
🎬 个人主页 :MSTcheng · CSDN
🌱 代码仓库 :MSTcheng · Gitee
🔥 精选专栏 : 《C语言》
《数据结构》
《C++由浅入深》
💬座右铭: 路虽远行则将至,事虽难做则必成!
前言:在前面的文章中我们向大家介绍了一些序列式容器,比如:basic_string、vector、deque、list等。而本篇文章我们将要进入树形容器------二叉搜索树的学习。
文章目录
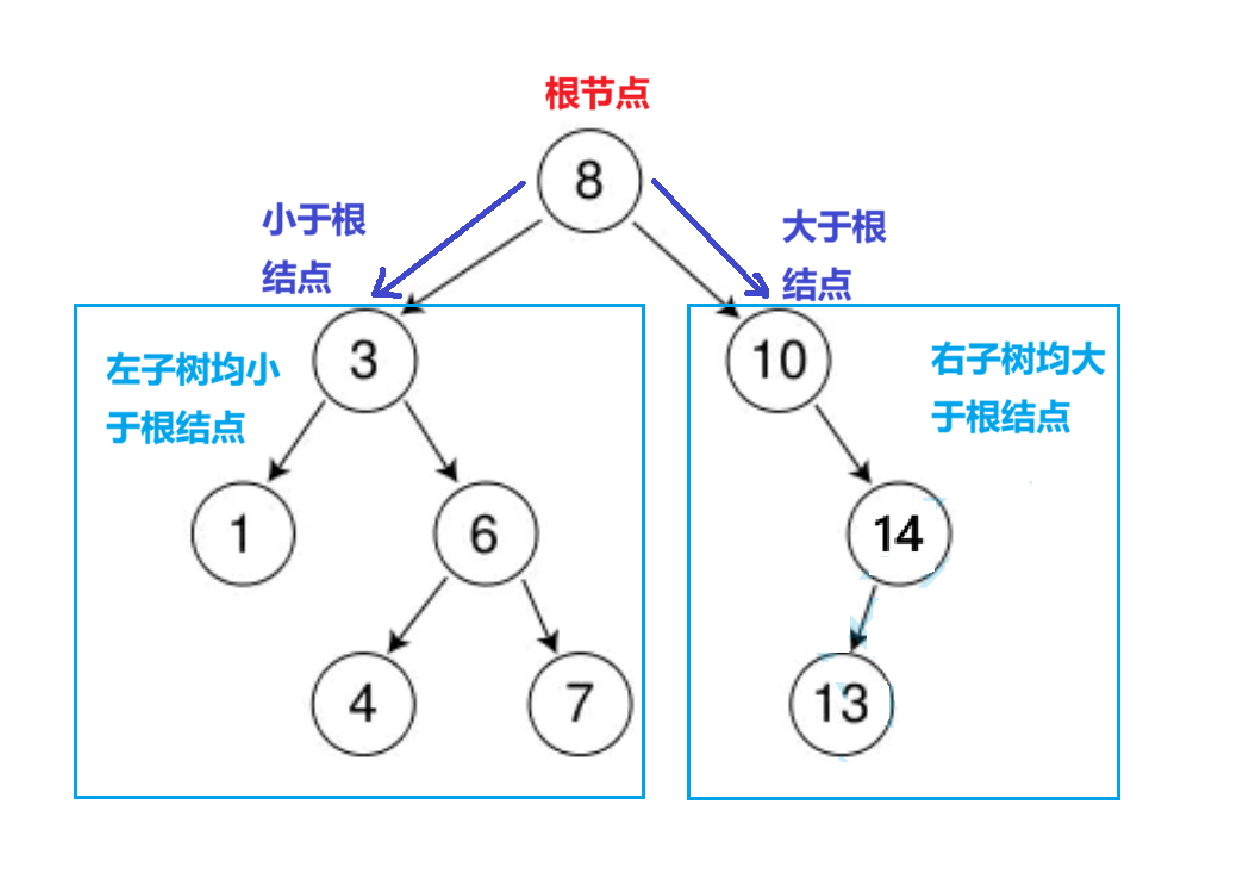
一、二叉搜索树的认识
1.1二叉搜索树的概念
二叉搜索树(Binary Search Tree, BST)是一种特殊的二叉树,满足以下性质:
- 对于任意节点,若其左子树不为空,则左子树中所有节点的值均小于该节点的值。
- 对于任意节点,若其右子树不为空,则右子树中所有节点的值均大于该节点的值。
- 左右子树也必须是二叉搜索树。
如下图:
思考: 既然插入一个比根小的值就往左子树插入,插入一个比根大的值就往右子树插入,插入的都是不同的值。那二叉搜索树能不能插入相同的值呢?
二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值 。具体看使用场景定义,后续我们学习
map/set/multimap/multiset系列容器底层就是⼆叉搜索树,其中map/set就不支持插入相等值 ,multimap/multiset就支持插入相等值。
1.2二叉搜索树的性能分析
为什么要进行二叉搜索树的性能分析?
二叉搜索树的核心功能是高效检索数据,所以性能分析至关重要。我们需要重点评估其查找效率。
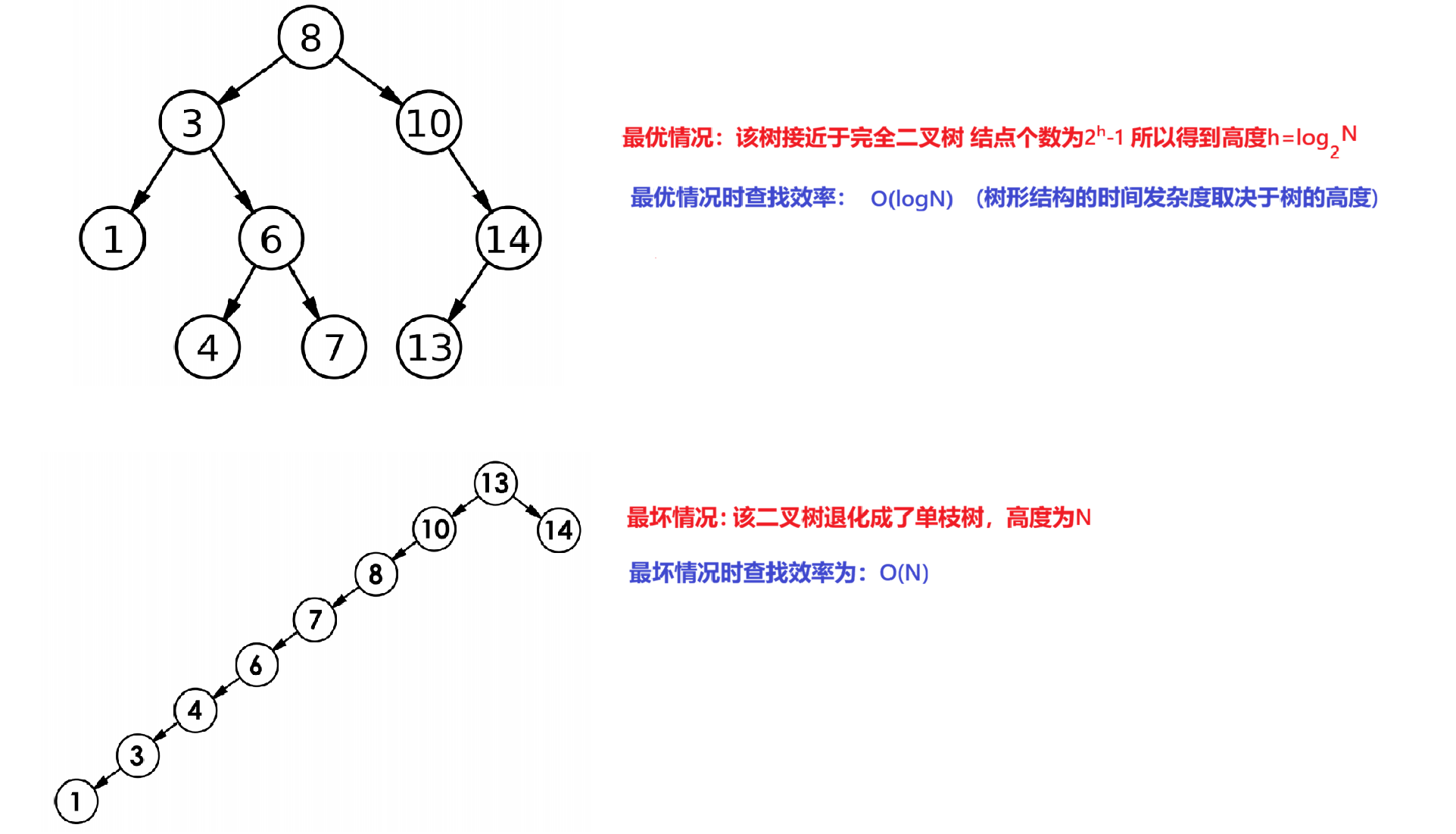
对于第二种情形的二叉树显然是不满足我们的需求的,所以使用二叉搜索树来存储的查找数据是不稳定的,因此要存储数据一般使用的二叉搜索树的变形------平衡二叉搜索树(AVL树)和红黑树来存储和查找数据。(AVL树和红黑树后面介绍)。
二、二叉搜索树的实现
2.1二叉搜索树的整体框架
1、定义结点的结构:
cpp
#include<iostream>
using namespace std;
//定义一个结点
template <class k>
struct BSTNode
{
k _key;
BSTNode<k>* _left;
BSTNode<k>* _right;
//构造函数
BSTNode(const k& key)
:_key(key)
,_left(nullptr)
,_right(nullptr)
{ }
};2、二叉搜索树的整体框架:
cpp
template<class k>
class BSTree
{
typedef BSTNode<k> Node;
public:
//中序遍历 将实现封成私有 外面提供一个接口
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
//中序遍历 采用递归
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
//中序 左-根-右
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
private:
Node* _root=nullptr;
};注意: 二叉搜索树的中序遍历我们不是直接放在公有而是直接给成私有,因为这个接口要传
_root,而_root在类外面是不能直接去访问的,但是又要提供这个接口,所以我们选择将他封装成私有(保证封装性),然后再提供一个外层接口来调用中序遍历这一接口。
2.2二叉搜索树的插入
插入的具体过程如下:
- 树为空 ,则直接新增结点,赋值给
root指针 - 树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点。
- 如果支持插入相等的值,插入值跟当前结点相等的值可以往右走,也可以往左走,找到空位置,插入新结点。(要注意的是要保持逻辑⼀致性,插入相等的值不要一会往右走,⼀会往左走)
cpp
bool Insert(const k& key)
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
//小于往左边走
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
//大于往右边走
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
//===================
//跳出循环此时cur为空
//先创建一个结点 给cur
//====================
cur= new Node(key);
//====================
//将parent与cur链接起来
//这时候还要判断cur是parent的左还是右
//如果传入的key大于parent的key那就插入在右边 小于反之
//====================
if (key > parent->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}注意:下面谈到的key均为我们要插入的值!
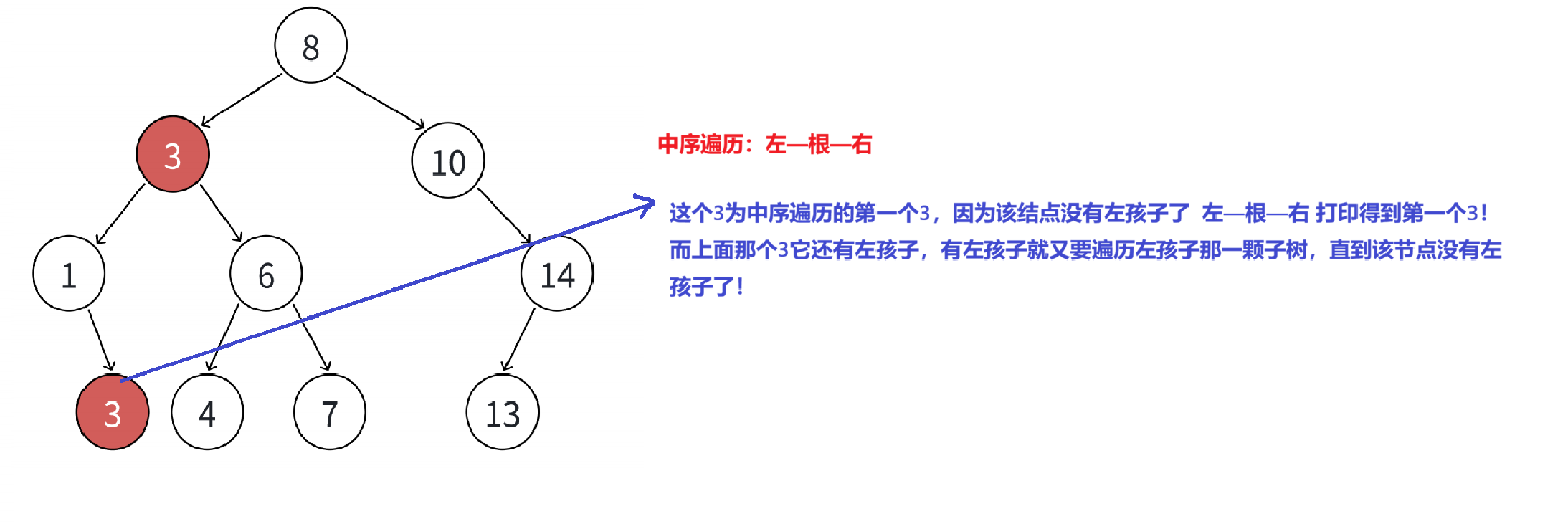
2.3二叉搜索树的查找
查找过程:
- 插入的
key首先从根结点开始比较 ,如果插入的key大于根结点的值那么就往根的右子树去查找,如果插入的key小于根的值,那么就往根的左子树去查找。 - 最多查找整棵树的高度次,如果还没有找到,则这个值不存在。
- 如果不支持相同的值插入 ,那么找到与
key值相等的结点就可以返回。(本篇文章实现的二叉搜索树不支持相同插入) - 如果如果支持插入相等的值 ,意味着有多个
key存在,⼀般要求查找中序的第⼀个key。如下图,查找3,要找到1的右孩子的那个3返回。(如下图)
代码示例:
cpp
bool Find(const k& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
//小于往左边走
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
//大于往右边走
parent = cur;
cur = cur->_right;
}
else
{
//找到了直接返回true
return true;
}
}
return false;
}2.4二叉树的删除
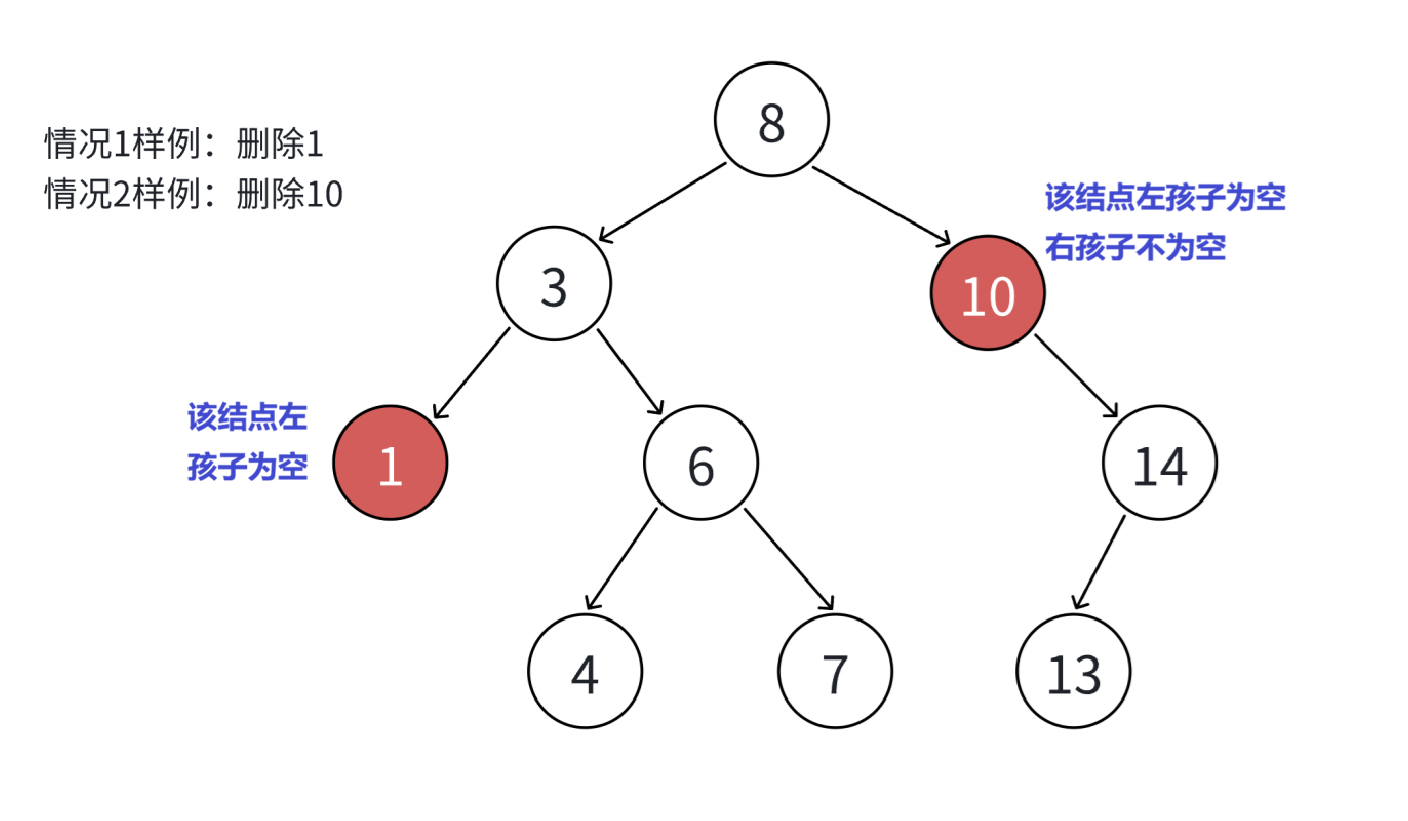
删除结点的具体过程:
-
要删除某个结点首先我们应该先找到它,如果不存在则返回false(删除失败),如果存在那么就要根据不同的情况来进行删除。
-
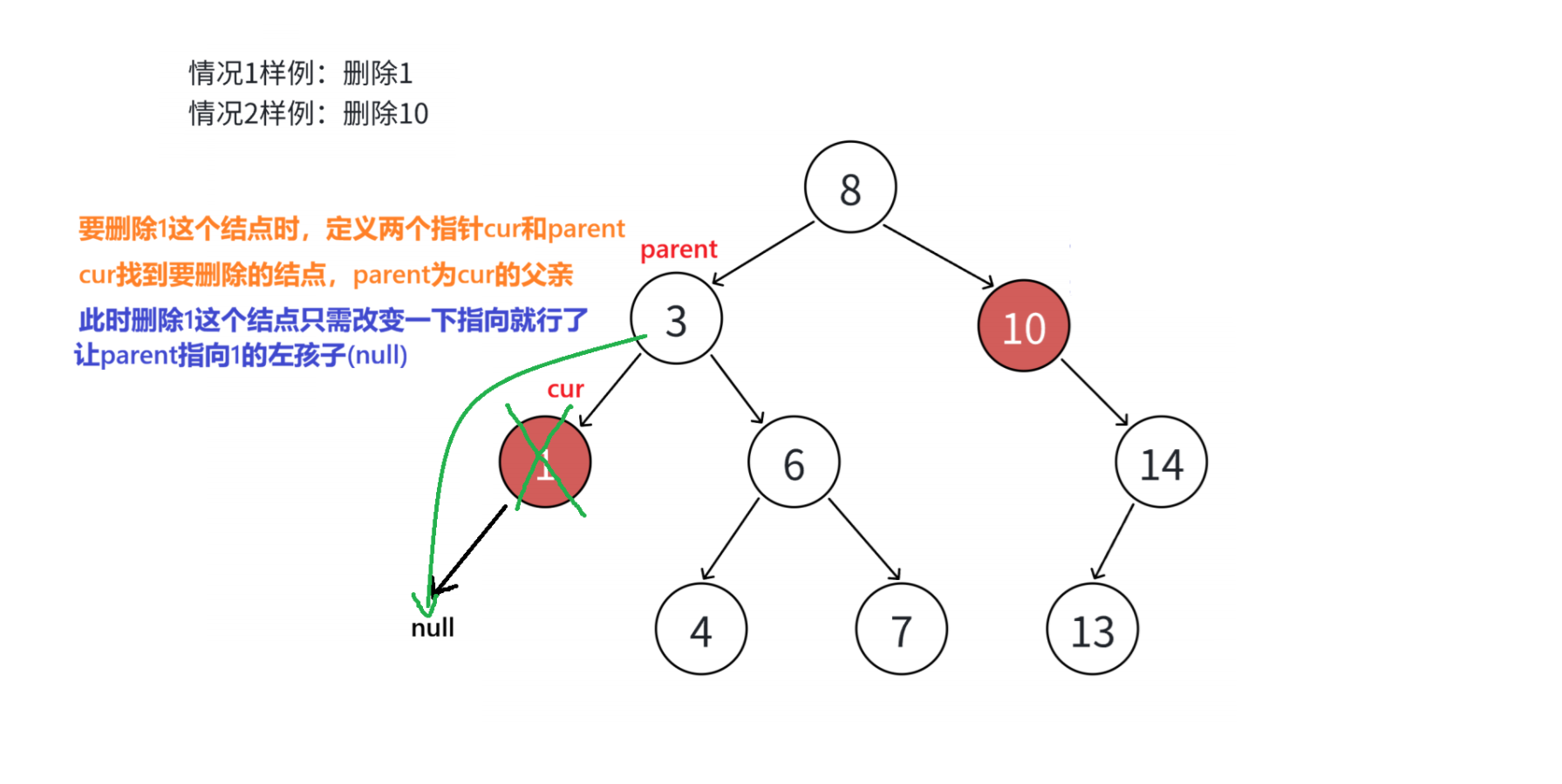
情况一 :要删除的结点x的左孩子为空。(如图下图值为3的结点)
-
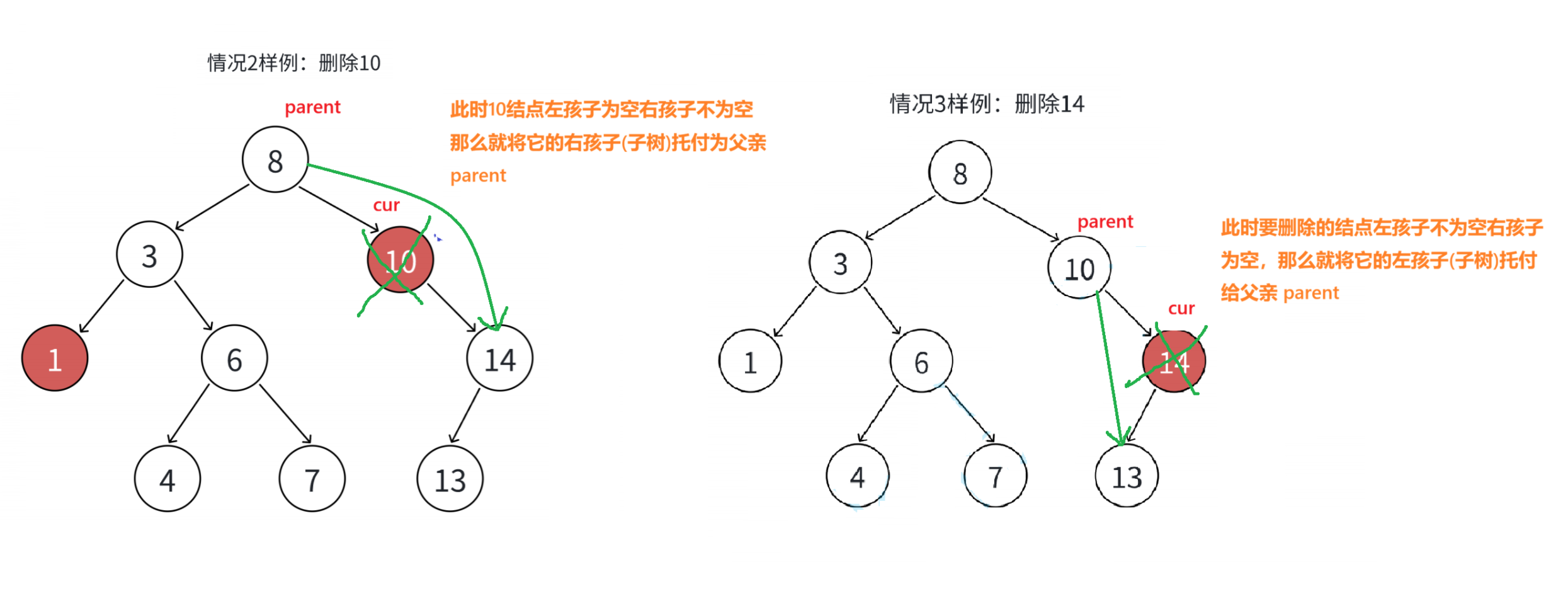
情况二: 要删除的结点x的左孩子为空,但右孩子不为空。 (如下图值为10的结点)
-
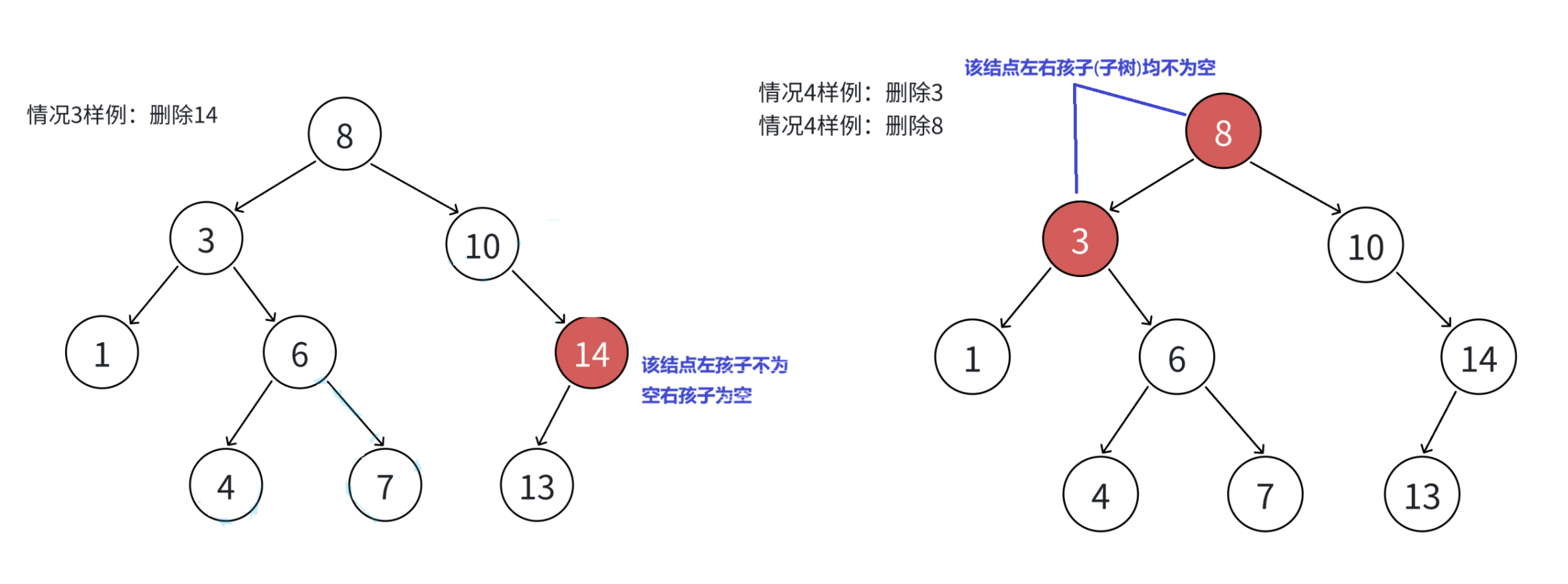
要删除的结点x的右孩子为空,但左孩子不为空。(如下图值为14的结点)
-
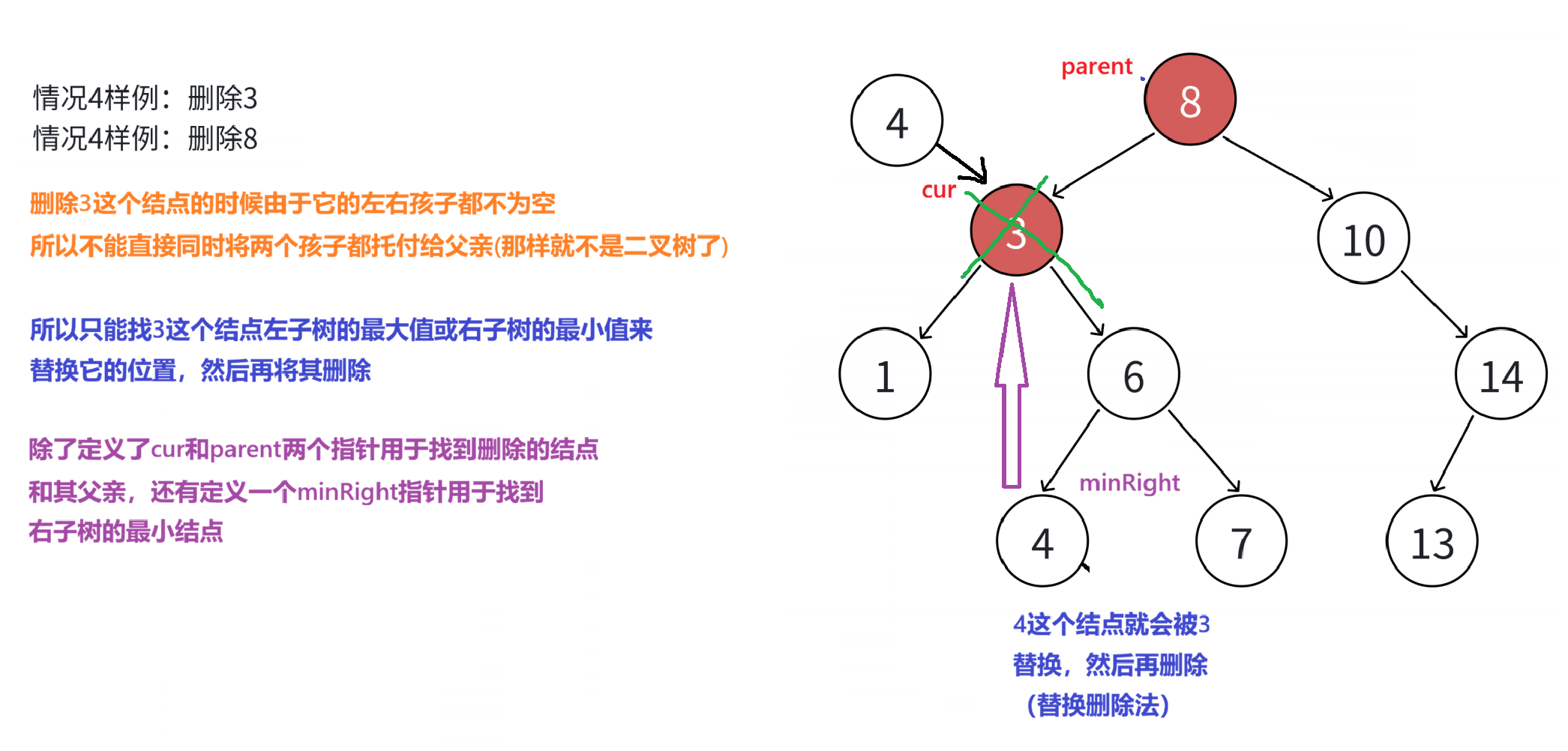
要删除的结点x的左右孩子均不为空。 (如下图值为3或8的结点)
解决方案如下(分别对应上面四种情况): -
把x结点的父亲对应孩子指针指向空,直接删除x结点。 (情况1可以当成2或者3处理,只是孩子为空让父亲的指针指向空而已)
-
把x结点的父亲对应孩子指针指向x的右孩子,直接删除x结点。(将右孩子托付给父亲前提只有一个孩子)
-
把x结点的父亲对应孩孩子指针指向x的左孩子,直接删除x结点。(将左孩子托付给父亲)
9.无法直接删除x结点,因为x的两个孩子无处安放,只能用替换法删除。 找x左子树的值最大结点R(最右结点 )或者x右子树的值最小结点R(最左结点 )替代x。因为这两个结点中任意一个,放到x的位置,都满足二叉搜索树的规则。替代x的意思就是x和R的两个结点的值交换,转而变成删除R结点,R结点符合情况2或情况3,可以直接删除。 (x结点就是要删除的那个结点,R结点就是右子树值最小的那个结点,如下图分别为3和4)
代码示例:
cpp
bool Erase(const k& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
//小于往左边走
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
//大于往右边走
parent = cur;
cur = cur->_right;
}
else
{
//找到了 准备删除
//===========================
//情况2
//左孩子为空 将右孩子托付给父亲
//===========================
if (cur->_left == nullptr)
{
if (cur != _root)
{
//此时要判断cur结点是parent的左孩子还是右孩子
if (cur == parent->_left)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_left;
}
}
else //当前结点是根节点且的左边为空 那么根节点就向右移动
{
_root = cur->_right;
}
delete cur;
}
//==========================
//情况3
//右孩子为空 将左孩子托付给父亲
//==========================
else if(cur->_right==nullptr) //cur的右为空
{
if (cur != _root)
{
if (cur == parent->_right)
{
//cur右为空 parent指向左
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
else //当前结点为根结点且右边为空 那么根结点就向左移动
{
_root = cur->_left;
}
delete cur;
}
//==============================
//情况4
//左右孩子都不为空 找右子树最小值替代
//==============================
else
{
//cur的左右都不为空 找右子树的最小结点来替代
Node* minRightParent = cur; //这里不能给nullptr 要给cur minRight没有进入循环 minRightParent没有更新导致后面的空指针解引用的报错
Node* minRight = cur->_right;
while (minRight->_left)
{
//如果minRight的左不为空 就继续往下找
minRightParent = minRight;
minRight = minRight->_left;
}
//跳出循环 当前minRight所在的结点就是右子树的最小结点
swap(cur->_key, minRight->_key);
//删除结点 此时minRight的左一定为空 但右孩子不能保证所以要判断!!!
//凡是要托付给父亲的结点(被删除的结点) 就要判断当前结点是父亲的左孩子还是右孩子
if (minRight == minRightParent->_left)
minRightParent->_left = minRight->_right;
else
minRightParent->_right = minRight->_right;
delete minRight;
}
return true;
}
}
return false;
}以上就是二叉搜索树的全部实现了,下面来看看二叉搜索树的应用场景。
三、二叉搜索树key和value的使用场景
上面实现的二叉树只有
key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值,搜索场景只需要判断key在不在。key的搜索场景实现的二叉树搜索树支持增删查,但是不支持修改,修改key破坏搜索树结构了。
因此,为了支持二叉树被修改我们增加一个value值,使得每一个key关键字都有与之对应的value值,value可以是任意类型的对象。所以以后我们在查找关键字对应的值value时就可以对其进行修改。但要注意key是不能被修改的!!!因为增/删/查还是以key为关键字走二叉搜索树的规则进行比较,修改的只能是value。
由于实现的逻辑与上面一致,只是多增加了一个模板参数所以我们直接给出代码:
cpp
//增加了一个模板参数v (value)
template <class k,class v>
struct BSTNode
{
k _key;
v _value;
BSTNode<k,v>* _left;
BSTNode<k,v>* _right;
//构造函数
BSTNode(const k& key,const v&value)
:_key(key)
,_value(value)
, _left(nullptr)
, _right(nullptr)
{
}
};
//增加一个模板参数v (value)
template<class k,class v>
class BSTree
{
typedef BSTNode<k,v> Node;
public:
bool Insert(const k& key,const v& value)
{
if (_root == nullptr)
{
_root = new Node(key,value);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else
{
return false;
}
}
//创建结点时增加一个value
cur = new Node(key,value);
if (key > parent->_key)
{
parent->_right = cur;
}
else
{
parent->_left = cur;
}
return true;
}
//================================
//与上面只实现key的搜索树的Find不一样上面的find找到了就行 这里的find找到的是对应value值
//这里Find的返回值直接改成Node* 返回一个结点
//因为返回一个结点可以同时拿到key和value的值
//================================
Node* Find(const k& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
//小于往左边走
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
//大于往右边走
parent = cur;
cur = cur->_right;
}
else
{
return cur;
}
}
return nullptr;
}
bool Erase(const k& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (key < cur->_key)
{
//小于往左边走
parent = cur;
cur = cur->_left;
}
else if (key > cur->_key)
{
//大于往右边走
parent = cur;
cur = cur->_right;
}
else
{
//找到了 准备删除 先判断删除的是不是根结点
//这时候判断 cur哪个孩子不为空 就托付给父亲
if (cur->_left == nullptr)
{
if (cur != _root)
{
if (cur == parent->_left)
{
parent->_left = cur->_right;
}
else
{
parent->_right = cur->_left;
}
}
else
{
_root = cur->_right;
}
delete cur;
}
else if (cur->_right == nullptr)
{
if (cur != _root)
{
if (cur == parent->_right)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
else
{
_root = cur->_left;
}
delete cur;
}
else
{
Node* minRightParent = cur;
Node* minRight = cur->_right;
while (minRight->_left)
{
minRightParent = minRight;
minRight = minRight->_left;
}
swap(cur->_key, minRight->_key);
if (minRight == minRightParent->_left)
minRightParent->_left = minRight->_right;
else
minRightParent->_right = minRight->_right;
delete minRight;
}
return true;
}
return false;
}
//中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
private:
void _InOrder(Node* root)
{
if (root == nullptr)
{
return;
}
//中序 左-根-右
_InOrder(root->_left);
cout << root->_key <<":"<<root->_value << " ";
_InOrder(root ->_right);
}
private:
Node* _root = nullptr;
};以上就是
key-value的模拟实现了,下面来具体看一下两个使用场景,一个是使用key查看在不在,一个是使用key-value统计次数.
1、使用查找在不在的key的场景:
cpp
void key_test()
{
key_value::BSTree<string, string> dict;
//BSTree<string, string> copy = dict;
dict.Insert("left", "左边");
dict.Insert("right", "右边");
dict.Insert("insert", "插入");
dict.Insert("string", "字符串");
string str;
while (cin >> str)
{
auto ret = dict.Find(str);
if (ret)
{
cout << "存在此单词" << endl;
}
else
{
cout << "无此单词,请重新输入" << endl;
}
}
return 0;
}
2、使用key-value统计的场景:
cpp
void test_key_value()
{
string arr[] = { "苹果", "西瓜", "苹果","苹果","苹果","苹果", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
key_value::BSTree<string, int> t;
for (auto& str : arr)
{
auto pNode = t.Find(str);
if (pNode==nullptr)
{
t.Insert(str, 1);
}
else
{
pNode->_value++;
}
}
t.InOrder();
return 0;
}
四、总结
二叉搜索树(BST)键(Key)与键值对(Key-Value)的比较
| 特性 | 键(Key) | 键值对(Key-Value) |
|---|---|---|
| 存储内容 | 仅存储键(唯一标识符) | 存储键和关联的值(键为唯一标识符) |
| 用途 | 主要用于排序、查找键是否存在 | 用于映射关系(如字典、哈希表功能) |
| 操作复杂度 | 插入、删除、查找均为平均 O(log n) | 同左,但需额外处理值的存储 |
| 内存占用 | 较小(仅存储键) | 较大(需存储键和值) |
| 示例应用 | 判断元素是否在集合中 | 存储学生ID(键)和成绩(值) |
| 实现差异 | 节点仅包含 key 和左右子节点指针 |
节点包含 key、value 和左右子节点指针 |
选择建议:
- 需要快速检查键是否存在或排序时,使用键结构。
- 需建立键到值的映射关系(如数据库索引)时,使用键值对结构。