前言
在当今的软件工程领域,将大型语言模型(LLM)集成至本地开发环境已成为提升生产效率的关键路径。Claude Code 作为 Anthropic 推出的新一代命令行辅助工具,具备深度理解代码库与执行系统操作的能力。而 DeepSeek V3.2 作为当前表现优异的模型,通过兼容 OpenAI 协议的 API 接口,能够为 Claude Code 提供强大的推理后端。
本文将详细阐述如何在 Ubuntu 环境下,从零构建基于 Claude Code 的智能终端开发环境。该环境将通过配置底层依赖、部署 Node.js 运行时、安装 CLI 工具以及进行复杂的环境变量注入,最终实现将 API 请求重定向至蓝耘(Lanyun)提供的 DeepSeek V3.2 服务端点。整个过程涵盖了系统运维、Shell 脚本编写、Python 接口调用以及 API 鉴权机制等多个技术维度。
第一阶段:底层系统环境构建
开发环境的稳定性始于操作系统的基础状态。在进行上层应用部署前,必须确保操作系统的包索引与核心构建工具处于最新状态。这不仅是为了获取最新的安全补丁,更是为了解决后续编译 Node.js 本地模块或 Python 扩展库时可能遇到的依赖缺失问题。
首先,通过 APT 包管理器更新本地软件源索引,并对已安装的软件包进行升级。紧接着,安装 curl(用于网络请求)、git(用于版本控制)、build-essential(包含 GCC/G++ 编译器及 Make 工具)以及 libssl-dev(SSL 开发库)。这些是现代 Web 开发与后端构建不可或缺的基础设施。
bash
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git build-essential libssl-dev执行上述指令后,APT 包管理器会解析依赖树并下载相应的数据包。终端窗口将实时滚动显示解压与安装的进度。待所有进程执行完毕,即意味着系统底层库已准备就绪,可以支持后续的高级运行时环境部署。
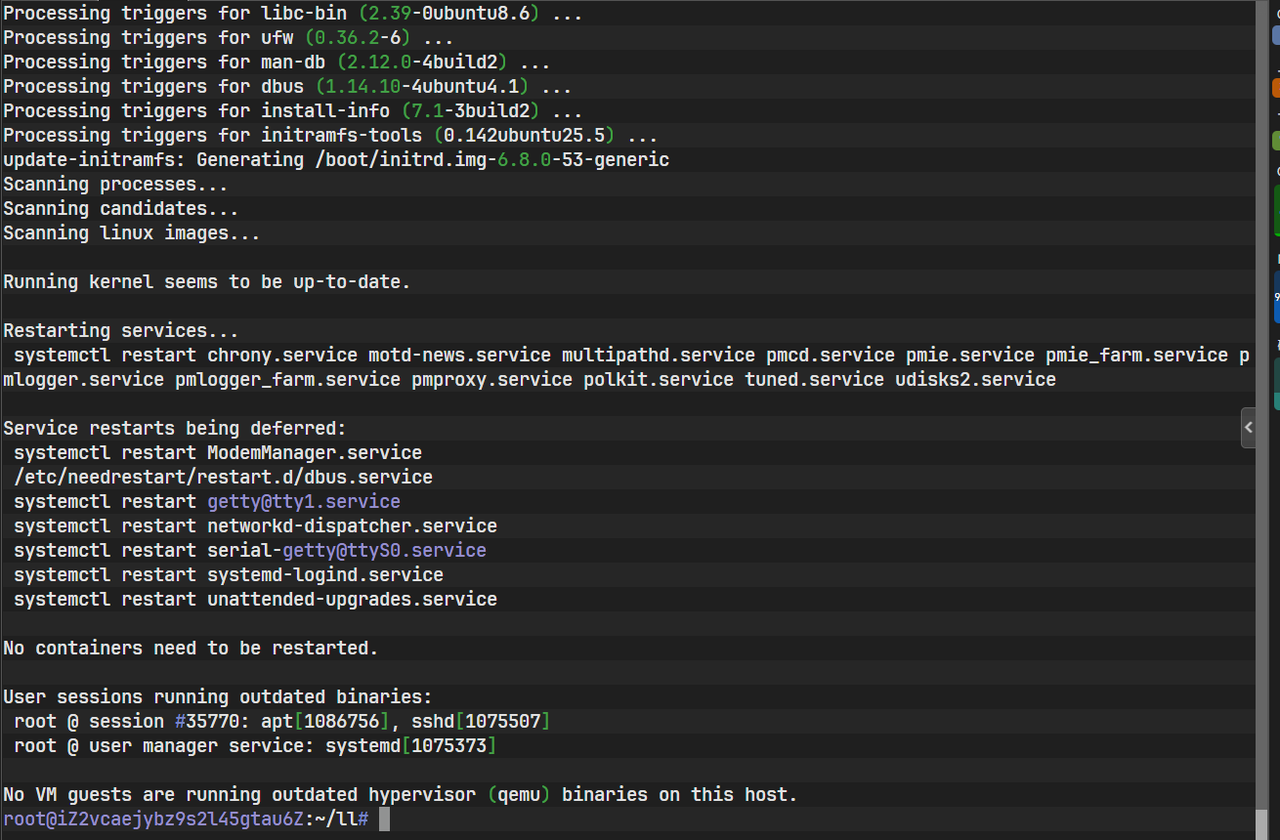
上图展示了基础依赖包安装完成后的终端状态。可以看到,系统成功处理了包括 build-essential 在内的多个核心组件,未报告任何依赖冲突或锁文件错误,为后续步骤奠定了坚实基础。
第二阶段:Node.js 运行时环境部署
Claude Code 本质上是一个基于 JavaScript/TypeScript 生态构建的工具,因此 Node.js 运行时环境是其运行的先决条件。Ubuntu 默认软件源中的 Node.js 版本往往滞后于官方发布的长期支持版(LTS),这可能导致新版 CLI 工具出现兼容性问题。因此,采用 NodeSource 提供的二进制分发源是更佳的实践方案。
通过 curl 获取 Node.js 20.x 版本的安装脚本,并通过管道传递给 bash 执行。该脚本会自动配置 GPG 密钥并将 NodeSource 仓库添加至系统的源列表中。随后,再次调用 apt-get 安装 nodejs 包。
Bash
curl -sL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt-get install -y nodejs该操作将同时安装 Node.js 运行时及其配套的包管理器 npm。npm 对于后续拉取和管理 Claude Code 至关重要。

上图记录了通过 NodeSource 脚本配置源并完成安装的过程。系统正确识别了安装源,并完成了二进制文件的解压与链接。安装结束后,必须对环境进行验证,以确保 PATH 环境变量已正确更新且二进制文件可执行。通过查询版本号指令,可以确认当前环境的具体状态。
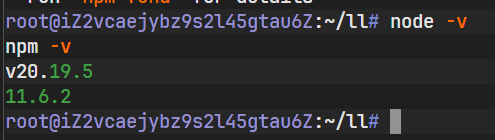
如上图所示,终端输出了 Node.js 的版本号。具体的版本号标识表明 JavaScript 运行时环境已完全就绪,可以开始承载基于 Node.js 的应用程序。
第三阶段:Claude Code 工具安装与初始化
Claude Code 是连接开发者与大模型的桥梁。由于其设计为系统级命令行工具,需要使用 npm 的全局安装模式(-g 标志),以便将 claude 命令注册到系统的 /usr/bin 或 /usr/local/bin 路径下,使其在任何目录下均可被调用。
bash
npm install -g @anthropic-ai/claude-code执行安装命令后,npm 会从注册表中拉取 @anthropic-ai/claude-code 包及其所有依赖项。
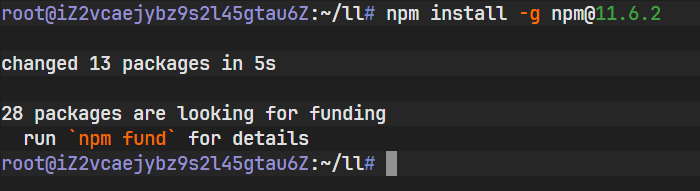
安装过程完成后,终端会显示已添加的包数量及耗时。此时,虽然二进制文件已存在于文件系统中,但由于尚未配置后端服务连接信息,直接运行工具会导致连接失败。Claude Code 默认尝试连接 Anthropic 的官方 API,而在未提供凭证或需重定向至第三方模型服务(如蓝耘提供的 DeepSeek)时,必须进行显式的配置。
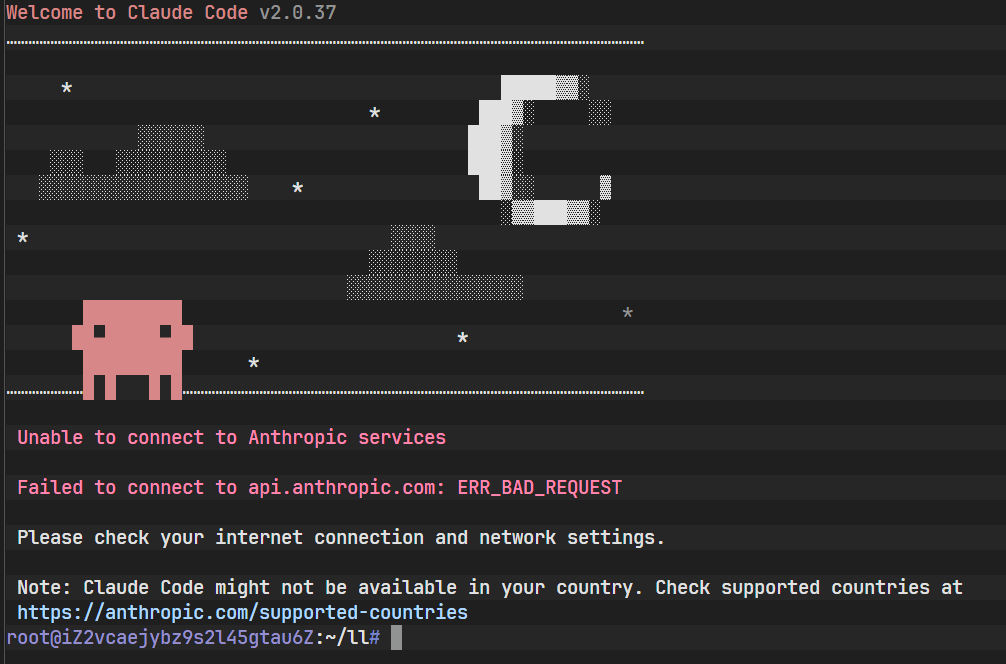
上图展示了首次尝试运行 claude 命令时的报错信息。系统提示连接错误或未授权,这验证了工具本身已安装成功,但缺乏必要的网络配置与鉴权信息。这引入了环境搭建中最关键的环节------环境变量配置。
第四阶段:API 网关配置与鉴权机制
为了让 Claude Code 能够调用蓝耘托管的 DeepSeek V3.2 模型,必须通过环境变量覆盖其默认的 API 端点(Base URL)和认证机制。这种设计允许工具在不修改源码的情况下,灵活适配兼容 OpenAI 接口规范的各类后端服务。
首先,需要访问蓝耘控制台获取 API 密钥(API Key)。该密钥是验证用户身份及计费的唯一凭证。
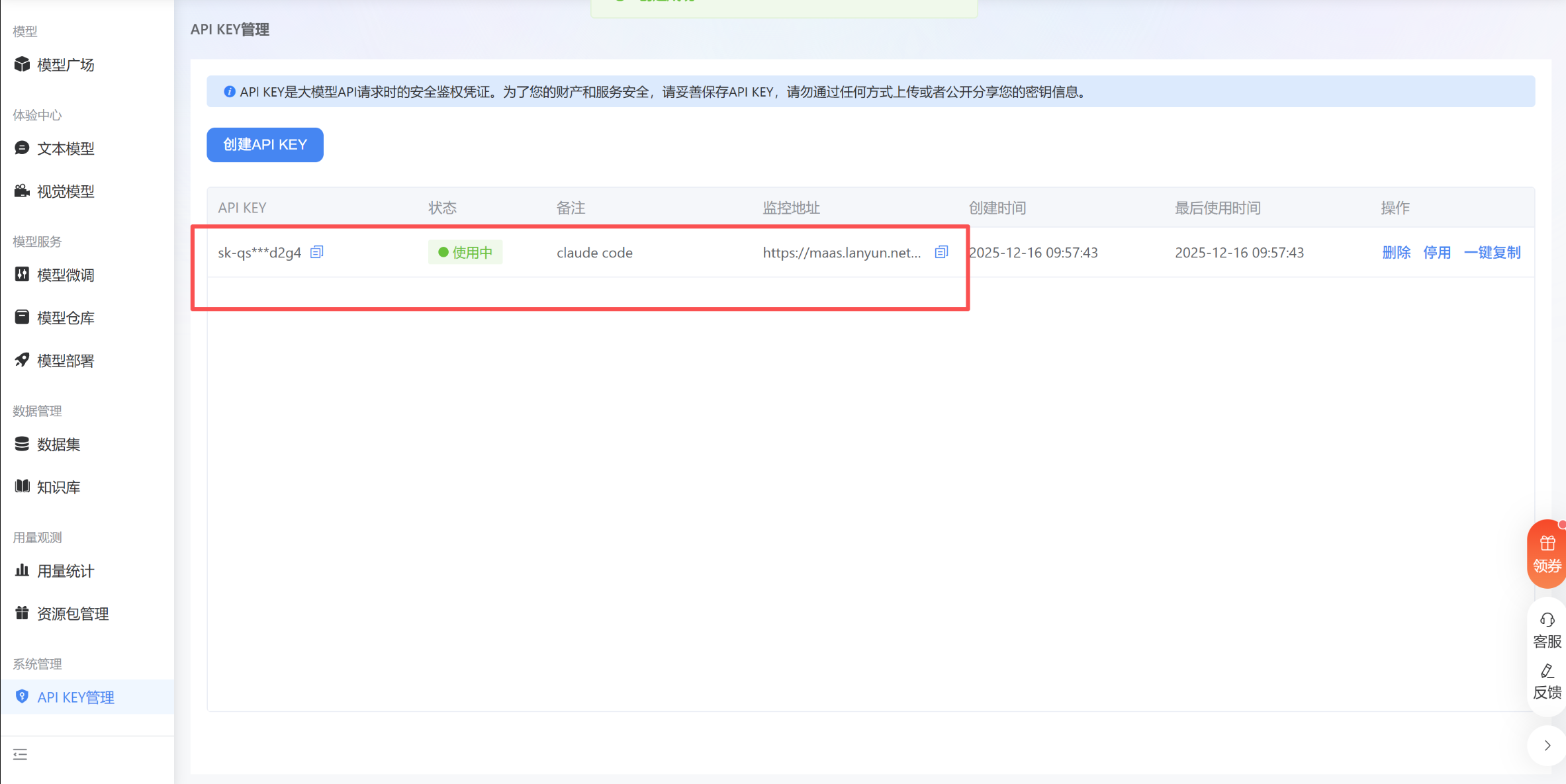
获取密钥后,需要将其注入到用户的 Shell 配置文件中。对于 Bash Shell,通常编辑 ~/.bashrc 文件。需要配置三个核心环境变量:
ANTHROPIC_BASE_URL: 必须指向蓝耘提供的兼容接口地址,例如https://maas-api.lanyun.net/anthropic-k2/。此变量告知 Claude Code 将请求发送至何处。ANTHROPIC_AUTH_TOKEN: 填入获取到的sk-开头的密钥字符串,用于通过服务端的鉴权校验。ANTHROPIC_MODEL: 指定具体的模型标识符,此处使用/maas/deepseek-ai/DeepSeek-V3.2,确保请求被路由至正确的 DeepSeek 模型实例。
Bash
echo 'export ANTHROPIC_BASE_URL="https://maas-api.lanyun.net/anthropic-k2/"' >> ~/.bashrc
echo 'export ANTHROPIC_AUTH_TOKEN="[您的密钥]"' >> ~/.bashrc
echo 'export ANTHROPIC_MODEL="/maas/deepseek-ai/DeepSeek-V3.2"' >> ~/.bashrc通过 echo 和重定向符号 >> 将上述配置追加至配置文件末尾,可确保配置的持久化,即使用户退出终端或重启系统,配置依然有效。
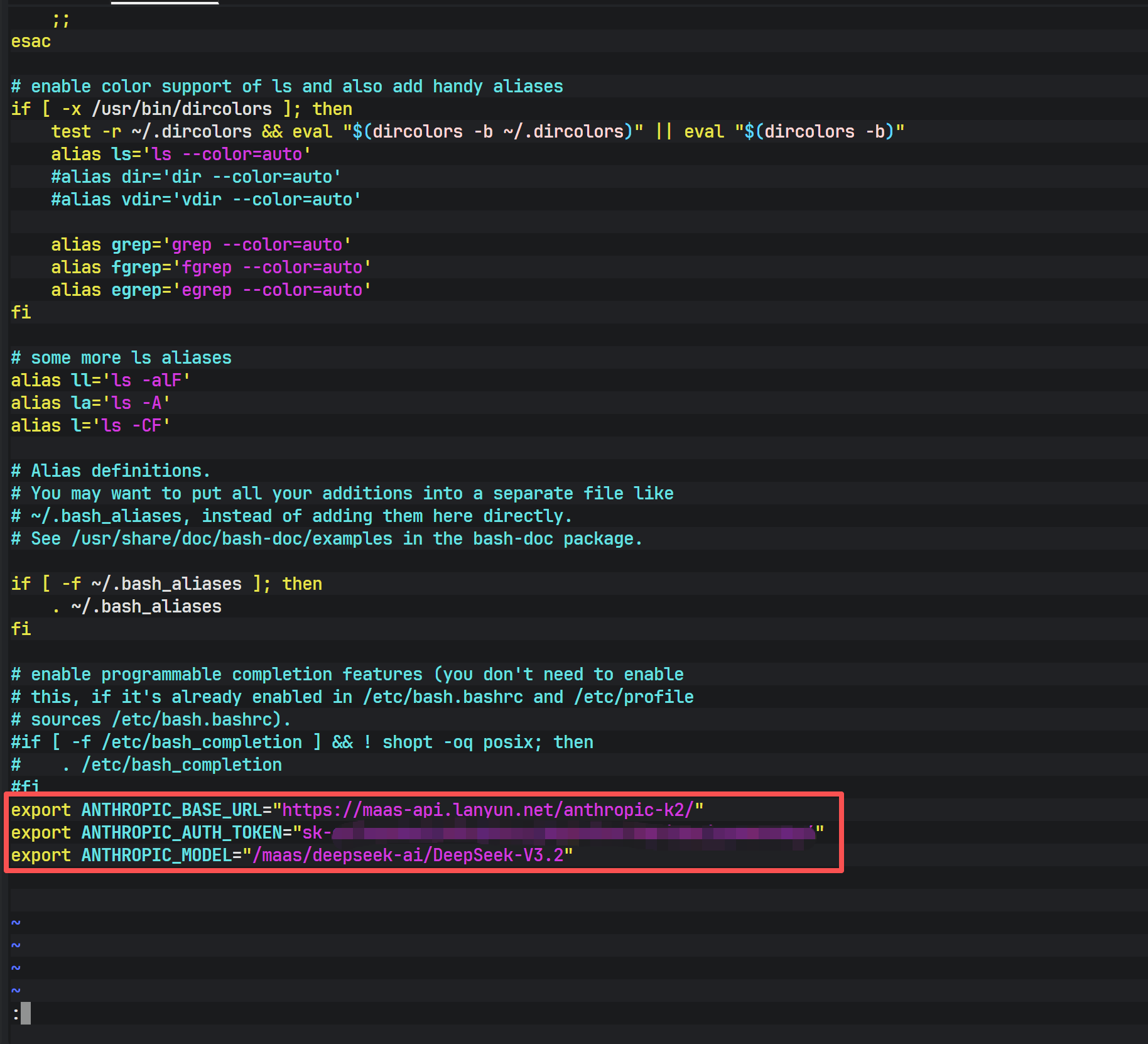
上图展示了编辑后的 .bashrc 文件内容,可以清晰地看到三条 export 语句已被正确写入文件末尾。为了确认环境变量是否已正确加载到当前 Shell 会话中,可以使用 env 命令进行检查。但在检查前,必须执行 source ~/.bashrc 使更改立即生效。
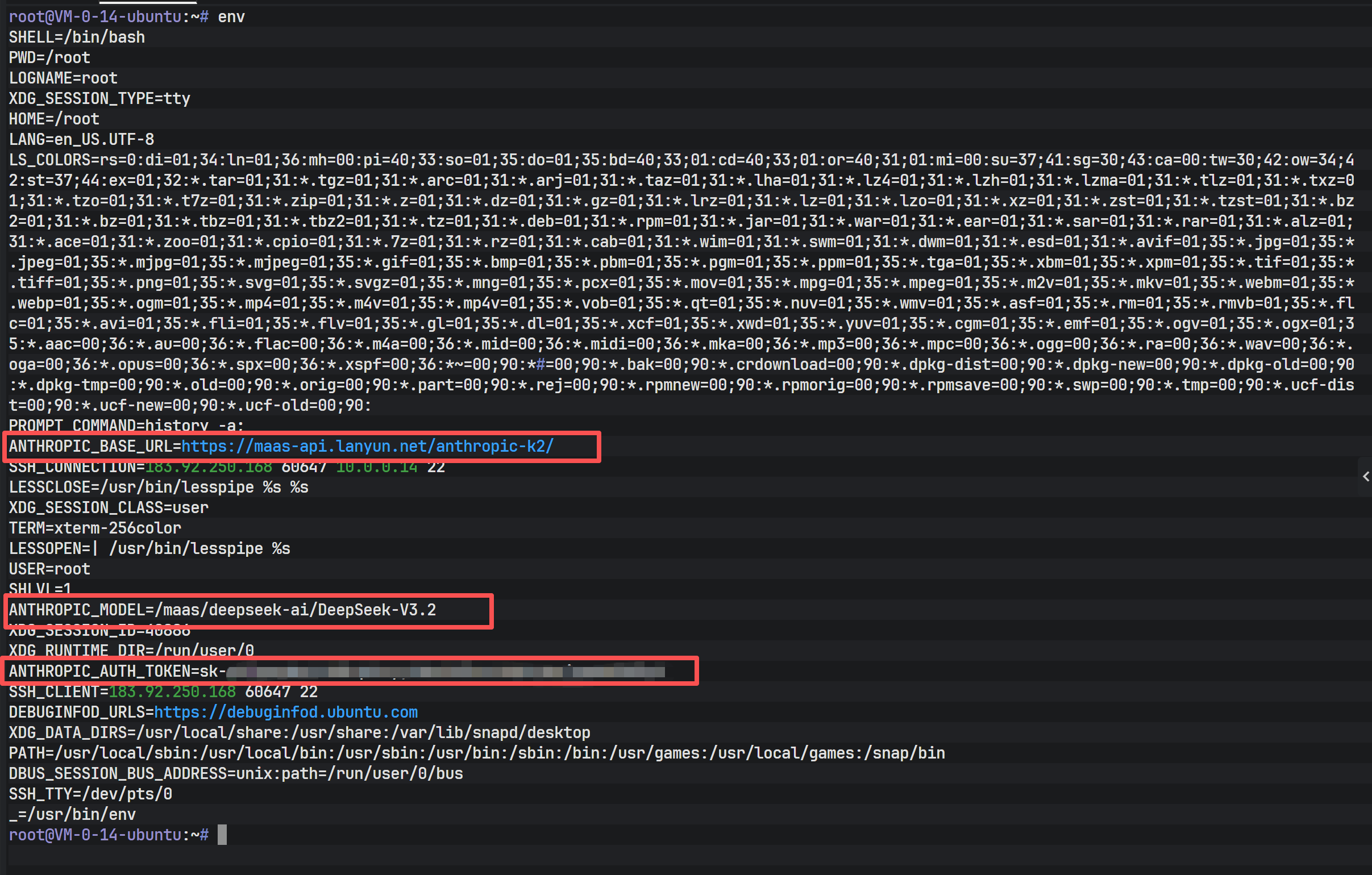
通过 env 命令输出的环境变量列表如上图所示,系统中已存在 ANTHROPIC_ 开头的相关配置,且值与设定一致。此时,Claude Code 已具备了与服务端通信的所有必要条件。
再次运行 claude 命令,系统将不再报错,而是进入初始化流程或交互界面。对于首次运行,可能会提示用户确认工作目录的信任设置。
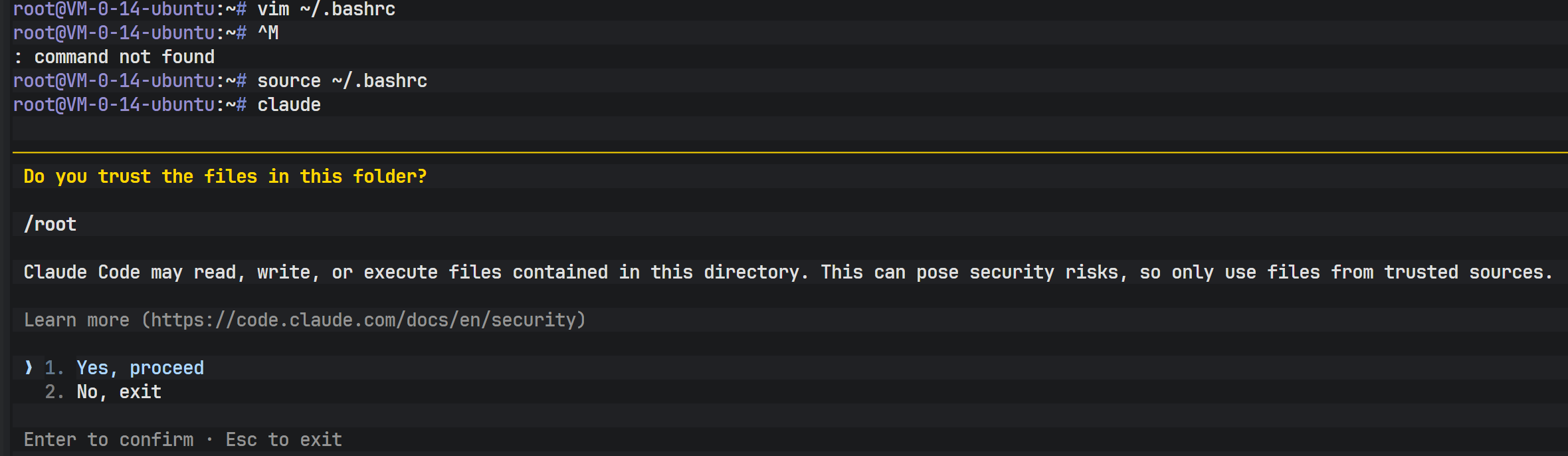
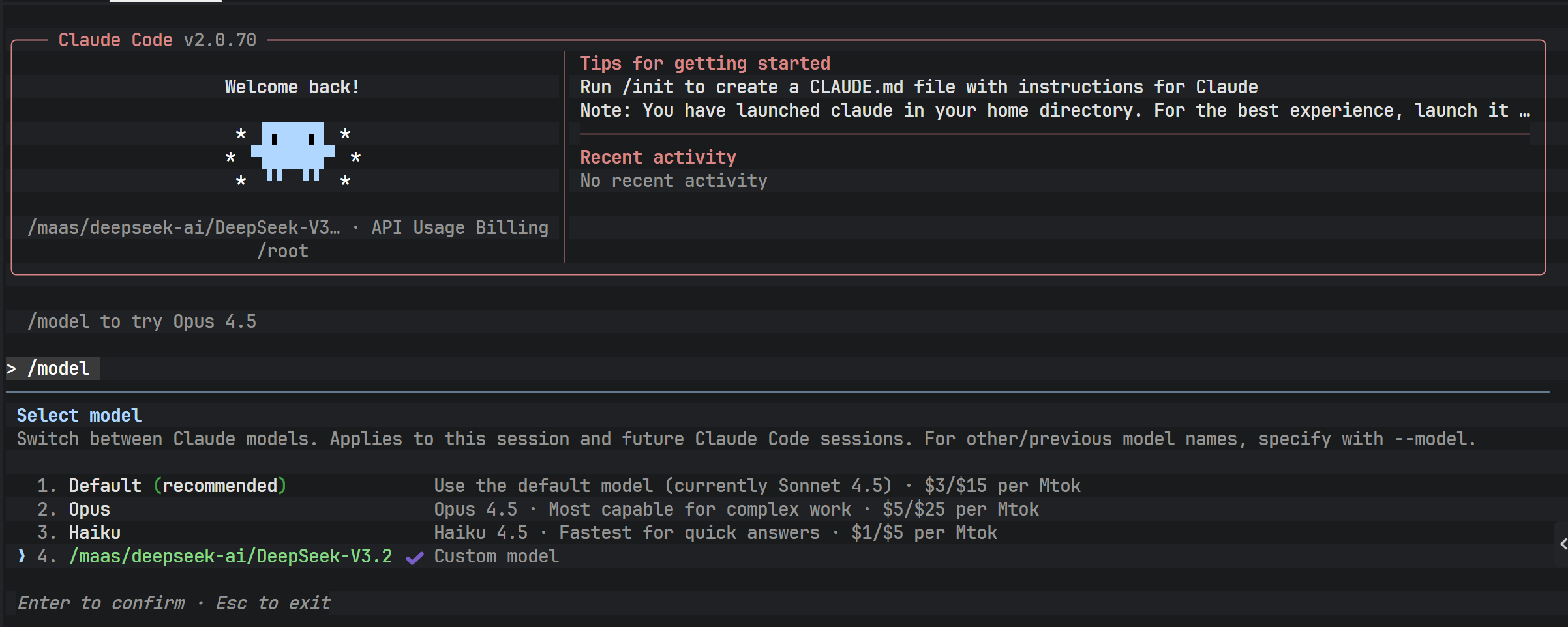
在成功连接后,可以通过工具内置的命令查看当前配置的模型信息。确认模型标识符与配置文件中的设定一致,标志着 API 路由已成功指向 DeepSeek V3.2。
第五阶段:自动化部署脚本的实现
在多台服务器或不同环境中重复上述手动配置步骤效率低下且容易出错。为此,编写一个自动化 Shell 脚本(install.sh)是标准化的解决方案。该脚本集成了环境检测、依赖安装、用户交互以及配置文件修改等全套逻辑。
脚本首先定义了 install_nodejs 函数,根据操作系统类型(Linux/Darwin)自动选择安装方式,通过 nvm(Node Version Manager)安装特定版本的 Node.js。随后,脚本会检查当前系统中是否已存在 Node.js 及其版本是否满足最低要求(v18+)。如果未满足,将触发升级或安装流程。
对于 Claude Code 本身,脚本同样会检测其安装状态。在配置环节,脚本通过 read -s 命令安全地获取用户输入的 API Key,避免密钥在屏幕上明文显示。接着,脚本利用 sed 命令对 .bashrc 或 .zshrc 等配置文件进行幂等性操作:先检测是否存在旧的配置,若存在则删除,随后追加新的环境变量。这种处理方式防止了配置文件中出现重复的 export 语句。
bash
./install.sh执行该脚本后,终端将引导用户完成整个配置流程。
上图展示了运行安装脚本时的交互界面,脚本自动识别了 Node.js 环境并跳过了重复安装,随后提示用户输入 API 密钥。
第六阶段:开发实战与 API 调用测试
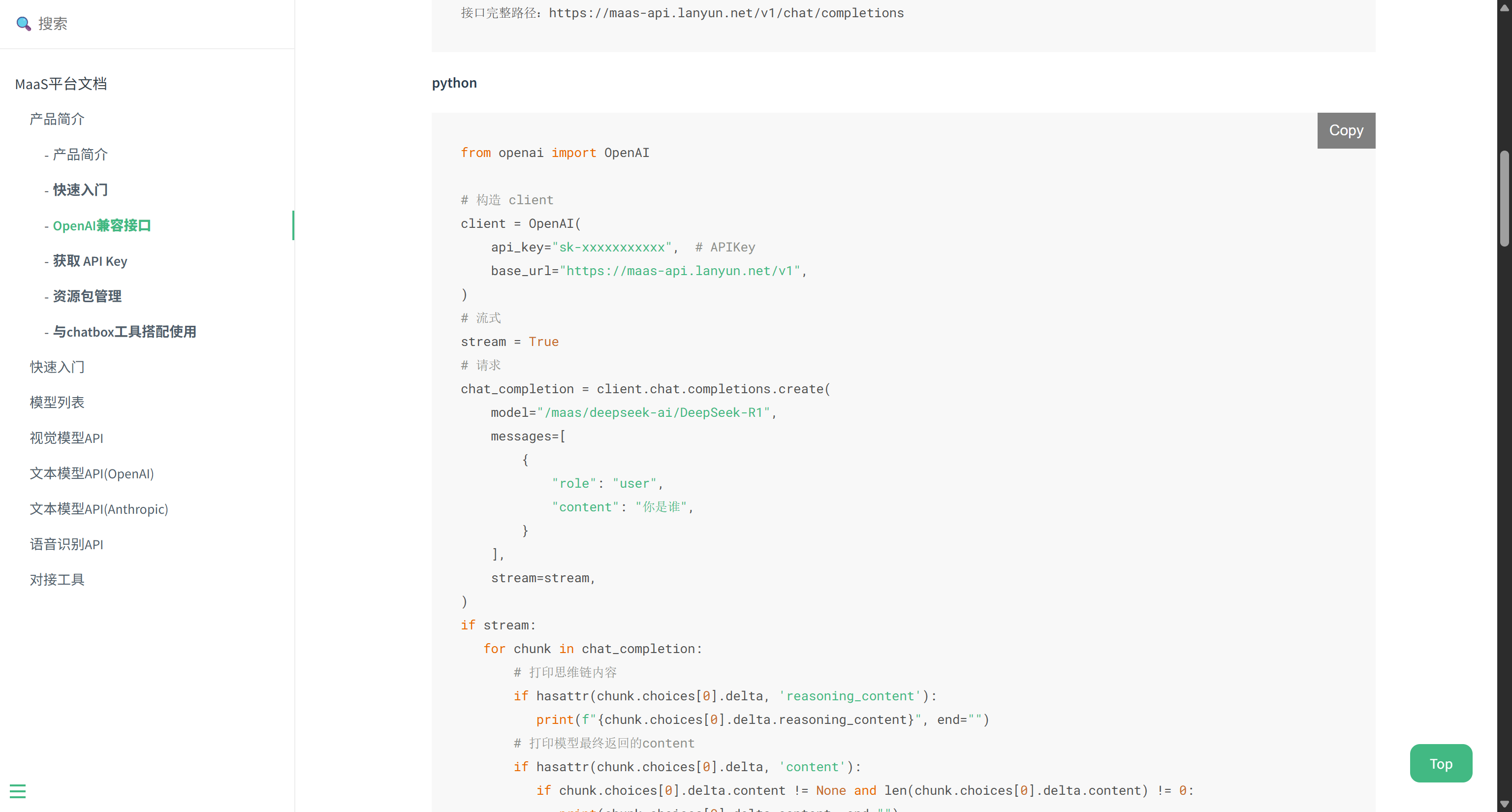
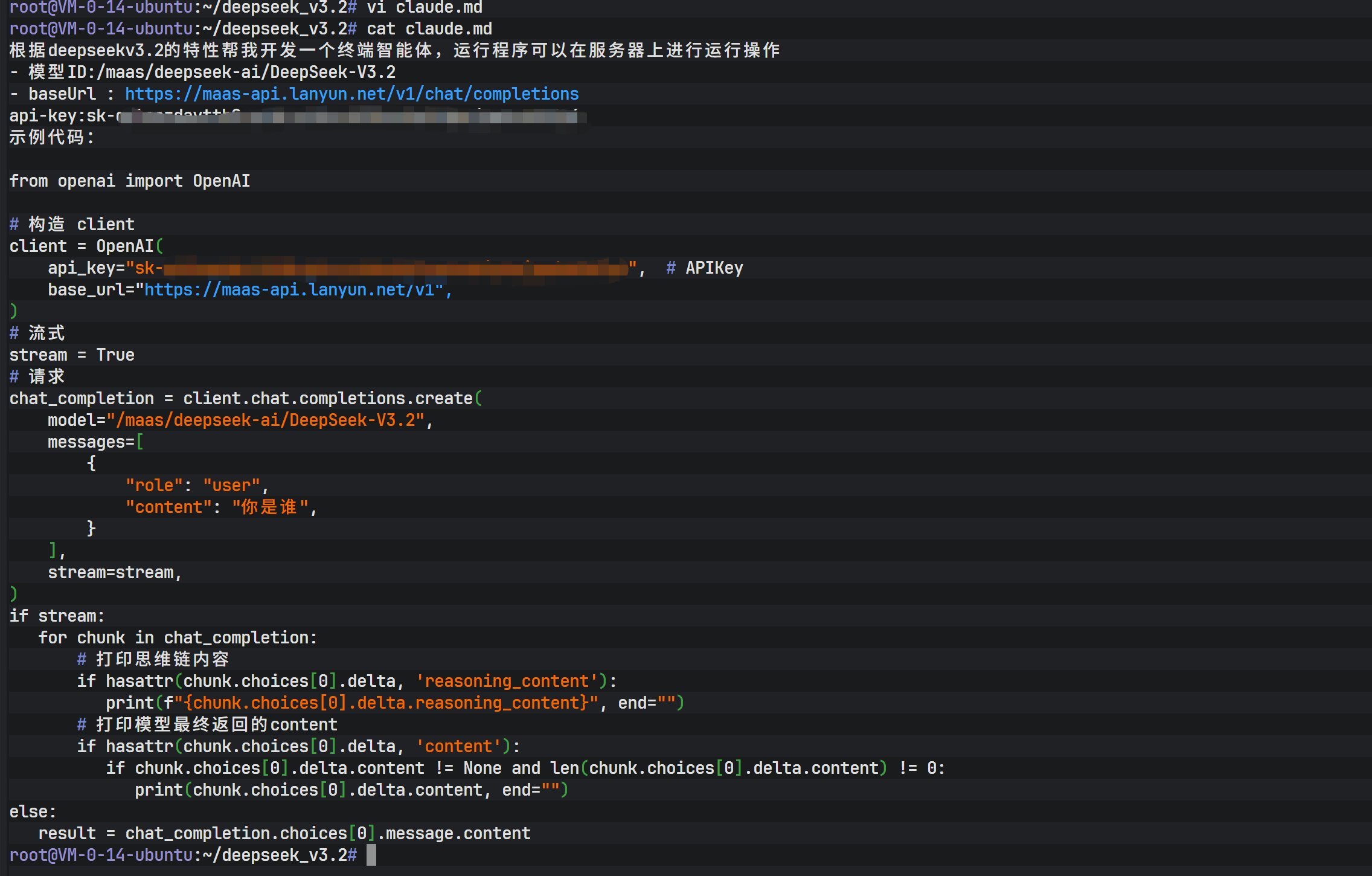
环境配置完成后,进入实际开发阶段。首先创建一个独立的项目文件夹,并初始化一个测试任务。为了验证 DeepSeek V3.2 的编程能力,可以编写一个 claude.md 文件,详细描述开发需求。需求中明确指定了模型 ID、Base URL 以及 API Key 的格式,并提供了一个基于 OpenAI Python SDK 的流式调用示例代码。
该示例代码展示了如何构造 OpenAI 客户端对象,将 base_url 指向蓝耘 API 网关。代码核心演示了流式(Streaming)响应的处理逻辑:通过遍历 chat_completion 生成器,实时获取并打印模型的思维链内容(reasoning_content)和最终回复内容(content)。这种流式处理对于构建低延迟的 AI 应用至关重要。
bash
根据deepseekv3.2的特性帮我开发一个终端智能体,运行程序可以在服务器上进行运行操作
- 模型ID:/maas/deepseek-ai/DeepSeek-V3.2
- baseUrl : https://maas-api.lanyun.net/v1/chat/completions
api-key:sk-*********************************
示例代码:
from openai import OpenAI
# 构造 client
client = OpenAI(
api_key="sk-xxxxxxxxxxx", # APIKey
base_url="https://maas-api.lanyun.net/v1",
)
# 流式
stream = True
# 请求
chat_completion = client.chat.completions.create(
model="/maas/deepseek-ai/DeepSeek-R1",
messages=[
{
"role": "user",
"content": "你是谁",
}
],
stream=stream,
)
if stream:
for chunk in chat_completion:
# 打印思维链内容
if hasattr(chunk.choices[0].delta, 'reasoning_content'):
print(f"{chunk.choices[0].delta.reasoning_content}", end="")
# 打印模型最终返回的content
if hasattr(chunk.choices[0].delta, 'content'):
if chunk.choices[0].delta.content != None and len(chunk.choices[0].delta.content) != 0:
print(chunk.choices[0].delta.content, end="")
else:
result = chat_completion.choices[0].message.contentClaude Code 工具将读取该 Markdown 文件中的指令,并尝试执行相关的开发任务。
上图展示了将需求文档传递给 Claude Code 后的初始状态。紧接着,通过自然语言与 Claude Code 进行交互,指令其根据文档内容生成实际的代码文件。
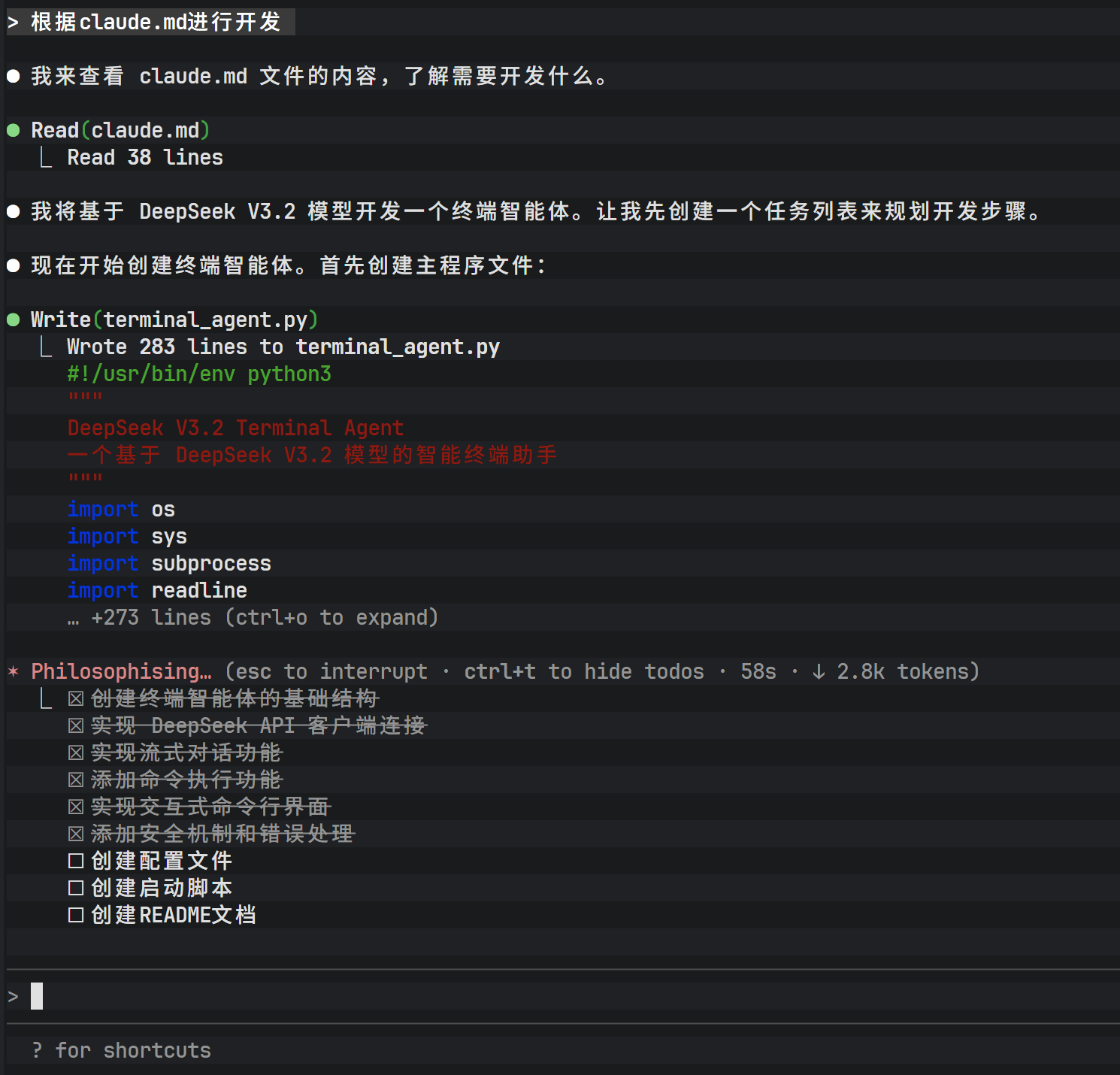
在交互过程中,Claude Code 会分析需求并列出计划创建的文件。用户需确认操作(输入 Yes),工具即开始在文件系统中生成代码。
生成过程完成后,可以看到主体 Python 代码文件已被写入磁盘。此时,DeepSeek 模型不仅生成了逻辑代码,还根据上下文推断出了可能需要的辅助文件。
为了使生成的脚本可执行,通常需要修改文件权限。Claude Code 具备执行 shell 命令的能力,可以直接处理 chmod 操作。
此外,完善的项目还需要文档支持。指令 Claude Code 生成 README.md 文件,它会自动根据代码逻辑生成项目说明、安装步骤及使用方法。
整个执行流程体现了极高的响应速度,这得益于蓝耘 API 的低延迟特性与 DeepSeek 模型的高效推理能力。
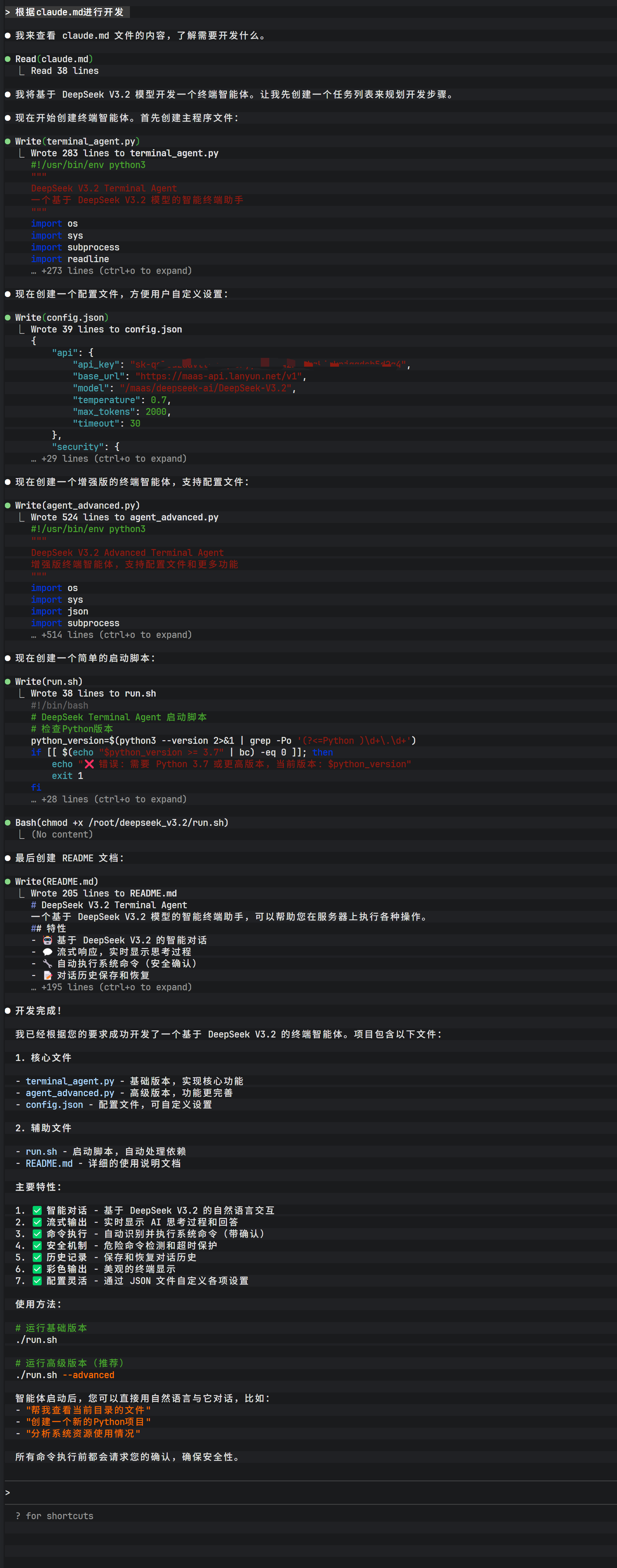
在项目目录中,可以找到生成的 run.sh 启动脚本。这是一个封装好的入口,用于启动刚才生成的智能体程序。
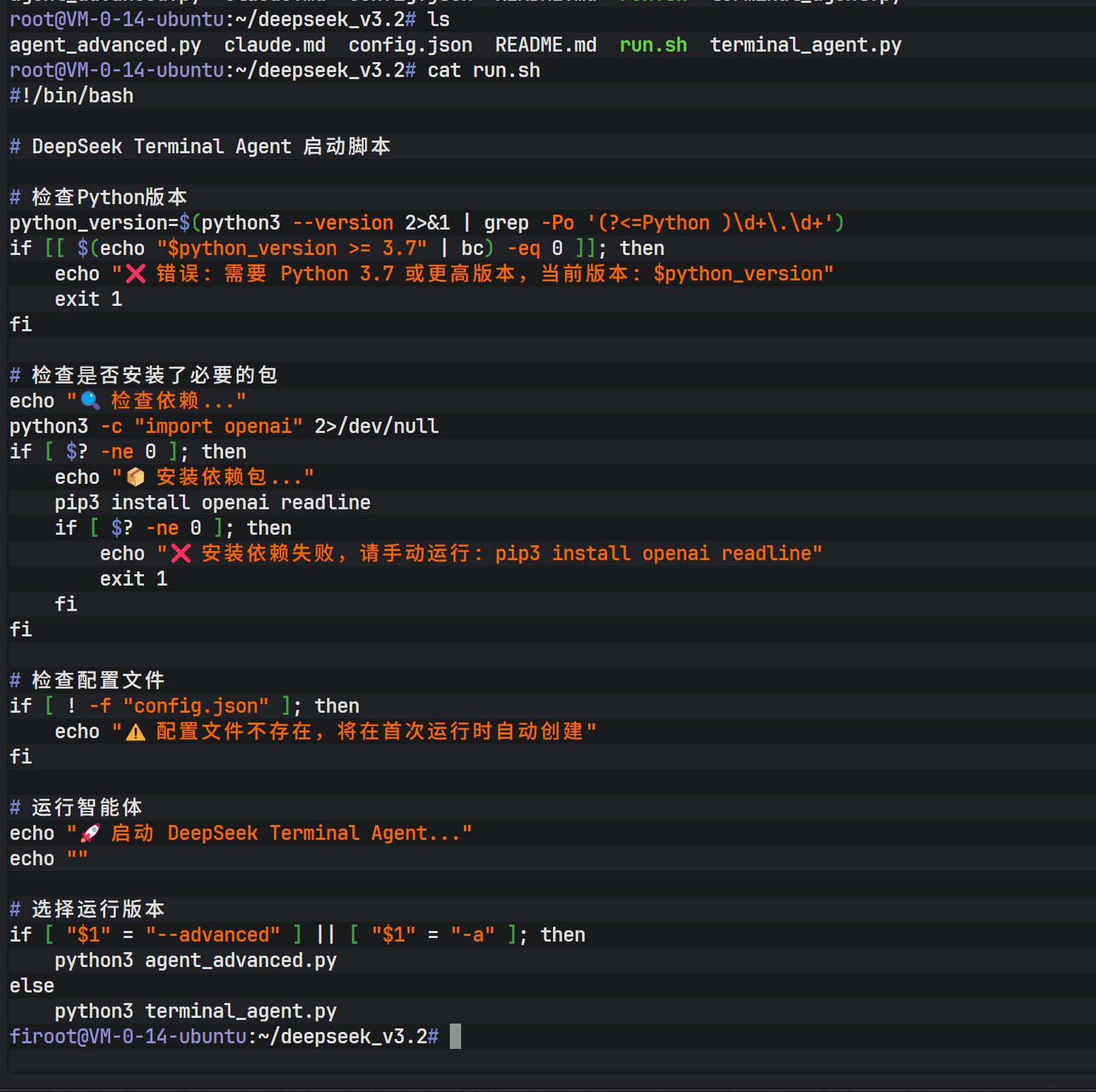
第七阶段:终端智能体的运行与扩展
在直接运行生成的 Python 程序之前,需要确保 Python 环境中安装了必要的依赖库。根据生成的代码分析,主要依赖包括 openai(用于 API 调用)和 readline(用于改善终端输入体验)。
bash
apt install python3-pip
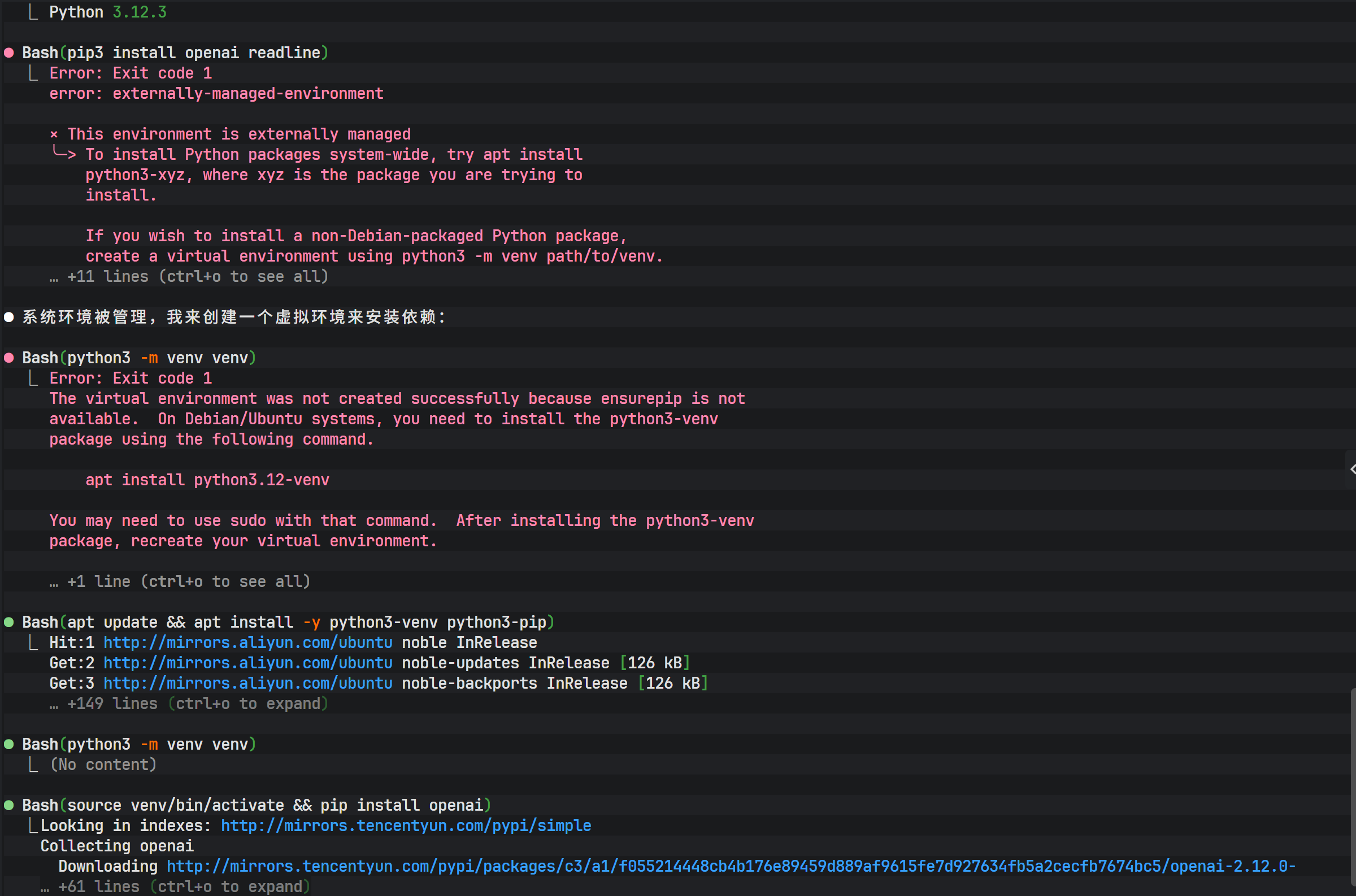
pip install openai readline如果遇到依赖安装报错,可以再次利用 Claude Code 的能力,让 AI 分析错误日志并自动执行修复命令。这种"AI 修复 AI 环境"的模式极大地降低了运维门槛。
依赖解决后,启动终端智能体。界面呈现出一个交互式的对话环境,类似于 Claude 的原生界面,但其核心驱动力来自 DeepSeek V3.2。
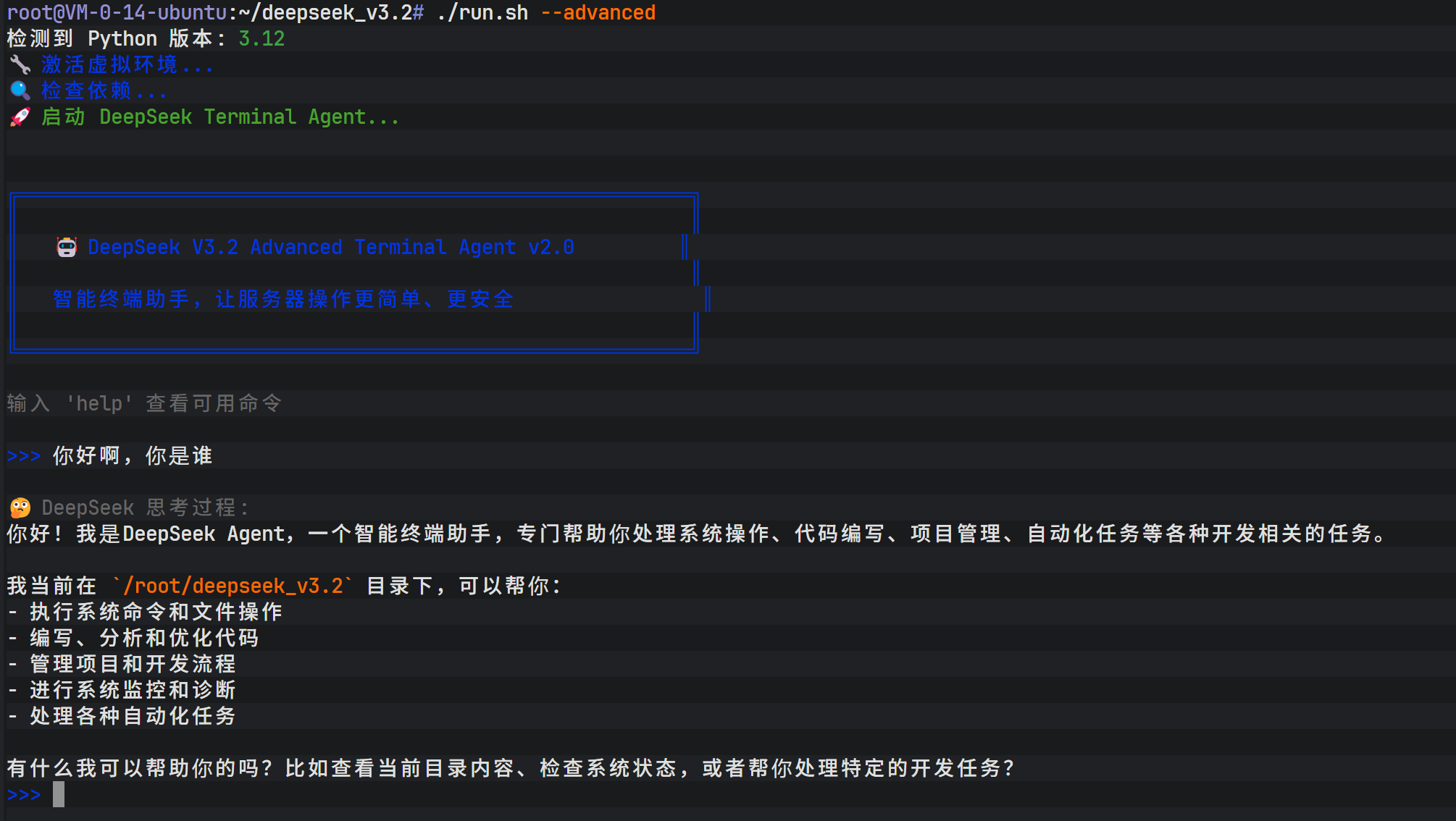
在该智能体中,可以下达复杂的编程任务,例如"生成一个 HTTP 的 C++ 代码"。模型不仅会生成 C++ 源代码,还会提供编译指令,甚至在允许的情况下直接进行编译测试。
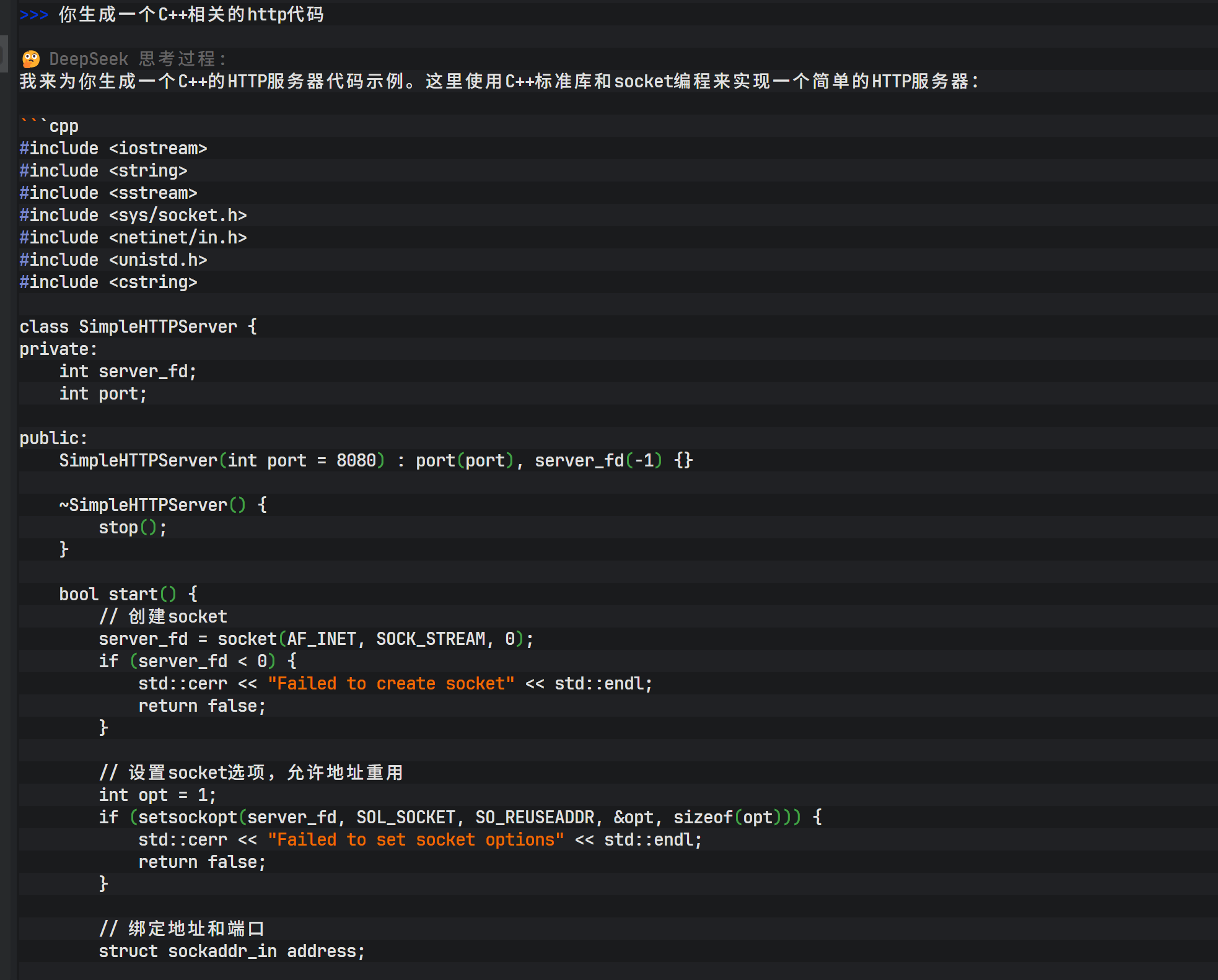
除了代码生成,该智能体还具备创意写作能力。例如输入"帮我写一个产品推广短视频脚本,产品是牛奶",模型会迅速生成包含分镜描述、旁白文案及背景音乐建议的完整脚本。

DeepSeek V3.2 的输出不仅包含最终结果,还展示了详细的思考过程(Thinking Process),这有助于用户理解模型是如何构建逻辑的。脚本内容涵盖了多个版本(温馨家庭篇、活力运动篇、情感故事篇),并针对不同社交平台提供了拍摄建议,展现了模型在多模态场景描述上的深度。
总结
通过上述七个阶段的详细实施,一个基于 Ubuntu、集成 Claude Code 与 DeepSeek V3.2 的高效终端开发环境便构建完成。该环境不仅能够自动化处理繁琐的编码任务,还通过标准化的 API 接口保留了极强的扩展性,为未来的 AI 辅助开发探索提供了无限可能。
bash
https://console.lanyun.net/#/register?promoterCode=0131