锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer架构详解 - 自注意力机制(Self-Attention)原理介绍
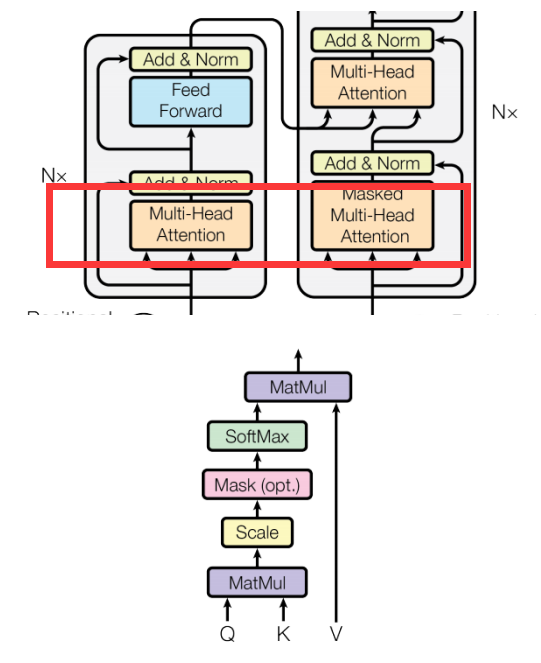
自注意力机制的目标是计算输入序列中每个词语与其他词语的关系。通过这种机制,模型能够自适应地选择与每个词语相关的信息,以构建其上下文表示。
核心组件:
-
Q(Query):查询向量,表示当前关注的点
-
K(Key):键向量,表示被查询的点
-
V(Value):值向量,包含实际的信息
-
注意力分数:Q和K的相似度
计算注意力权重
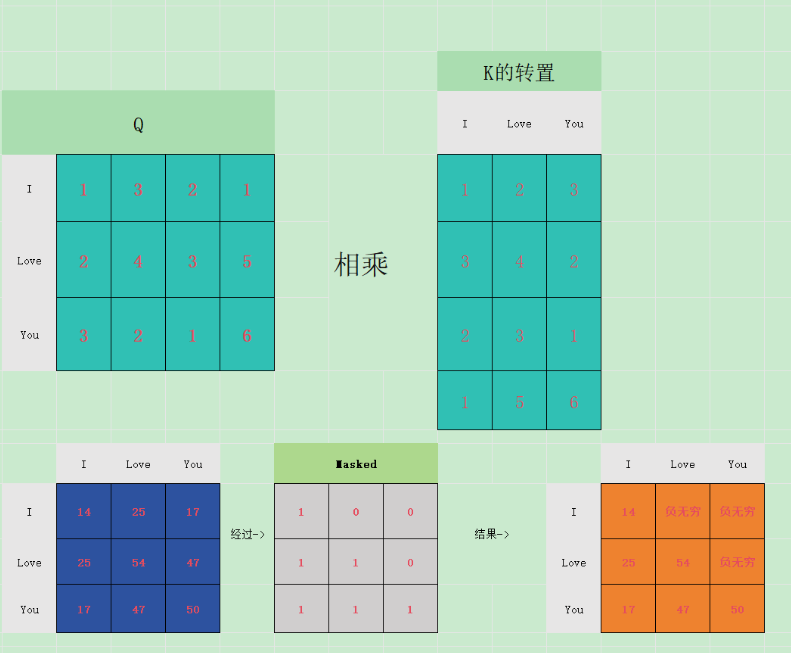
接着,通过计算 Query 和 Key 的相似度来确定每个词语对其他词语的关注程度。这个相似度通常通过计算点积来实现,并对结果进行缩放以避免数值过大。具体地,计算方式为:
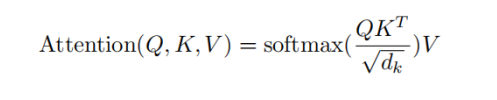
其中,dk是 Key 向量的维度。通过 softmax 操作,得到的矩阵表示了每个词语对于其他词语的注意力权重。
除以开根号dk,主要目的是防止梯度消失和q,k的统计变量满足正太分布,实现归一化。
输出
最后,将这些注意力权重与对应的 Value 向量进行加权平均,得到每个词语的上下文表示。