10 个 epoch 或当验证损失改善时保存
save_checkpoint(
model=model_1,
optimizer=optimizer,
epoch=100, # 当前训练到第 100 轮
loss=final_loss, # 当前损失值
filepath=MODEL_PATH / "checkpoint.pth"
)
# ---------- 加载检查点 ----------
# 从检查点恢复训练
# 适用场景:
# 1. 训练被中断,需要继续
# 2. 想从某个检查点开始微调
# 3. 加载最佳模型进行评估
model_1, optimizer, start_epoch, loss = load_checkpoint(
filepath=MODEL_PATH / "checkpoint.pth",
model=model_1,
optimizer=optimizer
)
# 继续训练示例:
# for epoch in range(start_epoch + 1, total_epochs):
# # 继续训练...
# pass
# 注意事项:
# 1. 检查点文件比只保存 state_dict 大,因为包含更多信息
# 2. 定期保存检查点可以防止训练中断导致的损失
# 3. 建议保存多个检查点(如 checkpoint_epoch_10.pth)
# 4. 可以只保留最近的 N 个检查点,节省磁盘空间5.5 最佳实践总结
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 生产部署 | state_dict() |
更灵活,可移植性好 |
| 中断训练 | Checkpoint | 可恢复训练状态 |
| 快速原型 | 完整模型 | 简单快速 |
| 跨版本 | state_dict() |
避免 PyTorch 版本问题 |
6. 完整流程整合
6.1 端到端示例代码
python
"""
完整的 PyTorch 线性回归工作流程
"""
import torch
from torch import nn
import matplotlib.pyplot as plt
from pathlib import Path
# ============================================================
# 步骤 1: 准备数据
# ============================================================
print("1. 准备数据...")
# 定义线性关系的真实参数
# 我们将训练模型来学习这些参数
weight = 0.7 # 斜率(真实值)
bias = 0.3 # 截距(真实值)
# 生成训练数据
# torch.arange(0, 1, 0.02) 生成 [0, 0.02, 0.04, ..., 0.98]
# unsqueeze(dim=1) 将形状从 [50] 变为 [50, 1](添加特征维度)
X = torch.arange(0, 1, 0.02).unsqueeze(dim=1)
# 根据线性方程生成标签: y = 0.7x + 0.3
y = weight * X + bias
# 划分训练集和测试集(80% 训练,20% 测试)
train_split = int(0.8 * len(X)) # 计算分割点(40 个样本)
X_train, y_train = X[:train_split], y[:train_split] # 前 80% 作为训练集
X_test, y_test = X[train_split:], y[train_split:] # 后 20% 作为测试集
print(f" 训练样本: {len(X_train)}, 测试样本: {len(X_test)}")
# ============================================================
# 步骤 2: 构建模型
# ============================================================
print("\n2. 构建模型...")
class LinearRegressionModelV2(nn.Module):
"""
简单的线性回归模型
使用 nn.Linear 层实现 y = wx + b
"""
def __init__(self):
super().__init__()
# 创建线性层:1 个输入特征,1 个输出特征
# 内部会自动初始化 weight 和 bias 参数
self.linear_layer = nn.Linear(in_features=1, out_features=1)
def forward(self, x):
"""前向传播:将输入传递给线性层"""
return self.linear_layer(x)
# 设置随机种子以确保可重复性
# 每次运行都会得到相同的初始参数
torch.manual_seed(42)
# 创建模型实例
model = LinearRegressionModelV2()
print(f" 模型: {model}")
# ============================================================
# 步骤 3: 设置损失函数和优化器
# ============================================================
print("\n3. 设置损失函数和优化器...")
# 损失函数:平均绝对误差(MAE / L1Loss)
# 用于衡量预测值与真实值之间的差距
# 公式: MAE = (1/n) * Σ|y_pred - y_true|
loss_fn = nn.L1Loss()
# 优化器:随机梯度下降(SGD)
# 用于根据梯度更新模型参数
# lr=0.01 是学习率,控制参数更新的步长
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
print(f" 损失函数: {loss_fn}")
print(f" 优化器: {optimizer.__class__.__name__}")
# ============================================================
# 步骤 4: 训练模型
# ============================================================
print("\n4. 开始训练...")
# 设置训练轮数
epochs = 200
# 主训练循环
for epoch in range(epochs):
# ---------- 训练阶段 ----------
# 设置为训练模式(启用 Dropout、BatchNorm 等)
model.train()
# 1. 前向传播:计算预测值
y_pred = model(X_train)
# 2. 计算损失:比较预测值和真实值
loss = loss_fn(y_pred, y_train)
# 3. 清零梯度:防止梯度累积(重要!)
optimizer.zero_grad()
# 4. 反向传播:计算梯度
loss.backward()
# 5. 更新参数:使用梯度更新模型参数
optimizer.step()
# ---------- 评估阶段 ----------
# 设置为评估模式(关闭 Dropout、BatchNorm 等)
model.eval()
# 使用推理模式(不计算梯度,节省内存)
with torch.inference_mode():
# 在测试集上进行预测
test_pred = model(X_test)
# 计算测试损失
test_loss = loss_fn(test_pred, y_test)
# 每 50 个 epoch 打印一次训练进度
if epoch % 50 == 0:
print(f" Epoch {epoch}: Train Loss = {loss:.4f}, Test Loss = {test_loss:.4f}")
# ============================================================
# 步骤 5: 评估模型
# ============================================================
print("\n5. 评估模型...")
# 设置为评估模式
model.eval()
# 使用推理模式进行最终评估
with torch.inference_mode():
# 在测试集上进行预测
y_preds = model(X_test)
# 计算最终测试损失
final_loss = loss_fn(y_preds, y_test)
# 打印评估结果
print(f" 最终测试损失: {final_loss:.4f}")
# 打印学到的参数
# 理想情况下应该接近真实参数(weight=0.7, bias=0.3)
print(f" 学到的权重: {model.state_dict()['linear_layer.weight'].item():.4f}")
print(f" 学到的偏置: {model.state_dict()['linear_layer.bias'].item():.4f}")
# ============================================================
# 步骤 6: 保存模型
# ============================================================
print("\n6. 保存模型...")
# 创建模型保存目录
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(exist_ok=True) # 如果目录已存在,不会报错
# 定义保存路径
SAVE_PATH = MODEL_PATH / "linear_model.pth"
# 保存模型参数(推荐方式)
# 只保存 state_dict,不保存整个模型
torch.save(model.state_dict(), SAVE_PATH)
print(f" 模型已保存到: {SAVE_PATH}")
print("\n✅ 完整流程执行完毕!")
# ============================================================
# 总结:PyTorch 工作流程的 6 个关键步骤
# ============================================================
# 1. 准备数据:生成或加载数据,划分训练集和测试集
# 2. 构建模型:定义神经网络结构(继承 nn.Module)
# 3. 设置损失和优化器:选择合适的损失函数和优化算法
# 4. 训练模型:循环执行前向传播、计算损失、反向传播、更新参数
# 5. 评估模型:在测试集上评估模型性能
# 6. 保存模型:保存训练好的模型参数供后续使用
# ============================================================第二部分:高级技术与最佳实践
7. 训练循环优化技术
7.1 自动混合精度 (AMP)
优势:
- ✅ 训练速度提升 1.5-3倍
- ✅ GPU 内存减半
- ✅ 保持相同的准确率
python
from torch.cuda.amp import autocast, GradScaler
# ==================== 创建梯度缩放器 ====================
# GradScaler 用于处理混合精度训练中的数值稳定性问题
#
# 为什么需要梯度缩放?
# - FP16(半精度)的数值范围比 FP32 小得多
# - 小梯度在 FP16 中可能会下溢(变为 0)
# - 缩放器会放大损失,使梯度不会下溢
scaler = GradScaler()
# ==================== 训练循环 ====================
for epoch in range(epochs):
# 设置为训练模式
model.train()
# 遍历数据批次
for batch, (X, y) in enumerate(train_loader):
# 将数据移动到 GPU
X, y = X.to(device), y.to(device)
# ==================== 混合精度前向传播 ====================
# autocast() 自动将操作转换为合适的精度
# - 矩阵乘法、卷积等计算密集型操作 → FP16(快速)
# - 归一化、损失计算等精度敏感操作 → FP32(准确)
with autocast():
# 前向传播(自动使用混合精度)
y_pred = model(X)
# 计算损失
loss = loss_fn(y_pred, y)
# ==================== 清零梯度 ====================
# 在反向传播前清除之前的梯度
optimizer.zero_grad()
# ==================== 缩放损失并反向传播 ====================
# scaler.scale(loss) 放大损失值
# 目的:防止 FP16 梯度下溢
# 例如:如果梯度是 0.0001,在 FP16 中可能变为 0
# 放大 1000 倍后变为 0.1,就不会下溢
scaler.scale(loss).backward()
# ==================== 更新参数 ====================
# scaler.step(optimizer) 执行以下操作:
# 1. 将梯度缩小回原始大小(反向缩放)
# 2. 检查梯度是否包含 inf 或 nan
# 3. 如果梯度正常,更新模型参数
# 4. 如果梯度异常,跳过这次更新
scaler.step(optimizer)
# scaler.update() 更新缩放因子
# - 如果最近的梯度都正常,增加缩放因子(更激进)
# - 如果出现 inf/nan,减小缩放因子(更保守)
# 这是一个自适应过程,无需手动调整
scaler.update()
# ==================== AMP 工作原理总结 ====================
# 1. autocast(): 自动选择 FP16 或 FP32 精度
# 2. scaler.scale(): 放大损失,防止梯度下溢
# 3. scaler.step(): 缩小梯度并更新参数
# 4. scaler.update(): 动态调整缩放因子
#
# 性能提升:
# - 训练速度:1.5-3倍(取决于模型和硬件)
# - 内存使用:减少约 50%
# - 精度影响:几乎没有(通常 <0.1% 差异)
#
# 适用场景:
# ✅ 大型模型(ResNet、Transformer 等)
# ✅ GPU 内存不足时
# ✅ 需要更大 batch size 时
# ❌ 小模型(收益不明显)
# ❌ CPU 训练(AMP 仅支持 CUDA)7.2 梯度累积 (Gradient Accumulation)
用途: 模拟更大的 batch size (当 GPU 内存不足时)
python
# ==================== 设置梯度累积步数 ====================
# 梯度累积的核心思想:
# - 实际 batch size = 8(受 GPU 内存限制)
# - 累积 4 个 batch 的梯度
# - 有效 batch size = 8 × 4 = 32
#
# 为什么需要梯度累积?
# - GPU 内存不足,无法使用大 batch size
# - 大 batch size 通常能提高训练稳定性和收敛速度
# - 梯度累积可以在不增加内存的情况下模拟大 batch
ACCUMULATION_STEPS = 4 # 累积 4 个 batch 后再更新参数
# ==================== 初始化梯度 ====================
# 在训练开始前清零梯度
optimizer.zero_grad()
# ==================== 训练循环 ====================
for i, (X, y) in enumerate(train_loader):
# 将数据移动到 GPU
X, y = X.to(device), y.to(device)
# ==================== 前向传播 ====================
# 计算预测值
y_pred = model(X)
# 计算损失
loss = loss_fn(y_pred, y)
# ==================== 归一化损失 ====================
# 关键步骤!将损失除以累积步数
#
# 为什么要归一化?
# - 如果不归一化,累积的梯度会是原来的 ACCUMULATION_STEPS 倍
# - 归一化后,累积梯度的平均值等于单个大 batch 的梯度
#
# 数学原理:
# - 4 个小 batch 的损失:L1, L2, L3, L4
# - 不归一化:总梯度 = ∇L1 + ∇L2 + ∇L3 + ∇L4
# - 归一化后:总梯度 = (∇L1 + ∇L2 + ∇L3 + ∇L4) / 4
# - 这等价于一个大 batch 的平均梯度
loss = loss / ACCUMULATION_STEPS
# ==================== 反向传播 ====================
# 计算梯度并累积(不清零)
# 梯度会自动累加到之前的梯度上
loss.backward()
# ==================== 条件更新参数 ====================
# 每累积 ACCUMULATION_STEPS 个 batch 后才更新一次参数
#
# 例如:ACCUMULATION_STEPS = 4
# - i=0: 累积梯度,不更新
# - i=1: 累积梯度,不更新
# - i=2: 累积梯度,不更新
# - i=3: 累积梯度,更新参数,清零梯度
# - i=4: 累积梯度,不更新
# - ...
if (i + 1) % ACCUMULATION_STEPS == 0:
# 使用累积的梯度更新参数
optimizer.step()
# 清零梯度,为下一轮累积做准备
optimizer.zero_grad()
# ==================== 梯度累积总结 ====================
# 优点:
# ✅ 在有限的 GPU 内存下模拟大 batch size
# ✅ 提高训练稳定性(大 batch 的优势)
# ✅ 不需要修改模型结构
# ✅ 实现简单,只需几行代码
#
# 缺点:
# ❌ 训练时间变长(更新频率降低)
# ❌ BatchNorm 统计量基于小 batch(可能不准确)
#
# 使用场景:
# - GPU 内存不足,无法使用理想的 batch size
# - 训练大型模型(BERT、GPT 等)
# - 需要稳定的训练过程
#
# 注意事项:
# 1. 必须归一化损失(除以 ACCUMULATION_STEPS)
# 2. 最后可能有不足 ACCUMULATION_STEPS 的 batch,需要特殊处理
# 3. 学习率可能需要相应调整(因为有效 batch size 变大了)7.3 学习率调度器 (Learning Rate Scheduler)
python
from torch.optim.lr_scheduler import (
StepLR, # 阶梯式学习率衰减
ReduceLROnPlateau, # 基于指标的自适应学习率
CosineAnnealingLR # 余弦退火学习率
)
# ==================== 方法 1: StepLR - 阶梯式衰减 ====================
# 每隔固定的 epoch 数降低学习率
#
# 参数说明:
# - step_size=30: 每 30 个 epoch 降低一次学习率
# - gamma=0.1: 学习率衰减因子(新学习率 = 旧学习率 × 0.1)
#
# 学习率变化示例(初始 lr=0.01):
# - Epoch 0-29: lr = 0.01
# - Epoch 30-59: lr = 0.001 (0.01 × 0.1)
# - Epoch 60-89: lr = 0.0001 (0.001 × 0.1)
#
# 适用场景:
# ✅ 训练过程比较稳定,知道大概在哪个阶段需要降低学习率
# ✅ 简单直接,容易理解和调试
# ❌ 不够灵活,无法根据训练情况自适应调整
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
# ==================== 方法 2: ReduceLROnPlateau - 自适应衰减 ====================
# 当监控的指标停止改善时降低学习率
# 这是最智能的调度器,能根据训练情况自动调整
#
# 参数说明:
# - mode='min': 监控指标越小越好(如 loss)
# 如果是准确率,应该用 mode='max'
# - factor=0.1: 学习率衰减因子(新学习率 = 旧学习率 × 0.1)
# - patience=10: 容忍度,如果 10 个 epoch 指标没有改善,就降低学习率
#
# 工作原理:
# 1. 每个 epoch 后,检查验证损失是否改善
# 2. 如果连续 10 个 epoch 都没有改善
# 3. 将学习率降低为原来的 0.1 倍
# 4. 重置计数器,继续监控
#
# 适用场景:
# ✅ 不确定何时需要降低学习率
# ✅ 训练过程不稳定,需要自适应调整
# ✅ 最推荐的方法,适用于大多数场景
scheduler = ReduceLROnPlateau(optimizer, mode='min',
factor=0.1, patience=10)
# ==================== 方法 3: CosineAnnealingLR - 余弦退火 ====================
# 学习率按照余弦函数曲线变化
#
# 参数说明:
# - T_max=epochs: 余弦周期的一半(通常设置为总 epoch 数)
#
# 学习率变化规律:
# - 开始时学习率较高
# - 按照余弦曲线平滑下降
# - 最后接近 0
#
# 数学公式:
# lr = lr_min + (lr_max - lr_min) × (1 + cos(π × epoch / T_max)) / 2
#
# 优点:
# ✅ 平滑的学习率变化,避免突然的跳跃
# ✅ 在训练后期学习率接近 0,有助于收敛
# ✅ 常用于训练 Transformer 等大型模型
#
# 适用场景:
# ✅ 训练周期固定且已知
# ✅ 需要平滑的学习率衰减
# ❌ 不适合需要中途调整训练周期的情况
scheduler = CosineAnnealingLR(optimizer, T_max=epochs)
# ==================== 在训练循环中使用调度器 ====================
for epoch in range(epochs):
# ---------- 训练代码 ----------
# model.train()
# ... 前向传播、计算损失、反向传播、更新参数 ...
# ---------- 评估代码 ----------
# model.eval()
# ... 计算验证损失 val_loss ...
# ==================== 更新学习率 ====================
# 不同的调度器有不同的调用方式:
# 方式 1: StepLR / CosineAnnealingLR
# 这些调度器只需要知道当前 epoch,不需要额外参数
scheduler.step()
# 方式 2: ReduceLROnPlateau
# 这个调度器需要监控指标(如验证损失)
# 根据指标的变化来决定是否降低学习率
# scheduler.step(val_loss)
# ==================== 打印当前学习率 ====================
# optimizer.param_groups 是一个列表,包含所有参数组
# 通常只有一个参数组,所以用 [0]
# 'lr' 键存储当前的学习率
current_lr = optimizer.param_groups[0]['lr']
print(f"Epoch {epoch}, LR: {current_lr}")
# ==================== 学习率调度器对比总结 ====================
#
# | 调度器 | 调整方式 | 优点 | 缺点 | 推荐场景 |
# |--------|---------|------|------|---------|
# | **StepLR** | 固定步长衰减 | 简单、可预测 | 不够灵活 | 训练过程稳定 |
# | **ReduceLROnPlateau** | 基于指标自适应 | 智能、灵活 | 需要监控指标 | 大多数场景(推荐)|
# | **CosineAnnealingLR** | 余弦曲线衰减 | 平滑、优雅 | 需要固定周期 | Transformer 等大模型 |
#
# 其他常用调度器:
# - ExponentialLR: 指数衰减(lr = lr × gamma^epoch)
# - MultiStepLR: 多阶梯衰减(在指定的 epoch 降低学习率)
# - OneCycleLR: 单周期学习率(先增后减,适合快速训练)
# - CyclicLR: 循环学习率(在最小值和最大值之间循环)
#
# 选择建议:
# 1. 不确定用哪个?→ 使用 ReduceLROnPlateau(最智能)
# 2. 训练 Transformer?→ 使用 CosineAnnealingLR 或 OneCycleLR
# 3. 需要简单可控?→ 使用 StepLR 或 MultiStepLR7.4 梯度裁剪 (Gradient Clipping)
用途: 防止梯度爆炸
python
import torch.nn.utils as nn_utils
# ==================== 设置梯度裁剪阈值 ====================
# 梯度裁剪的目的:防止梯度爆炸
#
# 什么是梯度爆炸?
# - 在深度网络中,梯度在反向传播时可能会指数级增长
# - 导致参数更新过大,模型无法收敛,甚至出现 NaN
#
# 梯度裁剪的原理:
# - 计算所有参数梯度的 L2 范数(总梯度大小)
# - 如果范数超过阈值,按比例缩小所有梯度
# - 保持梯度方向不变,只限制梯度大小
MAX_GRAD_NORM = 1.0 # 梯度范数的最大值
# ==================== 训练循环 ====================
for epoch in range(epochs):
for X, y in train_loader:
# 1. 清零梯度
optimizer.zero_grad()
# 2. 前向传播
y_pred = model(X)
# 3. 计算损失
loss = loss_fn(y_pred, y)
# 4. 反向传播(计算梯度)
loss.backward()
# ==================== 5. 梯度裁剪(关键步骤)====================
# clip_grad_norm_() 执行以下操作:
#
# 步骤 1: 计算所有参数梯度的 L2 范数
# total_norm = sqrt(sum(grad^2 for all parameters))
#
# 步骤 2: 如果 total_norm > MAX_GRAD_NORM
# 缩放因子 = MAX_GRAD_NORM / total_norm
# 所有梯度 *= 缩放因子
#
# 例如:
# - 如果 total_norm = 5.0, MAX_GRAD_NORM = 1.0
# - 缩放因子 = 1.0 / 5.0 = 0.2
# - 所有梯度都乘以 0.2,使总范数变为 1.0
#
# 参数说明:
# - model.parameters(): 要裁剪的参数
# - MAX_GRAD_NORM: 梯度范数的最大允许值
# - 返回值: 裁剪前的总梯度范数(可用于监控)
nn_utils.clip_grad_norm_(model.parameters(), MAX_GRAD_NORM)
# 注意:clip_grad_norm_() 中的下划线表示原地操作
# 直接修改参数的梯度,不创建新的张量
# 6. 更新参数
optimizer.step()
# ==================== 梯度裁剪详细说明 ====================
#
# 两种裁剪方法:
#
# 1. clip_grad_norm_() - 按范数裁剪(推荐)
# - 保持梯度方向不变
# - 只限制梯度的总大小
# - 适用于大多数场景
#
# 2. clip_grad_value_() - 按值裁剪
# - 将每个梯度限制在 [-threshold, threshold] 范围内
# - 可能改变梯度方向
# - 较少使用
#
# 使用示例:
# nn_utils.clip_grad_value_(model.parameters(), clip_value=0.5)
#
# ==================== 如何选择阈值?====================
#
# 常用阈值:
# - RNN/LSTM: 1.0 - 5.0(容易梯度爆炸)
# - Transformer: 1.0 - 2.0
# - CNN: 通常不需要(较少梯度爆炸)
#
# 调试方法:
# 1. 监控梯度范数:
# total_norm = nn_utils.clip_grad_norm_(model.parameters(), MAX_GRAD_NORM)
# print(f"Gradient norm: {total_norm:.4f}")
#
# 2. 如果经常看到 total_norm >> MAX_GRAD_NORM,说明梯度爆炸严重
# 3. 如果 total_norm 总是 < MAX_GRAD_NORM,可以适当增加阈值或不使用裁剪
#
# ==================== 梯度裁剪的优缺点 ====================
#
# 优点:
# ✅ 防止梯度爆炸,提高训练稳定性
# ✅ 允许使用更大的学习率
# ✅ 对 RNN/LSTM 等序列模型特别有效
# ✅ 实现简单,只需一行代码
#
# 缺点:
# ❌ 引入额外的超参数(阈值)
# ❌ 可能减慢收敛速度(限制了梯度大小)
# ❌ 对某些模型可能不是必需的
#
# 使用场景:
# ✅ 训练 RNN、LSTM、GRU(强烈推荐)
# ✅ 训练深度网络(如 ResNet-152)
# ✅ 出现 NaN 或 Inf 损失时
# ✅ 训练不稳定时
# ❌ 浅层网络或 CNN(通常不需要)
#
# 最佳实践:
# 1. 先尝试不使用梯度裁剪
# 2. 如果出现梯度爆炸(NaN、Inf),再添加
# 3. 从较大的阈值开始(如 5.0),逐步调小
# 4. 监控裁剪前的梯度范数,了解是否真的需要裁剪7.5 早停 (Early Stopping)
python
class EarlyStopping:
"""
早停机制(Early Stopping)
目的:
- 防止过拟合:当验证损失不再改善时停止训练
- 节省时间:避免无意义的训练
- 自动选择最佳模型:在验证损失最低时停止
工作原理:
- 监控验证损失
- 如果连续 N 个 epoch 没有改善,触发早停
- 保存验证损失最低时的模型
"""
def __init__(self, patience=7, min_delta=0):
"""
初始化早停机制
参数:
patience (int): 容忍度,允许多少个 epoch 没有改善
例如 patience=10,表示如果连续 10 个 epoch
验证损失都没有改善,就触发早停
min_delta (float): 最小改善量,只有改善超过这个值才算真正改善
例如 min_delta=0.001,表示验证损失必须降低
至少 0.001 才算改善,避免微小波动导致误判
示例:
# 宽松的早停(更多训练机会)
early_stopping = EarlyStopping(patience=20, min_delta=0.0001)
# 严格的早停(更快停止)
early_stopping = EarlyStopping(patience=5, min_delta=0.01)
"""
self.patience = patience # 容忍度
self.min_delta = min_delta # 最小改善量
self.counter = 0 # 计数器:记录连续多少个 epoch 没有改善
self.best_loss = None # 记录目前最好的验证损失
self.early_stop = False # 早停标志:是否应该停止训练
def __call__(self, val_loss):
"""
每个 epoch 后调用此方法,检查是否应该早停
参数:
val_loss (float): 当前 epoch 的验证损失
逻辑流程:
1. 如果是第一次调用,记录当前损失为最佳损失
2. 如果当前损失没有改善(或改善不足 min_delta):
- 计数器 +1
- 如果计数器达到 patience,触发早停
3. 如果当前损失有明显改善:
- 更新最佳损失
- 重置计数器为 0
"""
# ==================== 情况 1: 第一次调用 ====================
if self.best_loss is None:
# 第一个 epoch,直接记录为最佳损失
self.best_loss = val_loss
# ==================== 情况 2: 没有改善 ====================
# 判断条件:val_loss > self.best_loss - self.min_delta
#
# 数学解释:
# - 如果 val_loss = 0.5, best_loss = 0.4, min_delta = 0.01
# - 需要改善到 0.4 - 0.01 = 0.39 才算真正改善
# - 0.5 > 0.39,所以没有改善
#
# 为什么要减去 min_delta?
# - 避免因为微小的随机波动而重置计数器
# - 例如从 0.400 到 0.399,改善太小,可能只是噪声
elif val_loss > self.best_loss - self.min_delta:
# 损失没有改善(或改善不够),计数器 +1
self.counter += 1
print(f"EarlyStopping counter: {self.counter}/{self.patience}")
# 检查是否达到容忍度上限
if self.counter >= self.patience:
# 连续 patience 个 epoch 都没有改善,触发早停
self.early_stop = True
# ==================== 情况 3: 有明显改善 ====================
else:
# 损失有明显改善(降低超过 min_delta)
# 更新最佳损失
self.best_loss = val_loss
# 重置计数器,重新开始计数
self.counter = 0
# 这时通常应该保存模型(在外部实现)
# ==================== 使用示例 ====================
# 创建早停对象
# patience=10: 允许 10 个 epoch 没有改善
# min_delta=0.001: 损失必须降低至少 0.001 才算改善
early_stopping = EarlyStopping(patience=10, min_delta=0.001)
# 训练循环
for epoch in range(epochs):
# ---------- 训练阶段 ----------
# model.train()
# ... 前向传播、计算损失、反向传播、更新参数 ...
# ---------- 验证阶段 ----------
# model.eval()
# with torch.inference_mode():
# ... 计算验证损失 val_loss ...
# ==================== 检查早停 ====================
# 将当前验证损失传递给早停对象
early_stopping(val_loss)
# 检查是否应该停止训练
if early_stopping.early_stop:
print("Early stopping triggered!")
print(f"最佳验证损失: {early_stopping.best_loss:.4f}")
print(f"在 epoch {epoch} 停止训练")
break
# 如果验证损失改善了,保存模型(可选)
# if val_loss == early_stopping.best_loss:
# torch.save(model.state_dict(), 'best_model.pth')
# ==================== 早停机制详细说明 ====================
#
# 工作流程示例(patience=3, min_delta=0.01):
#
# Epoch | Val Loss | Best Loss | Counter | Action
# ------|----------|-----------|---------|------------------
# 1 | 1.000 | 1.000 | 0 | 初始化最佳损失
# 2 | 0.800 | 0.800 | 0 | 改善!更新最佳损失
# 3 | 0.750 | 0.750 | 0 | 改善!更新最佳损失
# 4 | 0.755 | 0.750 | 1 | 没改善,计数器+1
# 5 | 0.760 | 0.750 | 2 | 没改善,计数器+1
# 6 | 0.765 | 0.750 | 3 | 没改善,触发早停!
#
# ==================== 早停的优缺点 ====================
#
# 优点:
# ✅ 防止过拟合(在泛化性能最好时停止)
# ✅ 节省训练时间(不需要训练完所有 epoch)
# ✅ 自动化(不需要手动判断何时停止)
# ✅ 简单易用(只需几行代码)
#
# 缺点:
# ❌ 可能过早停止(验证集可能有噪声)
# ❌ 需要调整超参数(patience 和 min_delta)
# ❌ 需要验证集(增加数据划分复杂度)
#
# ==================== 参数选择建议 ====================
#
# patience 的选择:
# - 小数据集:5-10(训练快,可以早点停)
# - 大数据集:10-20(训练慢,需要更多耐心)
# - 不稳定的训练:15-30(给模型更多机会)
#
# min_delta 的选择:
# - 损失量级大(>1.0):0.01-0.1
# - 损失量级中(0.1-1.0):0.001-0.01
# - 损失量级小(<0.1):0.0001-0.001
#
# ==================== 最佳实践 ====================
#
# 1. 结合模型保存:
# if val_loss < best_loss:
# torch.save(model.state_dict(), 'best_model.pth')
#
# 2. 监控多个指标:
# 可以扩展类来同时监控损失和准确率
#
# 3. 使用验证集:
# 早停应该基于验证集,而不是训练集
#
# 4. 记录训练历史:
# 保存每个 epoch 的损失,用于后续分析
#
# 5. 先不用早停:
# 先完整训练一次,观察损失曲线,再决定 patience8. 模型评估指标
8.1 回归问题指标
python
def regression_metrics(y_true, y_pred):
"""
计算回归问题的常用评估指标
回归问题的目标是预测连续值,需要衡量预测值与真实值的接近程度
常用的四个指标:MAE, MSE, RMSE, R²
"""
# ==================== 数据准备 ====================
# 将 PyTorch 张量转换为 NumPy 数组
# .cpu() 将数据从 GPU 移动到 CPU(如果在 GPU 上)
# .numpy() 转换为 NumPy 数组,方便计算
y_true = y_true.cpu().numpy()
y_pred = y_pred.cpu().numpy()
# ==================== 指标 1: MAE (Mean Absolute Error) ====================
# 平均绝对误差
#
# 公式: MAE = (1/n) × Σ|y_true - y_pred|
#
# 含义:
# - 预测值与真实值的平均绝对差距
# - 所有误差的绝对值的平均
#
# 特点:
# ✅ 容易理解(平均误差多少)
# ✅ 单位与原始数据相同(如预测房价,MAE 单位是元)
# ✅ 对异常值不敏感(因为不平方)
#
# 解释:
# - MAE = 5 表示平均每个预测偏差 5 个单位
# - 越小越好,0 表示完美预测
mae = np.mean(np.abs(y_true - y_pred))
# ==================== 指标 2: MSE (Mean Squared Error) ====================
# 均方误差
#
# 公式: MSE = (1/n) × Σ(y_true - y_pred)²
#
# 含义:
# - 预测值与真实值的平方差的平均
# - 误差的平方的平均
#
# 特点:
# ✅ 数学性质好(可微分,凸函数)
# ✅ 常用作损失函数(nn.MSELoss)
# ❌ 单位是原始数据的平方(不直观)
# ❌ 对异常值敏感(因为平方会放大大误差)
#
# 解释:
# - MSE = 25 表示平均平方误差为 25
# - 越小越好,0 表示完美预测
mse = np.mean((y_true - y_pred) ** 2)
# ==================== 指标 3: RMSE (Root Mean Squared Error) ====================
# 均方根误差
#
# 公式: RMSE = √MSE = √[(1/n) × Σ(y_true - y_pred)²]
#
# 含义:
# - MSE 的平方根
# - 恢复到原始数据的单位
#
# 特点:
# ✅ 单位与原始数据相同(比 MSE 更直观)
# ✅ 对大误差有惩罚(因为先平方再开方)
# ✅ 最常用的回归评估指标之一
#
# 解释:
# - RMSE = 5 表示预测值平均偏离真实值 5 个单位
# - 越小越好,0 表示完美预测
# - RMSE 总是 ≥ MAE(因为平方会放大大误差)
rmse = np.sqrt(mse)
# ==================== 指标 4: R² Score (决定系数) ====================
# R² (R-squared) 或称为决定系数
#
# 公式: R² = 1 - (SS_res / SS_tot)
# 其中:
# - SS_res = Σ(y_true - y_pred)² (残差平方和)
# - SS_tot = Σ(y_true - ȳ)² (总平方和)
#
# 含义:
# - 模型解释了多少数据的变异性
# - 模型相对于"平均值预测"的改进程度
#
# 计算步骤:
# 步骤 1: 计算残差平方和(模型的预测误差)
ss_res = np.sum((y_true - y_pred) ** 2)
# 步骤 2: 计算总平方和(数据本身的变异性)
# np.mean(y_true) 是真实值的平均值
ss_tot = np.sum((y_true - np.mean(y_true)) ** 2)
# 步骤 3: 计算 R²
# R² = 1 - (残差平方和 / 总平方和)
r2 = 1 - (ss_res / ss_tot)
# R² 的解释:
# - R² = 1.0: 完美预测,模型解释了 100% 的变异性
# - R² = 0.8: 良好,模型解释了 80% 的变异性
# - R² = 0.5: 一般,模型解释了 50% 的变异性
# - R² = 0.0: 模型和预测平均值一样好(没有用)
# - R² < 0.0: 模型比预测平均值还差(很糟糕)
#
# 特点:
# ✅ 无量纲(0-1 之间,容易比较不同数据集)
# ✅ 直观(百分比形式,易于理解)
# ✅ 衡量模型的整体拟合优度
# ❌ 可能为负(当模型很差时)
# ==================== 返回所有指标 ====================
return {
'MAE': mae, # 平均绝对误差
'MSE': mse, # 均方误差
'RMSE': rmse, # 均方根误差
'R²': r2 # 决定系数
}
# ==================== 使用示例 ====================
# 设置模型为评估模式
model.eval()
# 使用推理模式进行预测(不计算梯度)
with torch.inference_mode():
# 在测试集上进行预测
y_pred = model(X_test)
# 计算所有评估指标
metrics = regression_metrics(y_test, y_pred)
# 打印评估结果
print("模型评估指标:")
for name, value in metrics.items():
print(f" {name}: {value:.4f}")
# ==================== 指标选择建议 ====================
#
# 根据不同场景选择合适的指标:
#
# 1. 需要直观理解误差大小?
# → 使用 MAE 或 RMSE(单位与原始数据相同)
#
# 2. 需要惩罚大误差?
# → 使用 RMSE 或 MSE(平方会放大大误差)
#
# 3. 需要比较不同数据集的模型?
# → 使用 R²(无量纲,0-1 之间)
#
# 4. 作为损失函数训练?
# → 使用 MSE(数学性质好,可微分)
#
# 5. 数据有异常值?
# → 使用 MAE(对异常值不敏感)
#
# ==================== 指标对比总结 ====================
#
# | 指标 | 单位 | 范围 | 对异常值 | 常用场景 |
# |------|------|------|----------|----------|
# | MAE | 原始单位 | [0, ∞) | 不敏感 | 日常报告、有异常值 |
# | MSE | 单位² | [0, ∞) | 敏感 | 损失函数、理论分析 |
# | RMSE | 原始单位 | [0, ∞) | 敏感 | 最常用、需要惩罚大误差 |
# | R² | 无量纲 | (-∞, 1] | 中等 | 模型比较、整体评估 |
#
# 最佳实践:
# - 同时报告多个指标(如 RMSE + R²)
# - MAE 和 RMSE 一起看可以了解误差分布
# - 如果 RMSE >> MAE,说明有较大的异常误差8.2 使用 torchmetrics 库
python
# ==================== 安装 torchmetrics ====================
# torchmetrics 是 PyTorch 官方推荐的指标计算库
#
# 优势:
# ✅ 自动处理批次累积(不需要手动平均)
# ✅ 支持分布式训练(多 GPU)
# ✅ GPU 加速(直接在 GPU 上计算)
# ✅ 类型安全(自动处理张量类型)
# ✅ 丰富的指标(100+ 种指标)
#
# 安装命令:
# pip install torchmetrics
from torchmetrics import MeanAbsoluteError, MeanSquaredError, R2Score
# ==================== 创建指标对象 ====================
# torchmetrics 使用面向对象的方式管理指标
# 每个指标都是一个可调用的对象,维护内部状态
#
# 创建指标对象(只需创建一次)
mae_metric = MeanAbsoluteError() # 平均绝对误差
mse_metric = MeanSquaredError() # 均方误差
r2_metric = R2Score() # R² 决定系数
# 注意:
# - 指标对象会自动累积多个批次的结果
# - 内部维护运行总和和样本计数
# - 最后调用 compute() 计算最终平均值
# ==================== 在评估循环中使用 ====================
# 遍历测试数据加载器
for X, y in test_loader:
# 使用推理模式(不计算梯度,节省内存)
with torch.inference_mode():
# 前向传播,获取预测值
y_pred = model(X)
# ==================== 更新指标 ====================
# update() 方法会累积当前批次的结果
#
# 工作原理:
# 1. 计算当前批次的指标值
# 2. 将结果累加到内部状态
# 3. 更新样本计数
#
# 例如对于 MAE:
# - 第 1 个批次: total_error = 10, count = 32
# - 第 2 个批次: total_error = 10 + 8 = 18, count = 32 + 32 = 64
# - 第 3 个批次: total_error = 18 + 12 = 30, count = 64 + 32 = 96
# - 最终 MAE = 30 / 96 = 0.3125
mae_metric.update(y_pred, y)
mse_metric.update(y_pred, y)
r2_metric.update(y_pred, y)
# 注意:
# - update() 不返回值,只更新内部状态
# - 可以在训练循环中多次调用
# - 支持不同大小的批次(自动处理)
# ==================== 计算最终指标值 ====================
# compute() 方法计算所有累积批次的最终指标
#
# 工作原理:
# - 使用累积的总和和计数计算平均值
# - 返回一个标量张量
# - 不会重置内部状态(需要手动调用 reset())
print(f"MAE: {mae_metric.compute():.4f}")
print(f"MSE: {mse_metric.compute():.4f}")
print(f"R²: {r2_metric.compute():.4f}")
# ==================== 重置指标(可选)====================
# 如果需要重新计算(例如下一个 epoch),需要重置
# mae_metric.reset()
# mse_metric.reset()
# r2_metric.reset()
# ==================== torchmetrics 的优势示例 ====================
#
# 手动计算 vs torchmetrics:
#
# 【手动计算】(容易出错)
# total_mae = 0
# total_samples = 0
# for X, y in test_loader:
# y_pred = model(X)
# total_mae += torch.abs(y_pred - y).sum().item()
# total_samples += y.size(0)
# mae = total_mae / total_samples
#
# 【使用 torchmetrics】(简洁、正确)
# mae_metric = MeanAbsoluteError()
# for X, y in test_loader:
# y_pred = model(X)
# mae_metric.update(y_pred, y)
# mae = mae_metric.compute()
#
# ==================== 高级用法 ====================
#
# 1. 移动到 GPU:
# mae_metric = MeanAbsoluteError().to(device)
#
# 2. 分布式训练:
# mae_metric = MeanAbsoluteError(dist_sync_on_step=True)
#
# 3. 批量创建指标:
# from torchmetrics import MetricCollection
# metrics = MetricCollection([
# MeanAbsoluteError(),
# MeanSquaredError(),
# R2Score()
# ])
# metrics.update(y_pred, y)
# results = metrics.compute() # 返回字典
#
# 4. 在训练循环中使用:
# for epoch in range(epochs):
# # 训练阶段
# train_metric.reset()
# for X, y in train_loader:
# y_pred = model(X)
# train_metric.update(y_pred, y)
# train_loss = train_metric.compute()
#
# # 验证阶段
# val_metric.reset()
# for X, y in val_loader:
# y_pred = model(X)
# val_metric.update(y_pred, y)
# val_loss = val_metric.compute()
#
# ==================== 常用回归指标 ====================
#
# torchmetrics 提供的回归指标:
# - MeanAbsoluteError (MAE)
# - MeanSquaredError (MSE)
# - MeanAbsolutePercentageError (MAPE)
# - R2Score (决定系数)
# - ExplainedVariance (解释方差)
# - PearsonCorrCoef (皮尔逊相关系数)
# - SpearmanCorrCoef (斯皮尔曼相关系数)
#
# ==================== 最佳实践 ====================
#
# 1. 在训练开始前创建指标对象
# 2. 每个 epoch 开始时调用 reset()
# 3. 在批次循环中调用 update()
# 4. 在 epoch 结束时调用 compute()
# 5. 将指标对象移动到与模型相同的设备
# 6. 使用 MetricCollection 管理多个指标9. 调试与监控
9.1 PyTorch Profiler
python
from torch.profiler import profile, ProfilerActivity
# ==================== PyTorch Profiler ====================
# PyTorch 内置的性能分析工具
#
# 用途:
# - 找出训练中的性能瓶颈
# - 分析 CPU 和 GPU 时间占用
# - 优化模型性能
# - 检测内存泄漏
#
# 参数说明:
# - activities: 要分析的活动类型
# * ProfilerActivity.CPU: 分析 CPU 操作
# * ProfilerActivity.CUDA: 分析 GPU 操作
# - record_shapes: 是否记录张量形状(有助于调试)
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True # 记录张量形状,帮助定位问题
) as prof:
# 运行 10 次迭代进行性能分析
# 注意:不要运行太多次,会产生大量数据
for _ in range(10):
# 前向传播
y_pred = model(X_train)
# 计算损失
loss = loss_fn(y_pred, y_train)
# 反向传播
loss.backward()
# profiler 会自动记录每个操作的时间
# ==================== 打印性能统计信息 ====================
# key_averages() 计算每个操作的平均时间
# table() 生成格式化的表格
#
# 参数:
# - sort_by: 排序依据
# * "cpu_time_total": 按 CPU 总时间排序
# * "cuda_time_total": 按 GPU 总时间排序
# * "self_cpu_time_total": 按 CPU 自身时间排序(不包括子操作)
# - row_limit: 显示前 N 行
print(prof.key_averages().table(sort_by="cpu_time_total", row_limit=10))
# 输出示例:
# --------------------------------- ------------ ------------ ------------
# Name Self CPU % Self CPU Total CPU
# --------------------------------- ------------ ------------ ------------
# aten::addmm 45.23% 123.45ms 123.45ms
# aten::mm 23.12% 63.21ms 63.21ms
# aten::copy_ 12.34% 33.76ms 33.76ms
# ...
#
# 解读:
# - Self CPU %: 该操作占总 CPU 时间的百分比
# - Self CPU: 该操作本身的 CPU 时间
# - Total CPU: 该操作及其子操作的总 CPU 时间
#
# 优化建议:
# 1. 如果某个操作占用时间过多,考虑优化
# 2. 检查是否有不必要的数据传输(CPU ↔ GPU)
# 3. 使用更高效的操作(如 in-place 操作)
# ==================== 导出到 Chrome Trace ====================
# 可以导出为 Chrome 可视化格式
# prof.export_chrome_trace("trace.json")
# 然后在 Chrome 浏览器中打开 chrome://tracing 加载文件
# ==================== 使用场景 ====================
# ✅ 模型训练速度慢,需要找出瓶颈
# ✅ GPU 利用率低,需要分析原因
# ✅ 内存使用过高,需要定位问题
# ✅ 对比不同实现的性能9.2 使用 TensorBoard
python
from torch.utils.tensorboard import SummaryWriter
# ==================== 创建 TensorBoard Writer ====================
# TensorBoard 是 TensorFlow 的可视化工具,PyTorch 也支持
#
# 优势:
# ✅ 实时可视化训练过程
# ✅ 对比多次实验
# ✅ 查看模型结构
# ✅ 分析参数分布
# ✅ 完全免费,本地运行
#
# 参数:
# - log_dir: 日志保存目录
# 建议格式: 'runs/实验名称_时间戳'
writer = SummaryWriter('runs/linear_regression')
# ==================== 训练循环中记录数据 ====================
for epoch in range(epochs):
# ---------- 训练代码 ----------
# model.train()
# ... 前向传播、计算损失、反向传播、更新参数 ...
# train_loss = ...
# ---------- 验证代码 ----------
# model.eval()
# ... 计算验证损失 ...
# test_loss = ...
# ==================== 记录标量值(损失、准确率等)====================
# add_scalar(tag, scalar_value, global_step)
#
# 参数:
# - tag: 标签名称(支持分组,用 / 分隔)
# - scalar_value: 要记录的值
# - global_step: 步数(通常是 epoch 或 iteration)
# 记录训练损失和测试损失
# 使用 'Loss/' 前缀将它们分组显示
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Loss/test', test_loss, epoch)
# ==================== 记录学习率 ====================
# 监控学习率变化(特别是使用学习率调度器时)
current_lr = optimizer.param_groups[0]['lr']
writer.add_scalar('Learning Rate', current_lr, epoch)
# ==================== 记录参数分布(直方图)====================
# 可视化模型参数的分布变化
# 有助于:
# - 检测梯度消失/爆炸
# - 观察参数更新情况
# - 诊断训练问题
for name, param in model.named_parameters():
# add_histogram(tag, values, global_step)
# 记录参数的直方图
writer.add_histogram(name, param, epoch)
# 也可以记录梯度的直方图(如果需要)
# if param.grad is not None:
# writer.add_histogram(f'{name}.grad', param.grad, epoch)
# ==================== 关闭 Writer ====================
# 确保所有数据都被写入磁盘
writer.close()
# ==================== 启动 TensorBoard ====================
# 在终端运行以下命令:
# tensorboard --logdir=runs
#
# 然后在浏览器中打开: http://localhost:6006
#
# TensorBoard 界面功能:
# - SCALARS: 查看损失、准确率等曲线
# - GRAPHS: 查看模型计算图
# - DISTRIBUTIONS: 查看参数分布
# - HISTOGRAMS: 查看参数直方图
# - IMAGES: 查看图像(如果记录了)
# ==================== 其他有用的记录方法 ====================
#
# 1. 记录图像:
# writer.add_image('predictions', img_tensor, epoch)
#
# 2. 记录模型结构:
# writer.add_graph(model, input_tensor)
#
# 3. 记录文本:
# writer.add_text('notes', 'This is a note', epoch)
#
# 4. 记录超参数和指标:
# writer.add_hparams(
# {'lr': 0.01, 'batch_size': 32},
# {'hparam/accuracy': 0.95, 'hparam/loss': 0.05}
# )
#
# 5. 记录 PR 曲线(分类问题):
# writer.add_pr_curve('pr_curve', labels, predictions, epoch)
# ==================== 最佳实践 ====================
# 1. 使用有意义的标签名称(如 'Loss/train' 而不是 'loss1')
# 2. 使用 / 分隔符创建层次结构
# 3. 定期记录(每个 epoch 或每 N 个 batch)
# 4. 记录多个指标以全面了解训练情况
# 5. 对比实验时使用不同的 log_dir9.3 使用 Weights & Biases (推荐)
python
# ==================== 安装 Weights & Biases ====================
# W&B 是现代化的实验跟踪和可视化平台
#
# 优势(相比 TensorBoard):
# ✅ 云端存储,随时随地访问
# ✅ 自动对比多次实验
# ✅ 团队协作功能
# ✅ 超参数搜索(Sweeps)
# ✅ 模型版本管理
# ✅ 更美观的界面
# ✅ 免费版功能已经很强大
#
# 安装命令:
# pip install wandb
#
# 首次使用需要登录:
# wandb login
# 然后输入 API key(在 wandb.ai 网站获取)
import wandb
# ==================== 初始化 W&B ====================
# wandb.init() 开始一个新的实验运行
#
# 参数:
# - project: 项目名称(将实验组织在一起)
# - name: 运行名称(可选,默认自动生成)
# - config: 超参数配置(字典)
# - tags: 标签列表(可选,用于过滤)
# - notes: 实验备注(可选)
wandb.init(
project="pytorch-linear-regression", # 项目名称
name="baseline-experiment", # 运行名称(可选)
config={ # 超参数配置
"learning_rate": 0.01,
"epochs": 100,
"batch_size": 8,
"optimizer": "SGD",
"loss_function": "L1Loss"
},
tags=["baseline", "linear-regression"] # 标签(可选)
)
# 也可以通过 wandb.config 访问配置
# lr = wandb.config.learning_rate
# ==================== 训练循环 ====================
for epoch in range(epochs):
# ---------- 训练阶段 ----------
# model.train()
# for X, y in train_loader:
# ... 前向传播、计算损失、反向传播、更新参数 ...
# train_loss = ...
# ---------- 验证阶段 ----------
# model.eval()
# with torch.inference_mode():
# ... 计算验证损失 ...
# test_loss = ...
# ==================== 记录指标 ====================
# wandb.log() 记录指标到云端
#
# 特点:
# - 自动创建图表
# - 支持嵌套字典
# - 自动处理时间步
# - 实时同步到云端
wandb.log({
"epoch": epoch,
"train_loss": train_loss,
"test_loss": test_loss,
"learning_rate": optimizer.param_groups[0]['lr']
})
# 也可以记录更多信息:
# wandb.log({
# "metrics/train_loss": train_loss,
# "metrics/test_loss": test_loss,
# "metrics/mae": mae,
# "metrics/r2": r2,
# "system/gpu_memory": torch.cuda.memory_allocated(),
# "gradients/mean": grad_mean,
# "gradients/max": grad_max
# })
# ==================== 保存模型到 W&B ====================
# wandb.save() 将文件上传到 W&B
# 支持模型文件、配置文件、代码等
torch.save(model.state_dict(), "model.pth")
wandb.save("model.pth")
# 也可以保存整个模型目录
# wandb.save("models/*.pth")
# ==================== 结束运行 ====================
# 标记实验完成(可选,脚本结束时会自动调用)
wandb.finish()
# ==================== W&B 高级功能 ====================
#
# 1. 记录图像:
# wandb.log({"predictions": wandb.Image(img)})
#
# 2. 记录表格:
# table = wandb.Table(columns=["epoch", "loss"], data=[[1, 0.5], [2, 0.3]])
# wandb.log({"results": table})
#
# 3. 记录模型(Artifacts):
# artifact = wandb.Artifact('model', type='model')
# artifact.add_file('model.pth')
# wandb.log_artifact(artifact)
#
# 4. 监控系统资源:
# wandb.init(monitor_gym=True) # 自动记录 CPU、GPU、内存
#
# 5. 超参数搜索(Sweeps):
# sweep_config = {
# 'method': 'random',
# 'parameters': {
# 'learning_rate': {'values': [0.001, 0.01, 0.1]},
# 'batch_size': {'values': [8, 16, 32]}
# }
# }
# sweep_id = wandb.sweep(sweep_config, project="my-project")
# wandb.agent(sweep_id, function=train)
#
# 6. 对比实验:
# 在 W&B 网页界面可以轻松对比多次运行
# - 并排查看图表
# - 对比超参数
# - 查看差异
# ==================== W&B vs TensorBoard ====================
#
# | 特性 | W&B | TensorBoard |
# |------|-----|-------------|
# | 存储 | 云端 | 本地 |
# | 访问 | 随时随地 | 需要运行服务 |
# | 协作 | 支持 | 不支持 |
# | 超参数搜索 | 内置 | 需要额外工具 |
# | 模型管理 | 支持 | 不支持 |
# | 免费版 | 功能丰富 | 完全免费 |
# | 学习曲线 | 简单 | 简单 |
#
# 选择建议:
# - 个人项目、离线环境 → TensorBoard
# - 团队项目、需要协作 → W&B
# - 需要超参数搜索 → W&B
# - 需要模型版本管理 → W&B
# ==================== 最佳实践 ====================
# 1. 为每次实验设置有意义的名称和标签
# 2. 记录所有重要的超参数到 config
# 3. 定期记录指标(每个 epoch 或每 N 个 batch)
# 4. 使用 Artifacts 管理模型版本
# 5. 添加实验备注,记录想法和发现
# 6. 使用 Sweeps 进行系统化的超参数搜索10. 生产部署最佳实践
10.1 模型导出为 ONNX
python
# ==================== ONNX 导出 ====================
# ONNX (Open Neural Network Exchange) 是一个开放的模型格式
#
# 优势:
# ✅ 跨平台:可以在不同框架间转换(PyTorch → TensorFlow → ONNX Runtime)
# ✅ 跨语言:支持 Python、C++、Java、C# 等
# ✅ 优化推理:ONNX Runtime 针对推理进行了优化
# ✅ 部署灵活:可以部署到移动端、嵌入式设备、云端
# ✅ 硬件加速:支持 CPU、GPU、NPU 等多种硬件
#
# 使用场景:
# - 生产环境部署(特别是非 Python 环境)
# - 移动端/边缘设备部署
# - 需要跨框架兼容性
# - 需要最优推理性能
# ==================== 创建示例输入 ====================
# ONNX 导出需要一个示例输入来追踪模型的计算图
# 形状必须与实际输入一致
#
# 参数说明:
# - (1, 1): batch_size=1, features=1
# - 对于图像模型可能是 (1, 3, 224, 224)
dummy_input = torch.randn(1, 1)
# ==================== 导出模型为 ONNX ====================
# torch.onnx.export() 将 PyTorch 模型转换为 ONNX 格式
#
# 参数详解:
torch.onnx.export(
model, # 要导出的 PyTorch 模型
dummy_input, # 示例输入(用于追踪计算图)
"model.onnx", # 输出文件路径
# ==================== 导出选项 ====================
export_params=True, # 是否导出模型参数(权重和偏置)
# True: 导出完整模型(推荐)
# False: 只导出模型结构
opset_version=11, # ONNX 算子集版本
# 版本越高,支持的操作越多
# 推荐使用 11 或更高(兼容性好)
# 最新版本可以到 17+
# ==================== 输入输出命名 ====================
input_names=['input'], # 输入节点名称(列表)
# 多输入模型: ['input1', 'input2']
# 有助于在其他框架中识别输入
output_names=['output'], # 输出节点名称(列表)
# 多输出模型: ['output1', 'output2']
# ==================== 其他有用的参数 ====================
# dynamic_axes={ # 动态维度(支持可变 batch size)
# 'input': {0: 'batch_size'},
# 'output': {0: 'batch_size'}
# },
# do_constant_folding=True, # 常量折叠优化(推荐)
# verbose=False, # 是否打印详细信息
)
print("✅ 模型已导出为 ONNX 格式")
# ==================== 验证 ONNX 模型 ====================
# 导出后应该验证模型是否正确
import onnx
# 加载 ONNX 模型
onnx_model = onnx.load("model.onnx")
# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)
print("✅ ONNX 模型验证通过")
# ==================== 使用 ONNX Runtime 推理 ====================
# 安装: pip install onnxruntime
# import onnxruntime as ort
#
# # 创建推理会话
# ort_session = ort.InferenceSession("model.onnx")
#
# # 准备输入
# ort_inputs = {"input": dummy_input.numpy()}
#
# # 运行推理
# ort_outputs = ort_session.run(None, ort_inputs)
#
# print(f"ONNX Runtime 输出: {ort_outputs[0]}")
# ==================== ONNX 导出最佳实践 ====================
# 1. 使用 model.eval() 确保模型处于评估模式
# 2. 使用代表性的 dummy_input(形状和数据类型要正确)
# 3. 设置 dynamic_axes 支持可变 batch size
# 4. 导出后验证模型(使用 onnx.checker)
# 5. 测试 ONNX 模型的输出是否与 PyTorch 一致
# 6. 使用较新的 opset_version 以获得更好的支持10.2 模型量化 (加速推理)
python
import os
# ==================== 模型量化 ====================
# 量化是将模型参数从 FP32(32位浮点数)转换为 INT8(8位整数)
#
# 优势:
# ✅ 模型大小减少 4 倍(32位 → 8位)
# ✅ 推理速度提升 2-4 倍(取决于硬件)
# ✅ 内存占用减少 4 倍
# ✅ 精度损失很小(通常 <1%)
# ✅ 适合移动端和边缘设备部署
#
# 三种量化方式:
# 1. 动态量化(Dynamic Quantization)- 最简单,推荐
# 2. 静态量化(Static Quantization)- 需要校准数据
# 3. 量化感知训练(QAT)- 训练时就考虑量化
# ==================== 动态量化 ====================
# 动态量化:在推理时动态计算量化参数
# 适用于:RNN、LSTM、Transformer 等模型
#
# torch.quantization.quantize_dynamic() 参数:
quantized_model = torch.quantization.quantize_dynamic(
model, # 要量化的模型
{nn.Linear}, # 要量化的层类型(集合)
# 常见选项:
# - {nn.Linear}: 只量化全连接层
# - {nn.Linear, nn.Conv2d}: 量化全连接和卷积层
# - {nn.LSTM, nn.Linear}: 量化 LSTM 和全连接层
dtype=torch.qint8 # 量化后的数据类型
# torch.qint8: 8位整数(推荐)
# torch.float16: 16位浮点数(半精度)
)
# 量化后的模型可以直接使用,API 与原模型相同
# ==================== 测试量化模型 ====================
# 验证量化模型的输出是否正确
with torch.inference_mode():
# 使用量化模型进行预测
quantized_pred = quantized_model(X_test)
# 对比原始模型和量化模型的输出
# with torch.inference_mode():
# original_pred = model(X_test)
#
# # 计算差异
# diff = torch.abs(original_pred - quantized_pred).mean()
# print(f"平均预测差异: {diff:.6f}")
# ==================== 对比模型大小 ====================
# 保存原始模型
torch.save(model.state_dict(), 'model.pth')
# 保存量化模型
torch.save(quantized_model.state_dict(), 'quantized_model.pth')
# 计算文件大小
original_size = os.path.getsize('model.pth') / 1024 # KB
quantized_size = os.path.getsize('quantized_model.pth') / 1024 # KB
print(f"原始模型大小: {original_size:.2f} KB")
print(f"量化模型大小: {quantized_size:.2f} KB")
print(f"压缩比例: {original_size / quantized_size:.2f}x")
print(f"大小减少: {(1 - quantized_size / original_size) * 100:.1f}%")
# 预期结果:
# - 模型大小减少约 75%(4倍压缩)
# - 推理速度提升 2-4 倍
# - 精度损失 <1%
# ==================== 静态量化示例 ====================
# 静态量化需要校准数据来确定量化参数
#
# # 1. 准备模型
# model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# model_prepared = torch.quantization.prepare(model)
#
# # 2. 校准(使用代表性数据)
# with torch.inference_mode():
# for X, y in calibration_loader:
# model_prepared(X)
#
# # 3. 转换为量化模型
# quantized_model = torch.quantization.convert(model_prepared)
# ==================== 量化感知训练(QAT)示例 ====================
# 在训练过程中模拟量化,获得更好的精度
#
# # 1. 准备模型
# model.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')
# model_prepared = torch.quantization.prepare_qat(model)
#
# # 2. 训练(正常训练流程)
# for epoch in range(epochs):
# for X, y in train_loader:
# optimizer.zero_grad()
# output = model_prepared(X)
# loss = loss_fn(output, y)
# loss.backward()
# optimizer.step()
#
# # 3. 转换为量化模型
# model_prepared.eval()
# quantized_model = torch.quantization.convert(model_prepared)
# ==================== 量化最佳实践 ====================
# 1. 优先使用动态量化(最简单,效果好)
# 2. 如果精度下降明显,尝试静态量化或 QAT
# 3. 量化后务必验证模型精度
# 4. 在目标设备上测试推理速度
# 5. 对比量化前后的性能和精度
# 6. 不是所有层都需要量化(如 BatchNorm 通常不量化)
# 7. 移动端部署时量化效果最明显
# ==================== 使用场景 ====================
# ✅ 移动端部署(Android、iOS)
# ✅ 边缘设备(树莓派、Jetson Nano)
# ✅ CPU 推理(量化对 CPU 加速明显)
# ✅ 内存受限的环境
# ❌ GPU 推理(量化对 GPU 加速不明显)
# ❌ 对精度要求极高的场景10.3 模型服务化 (使用 FastAPI)
python
# ==================== 文件名: api.py ====================
# FastAPI 是现代、快速的 Web 框架,用于构建 API
#
# 优势:
# ✅ 高性能(基于 Starlette 和 Pydantic)
# ✅ 自动生成 API 文档(Swagger UI)
# ✅ 类型验证(使用 Pydantic)
# ✅ 异步支持(async/await)
# ✅ 易于部署和扩展
#
# 安装:
# pip install fastapi uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
import torch
import logging
# ==================== 配置日志 ====================
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# ==================== 创建 FastAPI 应用 ====================
app = FastAPI(
title="PyTorch 线性回归 API", # API 标题
description="使用 PyTorch 模型进行预测", # API 描述
version="1.0.0" # API 版本
)
# ==================== 加载模型(启动时执行一次)====================
# 在应用启动时加载模型,避免每次请求都加载
try:
# 创建模型实例
model = LinearRegressionModelV2()
# 加载训练好的参数
model.load_state_dict(torch.load('model.pth', map_location='cpu'))
# map_location='cpu': 即使模型在 GPU 上训练,也加载到 CPU
# 生产环境通常使用 CPU 推理(成本低)
# 设置为评估模式(重要!)
model.eval()
logger.info("✅ 模型加载成功")
except Exception as e:
logger.error(f"❌ 模型加载失败: {e}")
raise
# ==================== 定义请求和响应模型 ====================
# 使用 Pydantic 进行数据验证
class PredictionRequest(BaseModel):
"""
预测请求模型
Pydantic 会自动验证输入数据:
- 类型检查(必须是 float)
- 范围检查(使用 Field)
- 自动生成 API 文档
"""
value: float = Field(
..., # ... 表示必填字段
description="输入值",
example=0.5, # 示例值(显示在 API 文档中)
ge=0.0, # 大于等于 0(可选的验证)
le=1.0 # 小于等于 1(可选的验证)
)
class PredictionResponse(BaseModel):
"""
预测响应模型
定义 API 返回的数据结构
"""
prediction: float = Field(
...,
description="预测结果"
)
input_value: float = Field(
...,
description="输入值(用于验证)"
)
# ==================== 健康检查端点 ====================
@app.get("/health")
def health_check():
"""
健康检查端点
用途:
- 监控服务是否正常运行
- 负载均衡器健康检查
- 容器编排(Kubernetes)健康探针
"""
return {
"status": "healthy",
"model_loaded": model is not None
}
# ==================== 预测端点 ====================
@app.post("/predict", response_model=PredictionResponse)
def predict(request: PredictionRequest):
"""
预测端点
接收输入值,返回模型预测结果
参数:
request: PredictionRequest - 包含输入值的请求
返回:
PredictionResponse - 包含预测结果的响应
异常:
HTTPException - 如果预测失败
"""
try:
# ==================== 预处理 ====================
# 将输入转换为张量
# [[request.value]]: 形状为 (1, 1) 的二维张量
X = torch.tensor([[request.value]], dtype=torch.float32)
# ==================== 推理 ====================
# 使用推理模式(不计算梯度,节省内存)
with torch.inference_mode():
# 模型预测
pred = model(X)
# ==================== 后处理 ====================
# 将张量转换为 Python 标量
prediction_value = pred.item()
# 记录日志
logger.info(f"预测成功: 输入={request.value}, 输出={prediction_value:.4f}")
# 返回响应
return PredictionResponse(
prediction=prediction_value,
input_value=request.value
)
except Exception as e:
# 记录错误
logger.error(f"预测失败: {e}")
# 返回 HTTP 500 错误
raise HTTPException(
status_code=500,
detail=f"预测失败: {str(e)}"
)
# ==================== 批量预测端点(可选)====================
class BatchPredictionRequest(BaseModel):
values: list[float] = Field(
...,
description="输入值列表",
example=[0.1, 0.2, 0.3]
)
class BatchPredictionResponse(BaseModel):
predictions: list[float] = Field(
...,
description="预测结果列表"
)
@app.post("/predict/batch", response_model=BatchPredictionResponse)
def predict_batch(request: BatchPredictionRequest):
"""
批量预测端点
一次处理多个输入,提高效率
"""
try:
# 转换为张量 (batch_size, 1)
X = torch.tensor([[v] for v in request.values], dtype=torch.float32)
with torch.inference_mode():
preds = model(X)
# 转换为列表
predictions = preds.squeeze().tolist()
return BatchPredictionResponse(predictions=predictions)
except Exception as e:
logger.error(f"批量预测失败: {e}")
raise HTTPException(status_code=500, detail=str(e))
# ==================== 运行说明 ====================
#
# 1. 启动服务(开发模式):
# uvicorn api:app --reload
#
# 参数说明:
# - api: 文件名(api.py)
# - app: FastAPI 应用实例
# - --reload: 代码修改后自动重启(仅开发时使用)
#
# 2. 启动服务(生产模式):
# uvicorn api:app --host 0.0.0.0 --port 8000 --workers 4
#
# 参数说明:
# - --host 0.0.0.0: 监听所有网络接口
# - --port 8000: 端口号
# - --workers 4: 工作进程数(根据 CPU 核心数调整)
#
# 3. 访问 API 文档:
# - Swagger UI: http://localhost:8000/docs
# - ReDoc: http://localhost:8000/redoc
#
# 4. 测试 API(使用 curl):
# curl -X POST "http://localhost:8000/predict" \
# -H "Content-Type: application/json" \
# -d '{"value": 0.5}'
#
# 5. 测试 API(使用 Python):
# import requests
# response = requests.post(
# "http://localhost:8000/predict",
# json={"value": 0.5}
# )
# print(response.json())
# ==================== 部署最佳实践 ====================
# 1. 使用环境变量管理配置(模型路径、端口等)
# 2. 添加认证和授权(API Key、JWT)
# 3. 实现请求限流(防止滥用)
# 4. 添加监控和日志(Prometheus、ELK)
# 5. 使用 Docker 容器化部署
# 6. 使用负载均衡器(Nginx、HAProxy)
# 7. 实现优雅关闭(处理完当前请求再关闭)
# 8. 添加缓存(Redis)提高性能
# 9. 使用 HTTPS 加密通信
# 10. 定期更新模型版本
# ==================== Docker 部署示例 ====================
# Dockerfile:
#
# FROM python:3.9-slim
# WORKDIR /app
# COPY requirements.txt .
# RUN pip install --no-cache-dir -r requirements.txt
# COPY api.py model.pth .
# EXPOSE 8000
# CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000"]
#
# 构建镜像:
# docker build -t pytorch-api .
#
# 运行容器:
# docker run -p 8000:8000 pytorch-api第三部分:实战项目
11. 完整项目示例
11.1 项目结构
pytorch_project/
├── data/
│ ├── raw/
│ └── processed/
├── models/
│ └── checkpoints/
├── notebooks/
│ └── exploration.ipynb
├── src/
│ ├── __init__.py
│ ├── data.py # 数据处理
│ ├── model.py # 模型定义
│ ├── train.py # 训练逻辑
│ ├── evaluate.py # 评估逻辑
│ └── utils.py # 工具函数
├── config.yaml # 配置文件
├── requirements.txt # 依赖
└── main.py # 主入口11.2 配置文件 (config.yaml)
yaml
# 数据配置
data:
train_ratio: 0.7
val_ratio: 0.15
test_ratio: 0.15
batch_size: 32
# 模型配置
model:
input_features: 1
output_features: 1
# 训练配置
training:
epochs: 100
learning_rate: 0.01
optimizer: "Adam"
loss_function: "MSE"
# 设备配置
device: "cuda" # or "cpu"
# 保存配置
save:
model_dir: "models"
checkpoint_dir: "models/checkpoints"11.3 完整代码实现
src/data.py
python
"""数据处理模块"""
import torch
from torch.utils.data import TensorDataset, DataLoader, random_split
# ==================== 数据生成函数 ====================
def create_linear_data(weight=0.7, bias=0.3, num_samples=1000):
"""
创建线性回归数据
生成符合 y = weight * x + bias + noise 的数据
用于测试和演示线性回归模型
参数:
weight (float): 线性关系的斜率,默认 0.7
bias (float): 线性关系的截距,默认 0.3
num_samples (int): 生成的样本数量,默认 1000
返回:
X (Tensor): 输入特征,形状 (num_samples, 1)
y (Tensor): 目标值,形状 (num_samples, 1)
"""
# torch.linspace(start, end, steps): 生成等间距的数值
# 在 [0, 1] 区间生成 num_samples 个均匀分布的点
# .unsqueeze(1): 增加一个维度,从 (1000,) 变为 (1000, 1)
# 这是因为 PyTorch 模型期望输入是 2D 张量 (batch_size, features)
X = torch.linspace(0, 1, num_samples).unsqueeze(1)
# 根据线性公式计算目标值: y = wx + b
y = weight * X + bias
# 添加高斯噪声,模拟真实世界数据的随机性
# torch.randn_like(y): 生成与 y 形状相同的标准正态分布随机数
# * 0.02: 控制噪声强度(标准差为 0.02)
y = y + torch.randn_like(y) * 0.02
return X, y
# ==================== 数据加载器准备函数 ====================
def prepare_dataloaders(X, y, train_ratio=0.7, val_ratio=0.15,
batch_size=32, num_workers=2):
"""
准备训练、验证、测试数据加载器
将原始数据按比例分割,并创建 PyTorch DataLoader
用于批量训练和评估模型
参数:
X (Tensor): 输入特征
y (Tensor): 目标值
train_ratio (float): 训练集比例,默认 0.7 (70%)
val_ratio (float): 验证集比例,默认 0.15 (15%)
测试集比例自动计算为 1 - train_ratio - val_ratio
batch_size (int): 每个批次的样本数,默认 32
num_workers (int): 数据加载的并行进程数,默认 2
设为 0 表示在主进程中加载(调试时有用)
返回:
train_loader: 训练数据加载器
val_loader: 验证数据加载器
test_loader: 测试数据加载器
"""
# ========== 步骤 1: 创建 Dataset ==========
# TensorDataset: 将多个张量打包成数据集
# 每个样本是 (X[i], y[i]) 的元组
# 支持索引访问: dataset[0] 返回第一个样本
dataset = TensorDataset(X, y)
# ========== 步骤 2: 计算分割大小 ==========
n = len(dataset) # 总样本数
train_size = int(n * train_ratio) # 训练集大小: 1000 * 0.7 = 700
val_size = int(n * val_ratio) # 验证集大小: 1000 * 0.15 = 150
test_size = n - train_size - val_size # 测试集大小: 1000 - 700 - 150 = 150
# 注意: 使用减法计算 test_size 确保总数正确
# 避免因 int() 截断导致的样本丢失
# ========== 步骤 3: 随机分割数据集 ==========
# random_split: 随机将数据集分割成多个子集
# 参数: (dataset, [size1, size2, size3])
# 返回: 三个 Subset 对象,保持对原数据集的引用
train_ds, val_ds, test_ds = random_split(
dataset,
[train_size, val_size, test_size]
)
# ========== 步骤 4: 创建 DataLoader ==========
# DataLoader: 提供批量数据迭代、打乱、多进程加载等功能
# 训练集 DataLoader
# shuffle=True: 每个 epoch 开始时打乱数据顺序
# 这有助于模型泛化,避免学习到数据顺序的模式
train_loader = DataLoader(
train_ds,
batch_size=batch_size,
shuffle=True, # 训练时打乱数据
num_workers=num_workers # 多进程加载,加速数据准备
)
# 验证集 DataLoader
# shuffle=False: 验证时不需要打乱,保证每次评估结果一致
val_loader = DataLoader(
val_ds,
batch_size=batch_size,
shuffle=False, # 验证时不打乱
num_workers=num_workers
)
# 测试集 DataLoader
# 与验证集相同,不打乱数据
test_loader = DataLoader(
test_ds,
batch_size=batch_size,
shuffle=False, # 测试时不打乱
num_workers=num_workers
)
return train_loader, val_loader, test_loader
# ==================== 使用示例 ====================
# X, y = create_linear_data(weight=0.7, bias=0.3, num_samples=1000)
# train_loader, val_loader, test_loader = prepare_dataloaders(X, y)
#
# # 迭代训练数据
# for batch_X, batch_y in train_loader:
# print(f"批次形状: X={batch_X.shape}, y={batch_y.shape}")
# # 输出: 批次形状: X=torch.Size([32, 1]), y=torch.Size([32, 1])src/model.py
python
"""
模型定义模块
职责:
- 定义神经网络架构
- 提供模型创建工厂函数
"""
import torch
from torch import nn
# ==================== 模型类定义 ====================
class LinearRegressionModel(nn.Module):
"""
线性回归模型
实现简单的线性变换: y = Wx + b
参数:
input_features (int): 输入特征数量,默认 1
output_features (int): 输出特征数量,默认 1
示例:
model = LinearRegressionModel(input_features=2, output_features=1)
output = model(torch.randn(32, 2)) # 输出形状: (32, 1)
"""
def __init__(self, input_features=1, output_features=1):
# 必须调用父类的 __init__
# 这会初始化 nn.Module 的内部状态(参数注册、钩子等)
super().__init__()
# nn.Linear: 全连接层(线性层)
# 内部包含:
# - weight: 形状 (output_features, input_features) 的权重矩阵
# - bias: 形状 (output_features,) 的偏置向量
# 计算: output = input @ weight.T + bias
self.linear = nn.Linear(input_features, output_features)
def forward(self, x):
"""
前向传播
参数:
x (Tensor): 输入张量,形状 (batch_size, input_features)
返回:
Tensor: 输出张量,形状 (batch_size, output_features)
"""
return self.linear(x)
# ==================== 模型工厂函数 ====================
def create_model(config, device="cpu"):
"""
根据配置创建模型
工厂模式:将模型创建逻辑封装,便于统一管理
参数:
config (dict): 配置字典,需包含 config['model']['input_features'] 等
device (str): 目标设备,"cpu" 或 "cuda"
返回:
nn.Module: 已移动到指定设备的模型实例
"""
model = LinearRegressionModel(
input_features=config['model']['input_features'],
output_features=config['model']['output_features']
)
# .to(device): 将模型的所有参数移动到指定设备
# 必须在训练前完成,确保模型和数据在同一设备上
return model.to(device)src/train.py
python
"""
训练模块
职责:
- 单个 epoch 的训练逻辑
- 验证逻辑
- 完整训练流程编排
"""
import torch
from torch import nn
from tqdm.auto import tqdm # 进度条库,auto 版本自动适配环境(notebook/终端)
# ==================== 单 Epoch 训练函数 ====================
def train_epoch(model, dataloader, loss_fn, optimizer, device):
"""
训练一个 epoch
执行完整的训练循环:遍历所有批次,更新模型参数
参数:
model: 要训练的模型
dataloader: 训练数据加载器
loss_fn: 损失函数
optimizer: 优化器
device: 计算设备
返回:
float: 该 epoch 的平均损失
"""
# 设置为训练模式
# 启用 Dropout、BatchNorm 的训练行为
model.train()
total_loss = 0
# 遍历所有批次
for X, y in dataloader:
# ========== 数据移动到设备 ==========
# 确保数据和模型在同一设备上
X, y = X.to(device), y.to(device)
# ========== 前向传播 ==========
y_pred = model(X) # 模型预测
loss = loss_fn(y_pred, y) # 计算损失
# ========== 反向传播 ==========
optimizer.zero_grad() # 清零梯度(PyTorch 默认累积梯度)
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 累积损失
# .item(): 将单元素张量转换为 Python 数值
# 这会将数据从 GPU 复制到 CPU,所以只在需要时使用
total_loss += loss.item()
# 返回平均损失
return total_loss / len(dataloader)
# ==================== 验证函数 ====================
def validate(model, dataloader, loss_fn, device):
"""
验证函数
在验证集上评估模型性能,不更新参数
参数:
model: 要验证的模型
dataloader: 验证数据加载器
loss_fn: 损失函数
device: 计算设备
返回:
float: 验证集的平均损失
"""
# 设置为评估模式
# 禁用 Dropout,BatchNorm 使用运行时统计量
model.eval()
total_loss = 0
# torch.inference_mode(): 禁用梯度计算
# 比 torch.no_grad() 更高效
# 用于推理/评估,节省内存和计算
with torch.inference_mode():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
y_pred = model(X)
loss = loss_fn(y_pred, y)
total_loss += loss.item()
return total_loss / len(dataloader)
# ==================== 完整训练流程 ====================
def train(model, train_loader, val_loader, config, device):
"""
完整训练流程
编排整个训练过程:设置优化器、执行训练循环、记录历史
参数:
model: 要训练的模型
train_loader: 训练数据加载器
val_loader: 验证数据加载器
config: 配置字典
device: 计算设备
返回:
dict: 训练历史,包含 'train_loss' 和 'val_loss' 列表
"""
# ========== 设置损失函数和优化器 ==========
# MSELoss: 均方误差,适用于回归问题
# 公式: MSE = (1/n) * Σ(y_pred - y_true)²
loss_fn = nn.MSELoss()
# Adam 优化器: 自适应学习率,通常效果好
# 从配置文件读取学习率,便于调参
optimizer = torch.optim.Adam(
model.parameters(), # 要优化的参数
lr=config['training']['learning_rate'] # 学习率
)
# ========== 训练循环 ==========
epochs = config['training']['epochs']
# 记录训练历史,用于后续可视化和分析
history = {'train_loss': [], 'val_loss': []}
# tqdm: 显示进度条
for epoch in tqdm(range(epochs), desc="Training"):
# 训练一个 epoch
train_loss = train_epoch(model, train_loader, loss_fn,
optimizer, device)
# 验证
val_loss = validate(model, val_loader, loss_fn, device)
# 记录历史
history['train_loss'].append(train_loss)
history['val_loss'].append(val_loss)
# 每 10 个 epoch 打印一次进度
if epoch % 10 == 0:
print(f"Epoch {epoch}: Train Loss = {train_loss:.4f}, "
f"Val Loss = {val_loss:.4f}")
return historysrc/evaluate.py
python
"""
评估模块
职责:
- 在测试集上评估模型
- 计算各种评估指标
"""
import torch
import numpy as np
# ==================== 模型评估函数 ====================
def evaluate_model(model, dataloader, device):
"""
评估模型
在测试集上运行模型,计算回归评估指标
参数:
model: 要评估的模型
dataloader: 测试数据加载器
device: 计算设备
返回:
dict: 包含各种评估指标的字典
- MAE: 平均绝对误差
- MSE: 均方误差
- RMSE: 均方根误差
"""
# 设置为评估模式
model.eval()
# 存储所有批次的预测和目标值
all_preds = []
all_targets = []
# 禁用梯度计算
with torch.inference_mode():
for X, y in dataloader:
# 只需要将输入移动到设备
X = X.to(device)
y_pred = model(X)
# 将预测结果移回 CPU 并存储
# .cpu(): 将张量从 GPU 移动到 CPU
# 这是必要的,因为最终需要在 CPU 上合并所有结果
all_preds.append(y_pred.cpu())
all_targets.append(y) # y 本来就在 CPU 上
# ========== 合并所有批次 ==========
# torch.cat: 沿指定维度拼接张量列表
# 将多个 (batch_size, 1) 的张量合并为 (total_samples, 1)
predictions = torch.cat(all_preds)
targets = torch.cat(all_targets)
# ========== 计算评估指标 ==========
# MAE (Mean Absolute Error) - 平均绝对误差
# 公式: MAE = (1/n) * Σ|y_pred - y_true|
# 特点: 对异常值不敏感,直观易理解
mae = torch.mean(torch.abs(predictions - targets))
# MSE (Mean Squared Error) - 均方误差
# 公式: MSE = (1/n) * Σ(y_pred - y_true)²
# 特点: 对大误差惩罚更重,常用于优化目标
mse = torch.mean((predictions - targets) ** 2)
# RMSE (Root Mean Squared Error) - 均方根误差
# 公式: RMSE = √MSE
# 特点: 与原始数据单位相同,更易解释
rmse = torch.sqrt(mse)
# .item(): 将单元素张量转换为 Python 数值
return {
'MAE': mae.item(),
'MSE': mse.item(),
'RMSE': rmse.item()
}main.py
python
"""
主程序入口
职责:
- 加载配置
- 编排整个训练流程
- 协调各模块之间的调用
"""
import torch
import yaml
from pathlib import Path
# 从各模块导入函数
from src.data import create_linear_data, prepare_dataloaders
from src.model import create_model
from src.train import train
from src.evaluate import evaluate_model
def main():
"""
主函数 - 完整的机器学习流程
流程:
1. 加载配置
2. 设置设备
3. 准备数据
4. 创建模型
5. 训练模型
6. 评估模型
7. 保存模型
"""
# ========== 步骤 1: 加载配置 ==========
# 使用 YAML 配置文件管理超参数
# 优点: 易于修改、版本控制、实验追踪
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
# ========== 步骤 2: 设置设备 ==========
# 优先使用 GPU(如果可用)
# torch.cuda.is_available(): 检查 CUDA 是否可用
device = config['device'] if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
# ========== 步骤 3: 准备数据 ==========
print("Creating data...")
X, y = create_linear_data(num_samples=1000)
print("Preparing dataloaders...")
train_loader, val_loader, test_loader = prepare_dataloaders(
X, y,
train_ratio=config['data']['train_ratio'],
val_ratio=config['data']['val_ratio'],
batch_size=config['data']['batch_size']
)
# ========== 步骤 4: 创建模型 ==========
print("Creating model...")
model = create_model(config, device)
# ========== 步骤 5: 训练模型 ==========
print("Training model...")
history = train(model, train_loader, val_loader, config, device)
# ========== 步骤 6: 评估模型 ==========
print("\nEvaluating model...")
metrics = evaluate_model(model, test_loader, device)
# 打印测试指标
print("Test Metrics:")
for name, value in metrics.items():
print(f" {name}: {value:.4f}")
# ========== 步骤 7: 保存模型 ==========
# 使用 pathlib 处理路径(跨平台兼容)
model_dir = Path(config['save']['model_dir'])
model_dir.mkdir(exist_ok=True) # 创建目录(如果不存在)
model_path = model_dir / 'final_model.pth'
# torch.save(): 保存模型
# model.state_dict(): 只保存模型参数(推荐方式)
# 优点: 文件小、加载灵活、不依赖模型类定义的位置
torch.save(model.state_dict(), model_path)
print(f"\nModel saved to {model_path}")
# ==================== 程序入口 ====================
# 当直接运行此文件时执行 main()
# 当被其他文件 import 时不执行
if __name__ == "__main__":
main()12. 常见问题与解决方案
12.1 训练问题
Q1: 损失不下降
可能原因和解决方案:
python
# 1. 学习率太小
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 尝试增大
# 2. 学习率太大
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001) # 尝试减小
# 3. 检查梯度是否为 None
for name, param in model.named_parameters():
if param.grad is None:
print(f"{name} has no gradient!")
# 4. 检查是否忘记调用 optimizer.zero_grad()
optimizer.zero_grad() # 必须在 loss.backward() 之前
# 5. 使用不同的优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)Q2: 模型过拟合
python
# 1. 添加 Dropout
class ModelWithDropout(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(10, 50)
self.dropout = nn.Dropout(0.5)
self.linear2 = nn.Linear(50, 1)
def forward(self, x):
x = torch.relu(self.linear1(x))
x = self.dropout(x)
return self.linear2(x)
# 2. 使用权重衰减 (L2 正则化)
optimizer = torch.optim.Adam(model.parameters(),
lr=0.001,
weight_decay=1e-4)
# 3. 早停
# (见前面的早停实现)
# 4. 数据增强 (对于图像/文本)
# 5. 使用更多训练数据Q3: 模型欠拟合
python
# 1. 增加模型复杂度
class BiggerModel(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.layers(x)
# 2. 训练更多 epochs
epochs = 500 # 增加
# 3. 降低正则化强度
optimizer = torch.optim.Adam(model.parameters(),
lr=0.001,
weight_decay=1e-5) # 减小
# 4. 尝试更复杂的特征工程12.2 性能问题
Q4: 训练速度慢
python
# 1. 使用 GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
# 2. 增加 batch size
train_loader = DataLoader(dataset, batch_size=64) # 增大
# 3. 使用 DataLoader 的 num_workers
train_loader = DataLoader(dataset, num_workers=4, pin_memory=True)
# 4. 使用混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
output = model(input)
loss = loss_fn(output, target)
# 5. 使用 torch.compile (PyTorch 2.0+)
model = torch.compile(model)Q5: 内存不足
python
# 1. 减小 batch size
train_loader = DataLoader(dataset, batch_size=16) # 减小
# 2. 使用梯度累积
# (见前面的梯度累积实现)
# 3. 使用梯度检查点 (Gradient Checkpointing)
from torch.utils.checkpoint import checkpoint
def forward(self, x):
x = checkpoint(self.layer1, x)
x = checkpoint(self.layer2, x)
return x
# 4. 清理缓存
torch.cuda.empty_cache()
# 5. 使用 FP16
model = model.half()12.3 数据问题
Q6: 数据不平衡
python
# 1. 使用加权损失函数
weights = torch.tensor([1.0, 10.0]) # 类别权重
loss_fn = nn.CrossEntropyLoss(weight=weights)
# 2. 过采样少数类
from torch.utils.data import WeightedRandomSampler
# 计算样本权重
samples_weight = [...] # 根据类别分配权重
sampler = WeightedRandomSampler(samples_weight, len(samples_weight))
train_loader = DataLoader(dataset, sampler=sampler)
# 3. 欠采样多数类Q7: 数据标准化
python
# 标准化数据 (均值=0, 标准差=1)
mean = X_train.mean()
std = X_train.std()
X_train_normalized = (X_train - mean) / std
X_test_normalized = (X_test - mean) / std
# 注意: 使用训练集的统计量来标准化测试集📊 性能对比表
优化技术效果对比
| 技术 | 训练速度提升 | 内存节省 | 精度影响 | 实现难度 |
|---|---|---|---|---|
| AMP | 1.5-3x | 50% | 无 | 低 |
| 梯度累积 | -10% | 75% | 无 | 低 |
| DataLoader workers | 1.5-2x | 无 | 无 | 低 |
| Gradient Checkpointing | -20% | 80% | 无 | 中 |
| 模型量化 | 2-4x | 75% | 微小 | 中 |
| ONNX导出 | 1.2-2x | 无 | 无 | 低 |
🎓 学习检查清单
完成本教程后,你应该能够:
- 理解 PyTorch 的完整工作流程
- 创建和划分数据集
- 构建自定义 PyTorch 模型
- 实现训练和评估循环
- 使用各种损失函数和优化器
- 保存和加载模型
- 应用混合精度训练
- 实现学习率调度
- 使用 TensorBoard/W&B 监控训练
- 导出模型为 ONNX
- 处理常见的训练问题
- 优化训练性能
- 构建完整的机器学习项目
📚 推荐资源
官方文档
学习资源
书籍推荐
- "Deep Learning with PyTorch" (官方书籍)
- "Programming PyTorch for Deep Learning"
在线课程
- Fast.ai - Practical Deep Learning
- Coursera - Deep Learning Specialization
- Zero to Mastery - PyTorch for Deep Learning
🚀 下一步
完成本教程后,建议学习:
- 02 - Neural Network Classification - 神经网络分类
- 03 - Computer Vision - 计算机视觉
- 04 - Custom Datasets - 自定义数据集
- 05 - Going Modular - 模块化开发
- 06 - Transfer Learning - 迁移学习
- 07 - Experiment Tracking - 实验追踪
- 08 - Model Deployment - 模型部署
📝 总结
本教程涵盖了:
✅ 基础工作流程 - 从数据到部署的完整流程
✅ 核心概念 - 模型、损失、优化器、训练循环
✅ 最佳实践 - 数据划分、模型保存、推理模式
✅ 高级技术 - AMP、梯度累积、学习率调度
✅ 性能优化 - 提升训练速度和减少内存使用
✅ 生产部署 - ONNX 导出、量化、API 服务
✅ 实战项目 - 完整的项目结构和代码
✅ 问题解决 - 常见问题的诊断和解决
记住: 机器学习是一个迭代的过程。不断实验、可视化、调试,直到获得满意的结果!