🫧个人主页:小年糕是糕手
🎨你不能左右天气,但你可以改变心情;你不能改变过去,但你可以决定未来!

目录
[3.2、断言 / 抛异常](#3.2、断言 / 抛异常)
[3.4、遍历 / 修改](#3.4、遍历 / 修改)
一、STL简介
1.1、什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的 组件库,而且是一个包罗数据结构与算法的软件框架。
1.2、STL的版本
原始版本Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。HP 版本 -- 所有 STL 实现版本的始祖。
P.J. 版本由 P.J. Plauger 开发,继承自 HP 版本,被 Windows Visual C++ 采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
RW 版本由 Rouge Wage 公司开发,继承自 HP 版本,被 C++ Builder 采用,不能公开或修改,可读性一般。
SGI 版本由 Silicon Graphics Computer Systems, Inc 公司开发,继承自 HP 版本。被 GCC (Linux) 采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程风格上看,阅读性非常高。我们后面学习 STL 要阅读部分源代码,主要参考的就是这个版本。
1.3、STL的六大组件
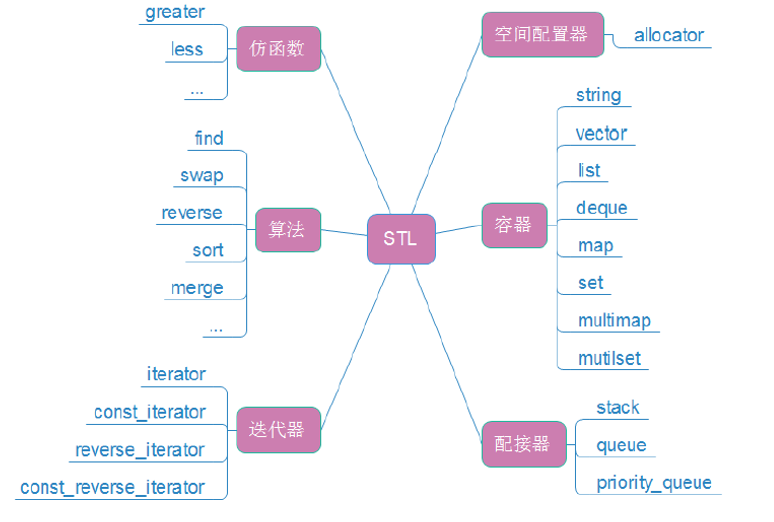
大家先简单了解一下即可,后面会为大家分开细致讲解!
二、编码
大家有没有思考过一个问题,我们经常会用sizeof去计算一个字符 / 字符串所占的字节数,但是大家有没有想过一个汉字所占的字节数是多少?他又是怎么算的?
这时候我们就不得不提到另一个话题 -- 编码
2.1、不同的编码方式
关于汉字所占的字节数,答案取决于具体的编码方式,不同编码下字节数不同。以下是常见情况的总结:
1. UTF-8 编码
大多数汉字占 3 个字节(常用汉字范围:U+4E00到U+9FFF)。
扩展的罕见汉字、繁体字或历史用字可能占 4 个字节(如部分CJK扩展区的汉字)。
2. GBK / GB2312 编码(常见于中文Windows系统)
- 每个汉字固定占 2 个字节。
3. UTF-16 编码
基本多文种平面(BMP)的汉字占 2 个字节(如常用汉字)。
扩展平面(如表情符号、罕见字)占 4 个字节(代理对形式)。
4. UTF-32 编码
- 每个字符固定占 4 个字节。
5. ASCII 编码
- 仅支持英文字符,无法表示汉字。
简单总结:
| 编码方式 | 汉字字节数(常见情况) | 备注 |
|---|---|---|
| UTF-8 | 3字节 | 现代Web和Linux系统主流 |
| GBK | 2字节 | 旧版Windows中文环境常用 |
| UTF-16 | 2字节(基本汉字) | Java内部内存表示、Windows API |
| UTF-32 | 4字节 | 固定长度,较少直接使用 |
2.2、GBK
我们常见的就是GBK,他一个汉字所占的字节数就是2,下面我们用代码来验证一下:
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
char buff1[] = "abcA";
buff1[0]++;
char buff2[] = "字节";
//GBK下一个汉字占俩个字节,字符串末尾有个\0,所以是五个字节
//CBK也兼容ASCII
cout << sizeof(buff2) << endl;
cout << buff2 << endl;
buff2[1]++;
cout << buff2 << endl;
buff2[1]++;
cout << buff2 << endl;
buff2[3]--;
cout << buff2 << endl;
buff2[3]--;
cout << buff2 << endl;
return 0;
}我们运行这段代码:
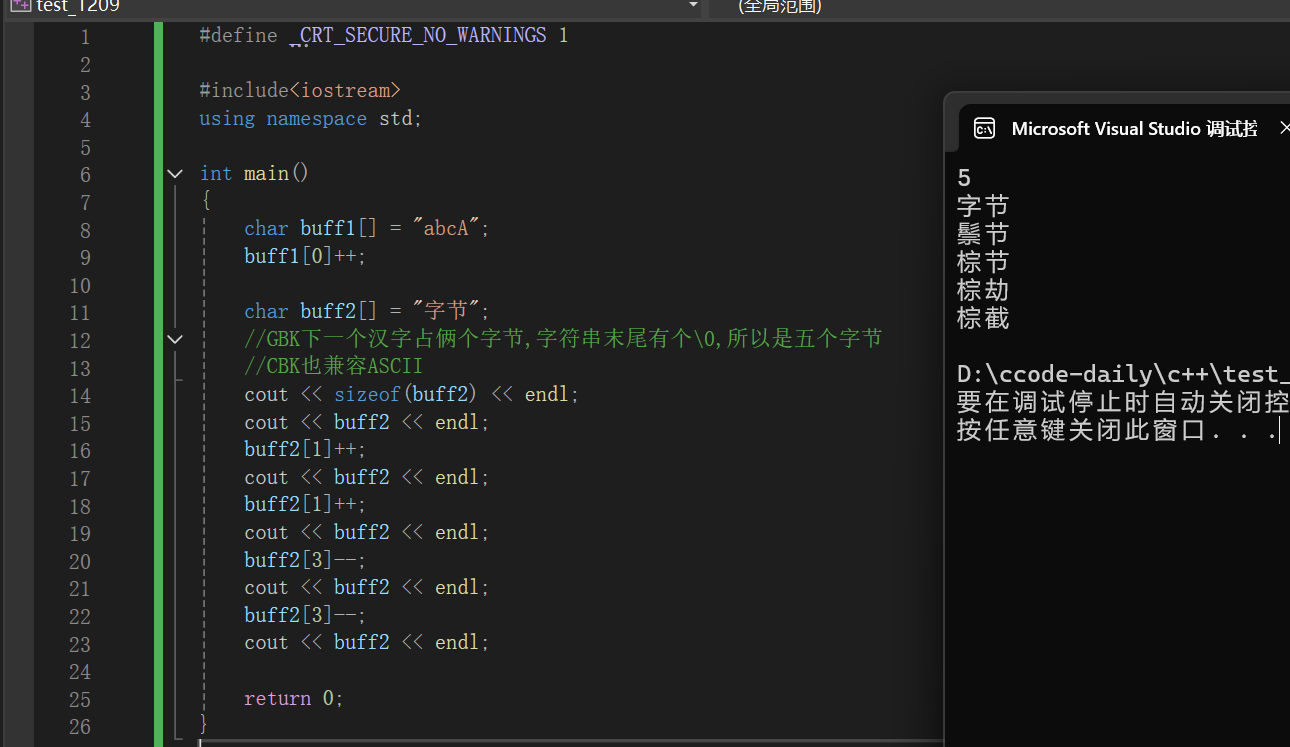
在GBK下我们不但看出来了一个汉字占2个字节数我们还能发现一般谐音的汉字都是放到一块的,这也是我"净网行动"的依据,公司会将不文明的字找出来,同音字编码连续或相近,有利于批量生成谐音黑名单(比如一个脏字的拼音对应一片编码区域),规划了网络文明用语。
三、初识string类
3.1、初始化
我们首先来看string类的初始化操作:
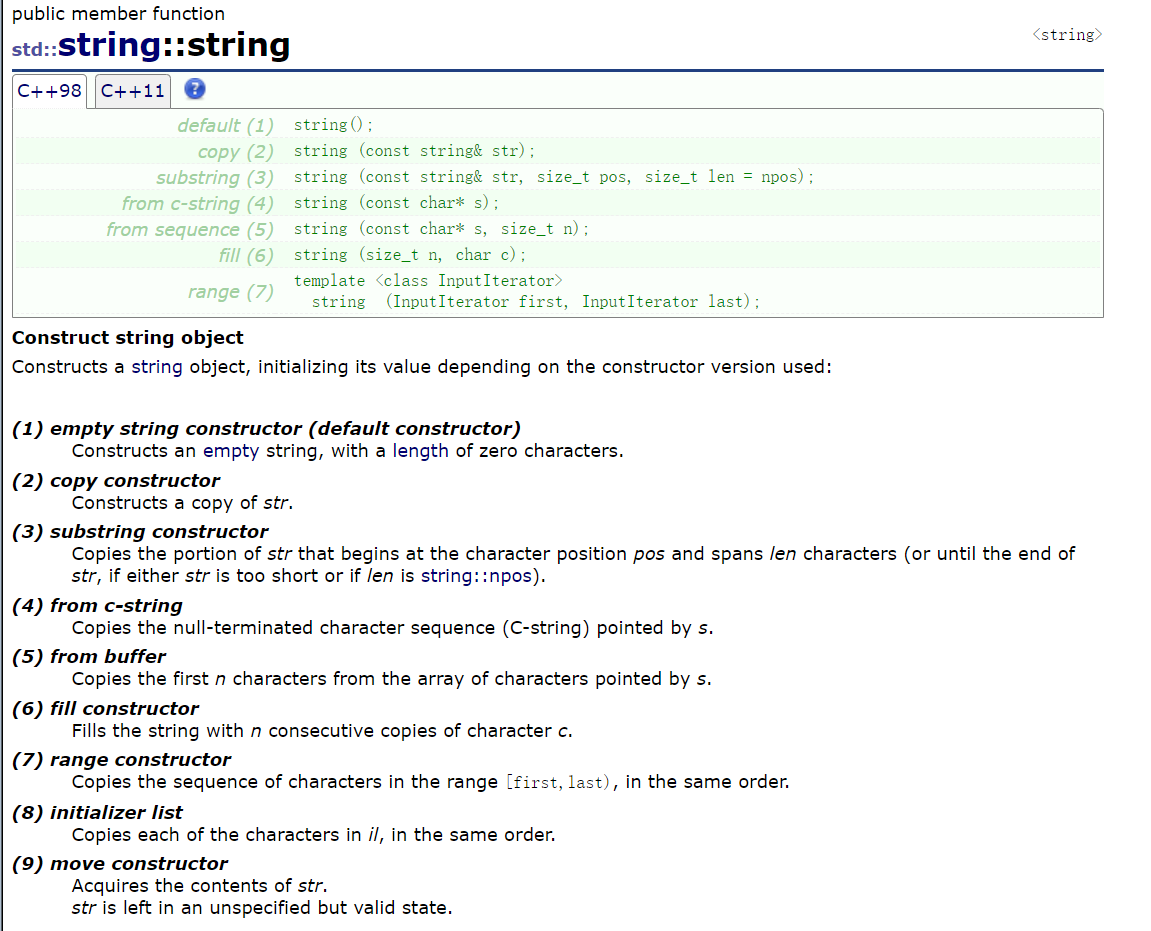
光看文献肯定会有点晦涩,但是我们要习惯于去自己查阅这些资料,这有助于我们的学习,同时也有助于我们提高自己的英文水平,下面我们来看代码解释:
cpp
#include<iostream>
#include<string>//string
#include<algorithm>//算法头文件
#include<list>//链表头文件
using namespace std;
//part2:
//初始化
void test_string1()
{
string s1;//默认构造
string s2("hello world");//使用常量字符串数组来构造
string s3(s2);
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
//从0位置开始取,取五个
string s4(s2, 0, 5);
cout << s4 << endl;
//从第五个位置开始取,超过的也不会报错,取完为止
string s6(s2, 5, 15);
//从第六个位置开始一直取到结束
string s7(s2, 6);
//这里有个字符串,我想取前六个
string s8("hello world", 6);
//想用10个*来初始化
string s9(10, '*');
//赋值
s8 = "xxxx";
cout << s8 << endl;
}3.2、断言 / 抛异常
这时候我们就要再来看一下他内部的断言 / 抛异常:

这个我们结合下文的遍历 / 修改一起演示
3.3、内部逻辑
cpp
//string内部逻辑
class string
{
public:
//引用返回,可以修改返回对象
char& operator[](size_t pos)
{
//返回的是对应字符的别名
return _str[pos];
}
private:
char* _str;
size_t size;
size_t capacity;
};3.4、遍历 / 修改
这里我们需要学习string内部的一个运算符重载:
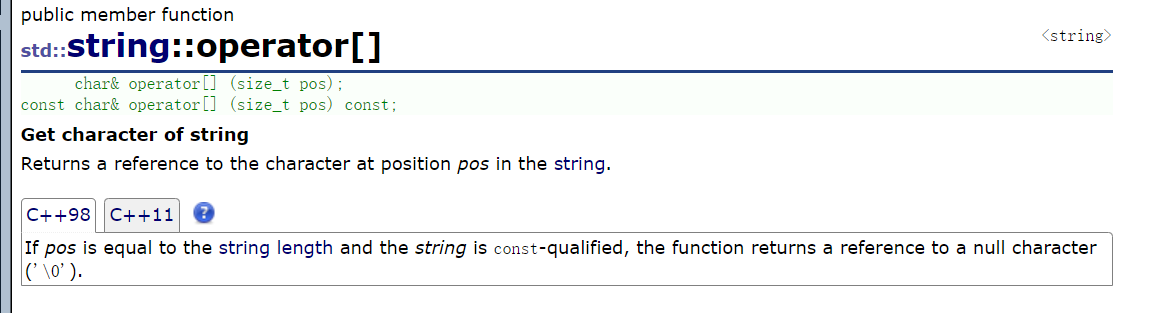
代码如下(注意结合注释):
cpp
void test_string2()
{
//运算符重载operator[]
string s1("hello world");
//我想去修改他第0个位置的字符
s1[0] = 'x';
//可以理解为让他变成了数组
//他的底层返回的是原字符的引用,这里是'h'
cout << s1 << endl;
cout << s1[0] << endl;
}我们可以加上断言 / 抛异常来完善这段代码:
cpp
#include<iostream>
#include<string>//string
#include<algorithm>//算法头文件
#include<list>//链表头文件
using namespace std;
void test_string2()
{
//运算符重载operator[]
string s1("hello world");
//我想去修改他第0个位置的字符
s1[0] = 'x';
//可以理解为让他变成了数组
//他的底层返回的是原字符的引用,这里是'h'
cout << s1 << endl;
cout << s1[0] << endl;
//C++中数组越界有严格的断言检查
//这里越界读和写都会报错
s1[12];//断言
//如果你嫌断言太激烈了,可以用at
s1.at(12);//越界,at会抛异常,抛异常是可以捕获的
//他们计算出的结果都是s1的长度(都是不包含\0)
//这里的\0被认为是标识字符,并不是有效字符
cout << s1.size() << endl;// 推荐
cout << s1.length() << endl;
//遍历 or 修改
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++;
}
cout << s1 << endl;
}
int main()
{
//test_string1();
try
{
test_string2();
}
catch (const exception& e)
{
cout << e.what() << endl;
}
return 0;
}当我们简单学习string类后我们来了解另一个"杀器" --迭代器
四、迭代器
我们要知道俩点:迭代器就是行为像指针一样的东西,他在所有容器都是通用的
4.1、初识迭代器
我们结合上述string类遍历 / 修改的例子来进一步认识一下迭代器:
cpp
void test_string2()
{
//运算符重载operator[]
string s1("hello world");
//我想去修改他第0个位置的字符
s1[0] = 'x';
//可以理解为让他变成了数组
//他的底层返回的是原字符的引用,这里是'h'
cout << s1 << endl;
cout << s1[0] << endl;
//C++中数组越界有严格的断言检查
//这里越界读和写都会报错
s1[12];//断言
//如果你嫌断言太激烈了,可以用at
s1.at(12);//越界,at会抛异常,抛异常是可以捕获的
//他们计算出的结果都是s1的长度(都是不包含\0)
//这里的\0被认为是标识字符,并不是有效字符
cout << s1.size() << endl;// 推荐
cout << s1.length() << endl;
//遍历 or 修改
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++;
}
cout << s1 << endl;
//迭代器 -- 所有容器都是通用的
//行为像指针一样的东西
string::iterator it1 = s1.begin();//指向的是字符串的第一个位置的字符
while (it1 != s1.end())//这里的end指向的是\0(标识字符)
{
//迭代器的使用,使用解引用
(*it1)--; //修改
cout << *it1 << " " << endl;
++it1; //指向迭代器下一个位置
}
cout << endl;
}这时候肯定有人就会吐槽我们老老实实使用数组 + 形式不就好了,搞这个迭代器意义是什么,我们一般情况下是可以使用数组来解决,但是我们如果要使用链表,数组 + 的形式就行不通了,这时候我们的迭代器就可以帮助我们很快的解决问题,大家要明白:每一个语法设计出来肯定都有它的意义,我们是站在先辈的肩膀上去前行的,当然先辈设计的东西有时候肯定也会存在缺陷,这就需要我们后辈不断地学习,去发现完善!
4.2、迭代器的优势
迭代器的优势体现在在链表等没有\[\]的数据中也可以遍历
cpp
//迭代器的优势体现在在链表等没有[]的数据中也可以遍历
void test()
{
string s1("hello world");
list<int> lt;
//在一个链表中插入1 2 3
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
list<int>::iterator lit = lt.begin();
while (lit != lt.end())
{
//迭代器的使用,使用解引用
(*lit)--; //修改
cout << *lit << " ";
++lit; //指向迭代器下一个位置
}
cout << endl;
}4.3、const迭代器
cpp
//只读不写记得加上const
//const迭代器
//const对象不是使用const iterator去遍历
//因为这里的const修饰的是迭代器本身,不能++,完成不了遍历
void Print(const string& s)
{
//const string::iterator it1 = s.begin();
string::const_iterator it1 = s.begin();
while (it1 != s.end())
{
//(*it1)--; //这里是const迭代器不能修改
cout << *it1 << endl;
++it1;
}
cout << endl;
}在 C++ 中,迭代器的 "const" 修饰分为两种情况:
const 容器::iterator:修饰的是迭代器本身 (迭代器这个变量不能被修改),但迭代器指向的内容可以修改;容器::const_iterator:修饰的是迭代器指向的内容 (内容不能被修改),但迭代器本身可以修改。
4.4、反向迭代器
cpp
void Print(const string& s)
{
//const string::iterator it1 = s.begin();
string::const_iterator it1 = s.begin();
while (it1 != s.end())
{
//(*it1)--; //这里是const迭代器不能修改
cout << *it1 << endl;
++it1;
}
cout << endl;
//反向迭代器 -- 倒着遍历
//rbegin指向的是尾部的数据,rend是第一个数据的前一个数据
//假设有hello world\0,rbegin指向的是d,rend指向的是h的前一个位置
string::const_reverse_iterator it2 = s.rbegin();
while (it2 != s.rend())
{
//*it2 = 'x' //不能修改
cout << *it2 << endl;
++it2;
}
cout << endl;
}4.5、总结
迭代器
1、提供统一的方式遍历修改容器
2、算法可以泛型化,借助迭代器处理容器的数据
五、算法find
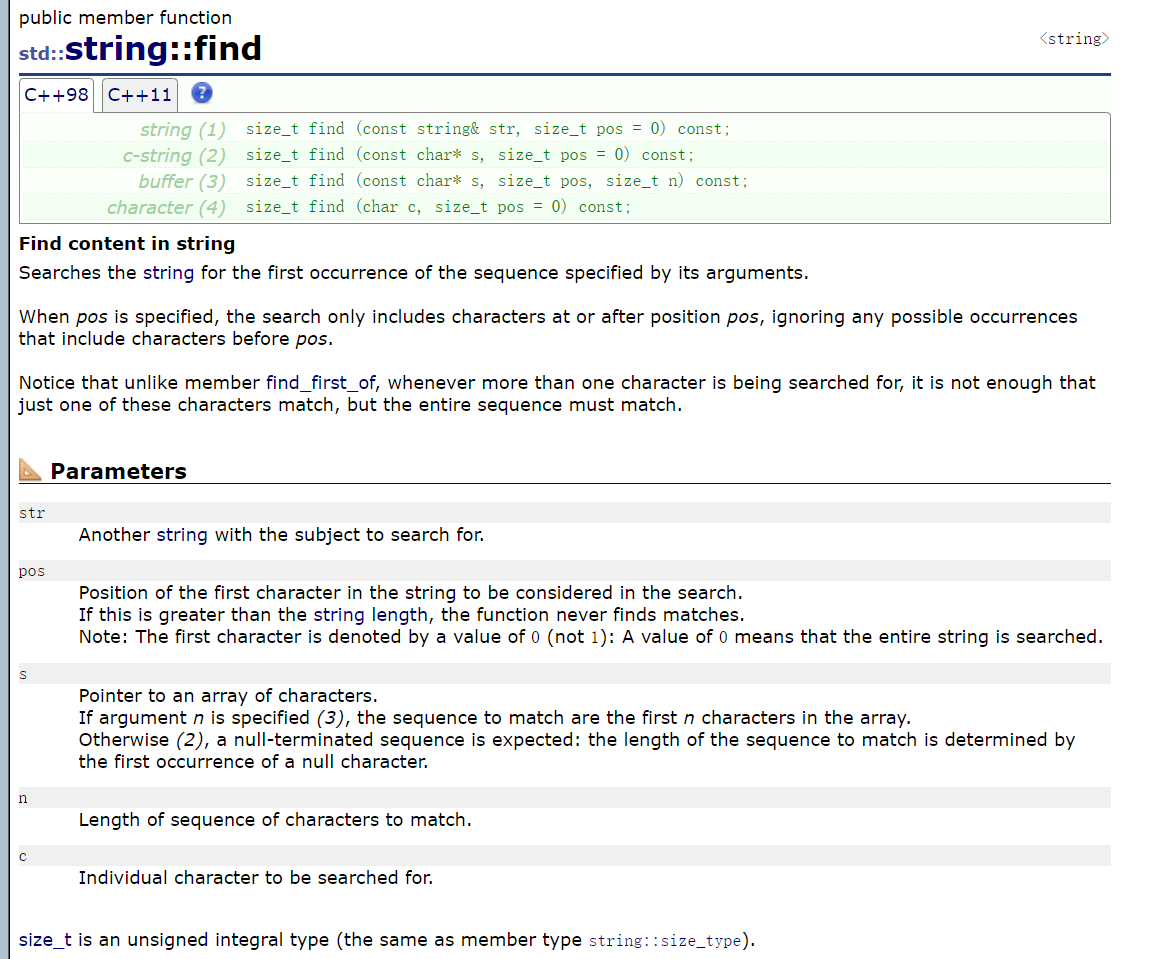
这里我们就简单的举个例子给大家看看就好了,最主要的还是自己去写代码实践:
cpp
#include<iostream>
#include<string>//string
#include<algorithm>//算法头文件
#include<list>//链表头文件
using namespace std;
//迭代器的优势体现在在链表等没有[]的数据中也可以遍历
void test()
{
string s1("hello world");
list<int> lt;
//在一个链表中插入1 2 3
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
list<int>::iterator lit = lt.begin();
while (lit != lt.end())
{
//迭代器的使用,使用解引用
(*lit)--; //修改
cout << *lit << " " << endl;
++lit; //指向迭代器下一个位置
}
cout << endl;
//算法find(查找)
//我们要查找一个字符串中是否有一个'x',可以采用迭代器 + 算法
string::iterator ret1 = find(s1.begin(), s1.end(), 'x');
if (ret1 != s1.end())
{
cout << "找到了x" << endl;
}
//查找链表中是否有对应字符
list<int>::iterator ret2 = find(lt.begin(), lt.end(), 'x');
if (ret2 != lt.end())
{
cout << "找到了x" << endl;
}
}记住在算法里面的迭代器区间一定是左闭右开
六、auto
6.1、初识auto
auto:通过初始化值类型自动推导对象类型,C++11中提供的语法
cpp
int i = 0;
//通过初始化类型自动推导对象类型
auto j = i;
auto k = 10;一般情况下我们发现确实没必须使用auto,还麻烦,但是当我们结合迭代器就会发现他的便捷之处
6.2、迭代器中的auto
下面我们直接通过代码来演示(注意看注释):
cpp
void Test()
{
string s1("hello world");
list<int> lt;
//在一个链表中插入1 2 3
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
string::iterator lt1 = s1.begin();
while (lt1 != s1.end())
{
//迭代器的使用,使用解引用
(*lt1)--; //修改
cout << *lt1 << " " << endl;
++lt1; //指向迭代器下一个位置
}
cout << endl;
//我们要查找一个字符串中是否有一个'x',可以采用迭代器 + 算法
//当我们用表达式来初始化时候就可以使用auto,但是一定程度上降低了代码的可读性
auto ret1 = find(s1.begin(), s1.end(), 'x');
if (ret1 != s1.end())
{
cout << "找到了x" << endl;
}
//查找链表中是否有对应字符
auto ret2 = find(lt.begin(), lt.end(), 'x');
if (ret2 != lt.end())
{
cout << "找到了x" << endl;
}
int i = 0;
//通过初始化类型自动推导对象类型
auto j = i;
auto k = 10;
//p1和p2均是指针
//下面俩种写法的区别是:
auto p1 = &i;//这里右边可以传指针,也可以不传指针
auto* p2 = &i;//这里必须传指针
cout << p1 << endl;
cout << p2 << endl;
//引用
int& r1 = i;
auto r2 = r1;//这里推导不出来引用,r1实际上是i的别名,推导出来的r2是int类型
auto& r3 = r1;//这里r3就是引用
}auto的一大价值之一就是当我们通过很复杂的表达式去初始化时就可以使用auto,同时我们要注意auto当指针类型时的写法
七、范围for
7.1、概述范围for
范围for:是C++11中提出来的一种新语法,能简洁地遍历容器(如数组、string、vector 等)中的所有元素,无需手动管理下标或迭代器。
cpp
void Test()
{
string s1("hello world");
list<int> lt;
//在一个链表中插入1 2 3
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
string::iterator lt1 = s1.begin();
while (lt1 != s1.end())
{
//迭代器的使用,使用解引用
(*lt1)--; //修改
cout << *lt1 << " " << endl;
++lt1; //指向迭代器下一个位置
}
cout << endl;
//我们要查找一个字符串中是否有一个'x',可以采用迭代器 + 算法
//当我们用表达式来初始化时候就可以使用auto,但是一定程度上降低了代码的可读性
auto ret1 = find(s1.begin(), s1.end(), 'x');
if (ret1 != s1.end())
{
cout << "找到了x" << endl;
}
//查找链表中是否有对应字符
auto ret2 = find(lt.begin(), lt.end(), 'x');
if (ret2 != lt.end())
{
cout << "找到了x" << endl;
}
int i = 0;
//通过初始化类型自动推导对象类型
auto j = i;
auto k = 10;
//p1和p2均是指针
//下面俩种写法的区别是:
auto p1 = &i;//这里右边可以传指针,也可以不传指针
auto* p2 = &i;//这里必须传指针
cout << p1 << endl;
cout << p2 << endl;
//引用
int& r1 = i;
auto r2 = r1;//这里推导不出来引用,r1实际上是i的别名,推导出来的r2是int类型
auto& r3 = r1;//这里r3就是引用
//C++11
//范围for
//自动取容器中的数据赋值给对象(s1 -> exo_m / exo_k)
//自动++、自动判断结束
for (auto exo_m : s1)
{
cout << exo_m << ' ';
}
cout << endl;
for (auto exo_k : lt)
{
cout << exo_k << ' ';
}
cout << endl;
}现在我们就有三种方式去遍历我们的链表、遍历我们的string
1、下标 +
2、迭代器
3、范围for
7.2、范围for中的修改

记住如果我们不需要去修改最好加上const
支持迭代器的容器,都可以用范围for
数组也支持(特殊处理)
cpp
#include<iostream>
using namespace std;
int main()
{
int a[10] = { 1,2,3 };
for (auto exo : a)
{
cout << exo << " ";
}
cout << endl;
}