目标检测作为计算机视觉的核心任务之一,其核心目标是精准预测图像中感兴趣目标的边界框与类别标签。长期以来,主流检测方法(如 Faster R-CNN、SSD 等)均采用间接建模方式,通过锚点生成、候选区域提取等预处理步骤,将集合预测问题转化为大量候选框的分类与回归任务。这类方法存在固有缺陷:锚点设计依赖人工经验、非极大值抑制(NMS)等后处理步骤需要手动调优、候选框分配规则存在启发式偏见,这些因素导致检测 pipeline 复杂且泛化能力受限。
2020 年,Facebook AI 提出的 DETR(DEtection TRansformer)首次将 Transformer 架构与二分图匹配损失结合,开创了端到端直接集合预测的目标检测新范式。该方法彻底摒弃了锚点生成、NMS 等人工设计组件,通过全局推理直接输出最终检测结果,不仅简化了检测流程,更在 COCO 数据集上实现了与高度优化的 Faster R-CNN 相当的性能,同时为全景分割等复杂任务提供了统一的扩展框架。
原文链接:https://arxiv.org/pdf/2005.12872
代码链接:https://github.com/facebookresearch/detr
沐小含持续分享前沿算法论文,欢迎关注...
一、核心思想:直接集合预测与 Transformer 的融合
1.1 从间接建模到直接集合预测
传统目标检测的本质是间接集合预测:通过生成大量候选框(锚点或候选区域),将目标检测转化为 "候选框分类 + 边界框回归" 的代理任务,再通过 NMS 等后处理去除重复预测。这种方式存在三大问题:
- 候选框与真实目标的匹配依赖人工设计的分配规则(如 IoU 阈值);
- NMS 的超参数(如 IoU 阈值)对检测结果影响显著;
- 模型无法直接建模目标间的全局关系,难以处理重叠或密集目标。
DETR 的核心创新是将目标检测视为直接集合预测问题:给定图像,模型直接输出一个固定大小的预测集合,集合中每个元素包含目标类别与边界框,无需任何后处理步骤。为实现这一目标,DETR 需解决两个关键问题:
- 集合损失函数:需保证预测集合与真实集合的排列不变性(即预测顺序不影响损失计算),并实现一对一匹配以避免重复预测;
- 全局建模架构:需建模目标间的相互关系与图像全局上下文,以准确区分目标并抑制冗余预测。
1.2 Transformer 的适配:全局注意力与并行解码
Transformer 架构的自注意力机制能够建模序列中所有元素的 pairwise 交互,天然适合处理集合预测的全局推理需求。与传统 RNN 的 autoregressive 解码不同,DETR 采用非自回归并行解码,能够同时输出所有预测结果,大幅提升推理效率。具体而言:
- 编码器通过自注意力机制捕捉图像全局特征,建模像素间的长距离依赖;
- 解码器通过 "目标查询(object queries)" 与编码器输出进行交互,同时建模目标间的关系;
- 目标查询是一组可学习的嵌入向量,其数量 N(默认 100)远大于图像中典型目标数量,未匹配到真实目标的查询将被标记为 "无目标(∅)"。
DETR 的整体流程如图 1 所示:CNN 骨干网络提取图像特征,Transformer 编码器 - 解码器对特征进行全局建模,最终通过前馈网络输出预测集合;训练阶段通过二分图匹配损失实现预测与真实目标的一对一分配。
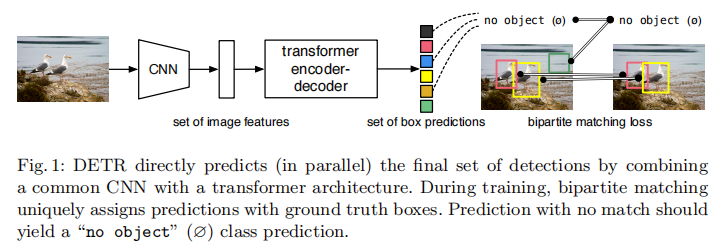
二、模型架构:模块化设计与细节解析
DETR 的架构异常简洁,仅包含三大核心组件:CNN 骨干网络、Transformer 编码器 - 解码器、预测头(FFN)。其整体结构如图 2 所示,各组件的详细设计如下:
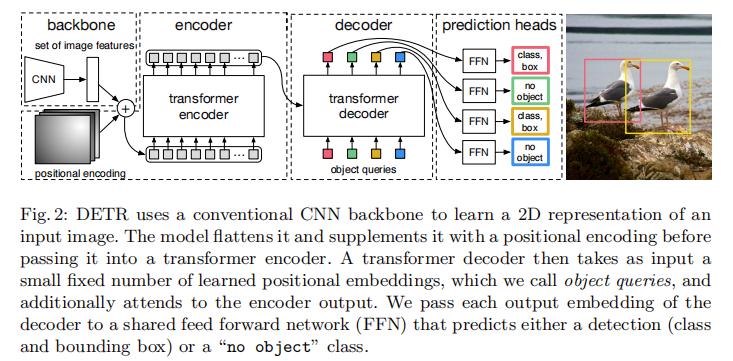
2.1 CNN 骨干网络:特征提取
输入图像为 (3 个颜色通道,原始分辨率
)。DETR 采用 ResNet 作为骨干网络(默认 ResNet-50/101),提取高维特征图
,其中
(ResNet-50 的输出通道数),
,
(经过 5 次下采样)。
为提升小目标检测性能,DETR 提供了一种改进的骨干网络变体(DC5):通过在 ResNet 的最后一个阶段使用空洞卷积(dilation)并移除步幅,将特征图分辨率提升 2 倍(,
),代价是编码器自注意力的计算量增加 16 倍,整体计算量提升 2 倍。
2.2 特征维度压缩与位置编码
Transformer 的输入通道数通常远小于 CNN 骨干网络的输出通道数(DETR 中设为 )。因此,通过一个 1×1 卷积层将 CNN 输出的特征图通道数从
压缩至
,得到
。
由于 Transformer 是排列不变的(对输入序列的顺序不敏感),需为特征添加位置编码以保留空间信息。DETR 采用两种位置编码:
- 空间位置编码(Spatial Positional Encoding):用于编码器输入,采用固定的正弦 - 余弦编码(2D 扩展),对每个空间位置
,编码向量的维度为
- 目标查询编码(Object Query Encoding):用于解码器输入,是一组可学习的嵌入向量(
位置编码的添加方式为:在每个注意力层的输入中,将位置编码与特征向量直接相加。
2.3 Transformer 编码器
编码器的输入是 flatten 后的特征序列:将 转化为
(空间维度展平为序列长度 HW),并添加空间位置编码。
编码器采用标准 Transformer 编码器结构,每个编码器层包含两个子层(图 10 左):
-
多头自注意力(Multi-Head Self-Attention):建模特征序列中所有元素的全局依赖,每个头的维度为
-
前馈网络(FFN):由两个 1×1 卷积层和 ReLU 激活组成,隐藏层维度为
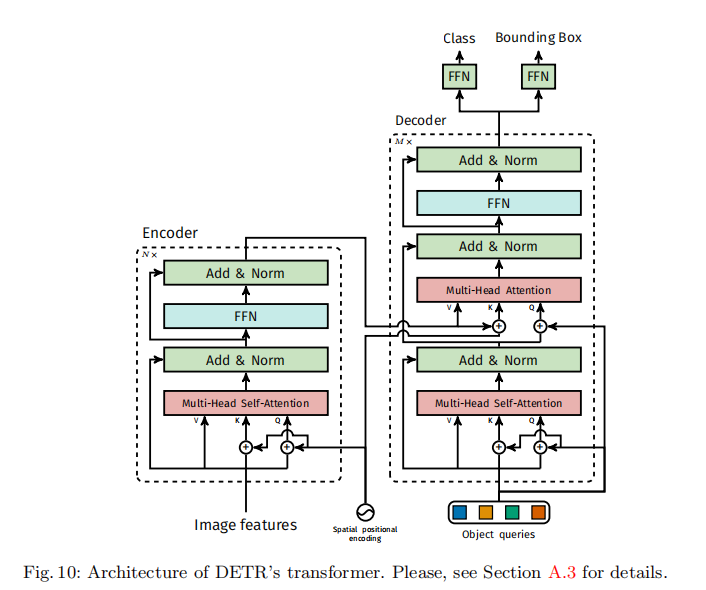
每个子层均采用 "残差连接 + 层归一化 + Dropout" 结构,Dropout 率设为 0.1。编码器的核心作用是通过全局自注意力捕捉图像的全局上下文,分离不同目标的特征表示,如图 3 所示:编码器能够自动聚焦于不同目标实例,为解码器提供清晰的目标特征。

2.4 Transformer 解码器
解码器采用标准 Transformer 解码器结构,但与原始 Transformer(自回归解码)不同,DETR 的解码器采用并行解码 :同时处理 个目标查询,输出
个嵌入向量,每个向量对应一个目标的特征表示。
解码器的输入包含三部分:
- 目标查询(可学习嵌入向量
- 编码器输出(记忆向量
- 目标查询的位置编码(与查询向量相加后输入每个注意力层)。
每个解码器层包含三个子层(图 10 右):
- 多头自注意力(Multi-Head Self-Attention):建模目标查询间的相互关系,抑制重复预测(例如,两个查询关注同一目标时,通过注意力权重调整实现竞争);
- 多头编码器 - 解码器注意力(Multi-Head Encoder-Decoder Attention):建模目标查询与编码器特征的交互,使每个查询能够聚焦于图像中对应的目标区域;
- 前馈网络(FFN):与编码器的 FFN 结构一致,用于目标特征的非线性变换。
解码器的核心作用是通过查询与图像特征的交互,以及查询间的关系建模,生成每个目标的精准特征表示。解码器注意力的可视化结果如图 6 所示:解码器通常聚焦于目标的关键部位(如头部、腿部),以准确提取目标边界与类别信息。

2.5 预测头(Feed-Forward Networks, FFN)
预测头是一个共享的 3 层感知机,输入为解码器输出的嵌入向量(),输出为目标的类别与边界框:
- 类别预测:通过线性层输出
- 边界框预测:通过线性层输出 4 个值(归一化的中心坐标
为提升训练稳定性,DETR 在每个解码器层后均添加了辅助预测头与辅助损失(Auxiliary Loss),所有辅助预测头共享参数,并通过共享层归一化处理不同解码器层的输入。辅助损失的作用是引导解码器逐层优化,尤其有助于模型学习目标数量的预测。
三、损失函数:二分图匹配与匈牙利损失
直接集合预测的核心挑战是设计排列不变的损失函数,确保模型输出与真实目标的匹配不受预测顺序影响。DETR 通过二分图匹配损失 (Bipartite Matching Loss)与匈牙利损失(Hungarian Loss)解决这一问题,分为两个步骤:
3.1 步骤 1:二分图匹配(Bipartite Matching)
给定真实目标集合 (大小为
)与预测集合
(大小为
,
),首先将真实集合填充为大小
(未填充部分标记为 "无目标"
),然后寻找一个最优排列
(
为
个元素的排列集合),使得预测与真实目标的匹配成本最小:
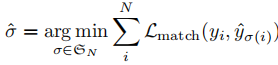
匹配成本 综合考虑类别匹配与边界框匹配,定义为:
其中:
最优排列 通过匈牙利算法(Hungarian Algorithm)求解,确保每个真实目标与唯一预测匹配,每个预测也仅匹配一个真实目标,从而避免重复预测。
3.2 步骤 2:匈牙利损失(Hungarian Loss)
在得到最优匹配 后,匈牙利损失计算匹配对的分类损失与边界框损失之和,定义为:
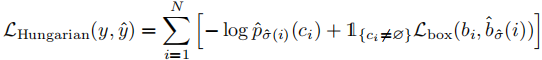
其中:
- 分类损失:负对数似然损失,对 "无目标" 类别(
- 边界框损失
- 超参数
3.3 损失组件的必要性验证
通过 ablation 实验验证损失各组件的作用,结果如表 4 所示:
- 仅使用 GIoU 损失时,模型性能仅下降 0.7 AP,说明 GIoU 是边界框匹配的核心;
- 仅使用
- 分类损失是模型训练的基础,无法移除(实验中未展示移除分类损失的情况,因会导致模型无法学习类别区分)。

四、实验验证:性能、消融与扩展
DETR 的实验主要基于 COCO 2017 数据集(118k 训练图像,5k 验证图像),评估指标包括 AP(平均精度)、APS(小目标 AP)、APM(中目标 AP)、APL(大目标 AP),并与 Faster R-CNN 进行全面对比。
4.1 与 Faster R-CNN 的性能对比
为确保对比公平,DETR 对 Faster R-CNN 进行了增强:添加 GIoU 损失、随机裁剪数据增强、延长训练周期(9× schedule),使其成为更强的基线。对比结果如表 1 所示:
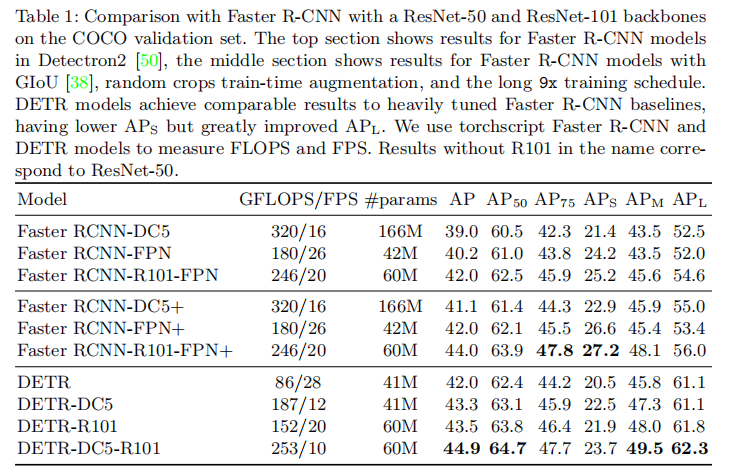
关键结论:
- 性能相当:DETR(ResNet-50)的 AP(42.0)略低于增强后的 Faster R-CNN+(44.9),但参数量仅为后者的 2/3,推理速度提升 2 倍以上;
- 大目标优势:DETR 的 APL(60.2)显著高于 Faster R-CNN + 的 APL(57.9),提升 7.8 个百分点,得益于 Transformer 的全局注意力机制;
- 小目标短板:DETR 的 APS(19.9)低于 Faster R-CNN + 的 APS(23.7),下降 5.5 个百分点,主要因 CNN 骨干网络下采样导致小目标特征丢失(DC5 变体可部分缓解);
- 扩展能力:DETR-R101 的 AP 达到 43.5,仍保持较高推理速度,证明模型架构的扩展性。
4.2 消融实验:关键组件的影响
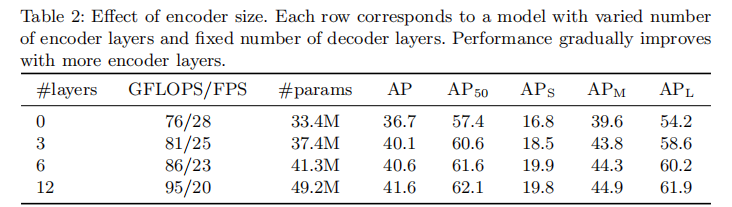
4.2.1 编码器层数的影响
编码器的核心作用是全局上下文建模,表 2 展示了不同编码器层数对性能的影响:
- 无编码器时(0 层),AP 仅为 36.7,APL 下降 6.0 个百分点,说明全局自注意力对大目标检测至关重要;
- 随着编码器层数增加(3→6→12),AP 逐步提升(40.1→40.6→41.6),但计算量与推理速度略有下降,验证了全局建模的价值。
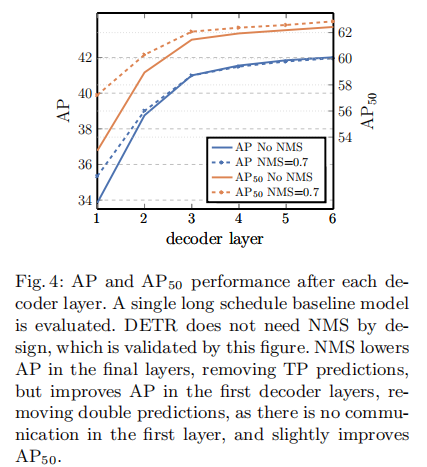
4.2.2 解码器层数与 NMS 的必要性
解码器通过多层自注意力建模目标间关系,图 4 展示了不同解码器层的性能及 NMS 的影响:
- 随着解码器层数增加(1→6),AP 从 33.8 提升至 40.6,AP50 从 52.1 提升至 61.6,说明多层交互对抑制重复预测至关重要;
- 第一层解码器输出需 NMS 提升性能(AP 从 33.8→35.2),因单层无法建模目标间关系,存在大量重复预测;
- 第六层解码器输出无需 NMS,甚至 NMS 会导致 AP 下降(40.6→40.2),因自注意力已有效抑制重复预测,NMS 会误删真实目标。
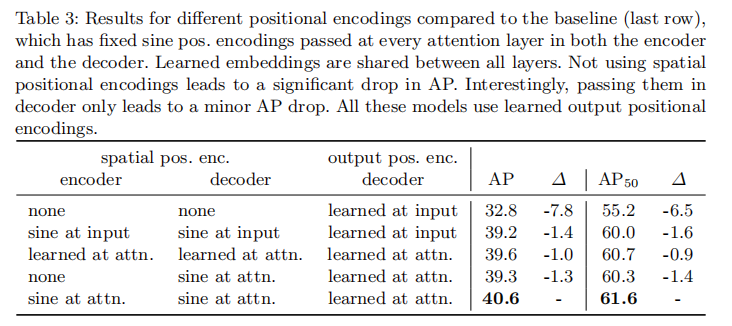
4.2.3 位置编码的影响
位置编码是 Transformer 保留空间信息的关键,表 3 展示了不同位置编码配置的性能:
- 移除空间位置编码后,AP 下降 7.8 个百分点,说明空间位置信息对检测至关重要;
- 固定正弦编码与可学习编码的性能接近(40.6 vs 39.6),证明固定编码足以提供有效的空间信息;
- 仅在解码器添加空间编码时,AP 仅下降 1.3 个百分点,说明编码器的全局特征已包含部分空间信息,解码器的查询交互可部分补偿。
4.2.4 前馈网络(FFN)的影响
FFN 在 Transformer 中起到非线性特征变换的作用,移除 FFN 后:
- 参数量从 41.3M 降至 28.7M;
- AP 下降 2.3 个百分点(40.6→38.3);证明 FFN 对特征提取与目标区分至关重要,其作用类似注意力增强的卷积层。
4.3 模型行为分析
4.3.1 目标查询的专业化
DETR 的 100 个目标查询会学习到不同的专业化分工,图 7 展示了验证集中所有预测框的分布:
- 每个查询专注于特定区域或尺寸的目标(如部分查询专门预测小目标,部分专门预测大目标);
- 几乎所有查询都有一个 "全图框" 模式,对应 COCO 数据集中常见的大目标分布;
- 这种专业化分工是模型通过训练自动学习的,无需人工设计。

4.3.2 对未见目标数量的泛化能力
COCO 训练集中部分类别(如长颈鹿)的实例数量极少(最多 13 个),DETR 在合成图像(24 个长颈鹿)上的测试结果如图 5 所示:
- 模型能够准确检测所有 24 个实例,证明目标查询没有过拟合到训练集中的目标数量分布;
- 这一结果验证了直接集合预测的优势:模型不依赖锚点或候选框的数量限制,能够泛化到 unseen 的目标密度。

4.4 扩展至全景分割
全景分割(Panoptic Segmentation)要求同时预测 "事物(Things,可数目标)" 与 "stuff(不可数背景,如天空、草地)",并输出像素级的实例分割结果。DETR 的架构天然支持全景分割的扩展,只需在解码器输出后添加一个掩码头(Mask Head),如图 8 所示:
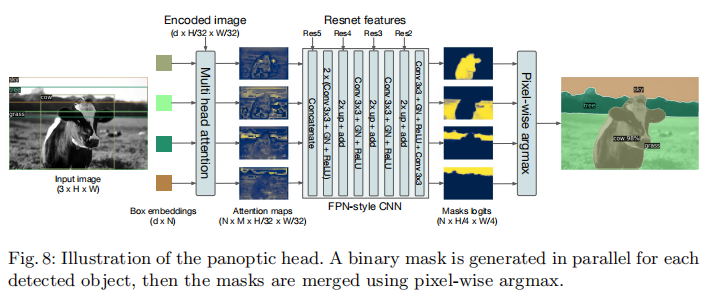
扩展细节:
- 训练阶段:DETR 同时预测事物与 stuff 的边界框,使用相同的二分图匹配损失;
- 掩码头:接收解码器输出的目标嵌入向量,通过多头注意力生成 M 个注意力热图(
- 掩码损失:使用 DICE/F-1 损失与 Focal 损失联合监督掩码预测;
- 推理阶段:通过像素级 argmax 融合所有掩码,确保无重叠,无需额外的启发式后处理。
全景分割性能
表 5 展示了 DETR 在 COCO 全景分割验证集上的性能,与 Panoptic FPN、UPSNet 等主流方法对比:
- DETR-R101 的 PQ(全景质量)达到 45.1,超过 Panoptic FPN++(R101,44.1)与 UPSNet-M(R50,43.0);
- 尤其在 stuff 类别上,DETR 的 PQst(37.0)显著高于 Panoptic FPN++(33.6),证明 Transformer 的全局推理对背景分割的优势;
- 事物类别的 PQth(50.5)与主流方法相当,尽管掩码 AP 较低(33.0),但通过全局匹配实现了更优的全景质量。
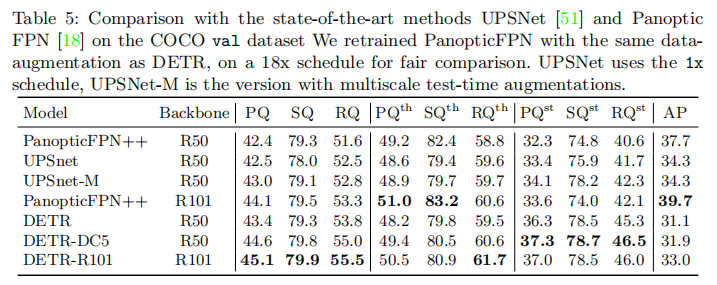
图 9 展示了 DETR 的全景分割定性结果,可见模型能够同时准确分割事物与 stuff,边界清晰且无重叠。

五、训练细节与实现
5.1 训练配置
- 优化器:AdamW,权重衰减
- 学习率:Transformer 的初始学习率
- 训练周期:基础周期 300 轮(200 轮后学习率下降 10 倍),与 Faster R-CNN 对比时使用 500 轮(400 轮后学习率下降 10 倍);
- 数据增强:随机缩放(最短边 480-800,最长边≤1333)、随机裁剪(概率 0.5);
- 批量大小:16 张 V100 GPU,每张 GPU 4 张图像,总批量 64;
- 初始化:Transformer 权重采用 Xavier 初始化,骨干网络使用 ImageNet 预训练权重,冻结 BatchNorm 层。
5.2 推理优化
- 无目标查询处理:推理时,将 "无目标" 类别的预测替换为第二高置信度的类别,提升 AP 约 2 个百分点;
- 掩码过滤:全景分割推理时,过滤置信度低于 85% 的预测,以及像素数少于 4 的小掩码。
5.3 代码实现
DETR 的实现异常简洁,无需专用库,仅依赖 PyTorch 与 Torchvision 的标准组件。以下是核心推理代码(约 50 行):
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# 提取ResNet-50的卷积层(去除最后两层)
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
# 特征维度压缩至hidden_dim
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# Transformer编码器-解码器
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
# 类别预测头(+1表示无目标类别)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
# 边界框预测头(sigmoid激活)
self.linear_bbox = nn.Linear(hidden_dim, 4)
# 可学习的目标查询
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# 空间位置编码(行/列嵌入)
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
# CNN骨干网络提取特征
x = self.backbone(inputs)
# 维度压缩
h = self.conv(x)
H, W = h.shape[-2:]
# 生成空间位置编码
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# Transformer前向传播(pos + 特征序列,目标查询)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
# 输出类别与边界框
return self.linear_class(h), self.linear_bbox(h).sigmoid()
# 模型初始化与推理
detr = DETR(num_classes=91, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)六、结论与展望
DETR 通过 "直接集合预测 + Transformer" 的创新组合,彻底重构了目标检测的 pipeline,摒弃了锚点、NMS 等人工设计组件,实现了端到端的检测流程。其核心贡献包括:
- 提出二分图匹配损失与匈牙利损失,解决了直接集合预测的排列不变性与一对一匹配问题;
- 首次将 Transformer 的全局注意力机制引入目标检测,有效建模目标间关系与图像全局上下文;
- 提供了简洁、通用的模型架构,无需专用库即可实现,且易于扩展至全景分割等复杂任务。
DETR 的局限性与未来改进方向:
- 小目标检测性能不足:可通过特征金字塔(FPN)、多尺度输入、更精细的位置编码等方式优化;
- 训练周期过长:当前需要 300-500 轮训练,可通过改进优化器、数据增强、预训练策略等加速收敛;
- 计算量较大:Transformer 的自注意力计算量与序列长度平方成正比,可通过稀疏注意力、分层注意力等方式降低计算成本。
DETR 的提出不仅推动了目标检测的范式转变,更启发了后续一系列基于 Transformer 的检测模型(如 Deformable DETR、Conditional DETR 等)。其 "全局建模 + 直接集合预测" 的思想为计算机视觉的结构化预测任务(如实例分割、目标追踪、视频理解)提供了新的思路,具有广泛的应用前景。