冬天一到,雪场又开始热闹起来。无论是老雪友还是新手,都有一个共同的噩梦:排队。
滑雪场怕排队------因为体验差;
滑雪的人更怕排队------因为时间都浪费在队伍里了。
尤其是那种几十米长的大蛇形队伍,一边冻得打哆嗦,一边还在怀疑人生:"为什么偏偏我排的这条线最慢?旁边那条看着就比我们快一倍......"
其实雪场也想解决这个问题,但现有的方法(比如 RFID 通行速率)并不靠谱:人少和人多时看起来差不多,根本反映不出队伍到底积压了多少。
所以想做一件简单但有用的事------用摄像头 + 计算机视觉算法,直接数队伍里到底有多少人,再算出真实的等待时间。
** **
**
Coovally平台提供了一站式AI开发环境,支持从数据准备、模型训练、验证评估到部署应用的全流程,帮助我们快速构建和落地自定义的AI模型。
Coovally平台不仅提供模型资源,还可以帮助你提供AI解决方案,可以扫描二维码,给你提供解决方案!!

快速讲一下计算机视觉是怎么"看"画面的
简单来说:
一帧视频其实就是一张图片,每个像素有红、绿、蓝三个数值。神经网络会用很多小滤波器在画面上扫来扫去,看看局部区域是否像它学过的东西。
- 浅层能看出边缘、纹理
- 深层能识别人、椅子、雪板这样的形状
- 最后几层它就不看像素了,而是看"特征"

我用的 YOLO 模型就是基于这种方式训练的,它从超级多真实世界的图像中学会了"找人"。所以即使不做额外训练,它也能在拥挤的缆车队伍里找到滑雪者的轮廓。
滑雪者检测流程怎么搭建的
很多雪场都有 24 小时的监控,比如基地、雪况、缆车队伍。可以自我选择不同环境和场景下的数据集,这里使用了Coovally提供的数据集。

先在 Colab 上用一小段录好的视频调试,保证整个逻辑是通的,再接入实时画面。
模型选型和参数调整
YOLOv11 有几种大小,从 mini 到 large,还有两种类型:
- 画框(Bounding Box)
给每个人画一个矩形框。这种方法速度快、重量轻,但矩形框并不能真正"理解"人的形状。而且拥挤时框会重叠、闪烁,计数不稳定
- 分割(Instance Segmentation)
为每位滑雪者生成一个完整的像素掩码。它不再是说"这个人存在于这个框内的某个位置",而是说"这些精确的像素属于这个人"。掩码应该能更好地处理拥挤和部分遮挡的情况。但更吃显卡
这次选的是 中型的分割模型 yolo11m-seg.pt,速度和准确度比较平衡。
- Confidence(置信度)
越低越"胆大",能抓到更多模糊的人影,但误报也可能变多。
- IoU(重叠阈值)
控制重叠的检测是否合并。拥挤的队伍里很容易两个人挤在一起,所以我把 IoU 调高(0.9),避免被误认为一个人。

专注真正的排队区域(ROI)
摄像头画面很大,有的区域根本不是队伍,比如雪地、建筑、路人。所以我只裁剪缆车队伍所在的区域:
ini
roi_crop = frame[roi_y1:roi_y2, roi_x1:roi_x2]这样更快也更准确。
- 检测并统计人数
对每帧画面跑分割模型,得到队伍中的人数。
ini
results = model.predict(roi_up, conf= 0.25 , iou= 0.9 ) # 分割逐帧统计会抖动,所以我用 15 秒的滑动窗口做平滑处理,让结果更稳定。
go
frame_counts.append ( { "frame" : frame_idx, "count_in_roi" : len (ids_in_roi) })
- 等待时间怎么估算?
核心逻辑很简单:
把缆车当成一台每分钟能"处理" X 个人的机器。
如果队伍中有 N 个人,那么:
等待时间 = N ÷ 每分钟实际上车人数实际吞吐量取决于:
- 缆车的理论最大容量(如四人椅 2000 人/小时)
- 实际装载率(一般 50%~95%)
例如:
- 理论:2000 人/小时 = 33 人/分钟
- 实际:75% 装载率 → 25 人/分钟
公式:
ini
Wait = N / (C × O / 60)真实系统当然最好能接入缆车运行状态,例如是否减速、停机。但我现在用的摄像头角度看不到这些细节。
- 第一次完整运行的结果
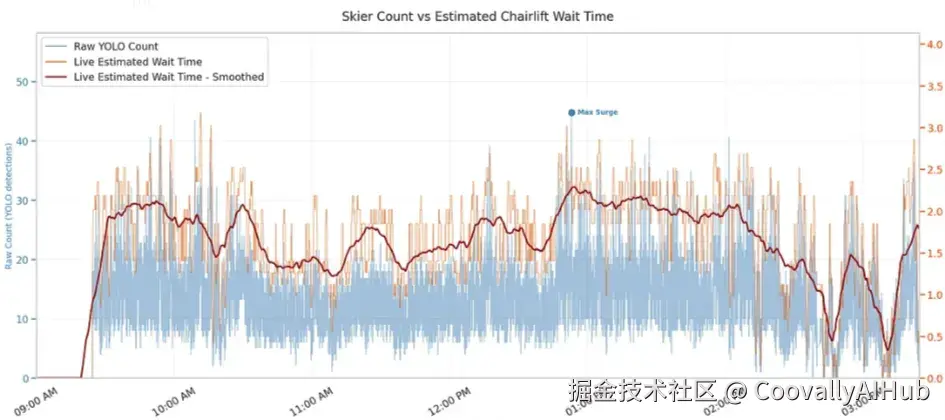
系统跑下来,非常稳定:
- 平均排队人数:10.9 人
- 峰值:45 人(中午 12:30)
- 高峰时段:下午 1 点
- 等待时间大部分都在 0--3 分钟之间
虽然人不多不算"压力测试",但整体流程已经验证可行。
- 尝试其他方法
人群密度估计模型(不检测单个人,直接预测区域人数)
简单像素占比(ROI 里"不是雪"的像素占了多少)
这些方法可能又快又够用。
总结
整体来看,这个系统的效果比我预期更好。即便摄像头不算理想、模型也没专项优化,光靠视频直接数人并换算成等待时间,已经比 RFID 闸机给的"流量数据"更靠谱。
当然也有局限:
- 摄像头角度会影响很大
- 人特别多时分割模型可能会吃力
- 更先进的模型(比如 Meta 的 SAM3)效果更强但太吃算力