Flink CDC 入门实战:从原理到踩坑全记录 (Java/SQL 双版本)
在构建实时数仓和数据湖的过程中,CDC (Change Data Capture) 是数据摄入最核心的环节。传统的 CDC 链路往往比较复杂,而 Flink CDC 凭借其"去 Kafka 化"的极简架构、全增量一体化读取以及无锁算法,成为了目前最主流的数据同步方案。
本文基于 Flink 1.17 和 Flink CDC 2.4 ,带你从零搭建一个实时同步应用,并重点复盘在实战中 90% 的开发者都会遇到的"坑"。
一、 为什么选择 Flink CDC?
1.1 传统方案 vs Flink CDC
传统链路 (Canal/Debezium):
MySQL -> Canal/Debezium -> Kafka -> Flink -> 目标端
痛点: 组件多、链路长、维护成本高、数据在 Kafka 中冗余存储。
1.2 Flink CDC 方案:
MySQL -> Flink -> 目标端
优势:
- 架构极简: 只需要 Flink 一个组件。
- 全增量一体化: 自动先读历史数据(快照),读完后无缝切换到 Binlog(增量),保证数据不丢不重 (Exactly-Once)。
- 无锁读取: 使用增量快照算法,读取全量数据时不需要锁表。
1.3 核心应用场景
- 实时数据同步: 比如 MySQL -> Elasticsearch / ClickHouse。
- 实时 ETL: 数据库变更 -> Flink 清洗/聚合 -> 下游系统。
- 缓存更新(Cache Invalidation): 监听数据库变更,实时失效 Redis 缓存。
二、 环境准备:MySQL (Docker)
Flink CDC 依赖 MySQL 的 Binlog 获取增量数据。请确保你的 MySQL 配置文件 (my.cnf 或 my.ini) 包含以下配置,并重启 MySQL:
Ini,TOML
[mysqld]
server-id = 123 # 必须是唯一的整数
log_bin = mysql-bin # 开启 binlog
binlog_format = ROW # 必须是 ROW 模式
binlog_row_image = FULL # 必须是 FULL如果你使用 Docker,请使用以下命令快速启动一个满足要求的 MySQL 实例:
bash
docker run -d \
--name mysql-flink-cdc \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 \
mysql:8.0 \
--server-id=1 \
--log-bin=mysql-bin \
--binlog-format=ROW \
--gtid-mode=OFF核心配置解读:
binlog-format=ROW : 必须开启 ROW 模式,这样才能记录每一行数据的具体变更。
server-id : 在 MySQL 集群或主从复制中,每个节点的 ID 必须全局唯一。Flink CDC 也会伪装成一个 Slave,因此 MySQL 自身的 ID 不能为 0。
验证配置是否成功
sql
-- 查看 binlog 是否开启 (ON 表示开启)
SHOW VARIABLES LIKE 'log_bin';
-- 查看格式 (必须是 ROW)
SHOW VARIABLES LIKE 'binlog_format';
-- 查看镜像模式 (必须是 FULL)
SHOW VARIABLES LIKE 'binlog_row_image';
-- 查看节点的 ID (必须>0)
SHOW VARIABLES LIKE 'server_id';ps:从 MySQL 8.0 开始,官方默认开启了 Binlog,并将格式默认设为了 ROW,刚好完美契合 Flink CDC 的需求
三、 实战阶段 1:DataStream API ("Hello World")
这是最底层的 API,适合做数据清洗、复杂自定义逻辑或监控报警。
3.1 Maven 依赖 (🩸坑点 ①)
除了核心依赖外,必须显式引入 flink-connector-base,否则本地运行会报错。
yml
<dependencies>
<!-- Flink Streaming 核心 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.1</version>
</dependency>
<!-- Flink MySQL CDC 连接器 -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.4.1</version>
</dependency>
<!-- ⚠️ 坑点1:本地 IDEA 运行必须补全这个基础包,否则报 NoClassDefFoundError -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.17.1</version>
</dependency>
<!-- 开启 Web UI (可选,用于本地查看 Flink 仪表盘) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>1.17.1</version>
</dependency>
</dependencies>3.2 Java 代码实现
java
package com.jerry.flinkcdcdemo;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jerry.flinkcdcdemo.domain.Product;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
/***
* flink - cdc - mysql
* 使用 flink cdc DataStream
*
* 如果只是做清洗、过滤、简单报警: 使用 DataStream API 是最灵活、最高效的。
* 如果要做聚合统计 (Sum, GroupBy, Window): 强烈建议使用 Flink SQL / Table API。参照
*/
public class FlinkCdcDataStreamDemo {
public static void main(String[] args) throws Exception {
// 1. 环境准备 (带 Web UI)
Configuration conf = new Configuration();
conf.setInteger(RestOptions.PORT, 8801);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
// 为了方便本地观察,设置并行度为 1
env.setParallelism(1);
// 开启 Checkpoint (生产环境必须开启,用于故障恢复和保证 Exactly-Once)
// 每 3000ms 做一次 Checkpoint
env.enableCheckpointing(300000);
// 2. 配置 Source (为了数字显示正常,加上那个配置)
Map<String, Object> customConverterConfigs = new HashMap<>(); // ⚠️ 坑点3:配置 DECIMAL 格式化,防止金额变成 Base64 乱码
// key: "decimal.format" -> value: "NUMERIC" (转成普通数字) 或者 "STRING" (转成字符串)
customConverterConfigs.put("decimal.format", "NUMERIC");
// 3. 构建 MySQL CDC Source
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.serverTimeZone("UTC") // ⚠️ 坑点4:解决时区不一致导致的连接报错
.hostname("8.xx.xxx.xx") // 数据库地址 // ⚠️ 坑点2:务必使用真实 IP,不要无脑写 localhost
.port(3306) // 端口
.databaseList("flink_demo") // 监控的数据库
.tableList("flink_demo.products") // 监控的表 (库名.表名)
.username("root") // 用户名
.password("passward") // 替换为你的密码!!!
/**
* initial(): 第一次启动时,读取全量数据,然后切换到 Binlog。
* latest(): 只读取启动之后的新变更。
*/
.startupOptions(com.ververica.cdc.connectors.mysql.table.StartupOptions.initial())
.deserializer(new JsonDebeziumDeserializationSchema(false, customConverterConfigs)) // 将变更数据转为 JSON 字符串
.build();
// 4. 将 Source 添加到环境,生成 DataStream
DataStream<String> rawStream = env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL CDC Source");
// 4. Map: 解析 JSON 字符串 -> Product 对象
DataStream<Product> productStream = rawStream.map(new MapFunction<String, Product>() {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public Product map(String value) throws Exception {
JsonNode root = objectMapper.readTree(value);
// 获取操作类型: r=read, c=create, u=update, d=delete
String op = root.get("op").asText();
// 只有 insert(c), update(u), read(r) 会有 "after" 数据
// delete(d) 只有 "before" 数据
JsonNode dataNode = op.equals("d") ? root.get("before") : root.get("after");
if (dataNode == null || dataNode.isNull()) {
return null; // 异常情况保护
}
return new Product(
dataNode.get("id").asInt(),
dataNode.get("name").asText(),
dataNode.get("price").asDouble(),
op
);
}
}).filter(p -> p != null); // 过滤掉空数据
productStream.print(); // 3. 打印原始 JSON 字符串
// 5. KeyBy & Process: 按商品名分组,监控价格剧烈波动
productStream
.keyBy(p -> p.name) // 按商品名称分组
.process(new KeyedProcessFunction<String, Product, String>() {
// 这里可以定义状态 (State),比如保存上一次的价格
// ValueState<Double> lastPriceState;
@Override
public void processElement(Product current, Context ctx, Collector<String> out) throws Exception {
String op = current.op;
// 简单的业务逻辑演示
if ("r".equals(op) || "c".equals(op)) {
out.collect("【新上架/初始化】商品: " + current.name + ", 价格: " + current.price);
}
else if ("u".equals(op)) {
// 这里其实可以通过 Debezium 原始 JSON 的 "before" 字段拿到旧价格
// 但为了演示 API,我们假设这里做简单的阈值判断
if (current.price > 10000) {
out.collect("【 ⚠ 价格预警】商品 " + current.name + " 价格过高: " + current.price);
} else {
out.collect("【价格更新】商品 " + current.name + " 现价: " + current.price);
}
}
else if ("d".equals(op)) {
out.collect("【商品下架】商品: " + current.name);
}
}
})
.print(); // 6. 打印结果
// 6. 执行任务
env.execute("Flink CDC Simple Demo");
}
}🩸 DataStream API 踩坑复盘
- 报错
java.lang.NoClassDefFoundError: .../RecordEmitter
- 原因: 项目中缺少
flink-connector-base依赖。虽然flink-streaming-java包含了部分基础类,但FLIP-27 Source接口的实现位于connector-base中。- 报错
The MySQL server has a timezone offset ...
- 原因: MySQL 容器通常默认是 UTC 时区,而本地 Java 程序(如 Windows/Mac)默认取系统时区(如 Asia/Shanghai)。Flink CDC 对时间类型极其敏感,要求两端时区对齐。
- 解决: 代码中添加 .serverTimeZone("UTC")。
- 现象:价格字段显示为 "price": "CSdc" (乱码)
- 原因: 底层 Debezium 为了不丢失精度,默认将 DECIMAL 类型序列化为 Base64 编码的字符串。
- 解决: 自定义反序列化配置 decimal.format 为 NUMERIC。
⚠️ 额外提示:关于 Java 17 的潜在问题
我的运行环境是 JDK 17 (D:\JAVA\Java\openjdk-17.0.14\bin\java.exe)。
修复了上面的报错后,再次运行可能会遇到类似 InaccessibleObjectException 或 module java.base does not "opens java.util" to unnamed module 的错误。这是因为 Flink 在 Java 17 下运行时,需要开放一些模块权限。
如果修复依赖后遇到上述新报错,在 IDEA 的"运行配置 (Run Configuration)" -> "VM Options" 中加入以下参数:
Plaintext
--add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.net=ALL-UNNAMED --add-opens java.base/java.io=ALL-UNNAMED**建议:**最省事的方法是将项目 JDK 切换回 Java 8 (1.8) 或 Java 11,这两个版本对 Flink 1.17 的支持最丝滑,不需要加额外的 JVM 参数。
⚠️补充mysql建表语句:
sql
CREATE DATABASE flink_demo;
USE flink_demo;
CREATE TABLE products (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255),
price DECIMAL(10, 2),
description VARCHAR(255)
);
INSERT INTO products (name, price, description) VALUES ('iPhone 15', 5999.00, 'Apple Phone');⚠️初始化数据库后,启动flink程序:
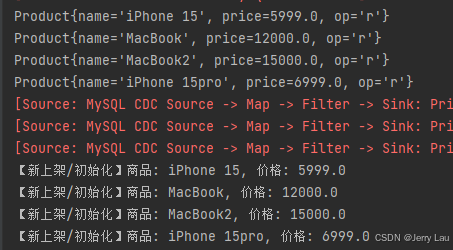
添加一条数据后,可以看到
sql
update products set price=5499 where id = 1;
op: 操作类型(r=快照读取, c=插入, u=更新, d=删除)
四、 实战阶段 2:Flink SQL API (进阶聚合)
如果你要做实时统计(例如:实时计算商品总价值、PV/UV),DataStream API 处理 CDC 的"撤回流"(Retract Stream)非常麻烦(需要手动处理 -U 减去旧值,+U 加上新值),而 Flink SQL 是处理 CDC 数据的终极武器。
4.1 Maven 依赖冲突 (🩸坑点 ⑤)
从 DataStream 切换到 SQL 开发时,最容易遇到 Ambiguous factory classes 错误。
冲突原因: flink-table-planner-loader 和 flink-table-planner_2.12 不能共存。前者是轻量级加载器,后者是完整的执行引擎。本地调试需要完整的引擎。
解决办法: 移除 loader 依赖,引入 planner 和 bridge。
yml
<!-- 必须引入 Bridge -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>1.17.1</version>
</dependency>
<!-- 必须引入完整的 Planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.17.1</version>
</dependency>
<!-- ❌ 务必移除或注释掉 flink-table-planner-loader -->4.2 SQL 逻辑实现
Flink SQL 会自动识别 CDC 数据的变更类型(Insert, Update, Delete),通过 -U/+U 机制自动维护聚合结果。
java
package com.jerry.flinkcdcdemo;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/***
* 基于 Flink SQL 的 CDC 示例
* 1. 从 MySQL 数据库读取增量数据
* 2. 打印到控制台
* 3. 执行 SQL 查询
* - 简单查询 (SELECT *)
* - 带过滤条件 (WHERE)
*/
public class FlinkSqlCdcDemo {
public static void main(String[] args) {
// 1. 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 创建 Table 环境 (Flink SQL 的入口)
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 2. 用 SQL 定义 Source 表 (DDL)
// 这相当于告诉 Flink:MySQL 里有一张表,长这样,请你去连接它
String createTableSql = "CREATE TABLE products_cdc (" + // ⚠️注意:这是逻辑映射,不是在 MySQL 创建物理表
" id INT PRIMARY KEY NOT ENFORCED," + // 必须声明主键 与 MySQL 中的主键保持一致
" name STRING," +
" price DECIMAL(10, 2)," +
" description STRING" +
") WITH (" +
" 'connector' = 'mysql-cdc'," + // 使用 MySQL CDC 连接器
" 'hostname' = '8.xx.xxx.xx'," +
" 'port' = '3306'," +
" 'username' = 'root'," +
" 'password' = 'passward'," + // 记得改密码
" 'database-name' = 'flink_demo'," + // <--- 这里指明了它实际上连的是 MySQL 的哪个库
" 'table-name' = 'products'," + // <--- 这里指明了它实际上连的是 MySQL 的哪个表
" 'server-time-zone' = 'UTC'" + // 解决时区报错的关键
")";
// 执行建表语句 (注册元数据,还不会真正运行)
tableEnv.executeSql(createTableSql);
// ==========================================
// 玩法 1:简单查询 (相当于 SELECT * FROM)
// ==========================================
// tableEnv.executeSql("SELECT * FROM products_cdc").print();
// ==========================================
// 玩法 2:带过滤的查询
// ==========================================
// tableEnv.executeSql("SELECT id, name, price FROM products_cdc WHERE price > 5000").print();
// ==========================================
// 玩法 3:实时聚合 (这是 DataStream 最难做,但 SQL 最简单的)
// 需求:实时计算所有商品的总价值,以及最贵的商品价格是多少
// ==========================================
String aggSql = "SELECT " +
" COUNT(*) as product_count, " +
" SUM(price) as total_value, " +
" MAX(price) as max_price " +
"FROM products_cdc";
System.out.println("开始执行实时聚合 SQL...");
tableEnv.executeSql(aggSql).print();
}
}🩸 Flink SQL 核心概念辨析 (小白误区)
Q1:"为什么我 executeSql 了,数据库里没看到表?"
- 误区: 认为 Flink 的 CREATE TABLE 等同于 MySQL 的 DDL。
- 正解:
Flink中的CREATE TABLE只是在内存中注册了一个逻辑映射关系,告诉 Flink 引擎:"当你查 products_cdc 时,请去连接 MySQL 的 products 表读取 Binlog"。它不会在 MySQL 中创建任何物理文件。
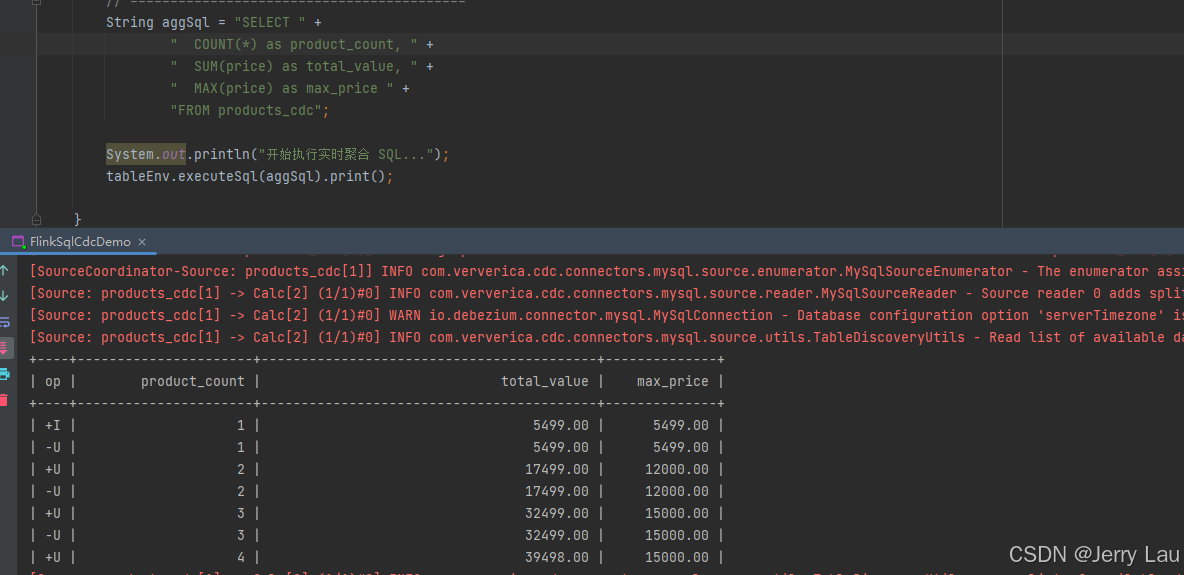
Q2:"为什么控制台打印的结果和数据库查出来的不一样?"
- 现象: Flink 控制台会疯狂打印 +I, -U, +U 的数据流,看起来很乱。
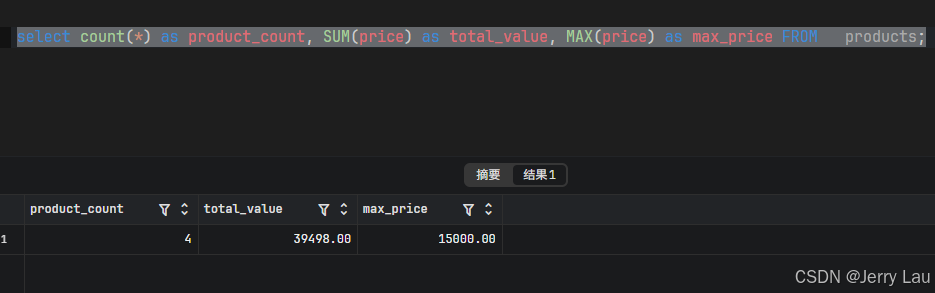
- 正解:数据库展示的是静态快照 (Snapshot)------即"比赛结束时的比分"。
- Flink 展示的是动态流 (Changelog Stream)------即"整场比赛的进球记录"。
- 仔细观察 Flink 日志中最新的一条 +U (Update After) 数据,你会发现它的数值与数据库当前查询的结果是完全一致的。
现象: Flink 控制台会疯狂打印 +I, -U, +U 的数据流,看起来很乱。
那对于Q2,我来个比较通俗的解释
数据库 (Static View)
你在数据库里执行 SELECT 时,数据库给你的是**"此时此刻"**的快照。它不会告诉你"刚才这个总数是 12000,后来变成了 27000,最后变成了 39998"。它直接把最终结果甩给你。
Flink SQL (Dynamic Stream)Flink 是流式计算,它给你展示的是一部 "记账电影"。
请看你截图中的日志流:| +I | 1 | ...: 刚开始,Flink 读到了第 1 条数据,算出总价是 6999。
| -U | 1 | ... & | +U | 2 | ...: 紧接着,Flink 发现数据变了(或者读到了第 2 条数据),它先把旧的结果(6999)撤回(-U),然后输出新的累加结果(12998)。
... (中间经过多次计算) ...
| +U | 4 | 39998.00 | ...: 这就是最终态! 当所有数据都处理完,或者没有新变动时,这就是当前的结果。
比喻:数据库 像是比分牌,你抬头看一眼,现在的比分是 4:0。
Flink 像是现场解说员,他会告诉你:"刚才进了第 1 个球... 哎呀现在进了第 2 个... 现在是第 3 个... 好的比赛结束,最终 4:0"。
五、 总结
搭建一个 Production-Ready 的 Flink CDC 应用,代码量其实很少,但环境配置和依赖管理才是最大的拦路虎。
Checklist:
- Dependencies: 确保 planner 不冲突,connector-base 不缺失。
- Config: MySQL Binlog
- 格式为 ROW,时区设置为 UTC,Decimal 格式化要处理。
- Network: Docker 环境下分清 localhost
- 和真实宿主机 IP,防止 Connection Refused。
- Concept: 理解 Flink SQL 的逻辑表映射和动态表(Dynamic Table)的撤回机制。
掌握了这些,你就掌握了构建实时数仓的第一把钥匙!🚀