在嵌入式智能领域,从人类演示中学习机器人操作是主流范式,但人类手部与不同形态机器人手(如2指、3指、5指)之间的形态差异鸿沟,成为技术落地的核心障碍:
基于动作重定向的方法仅映射运动学姿态,忽略动态信息;
传统模仿学习局限于复制人类动作,因手指数量、自由度等物理差异,任务性能远低于人类水平;
现有强化学习方法存在两难:要么依赖人类轨迹导致策略无法适配机器人自身形态,要么完全脱离人类先验陷入局部最优;
缺乏统一框架,多数方法仅针对特定机器人手设计,无法泛化到多样化形态。
UniBYD核心目标是构建一种学习范式:突破单纯的人类动作模仿,让机器人自主发现与自身物理特性匹配的操作策略,实现跨形态机器人手的高效泛化。
核心创新:UniBYD框架设计
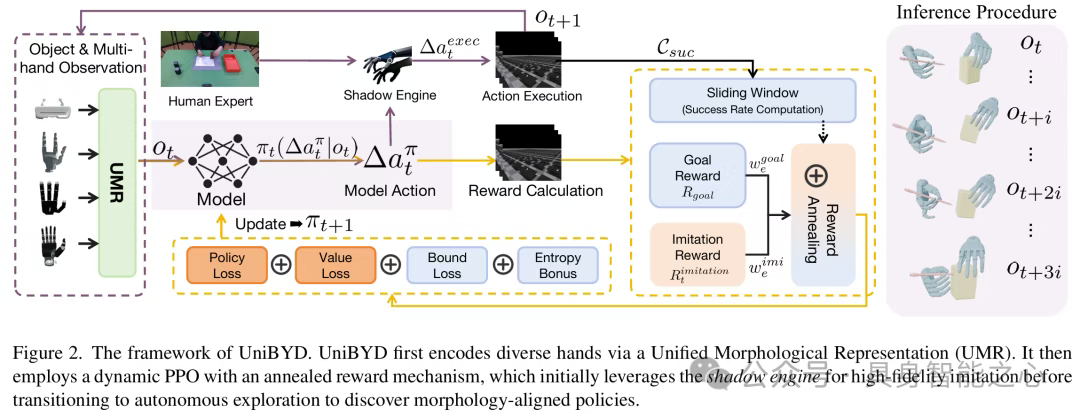
UniBYD是一套统一的强化学习框架,通过统一形态表示、动态强化学习机制、精细模仿引导三大核心组件,实现从模仿到探索的平滑过渡,最终学到适配机器人形态的操作策略(figure2)。
图片
统一形态表示(UMR):跨形态建模的基础
为解决不同机器人手形态(自由度、手指数量、刚体数量)的建模差异,UMR将动态状态与静态属性统一为固定维度表示:
动态状态处理:手腕状态固定为13维(位置、姿态、速度);关节状态(角度、速度)通过零填充至最大自由度,并对关节角度进行三角函数编码(、)避免环绕问题,得到填充后的关节状态:
静态属性补充:从URDF模型提取手指数量、自由度、刚体数量,构成静态描述符;
最终观测向量:拼接手腕状态、填充后关节状态与静态描述符,即,让政策网络能处理任意形态的机器人手。
动态PPO:从模仿到探索的渐进式学习
基于UMR提供的统一观测空间,动态PPO通过奖励退火机制和损失协同平衡,实现从模仿人类到自主探索的平滑过渡。
(1)奖励退火机制:动态调整模仿与探索权重
设计两类核心奖励,并通过权重动态变化引导学习阶段过渡:
模仿奖励():稠密奖励,量化当前状态与人类演示状态的相似度,涵盖手腕姿态、指尖位置、关节运动、物体状态等多维度差异,同时加入动作能耗惩罚:
目标奖励():稀疏奖励,仅当任务成功完成时给予固定奖励,引导策略关注任务目标而非单纯模仿:
动态权重调整:总奖励为两类奖励的加权和,权重随训练进程、模仿质量(滑动窗口平均模仿奖励)和成功率()动态变化:
权重变化分为三阶段:
早期模仿阶段(或):,完全依赖模仿奖励;
混合阶段:,模仿权重随成功率衰减,逐步转向目标奖励;
探索阶段():(极小值),策略完全以任务成功为导向自主探索。
(2)损失协同平衡:保证探索有效性与物理可行性
为避免过早收敛和动作超出物理范围,在PPO目标中加入两类损失:
熵正则化:鼓励策略探索,系数随训练线性衰减,早期探索充分,后期逐步收敛:
边界损失:通过可微软边界惩罚,避免动作均值超出物理范围,解决硬裁剪破坏梯度的问题:
最终PPO目标函数:
熵正则化与边界损失形成协同:前者促进探索,后者约束探索在物理可行范围内。
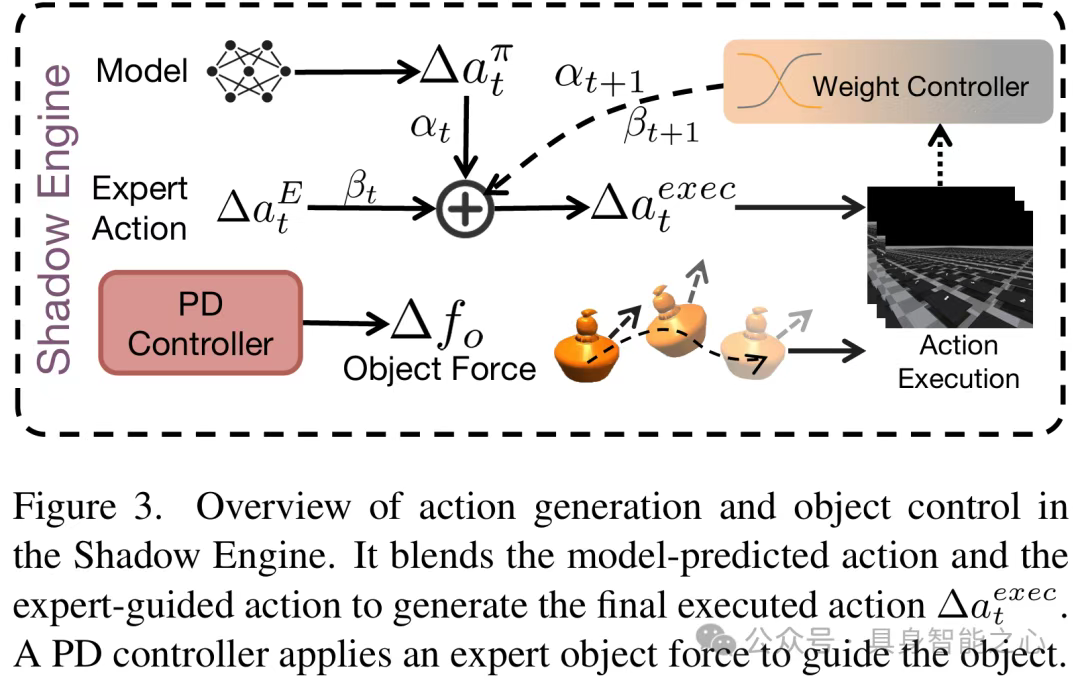
混合马尔可夫影子引擎:早期模仿的精细引导
早期训练中,政策网络较弱,微小动作偏差会累积导致任务失败,影子引擎通过动作混合和对象辅助控制解决这一问题(figure3):
图片
(1)灵巧手控制:混合政策与专家动作
执行动作并非单纯的政策预测,而是政策动作与人类专家动作的加权混合,权重随训练epoch线性调整:
早期():完全依赖专家动作,政策学习单步操作,避免误差累积;
中期(衰减):逐步增加政策动作权重,让政策在专家引导下学习状态转移逻辑;
后期():完全依赖政策动作,过渡到纯马尔可夫决策过程。
(2)对象控制:PD控制器辅助稳定
通过PD控制器对操作对象施加动态支撑力,约束对象沿专家轨迹运动,避免掉落或大幅偏离,支撑力增益随训练同步衰减:
实验设计与核心结果
为全面验证框架性能,设计了UniManip基准和多维度实验,涵盖模拟与真实世界场景。
- UniManip基准:首个跨形态机器人操作基准
任务覆盖:29类单/双手操作任务,适配2指、3指、5指机器人手(5指支持双手任务,2/3指仅单任务);
评价指标:
成功率(SR):所有时间步满足位置误差≤3cm、姿态误差≤30°的任务占比;
位置误差(PE)/姿态误差(OE):成功任务中对象状态与目标的平均偏差;
适配分数(AS):专家评分(0-10),评估策略与机器人形态的适配性和操作质量。 - 对比实验:超越现有SOTA
对比基于逆运动学的重定向方法、ManipTrans(当前SOTA)、DexMachina*(复现版本),结果显示(table1):
图片
跨形态泛化:唯一在所有手形态(2指、3指、5指单/双手)上均实现高成功率的框架;
成功率提升:整体比ManipTrans高67.9%,5指单任务从29.75%提升至87.47%,5指双手任务达到78.07%(其他方法均失败);
操作精度:PE和OE分别降低81.65%和58.77%,AS达到8.83(远超ManipTrans的6.69)。
可视化结果(figure4)显示:ManipTrans机械复制人类三指抓握马克杯的动作,因机器人手指过宽导致滑落;而UniBYD适配机器人形态,采用两指穿柄+小指支撑的策略,成功完成任务。
- 消融实验:组件有效性验证
通过逐步添加核心组件(影子引擎SE、目标奖励GR、损失协同平衡LSC),验证各模块贡献(table2):
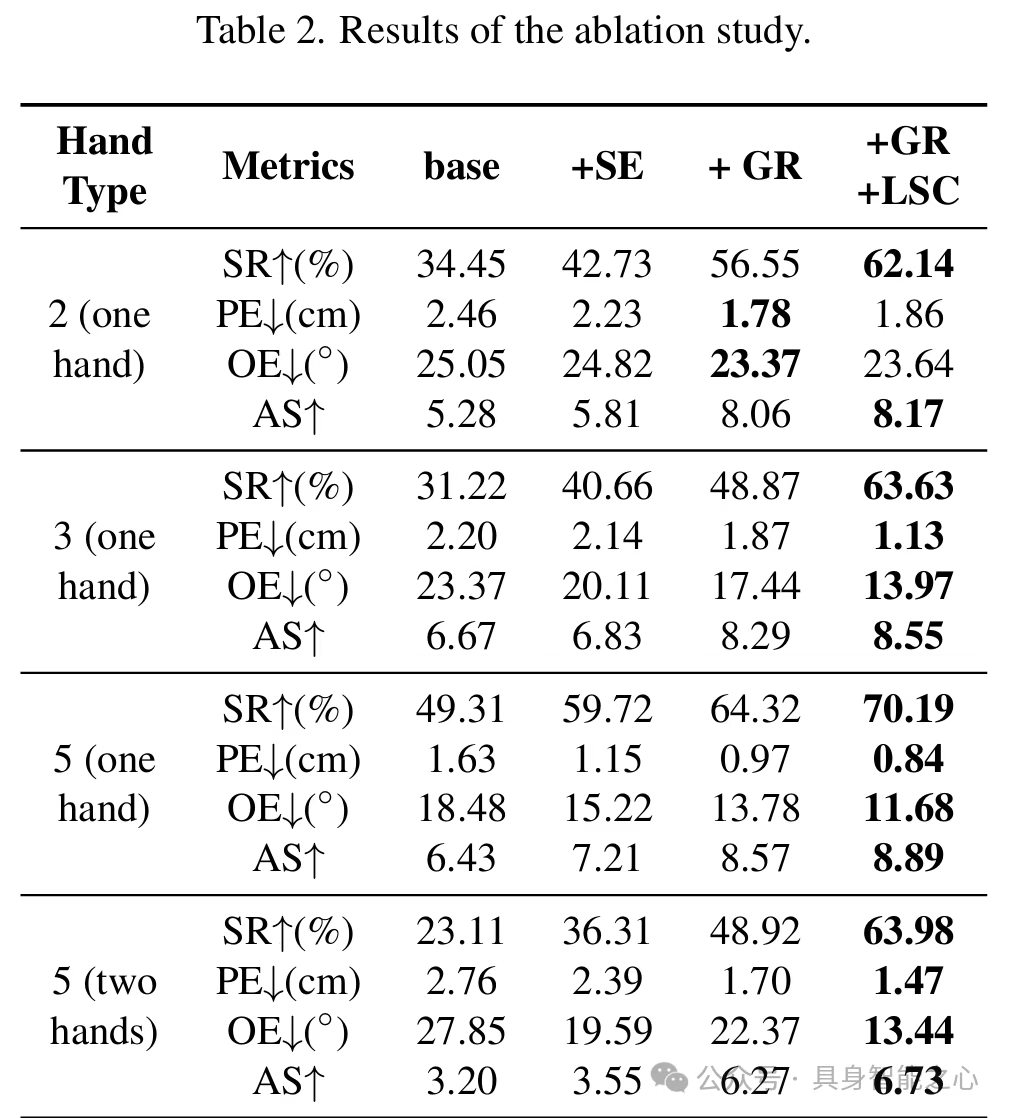
基础模型(仅模仿奖励):SR较低,无法适配形态;
+SE:SR提升10.33%,解决早期训练稳定性问题;
+SE+GR:SR再提升20.14%,AS达7.80,目标奖励有效引导形态适配策略探索;
+SE+GR+LSC:性能最优,避免过早收敛,发现更优策略。
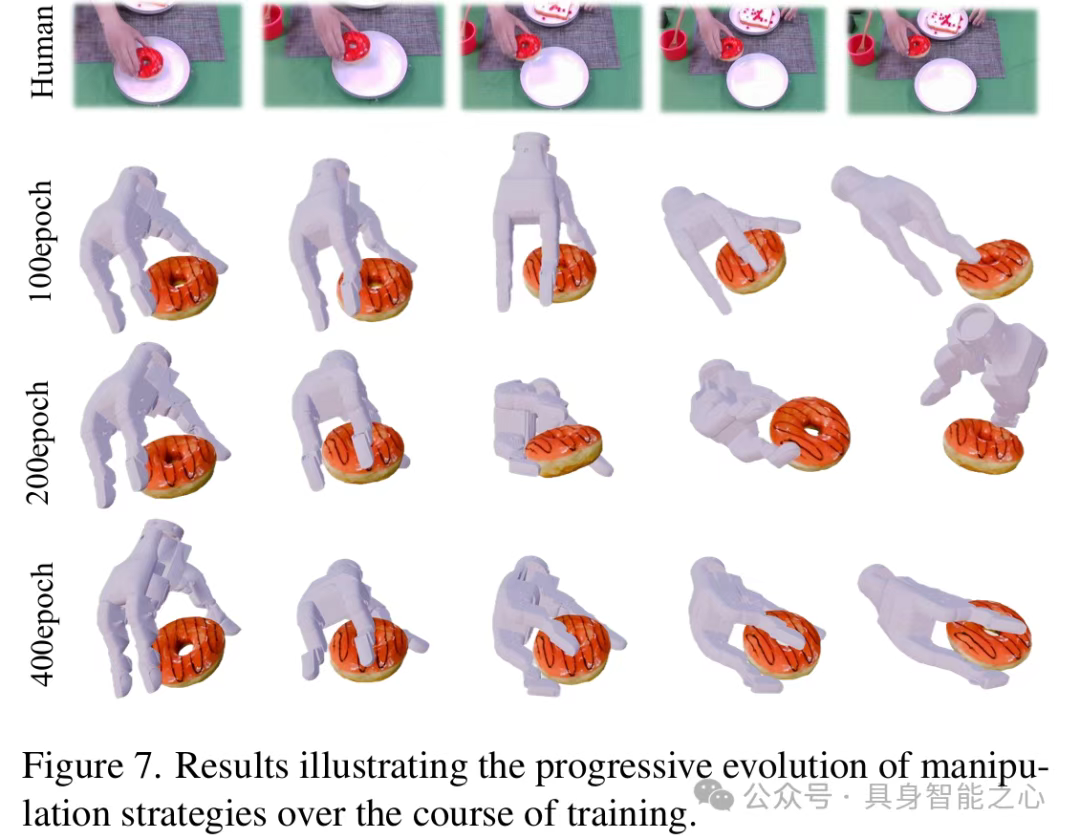
训练过程可视化(figure5)显示:基础模型快速陷入局部最优,而UniBYD通过组件协同,后期成功率持续上升并稳定在高值;策略进化过程(figure7)显示,训练从单纯模仿逐步过渡到适配机器人形态的自主探索,最终形成高效操作策略。
图片
- 真实世界迁移:从模拟到实物的有效性
在X-Arm 2指、Casia Hand-G 3指、OHandT M 5指机器人上验证,任务成功率分别达到52%(26/50)、64%(32/50)、70%(35/50)。figure8显示,UniBYD针对不同手形态调整策略:2指斜向夹紧烧杯,3指环绕包裹烧杯,充分适配硬件特性。
核心结论与意义
范式突破:跳出"复制人类动作"的局限,提出"形态适配策略"学习范式,通过动态强化学习实现从模仿到探索的平滑过渡;
泛化能力:UMR统一了不同形态机器人手的表示,使框架能直接适配2指、3指、5指单/双手,解决了跨形态泛化的核心难题;
性能与实用性:在UniManip基准上大幅超越SOTA,且成功迁移至真实世界机器人,为多样化机器人操作任务提供了通用解决方案;
基准价值:UniManip作为首个跨形态操作基准,填补了现有评估体系的空白,为该领域研究提供了统一的对比标准。
参考
1UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations