在自动驾驶与机器人领域,3D 场景理解是核心技术难题,而 3D 目标检测作为其关键组成部分,直接影响着智能系统对周围环境的感知与决策能力。当前主流的 3D 目标检测方法高度依赖激光雷达(LiDAR)传感器,凭借其精准的 3D 信息获取能力,各类基于 LiDAR 点云的检测算法取得了显著进展。然而,LiDAR 存在数据分辨率稀疏、设备成本高昂等固有缺陷,限制了其大规模普及应用。
相比之下,摄像机设备成本更低、数据分辨率更高,基于图像的 3D 目标检测方法具有更强的实用性。但由于 2D 图像到 3D 空间的信息映射存在天然瓶颈,现有单目或双目图像 - based 检测方法在精度上与 LiDAR-based 方法仍存在较大差距。为此,香港中文大学与 SmartMore 联合提出了一种名为 Deep Stereo Geometry Network(DSGN)的端到端立体视觉 3D 目标检测框架,通过创新的 3D 几何体积表示,有效缩小了图像 - based 与 LiDAR-based 方法的性能差距,为低成本 3D 感知系统提供了新的解决方案。
原文链接:https://arxiv.org/pdf/2001.03398
代码链接:https://github.com/dvlab-research/DSGN
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心挑战
1.1 3D 目标检测技术现状
3D 目标检测方法主要分为三大类:
- LiDAR-based 方法:通过激光雷达直接获取场景的 3D 点云数据,基于体素(voxel-based)或点云(point-based)的网络架构(如 VoxelNet、PointRCNN 等)能精准提取 3D 几何特征,检测精度领先,但设备成本高(64 线 LiDAR 约 7.5 万美元),点云数据稀疏。
- 单目图像 - based 方法:仅依赖单张 2D 图像进行 3D 目标检测,如 MonoGRNet、M3D-RPN 等,设备成本最低,但需通过单目视觉线索(如目标尺度、上下文信息)间接估计深度,3D 几何信息缺失严重,检测精度有限。
- 立体图像 - based 方法:利用双目相机的视差信息计算深度,如 Stereo R-CNN、Pseudo-LiDAR 等,兼顾成本与信息丰富度,但现有方法多采用 "深度估计 + 目标检测" 两阶段分离设计,或通过非可微转换生成伪点云,存在信息损失、网络优化困难等问题。
1.2 核心挑战
基于图像的 3D 目标检测面临两大核心难题:
- 3D 表示困境:2D 图像是 3D 场景的投影,同一 3D 特征在不同姿态下会产生不同的 2D 外观,导致 2D 网络难以提取稳定的 3D 信息;现有中间表示(如伪点云)存在非可微性、目标伪影(streaking artifacts)等问题,影响检测精度。
- 深度与语义融合难题:深度信息是 3D 检测的基础,但立体匹配得到的视差与真实 3D 深度存在非线性映射关系,且如何将深度几何信息与高层语义特征有效融合,是提升检测性能的关键。
1.3 本文核心贡献
为解决上述挑战,DSGN 提出了以下三大核心贡献:
- 构建了一种从平面扫描体积(Plane-Sweep Volume, PSV)到 3D 几何体积(3D Geometric Volume, 3DGV)的可微转换机制,在 3D 规则空间中同时编码几何结构与语义线索,搭建了 2D 图像与 3D 空间的桥梁。
- 设计了端到端的一体化 pipeline,联合优化立体匹配(深度估计)与 3D 目标检测任务,同时学习像素级匹配特征与高层语义特征,无需复杂后处理。
- 在 KITTI 3D 目标检测基准数据集上,以简洁的网络设计超越了所有现有立体视觉 - based 方法(AP 提升约 10 个百分点),甚至在部分场景下达到了与经典 LiDAR-based 方法(如 MV3D)相当的性能。
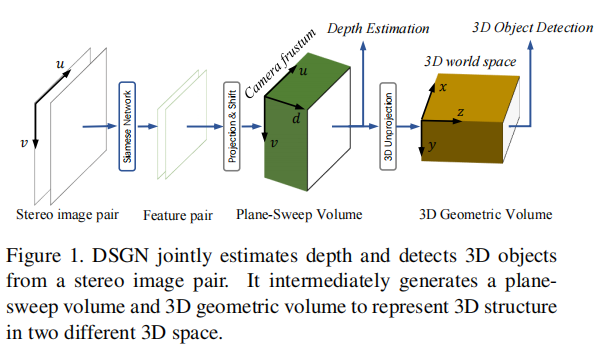
二、相关工作综述
2.1 立体匹配与多视图立体视觉
- 立体匹配:传统方法通过构建 3D 代价体积(cost volume)计算视差,如 GC-Net 采用拼接 - based 代价体积,PSMNet 引入金字塔池化与堆叠沙漏模块,在 KITTI 立体匹配基准上实现了低于 2% 的 3 像素误差。
- 多视图立体视觉(MVS):MVSNet 通过在相机视锥内构建平面扫描体积生成深度图,Point-MVSNet 将平面扫描体积转换为点云以节省计算量,Kar 等人提出了可微的投影与反投影操作,为多视图 3D 重建提供了新思路。
2.2 3D 目标检测方法分类
- LiDAR-based:分为体素 - based(如 VoxelNet、PointPillars)和点云 - based(如 PointNet++、PointRCNN),直接处理 3D 点云,几何信息完整,但依赖昂贵设备。
- 图像 - based:
- 带深度预测的检测方法:如 Stereo R-CNN 通过多分支显式处理约束条件,MonoGRNet 仅依赖语义线索渐进式定位 3D 目标,但像素匹配未被充分利用。
- 基于 3D 表示的检测方法:3DOP 通过立体视觉生成点云并编码先验知识,Pseudo-LiDAR 系列将深度图转换为伪点云后使用 LiDAR-based 检测器,但存在多网络分离、信息损失等问题。
三、DSGN 核心方法详解
DSGN 的整体架构如图 2 所示,主要包含四大模块:2D 特征提取、平面扫描体积与 3D 几何体积构建、深度估计、3D 目标检测。其核心思想是通过可微的体积转换,将立体图像的视差信息与语义特征融合到 3D 规则空间中,实现深度估计与 3D 检测的联合优化。
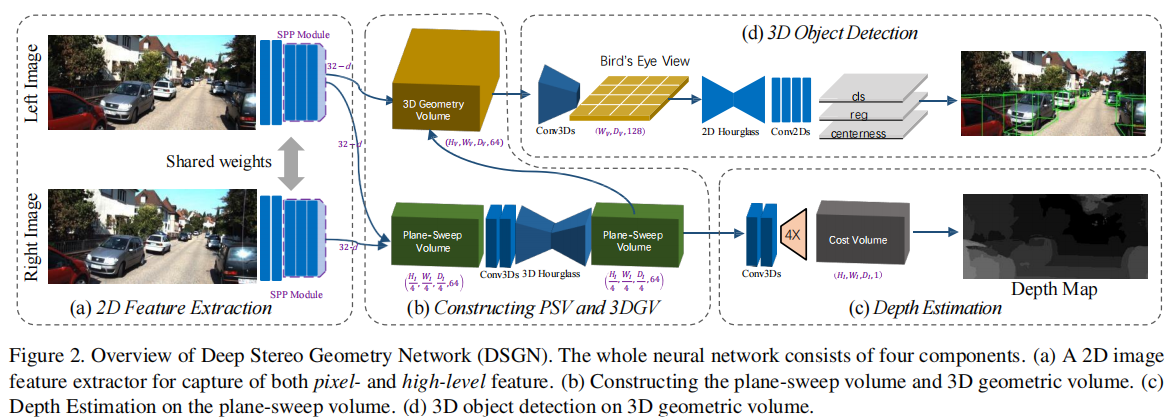
注:(a) 2D 特征提取器,捕获像素级与高层特征;(b) 构建平面扫描体积(PSV)与 3D 几何体积(3DGV);(c) 基于 PSV 的深度估计;(d) 基于 3DGV 的 3D 目标检测。
3.1 动机:3D 表示的选择与优化
现有 3D 表示方法存在明显缺陷:
- 点云 - based 表示:需通过深度预测与非可微转换生成,存在目标边缘伪影,多目标场景下难以优化。
- 体素 - based 表示:如 OFT-Net 直接将图像特征映射到 3D 体素网格,但未显式编码 3D 几何信息,仍依赖 2D 视图特征。
DSGN 的核心洞察的是:立体相机提供了显式的像素匹配约束,可用于计算深度;通过构建中间体积表示,将该约束与 3D 几何信息结合,能更有效地学习 3D 目标特征。具体而言,DSGN 先在相机视锥空间构建平面扫描体积(PSV)以学习像素匹配约束,再通过可微转换将其映射到 3D 世界空间的 3D 几何体积(3DGV),实现几何信息与语义特征的统一编码。
3.2 2D 特征提取
立体匹配与目标检测对特征的需求不同:立体匹配需要细粒度的像素级特征,目标检测则依赖具有判别力的高层语义特征。为此,DSGN 基于 PSMNet 的 backbone 进行改进,主要修改如下:
- 调整卷积块数量分配:将 conv2-conv5 的基础块数量从 {3,16,3,3} 改为 {3,6,12,4},将计算量向高层卷积转移,增强语义特征提取能力。
- 调整输出通道数:conv1 的输出通道数从 32 改为 64,基础残差块的输出通道数从 128 改为 192,提升特征表达能力。
- 保留 SPP 模块:拼接 conv4 与 conv5 的输出,融合多尺度特征。
该设计在保证立体匹配精度的同时,为目标检测提供了充足的高层语义信息,且未引入过多计算开销。
3.3 3D 几何体积构建
3D 几何体积(3DGV)的构建是 DSGN 的核心创新,分为平面扫描体积(PSV)构建与可微转换两步,流程如图 3 所示。
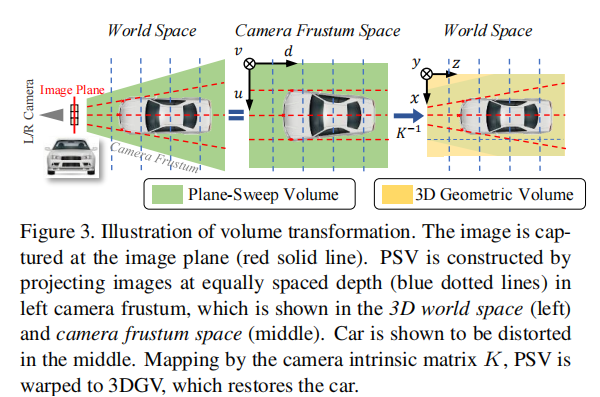
注:左图为 3D 世界空间,中图为相机视锥空间(PSV 所在),右图为转换后的 3D 几何体积(3DGV),汽车在 PSV 中存在畸变,转换后恢复真实形状。
3.3.1 平面扫描体积(PSV)
传统立体匹配的代价体积基于视差构建,存在远距离目标视差相近、3D 空间特征映射不平衡的问题(如 KITTI 数据集中 40 米与 39 米处目标的视差差小于 0.25 像素)。DSGN 采用平面扫描策略构建 PSV,具体步骤如下:
- 对左右目图像的 2D 特征图(尺寸为
)进行处理,将右目特征图重投影到左目相机坐标系。
- 在预定义的深度范围内(
- 将左目特征
PSV 的坐标系为,其中
为图像像素坐标,
为深度维度,该体积能自然地在相机视锥内施加像素匹配约束,且等间隔深度采样保证了 3D 空间特征映射的平衡性。
3.3.2 可微转换至 3D 几何体积(3DGV)
通过相机内参矩阵,将 PSV 从相机视锥空间可微地转换到 3D 世界空间
,转换公式如下:
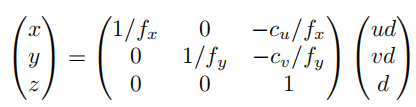
其中, 为相机水平与垂直焦距,
为相机主点坐标。转换过程通过三线性插值实现,具有完全可微性,可通过反向传播联合优化。
3DGV 的参数设置:在相机视角下,沿右(X)、下(Y)、前(Z)方向将感兴趣区域(单位:米)离散化为
的体素网格,每个体素尺寸为
(米)。该体积保留了 PSV 中的像素匹配信息,同时将其映射到真实 3D 空间,为 3D 目标检测提供了富含几何结构的特征表示。
3.4 深度估计
深度估计基于 PSV 进行,具体步骤如下:
- 对 PSV 应用 1 个 3D 沙漏模块与额外 3D 卷积,将特征压缩为 1D 代价体积(尺寸为
- 采用软.argmin 操作计算深度期望,公式如下:
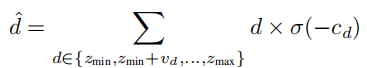
其中, 为深度
对应的匹配代价,
为 softmax 函数,鼓励每个像素选择单一深度平面。
- 通过三线性插值将代价体积上采样至图像尺寸,得到最终深度图。
相比 PSMNet 使用 3 个 3D 沙漏模块,DSGN 仅使用 1 个以节省计算量,且通过后续 3D 检测网络的联合优化补偿了精度损失。
3.5 3D 目标检测
3D 目标检测基于 3DGV 的鸟瞰图(BEV)特征进行,借鉴 FCOS 的中心度分支思想,设计了基于距离的目标分配策略。
3.5.1 BEV 特征提取
将 3DGV 沿高度维度(Y 轴)下采样,得到 BEV 特征图F(尺寸为),该特征图编码了目标在水平面上的位置与形状信息。
3.5.2 锚点设计
在 BEV 特征图的每个位置放置 4 个不同朝向(
)的锚点,锚点尺寸按目标类别预定义:
- 汽车(Car):
- 行人(Pedestrian):
- 自行车(Cyclist):
锚点的垂直中心分别设为 0.825(汽车)和 0.74(行人和自行车)。
3.5.3 基于距离的目标分配
考虑目标朝向,定义锚点与真实框的距离为 8 个角点的平均欧氏距离:
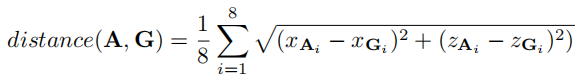
为平衡正负样本,选择与真实框距离最近的个锚点作为正样本(
为真实框在 BEV 上覆盖的体素数,
用于汽车,
用于行人和自行车)。
中心度定义为 8 个角点归一化距离的负指数,用于过滤低质量检测框。
3.5.4 回归与分类
- 回归目标:对锚点的位置
- 回归策略:汽车采用联合优化 8 个角点的方式,行人和自行车采用分离优化各参数的方式(因行人朝向难以准确标注)。
- 分类:采用 Focal Loss 解决类别不平衡问题,中心度采用二元交叉熵(BCE)损失。
3.6 多任务训练损失
DSGN 采用多任务损失函数联合训练深度估计与 3D 目标检测,总损失为:
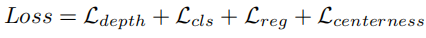
各损失项定义如下:
-
深度回归损失:采用 Smooth L1 损失,仅对有 LiDAR 真实深度的像素计算:
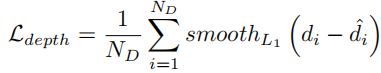
其中,
-
分类损失:Focal Loss,仅对正样本计算:
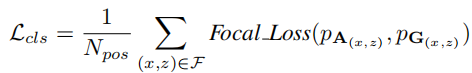
其中,
-
3D 边界框回归损失:Smooth L1 损失,基于锚点与真实框的 L1 距离:
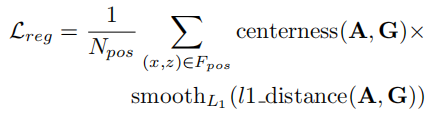
-
中心度损失:BCE 损失,用于优化中心度预测。
四、实验设置与结果分析
4.1 数据集与评估指标
- 数据集:采用 KITTI 3D 目标检测数据集,包含 7481 对训练立体图像与点云,7518 对测试数据。训练集按常规协议分为训练集(3712 张)与验证集(3769 张),测试集提交至 KITTI 排行榜评估。
- 评估指标:KITTI 数据集按遮挡程度、截断程度和目标尺寸分为 Easy、Moderate、Hard 三个难度等级,评估指标为平均精度(AP),其中汽车的 IoU 阈值为 0.7,行人和自行车为 0.5,涵盖 2D 检测、鸟瞰图(BEV)检测和 3D 检测三个任务。
4.2 实现细节
- 硬件配置:4 块 NVIDIA Tesla V100(32G)GPU,批次大小为 4(每块 GPU 处理 1 对 384×1248 的立体图像)。
- 优化器:Adam 优化器,初始学习率 0.001,50 个 epoch 后学习率降低 10 倍,总训练时间约 17 小时。
- 数据增强:仅采用水平翻转。
- 预训练策略:行人和自行车的标注数据仅占 1/3,因此先使用所有训练数据预训练立体匹配网络,再用带 3D 框标注的数据微调检测分支。
4.3 主要实验结果
4.3.1 KITTI 测试集结果(表 1)
DSGN 在测试集上的性能全面超越现有立体视觉 - based 方法,具体表现如下:
- 3D 检测 AP(Moderate):汽车 52.18%,远超 Stereo R-CNN(30.23%)和 Pseudo-LiDAR++(42.43%);
- BEV 检测 AP(Moderate):汽车 65.05%,接近 LiDAR-based 方法 MV3D(78.98%);
- 2D 检测 AP(Moderate):汽车 86.43%,保持领先水平。
值得注意的是,DSGN 未使用额外数据集预训练(如 Pseudo-LiDAR++ 使用 Scene Flow 数据集),仅在 KITTI 7K 训练数据上从头训练,且为单网络架构,而其他方法多依赖多网络串联。此外,DSGN 在 Easy 难度下的 3D 检测 AP(73.50%)已超过 MV3D(68.35%),证明其在近距离场景下的有效性。
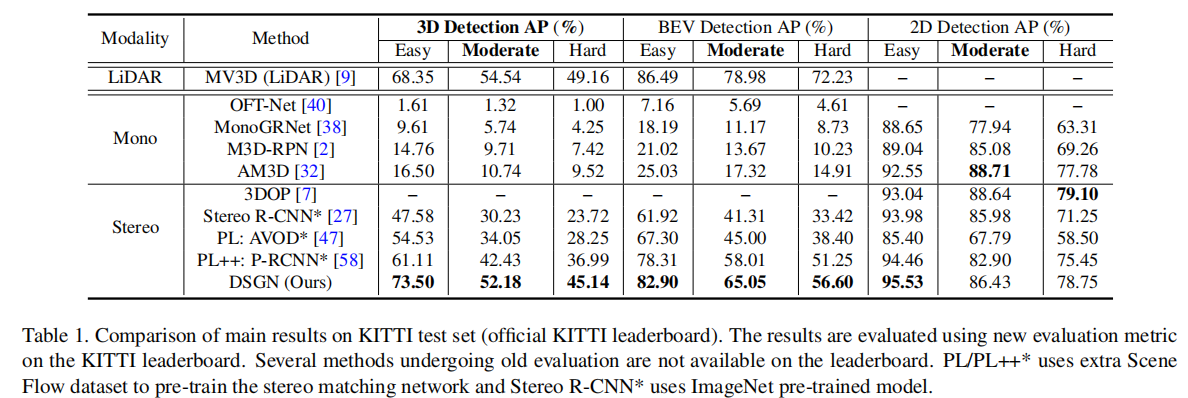
注:PL/PL++使用 Scene Flow 数据集预训练,Stereo R-CNN使用 ImageNet 预训练的 ResNet-101。
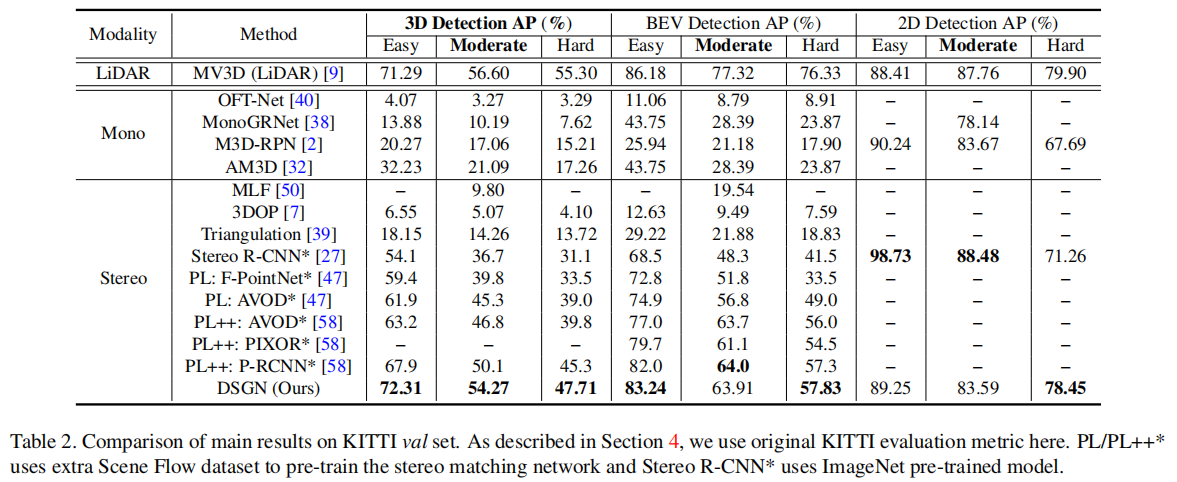
4.3.2 KITTI 验证集结果(表 2)
在验证集上,DSGN 同样保持领先优势:
- 3D 检测 AP(Moderate):汽车 54.27%,超过 Pseudo-LiDAR++(50.1%);
- BEV 检测 AP(Moderate):汽车 63.91%,与 Pseudo-LiDAR++(64.0%)相当;
- 2D 检测 AP(Moderate):汽车 83.59%,保持稳定性能。
4.3.3 推理时间
在 NVIDIA Tesla V100 GPU 上,DSGN 处理一对立体图像的平均推理时间为 0.682 秒,各模块耗时如下:
- 2D 特征提取:0.113 秒
- PSV 与 3DGV 构建:0.285 秒
- 3D 目标检测:0.284 秒
计算瓶颈主要在于 3D 卷积层,未来可通过模型压缩或高效卷积算子进一步优化。
4.4 消融实验分析
4.4.1 3D 体积构建的影响(表 3)
该实验探究了输入数据、体积转换方式和深度监督对性能的影响,核心结论如下:
- 深度监督的重要性:基于 LiDAR 点云的深度监督能显著提升性能,例如立体图像输入 + IMG→3DV 转换,有监督比无监督的 3D AP 提升 31.54 个百分点。
- 立体图像的优势:在有深度监督的情况下,立体图像输入的性能远超单目输入(42.57% vs 13.66% 3D AP),证明像素匹配约束对 3D 几何学习的重要性。
- 平面扫描体积的有效性:IMG→PSCV→3DGV 的转换方式(54.27% 3D AP)优于 IMG→CV→3DGV(45.89%)和直接 IMG→3DV(42.57%),说明平面扫描体积能更均衡地映射特征到 3D 空间,保留更多深度信息。
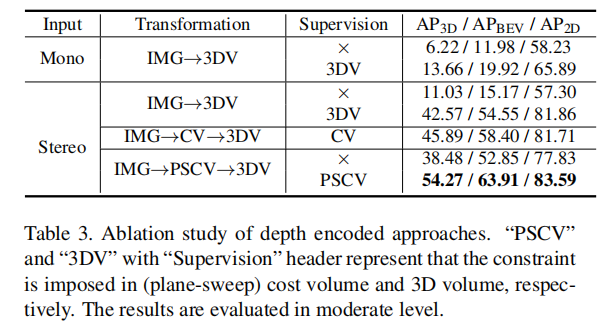
注:"PSCV" 表示在平面扫描代价体积上施加监督,"3DV" 表示在 3D 体积上施加监督。
4.4.2 深度估计的影响(表 4)
该实验对比了 DSGN 与 PSMNet-PSV*(修改为 1 个 3D 沙漏模块)的深度估计精度与检测性能,结论如下:
- 仅训练深度估计分支时,DSGN 的深度误差(均值 0.5279 米,中位数 0.1055 米)略优于 PSMNet-PSV*(均值 0.5337 米,中位数 0.1093 米),证明其 2D 特征提取器的有效性。
- 联合训练深度估计与 3D 检测时,两者的深度误差均略有上升,但 DSGN 的 3D AP(54.27%)比 PSMNet-PSV*(46.41%)高出 7.86 个百分点,说明 DSGN 的特征提取器能更好地平衡像素级匹配特征与高层语义特征。
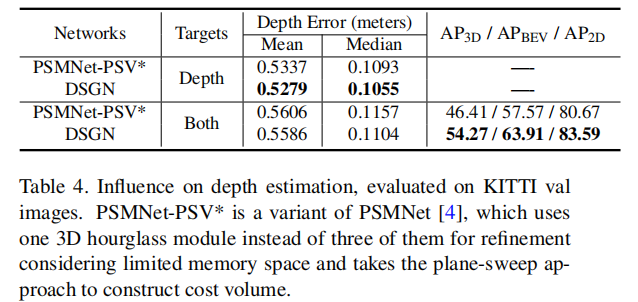
4.4.3 3D 几何表示的影响(表 6)
该实验探究了不同体素特征编码方式的性能,结论如下:
- "Last Features"(使用代价体积的最后一层特征映射到 3DGV)的性能最优(54.27% 3D AP),远超 "Occupancy"(二值体素占用,37.86%)和 "Probability"(体素占用概率,43.24%)。
- 证明潜特征嵌入能更有效地编码 3D 几何信息与语义线索,而显式的体素占用表示会丢失部分细节信息。
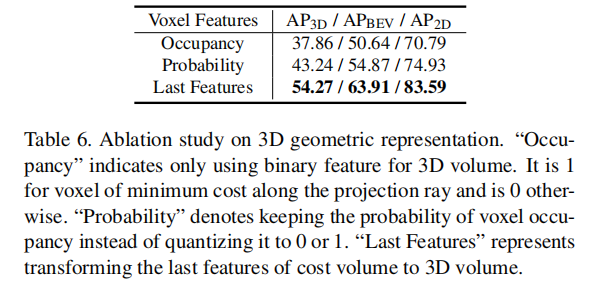
4.4.4 网络组件的影响(表 7)
该实验验证了各关键组件对性能的贡献,核心结论如下:
- 联合优化边界框角点(JOINT)比分离优化参数提升 4.80 个 3D AP。
- 图像特征加权注意力(ATT)能提升 1.01 个 3D AP,证明深度概率加权的语义特征融合有效。
- 3DGV 中加入沙漏模块(HG)和水平翻转增强(Flip)能进一步提升性能,最终达到 54.27% 的 3D AP。

注:"JOINT" 表示联合优化角点,"IMG" 表示拼接图像特征,"ATT" 表示深度概率加权注意力,"Depth" 表示 warp 代价体积,"HG" 表示 3D 沙漏模块,"Flip" 表示水平翻转增强。
4.5 补充实验分析
4.5.1 深度估计精度与检测性能的相关性(表 5、图 4)
实验发现,当深度误差阈值为 0.3 米时,深度估计精度与检测性能的皮尔逊相关系数(PCC)最高(0.450),说明适度的深度误差可通过 3D 检测网络的回归分支补偿,端到端训练能有效缓解深度估计误差对检测性能的影响。

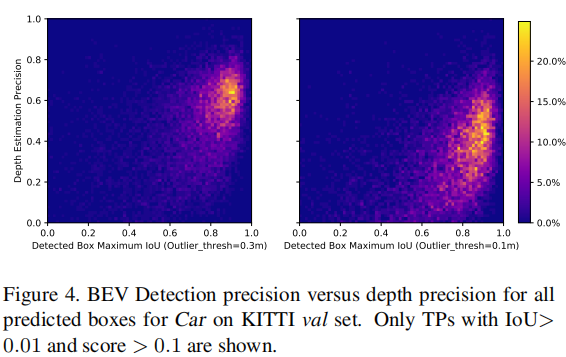
注:左图为误差阈值 0.3 米,右图为 0.1 米,仅显示 IoU>0.01 且得分 > 0.1 的真阳性样本。
4.5.2 目标距离对检测性能的影响(图 5)
随着目标距离增加,3D AP、BEV AP 和 2D AP 均呈下降趋势,其中 3D AP 下降最快,2D AP 下降最慢。在 25 米范围内,平均检测精度保持 80% 以上,证明 DSGN 在近距离场景(如低速自动驾驶)中表现优异;超过 20 米后,BEV 定位精度成为影响 3D 检测性能的关键。
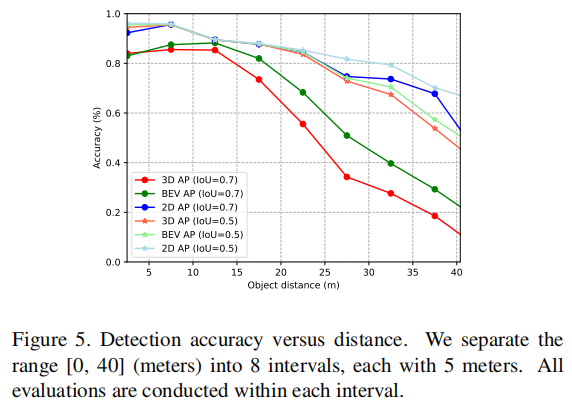
注:将距离范围 0,40 米分为 8 个区间,每个区间 5 米,分别计算各精度指标。
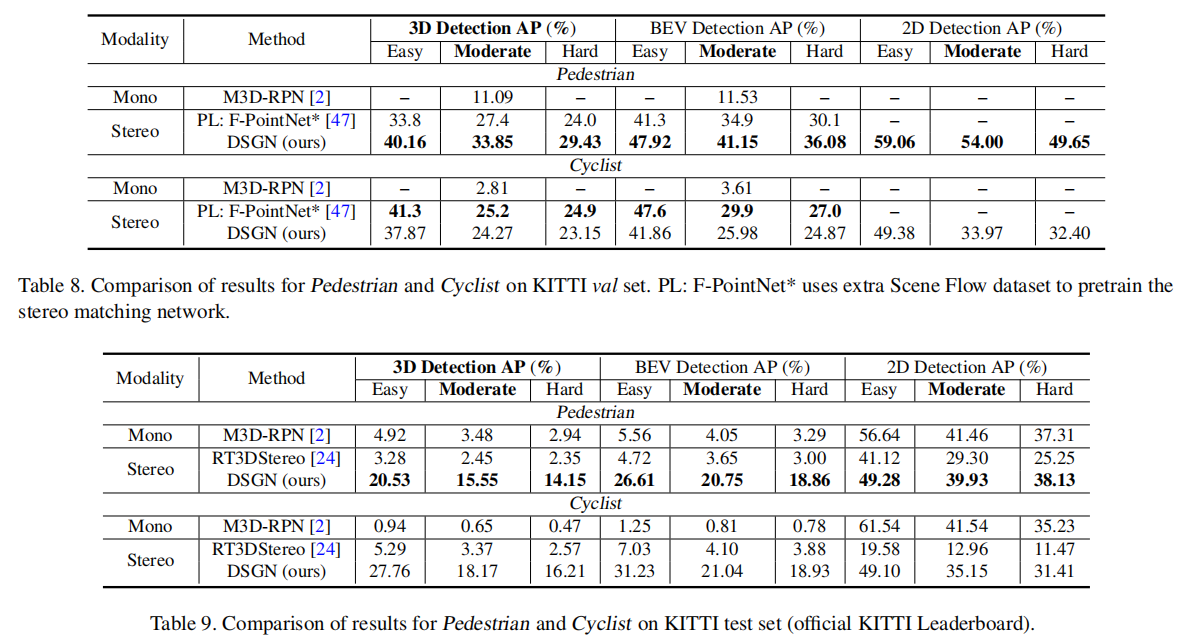
4.5.3 行人和自行车检测结果(表 8、表 9)
DSGN 在行人检测上表现优于 Pseudo-LiDAR(33.85% vs 27.4% 3D AP),但在自行车检测上略逊(24.27% vs 25.2%),主要原因是自行车的姿态变化更复杂,且标注数据有限。在 KITTI 测试集上,DSGN 的行人 3D AP(15.55%)和自行车 3D AP(18.17%)仍领先于其他立体视觉 - based 方法。
五、结论与未来展望
5.1 主要结论
DSGN 提出了一种基于立体视觉的端到端 3D 目标检测框架,通过创新的平面扫描体积(PSV)与 3D 几何体积(3DGV)的可微转换,在 3D 规则空间中统一编码几何信息与语义特征,实现了深度估计与 3D 检测的联合优化。该方法无需额外数据集预训练,以简洁的单网络架构超越了所有现有立体视觉 - based 方法,在 KITTI 数据集上达到了与部分 LiDAR-based 方法相当的性能,为低成本 3D 感知系统提供了高效解决方案。
5.2 未来工作方向
- 缩小与顶尖 LiDAR-based 方法的差距:当前 DSGN 在 BEV 检测的 Moderate 和 Hard 难度下与顶尖 LiDAR 方法仍有 12 个 AP 的差距,未来可结合高分辨率立体匹配技术,提升远距离、遮挡目标的深度估计精度。
- 3D 体积构建的深入研究:现有体积转换机制的理论基础仍需进一步探索,如何更高效地平衡深度信息与语义信息,以及多视图图像的体积构建方法,值得深入研究。
- 计算效率优化:3D 卷积是当前的计算瓶颈,未来可借鉴稀疏卷积、动态卷积等高效算子,或通过网络架构搜索(NAS)平衡性能与速度。
- 低速自动驾驶应用:DSGN 在近距离场景下的性能已接近 LiDAR-based 方法,且硬件成本更低(Tesla V100 约 1.1 万美元 vs LiDAR 7.5 万美元),未来可针对低速场景(如园区物流、港口调度)进行定制化优化,推动实际应用落地。
六、总结
DSGN 通过创新的 3D 几何体积表示与端到端联合优化,有效解决了基于图像的 3D 目标检测中几何信息缺失、深度与语义融合困难等核心问题,显著缩小了与 LiDAR-based 方法的性能差距。其设计思路为后续研究提供了重要借鉴:在 2D 图像与 3D 空间之间构建可微的中间表示,充分利用立体视觉的像素匹配约束,是提升图像 - based 3D 检测性能的关键。随着硬件计算能力的提升与算法的持续优化,基于立体视觉的 3D 目标检测有望在更多实际场景中替代 LiDAR,推动自动驾驶与机器人技术的规模化应用。