文章目录
- 一、深度神经网络的不同层
-
- [1.1 全连接层](#1.1 全连接层)
- [1.2 卷积层、池化层](#1.2 卷积层、池化层)
- [二、 CNN-based系列深度神经网络](#二、 CNN-based系列深度神经网络)
-
- [2.1 LeNet](#2.1 LeNet)
- [2.2 AlexNet](#2.2 AlexNet)
- [2.3 VGG](#2.3 VGG)
- [2.4 ResNet](#2.4 ResNet)
- [2.5 GoogLeNet](#2.5 GoogLeNet)
- 三、RNN-based系列深度神经网络
-
- [3.1 RNN](#3.1 RNN)
- [3.2 LSTM](#3.2 LSTM)
- [3.3 GRU](#3.3 GRU)
本文学习要点:
1.深度神经网络分层架构:
全连接层
卷积层
池化层
2.深度神经网络代表:
CNN:CNN、AlexNet、VGG-Net、GoogLeNet(Inception)、ResNet(残差连接)
RNN:RNN、LSTM、GRU
编码器-解码器架构:序列到序列模型(Seq2Seq)
一、深度神经网络的不同层
1.1 全连接层
全连接神经网络:MLP神经网络就是一种全连接神经网络,最基础的用途是数值预测,即解决输入为连续的数值,输出也为连续的数值的任务。
关于全连接神经网络,可查看这位大佬的博客:https://www.bbbdata.com/text/501
1.2 卷积层、池化层
在卷积神经网络之前,比较火的是BP神经网络,因为BP神经网络只要隐神经元足够多,就能拟合任意曲线。但是,BP神经网络在应用于图象识别时,却难以进行,效果也并不太好,因为图象识别的输入比较多,就导致隐神经元也必须足够多,这样模型中的参数比较多,参数过多,训练就非常困难,而且模型的拟合能力也过强,导致模型预测效果往往不佳。
以图像处理为例,可以注意到,图像的每个像素并非是孤立的,它与周边的像素紧密相连,传统的全连接神经网络显然没有利用这一信息,于是卷积神经网络CNN诞生了。
CNN引入了卷积层与池化层,先对输入进行信息融合与降维,在将输入个数压缩得更少后,再使用传统的全连接神经网络进行拟合。
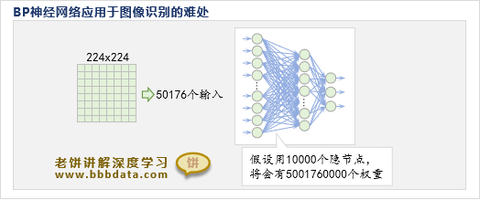
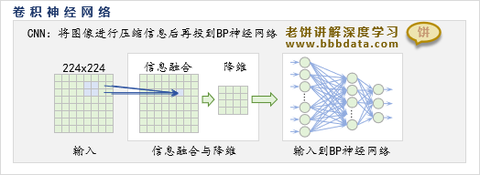
CNN的核心: 卷积操作(接收野)、池化操作(信息压缩)。
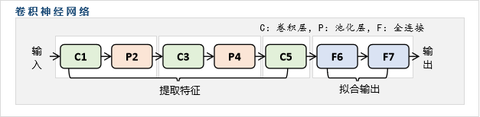
经过这样的处理后,在FeatureMap变得较小时,再会用传统的全连接神经网络来拟合输出;由于此时FeatureMap较小,所以传统神经网络的求解压力将减小,将不再存在太大的难题;值得注意的是,池化层是没有参数的,而卷积层的参数个数只受卷积核大小的影响,由于它们不直接受输入图片大小的影响,所以利用卷积层与池化层将图片Size进行压缩的代价相对是较小的。
关于CNN的详细解读可参考:https://www.bbbdata.com/text/652
二、 CNN-based系列深度神经网络
基础CNN模型并非某个人独立提出的模型结构,而是随着各种CNN模型(LeNet,AlexNet,VGG,...ResNet)的提出,逐渐在领域内形成一种公认的Base结构,从而就有了"基础CNN模型结构"。基础CNN模型结构最早成型于LeNet,然后在AlexNet中成熟,并在其它模型中丰富与完善。
总的来说,不管是"卷积神经网络"还是"基础卷积神经网络",都不是指某个公认的、唯一的模型,而是符合"使用了卷积运算"的都叫卷积神经网络,同理,"只使用了卷积神经网络的基础技术"的都叫"基础卷积神经网络"。
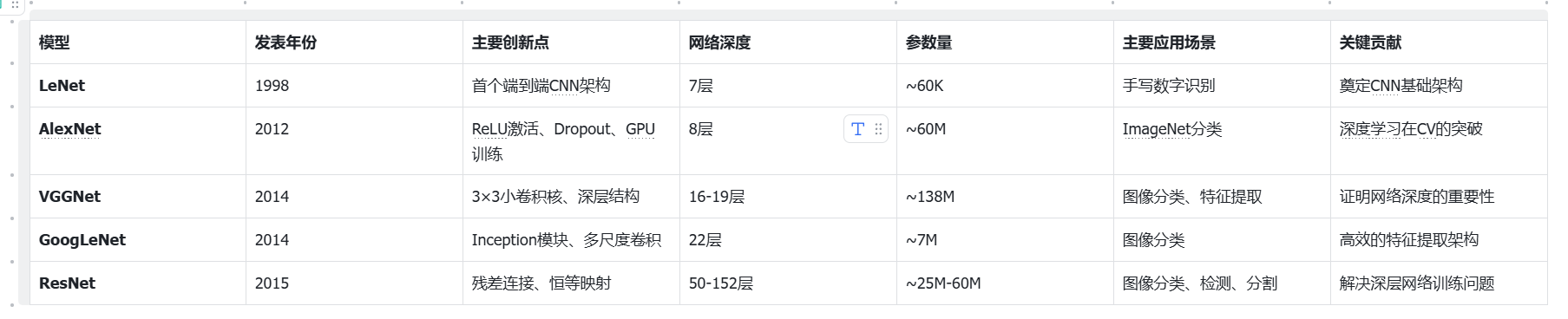
2.1 LeNet
LeNet是第一个成功应用于数字识别的卷积神经网络,其创新点在于首次将卷积层、池化层和全连接层组合成一个端到端的深度学习架构,通过局部感受野 、权值共享 和空间降采样等机制,有效提取图像特征并减少参数数量,为后续CNN发展奠定了基础。
论文:《Gradient - Based Learning Applied to Document Recognition》
-
奠定卷积神经网络基础:
LeNet首次证明了卷积神经网络在计算机视觉任务中的有效性,其"卷积-池化"的结构模式成为现代CNN的基本框架,为后续的AlexNet、VGG、ResNet等模型奠定了基础。
-
推动深度学习复兴:
在深度学习的"黑暗时代",LeNet的成功应用展示了神经网络的潜力,为2012年后深度学习的复兴埋下了伏笔。Yann LeCun也因此成为深度学习三巨头之一。
-
现代改进与发展:
虽然LeNet结构简单,但现代CNN仍延续其核心思想并进行了多方面改进:
- 使用ReLU等更高效的激活函数替代sigmoid
- 采用最大池化替代平均池化
- 增加网络深度和宽度,提升特征提取能力
- 引入批归一化、残差连接等技术
- 使用Dropout等方法防止过拟合
-
教学价值:
由于结构简单、概念清晰,LeNet至今仍是深度学习和计算机视觉入门的经典教学案例,帮助初学者理解卷积神经网络的基本原理和工作机制。
2.2 AlexNet
AlexNet在ImageNet竞赛中首次超越传统方法,其创新点包括使用ReLU激活函数替代Sigmoid解决梯度消失问题 、引入Dropout正则化防止过拟合 、采用数据增强技术 提高泛化能力、使用GPU并行训练 加速计算,以及采用局部响应归一化(LRN) 增强特征表达,标志着深度学习在计算机视觉领域的突破。
论文:《ImageNet Classification with Deep Convolutional Neural Networks》
- 数据增强操作:
使用了多种数据增强技术,包括随机裁剪、水平翻转和颜色变换,显著增加了训练数据量,减少了过拟合,提高了模型泛化能力。- 随机裁剪原始图像的224×224区域
- 水平翻转图像
- 对RGB像素值进行PCA变换
- Dropout正则化:
AlexNet引入了Dropout技术,在训练过程中随机"丢弃"一部分神经元,有效减少了过拟合。这相当于同时训练多个子网络,提高了模型的鲁棒性。- 在训练时,每个神经元以概率p被暂时"丢弃"
- 测试时,所有神经元保留,但权重乘以(1-p)
- AlexNet在FC6和FC7层使用p=0.5的Dropout
- 双GPU并行计算:
AlexNet通过将网络分布在两个GPU上并行计算,大幅加速了训练过程。这是深度学习中多GPU训练的早期实践,为后续大规模模型训练奠定了基础。- Conv1、Conv2和Conv5的卷积核在两个GPU上独立计算
- Conv3和Conv4的卷积核跨GPU连接
- 全连接层在两个GPU上复制并同步
- 其他重要技术:
- 局部响应归一化(LRN):
AlexNet在Conv1和Conv2后使用LRN,通过增强大激活值、抑制小激活值,增加了模型的泛化能力。虽然现代网络通常用Batch Normalization替代LRN,但这是早期尝试之一。 - 重叠池化(Overlapping Pooling):
AlexNet使用步长小于池化窗口大小的池化操作,如3×3窗口步长为2,这种重叠池化减少了过拟合,提高了特征提取的精确性。 - 多尺度训练:
在训练过程中,将原始图像缩放到不同尺寸(256-512像素),然后随机裁剪224×224区域,使模型学习到不同尺度的特征。
- 局部响应归一化(LRN):
2.3 VGG
VGGNet的创新点在于采用简单而有效的设计理念,使用3×3小卷积核的深层网络结构,通过堆叠多个小卷积层替代大卷积核,在保持感受野的同时大幅减少参数数量,同时证明了网络深度对性能提升的重要性,其模块化设计思想影响了后续网络架构的发展。
论文:《Very Deep Convolutional Networks for Large - Scale Image Recognition》
VGG模型组成:
- 卷积部分:由多个卷积块组成,每个卷积块包含1-3个3×3卷积层, followed by一个ReLU激活函数和一个2×2的最大池化层(除最后一个卷积块外)
- 全连接部分:包含3个全连接层,最后接一个softmax激活函数用于分类
2.4 ResNet
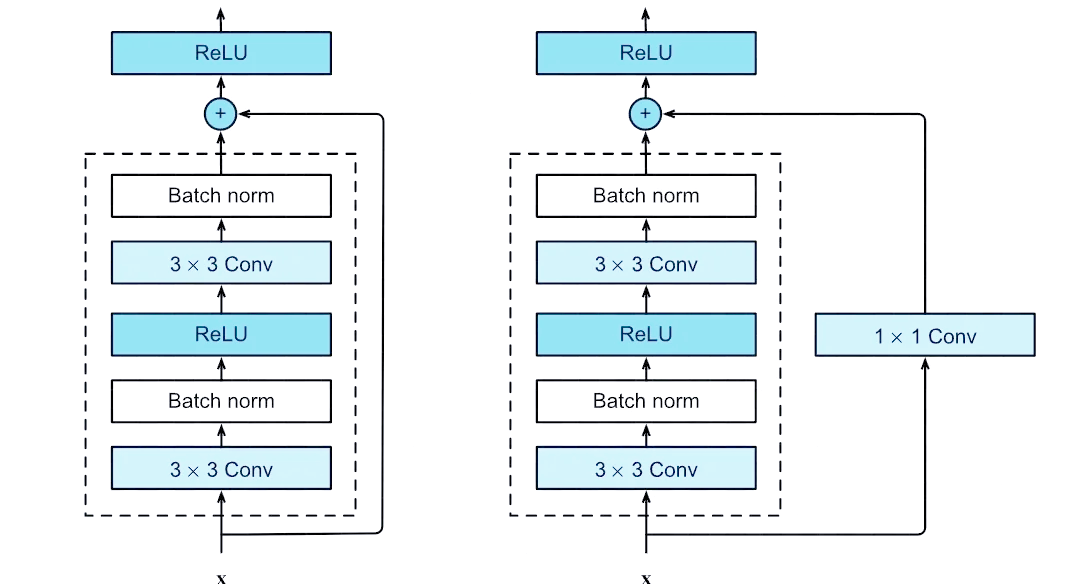
ResNet通过引入残差连接(跳跃连接)解决了深层网络的梯度消失和退化问题,其核心创新是"恒等映射"思想,让网络可以直接学习残差函数,使得训练超深层网络(如152层)成为可能,同时通过批归一化等技术进一步稳定训练过程,在多个视觉任务上取得了突破性成果。
论文:《Deep Residual Learning for Image Recognition》
2.5 GoogLeNet
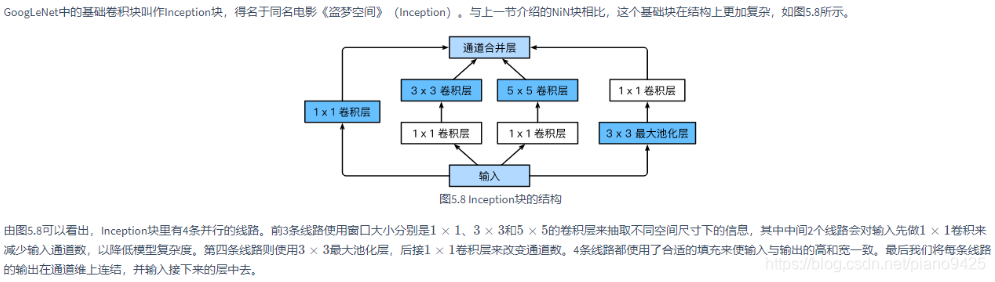
GoogLeNet的创新点在于提出Inception模块,采用多尺度并行卷积结构,同时使用1×1、3×3、5×5卷积核和最大池化层,通过1×1卷积进行降维减少计算量,这种设计既提高了特征提取的多样性,又有效控制了参数量和计算复杂度,为后续网络设计提供了新的思路。
论文:《Going Deeper with Convolutions》
三、RNN-based系列深度神经网络
3.1 RNN
RNN(Recurrent Neural Network,循环神经网络)是一类专门用于处理序列数据的神经网络模型,核心特点是通过引入"循环连接"让网络具备记忆能力,能捕捉数据中的时序依赖关系------不同于前馈神经网络(如CNN、BP网络)的单向信息传递,RNN在处理每个序列元素时,会将当前输入与上一时刻的隐藏状态结合计算,使网络能利用历史信息理解上下文。其结构中包含重复的神经元模块(隐藏层),每个模块的输出不仅传递给下一层,还会反馈到自身作为下一时刻的输入,最终通过隐藏状态输出预测结果。
RNN最初被用于解决语音识别、自然语言处理(如文本生成、机器翻译)、时间序列预测等任务,但存在梯度消失/爆炸问题,难以捕捉长距离时序依赖,后续衍生出LSTM(长短期记忆网络)、GRU(门控循环单元)等改进模型,通过门控机制优化了长序列信息的记忆与传递能力。
详细解读可参考:https://zybuluo.com/hanbingtao/note/541458
3.2 LSTM
LSTM(Long Short-Term Memory,长短期记忆网络)是 Hochreiter & Schmidhuber 于 1997 年提出的 RNN 改进模型,核心通过引入 "门控机制"(输入门、遗忘门、输出门)和 "细胞状态"(Cell State)解决传统 RNN 的梯度消失 / 爆炸问题,实现对长距离时序依赖的有效捕捉。
传统 RNN 因仅靠简单隐藏状态传递信息,在处理长序列时,梯度会随反向传播的层数增加急剧衰减或膨胀,导致无法学习到远距离的上下文关联;而 LSTM 的细胞状态如同 "信息传送带",能稳定存储长序列中的关键信息,遗忘门可选择性丢弃无用历史信息,输入门决定新信息的融入程度,输出门控制当前细胞状态的输出,数学上通过 sigmoid 和 tanh 激活函数实现门控的开关调节,既保留了 RNN 处理序列数据的能力,又突破了短记忆瓶颈。LSTM 广泛应用于长文本翻译、语音识别、时间序列预测(如股价、气象)等需要依赖长距离上下文的任务,是自然语言处理和时序建模领域的基础模型之一。
详细解读可参考:https://www.zhihu.com/question/445411028/answer/2323876011
3.3 GRU
GRU(Gated Recurrent Unit,门控循环单元)是 Cho 等人于 2014 年提出的 LSTM 简化版循环神经网络模型,它通过合并门控结构(将 LSTM 的遗忘门与输入门整合为更新门,同时用重置门替代输出门),在保持对长距离时序依赖捕捉能力的前提下,减少了参数数量、提升了计算效率。
相比 LSTM,GRU 去掉了细胞状态,仅通过隐藏状态传递信息,结构更简洁、训练速度更快,同时有效解决了传统 RNN 的梯度消失 / 爆炸问题,能捕捉长序列中的上下文关联,广泛应用于机器翻译、文本生成、语音识别等序列建模任务,是平衡性能与效率的经典门控循环模型。