
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [1 ~> 使用库:标准库和第三方库](#1 ~> 使用库:标准库和第三方库)
- [2 ~> 标准库](#2 ~> 标准库)
-
- [2.1 认识标准库](#2.1 认识标准库)
-
- [2.1.1 理论](#2.1.1 理论)
- [2.2 使用 import 导入模块](#2.2 使用 import 导入模块)
-
- [2.2.1 理论](#2.2.1 理论)
- [2.2.2 最佳实践](#2.2.2 最佳实践)
- [2.3 代码示例:日期计算](#2.3 代码示例:日期计算)
-
- [2.3.1 理论](#2.3.1 理论)
- [2.3.2 最佳实践](#2.3.2 最佳实践)
- [2.3.3 英文文档看不懂的问题](#2.3.3 英文文档看不懂的问题)
- [2.4 代码示例:字符串操作](#2.4 代码示例:字符串操作)
-
- [2.4.1 剑指offer 58:翻转单词顺序](#2.4.1 剑指offer 58:翻转单词顺序)
-
- [2.4.1.1 理论](#2.4.1.1 理论)
- [2.4.1.2 答案参考](#2.4.1.2 答案参考)
- [2.4.1.3 最佳实践](#2.4.1.3 最佳实践)
- [2.4.2 leetcode 796:旋转字符串](#2.4.2 leetcode 796:旋转字符串)
-
- [2.4.2.1 理论](#2.4.2.1 理论)
- [2.4.2.2 参考答案](#2.4.2.2 参考答案)
- [2.4.2.3 最佳实践](#2.4.2.3 最佳实践)
- [2.4.3 leetcode 2255:统计是给定字符串前缀的字符串数目](#2.4.3 leetcode 2255:统计是给定字符串前缀的字符串数目)
-
- [2.4.3.1 理论](#2.4.3.1 理论)
- [2.4.3.2 参考答案](#2.4.3.2 参考答案)
- [2.4.3.3 最佳实践](#2.4.3.3 最佳实践)
- [2.4.4 其它字符串操作](#2.4.4 其它字符串操作)
- [2.5 代码示例:文件查找工具](#2.5 代码示例:文件查找工具)
-
- [2.5.1 理论](#2.5.1 理论)
- [2.5.2 最佳实践](#2.5.2 最佳实践)
- [2.5.3 其它os模块操作](#2.5.3 其它os模块操作)
- [3 ~> 第三方库](#3 ~> 第三方库)
-
- [3.1 认识第三方库](#3.1 认识第三方库)
- [3.2 使用pip](#3.2 使用pip)
-
- [3.2.1 理论](#3.2.1 理论)
- [3.2.2 最佳实践](#3.2.2 最佳实践)
- [3.3 代码示例:生成二维码](#3.3 代码示例:生成二维码)
-
- [3.3.1 通过搜索引擎,确定使用哪个库](#3.3.1 通过搜索引擎,确定使用哪个库)
- [3.3.2 查看 qrcode 文档](#3.3.2 查看 qrcode 文档)
- [3.3.3 使用 pip 安装](#3.3.3 使用 pip 安装)
- [3.3.4 编写代码](#3.3.4 编写代码)
- [3.3.5 最佳实践](#3.3.5 最佳实践)
- [3.4 代码示例:操作 excel](#3.4 代码示例:操作 excel)
-
- [3.4.1 理论](#3.4.1 理论)
- [3.4.2 需求](#3.4.2 需求)
- [3.4.3 操作](#3.4.3 操作)
-
- [3.4.3.1 安装 xlrd](#3.4.3.1 安装 xlrd)
- [3.4.3.2 编写代码](#3.4.3.2 编写代码)
- [3.4.4 最佳实践](#3.4.4 最佳实践)
- 结尾

1 ~> 使用库:标准库和第三方库
库就是是别人已经写好了的代码,可以让我们直接拿来用。
荀子曰:"君子性非异也,善假于物也"。
一个编程语言能不能流行起来,一方面取决于语法是否简单方便容易学习,一方面取决于生态是否完备。
所谓的"生态"指的就是语言是否有足够丰富的库,来应对各种各样的场景。
实际开发中,也并非所有的代码都自己手写,而是要充分利用现成的库,简化开发过程。
按照库的来源,可以大致分成两大类------
-
标准库:Python自带的库.只要安装了Python就可以直接使用。
-
第三方库:其他人实现的库,要想使用,需要额外安装。
咱们自己也可以实现
"第三方库"发布出去,交给别人来使用。

来源,可以大致分成以上两大类。
2 ~> 标准库
2.1 认识标准库
2.1.1 理论
Python 自身内置了非常丰富的库,在Python官方文档上可以看到这些库的内容:Python 官方文档
简单来说, 主要是这些部分:
- 内置函数 (如 print, input 等)
-内置类型 (针对 int, str, bool, list, dict 等类型内置的操作). - 文本处理
- 时间日期
- 数学计算
- 文件目录
- 数据存储 (操作数据库, 数据序列化等)
- 加密解密
- 操作系统相关
- 并发编程相关 (多进程, 多线程, 协程, 异步等).
- 网络编程相关
- 多媒体相关 (音频处理, 视频处理等)
- 图形化界面相关
- ...
我们不需要把这些库的内容都背下来,只要大概知道里面有啥,需要用的时候能够找到即可。
2.2 使用 import 导入模块
2.2.1 理论
使用import可以导入标准库的一个 模块。
python
import [模块名]所谓"模块",其实就是一个单独的.py文件。
使用import语句可以把这个外部的.py文件导入到当前.py文件中,并执行其中的代码。
2.2.2 最佳实践
最佳实践等到后面我们使用起来就知道啦。
2.3 代码示例:日期计算
2.3.1 理论
输入任意的两个日期,计算两个日期之间隔了多少天。
- 使用
import语句导入标准库的datetime模块。 - 使用
datetime.datetime构造两个日期,参数使用年 / 月 / 日这样的格式。 - 两个日期对象相减,即可得到日期的差值。
python
import datetime
date1 = datetime.datetime(2012, 2, 14)
date2 = datetime.datetime(2022, 7, 12)
print(date2 - date1)
嘻嘻,快来看一下你和心爱的人已经认识了多少天了!
关于datetime的更多操作,可以参考官方文档:datetime
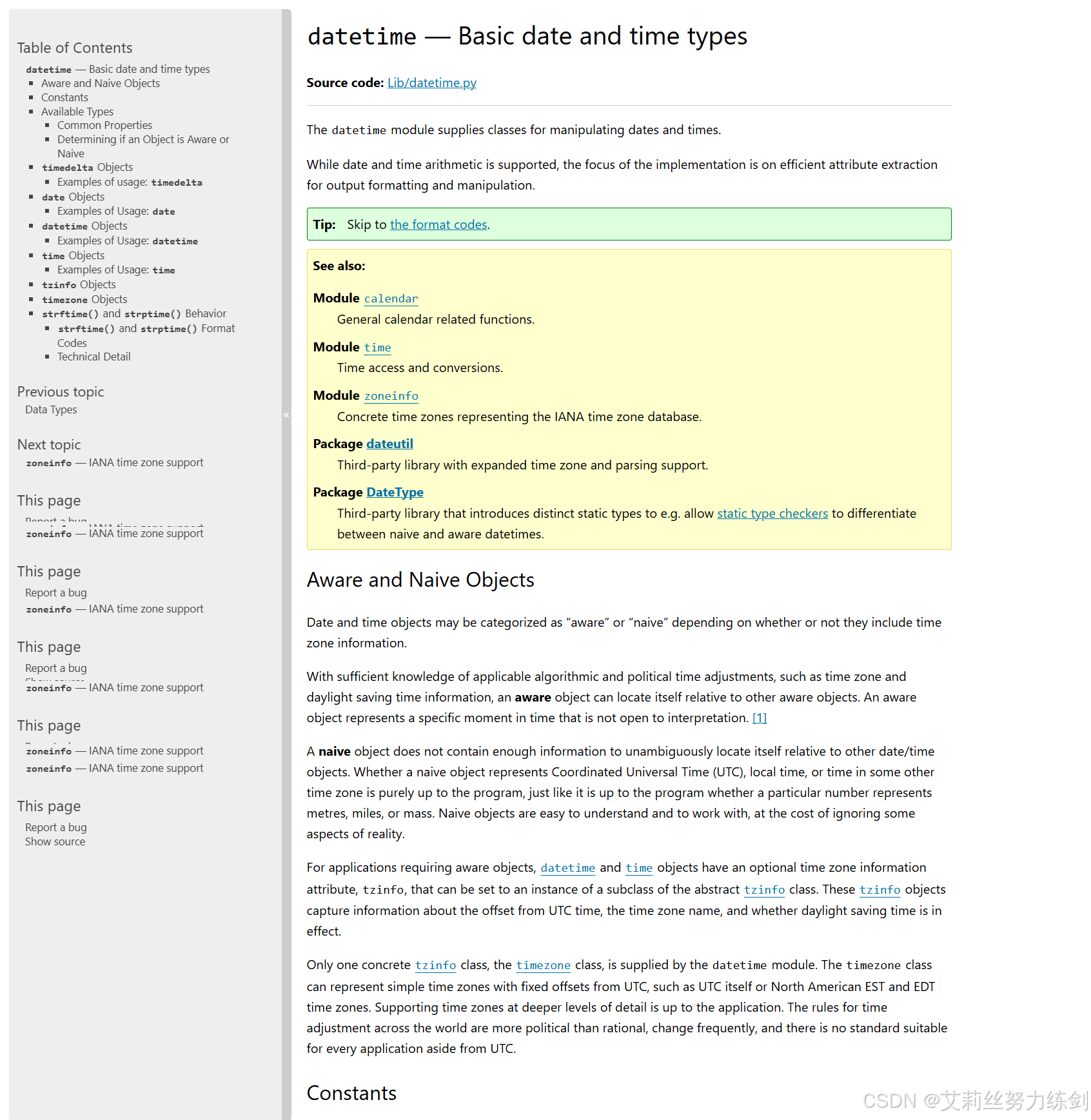
2.3.2 最佳实践
python
# 代码案例:日期计算器(日期之间作差)
# datetime
# import datetime # (import)导入对应的模块
# # 先构造 datetime 变量
#
# # datetime.datetime(模块名.类型名)
# date1 = datetime.datetime(2006,12,14)
# date2 = datetime.datetime(2025,12,14)
# # 也可以通过关键字参数传
# # date1 = datetime.datetime(year=2025,month=12,day=14) # 更加直观
# print(date2 - date1) # 两种相减可得出相差多久
# # 这样写还有点别扭,我们可以直接这样写
# from datetime import datetime # 变成从datetime模块import一个datetime类型
# # 通过这样的改变,让我们后续无需再写[datetime.] --> [模块名.]的方式------改进的写法
#
# # 先构造 datetime 变量
# date1 = datetime(2006,12,14)
# date2 = datetime(2025,12,14)
# print(date2 - date1) # 结果完全一样
# 还有一种写法:既能在这行代码中知道模块名是什么,也能体现出后续构造的对象是什么类型
# 比较直观
import datetime as dt # 还是datetime模块导入,但是给datetime取了一个别名dt,通过dt代表了datetime
# 通过这样的改变,让我们后续无需再写[datetime.] --> [模块名.]的方式------改进的写法
# 先构造 datetime 变量
date1 = dt.datetime(2006,12,14)
date2 = dt.datetime(2025,12,14)
print(date2 - date1) # 结果完全一样
# 判断星期几、格式化硬件打印时间戳......2.3.3 英文文档看不懂的问题
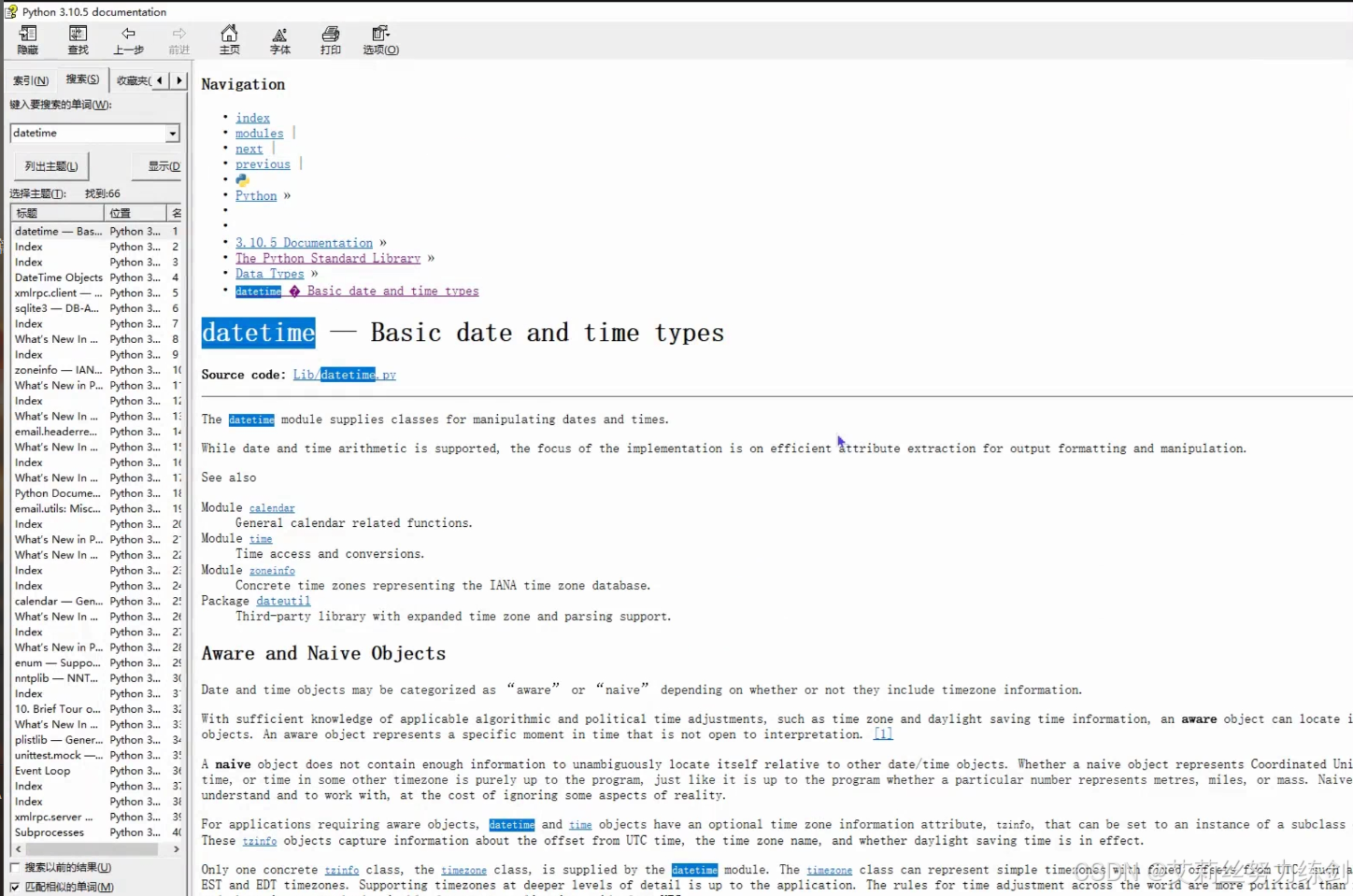
像上面这样,Python文档是国外的网站,搜索起来太慢了,等不及怎么办?
这样虽然也能找到,但是搜索不方便,而且太慢了------
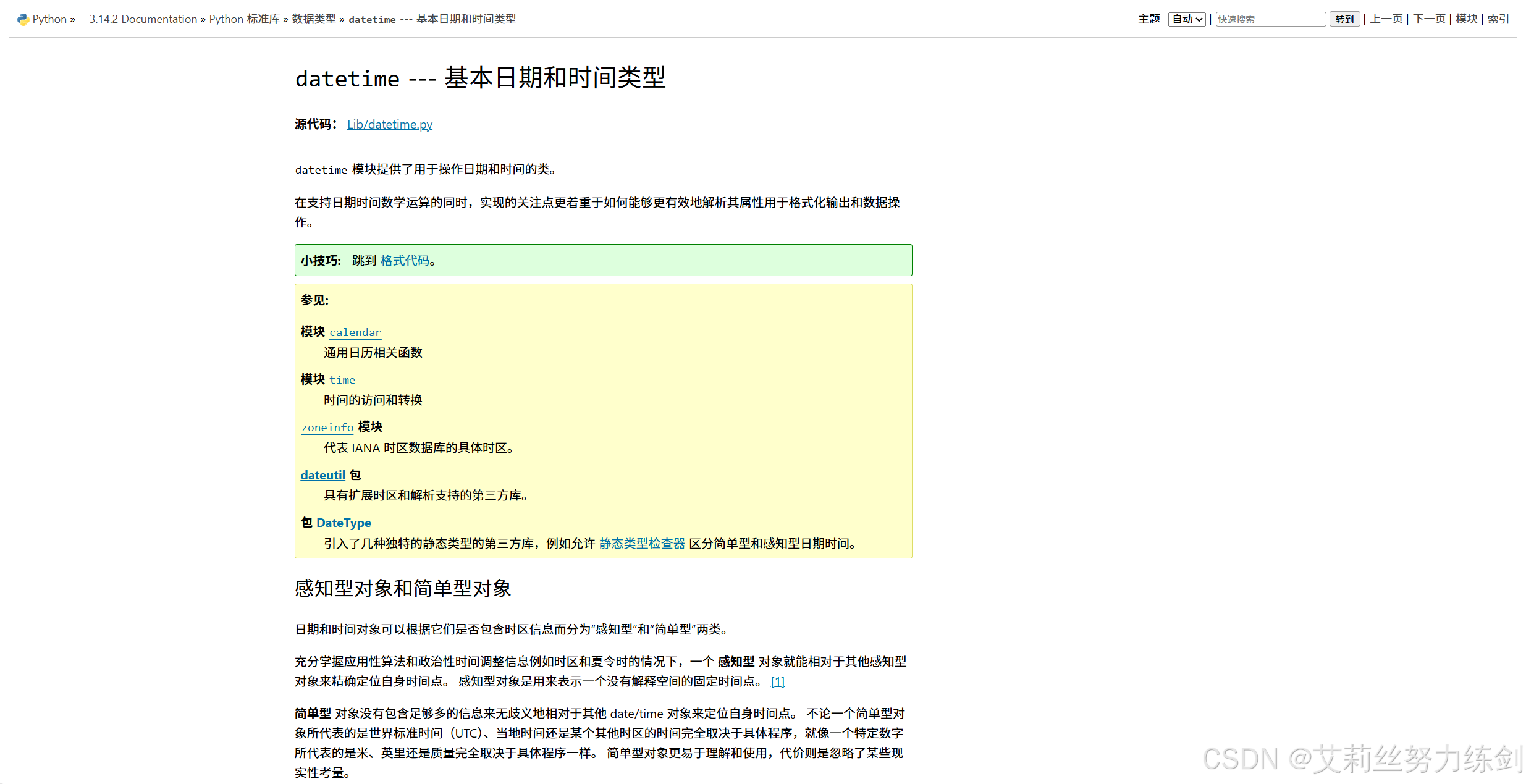
我们下载Python时候就顺带下载的离线模式的Python文档,可以快速查找,缺点就是:这个离线文档全是英文!
2.4 代码示例:字符串操作
字符串是Python的内置类型,字符串的很多方法不需要导入额外的模块,即可直接使用。
2.4.1 剑指offer 58:翻转单词顺序
力扣链接:剑指offer 58:翻转单词顺序
2.4.1.1 理论
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串"l am a student.",则输出"student.aamI"。
- 使用
str的split方法进行字符串切分,指定空格为分隔符,返回结果是一个列表。 - 使用列表的
reverse方法进行逆序。 - 使用
str的join方法进行字符串拼接------把列表中的内容进行合并。
2.4.1.2 答案参考
python
def reverseWords(s):
tokens = s.split()
tokens.reverse()
return ' '.join(tokens)
print(reverseWords('I am a student.'))2.4.1.3 最佳实践
python
# 代码示例:字符串操作
# 代码案例:单词逆序(剑指offer中的题目)
# 剑指offer:是一本包含很多算法题的书!
# 每个参加秋招的同学都至少把这本书刷个两遍!很多面试官出算法题就是从这本书里找的!
# 如果真的遇到了原题,千万不要表现出来!这时候就到了考验演技的时候了!
# 可以多"思考"一下,读读题,不要一口气写完,停顿一下
# 题目:怎样区分的单词?根据空格来分割
# 在Python中,思路是这样的:
# 1、针对上述字符串,使用空格进行划分
# 字符串 split 方法,可以指定分隔符,把字符串分成多个部分,放到一个 list 里
# 2、针对刚才的切分结果列表,进行逆序(reverse方法)
# 3、再把逆序后的列表,组合起来(join,并且可以在组合指定分隔符为1个空格)
def reverseWords(s:str): # s:[类型声明],这样下面就有提示了(变量有了类型声明之后)
tokens = s.split(' ') # 没有代码提示:是因为Python是动态类型的语言,所以我们写s的时候,
# 其实Pycharm是不知道s是什么类型的,不知道是啥类型,也就不知道有哪些方法,
# 所以s.spilt到底能不能调用,以及有没有其它方法,这是不好确定的
tokens.reverse() # 逆序
return ' '.join(tokens) # 借助空格分隔符,把这里的字符串重新拼接成一个更长的字符串
# 输入一个字符串,运行程序
print(reverseWords("I am a student."))2.4.2 leetcode 796:旋转字符串
力扣链接:leetcode 796:旋转字符串
2.4.2.1 理论
给定两个字符串,
s和goal。如果在若干次旋转操作之后,s能变成goal,那么返回true。
s的旋转操作就是将s最左边的字符移动到最右边。例如,若
s='abcde',在旋转一次之后结果就是'bcdea'。
- 使用
len方法求字符串的长度.如果长度不相同,则一定不能旋转得到。 - 将
s和自己进行拼接,然后直接使用in方法来判定goal是否是s+s的子串。
2.4.2.2 参考答案
python
def rotateString(s, goal):
return len(s) == len(goal) and goal in s + s
print(rotateString('abcde', 'cdeab'))2.4.2.3 最佳实践
python
# 代码案例:旋转字符串
# 题目要求
# 如果在若干次旋转操作之后,s 能变成 goal ,那么返回 true
# s = "abcde" "bcdea" "cdead" "deabc" "eabcd"(s通过旋转能得到的内容)
# 把最左侧的字符,给放到最右侧去!
# s + s => "abcdeabcde" # 每个旋转后得到的字符串都可以在这样一个大字符串中找到
def rotateString(s, goal):
if len(s) != len(goal):
return False
return goal in (s + s) # in判断某个字符串是否是另外一个字符串的子串
print(rotateString("abcde","cdeab"))
print(rotateString("abcde","edcba"))2.4.3 leetcode 2255:统计是给定字符串前缀的字符串数目
力扣链接:leetcode 2255:统计是给定字符串前缀的字符串数目
2.4.3.1 理论
给你一个字符串数组words和一个字符串s,其中words[i]和s只包含小写英文字母。
请你返回words中是字符串s前缀的字符串数目。
一个字符串的前缀是出现在字符串开头的子字符串。子字符串是一个字符串中的连续一段字符序列。
- 依次遍历words中的字符串。
- 直接使用字符串的
startswith方法即可判定当前字符串是否是s的前缀。
2.4.3.2 参考答案
python
def countPrefixes(words, s):
res = 0 # 符合要求字符串个数
for word in words:
if s.startswith(word):
res += 1
return res
print(countPrefixes(["a","b","c","ab","bc","abc"], "abc"))2.4.3.3 最佳实践
python
# 代码案例:统计字符串前缀
# 遍历 words,取出每个字符串,判定当前这个字符串是否是 s 的前缀即可(s是否是以这个字符串开题的)
def countPrefixes(words: list,s: str):
count = 0
for word in words:
if s.startswith(word): # 使用 in 操作可以判断 word 是不是 s 的一部分
# s 是以 word 开头
count += 1
return count # 注意缩进
print(countPrefixes(['a','b','c','ab','bc','abc'],'abc'))
print(countPrefixes(['a','a'],'aa'))2.4.4 其它字符串操作
关于字符串的更多操作,参考官方文档:查看文档中的字符串操作
2.5 代码示例:文件查找工具
2.5.1 理论
指定一个待搜索路径,同时指定一个待搜索的关键字。
在待搜索路径中查找是否文件名中包含这个关键字------
-
使用
os.walk即可实现目录的递归遍历。 -
os.walk返回一个三元组,分别是当前路径,当前路径下包含的目录名(多个),当前路径下包含的文件名(多个)
python
import os
inputPath = input('请输入待搜索路径: ')
pattern = input('请输入待搜索关键词: ')
for dirpath, dirnames, filenames in os.walk(inputPath):
for f in filenames:
if pattern in f:
print(f'{dirpath}/{f}')
2.5.2 最佳实践
python
# 文件搜索工具
# 很多目录,很多文件,想找到某个文件,就不太容易
# 文件搜索工具------如everything
# 实现文件查找工具
# 输入要查找的路径,输入要搜索的文件名(一部分)
# 自动地在指定的路径进行查找
# import os
#
# inputPath = input('请输入要搜索的路径:')
# pattern = input('请输入要搜索的关键词:')
# 递归查找,遇到子目录,就进到目录里面进行查找
#OS.walk(OS:操作系统),只需要使用简单的循环就可以完成递归遍历的过程,就不必手写递归代码了
# for dirpath,dirnames,filenames in os.walk(inputPath):
# print('----------------------------')
# print(f'dirpath = {dirpath}')
# print('dirnames:')
# for name in dirnames:
# print(name)
# print('filename:')
# for name in filenames:
# print(name)
# dirpath: 遍历到当前位置,对应的路径是啥
# dirnames: 当前目录下,都有哪些目录,是一个列表,可以包含多个目录名
# filenames: 当前目录下,都有哪些文件名,是一个列表,可以包含多个文件名
# os.walk: os.walk 每次调用都能自动的去针对子目录进行递归的操作,只需要使用上述循环就可以把所有的路径都获取出来
# 正式实现一下这里的功能
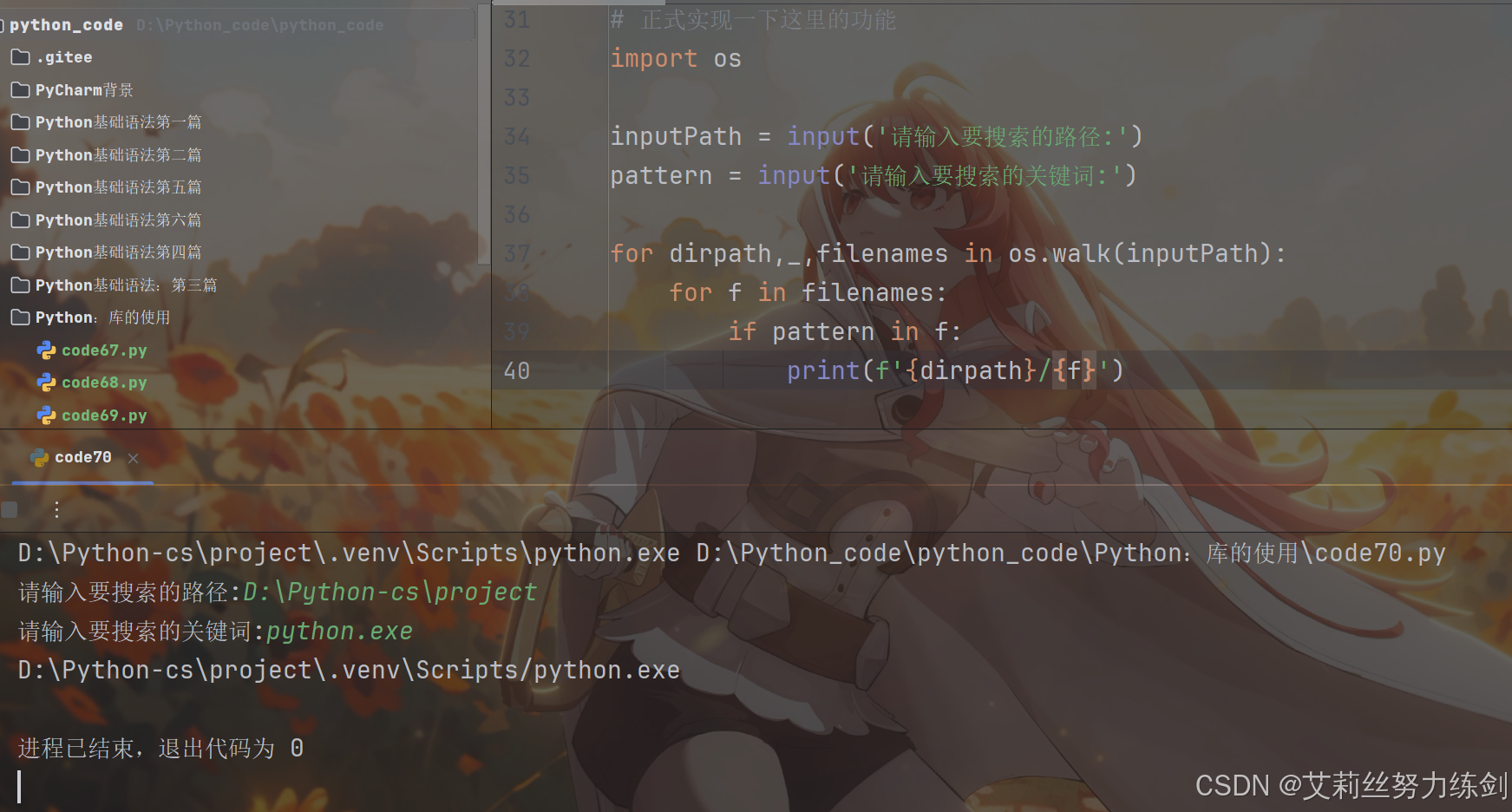
import os
inputPath = input('请输入要搜索的路径:')
pattern = input('请输入要搜索的关键词:')
for dirpath,_,filenames in os.walk(inputPath):
for f in filenames:
if pattern in f:
print(f'{dirpath}/{f}')
# 这里只是一个简单粗暴的遍历,比不了 everything,不算特别高效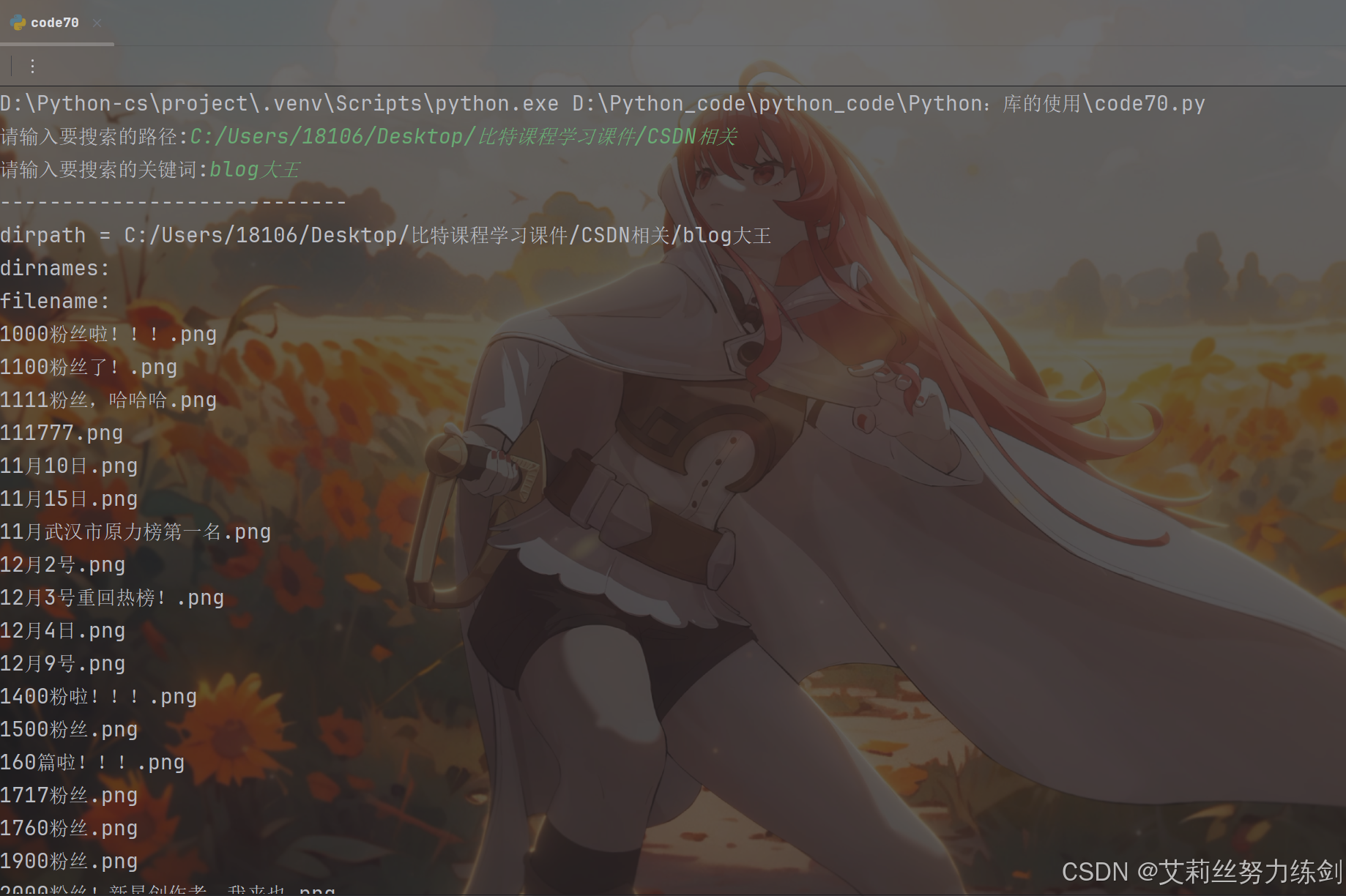
2.5.3 其它os模块操作
关于os模块的更多操作,参考官方文档:文档中的更多os操作
3 ~> 第三方库
3.1 认识第三方库
第三方库就是别人已经实现好了的库,我们可以拿过来直接使用。
虽然标准库已经很强大了,但是终究是有限的;而第三方库可以视为是集合了全世界Python程序猿的智慧,可以说是几乎无穷无尽。
问题来了,当我们遇到一个需求场景的时候,如何知道,该使用哪个第三方库呢?
这时候就需要用到下面几个网站了:
当我们确定了该使用哪个第三方库之后,就可以使用pip来安装第三方库了。
3.2 使用pip
3.2.1 理论
pip 是 Python 内置的 包管理器。
所谓
包管理器就类似于我们平时使用的手机app应用商店一样。第三方库有很多,是不同的人,不同的组织实现的.为了方便大家整理,Python官方提供了一个网站PyPI(PyPI),来收集第三方库。
其他大佬写好的第三方库也会申请上传到PyPI上。
这个时候就可以方便的使用pip工具来下载PyPI上的库了。
pip在我们安装Python的时候就已经内置了,无需额外安装。
pip是一个可执行程序,就在Python的安装目录中。
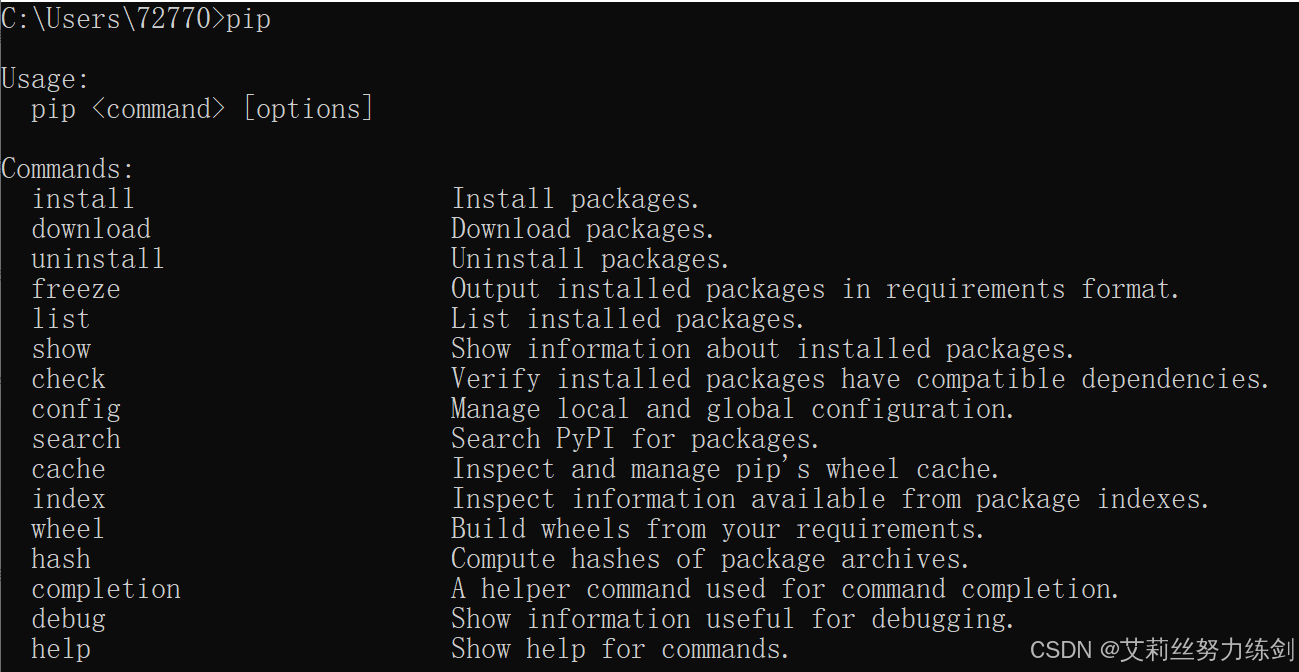
打开cmd,直接输入pip,如果显示以下帮助信息,说明pip已经准备就绪。
如果最开始按照要求在安装 Python 的时候勾选了这个选项------
那么 pip 就是默认可用的。

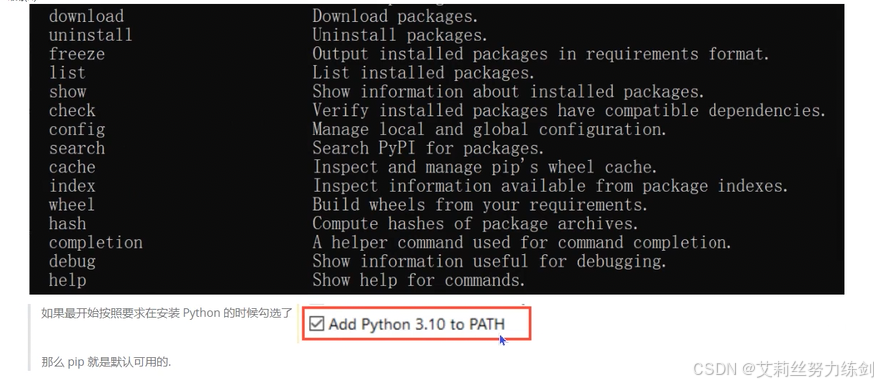
如果pip不能使用,说明安装Pycharm时,没有勾选这个选项。
如果提示:
'pip'不是内部或外部命令,也不是可运行的程序
或批处理文件。
则说明没有正确的把pip加入到PATH中,可以手动把pip所在的路径加入到PATH环境变量中(参考这篇文章:windows环境下面配置pip环境变量)。
或者卸载重装Python,记得勾上上述选项,也许是更简单的办法
使用以下命令,即可安装第三方库------
python
pip install [库名]注意: 这个命令需要从网络上下载,使用时要保证网络畅通。
安装成功后,即可使用import导入相关模块,即可进行使用。
注意:如果使用pip安装完第三方库之后,在PyCharm中仍然提示找不到对应的模块,则检查Settings->Project->PythonInterpreter,看当前Python解释器设置的是否正确(如果一个机器上安装了多个版本的Python,容易出现这种情况)。
3.2.2 最佳实践
python
# 第三方库(规模远超标准库)
# 认识第三方库
# 代码案例:pip的使用
# pip(Python内置的包管理器)
# 手机app,app其实是来自于不同的厂商------应用商店(下载程序不必找官网啦)
# Python的第三方库也是如此!
# Python官方搞了一个网址 pypi,把各种第三方库给收集起来了!又提供了一个 pip 工具
# 使用 pip 就能直接从 pypi 上面下载你想要的第三方库
# pip 我们视为是 Python 世界中的应用商店
# 安装 Python 的时候已经自动地把 pip 装好了,我们直接就能使用!
# 如何使用 pip 呢?pip是一个命令行程序
# 很多语言都有依赖第三方库
pip效果如下所示,是不是蛮像应用商店的------
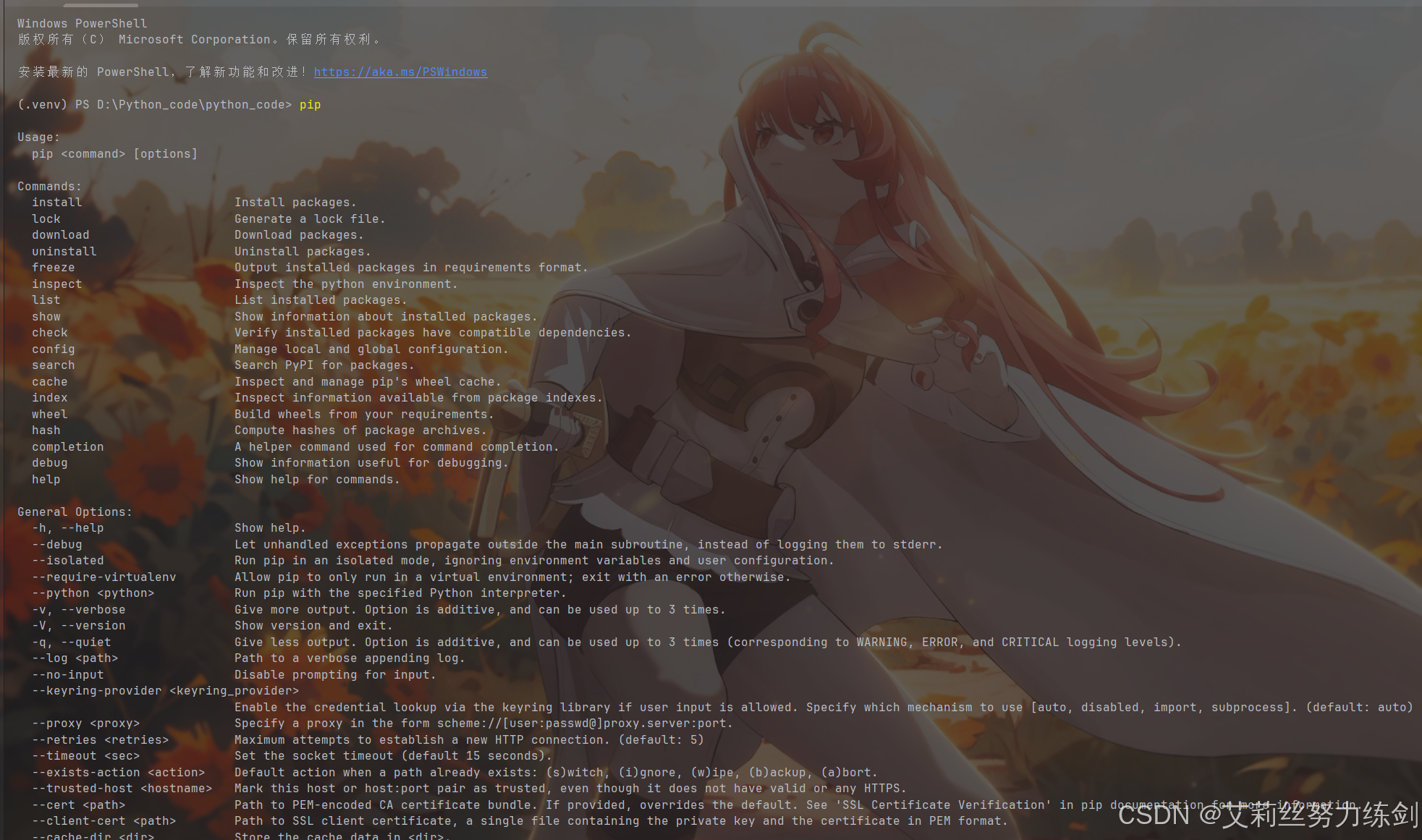
像上面这样,说明pip已经安装了,可以使用。
3.3 代码示例:生成二维码
3.3.1 通过搜索引擎,确定使用哪个库

得到情报,qrcode这个库,可以用来生成二维码。
3.3.2 查看 qrcode 文档
在PyPI上搜索qrcode:

点击则进入qrcode的详情页。
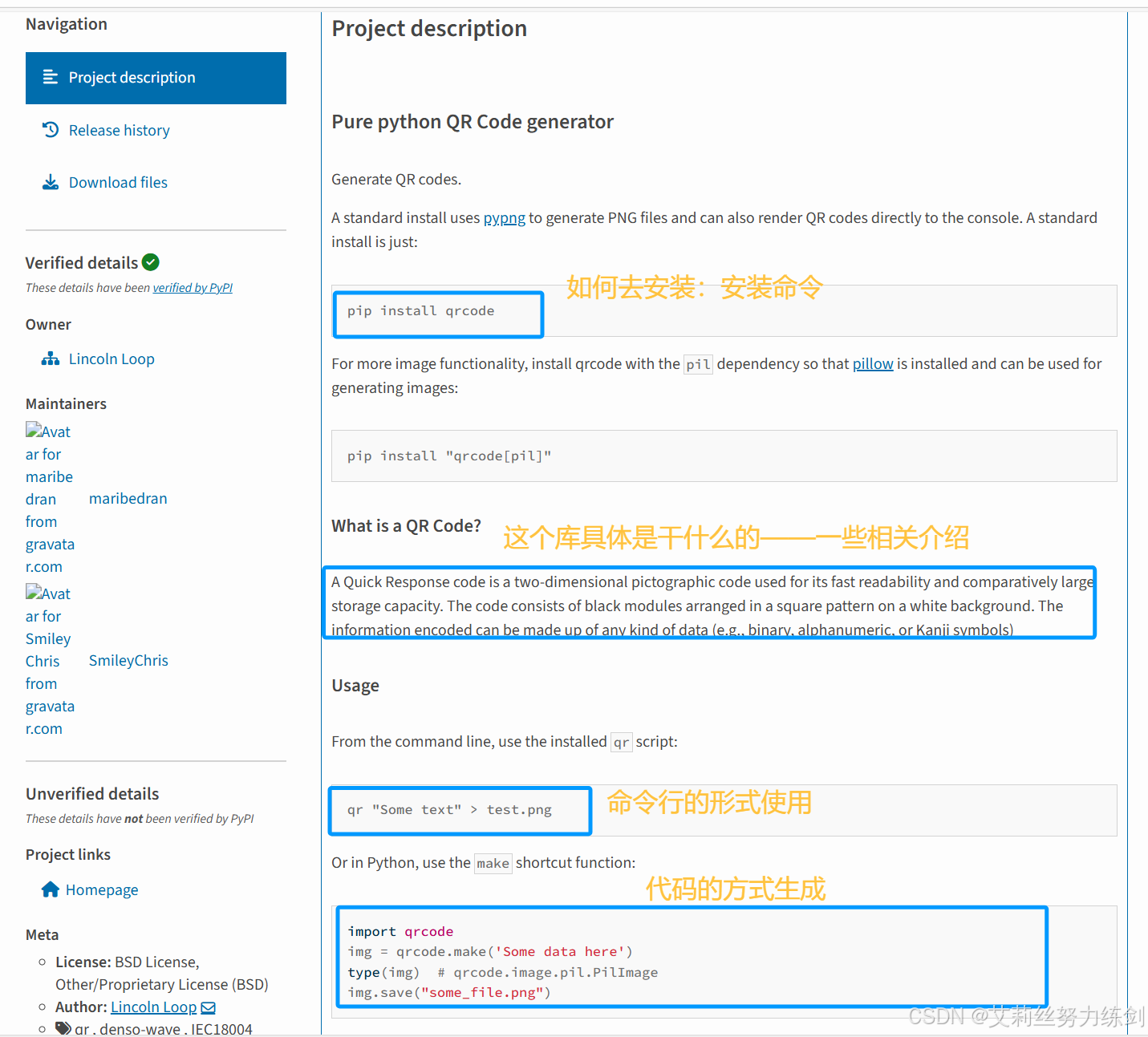
文档开头描述了如何安装qrcode。

页面中央位置描述了 qrcode 库的使用方法。
3.3.3 使用 pip 安装
bash
pip install qrcode[pil]注意:pip安装的时候可能会有警告,提示使用的pip版本太低,这个警告我们不必处理,不影响我们正常使用。
3.3.4 编写代码
按照文档给出的示例,模仿一段代码:
python
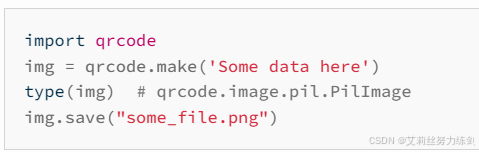
import qrcode
img = qrcode.make('艾莉丝努力练剑')
img.save('qrcode.png')运行完毕后,得到结果如下:
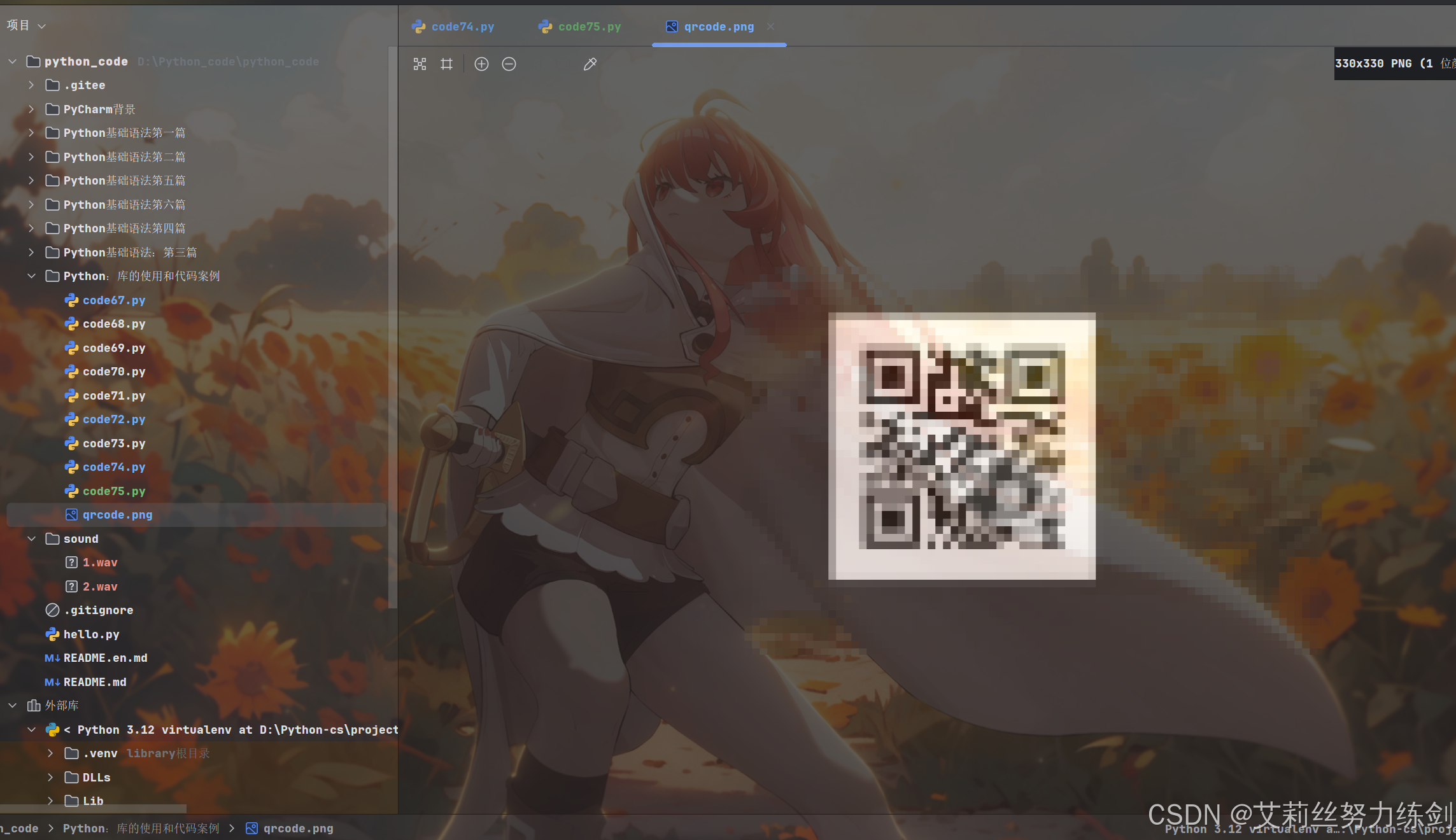
使用微信或者其他工具扫码,即可看到二维码内容。
所谓二维码,本质上就是使用黑白点阵表示一个字符串。
我们日常使用的二维码内部一般是一个URL,扫码后会自动跳转到对应的地址,从而打开一个网页。
3.3.5 最佳实践
python
# 二维码生成工具
# 二维码本质上就是一段字符串
# 我们可以把任意的字符串,制作成一个二维码图片
# 生活中使用的二维码,更多的是一个URL(网址)
# 标准库里面能不能干这件事情?好像没有这个功能
# 这时候就要看第三方库了------搜索引擎------qrcode
import qrcode
img = qrcode.make('艾莉丝努力练剑!')
# img = qrcode.make('艾莉丝努力练剑!秃秃,新的一周,继续加油吧!艾莉丝会一直支持你哒!')
img.save('qrcode.png')
# no news is good news3.4 代码示例:操作 excel
3.4.1 理论
读取excel可以使用xlrd模块.文档地址:xlrd
修改excel可以使用xlwt模块.文档地址:xlwt
此处以xlrd为例,演示excel的基本操作。
3.4.2 需求
需求 有如下excel表格d:/test.xlsx:
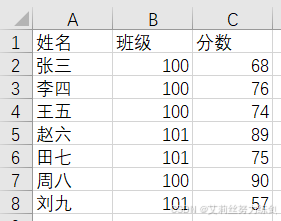
求100班的同学的平均分。
虽然excel自身支持很强大的功能,也可以求和,求平均值,但是如果是稍微复杂的需求,操作起来可能就没那么方便了。
3.4.3 操作
3.4.3.1 安装 xlrd
bash
pip install xlrd==1.2.0注意:此处要指定版本号安装,如果不指定版本号,则安装最新版,最新版里删除了对xlsx格式文件的支持。
3.4.3.2 编写代码
- 使用
open_workbook方法打开一个 excel 文件。 - 使用
xlsx.sheet_by_index(0)获取到 0 号标签页。 - 使用
table.nrows获取到表格的行数。 - 使用
table.cell_value(row, col)获取到表格中row, col位置的元素值。
python
import xlrd
# 1. 打开 xlsx 文件
xlsx = xlrd.open_workbook('d:/test.xlsx')
# 2. 获取 0 号标签页. (当前只有一个标签页)
table = xlsx.sheet_by_index(0)
# 3. 获取总行数
nrows = table.nrows
# 4. 遍历数据
count = 0
total = 0
for i in range(1, nrows):
# 使用 cell_value(row, col) 获取到指定坐标单元格的值.
classId = table.cell_value(i, 1)
if classId == 101:
total += table.cell_value(i, 2)
count += 1
print(f'平均分: {total / count}')3.4.4 最佳实践
python
# 代码案例:操作excel
# 操作 excel
import xlrd
# 1、先打开 xlsx 文件
xlsx = xlrd.open_workbook('C:/Users/18106/Desktop/比特课程学习课件/Python/Python:Excel操作.xlsx')
# 2、获取到指定的标签页
table = xlsx.sheet_by_index(0)
# 3、获取到表格中有多少行
nrows = table.nrows
# 4、进行循环统计操作
total = 0
count = 0
for i in range(1,nrows):
# 拿到当前同学的班级
classID = table.cell_value(i,1)
if classID == 100:
total += table.cell_value(i,2)
count += 1
print(f'平均分: {total / count}')结尾
uu们,本文的内容到这里就全部结束了,艾莉丝再次感谢您的阅读!
结语:希望对学习Python相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Python基础:语法第六课】Python文件操作安全指南:告别资源泄露与编码乱码
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
