VLM相关论文阅读:【LoRA】Low-rank Adaptation of Large Language Models
- [【前言】论文简介 🍀](#【前言】论文简介 🍀)
- 1、介绍(Introduction)🐳
- [2、问题陈述(Problem Statement) 🌟](#2、问题陈述(Problem Statement) 🌟)
- [3、现有的解决方案还不够好吗?(Aren't Existing Solutions good enough?)🙋](#3、现有的解决方案还不够好吗?(Aren't Existing Solutions good enough?)🙋)
- [4、论文方法(Our Method)🔧](#4、论文方法(Our Method)🔧)
-
- [4.1 低秩参数化更新矩阵(Low-rank-Parametrized Update Matrices)](#4.1 低秩参数化更新矩阵(Low-rank-Parametrized Update Matrices))
- [4.2 将LoRA应用于Transformer(Applying LoRA to Transformer)](#4.2 将LoRA应用于Transformer(Applying LoRA to Transformer))
- [5、实证实验(Empirical Experiments)](#5、实证实验(Empirical Experiments))
- [6、相关工作(Related Works)](#6、相关工作(Related Works))
- [7、理解低秩更新(Understanding the Low-rank Updates)🧮](#7、理解低秩更新(Understanding the Low-rank Updates)🧮)
-
- [7.1 应当将 LoRA 应用于 Transformer 中的哪些权重矩阵?(Which Weight Matrices in Transformer Should We Apply LoRA to?)](#7.1 应当将 LoRA 应用于 Transformer 中的哪些权重矩阵?(Which Weight Matrices in Transformer Should We Apply LoRA to?))
- [7.2 LoRA 的最优秩 r r r 是多少?(What Is the Optimal Rank r for LoRA?)](#7.2 LoRA 的最优秩 r r r 是多少?(What Is the Optimal Rank r for LoRA?))
- [7.3 适应矩阵 Δ W \Delta W ΔW 与 W W W 相比如何?(How Does the Adaptation Matrix ∆W Compare to W ?)](#7.3 适应矩阵 Δ W \Delta W ΔW 与 W W W 相比如何?(How Does the Adaptation Matrix ∆W Compare to W ?))
- [8、结论和未来工作(Conclusion and Future Work)🚀](#8、结论和未来工作(Conclusion and Future Work)🚀)
【前言】论文简介 🍀
- 📖 题目:【LoRA】Low-rank adaptation of large language models
- 🏫 单位:Microsoft Corporation
- 🌍 主页:https://github.com/microsoft/LoRA
- ✒️ 摘要:自然语言处理的一个重要范式是在通用领域数据上进行大规模预训练,然后适应特定任务或领域。随着预训练模型越来越大,重新训练所有模型参数的全量微调变得越发不可行。以GPT-3 175B为例,部署每一个都拥有1750亿参数的独立微调模型实例,其成本是极其高昂的。论文提出了低秩自适应(LoRA),该方法冻结预训练模型的权重,并将可训练的秩分解矩阵注入Transformer架构的每一层,从而大大减少了下游任务所需的可训练参数数量。与使用Adam优化器微调GPT-3 175B相比,LoRA可以将可训练参数数量减少10000倍,并将GPU显存需求降低3倍。尽管LoRA拥有的可训练参数更少、训练吞吐量更高,且与adapter不同的是没有额外的推理延迟,但其在RoBERTa、DeBERTa、GPT-2和GPT-3上的模型质量表现仍能与全量微调媲美甚至更好。论文还对语言模型适配中的秩亏现象进行了实证研究,从而阐明了LoRA的有效性。论文发布了一个软件包以促进LoRA与PyTorch模型的集成,并在https://github.com/microsoft/LoRA提供了针对RoBERTa、DeBERTa和GPT-2的实现代码及模型检查点文件。
1、介绍(Introduction)🐳
自然语言处理中的许多应用都依赖于将一个大规模预训练语言模型适配到多个下游应用中。这种适配通常是通过微调完成的,该过程会更新预训练模型的所有参数。微调的主要缺点是新模型包含与原始模型一样多的参数。随着更大的模型每隔几个月就被训练出来,对于GPT-2或RoBERTa large来说这仅仅是一种"不便",但对于拥有1750亿可训练参数的GPT-3来说,这已经变成了一个关键的部署挑战。
许多人试图通过仅适配部分参数或为新任务学习外部模块来缓解这一问题。通过这种方式,对于每个任务,除了预训练模型外,只需要存储和加载少量特定于任务的参数,从而在部署时极大地提高了运行效率。然而,现有技术通常会因增加模型深度而引入推理延迟,或者减少模型的可用序列长度。更重要的是,这些方法往往无法达到微调基线的性能,从而在效率和模型质量之间形成了权衡。
论文从先前的研究中获得灵感,这些研究表明学习到的过参数化模型实际上存在于一个低内在维度上。论文假设模型适配过程中的权重变化也具有较低的"内在秩",从而引出了论文提出的低秩自适应即LoRA方法。 LoRA允许通过优化适配过程中稠密层变化的秩分解矩阵来间接训练神经网络中的一些稠密层,同时保持预训练权重冻结。以GPT-3 175B为例,论文展示了即使在全秩高达12288的情况下,一个非常低的秩(例如r可以为1或2)也已足够,这使得LoRA在存储和计算方面都非常高效。
LoRA拥有几个关键优势:
- 一个预训练模型可以被共享并用于构建许多用于不同任务的小型LoRA模块。论文可以通过替换图中的矩阵A和B来冻结共享模型并高效地切换任务,从而显著降低存储需求和任务切换的开销。
- LoRA使训练更加高效,并且在使用自适应优化器时将硬件门槛降低了多达3倍,因为不需要为大多数参数计算梯度或维护优化器状态。相反,论文只优化注入的、小得多的低秩矩阵。
- 论文简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,从构造上保证了与全量微调模型相比没有引入推理延迟。
- LoRA与许多先前的方法是正交的,并且可以与其中许多方法结合使用,例如前缀微调。论文在附录E中提供了一个示例。
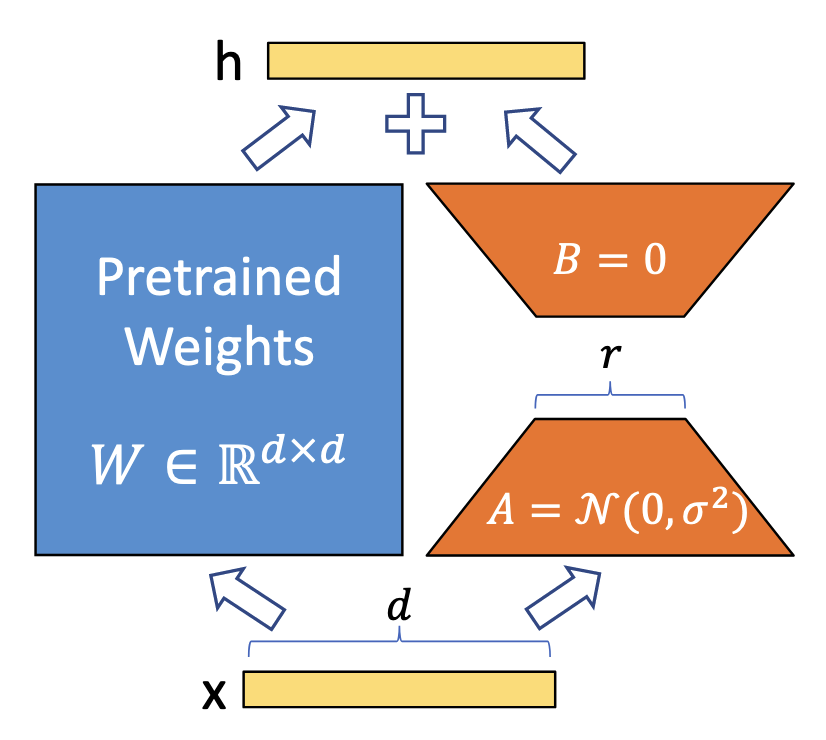
图1:论文的重参数化。论文仅训练A和B。
术语和约定(Terminologies and Conventions) 论文频繁引用Transformer架构,并使用常规术语来描述其维度。论文将Transformer层的输入和输出维度大小称为 d m o d e l d_{model} dmodel。论文使用 W q 、 W k 、 W v W_q、W_k、W_v Wq、Wk、Wv和 W o W_o Wo指代自注意力模块中的查询、键、值和输出投影矩阵。 W W W 或 W 0 W_0 W0 指代预训练权重矩阵, ∆ W ∆W ∆W 指代其在适配过程中的累积梯度更新。论文使用 r r r 表示LoRA模块的秩。论文遵循既定约定,使用Adam进行模型优化,并使用 d f f n = 4 × d m o d e l d_{ffn} = 4 × d_{model} dffn=4×dmodel 作为Transformer MLP前馈维度。
2、问题陈述(Problem Statement) 🌟
虽然论文的提议与训练目标无关,但论文专注于语言建模作为驱动用例。下面是对语言建模问题的简要描述,特别是给定特定任务提示时条件概率的最大化。
假设给定一个由 Φ \Phi Φ 参数化的预训练自回归语言模型 P Φ ( y ∣ x ) P_{\Phi}(y|x) PΦ(y∣x)。例如, P Φ ( y ∣ x ) P_{\Phi}(y|x) PΦ(y∣x) 可以是基于 Transformer 架构的通用多任务学习器,如 GPT。考虑将此预训练模型适配到下游条件文本生成任务,例如摘要、机器阅读理解 (MRC) 和自然语言转 SQL (NL2SQL)。每个下游任务由上下文-目标对的训练数据集 Z = { ( x i , y i ) } i = 1 , . . , N \mathcal{Z} = \{(x_i, y_i)\}_{i=1,..,N} Z={(xi,yi)}i=1,..,N 表示,其中 x i x_i xi 和 y i y_i yi 都是 token 序列。例如,在 NL2SQL 中, x i x_i xi 是自然语言查询, y i y_i yi 是其对应的 SQL 命令;对于摘要, x i x_i xi 是文章内容, y i y_i yi 是其摘要。
在全量微调期间,模型被初始化为预训练权重 Φ 0 \Phi_0 Φ0,并通过反复跟随梯度更新为 Φ 0 + Δ Φ \Phi_0 + \Delta\Phi Φ0+ΔΦ,以最大化条件语言建模目标:
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) ( 1 ) \max_{\Phi} \sum_{(x,y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log (P_{\Phi}(y_t | x, y_{<t})) \quad (1) Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))(1)
全量微调的一个主要缺点是,对于每个下游任务,都需要学习一组不同的参数 Δ Φ \Delta\Phi ΔΦ,其维度 ∣ Δ Φ ∣ |\Delta\Phi| ∣ΔΦ∣ 等于 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣。因此,如果预训练模型很大(例如 ∣ Φ 0 ∣ ≈ 1750 |\Phi_0| \approx 1750 ∣Φ0∣≈1750 亿的 GPT-3),存储和部署许多独立的微调模型实例将面临挑战,甚至根本不可行。
在接下来的章节中,论文提议使用一种低秩表示来编码 Δ Φ \Delta\Phi ΔΦ,这既具有计算效率又具有存储效率。当预训练模型是 GPT-3 175B 时,可训练参数的数量 ∣ Θ ∣ |\Theta| ∣Θ∣ 可以小至 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣ 的 0.01%。
3、现有的解决方案还不够好吗?(Aren't Existing Solutions good enough?)🙋
论文着手解决的问题绝非新鲜事。自迁移学习诞生以来,已有数十项工作致力于使模型适配在参数和计算方面更加高效。请参阅第6节关于一些知名工作的综述。以语言建模为例,在涉及高效适配时主要有两种策略:添加适配器层或优化某种形式的输入层激活。然而,这两种策略都有其局限性,特别是在大规模且对延迟敏感的生产场景中。
适配器层引入推理延迟(Adapter Layers Introduce Inference Latency)。适配器存在许多变体。论文重点关注 Houlsby 等人的原始设计(每个 Transformer 块包含两个适配器层)以及 Lin 等人较新的设计(每块仅包含一个适配器层,但具有额外的 LayerNorm)。虽然可以通过剪枝层或利用多任务设置来降低整体延迟,但没有直接方法可以绕过适配器层中的额外计算。这似乎不是个问题,因为适配器层通过采用较小的瓶颈维度,设计为仅包含极少量的参数(有时小于原始模型的 1%),从而限制了它们增加的 FLOPs。然而,大型神经网络依赖硬件并行性来保持低延迟,而适配器层必须被顺序处理。这在批大小通常小至 1 的在线推理场景中会有明显影响。在没有模型并行的通用场景中,例如在单个 GPU 上对 GPT-2 medium 进行推理,论文观察到使用适配器时延迟显著增加,即使瓶颈维度非常小也是如此(表 1)。
当需要像Shoeybi等人(2020)或Lepikhin等人(2020)那样对模型进行分片时,这个问题会变得更加严重,因为除非多次冗余地存储适配器参数,否则额外的深度需要更多的同步GPU操作,例如AllReduce和Broadcast。
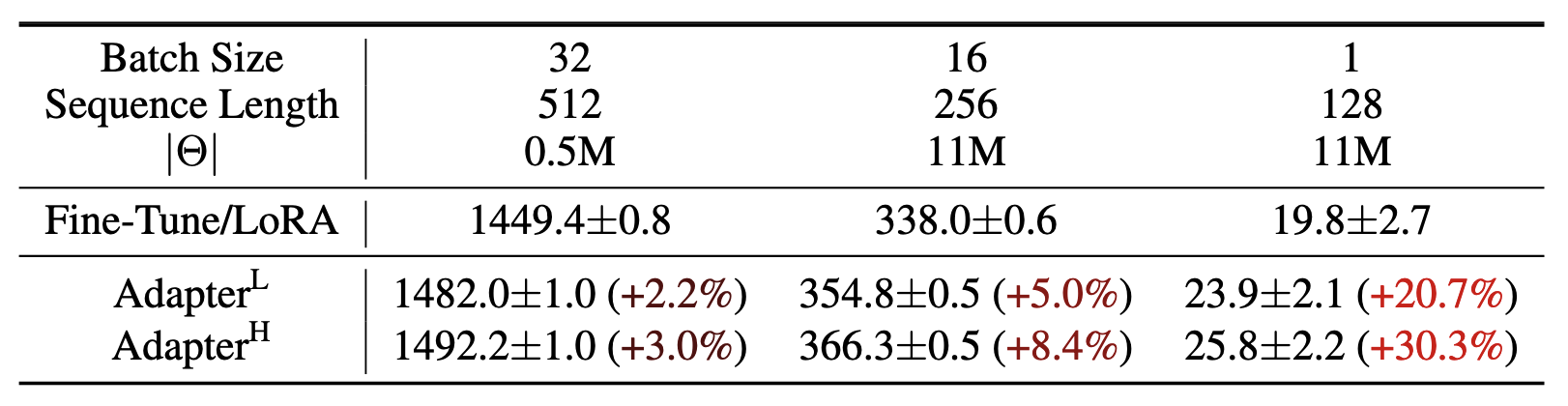
表1:GPT-2 medium中单次前向传播的推理延迟(以毫秒为单位),取100次试验的平均值。论文使用的是NVIDIA Quadro RTX8000。" ∣ Θ ∣ |\Theta| ∣Θ∣"表示适配器层中可训练参数的数量。AdapterL和AdapterH是适配器微调的两种变体,论文在第5.1节中对其进行了描述。在在线、短序列长度的场景中,适配器层引入的推理延迟可能是显著的。详见附录B中的完整研究。
直接优化提示很难(Directly Optimizing the Prompt is Hard) 另一个方向,以前缀微调为例,面临着不同的挑战。论文观察到前缀微调很难优化,并且其性能随可训练参数的变化呈现非单调变化,这证实了原始论文中的类似观察结果。更根本的是,为适配保留一部分序列长度必然会减少用于处理下游任务的可用序列长度,论文推测这使得提示微调与其他方法相比性能较差。论文将任务性能的研究留待第5节讨论。
相关文章:Prefix-Tuning: Optimizing Continuous Prompts for Generation.
4、论文方法(Our Method)🔧
论文描述了LoRA的简单设计及其其实际优势。尽管论文在实验中仅关注Transformer语言模型中的某些权重作为驱动用例,但此处概述的原则适用于深度学习模型中的任何稠密层。
4.1 低秩参数化更新矩阵(Low-rank-Parametrized Update Matrices)
神经网络包含许多执行矩阵乘法的稠密层。这些层中的权重矩阵通常具有满秩。当适配特定任务时,Aghajanyan等人表明预训练语言模型具有较低的"内在维度",尽管随机投影到较小的子空间,仍能有效地学习。受此启发,论文假设在适配过程中权重的更新也具有较低的"内在秩"。对于预训练权重矩阵 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k,论文通过用低秩分解 W 0 + Δ W = W 0 + B A W_0 + \Delta W = W_0 + BA W0+ΔW=W0+BA 来表示更新,从而限制其更新,其中 B ∈ R d × r B \in \mathbb{R}^{d \times r} B∈Rd×r, A ∈ R r × k A \in \mathbb{R}^{r \times k} A∈Rr×k,且秩 r ≪ min ( d , k ) r \ll \min(d, k) r≪min(d,k)。在训练期间, W 0 W_0 W0 被冻结且不接受梯度更新,而 A A A 和 B B B 包含可训练参数。注意 W 0 W_0 W0 和 Δ W = B A \Delta W = BA ΔW=BA 都与相同的输入相乘,并且它们各自的输出向量按坐标相加。对于 h = W 0 x h = W_0x h=W0x,论文修改后的前向传播得出:
h = W 0 x + Δ W x = W 0 x + B A x ( 3 ) h = W_0x + \Delta W x = W_0x + BAx \quad (3) h=W0x+ΔWx=W0x+BAx(3)
论文在图1中展示了这种重参数化。论文对 A A A 使用随机高斯初始化,对 B B B 使用零初始化,因此 Δ W = B A \Delta W = BA ΔW=BA 在训练开始时为零。论文随后将 Δ W x \Delta W x ΔWx 按 α r \frac{\alpha}{r} rα 进行缩放,其中 α \alpha α 是一个常数。当使用Adam进行优化时,如果适当地缩放初始化,调整 α \alpha α 大致相当于调整学习率。因此,论文简单地将 α \alpha α 设置为尝试的第一个 r r r 的值,且不再对其进行调整。这种缩放有助于减少在改变 r r r时重新调整超参数的需要。
图1:论文的重参数化。论文仅训练A和B。
全量微调的推广(A Generalization of Full Fine-tuning) 。微调的一种更通用的形式允许训练预训练参数的一个子集。LoRA更进一步,不要求权重矩阵在适配过程中的累积梯度更新具有满秩。这意味着当将LoRA应用于所有权重矩阵并训练所有偏置时,通过将LoRA的秩 r r r 设置为预训练权重矩阵的秩,论文大致恢复了全量微调的表达能力。换句话说,随着可训练参数数量的增加,训练LoRA大致收敛于训练原始模型,而基于适配器的方法收敛于MLP,基于前缀的方法则收敛于一个无法处理长输入序列的模型。
无额外推理延迟(No Additional Inference Latency) 。当部署在生产环境中时,论文可以显式计算并存储 W = W 0 + B A W = W_0 + BA W=W0+BA 并照常进行推理。注意 W 0 W_0 W0 和 B A BA BA 都属于 R d × k \mathbb{R}^{d \times k} Rd×k。当需要切换到另一个下游任务时,论文可以通过减去 B A BA BA 然后加上不同的 B ′ A ′ B'A' B′A′ 来恢复 W 0 W_0 W0,这是一项内存开销极小的快速操作。至关重要的是,这在构造上保证了与微调模型相比,论文在推理过程中没有引入任何额外的延迟。
4.2 将LoRA应用于Transformer(Applying LoRA to Transformer)
原则上,可以将LoRA应用于神经网络中权重矩阵的任何子集,以减少可训练参数的数量。在Transformer架构中,自注意力模块包含四个权重矩阵( W q W_q Wq、 W k W_k Wk、 W v W_v Wv、 W o W_o Wo),MLP模块包含两个。论文将 W q W_q Wq(或 W k W_k Wk、 W v W_v Wv)视为维度为 d m o d e l × d m o d e l d_{model} \times d_{model} dmodel×dmodel的单个矩阵,尽管输出维度通常被切分成注意力头。出于简单性和参数效率的考虑,论文限制其研究仅针对下游任务适配注意力权重,并冻结MLP模块(因此它们不会在下游任务中被训练)。论文在7.1节进一步研究了在Transformer中适配不同类型的注意力权重矩阵的影响。论文将适配MLP层、LayerNorm层和偏置的实证研究留待未来的工作。
实际优势与局限性(Practical Benefits and Limitations) 。最显著的优势来自于内存和存储使用量的减少。对于使用Adam训练的大型Transformer,如果 r ≪ d m o d e l r \ll d_{model} r≪dmodel,论文将显存使用量减少了多达2/3,因为不需要为冻结参数存储优化器状态。在GPT-3 175B上,论文将训练期间的显存消耗从1.2TB降低到了350GB。当 r = 4 r=4 r=4 且仅适配查询和值投影矩阵时,检查点大小减少了大约10000倍(从350GB减少到35MB)。这使得可以用显著更少的GPU进行训练并避免I/O瓶颈。另一个优势是,论文可以在部署时以低得多的成本在任务之间切换,只需交换LoRA权重而不是所有参数。这允许创建许多定制模型,这些模型可以在将预训练权重存储在显存中的机器上即时换入和换出。论文还观察到,与全量微调相比,GPT-3 175B的训练速度提高了25%,因为不需要计算绝大多数参数的梯度。
LoRA也有其局限性。例如,如果选择将A和B吸收到W中以消除额外的推理延迟,那么在单次前向传播中,将使用不同A和B的不同任务的输入进行批处理就不是一件容易的事。虽然在对延迟要求不高的场景中,可以不合并权重,并针对一个批次中的样本动态选择要使用的LoRA模块。
5、实证实验(Empirical Experiments)
省略。这部分不是重点。
6、相关工作(Related Works)
省略。这部分不是重点。
7、理解低秩更新(Understanding the Low-rank Updates)🧮
鉴于 LoRA 的实证优势,论文希望进一步阐述从下游任务中学习到的低秩适应的性质。值得注意的是,低秩结构不仅降低了硬件门槛,使得并行运行多个实验成为可能,而且还就更新权重如何与预训练权重相关联提供了更好的可解释性。论文的研究重点是 GPT-3 175B,在该模型上实现了最大程度的可训练参数缩减(高达 10 , 000 × 10,000\times 10,000×),且未对任务性能产生负面影响。
论文进行了一系列实证研究以回答以下问题:1) 给定参数预算约束,应当调整预训练 Transformer 中权重矩阵的哪个子集,以最大化下游性能?2) "最优"适应矩阵 Δ W \Delta W ΔW 真的是秩亏的吗?如果是,实践中使用什么秩比较好?3) Δ W \Delta W ΔW 和 W W W 之间有什么联系? Δ W \Delta W ΔW 与 W W W 高度相关吗?相比于 W W W, Δ W \Delta W ΔW 有多大?
论文认为,对问题 (2) 和 (3) 的回答揭示了将预训练语言模型用于下游任务的基本原理,这是 NLP 中的一个关键课题。
7.1 应当将 LoRA 应用于 Transformer 中的哪些权重矩阵?(Which Weight Matrices in Transformer Should We Apply LoRA to?)
在给定有限参数预算的情况下,为了在下游任务中获得最佳性能,论文应该用 LoRA 调整哪种类型的权重?正如第 4.2 节所述,论文仅考虑自注意力模块中的权重矩阵。论文在 GPT-3 175B 上设定了 18M 的参数预算(若以 FP16 存储约 35MB),对于所有 96 层而言,这对应于如果调整一种类型的注意力权重则 r = 8 r=8 r=8,或者如果调整两种类型则 r = 4 r=4 r=4。结果展示在表 5 中。
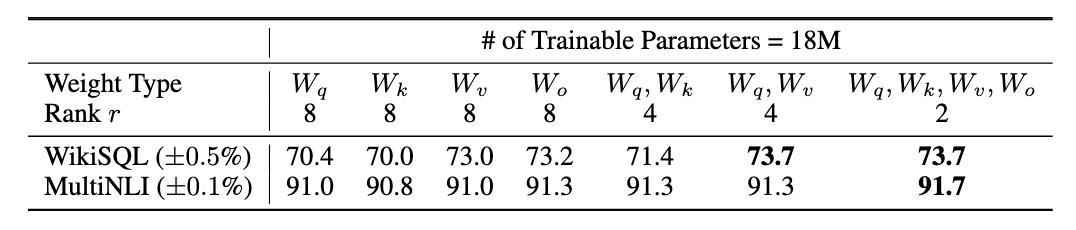
表 5:在给定相同数量的可训练参数的情况下,在 GPT-3 中对不同类型的注意力权重应用 LoRA 后,WikiSQL 和 MultiNLI 上的验证准确率。同时调整 W q W_q Wq 和 W v W_v Wv 总体上能获得最佳性能。论文发现对于给定数据集,跨随机种子的标准差是一致的,论文将其报告在第一列中。
值得注意的是,将所有参数投入 Δ W q \Delta W_q ΔWq 或 Δ W k \Delta W_k ΔWk 会导致性能显著降低,而同时调整 W q W_q Wq 和 W v W_v Wv 会产生最佳结果。这表明,即使秩为 4 也能在 Δ W \Delta W ΔW 中捕获足够的信息,因此调整更多的权重矩阵优于以更大的秩调整单一类型的权重。
7.2 LoRA 的最优秩 r r r 是多少?(What Is the Optimal Rank r for LoRA?)
论文将注意力转向秩 r r r 对模型性能的影响。论文调整 { W q , W v } \{W_q, W_v\} {Wq,Wv}、 { W q , W k , W v , W c } \{W_q, W_k, W_v, W_c\} {Wq,Wk,Wv,Wc} 以及仅 W q W_q Wq 进行比较。
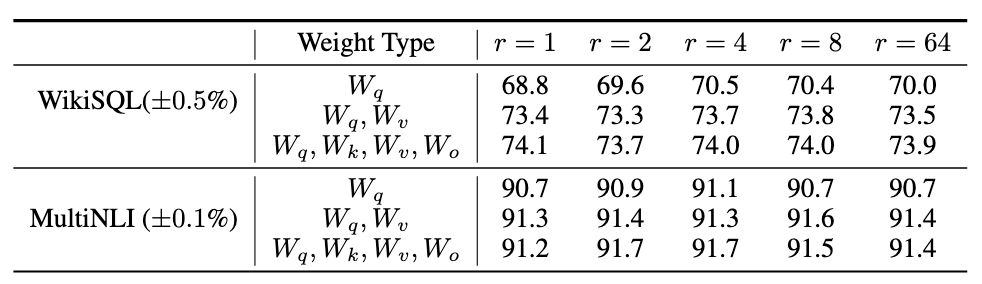
表 6:使用不同秩 r r r 时 WikiSQL 和 MultiNLI 上的验证准确率。令论文惊讶的是,在这些数据集上,小到 1 的秩就足以调整 W q W_q Wq 和 W v W_v Wv,而单独训练 W q W_q Wq 则需要更大的 r r r。论文在 H.2 节中在 GPT-2 上进行了类似的实验。
表 6 显示,令人惊讶的是,LoRA 在 r r r 非常小的情况下就已经表现出竞争力(对于 { W q , W v } \{W_q, W_v\} {Wq,Wv} 比仅对于 W q W_q Wq 更是如此)。这表明更新矩阵 Δ W \Delta W ΔW 可能具有非常小的"本征秩"。为了进一步支持这一发现,论文检查了由不同 r r r 选择和不同随机种子学习到的子空间的重叠情况。论文认为,增加 r r r 并未覆盖更有意义的子空间,这表明低秩适应矩阵是足够的
不同 r r r 之间的子空间相似度。给定 A r = 8 A_{r=8} Ar=8 和 A r = 64 A_{r=64} Ar=64,即使用相同的预训练模型学习到的秩 r = 8 r = 8 r=8 和 64 64 64 的适应矩阵,论文进行奇异值分解并获得右奇异酉矩阵(right-singular unitary matrices) U A r = 8 U_{A_{r=8}} UAr=8 和 U A r = 64 U_{A_{r=64}} UAr=64。论文希望回答:由 U A r = 8 U_{A_{r=8}} UAr=8 中前 i i i 个奇异向量(其中 1 ≤ i ≤ 8 1 \le i \le 8 1≤i≤8)张成的子空间,有多少包含在由 U A r = 64 U_{A_{r=64}} UAr=64 中前 j j j 个奇异向量(其中 1 ≤ j ≤ 64 1 \le j \le 64 1≤j≤64)张成的子空间中?论文使用基于格拉斯曼距离的归一化子空间相似度来度量这一量(关于更形式化的讨论见附录 G)
ϕ ( A r = 8 , A r = 64 , i , j ) = ∥ U A r = 8 i ⊤ U A r = 64 j ∥ F 2 min ( i , j ) ∈ 0 , 1 ( 4 ) \phi(A_{r=8}, A_{r=64}, i, j) = \frac{\|U_{A_{r=8}}^{i \top} U_{A_{r=64}}^{j}\|_F^2}{\min(i, j)} \in 0, 1 \quad (4) ϕ(Ar=8,Ar=64,i,j)=min(i,j)∥UAr=8i⊤UAr=64j∥F2∈0,1(4)
其中 U A r = 8 i U_{A_{r=8}}^i UAr=8i 表示 U A r = 8 U_{A_{r=8}} UAr=8 中对应于前 i i i 个奇异向量的列。 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 的取值范围为 0 , 1 0, 1 0,1,其中 1 表示子空间完全重叠,0 表示完全分离。关于 ϕ \phi ϕ 随 i i i 和 j j j 变化的情况,请参见图 3。由于篇幅限制,论文仅考察第 48 层(共 96 层),但正如 H.1 节所示,该结论对其他层同样成立。
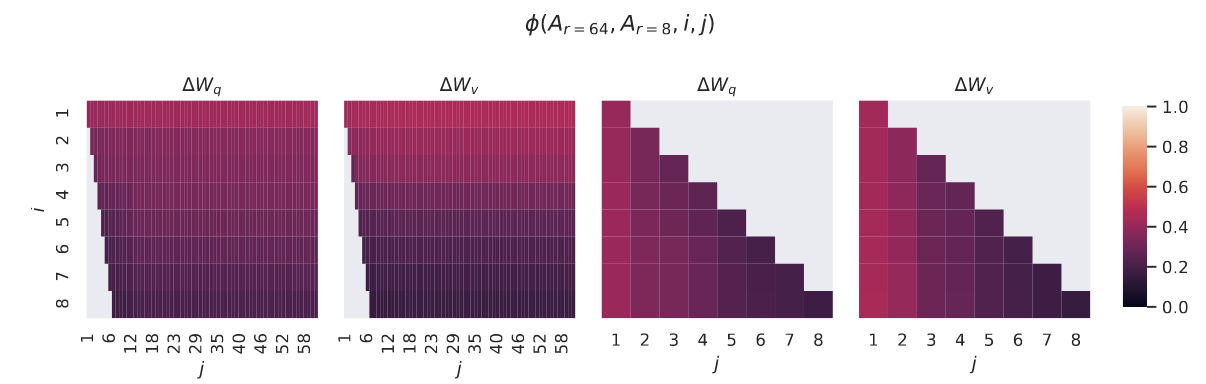
图 3:针对 Δ W q \Delta W_q ΔWq 和 Δ W v \Delta W_v ΔWv, A r = 8 A_{r=8} Ar=8 和 A r = 64 A_{r=64} Ar=64 列向量之间的子空间相似度。第三和第四幅图放大了前两幅图中的左下三角区域。 r = 8 r=8 r=8 中的主要方向包含在 r = 64 r=64 r=64 中,反之亦然。
论文从图 3 中得出了一个重要观察结果。对应于最大奇异向量的方向在 A r = 8 A_{r=8} Ar=8 和 A r = 64 A_{r=64} Ar=64 之间显著重叠,而其他方向则不然。具体而言, A r = 8 A_{r=8} Ar=8 的 Δ W v \Delta W_v ΔWv(分别为 Δ W q \Delta W_q ΔWq)与 A r = 64 A_{r=64} Ar=64 的 Δ W v \Delta W_v ΔWv(分别为 Δ W q \Delta W_q ΔWq)共享一个维数为 1 且归一化相似度 > 0.5 > 0.5 >0.5 的子空间,这解释了为什么 r = 1 r = 1 r=1 在 GPT-3 的下游任务中表现相当出色。
由于 A r = 8 A_{r=8} Ar=8 和 A r = 64 A_{r=64} Ar=64 都是使用相同的预训练模型学习得到的,图 3 表明 A r = 8 A_{r=8} Ar=8 和 A r = 64 A_{r=64} Ar=64 的最大奇异向量方向是最有用的,而其他方向可能主要包含训练过程中积累的随机噪声。因此,适应矩阵确实可以具有非常低的秩。
不同随机种子之间的子空间相似度。论文通过绘制两次使用不同随机种子的 r = 64 r = 64 r=64 运行之间的归一化子空间相似度来进一步证实这一点,如图 4 所示。 Δ W q \Delta W_q ΔWq 似乎比 Δ W v \Delta W_v ΔWv 具有更高的"本征秩",因为两次运行都为 Δ W q \Delta W_q ΔWq 学习到了更多的共同奇异值方向,这与论文在表 6 中的实证观察一致。作为比较,论文还绘制了两个随机高斯矩阵,它们彼此之间不共享任何共同的奇异值方向。
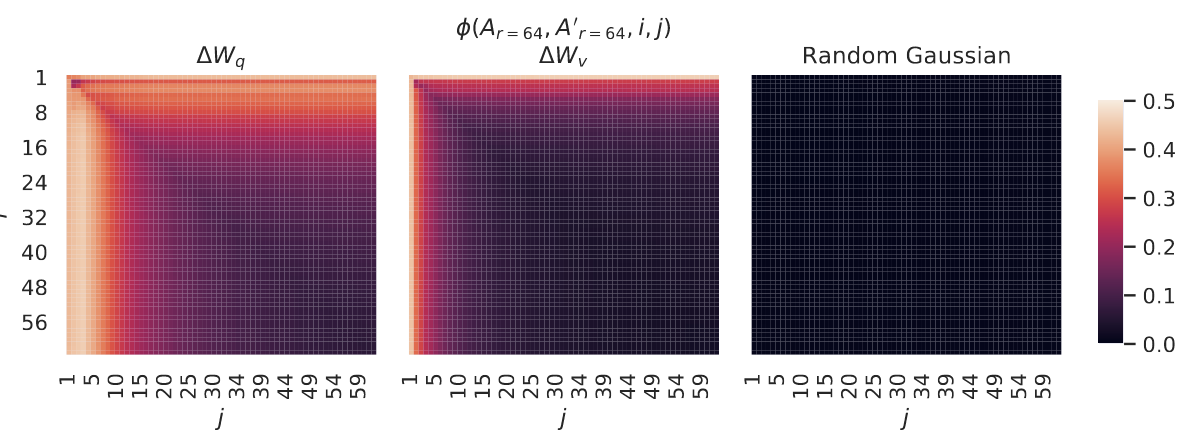
图 4:左图和中图:针对第 48 层的 Δ W q \Delta W_q ΔWq 和 Δ W v \Delta W_v ΔWv,来自两个随机种子的 A r = 64 A_{r=64} Ar=64 列向量之间的归一化子空间相似度。右图:两个随机高斯矩阵的列向量之间的相同热图。关于其他层见 H.1 节。
7.3 适应矩阵 Δ W \Delta W ΔW 与 W W W 相比如何?(How Does the Adaptation Matrix ∆W Compare to W ?)
论文进一步研究 Δ W \Delta W ΔW 和 W W W 之间的关系。特别是, Δ W \Delta W ΔW 与 W W W 高度相关吗?(或者在数学上, Δ W \Delta W ΔW 是否主要包含在 W W W 的顶层奇异方向中?)此外,与 W W W 中对应的方向相比, Δ W \Delta W ΔW 有多"大"?这可以揭示适应预训练语言模型的潜在机制。
为了回答这些问题,论文通过计算 U ⊤ W V ⊤ U^\top W V^\top U⊤WV⊤ 将 W W W 投影到 Δ W \Delta W ΔW 的 r r r 维子空间上,其中 U U U/ V V V 是 Δ W \Delta W ΔW 的左/右奇异向量矩阵。然后,论文比较 ∥ U ⊤ W V ⊤ ∥ F \|U^\top W V^\top\|_F ∥U⊤WV⊤∥F 和 ∥ W ∥ F \|W\|_F ∥W∥F 的 Frobenius 范数。作为对比,论文还通过将 U U U、 V V V 替换为 W W W 的前 r r r 个奇异向量或随机矩阵来计算 ∥ U ⊤ W V ⊤ ∥ F \|U^\top W V^\top\|_F ∥U⊤WV⊤∥F。

表 7: U ⊤ W q V ⊤ U^\top W_q V^\top U⊤WqV⊤ 的 Frobenius 范数,其中 U U U 和 V V V 是 (1) Δ W q \Delta W_q ΔWq、(2) W q W_q Wq 或 (3) 随机矩阵的左/右前 r r r 个奇异向量方向。权重矩阵取自 GPT-3 的第 48 层。
论文从表 7 中得出几个结论。首先,与随机矩阵相比, Δ W \Delta W ΔW 与 W W W 具有更强的相关性,这表明 Δ W \Delta W ΔW 放大了一些 W W W 中已经存在的特征。其次, Δ W \Delta W ΔW 并没有重复 W W W 的顶层奇异方向,而是仅放大 W W W 中未被强调的方向。第三,放大倍数相当大:对于 r = 4 r=4 r=4,为 21.5 ≈ 6.91 / 0.32 21.5 \approx 6.91/0.32 21.5≈6.91/0.32。关于为何 r = 64 r=64 r=64 具有较小的放大倍数,请参见 H.4 节。论文还在 H.3 节中提供了一个可视化,展示了当包含更多来自 W q W_q Wq 的顶层奇异方向时,相关性是如何变化的。这表明低秩适应矩阵可能放大了对特定下游任务重要、但在通用预训练模型中已学到却未被强调的特征。
8、结论和未来工作(Conclusion and Future Work)🚀
微调巨大的语言模型在所需硬件以及为不同任务托管独立实例的存储/切换成本方面极其昂贵。论文提出了LoRA,这是一种高效的适配策略,它既不引入推理延迟也不减少输入序列长度,同时保持高模型质量。重要的是,通过共享绝大多数模型参数,它允许在作为服务部署时进行快速任务切换。虽然论文专注于Transformer语言模型,但提出的原则普遍适用于任何具有稠密层的神经网络。
未来的工作有许多方向。1) LoRA可以与其他高效适配方法结合,有望提供正交的改进。2) 微调或LoRA背后的机制尚不清楚------预训练期间学到的特征是如何转化以便在下游任务上表现良好的?论文认为,相比全量微调,LoRA使回答这个问题变得更加易于处理。3) 论文主要依赖启发式方法来选择应用LoRA的权重矩阵。是否存在更具原则性的方法来做到这一点?4) 最后, Δ W \Delta W ΔW的秩亏表明 W W W可能也是秩亏的,这也可以作为未来工作的灵感来源。