
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [1 ~> 概念初识:文件是什么?](#1 ~> 概念初识:文件是什么?)
-
- [1.1 概念](#1.1 概念)
- [1.2 理论](#1.2 理论)
- [1.3 理论](#1.3 理论)
- [2 ~> 文件路径](#2 ~> 文件路径)
-
- [2.1 理论](#2.1 理论)
- [2.2 最佳实践](#2.2 最佳实践)
- [3 ~> 文件操作](#3 ~> 文件操作)
-
- [3.1 打开文件](#3.1 打开文件)
-
- [3.1.1 理论](#3.1.1 理论)
- [3.1.2 当文件不存在的时候,尝试按照读方式打开会怎么样?](#3.1.2 当文件不存在的时候,尝试按照读方式打开会怎么样?)
- [3.1.3 最佳实践](#3.1.3 最佳实践)
- [3.2 关闭文件](#3.2 关闭文件)
-
- [3.2.1 理论](#3.2.1 理论)
- [3.2.2 一个程序能同时打开的文件个数,是存在上限的](#3.2.2 一个程序能同时打开的文件个数,是存在上限的)
- [3.2.3 最佳实践](#3.2.3 最佳实践)
- [3.3 写文件](#3.3 写文件)
-
- [3.3.1 理论](#3.3.1 理论)
- [3.3.2 最佳实践](#3.3.2 最佳实践)
- [3.4 读文件](#3.4 读文件)
-
- [3.4.1 理论](#3.4.1 理论)
- [3.4.2 理论](#3.4.2 理论)
- [4 ~> 关于中文的处理:gbk和UTF-8](#4 ~> 关于中文的处理:gbk和UTF-8)
-
- [4.1 理论](#4.1 理论)
- [4.2 "字符集":计算机表示中文的时候,会采取一定的编码方式](#4.2 “字符集”:计算机表示中文的时候,会采取一定的编码方式)
- [4.3 最佳实践](#4.3 最佳实践)
- [5 ~> 使用上下文管理器](#5 ~> 使用上下文管理器)
-
- [5.1 理论](#5.1 理论)
- [5.2 最佳实践](#5.2 最佳实践)
- 结尾

1 ~> 概念初识:文件是什么?
1.1 概念
变量是把数据保存到内存中,如果程序重启/主机重启,内存中的数据就会丢失。
要想能让数据被持久化存储,就可以把数据存储到硬盘中,也就是在 文件 中保存。
1.2 理论
在Windows"此电脑"中,看到的内容都是文件------
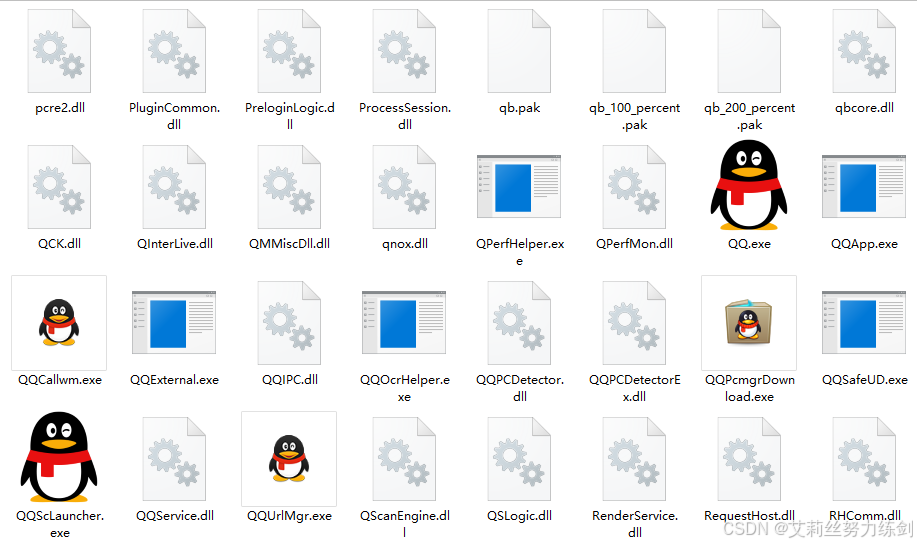
通过文件的后缀名,可以看到文件的类型,常见的文件的类型如下:
文本文件(txt)
可执行文件(exe,dll)
图片文件(jpg,gif)
视频文件(mp4,mov)
office文件(ppt,docx)
我们本文主要就是讨论 文本文件。

1.3 理论
bash
# 文件
# 文件是什么
# 数据都是保存在硬盘上的!
# 电影 mp4
# 歌曲 mp3
# 图片 jpg
# 文本 txt
# 表格 xlsx
# CPU,存储器,输入设备,输出设备
# 存储器-->
# 1.内存 变量,就是在内存中
# 2.硬盘 文件,就是在硬盘中
# 1.内存的空间更小,硬盘空间更大
# 2.内存访问更快,硬盘访问更慢
# 3.内存成本更贵,硬盘成本更便宜
# 4.内存的数据易失,硬盘的数据持久化存储(硬盘上存储的数据就是以文件的形式来组织的)
# 此电脑 => C盘,D盘~这里的内容都是硬盘上的内容,也都是文件!
# 文件夹(目录)也是一种特殊的文件,目录文件(------Linux下一切皆文件)
# 此电脑这个称呼有个有趣的小发展------
# windows xp 我的电脑
# windows7 计算机
# windows8 这台电脑
# windows10 此电脑
# windows11 此电脑(居然没延续改名的传统,有点小失望)
# 即使都是文件,文件里面存储数据的内容 / 格式,也是差异很大的
# 我们重点学习文本文件2 ~> 文件路径
2.1 理论
一个机器上,会存在很多文件,为了让这些文件更方面的被组织,往往会使用很多的"文件夹"(也叫做 目录)来整理文件。
实际一个文件往往是放在一系列的目录结构之中的。
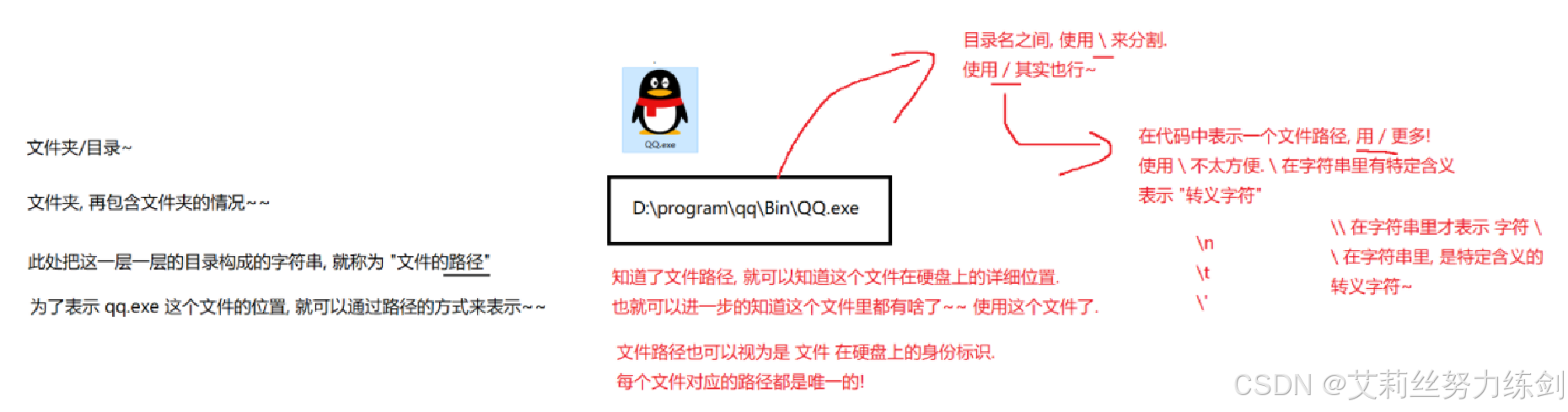
为了方便确定一个文件所在的位置,使用 文件路径 来进行描述。
例如,上述截图中的QQ.exe这个文件,描述这个文件的位置,就可以使用路径D:\program\qq\Bin\QQ.exe来表示。
D:表示 盘符. 不区分大小写。
每一个\表示一级目录.当前QQ.exe就是放在"D盘下的program目录下的qq目录下的Bin目录中"。
目录之间的分隔符,可以使用\也可以使用/一般在编写代码的时候使用/更方便。
上述以盘符开头的路径,我们也称为 绝对路径 。
除了绝对路径之外,还有一种常见的表示方式是 相对路径 ,相对路径需要先指定一个基准目录,然后以基准目录为参照点,间接的找到目标文件,本文暂时不详细介绍。
描述一个文件的位置,使用 绝对路径 和 相对路径 都是可以的,对于新手来说,使用 绝对路径 更简单更好理解,也不容易出错。
2.2 最佳实践
bash
# 文件路径
# 文件夹 / 目录
# 文件夹再包含文件夹的情况------此处把这一层一层的目录构成的字符串,就称为"文件的路径"
# 为了表示qq.exe这个文件的位置,就可以通过路径的方式,如D:program\qq\Bin\QQ.exe(文件的路径)
# 知道了文件路径,就可以知道这个文件在硬盘上的详细位置,也就可以进一步的知道这个文件里都有啥了-->使用这个文件了。
# 文件路径也可以视为是文件在硬盘上的身份标识,每个文件对应的路径都是唯一的!
# 目录名之间,使用\来分割,使用/其实也行(当时主流的是/,但是Windows产品发布前产品经理临时变卦)
# 后来大家觉得太麻烦,迫于压力,Windows又支持/了,这样一来,也就是说: Windows上面支持两种风格的斜杠
# 在代码中表示一个文件路径,用/更多!
# 使用\不太方便 --> \在字符串里有特定含义:表示"转义字符"
# 转义字符,像\n、\t、\'
# \\在字符串里才表示[字符\],\在字符串里,是特定含义的,转义字符3 ~> 文件操作
要使用文件,主要是通过文件来保存数据,并且在后续把保存的数据读取出来。但是,要想读写文件,需要先"打开文件",读写完毕之后还要"关闭文件"。
3.1 打开文件
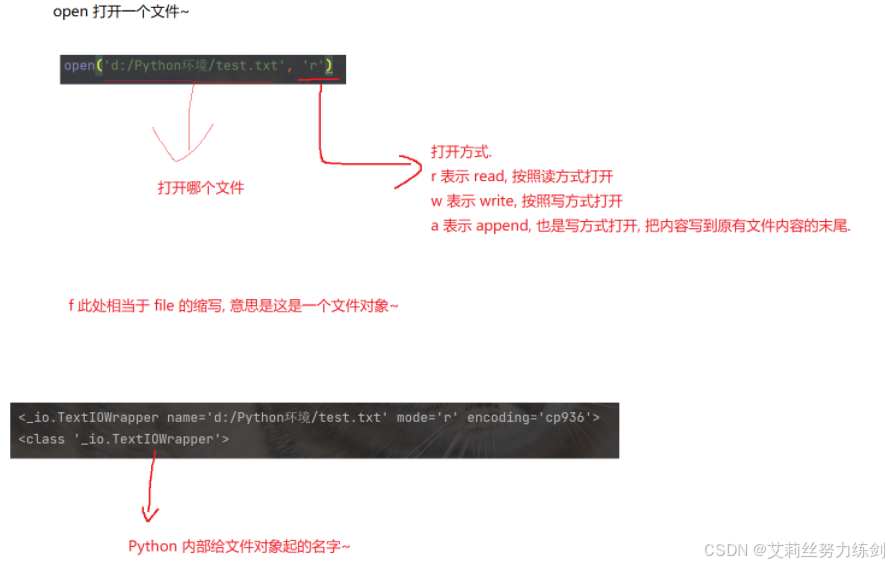

3.1.1 理论
使用内建函数open打开一个文件。
bash
f = open('d:/test.txt', 'r')第一个参数是一个字符串,表示要打开的文件路径
第二个参数是一个字符串,表示打开方式.其中表示按照读方式打开,w表示按照写方式打开.a表示追加写方式打开。
如果打开文件成功,返回一个文件对象,后续的读写文件操作都是围绕这个文件对象展开。
如果打开文件失败(比如路径指定的文件不存在),就会抛出异常。

3.1.2 当文件不存在的时候,尝试按照读方式打开会怎么样?
当文件不存在的时候,尝试按照读方式打开,就抛出了文件没找到的异常。

3.1.3 最佳实践
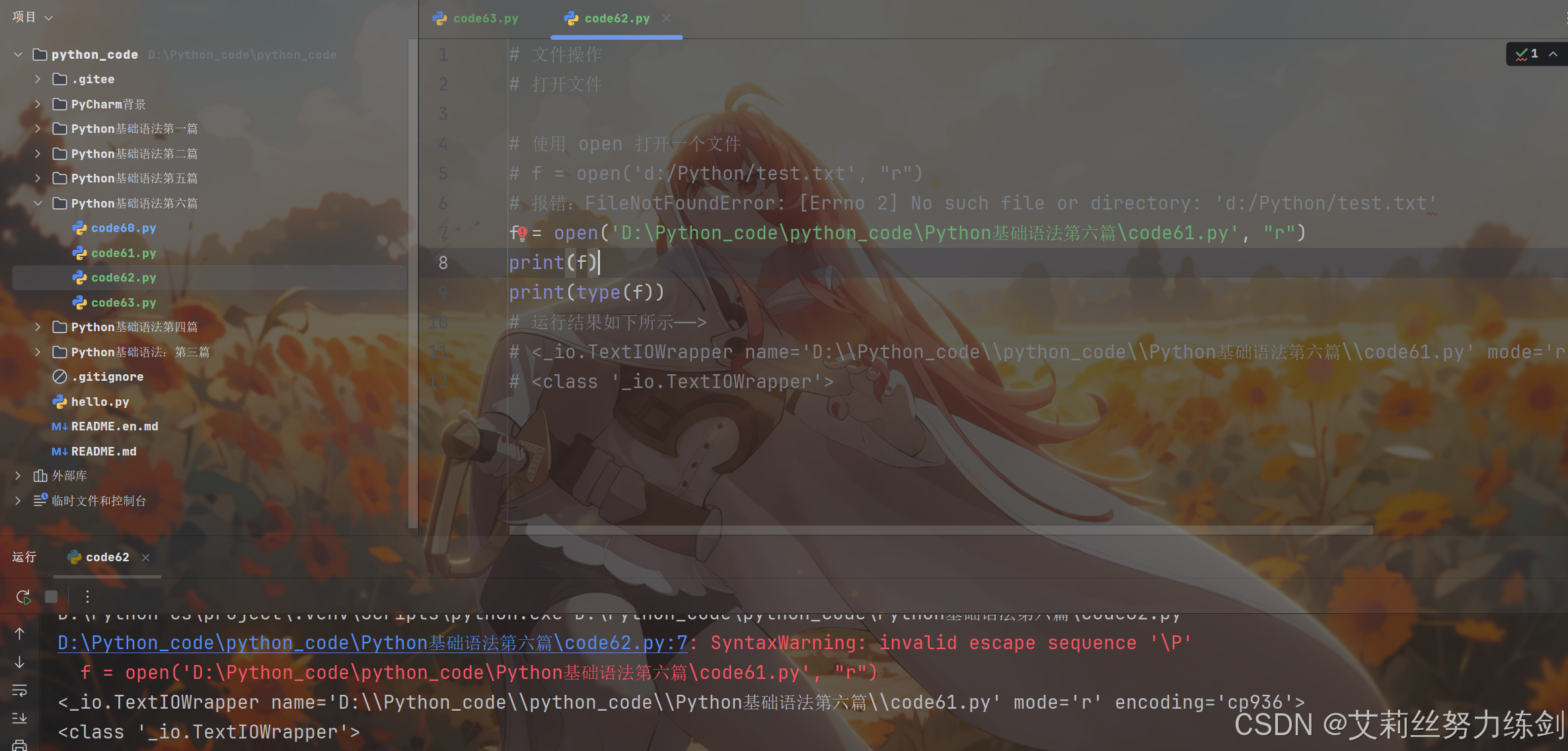
bash
# 文件操作
# 打开文件
# 使用 open 打开一个文件
# f = open('d:/Python/test.txt', "r")
# 报错:FileNotFoundError: [Errno 2] No such file or directory: 'd:/Python/test.txt'
f = open('D:\Python_code\python_code\Python基础语法第六篇\code61.py', "r")
print(f)
print(type(f))
# 运行结果如下所示------>
# <_io.TextIOWrapper name='D:\\Python_code\\python_code\\Python基础语法第六篇\\code61.py' mode='r' encoding='cp936'>
# <class '_io.TextIOWrapper'>
# 文件打开了是一定要关闭的
f.close()3.2 关闭文件

3.2.1 理论
使用close方法关闭已经打开的文件。
bash
f.close()使用完毕的文件要记得及时关闭!
3.2.2 一个程序能同时打开的文件个数,是存在上限的

bash
flist = []
count = 0
while True:
f = open('d:/test.txt', 'r')
flist.append(f)
count += 1
print(f'count = {count}')
如上面代码所示,如果一直循环的打开文件,而不去关闭的话,就会出现上述报错。
当一个程序打开的文件个数超过上限,就会抛出异常。
注意:上述代码中,使用一个列表来保存了所有的文件对象,如果不进行保存,那么Python内置的垃圾回收机制,会在文件对象销毁的时候自动关闭文件。但是由于垃圾回收操作不一定及时,所以我们写代码仍然要考虑手动关闭,尽量避免依赖自动关闭。

3.2.3 最佳实践
bash
# 关闭文件
# 打开文件个数的上限
flist = []
count = 0
while True:
f = open('D:\Python_code\python_code\Python基础语法第六篇\code61.py', 'r')
flist.append(f) # Python留的一个后手
count += 1
print(f'打开文件的个数: {count}')
# 光是打开没有关闭,报错:OSError: [Errno 24] Too many open files: ......
f.close(f)
# 在系统中,是可以通过一些设置项,来配置能打开文件的最大数目的
# 但是无论配置多少,都不是无穷无尽的~~就需要记得要及时关闭,释放资源3.3 写文件

3.3.1 理论
文件打开之后,就可以写文件了。
写文件,要使用写方式打开,open第二个参数设为'w'。
使用write方法写入文件。
bash
f = open('d:/test.txt', 'w')
f.write('hello')
f.close()
用记事本打开文件,即可看到文件修改后的内容。
如果是使用'r'方式打开文件,则写入时会抛出异常。
bash
f = open('d:/test.txt', 'r')
f.write('hello')
f.close()
使用'w'一旦打开文件成功,就会清空文件原有的数据。
使用'a'实现"追加写",此时原有内容不变,写入的内容会存在于之前文件内容的末尾。
bash
f = open('d:/test.txt', 'w')
f.write('hello')
f.close()
f = open('d:/test.txt', 'a')
f.write('world')
f.close()
针对已经关闭的文件对象进行写操作,也会抛出异常。
bash
f = open('d:/test.txt', 'w')
f.write('hello')
f.close()
f.write('world')
3.3.2 最佳实践
bash
# 写文件(write)
# 使用 write 来实现写文件的操作
# f = open('D:\Python_code\python_code\Python基础语法第六篇', 'w')
# f.write('hello')
# f.close()
# 写文件的时候,需要使用 w 的方式打开,如果使用 r 的方式打开,则会抛出异常
# f = open('D:\Python_code\python_code\Python基础语法第六篇', 'r')
# f.write('world')
# f.close()
# 报错:io.UnsupportedOperation(不支持的操作): not writable(不可写)
# 写方式打开,其实又有两种情况,直接写方式打开,追加方式打开
# f = open('D:\Python_code\python_code\Python基础语法第六篇', 'w')
# f.close()
# # (直接打开关闭)如果使用写方式打开,会清空文件原有的内容!
# f = open('D:\Python_code\python_code\Python基础语法第六篇\code65.txt', 'w')
# f.write('11111\n')
# f.close()
#
# f = open('D:\Python_code\python_code\Python基础语法第六篇\code65.txt', 'a')
# f.write('22222\n')
# f.close()
# 如果文件对象已经被关闭,那么意味着系统中和文件相关的内存资源已经被释放了,强行去写就会出异常
f = open('D:\Python_code\python_code\Python基础语法第六篇/test.txt', 'w')
f.close()
f.write('22222\n')
# 报错:ValueError: I/O operation on closed file.3.4 读文件
3.4.1 理论
读文件内容需要使用'r'的方式打开文件。
使用read方法完成读操作,参数表示"读取几个字符"。
bash
f = open('d:/test.txt', 'r')
result = f.read(2)
print(result)
f.close()
如果文件是多行文本,可以使用for循环一次读取一行。

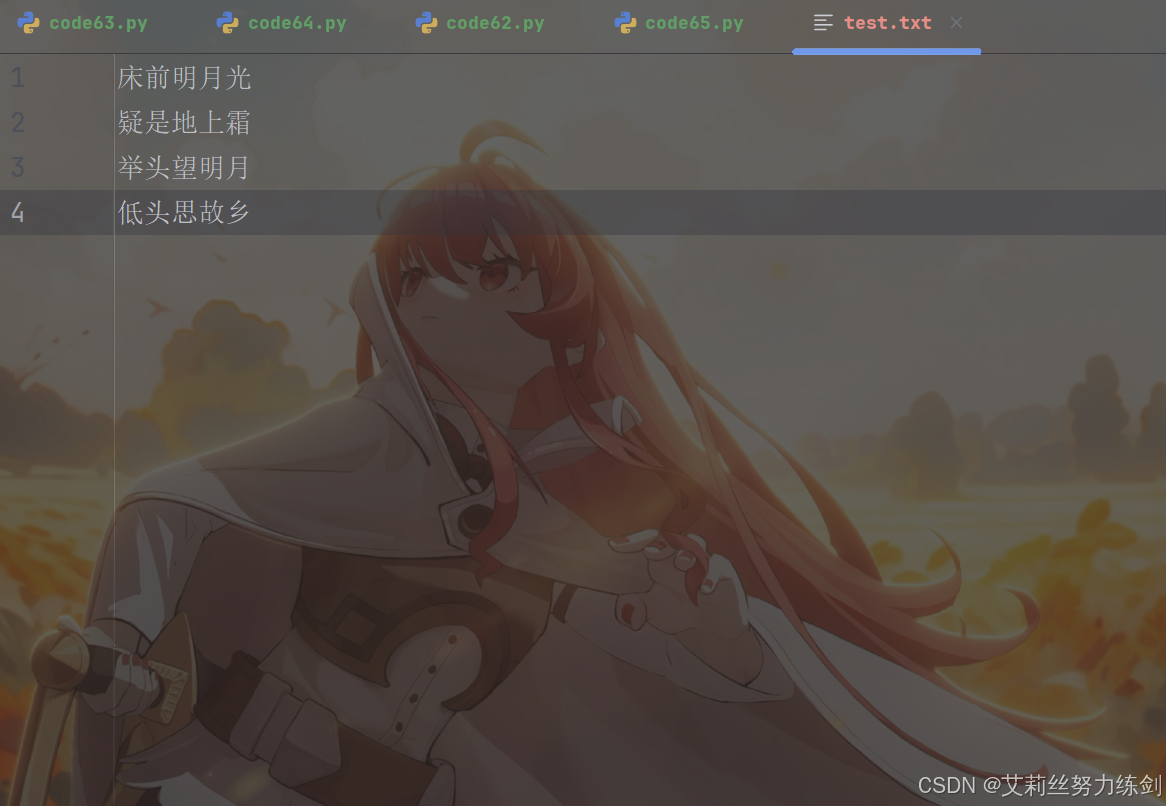
先构造一个多行文件。
bash
f = open('d:/test.txt', 'r')
for line in f:
print(f'line = {line}')
f.close()
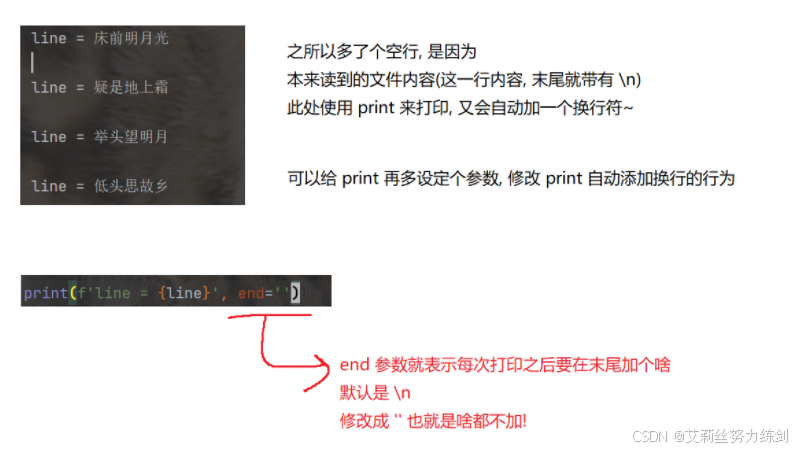
注意: 由于文件里每一行末尾都自带换行符,print打印一行的时候又会默认加上一个换行符,因此打印结果看起来之间存在空行。
使用print(f'line = {line}' , end=' ')手动把print自带的换行符去掉。
使用readlines直接把文件整个内容读取出来,返回一个列表。每个元素即为一行。
bash
f = open('d:/test.txt', 'r')
lines = f.readlines()
print(lines)
f.close()
3.4.2 理论
bash
# 读文件
# 1、使用 read 来读取文件内容,指定读几个字符。
f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt', 'r')
result = f.read(2)
print(result)
f.close()
# 报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 14: illegal multibyte sequence
# 中文和英文类似,在计算机中,都是使用"数字"来表示字符的
# 哪个数字,对应哪个汉字?其实在计算机中,可以有多个版本
# 最主流的版本:(1)GBK;(2)UTF8。
# 这里是UTF-8的格式:此处我们使用的办法,是让代码按照UTF-8来进行处理
# 相比于gbk,UTF-8是使用更广泛的编码方式(最最主流的写法)
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# result = f.read(2)
# print(result)
# f.close()
# 2、更常见的需求,是按行来读取
# 最简单的办法,直接 for 循环
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# for line in f:
# print(f'line = {line}')
# f.close()
# 读出来的结果多了个空行
# line = 床前明月光
#
# line = 疑是地上霜
#
# line = 举头望明月
#
# line = 低头思故乡
# 之所以多了个空行,是因为本来读到的文件内容(这一行内容,末尾就带有\n)
# 此处使用print来打印,又会自动加一个换行符
# 解决方案:可以给print再多设定个参数,修改print自动添加换行的行为
# 实操
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# for line in f:
# print(f'line = {line}',end='')
# f.close()
# # end参数就表示每次打印之后要在末尾加个啥(默认是\n),修改成空字符串''就是啥都不加
# 3、还可以使用 readlines 方法直接把整个文件的所有内容都读出来,按照行组织到一个列表里
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# lines = f.readlines()
# print(lines)
# f.close()
# 每一行的末尾都有\n:['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡']
# 和前面的 for 循环相比,好处就是它一次就读完了(硬盘操作,读的次数越多,耗时越长,分多次读不如一次读完)
# 内存很大的东西一次读完,前提是内存足够大4 ~> 关于中文的处理:gbk和UTF-8
4.1 理论
当文件内容存在中文的时候,读取文件内容不一定就顺利。同样是上述代码,有的uu在执行时可能会出现异常。

完整的如下------
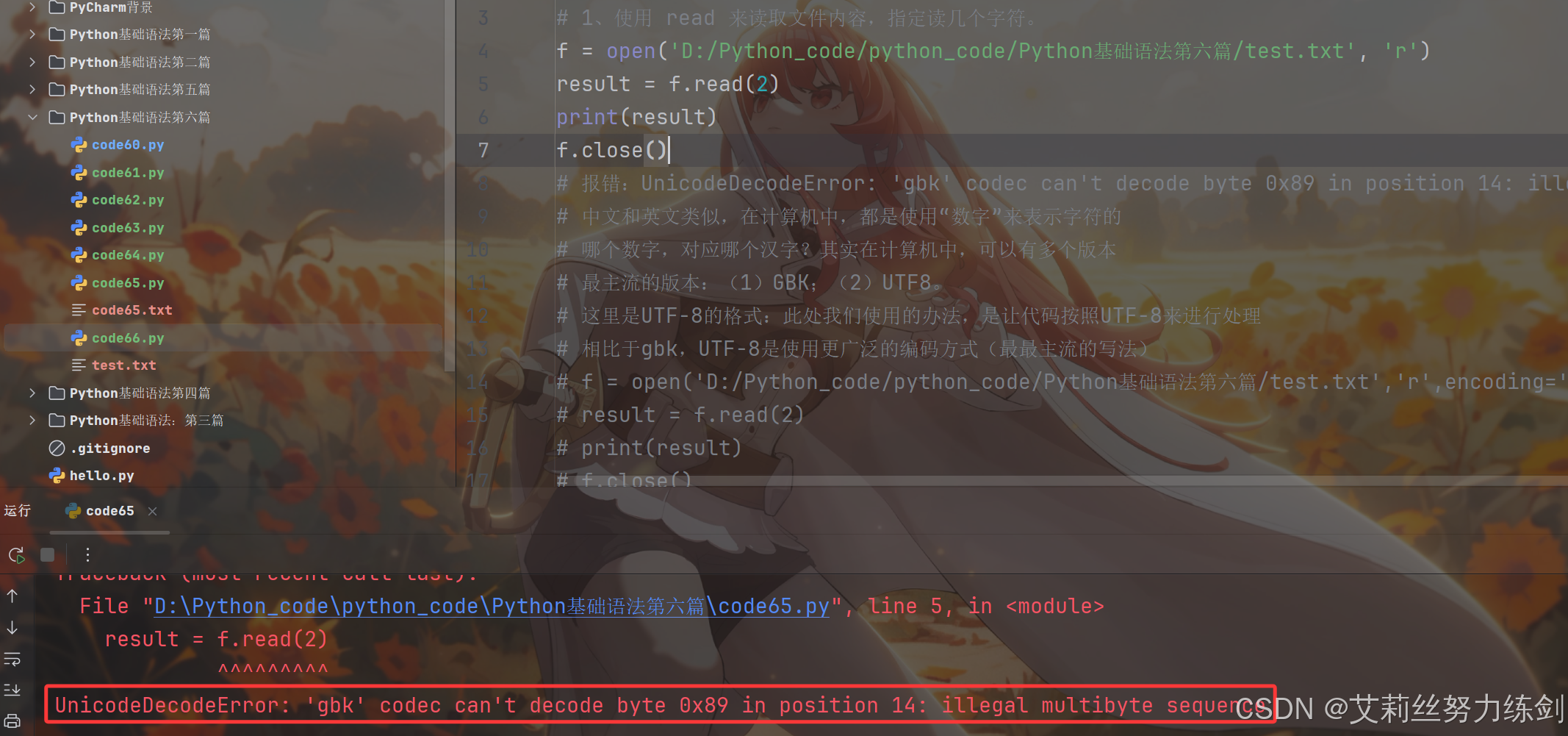
有的uu可能会出现乱码------

4.2 "字符集":计算机表示中文的时候,会采取一定的编码方式
所谓"编码方式",本质上就是使用数字表示汉字。
我们知道,计算机只能表示二进制数据,要想表示英文字母,或者汉字,或者其他文字符号,就都要通过编码。
最简单的字符编码就是ascii.使用一个简单的整数就可以表示英文字母和阿拉伯数字。
但是要想表示汉字,就需要一个更大的码表。
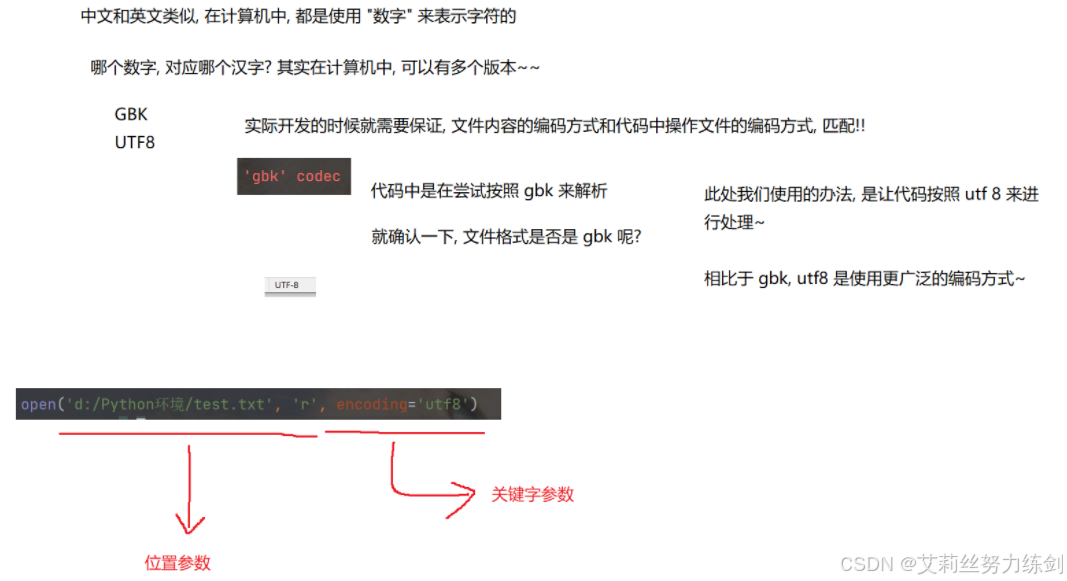
一般常用的汉字编码方式,主要是
GBK和UTF-8。
必须要保证文件本身的编码方式,和Python代码中读取文件使用的编码方式匹配,才能避免出现上述问题。
Python3中默认打开文件的字符集跟随系统,而Windows简体中文版的字符集采用了
GBK,所以如果文件本身是GBK的编码,直接就能正确处理。如果文件本身是其他编码(比如
UTF-8),那么直接打开就可能出现上述问题。
使用记事本打开文本文件,在"菜单栏" ~> "文件" ~> "另存为" 窗口中,可以看到当前文件的编码方式。

如果此处的编码为ANSI,则表示GBK编码。
如果此处为UTF-8,则表示UTF-8编码。
此时修改打开文件的代码,给open方法加上encoding参数,显式的指定为和文本相同的字符集,问题即可解决。
bash
f = open('d:/test.txt', 'r', encoding='utf8')PS:字符编码问题,是编程中一类比较常见,又比较棘手的问题,需要对于字符编码有一定的理解,才能从容应对。
我们可以看一下这篇文章:程序员必备:彻底弄懂常见的7种中文字符编码
4.3 最佳实践
bash
# 读文件
# 1、使用 read 来读取文件内容,指定读几个字符。
f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt', 'r')
result = f.read(2)
print(result)
f.close()
# 报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0x89 in position 14: illegal multibyte sequence
# 中文和英文类似,在计算机中,都是使用"数字"来表示字符的
# 哪个数字,对应哪个汉字?其实在计算机中,可以有多个版本
# 最主流的版本:(1)GBK;(2)UTF8。
# 这里是UTF-8的格式:此处我们使用的办法,是让代码按照UTF-8来进行处理
# 相比于gbk,UTF-8是使用更广泛的编码方式(最最主流的写法)
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# result = f.read(2)
# print(result)
# f.close()
# 2、更常见的需求,是按行来读取
# 最简单的办法,直接 for 循环
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# for line in f:
# print(f'line = {line}')
# f.close()
# 读出来的结果多了个空行
# line = 床前明月光
#
# line = 疑是地上霜
#
# line = 举头望明月
#
# line = 低头思故乡
# 之所以多了个空行,是因为本来读到的文件内容(这一行内容,末尾就带有\n)
# 此处使用print来打印,又会自动加一个换行符
# 解决方案:可以给print再多设定个参数,修改print自动添加换行的行为
# 实操
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# for line in f:
# print(f'line = {line}',end='')
# f.close()
# # end参数就表示每次打印之后要在末尾加个啥(默认是\n),修改成空字符串''就是啥都不加
# 3、还可以使用 readlines 方法直接把整个文件的所有内容都读出来,按照行组织到一个列表里
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# lines = f.readlines()
# print(lines)
# f.close()
# 每一行的末尾都有\n:['床前明月光\n', '疑是地上霜\n', '举头望明月\n', '低头思故乡']
# 和前面的 for 循环相比,好处就是它一次就读完了(硬盘操作,读的次数越多,耗时越长,分多次读不如一次读完)
# 内存很大的东西一次读完,前提是内存足够大5 ~> 使用上下文管理器
5.1 理论
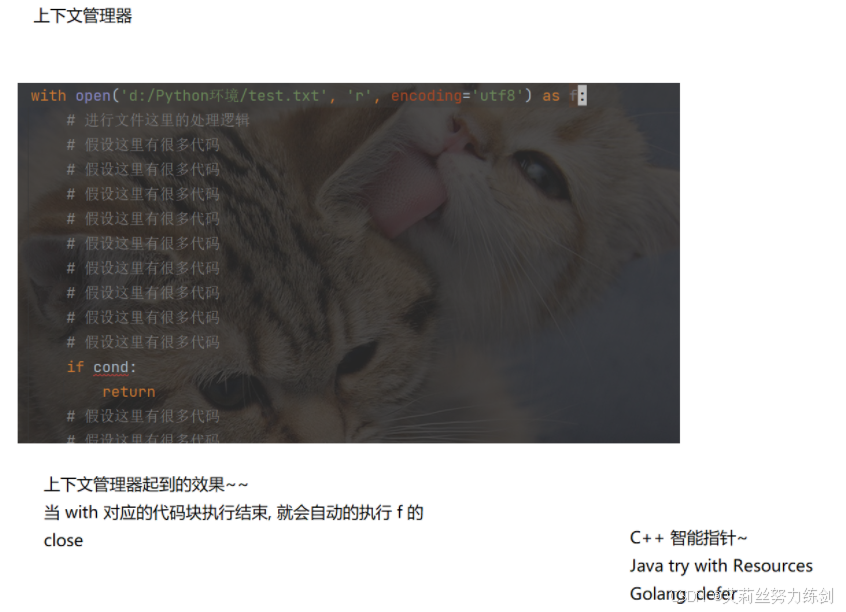
打开文件之后,是容易忘记关闭的.Python提供了 上下文管理器,来帮助程序猿自动关闭文件。
(1)使用with语句打开文件;
(2)当with内部的代码块执行完毕后,就会自动调用关闭方法。
bash
with open('d:/test.txt', 'r', encoding='utf8') as f:
lines = f.readlines()
print(lines)5.2 最佳实践
bash
# 上下文管理器
# Python中文件操作另外一个重要的机制
# 使用上下文管理器,就能解决资源泄露的问题
# 有些情况还是非常容易遗漏 close 的,防不胜防
# def func():
# f = open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8')
# # 中间来写其他的操作文件的逻辑
# #万一中间的代码里,有条件判定,函数返回,抛出异常
# if cond:
# # 进行条件处理
# f.close()
# return
# # 进行文件这里的处理逻辑
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# if cond:
# return
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
# # 假设这里有很多代码
def func():
with open('D:/Python_code/python_code/Python基础语法第六篇/test.txt','r',encoding='utf8') as f:
# 进行文件这里的处理逻辑
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
if cond:
return
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
if cond:
return
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码
# 假设这里有很多代码结尾
uu们,本文的内容到这里就全部结束了,艾莉丝再次感谢您的阅读!
结语:希望对学习Python相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Python基础:语法第五课】Python字典高效使用指南:避开KeyError,掌握遍历与增删改查精髓
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
