锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer架构详解 - 残差连接(Residual Connection)详解以及算法实现
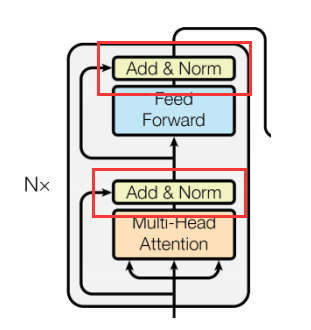
在深层网络中,随着网络深度的增加,梯度在反向传播时容易消失或爆炸,导致网络难以训练。为了解决这个问题,Transformer采用了残差连接,即将每一层的输入与该层的输出进行相加,而不是直接使用该层的输出。
形式:

这种连接方式保证了在网络初期,若子层变换的结果接近于零,则输出与输入相同,从而缓解了深度神经网络中梯度消失的问题。
优点:
-
恒等映射:使得网络能容易地学习到恒等映射,即如果某一层的变换没有效果,模型可以跳过该层。
-
梯度流畅:在反向传播时,梯度可以通过残差连接直接传递,避免了梯度消失的问题。
代码实现:
# 实现残差连接
class ResidualConnection(nn.Module):
def __init__(self, d_model, dropout=0.1):
# d_model 词嵌入维度 512 dropout 随机丢失率
super().__init__()
self.norm = LayerNorm(features=d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
前向传播
参数:
x: 输入张量 [batch_size, seq_len, d_model]
sublayer: 残差连接的子层 多头自注意力机制,或者来自前馈神经网络
返回:
残差连接后的张量
"""
return x + self.dropout(self.norm(sublayer(x)))
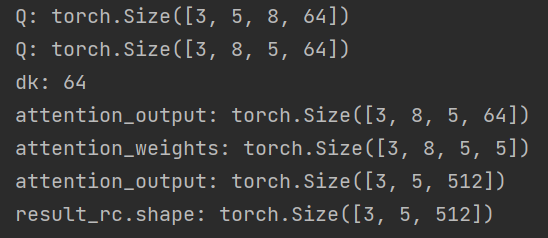
if __name__ == '__main__':
vocab_size = 2000 # 词表大小
embedding_dim = 512 # 词嵌入维度的大小
embeddings = Embeddings(vocab_size, embedding_dim)
embed_result = embeddings(
torch.tensor([[1999, 2, 99, 4, 5], [66, 2, 3, 22, 5], [66, 2, 3, 4, 5]]))
print("embed_result.shape:", embed_result.shape)
print("embed_result", embed_result)
positional_encoding = PositionalEncoding(embedding_dim)
result = positional_encoding(embed_result)
print("result:", result)
print("result.shape:", result.shape)
# 测试自注意力机制
# query = key = value = result
# mask = create_sequence_mask(5)
# dropout = nn.Dropout(0.1)
# attention_output, attention_weights = self_attention(query, key, value, mask, dropout)
# print("attention_output.shape:", attention_output.shape) # [3, 5, 512]
# print("attention_weights.shape:", attention_weights.shape) # [3, 5, 5]
mha = MultiHeadAttention(d_model=512, num_heads=8)
# print(mha)
mask = create_sequence_mask(5)
# 定义匿名函数
sublayer = lambda x: mha(x, x, x, mask)
# 测试残差连接
rc = ResidualConnection(d_model=512)
result_rc = rc(result, sublayer)
print("result_rc.shape:", result_rc.shape)运行输出: